在本文中,我们将详细介绍深入理解PHP+Mysql分布式事务与解决方案的各个方面,并为您提供关于phpmysql分布式的相关解答,同时,我们也将为您带来关于MYSQL分布式事务解决方案、MySQL分布
在本文中,我们将详细介绍深入理解PHP+Mysql分布式事务与解决方案的各个方面,并为您提供关于php mysql分布式的相关解答,同时,我们也将为您带来关于MYSQL 分布式事务解决方案、MySQL分布式事务处理与并发控制的项目经验解析、mysql大型分布式集群 mysql分布式部署 Mycat分库分表 mycat读写分离 MySQL集群与优化 高可用数据架构 mysql分布式事务教程、MySql的分布式事务:如何在分布式环境实现MySQL的事务管理的有用知识。
本文目录一览:- 深入理解PHP+Mysql分布式事务与解决方案(php mysql分布式)
- MYSQL 分布式事务解决方案
- MySQL分布式事务处理与并发控制的项目经验解析
- mysql大型分布式集群 mysql分布式部署 Mycat分库分表 mycat读写分离 MySQL集群与优化 高可用数据架构 mysql分布式事务教程
- MySql的分布式事务:如何在分布式环境实现MySQL的事务管理
")
深入理解PHP+Mysql分布式事务与解决方案(php mysql分布式)
事务(Transaction)是访问并可能更新数据库中各种数据项的一个程序执行单元;
事务的ACID特性
事务应该具有4个属性:原子性、一致性、隔离性、持续性
原子性(atomicity)。一个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
一致性(consistency)。事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
隔离性(isolation)。一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
持久性(durability)。持续性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
分布式事务:分布式事务的参与者、资源管理器、事务管理器等位于不用的节点上,这些不同的节点相互协作共同完成一个具有逻辑完整性的事务。
mysql从5.0开始支持XA DataSource。Connector/J 版本要使用5.0版本,5.0以下的不支持。
常见的分布式事务解决方案
基于XA协议的两阶段提交
XA协议由Tuxedo首先提出的,并交给X/Open组织,作为资源管理器(数据库)与事务管理器的接口标准。目前,Oracle、Informix、DB2和Sybase等各大数据库厂家都提供对XA的支持。XA协议采用两阶段提交方式来管理分布式事务。XA接口提供资源管理器与事务管理器之间进行通信的标准接口。XA协议包括两套函数,以xa_开头的及以ax_开头的。
以下的函数使事务管理器可以对资源管理器进行的操作:
1)xa_open,xa_close:建立和关闭与资源管理器的连接。
2)xa_start,xa_end:开始和结束一个本地事务。
3)xa_prepare,xa_commit,xa_rollback:预提交、提交和回滚一个本地事务。
4)xa_recover:回滚一个已进行预提交的事务。
5)ax_开头的函数使资源管理器可以动态地在事务管理器中进行注册,并可以对XID(TRANSACTION IDS)进行操作。
6)ax_reg,ax_unreg;允许一个资源管理器在一个TMS(TRANSACTION MANAGER SERVER)中动态注册或撤消注册。
XA实现分布式事务的原理如下:
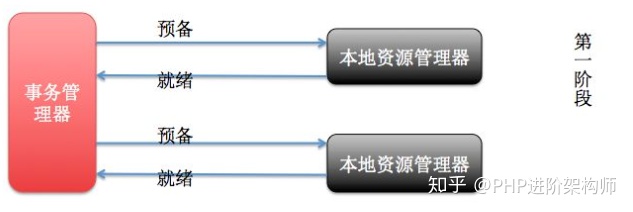
MySQL XA分为两类,内部XA与外部XA;内部XA用于同一实例下跨多个引擎的事务,由大家熟悉的Binlog作为协调者;外部XA用于跨多MySQL实例的分 布式事务,需要应用层介入作为协调者(崩溃时的悬挂事务,全局提交还是回滚,需要由应用层决定,对应用层的实现要求较高);
Binlog作为内部XA的协调者,在binlog中出现的内部xid,在crash recover时,由binlog负责提交。(这是因为,binlog不进行prepare, 只进行commit,因此在binlog中出现的内部xid,一定能够保证其在底层各存储引擎中已经完成prepare)。
MySQL数据库外部XA可以用在分布式数据库代理层,实现对MySQL数据库的分布式事务支持,例如开源的代理工具:网易的DDB,淘宝的TDDL,B2B的Cobar等等。
示例
public function testAction(){
$goods_id=1;
$goods_name = "关注PHP开源社区微信公众号领取PHP大厂面试题";
$num = 1;
$rs_order = $this->test->createorder($goods_id,$goods_name,$num);
$rs_goods = $this->test->deduction($goods_id,$num);
if($rs_order[''status''] =="success" && $rs_goods[''status'']=="success"){
$this->test->commitdb($rs_order[''XA'']);
$this->test->commitdb1($rs_goods[''XA'']);
