如果您想了解SQLAlchemyJoinedload过滤器列和sqldeveloper过滤器的知识,那么本篇文章将是您的不二之选。我们将深入剖析SQLAlchemyJoinedload过滤器列的各个方
如果您想了解SQLAlchemy Joinedload过滤器列和sqldeveloper过滤器的知识,那么本篇文章将是您的不二之选。我们将深入剖析SQLAlchemy Joinedload过滤器列的各个方面,并为您解答sqldeveloper过滤器的疑在这篇文章中,我们将为您介绍SQLAlchemy Joinedload过滤器列的相关知识,同时也会详细的解释sqldeveloper过滤器的运用方法,并给出实际的案例分析,希望能帮助到您!
本文目录一览:- SQLAlchemy Joinedload过滤器列(sqldeveloper过滤器)
- apscheduler遇到错误:SQLAlchemyJobStore requires SQLAlchemy
- flask_sqlalchemy join的正确使用方法
- flask_sqlalchemy和sqlalchemy的区别有哪些?
- flask_sqlalchemy和sqlalchemy联系区别及其使用方式
")
SQLAlchemy Joinedload过滤器列(sqldeveloper过滤器)
嗨,我想使用joinedload对查询进行过滤。但是我似乎无法使其正常工作。以下是我的示例查询
result = ( session.query(Work). options( joinedload(Work.company_users). joinedload(CompanyUser.user) ). filter(Work.id == 1). filter(User.first_name == ''The name''). <<--- I can''t get this to work. all() )运行此命令时,它返回的行超出了我的期望。实际结果应仅返回8行。但是执行此查询后,它返回234行,这比我预期的要多
答案1
小编典典它不起作用的原因是joinedload(以及所有其他关系加载技术)是完全透明的。也就是说,joinedload在查询中包含a不会导致填充关系,而不会以任何其他方式影响它。您应该阅读“加入渴望的禅宗”,其开头为:
由于急切的联合加载似乎与的使用非常相似
Query.join(),因此经常混淆应何时使用以及如何使用它。了解区别的关键在于,尽管该区别Query.join()用于更改查询的结果,但joinedload()要花很长时间不更改查询的结果,而是隐藏呈现的联接的效果,以仅允许存在相关对象。
技巧之一是对无法使用的联接表使用别名。然后,您的查询最终在Work和User之间执行隐式交叉联接,从而在多余的行之间进行隐式交叉联接。因此,为了根据联接的表进行过滤,请使用Query.join():
session.query(Work).\ join(Work.company_users).\ join(CompanyUser.user).\ filter(Work.id == 1).\ filter(User.first_name == ''The name'').\ all()并且如果还需要适当的预加载,则可以使用以下命令指示查询已包含联接contains_eager():
session.query(Work).\ join(Work.company_users).\ join(CompanyUser.user).\ options(contains_eager(Work.company_users). contains_eager(CompanyUser.user)).\ filter(Work.id == 1).\ filter(User.first_name == ''The name'').\ all()请注意对的链接调用contains_eager()。

apscheduler遇到错误:SQLAlchemyJobStore requires SQLAlchemy

英文:SQLAlchemyJobStore requires SQLAlchemy installed
翻译下:SQLAlchemyJobStore需要安装SQLAlchemy
说白了就是需要安装SQLAlchemy
安装也很简单
pip install sqlalchemy
关注我获取更多内容

flask_sqlalchemy join的正确使用方法
flask_sqlalchemy包裹了sqlalchemy一些操作,其能够更好的与flask协作,flask_sqlalchemy中的大部分api来自于sqlalchemy.orm.query.Query,直接使用集成db.Model类的query属性就可以得到Query类,例如一下实例
class Users(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(20), unique=True, nullable=False)
password = db.Column(db.String(40), nullable=False)
class File(db.Model):
id = db.Column(db.Integer, primary_key=True)
userid = db.Column(db.Integer, db.ForeignKey("users.id"), nullable=False)
filename = db.Column(db.String(40), nullable=False)
filesize = db.Column(db.Integer)
直接使用File.query就会返回db.session.query(SomeMappedClass),使用的api参照Query的api。
在使用Qurey的join的时候采用代码,File.query.join(Users.id),这是官方给出的文档中的使用方式
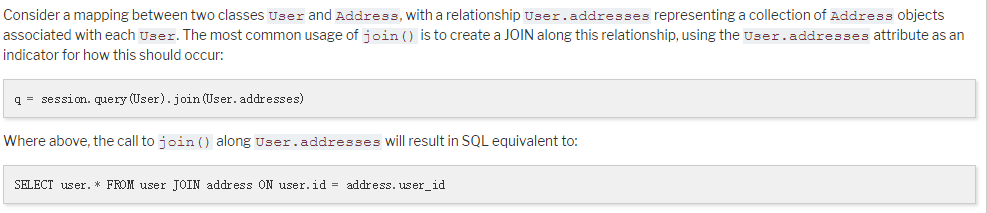
但我在使用后出现错误

