本篇文章给大家谈谈阅读笔记ActivelearningfromCrowdswithunsureoption,以及阅读笔记摘抄大全的知识点,同时本文还将给你拓展175+CustomersAchieveM
本篇文章给大家谈谈阅读笔记 Active learning from Crowds with unsure option,以及阅读笔记摘抄大全的知识点,同时本文还将给你拓展175+ Customers Achieve Machine Learning Success with AWS’s Machine Learning Solutions Lab、A Discriminative Feature Learning Approach for Deep Face Recognition、A Diversity-Promoting Objective Function for Neural Conversation Models论文阅读、A Survey on Deep Learning for Named Entity Recognition(2020)阅读笔记等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- 阅读笔记 Active learning from Crowds with unsure option(阅读笔记摘抄大全)
- 175+ Customers Achieve Machine Learning Success with AWS’s Machine Learning Solutions Lab
- A Discriminative Feature Learning Approach for Deep Face Recognition
- A Diversity-Promoting Objective Function for Neural Conversation Models论文阅读
- A Survey on Deep Learning for Named Entity Recognition(2020)阅读笔记
")
阅读笔记 Active learning from Crowds with unsure option(阅读笔记摘抄大全)
这是 Tang ke 老师的文章。一篇写得非常好的文章。这篇paper 的 idea 和 算法 都很简单,但其有着不小的贡献,主要是其提出了 ALCU 这一框架。另外,其Paper 中用到了各种小的trick 。另外,实验部分很充分,很 convincing 为这篇paper 增色不少。
个人觉得有收获的点很多
1. Active Learning 和众包的关系:Active Learning 最终目的是要学一个分类模型,而现在一般众包干的事情是提供标记,所以Active Learning 一般可以利用众包,而众包无法利用active leanring。
2、这篇文章主要是在原来的基础上加上了工人可以提供 unsure option,也即 Active learning from crowds with unsure option,通过 unsure option 可以不强制不确定的工人提供标记。这更加逼近original Active learning,专家提供标记(标记昂贵且精度高,接近于 oracle)
3.这篇文章用了所谓的2个 SVM 模型,一个作为最终的二分类模型,一个作为工人是否会提供 unsure (negative) 的二分类模型。但工人是否提供 unsure 的这个二分类模型用于选择工人,当有很多工人时,这相当于避免了选取可能会给出 unsure 的工人,但是还是无法保证 选到的那个工人给出的标记的精度很高,没有对工人的精度的衡量,只判断工人是不是 unsure 。
4. SVM 模型作为了一个二值分类器,似乎公式不太对,没有把 label 写进去。
5.其在 related work 中提到 yan yan 2011 的工作看上去好,但是引入很难的中间过程,这与 vipnik 相冲突
6. Active learning 部分 用了最简单的 uncertainty sampling 作为询问策略,定义了一个奖励函数 实际上就是 (1/2-p)^2,其中 p 是通过 SVM 的输出嵌套上一个 logistic function 作为 后验概率。这个值的实际大小意义不大,但其排序大小可能还是有用的,相当于 靠近分类边界的先被挑选出来。
7. 这篇文章有自相矛盾的地方,文章通篇阐述 给 labeler 提供 unsure option 可以带来好处。但是实际的算法 ALUC-SVM 中选择 labeler 时,假定lablers 的数量足够多,且$g_t(x)$ 足够好,由于只选择一个最大的 $g_t(x)$ 对应的 labeler,则选中的labeler 提供 unsure option 的概率应该很小才对。或者说,$g_t(x)$ 能不能学的出来是个大问题。
另有一篇把 unsure option 扩展到 Crowdsourcing 的文章。