}else{
$this->test->rollbackdb($rs_order[''XA'']);
$this->test->rollbackdb1($rs_goods[''XA'']);
}
print_r($rs_order);
echo "<br />";
print_r($rs_goods);
die("dddd");
}
public function createorder($goods_id,$goods_name,$num){
$XA = uniqid("");
$this->_db->query("XA START ''$XA''");
$_rs = true;
try {
$data = array();
$data[''order_id''] = "V".date("YmdHis");
$data[''goods_name''] = $goods_name;
$data[''goods_num''] = $num;
$this->_db->insert("temp_orders",$data);
$rs = $this->_db->lastInsertId();
if($rs){
$_rs = true;
}else{
$_rs = false;
}
} catch (Exception $e) {
$_rs = false;
}
$this->_db->query("XA END ''$XA''");
if($_rs){
$this->_db->query("XA PREPARE ''$XA''");
return array("status"=>"success","XA"=>$XA);
}else{
return array("status"=>"nosuccess","XA"=>$XA);
}
}
public function deduction($id){
$XA = uniqid("");
$this->db1->query("XA START ''$XA''");
$last_rs = true;
try {
$sql = "select * from temp_goods where id = ''$id'' and goods_num>0";
$rs = $this->db1->fetchRow($sql);
if(!empty($rs)){
$sql = "update temp_goods set goods_num = goods_num-1 where id = ''$id''";
$rd = $this->db1->query($sql);
if($rd){
$last_rs = true;
}else{
$last_rs = false;
}
}else{
$last_rs = false;;
}
} catch (Exception $e) {
$last_rs = false;;
}
$this->db1->query("XA END ''$XA''");
if($last_rs){
$this->db1->query("XA PREPARE ''$XA''");
return array("status"=>"success","XA"=>$XA);
}else{
return array("status"=>"nosuccess","XA"=>$XA);
}
}
//提交事务!
public function commitdb($xa){
return $this->_db->query("XA COMMIT ''$xa''");
}
//回滚事务
public function rollbackdb($xa){
return $this->_db->query("XA ROLLBACK ''$xa''");
}
//提交事务!
public function commitdb1($xa){
return $this->db1->query("XA COMMIT ''$xa''");
}
//回滚事务
public function rollbackdb1($xa){
return $this->db1->query("XA ROLLBACK ''$xa''");
}
总结
分布式事务,本质上是对多个数据库的事务进行统一控制,按照控制力度可以分为:不控制、部分控制和完全控制。不控制就是不引入分布式事务,部分控制就是各种变种的两阶段提交,包括上面提到的消息事务+最终一致性、TCC模式,而完全控制就是完全实现两阶段提交。部分控制的好处是并发量和性能很好,缺点是数据一致性减弱了,完全控制则是牺牲了性能,保障了一致性,具体用哪种方式,最终还是取决于业务场景。作为技术人员,一定不能忘了技术是为业务服务的,不要为了技术而技术,针对不同业务进行技术选型也是一种很重要的能力
到此这篇关于深入理解PHP+Mysql分布式事务与解决方案的文章就介绍到这了,更多相关PHP Mysql分布式事务内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
- PHP+Mysql分布式事务与解决方案深入理解
- MySQL分布式恢复进阶

MYSQL 分布式事务解决方案
前言
谈起mysql事务的特性,人尽皆知的就是四个特性:ACID,原子性、一致性、隔离性、持久性。其中原子性、隔离性、持久性理解起来相对直观,各个地方对它们的定义也比较统一。相比之下“一致性”则显得不那么直观,你似乎好像明白它的意思,但是真的让你讲你又说不出来。本文会着重讲一下数据库中的"一致性"到底是什么意思。
一、为什么会有事务?
