对于来自字符串源的PythonxmlElementTree?感兴趣的读者,本文将提供您所需要的所有信息,我们将详细讲解来自字符串灰色,并且为您提供关于pythonXMLElementTree的增删改查
对于来自字符串源的Python xml ElementTree?感兴趣的读者,本文将提供您所需要的所有信息,我们将详细讲解来自字符串灰色,并且为您提供关于python XML ElementTree的增删改查、python xml.etree.ElementTree遍历xml所有节点实例详解、python XML文件解析:用ElementTree解析XML、python xml解析之 xml.etree.ElementTree的宝贵知识。
本文目录一览:- 来自字符串源的Python xml ElementTree?(来自字符串灰色)
- python XML ElementTree的增删改查
- python xml.etree.ElementTree遍历xml所有节点实例详解
- python XML文件解析:用ElementTree解析XML
- python xml解析之 xml.etree.ElementTree
")
来自字符串源的Python xml ElementTree?(来自字符串灰色)
ElementTree.parse从文件读取,如果我已经在字符串中包含XML数据,该如何使用?
也许我在这里丢失了一些东西,但是必须有一种方法可以使用ElementTree而不将字符串写出到文件中并再次读取它。
xml.etree.elementtree
答案1
小编典典如果您xml.etree.ElementTree.parse用于从文件中进行解析,则可以使用xml.etree.ElementTree.fromstring从文本中进行解析。
参见xml.etree.ElementTree

python XML ElementTree的增删改查
import xml.etree.ElementTree as ET
"""
ElementTree.write() 将构建的XML文档写入(更新)文件。
Element.set(key, value) 添加和修改属性
Element.text = '''' 直接改变字段内容
Element.remove(Element) 删除Element节点
Element.append(Element) 为当前的Elment对象添加子对象
ET.SubElement(Element,tag)创建子节点
"""
# 增加自动缩进换行
def indent(elem, level=0):
i = "\n" + level*" "
if len(elem):
if not elem.text or not elem.text.strip():
elem.text = i + " "
if not elem.tail or not elem.tail.strip():
elem.tail = i
for elem in elem:
indent(elem, level+1)
if not elem.tail or not elem.tail.strip():
elem.tail = i
else:
if level and (not elem.tail or not elem.tail.strip()):
elem.tail = i
#------------新增XML----------
#创建根节点
a = ET.Element("student")
#创建子节点,并添加属性
b = ET.SubElement(a,"name")
b.attrib = {"NO.":"001"}
#添加数据
b.text = "张三"
#创建elementtree对象,写文件
indent(a,0)
tree = ET.ElementTree(a)
tree.write("writeXml.xml",encoding="utf-8")
#----------编辑XML--------
# 读取待修改文件
updateTree = ET.parse("writeXml.xml")
root = updateTree.getroot()
# --新增--
# 创建新节点并添加为root的子节点
newnode = ET.Element("name")
newnode.attrib = {"NO.":"003"}
newnode.text = "张三水"
root.append(newnode)
#---修改---
sub1 = root.findall("name")[2]
# --修改节点的属性
sub1.set("NO.","100")
# --修改节点内文本
sub1.text="陈真"
#----删除---
#--删除标签内文本
sub1.text = ""
#--删除标签的属性
del sub1.attrib["NO."]