175+ Customers Achieve Machine Learning Success with AWS’s Machine Learning Solutions Lab
https://amazonaws-china.com/blogs/machine-learning/175-customers-achieve-machine-learning-success-with-awss-machine-learning-solutions-lab/
AWS introduced the Machine Learning (ML) Solutions Lab a little over two years ago to connect our machine learning experts and data scientists with AWS customers. Our goal was to help our customers solve their most pressing business problems using ML. We’ve helped our customers increase fraud detection rates, improved forecasting and predictions for more efficient operations, drive additional revenues through personalization, and even help organizations scale their response to crisis like human trafficking.
Since we began, we’ve successfully assisted over 175 customers across a diverse spectrum of industries including retail, healthcare, energy, public sector and sports to create new machine learning-powered solutions. And we’ve increased our capacity more than 5x and expanded from North America to Asia, Australia and Europe to meet the growing ML needs of our customers around the world.
In our partnership with the National Football League (NFL), we’ve identified and built an entirely new way for fans to engage with the sport through Next Gen Stats, which features stats such as Completion Probability, 3rd Down Conversion Probability, Expected Yards After Catch, Win Probability, and Catch Prediction. Today, Next Gen Stats are an important part of how fans experience the game. And recently we’ve kicked off a new initiative with the NFL to tackle the next challenge—predicting and limiting player injury. As part of this initiative we’re working with the NFL to develop the “Digital Athlete”, a virtual representation of a composite NFL player which will enable us to eventually predict injury and recovery trajectories
In healthcare, we’re working with Cerner, the world’s largest publicly traded healthcare IT company, to apply machine learning-driven solutions to its mission of improving the health of individuals and populations while reducing costs and increasing clinician satisfaction. One important area of this project is using health prediction capabilities to uncover important and potentially life-saving insights within trusted-source, digital health data. For example, using Amazon SageMaker we built a solution to enable researchers to query anonymized patient data to build complex models and algorithms that predicts congestive heart failure up to 15 months before clinical manifestation. And Cerner will also be using AWS AI services such as the newly introduced Amazon Transcribe Medical to free up physicians from tasks such as writing down notes through a virtual scribe.
In the public sector, we collaborated with the NASA Heliophysics Lab to better understand solar super storms. We brought together the expert scientists at NASA with the machine learning experts in the ML Solutions Lab and the AWS Professional Services organizations to improve the ability to predict and categorize solar super storms. With Amazon SageMaker, NASA is using unsupervised learning and anomaly detection to explore the extreme conditions associated with super storms. Such space weather can create radiation hazards for astronauts, cause upsets in satellite electronics, interfere with airplane and shipping radio communications, and damage electric power grids on the ground – making prediction and early warnings critical.
World Kinect Energy Services, a global leader in energy management, fuel supply, and sustainability, turned to the ML Solutions Lab to improve their ability to anticipate the impact of weather changes on energy prices. An important piece of their business model involves trading financial contracts derived from energy prices. This requires an accurate forecast of the energy price. To improve and automate the process of forecasting—historically done manually—we collaborated with them to develop a model using Amazon SageMaker to predict the upcoming weather trends and therefore the prices of future months’ electricity, enabling unprecedented long-range energy trading. By using a deep learning forecasting model to replace the old manual process, World Kinect Energy Services improves their hedging strategy. With the current results, the team is now adding additional signals focused on trend and volatility and is on its way to realizing an accuracy of greater than 60% over the manual process.
And in manufacturing, we worked with Formosa Plastics, one of Taiwan’s top petrochemical companies and a leading plastics manufacturers, to apply ML to more accurately detect defects and reduce manual labor costs. Formosa Plastics needed to ensure the highest Silicon Wafer quality, but the defect inspection process was time consuming and required time from a highly experienced engineers.
Together with the ML Solutions Lab, Fromosa Plastics created and deployed a model using Amazon SageMaker to automatically detect defects. The model reduced their employee time spent doing manual inspection in half and increased the accuracy of detection.
Energized by the progress our customers have made and listening closely to their needs, we continue to increase our capacity to support even more customers seeking Amazon’s expertise in ML. And we recently introduced a new program, AWS Machine Learning Embark program, which combines workshops, on-site training, an ML Solutions Lab engagement, and an AWS DeepRacer event to help organizations fast-track their adoption of ML.
We started the ML Solutions Lab because we believe machine learning has the ability to transform every industry, process, and business, but the path to machine learning success is not always straightforward. Many organizations need a partner to help them along their journey. Amazon has been investing in machine learning for more than 20 years, innovating in areas such as fulfilment and logistics, personalization and recommendations, forecasting, robotics and automation, fraud prevention, and supply chain optimization. We bring the learnings from this experience to every customer engagement. We’re excited to be a part of our customers’ adoption of this transformational technology, and we look forward to another year of working hand in hand with our customers to find the most impactful ML use cases for their organization. To learn more about the AWS Machine Learning Solutions Lab contact your account manager or visit us at https://aws.amazon.com/ml-solutions-lab/.
About the Author
Michelle K. Lee, Vice President of the Machine Learning Solutions Lab, AWS