后来才发现,文档中说明了使用条件在User与Address存在mapping的,而我这里并没有,使用的db.Model类与官方的类也不相同,因此在文档后续中查找到了下面一条信息
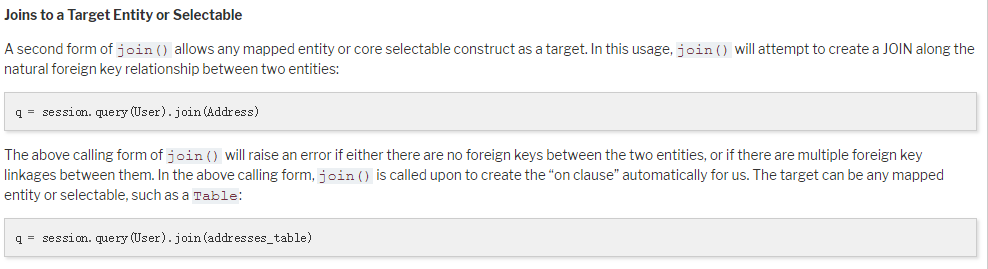
这个是将传入的参数换为入口或者是表,这样才了解到之前的用法是有问题,按照这里的说法应该是可以传入一个表或者是另外的query,因此参数应该是这样的
File.query.join(Users.query)
File.query.join(Users)
File.query.join(Users.__table__)
通过源代码可以看到,flask_sqlalchemy会将定义的Column创建为一张sqlalchemy表并存在__table__中。而在这里Users.query代表了一个query入口,Model也应该实现了类似query相应的入口,因此可以简写。

flask_sqlalchemy和sqlalchemy的区别有哪些?
概要的说:
SQLAlchemy是python社区使用最广泛的ORM之一,SQL-Alchmy直译过来就是SQL炼金术。
Flask-SQLAlchemy集成了SQLAlchemy,它简化了连接数据库服务器、管理数据库操作会话等各类工作,让Flask中的数据处理体验变得更加轻松。
虽然我们要使用的大部分类和函数都由SQLAlchmey提供,但在Flask-SQLAlchemy中,大多数情况下,我们不需要手动从SQLAlchemy导入类或函数。在sqlalchemy和sqlalchemy.orm模块中实现的类和函数
,以及其他几个常用的模块和对象都可以作为db对象的属性调用。当我们创建这样的调用时,Flask-SQLAlchemy会自动把这些调用转发到对应的类、函数或模块
具体区别:
区别1:定义模型:
flask_sqlalchemy需要使用db.Column,而sqlalchemy则不需要
flask_sqlalchemy写法:
1 class Role(db.Model):
2 __tablename__ = ''roles''
3 id = db.Column(db.Integer, primary_key=True)
4 name = db.Column(db.String(64))
5 user = db.relationship(''User'', backref=''role'')
6
7 def __repr__(self):
8 return ''<Role %r>'' % self.name
sqlalcehmy写法:
1 class EnvConfig(Base):
2 __tablename__="env_config"
3 id=Column(Integer,primary_key=True)
4 host = Column(String(50)) # 默认值 1 0:appapi.5i5j.com,
5 def __repr__(self):
6 return "<EnvConfig.%s>"%self.host区别2:声明字段类型
flask_sqlalchemy使用定义字段类型时无须额外导入类型,一切类型都通过db对象直接调用
1 from flask import Flask
2 from flask_sqlalchemy import SQLAlchemy
3
4 app = Flask(__name__)
5
6 # 设置连接数据库的URL
7 # 不同的数据库采用不同的引擎连接语句:
8 # MySQL: mysql://username:password@hostname/database
9
10 app.config[''SQLALCHEMY_DATABASE_URI''] =''mysql+mysqlconnector://root:admin123456@10.1.71.32:3306/test''
11
12 # 设置每次请求结束后会自动提交数据库的改动
13 app.config[''SQLALCHEMY_COMMIT_ON_TEARDOWN''] = True
14 app.config[''SQLALCHEMY_TRACK_MODIFICATIONS''] = True
15
16 # 查询时显示原始SQL语句
17 app.config[''SQLALCHEMY_ECHO''] = False
18 db = SQLAlchemy(app)
sqlalchemy需要单独导入字段声明类型:
1 from sqlalchemy.ext.declarative import declarative_base
2 from sqlalchemy import Column,Integer,Text,String,Enum
3 Base =declarative_base()完整的代码片断:
# 导入依赖
from sqlalchemy import Column, String, create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# 创建对象的基类
Base = declarative_base()
# 定义User对象
class User(Base):
# 表的名字
__tablename__ = ''user''
# 表的结构
id = Column(String(20), primary_key=True)
name = Column(String(20))
# 初始化数据库链接
engine = create_engine(''mysql+mysqlconnector://root:123456@localhost:3306/test'')
# 创建DBSession类型
DBSession = sessionmaker(bind=engine)
# 添加
# 创建Session对象
session = DBSession()
# 创建User对象
new_user = User(id=''5'', name=''Bob'')