很多人以为’‘事务’''的概念是天然存在的,就像空气一样理所当然的存在。
实际上并非如此,之所以出现事务是因为:当应用程序访问数据库时,事务能够简化编程的步骤,不必考虑各种潜在的错误和并发问题。
我们使用事务时,要么回滚,要么提交。只用处理业务问题,而不必关注网络抖动或者物理机器问题。不用没完没了的try…catch和异常判断。事务是为了服务应用层诞生的,并非伴随着数据库系统出现。
如果没有事务,那就必须用代码去保证数据的完整性和准确性。这绝对会是程序员的灾难。
1. 事务的四种特性
1.1. 事务的四种特性的定义
原子性(Atomicity):一个事务必须被视为一个不可分割的最小工作单元,事务中的操作要么全部成功,要么全部失败。原子性其实并不能保证一致性
一致性(Consistency): 指事务必须使数据库从一个一致性状态变换到另一个一致性状态,这种状态是语义上的不是语法上的。例如: 从账户A转一笔钱到账户B上,账户A上的钱少了100,账户B上的钱多了100,这就是一致性的问题。如果只是一方多了10块或者一方少了10块,就说明没有达到一致性的问题,但是事务中的操作全部是成功了的,它保证了原子性,但没有保证一致性
其他:几个并行执行的事务,其执行结果必须与按某一顺序 串行执行的结果相一致。
隔离性(Isolation): 通常来说,一个事务所做的修改在最终提交以前,对其他事务是不可见的。
其他解释:事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须是透明的。
持久性(Durability):一旦事务提交,则其所做的修改就会永久保存到数据库中。
2. 四种隔离级别
2.1. 四种隔离级别的定义
读未提交 ( READ UNCOMMITTED )
事务中的修改,即使没有提交,其他的事务也都是可见的。事务可以读取到未提交的数据,这被成为脏读
读提交 (READ COMMITTED)
大多数数据库系统的默认隔离级别,一个事务从开始直到提交之前,所做的任何修改对其他事务都是不可见的,这个级别也叫不可重复读
可重复读 (REPEATABLE READ) MySQL默认的隔离级别
可重复读解决了脏读的问题,该级别保证了再同一个事务中多次读取同样的结果是一致的,但理论上该隔离级别无法解决幻读的问题。幻读就是指当某个事务在读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围内的记录时就会出现幻行。通过MVCC多版本并发控制解决幻读的问题
可串行化 (SERIALIZABLE)
最高的隔离级别。SERIALIZABLE是最高的隔离级别。它通过强制事务串行执行,避免了前面说的问题。简单来说,SERIALIZABLE 会在读取的每一行数据上都加锁,所以可能导致大量的超时和锁争用问题

二、为什么"一致性"很难理解?