A Discriminative Feature Learning Approach for Deep Face Recognition
url: https://kpzhang93.github.io/papers/eccv2016.pdf year: ECCV2016
abstract
对于人脸识别任务来说,网络学习到的特征具有判别性是一件很重要的事情。增加类间距离,减小类内距离在人脸识别任务中很重要。那么,该如何增加类间距离,减小类内距离呢?通常,我们使用 softmax loss 作为分类任务的 loss, 但是,单单依赖使用 softmax 监督学习到的特征只能将不同类别分开,却无法约束不同类别之间的距离以及类内距离。为了达到增加类间距离,减小类内距离的目的,就需要额外的监督信号,center loss 就是其中一种.
center loss 包含两个流程:
- 学习一个类别的深度特征的中心
- 使用该中心约束属于该类别的特征表示
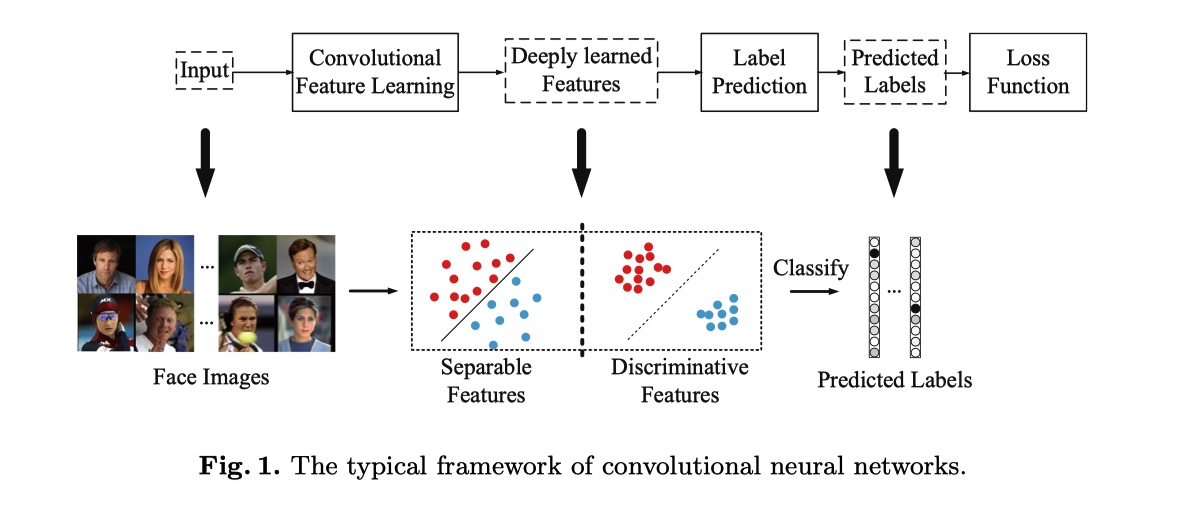 

最常用的 CNN 执行特征学习和标签预测,将输入数据映射到深度特征 (最后隐藏层的输出),然后映射到预测标签,如上图所示。最后一个完全连接层就像一个线性分类器,不同类的深层特征通过决策边界来区分。
center loss design
如何开发一个有效的损失函数来提高深度学习特征的判别力呢? 直观地说,最小化类内方差同时保持不同类的特征可分离是关键。
center loss 形式如下: 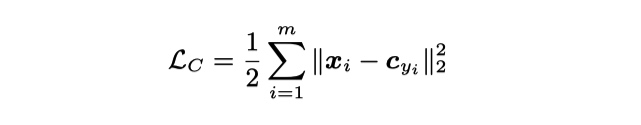 