#--删除一个节点
root.remove(sub1)
# 写回原文件
indent(root,0)
updateTree.write("writeXml.xml",encoding="utf-8", xml_declaration=True)XML操作封装
def change_node_properties(nodelist, kv_map, is_delete=False):
''''''修改/增加 /删除 节点的属性及属性值
nodelist: 节点列表
kv_map:属性及属性值map''''''
for node in nodelist:
for key in kv_map:
if is_delete:
if key in node.attrib:
del node.attrib[key]
else:
node.set(key, kv_map.get(key))
def change_node_text(nodelist, text, is_add=False, is_delete=False):
''''''改变/增加/删除一个节点的文本内容
nodelist:节点列表
text : 更新后的文本''''''
for node in nodelist:
if is_add:
node.text += text
elif is_delete:
node.text = ""
else:
node.text = text
def create_childnode(node,tag, property_map, content):
''''''新造一个子节点
node:节点
tag:子节点标签
property_map:属性及属性值map
content: 节点闭合标签里的文本内容
''''''
element = ET.Element(tag, property_map)
element.text = content
node.append(element)
def del_node_by_tagkeyvalue(node, tag, kv_map):
''''''通过属性及属性值定位一个节点,并删除之
node: 父节点
tag:子节点标签
kv_map: 属性及属性值列表''''''
for child in node:
if child.tag == tag and child.attrib==kv_map:
node.remove(child)

python xml.etree.ElementTree遍历xml所有节点实例详解
python xml.etree.ElementTree遍历xml所有节点
XML文件内容:
<students> <student name='刘备' sex='男' age='35'/> <student name='吕布' sex='男' age='38'/> <student name='貂蝉' sex='女' age='22'/> </students>
代码:
#-*- coding: UTF-8 -*-
# 从文件中读取数据
import xml.etree.ElementTree as ET
#全局唯一标识
unique_id = 1
#遍历所有的节点
def walkData(root_node,level,result_list):
global unique_id
temp_list =[unique_id,root_node.tag,root_node.attrib]
result_list.append(temp_list)
unique_id += 1
#遍历每个子节点
children_node = root_node.getchildren()
if len(children_node) == 0:
return
for child in children_node:
walkData(child,level + 1,result_list)
return
#获得原始数据
#out:
#[
# #ID,Level,Attr Map
# [1,1,{'ID':1,'Name':'test1'}],# [2,'Name':'test2'}],#]
def getXmlData(file_name):
level = 1 #节点的深度从1开始
result_list = []
root = ET.parse(file_name).getroot()
walkData(root,result_list)
return result_list
if __name__ == '__main__':
file_name = 'test.xml'
R = getXmlData(file_name)
for x in R:
print x
pass
输出结果:
[1,'students',{}]
[2,2,'student',{'age': '35','name': u'\u5218\u5907','sex': u'\u7537'}]
[3,{'age': '38','name': u'\u5415\u5e03','sex': u'\u7537'}]
[4,{'age': '22','name': u'\u8c82\u8749','sex': u'\u5973'}]
感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!

python XML文件解析:用ElementTree解析XML
Python标准库中,提供了ET的两种实现。一个是纯Python实现的xml.etree.ElementTree,另一个是速度更快的C语言实现xml.etree.cElementTree。请记住始终使用C语言实现,因为它的速度要快很多,而且内存消耗也要少很多。如果你所使用的Python版本中没有cElementTree所需的加速模块,你可以这样导入模块
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
xml file
<?xml version="1.0"?>
<doc>
<branch name="codingpy.com" hash="1cdf045c">
text,source
</branch>
<branch name="release01" hash="f200013e">
<sub-branch name="subrelease01">
xml,sgml
</sub-branch>
</branch>
<branch name="invalid">
</branch>
</doc>
1、将XML文档解析为树(tree)
加载这个文档,并进行解析
>>> import xml.etree.ElementTree as ET
>>> tree = ET.ElementTree(file=''doc1.xml'')获取根元素(root element):
>>> tree.getroot()
<Element ''doc'' at 0x11eb780>根元素(root)是一个Element对象,看根元素都有哪些属性:
>>> root = tree.getroot()
>>> root.tag, root.attrib
(''doc'', {})根元素并没有属性。与其他Element对象一样,根元素也具备遍历其直接子元素的接口:
>>> for child_of_root in root:
... print child_of_root.tag, child_of_root.attrib
...
branch {''hash'': ''1cdf045c'', ''name'': ''codingpy.com''}
branch {''hash'': ''f200013e'', ''name'': ''release01''}
branch {''name'': ''invalid''}还可以通过索引值来访问特定的子元素:
>>> root[0].tag, root[0].text
(''branch'', ''\n text,source\n '')
2、查找需要的元素
Element对象有一个iter方法,可以对某个元素对象之下所有的子元素进行深度优先遍历(DFS)。ElementTree对象同样也有这个方法。下面是查找XML文档中所有元素的最简单方法:
>>> for elem in tree.iter():
... print elem.tag, elem.attrib
...