我觉得一致性难理解有两个方面的原因。
“一致性”的意义被泛化
各种系统、各种设计中都在使用“一致性”的概念。目前起码有四种一致性的概念。
ACID中的一致性
一致性哈希
CAP定理的一致性
分布式多副本一致性
其中CAP的一致性是指线性一致性,主要描述了在故障和延时下的副本之前的协同问题。一致性哈希是为了解决分布式缓存问题。分布式多副本一致性则是保持分布式系统中各个节点之间的数据一致。
上边这些都不是ACID中的一致性的含义,但是你也不能完全说一点关系也没有。很多人把数据库的一致性和其他一致性概念混淆,所以经常迷迷糊糊的,说也说不清。
数据库一致性有两层含义
数据库的一致性其实包含两个层面。从数据库层面理解,“一致性”实际上是一组约束、规则。从业务层面讲,“一致性”实际上是指事务把数据库从一个有效的状态转移成另一个有效状态。
一致性一种约束
从数据库的角度来看,它只关心transcation是否符合定义好的规则,如果符合规则,那么就是符合一致性的。
那么这些规则是什么?它可以是约束,可以是CASCADE(在父表上update/delete记录时,同步update/delete掉子表的匹配记录),也可以是trigger。亦或者是它们的组合。
用商品库存的例子来说。当库存>=1时表示有商品,此时可以售卖。库存=0表示没有商品不能售卖。根据我们朴素的生活经验,库存不能小于0。
因此,我们的数据库对商品数量进行约束,使其数量大于等于0。当库存=0时,倘若还执行update good_table set good_number=good_number-1语句,数据库会拒绝执行,因为这破坏了“一致性”。
从数据库的角度来说,它认为的一致性就是如此。但是,对于业务上的逻辑,数据库并不知晓,它也不会关注。比如,两个用户同时在某一时刻对库存减一,导致某个用户的减库存操作被另一个用户覆盖(经常发生的超卖问题就是如此,比如前两天各个技术公众号转发的名为“秒杀飞天茅台超卖”的文章)。数据库并不能抵御这种错误的发生。
这就是我马上要讲的,一致性是一种目的。
一致性是一种目的
从更高层面来讲,“一致性”是编程过程中,想要达成的一种目的。保证事务只能从一个正确的状态转移到另一个正确的状态。
什么是正确的状态?
数据库用一定的模式存储数据,本质上是对真实世界的建模,是物理世界的映射。当数据库中的状态与现实世界的数据状态保持一致时,数据库就是正确的状态。
上边的话可能有点抽象,没关系,我举个例子。我们还转账的例子来说,假设A的银行账户有500元,B的账户为0元。A通过网络给B转账100元。转账的过程一定分为两个阶段,第一从A的账户里扣100元,第二给B的账户加100元。如果过程顺利,A的账户变400元,B的账户为100元。
然而如果出现“一致性”问题,则有可能出现A的账户变400元,但是B的账户还是0元。这种情况在现实世界绝对不会发生,100元的钞票要么已经递到了B手上,要么还是在A手上,无论如果都不会有A的100元莫名其妙不见了,而B手上也没有100元的情况。除非是见了鬼…(ps:这种情况下还是别讨论啥一致性问题了,赶紧去配个眼镜,这样能控制近视的度数)。
和真实世界保持一致,就是正确的状态。
此时的“一致性”是一种目的,单靠数据库是完不成的,但偏偏数据库又是“一致性”的表现载体。那么,如何达到这种一致性呢?
锁!!此时,要靠各种锁达成一致性,悲观锁(select xxx from xxx for update)、乐观锁(mvcc,select xxx from xxx lock in share mode)等等,这个就说来话长了,改日另起一篇吧。
“一致性”概念泛滥,要清楚地将数据库的“一致性”与其他“一致性”区分。数据库的”一致性“从底层来说,是一组约束。这组约束可以是约束条件、可以是触发器等,也可以是它们的组合。从更高的层面来说,“一致性”是一种目的,即保持数据库与真实世界之间的正确映射。此时,需要靠各种锁来达成“一致性”。
2PC、3PC、TCC、本地消息表、消息事务、最大努力通知
外加
阿里的sagas 目前在梳理阶段,梳理好后会分享出来