$c_{y_i} \in R^d$ 为第 $y_i$ 类的特征表示的中心 center 更新策略 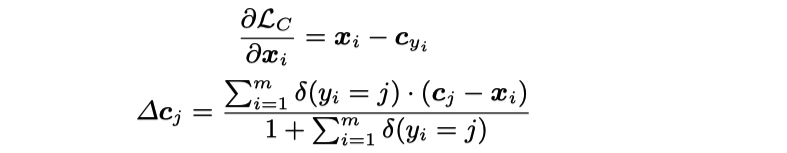 

total loss 函数  

 

toy experiment 可视化
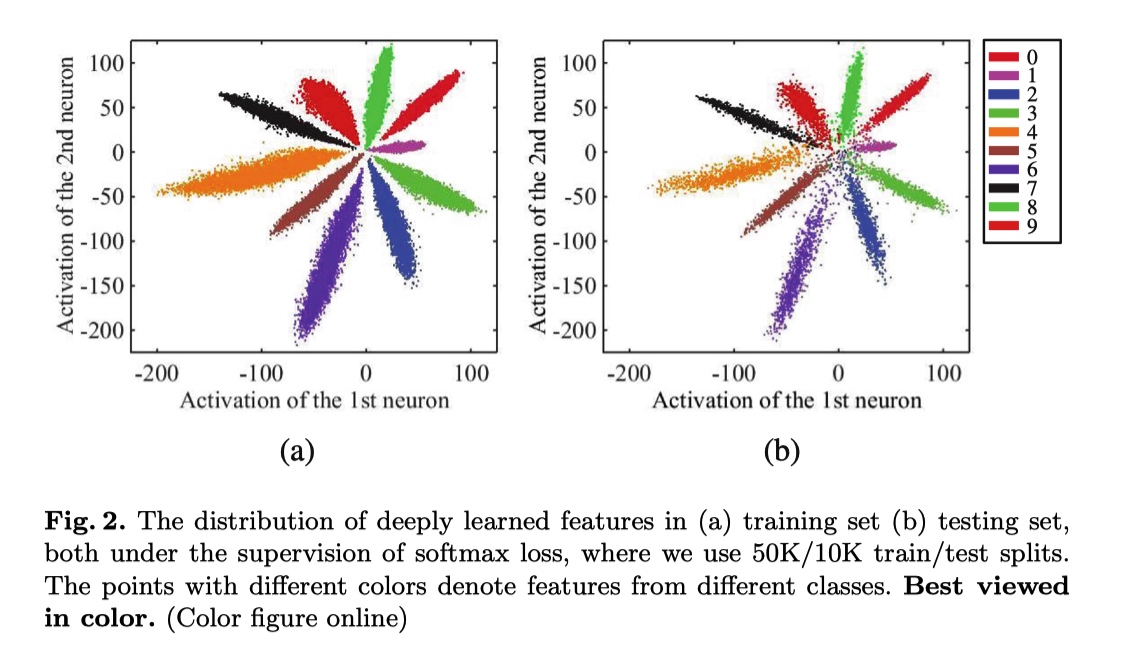 

 