# 添加到session
session.add(new_user)
# 提交
session.commit()
# 关闭session
session.close()
# 查询
# 创建session
session = DBSession()
# 利用session创建查询,query(对象类).filter(条件).one()/all()
user = session.query(User).filter(User.id==''5'').one()
print(''type:{0}''.format(type(user)))
print(''name:{0}''.format(user.name))
# 关闭session
session.close()
# 更新
session = DBSession()
user_result = session.query(User).filter_by(id=''1'').first()
user_result.name = "jack"
session.commit()
session.close()
# 删除
session = DBSession()
user_willdel = session.query(User).filter_by(id=''5'').first()
session.delete(user4._willdel)
session.commit()
session.close()
区别3:
查询方式不一样
sqlalchemy通过session.query(模型名)查询
而flask_sqlalchemy则是通过 模型名.query查询
#SQLAlchemy
result_id = session.query(ScriptRunResult).order_by(ScriptRunResult.id.desc()).all()[0].id
result_id =
#Flask-SQLAlchemy
ScriptRunResult.query.order_by(ScriptRunResult.id.desc()).all()[0].id

flask_sqlalchemy和sqlalchemy联系区别及其使用方式
### 使用SQLAlchemy去连接数据库:
1.使用SQLALchemy去连接数据库,需要使用一些配置信息,然后将他们组合成满足条件的字符串:
HOSTNAME = ''127.0.0.1''
PORT = ''3306''
DATABASE = ''1''
USERNAME = ''root''
PASSWORD = ''root''
DB_URI = "mysql+mysqlconnector://{username}:{password}@{host}:{port}/{db}?charset=utf8".format(username=USERNAME,password=PASSWORD,host=HOSTNAME,port=PORT,db=DATABASE)
2.然后使用`create_engine`创建一个引擎`engine`,
engine = create_engine(DB_URI)
3.构建session对象:所有和数据库的ORM操作都必须通过一个叫做`session`的会话对象来实现,通过以下代码来获取会话对象:
from sqlalchemy.orm import sessionmaker
engine = create_engine(DB_URI)
session = sessionmaker(engine)()
4.将ORM模型映射到数据库中:
(1)用`declarative_base`根据`engine`创建一个ORM基类。
from sqlalchemy.ext.declarative import declarative_base
engine = create_engine(DB_URI)
Base = declarative_base(engine)
(2)用这个`Base`类作为基类来写自己的ORM类。要定义`__tablename__`类属性,来指定这个模型映射到数据库中的表名。
class Person(Base):
__tablename__ = ''person''
(3)在这个ORM模型中创建一些属性,来跟表中的字段进行一一映射。这些属性必须是sqlalchemy给我们提供好的数据类型。
from sqlalchemy import create_engine,Column,Integer,String
id = Column(Integer,primary_key=True,autoincrement=True)
(4)使用`Base.metadata.create_all()`来将模型映射到数据库中。
(5) 一旦使用`Base.metadata.create_all()`将模型映射到数据库中后,即使改变了模型的字段,也不会重新映射了。目前来说,只能删除这个表重新建了
# Base.metadata.drop_all() # 删除这个表以及里面的数据
# Base.metadata.create_all() # 新建表以及表结构
### 完整示例代码
from sqlalchemy import create_engine,Column,Integer,String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
HOSTNAME = ''127.0.0.1''
PORT = ''3306''
DATABASE = ''1''
USERNAME = ''root''
PASSWORD = ''root''
# dialect+driver://username:password@host:port/database
DB_URI = "mysql+pymysql://{username}:{password}@{host}:{port}/{db}?charset=utf8".format(username=USERNAME,password=PASSWORD,host=HOSTNAME,port=PORT,db=DATABASE)