https://blog.csdn.net/qq_44969643/article/details/125631600?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-125631600-blog-112400384.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-125631600-blog-112400384.pc_relevant_default&utm_relevant_index=1
参考:
https://zhuanlan.zhihu.com/p/183753774
https://blog.csdn.net/y1391625461/article/details/125171996
https://blog.csdn.net/flynetcn/article/details/124592621

MySQL分布式事务处理与并发控制的项目经验解析

MySQL分布式事务处理与并发控制的项目经验解析
近年来,随着互联网的迅猛发展和用户数量的不断增加,对于数据库的要求也日益提高。在大型分布式系统中,MySQL作为最常用的关系型数据库管理系统之一,一直扮演着重要的角色。但是,随着数据规模的增大和并发访问的增加,MySQL的性能和扩展性面临了严峻的挑战。特别是在分布式环境下,如何处理事务和控制并发成为了一个亟待解决的问题。
本文将通过对一个实际项目的经验解析,探讨MySQL在分布式环境下的事务处理和并发控制的最佳实践。
在我们的项目中,需要处理海量的数据,并且要求数据的一致性和可靠性。为了满足这些要求,我们采用了基于两阶段提交(2PC)协议的分布式事务处理机制。
首先,为了实现分布式事务,我们将数据库拆分为多个独立的片段,每个片段都部署在不同的节点上。这样,每个节点只需要负责管理和处理自己的数据,大大降低了数据库的负载和延迟。
其次,为了保证事务的一致性,我们引入了协调者和参与者的概念。协调者是一个特殊的节点,负责协调分布式事务的执行流程。参与者是负责执行实际操作的节点,当参与者执行完操作后,将结果返回给协调者。
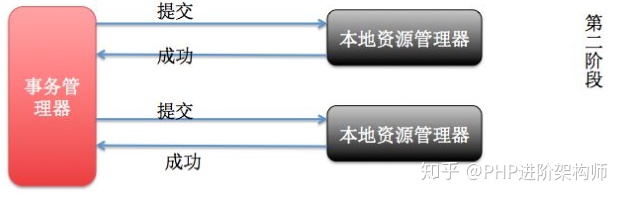
在事务的执行中,我们采用了两阶段提交(2PC)协议。第一阶段是准备阶段,在这个阶段,协调者向所有参与者发送准备请求,参与者执行相关操作并且记录redo日志。如果所有参与者都成功执行并返回准备完成的消息,协调者再发送提交请求;否则,协调者发送中止请求。第二阶段是提交阶段,参与者收到提交请求后,执行事务提交的操作。
除了分布式事务处理,我们还需要解决并发控制的问题。在分布式环境下,由于多个节点同时访问同一份数据,数据库的一致性和并发性容易受到影响。为了解决这个问题,我们采用了乐观并发控制策略。
乐观并发控制是一种基于版本的并发控制策略,它通过在数据库中为每个数据项添加版本号,来判断读写操作之间的冲突。当一个事务读取一个数据项时,会记录当前的版本号;当该事务提交时,会检查当前版本号是否与之前读取的版本号一致。如果一致,说明事务期间没有其他事务对该数据项进行修改,可以提交;如果不一致,则需要重新执行事务。
同时,为了提高并发性,我们还采用了分布式锁的方式,通过锁机制来控制对共享资源的访问。对于读操作,我们使用共享锁;对于写操作,我们使用排他锁。
我们的项目经验表明,通过采用基于两阶段提交协议的分布式事务处理机制和乐观并发控制策略,可以有效地解决MySQL在分布式环境下的事务处理和并发控制的问题。同时,通过合理的数据拆分和分布式锁的使用,可以提高系统的性能和扩展性。
总之,MySQL分布式事务处理与并发控制是一个复杂而关键的问题,在实际项目中需要综合考虑系统的数据规模、访问模式和性能要求等因素。通过不断的实践和总结,我们相信能够找到适合自己系统的最佳实践,提高系统的可靠性和性能。
以上就是MySQL分布式事务处理与并发控制的项目经验解析的详细内容,更多请关注php中文网其它相关文章!