超参设置实验
$\lambda \quad$ softmax 与 center loss 的平衡调节因子 $\alpha \quad$ center 学习率,即 $ center -= \alpha \times diff$ 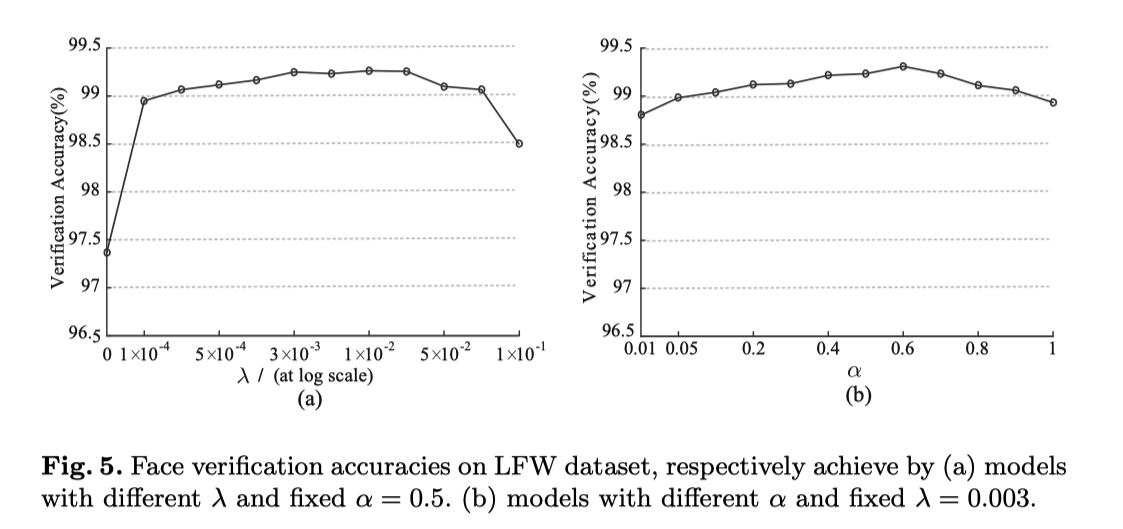 