engine = create_engine(DB_URI)
Base = declarative_base(engine)
session = sessionmaker(engine)()
class Person(Base):
__tablename__ = ''person''
id = Column(Integer,primary_key=True,autoincrement=True)
name = Column(String(50))
age = Column(Integer)
country = Column(String(50))
# Base.metadata.drop_all()
# Base.metadata.create_all()
# 新增多条数据
p1 = Person(name=''zhiliao1'',age=19,country=''china'')
p2 = Person(name=''zhiliao2'',age=20,country=''china'')
session.add_all([p1,p2])
session.commit()
# 查询数据
person = session.query(Person).first()
print(person)
### 使用Flask-SQLAlchemy去连接数据库:
1.数据库连接:
(1)跟sqlalchemy一样,定义好数据库连接字符串DB_URI。
(2)将这个定义好的数据库连接字符串DB_URI,通过`SQLALCHEMY_DATABASE_URI`这个键放到`app.config`中。
示例代码:app.config["SQLALCHEMY_DATABASE_URI"] = DB_URI
(3)使用`flask_sqlalchemy.SQLAlchemy`这个类定义一个对象,并将`app`传入进去。
示例代码:
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy(app)
2.创建ORM模型:
还是跟使用sqlalchemy一样,定义模型。现在不再是需要使用`delarative_base`来创建一个基类。而是使用`db.Model`来作为基类。
3.使用session:
以后session也不需要使用`sessionmaker`来创建了。直接使用`db.session`就可以了。操作这个session的时候就跟之前的`sqlalchemy`的`session`是一模一样的。
4.在模型类中,`Column`、`String`、`Integer`以及`relationship`等,都不需要导入了,直接使用`db`下面相应的属性名就可以了。
id = db.Column(db.Integer,primary_key=True,autoincrement=True)
# 将ORM模型映射到数据库:
1. db.drop_all()
2. db.create_all()
### 完整示例代码
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
HOSTNAME = ''127.0.0.1''
PORT = ''3306''
DATABASE = ''1''
USERNAME = ''root''
PASSWORD = ''root''
DB_URI = "mysql+pymysql://{username}:{password}@{host}:{port}/{db}?charset=utf8mb4".format(username=USERNAME,password=PASSWORD,host=HOSTNAME,port=PORT,db=DATABASE)
app.config[''SQLALCHEMY_DATABASE_URI''] = DB_URI
app.config[''SQLALCHEMY_TRACK_MODIFICATIONS''] = False
db = SQLAlchemy(app)
class UserModel(db.Model):
__tablename__ = ''user_model''
id = db.Column(db.Integer,primary_key=True,autoincrement=True)
username = db.Column(db.String(50),nullable=False)
def __repr__(self):
return "<User(username: %s)>" % self.username
# db.drop_all()
# db.create_all()
class Article(db.Model):
__tablename__ = ''article''
id = db.Column(db.Integer,primary_key=True,autoincrement=True)
title = db.Column(db.String(50),nullable=False)
# 新增数据
article = Article(title=''title one'')
db.session.add(article)
db.session.commit()
# 查询数据
article = Article.query.first()
print(article)
关于SQLAlchemy Joinedload过滤器列和sqldeveloper过滤器的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于apscheduler遇到错误:SQLAlchemyJobStore requires SQLAlchemy、flask_sqlalchemy join的正确使用方法、flask_sqlalchemy和sqlalchemy的区别有哪些?、flask_sqlalchemy和sqlalchemy联系区别及其使用方式等相关内容,可以在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