mysql大型分布式集群 mysql分布式部署 Mycat分库分表 mycat读写分离 MySQL集群与优化 高可用数据架构 mysql分布式事务教程
MysqL分布式集群部署mycat分库分表系列(共三套)
系列一:《分布式集群+分库分表实战教程》
本套课程将通过分布式集群和分库分表两部分内容进行讲解
1、主要解决针对大型网站架构中持久化部分中,大量数据存储以及高并发访问所带来是数据读写问题。分布式是将一个业务拆分为多个子业务,部署在不同的服务器上。集群是同一个业务,部署在多个服务器上。
2、着重对数据切分做了细致丰富的讲解,从数据切分的原理出发,一步一步深入理解数据的切分,通过深入理解各种切分策略来设计和优化我们的系统。这部分中我们还用到了数据库中间件和客户端组件来进行数据的切分,让广大网友能够对数据的切分从理论到实战都会有一个质的飞跃。
学完本套课程以后能够达到的效果:
期望通过本课程能帮助大家学习到如何通过分布式+集群的方式来提高io的吞吐量,以及数据库的主从复制,主主复制,负载均衡,高可用,分库分表以及数据库中间件的使用。希望能够帮助大家更加清楚了解架构的工作模式,从而写出更高质量的代码。对于企业的架构人员可以优化企业架构。对于兴趣爱好者,可以作为一个很好的入门。
课程讲解过程中尽可能用简单的语言描述其中的原理,通过实例来帮助初学者快速上手。案例中代码全部手写,实例全部现场真实环境演示。
教程样例项目中用到的技术及相应的环境:
MysqL5.7 CentOS6.9 Vmware Spring3.x以上 JDK8 Maven XShell Xftp
教程中所有的与编程相关均使用Java来进行演示,但与编程语言无关,可使用任何编程语言进行测试。
课程大纲
第1节课程概述 [免费观看] 00:12:22分钟 |
第2节课程背景 [免费观看] 00:09:12分钟 |
第3节纵观大型网站架构发展,总结持久化部分需要应对的问题 [免费观看] 00:27:12分钟 |
第4节操作系统安装以及配置00:31:22分钟 |
第5节在CentOS上通过yum安装MysqL5.700:15:32分钟 |
第6节MysqL初次见面-MysqL5.7的用户以及安全策略00:05:34分钟 |
第7节MysqL初次见面续-MysqL基本操作00:37:36分钟 |
第8节认识主从复制00:15:01分钟 |
第9节主从复制的准备工作01-MysqL用户以及权限00:12:11分钟 |
第10节主从复制的准备工作02-binlog日志详解00:33:23分钟 |
第11节主从实战01-准备环境00:26:06分钟 |
第12节主从实战02-主节点配置00:06:19分钟 |
第13节主从实战03-从节点配置00:10:45分钟 |
第14节java操作主从0100:24:26分钟 |
第15节java操作主从0200:13:48分钟 |
第16节主主复制00:32:23分钟 |
第17节负载均衡概述以及环境准备00:20:42分钟 |
第18节搭建负载均衡-0100:22:54分钟 |
第19节搭建负载均衡-0200:06:06分钟 |
第20节启动haproxy的监控功能00:14:52分钟 |
第21节高可用以及环境准备00:40:14分钟 |
第22节搭建keepalived00:19:42分钟 |
第23节Keepalived配置简介00:11:01分钟 |
第24节Keepalived配置邮件00:42:27分钟 |
第25节Keepalived其他配置00:12:13分钟 |
第26节分库分表概述00:12:18分钟 |
第27节逻辑分表01-水平分表00:32:43分钟 |
第28节逻辑分表02-水平分表续及垂直分表00:13:36分钟 |
第29节表分区00:42:19分钟 |
第30节数据库中间件01-认识mycat00:22:32分钟 |
第31节数据库中间件02-mycat安装00:18:18分钟 |
第32节数据库中间件03-mycat的helloworld00:31:11分钟 |
第33节数据库中间件04-mycat的初识00:13:57分钟 |
第34节数据库中间件05-mycat的数据切分00:13:50分钟 |
第35节数据库中间件06-mycat的读写分离-0100:11:16分钟 |
第36节数据库中间件06-mycat的读写分离-0200:24:06分钟 |
第37节数据库中间件06-mycat的读写分离03-读写分离补充00:03:37分钟 |
第38节数据库中间件07-mycat的高可用-0100:10:01分钟 |
第39节数据库中间件08-mycat的高可用-0200:06:13分钟 |
第40节数据库中间件09-mycat集群00:08:08分钟 |