doc {}
branch {''hash'': ''1cdf045c'', ''name'': ''codingpy.com''}
branch {''hash'': ''f200013e'', ''name'': ''release01''}
sub-branch {''name'': ''subrelease01''}
branch {''name'': ''invalid''}可以对树进行任意遍历——遍历所有元素,查找出自己感兴趣的属性。但是ET可以让这个工作更加简便、快捷。iter方法可以接受tag名称,然后遍历所有具备所提供tag的元素:
>>> for elem in tree.iter(tag=''branch''):
... print elem.tag, elem.attrib
...
branch {''hash'': ''1cdf045c'', ''name'': ''codingpy.com''}
branch {''hash'': ''f200013e'', ''name'': ''release01''}
branch {''name'': ''invalid''}
3、支持通过XPath查找元素
使用XPath查找感兴趣的元素,更加方便。Element对象中有一些find方法可以接受Xpath路径作为参数,find方法会返回第一个匹配的子元素,findall以列表的形式返回所有匹配的子元素, iterfind则返回一个所有匹配元素的迭代器(iterator)。ElementTree对象也具备这些方法,相应地它的查找是从根节点开始的。
下面是一个使用XPath查找元素的示例:
>>> for elem in tree.iterfind(''branch/sub-branch''):
... print elem.tag, elem.attrib
...
sub-branch {''name'': ''subrelease01''}上面的代码返回了branch元素之下所有tag为sub-branch的元素。接下来查找所有具备某个name属性的branch元素:
>>> for elem in tree.iterfind(''branch[@name="release01"]''):
... print elem.tag, elem.attrib
...
branch {''hash'': ''f200013e'', ''name'': ''release01''}
4、构建XML文档
利用ET,很容易就可以完成XML文档构建,并写入保存为文件。ElementTree对象的write方法就可以实现这个需求。
一般来说,有两种主要使用场景。一是你先读取一个XML文档,进行修改,然后再将修改写入文档,二是从头创建一个新XML文档。
修改文档的话,可以通过调整Element对象来实现。请看下面的例子:
>>> root = tree.getroot()
>>> del root[2]
>>> root[0].set(''foo'', ''bar'')
>>> for subelem in root:
... print subelem.tag, subelem.attrib
...
branch {''foo'': ''bar'', ''hash'': ''1cdf045c'', ''name'': ''codingpy.com''}
branch {''hash'': ''f200013e'', ''name'': ''release01''}在上面的代码中,我们删除了root元素的第三个子元素,为第一个子元素增加了新属性。这个树可以重新写入至文件中。最终的XML文档应该是下面这样的:
>>> import sys
>>> tree.write(sys.stdout)
<doc>
<branch foo="bar" hash="1cdf045c" name="codingpy.com">