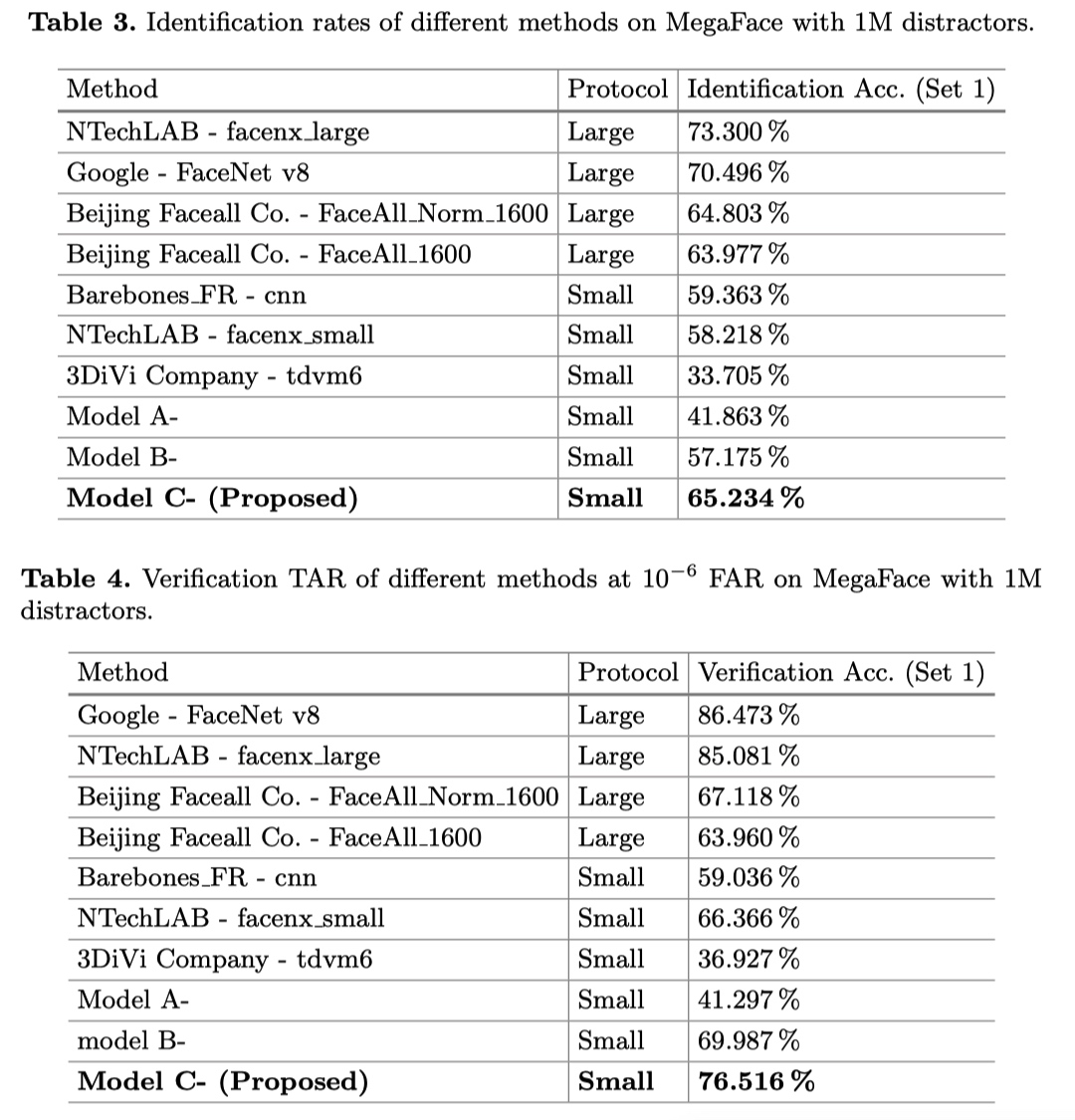
experiment result

thought
就身边的哥们用 center loss 的经验来看,center loss 在用于非人脸识别的任务上,貌似效果一般或者没有效果。可能只有像人脸任务一样,类内深度特征分布聚成一簇的情况下,该 loss 比较有效。如果分类任务中,类内特征差异比较大,可能分为几个小簇 (如年龄预测), 该 loss 可能就没有啥用处了。而且 center loss 没有做特征归一化,不同类的特征表示数量级可能不一样,导致一个数量级比较大特征即使已经很相似了,但是其微小的差距也可能比其他的数量级小的特征的不相似时的的数值大.
而且,学习到的 center 只用于监督训练,在预测过程中不包含任何与 center 的比较过程.
就学习 center 这一思想而言,感觉 cosface 中提到的 large margin cosine loss 中用于学习 feature 与权重之间的 cosine 角度,比较好的实现这种学习一个 center (以 filter 的权重为 center), 然后让 center 尽量与 feature 距离近的思想可能更好一点,即能在训练时规范 feature 与 center 之间的距离,又能在预测时候,通过与 center 比对 cosine 大小来做出预测.

A Diversity-Promoting Objective Function for Neural Conversation Models论文阅读
本文来自李纪为博士的论文 A Diversity-Promoting Objective Function for Neural Conversation Models
1,概述
对于seq2seq模型类的对话系统,无论输入是什么,都倾向于生成安全,通用的回复(例如 i don''t know 这一类的回复),因为这种响应更符合语法规则,在训练集中出现频率也较高,最终生成的概率也最大,而有意义的响应生成概率往往比他们小。如下表所示:

上面的表中是seq2seq对话系统产生的结果,分数最高的回复通常是最常见的句子,当然更有意义的回复也会出现在N-best列表(beam search的结果)中,但一般分数相对更低一点。主要是一般seq2seq模型中的目标函数通常是最大似然函数,最大似然函数更倾向于训练集中频率更高的回复。
本论文提出使用MMI(最大互信息)来替换最大似然函数作为新的目标函数,目的是使用互信息减小“I don’t Know”这类无聊响应的生成概率。
2 MMI 模型
在原始的seq2seq模型中,使用的目标函数是最大似然函数,就是在给定输入S的情况下生成T的概率,其表达式如下:
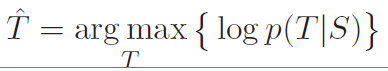
从这个表达式可以看到,实际上就是给定了源句子的情况下,选择概率最大的句子最为目标句子,这种情况下就会倾向于训练集中出现频率大的句子。
因此引入互信息作为新的目标函数,互信息的定义:度量两个时间集合之间的相关性。其表达式如下:
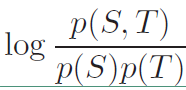
将上面的表达式可以改写成:
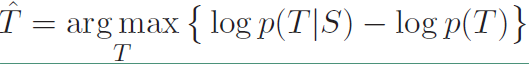
我们在上面的式子的基础上对第二项加上一个$\lambda$参数,表达式改写成:
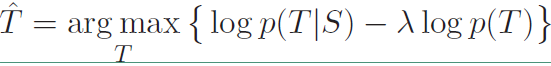
这就是本论文中提出的第一个目标函数MMI-antiLM,在其基础上添加了目标序列本身的概率$logp(T)$,$p(T)$就是一句话存在的概率,也就是一个模型,前面的$\lambda$是惩罚因子,越大说明对语言模型惩罚力度越大。由于这里用的是减号,所以相当于在原本的目标上减去语言模型的概率,也就降低了“I don’t know”这类高频句子的出现概率。
然后还提出了第二个目标函数MMI-bidi,在原始目标函数基础上添加$logp(S|T)$,也就是$T$的基础上产生$S$的概率,其具体表达式如下:
![]()
而且可以通过改变$\lambda$的大小衡量二者的重要性,其表达式变为:

$logp(S|T)$可以表示在响应输入模型时产生输入的概率,自然像“I don’t know”这种答案的概率会比较低,而这里使用的是相加,所以会降低这种相应的概率。
接下来我们来详细的看看这两个目标函数
1)MMI-antiLM
如上所说,MMI-antiLM模型使用第一个目标函数,引入了$logp(T)$,但该方法同时也存在一个问题:模型倾向于生成生成不符合语言模型的相应。按理说$\lambda$取值小于1的时候,不应该出现这样的问题,所以在实际使用过程中需要对其进行修正。由于解码过程中往往第一个单词或者前面几个单词是根据encode向量选择的,后面的单词更倾向于根据前面decode的单词和语言模型选择,而encode的信息影响较小。也就是说我们只需要对前面几个单词进行惩罚,后面的单词直接根据语言模型选择即可,这样就不会使整个句子不符合语言模型了。使用下式中的$U(T)$代替$p(T)$,式中$g(k)$表示要惩罚的句子长度,其中$p(T)$如下
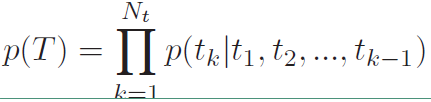
$U(T)$的表达式如下:
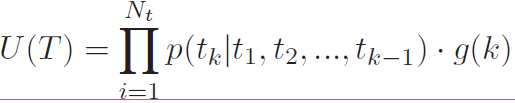
引入一个$\gamma$参数来对序列进行截断,是的$g(k)$的表达式如下:

而最终的目标函数如下:
![]()
此外,此外实际使用中还加入了响应句子的长度这个因素,也作为模型相应的依据,所以将上面的目标函数修正为下式:
![]()
2)MMI-bidi
MMI-bidi模型也面临一个问题就是$(1-{\lambda})logp(T|S) + {\lambda}logp(S|T)$是一个很难求解的问题。要求得$p(S|T)$项,这就需要先计算出完整的$T$序列再将其传入一个提前训练好的反向seq2seq模型中计算该项的值。但是考虑到$S$序列会产生无数个可能的$T$序列,我们不可能将每一个$T$都进行计算,所以这里引入beam-search只计算前200个序列$T$来代替。然后使用式子的第二项对N-best列表重新排序,因为由标准seq2seq模型生成的N-best列表中的候选语句通常是语法正确的,所以从这N个解中最终选择的回复通常也是语法正确的。
然而,重排序有一个明显的缺陷就是,由于优先强调标准seq2seq的目标函数会导致非全局最优回复的产生,而且,很大程度上依赖系统成功生成足够多样的N个最优回复,也就是要求N足够大。然而标准seq2seq模型测试(解码)过程中的beam search存在一个问题导致重排序并不可用:搜索结果中缺乏多样性。因为在搜索结果里的备选回复之间通常只是标点符号或句子形态上较小的改变,大多数词语是重叠的。所以由于N-best列表中缺乏多样性的原因,会使得重排序也没什么效果。所以为了解决这类问题,需要为重排序提供一个更加多样化的N-best列表。
因此作者提出了一种新的beam search的方法,我们通过一张图来看这两种beam search:

具体的做法就如上图所示,在beam search中是不管父节点的,而是将所有的子节点混在一起进行排序选择,而在改版的beam search中,先对同一父节点下的子节点排序,然后对排序后的子节点进行进行不同的惩罚,如图中对排前面的减1,排后面的减2,做完惩罚处理后,再将所有的子节点混合在一起进行排序选择。这样的beam search会增加N-best列表的多样性。
另外在MMI-bidi也做了和MMI-antiLM中同样的处理,增加了回复长度的影响。
阅读笔记")
A Survey on Deep Learning for Named Entity Recognition(2020)阅读笔记
1. Summary
文章主要介绍了NER的资源(NER语料及工具),并从distributed representation for input,context encoder和tag decoder三个维度介绍了目前现有的工作,并调研了目前最具代表性的深度学习方法。最后提出了目前NER系统面临的挑战以及未来的研究方向。
2. Introduction
(1) NEs通常分为两种:generic NEs (e.g., person and location) and domain-specific NEs (e.g., proteins, enzymes, and genes)。
(2) 主流NER方法有以下四种:
- Rule-based approaches: which do not need annotated data as they rely on hand-crafted rules.
- Unsupervised learning approaches: which rely on unsupervised algorithms without hand-labeled training examples.
- Feature-based supervised learning approaches: which rely on supervised learning algorithms with careful feature engineering.
- Deep-learning based approaches: which automatically discover representations needed for the classification and/or detection from raw input in an end-to-end manner.
3. Motivation
近年来深度学习方法在多个领域取得巨大的成功,在NER系统上应用深度学习方法也成功在多个NER任务上达成SOTA。作者期望通过比较不同的深度学习架构,以获知哪些因素影响了NER的性能。
4. Content
本文可视作NER系统的百科全书,非常详尽地介绍了NER的概念,传统方法以及深度学习方法。
- Input Representation通常包括word-level、character-level、hybrid等表征方式,最近较新的有sub-word级别的表征,可视作word和character级别间的折中。
- Context Encoder包括了CNN、RNN、Transformer等网络结构,如今使用预训练embedding的Transformer正成为NER一种新的范式。
- Tag Decoder常用的有MLP+Softmax、CRF、RNN和Pointer network。
- 基于DL的NER性能在很大程度上取决于Input Representation,引入额外知识可以提升模型性能,然而是否应该引入额外知识在学界并没有达成一致。引入额外知识会影响端到端的学习和模型的通用性。此外,基于Transformer的NER系统在不使用预训练embedding和训练数据量较小时表现欠佳。
- 同时,文章还简要介绍了使用多任务学习、迁移学习、主动学习(active learning)、强化学习和对抗学习(adversarial learning)等方法来实现NER系统。
目前在CoNLL03数据集上,Cloze-driven pretraining of self-attention networks达到SOTA(F-score93.5%);在OntoNotes5.0数据上BERT+Dice loss达到SOTA(F-score92.07%)。一些模型在NER数据上的性能表现如下:

5. Challenges and Future Directions
- 挑战主要包括因语言歧义性(language ambiguity)带来标注语料质量与一致性的下降,以及识别非正式文体(如tweeter和微博短评)以及语料中没见过的实体。
- 本文提到可能的未来方向有:细粒度NER和边界检测、NER与实体联合链接、利用附加资源解决非正式文体的实体识别、基于深度学习方法的NER可拓展性(参数量太大)、使用迁移学习的NER、易于使用的NER工具包。
今天关于阅读笔记 Active learning from Crowds with unsure option和阅读笔记摘抄大全的介绍到此结束,谢谢您的阅读,有关175+ Customers Achieve Machine Learning Success with AWS’s Machine Learning Solutions Lab、A Discriminative Feature Learning Approach for Deep Face Recognition、A Diversity-Promoting Objective Function for Neural Conversation Models论文阅读、A Survey on Deep Learning for Named Entity Recognition(2020)阅读笔记等更多相关知识的信息可以在本站进行查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