text,source
</branch>
<branch hash="f200013e" name="release01">
<sub-branch name="subrelease01">
xml,sgml
</sub-branch>
</branch>
</doc>
请注意,文档中元素的属性顺序与原文档不同。这是因为ET是以字典的形式保存属性的,而字典是一个无序的数据结构。当然,XML也不关注属性的顺序。
从头构建一个完整的文档也很容易。ET模块提供了一个SubElement工厂函数,让创建元素的过程变得很简单:
>>> a = ET.Element(''elem'')
>>> c = ET.SubElement(a, ''child1'')
>>> c.text = "some text"
>>> d = ET.SubElement(a, ''child2'')
>>> b = ET.Element(''elem_b'')
>>> root = ET.Element(''root'')
>>> root.extend((a, b))
>>> tree = ET.ElementTree(root)
>>> tree.write(sys.stdout)
<root><elem><child1>some text</child1><child2 /></elem><elem_b /></root>
拿例子敲下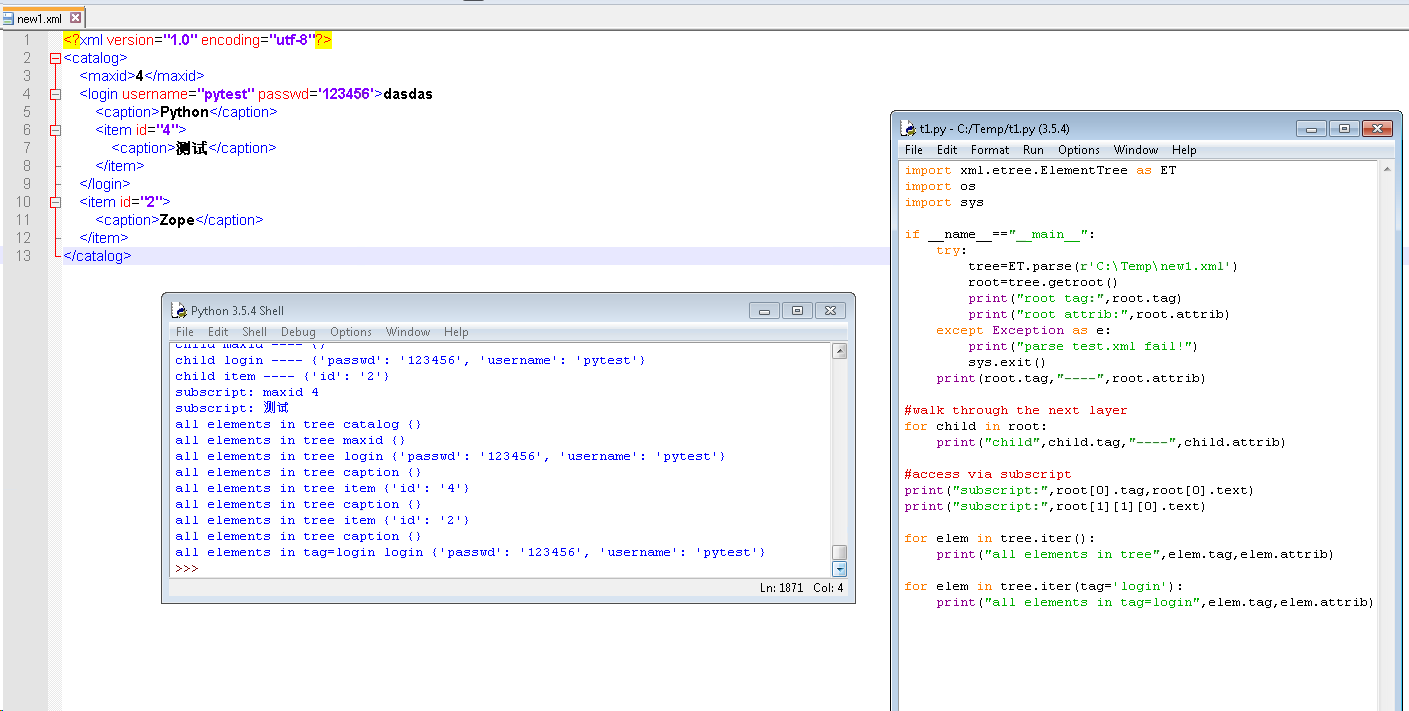

python xml解析之 xml.etree.ElementTree
import xml.etree.ElementTree as tree
import io
xml = ''''''<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
''''''
parse = tree.fromstring(xml) #type:tree.Element #根节点
for e in parse: #遍历
print(e.tag) # 节点名称
print(e.attrib.get(''name''))#节点属性
result = parse.findall(''country'') # 只能找到子节点 第一层
print(result) #[<Element ''country'' at 0x0000000001DDE7C8>, <Element ''country'' at 0x000000000291F908>, <Element ''country'' at 0x000000000291FA98>]
print([e for e in parse.iter(''rank'') if e.attrib.get(''updated'') == ''yes'']) #递归遍历所有
#父节点 parse 添加子节点
print(tree.SubElement(parse, ''test'', attrib={''name'': ''ceshi''})) #工厂方式添加子节点
print(tree.tostring(parse).decode(''utf-8'')) #输出xml文档
我们今天的关于来自字符串源的Python xml ElementTree?和来自字符串灰色的分享已经告一段落,感谢您的关注,如果您想了解更多关于python XML ElementTree的增删改查、python xml.etree.ElementTree遍历xml所有节点实例详解、python XML文件解析:用ElementTree解析XML、python xml解析之 xml.etree.ElementTree的相关信息,请在本站查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