第41节mySQL查询缓存00:08:17分钟 |
第42节数据库切分概述00:37:09分钟 |
第43节java环境配置00:13:42分钟 |
第44节水平切分原理及单表切分后的操作00:47:46分钟 |
第45节水平切分原理及单表切分后的操作-200:19:32分钟 |
第46节水平切分多表关联操作00:38:14分钟 |
第47节垂直切分原理及操作00:17:23分钟 |
第48节全局序列号00:21:35分钟 |
第49节数据库切分策略-分片枚举00:35:49分钟 |
第50节数据库切分策略-hash00:41:16分钟 |
第51节数据库切分策略-范围约定00:17:20分钟 |
第52节数据库切分策略-取模00:13:54分钟 |
第53节数据库切分策略-按日期分片00:17:43分钟 |
第54节全局表00:04:27分钟 |
第55节认识MyCat00:13:55分钟 |
第56节部署MyCat00:20:20分钟 |
第57节使用MyCat完成简单的数据库分片00:28:58分钟 |
第58节MyCat分片策略00:13:08分钟 |
第59节MyCat全局表配置00:05:18分钟 |
第60节MyCatER表配置00:20:27分钟 |
第61节另外一种切分方式-使用客户端组件的方式实现数据库分00:06:20分钟 |
第62节课程总结00:01:56分钟 |
系列二:《MysqL分布式部署 Mycat分库分表 mycat读写分离》教程
第1章 课程介绍
课程介绍
1-1 MyCAT导学
1-2 课程介绍
第2章 MyCAT入门
这一章中,我们将回顾了垂直切分,水平切分,分库分表等基础概念,然后快速回如何安装和启动MyCAT的,介绍如何以打包好的可执行程序的方式来启动MyCAT。以及如何对其相关的启动配置文件进行配置。
2-1 章节综述
2-2 什么是MyCAT
2-3 什么是数据库中间层
2-4 MyCAT的主要作用
2-5 MyCAT基本元素
2-6 MyCAT安装
第3章 MYCAT核心配置详解
本章将对MyCAT的常用核心配置文件server.xml、rule.xml以及schema.xml详细讲解,也会对常用的分片算法进行逐一讲解
3-1 章节综述
3-2 常用配置文件间的关系
3-3 server.xml配置详解
3-4 log4j2.xml配置文件
3-5 rule.xml文件详解
3-6 常用分片算法(上)
3-7 常用分片算法(下)
3-8 schema.xml文件用途
3-9 schema定义逻辑库
3-10 table标签
3-11 datanode标签
3-12 dataHost标签
3-13 dataHost标签属性
3-14 heartbeat标签
3-15 writehost标签
3-16 schema总结
第4章 MYCAT进阶实战之垂直分库
本章将使用配置文件的标签和属性的理论结合实践来让大家明白在一个具体的项目中如何对数据库进行分库分表操作。本章聚焦垂直分库。
4-1 为什么要进行垂直分库和相关步骤
4-2 收集分析业务模块
4-3 MysqL复制的步骤
4-4 MysqL复制环境说明
4-5 MysqL复制实战
4-6 MysqL复制总结
4-7 垂直切分
4-8 垂直切分相关配置
4-9 垂直切分schema文件配置
4-10 垂直切分server文件配置
4-11 后续工作
4-12 MyCAT启动调试
4-13 MyCAT验证配置
4-14 清理多余数据
4-15 跨分片查询
4-16 配置和验证全局表
4-17 垂直切分的优缺点
第5章 MYCAT进阶实战之水平分库
本章将使用配置文件的标签和属性的理论结合实践来让大家明白在一个具体的项目中如何对数据库进行分库分表操作。本章聚焦水平分库。
5-1 水平分库和分片原则
5-2 分片后如何处理查询
5-3 水平分片步骤
5-4 如何选择分片键
5-5 分析业务模型
5-6 部署分片集群
5-7 演示环境说明
5-8 水平切分演示
5-9 全局自增ID
5-10 ER分片
5-11 sql拦截
5-12 sql防火墙
第6章 MyCAT高可用集群
成熟稳定的生产系统来说,服务的高可用是最基本的要求,因此本章主要介绍如何使用MyCAT构键一个高可用的系统。
6-1 高可用的基本要求
6-2 当前架构离高可用还有多远
6-3 使用ZK记录MyCAT配置
6-4 部署ZK集群
6-5 初始化ZK并配置MyCAT支持ZK
6-6 Haproxy部署详解
6-7 keepalived安装、配置、验证
6-8 MyCAT读写分离
6-9 MysqL主从配置
6-10 schema.xml配置
6-11 MyCAT读写分离配置
6-12 高可用总结
第7章 MyCAT管理及监控
本章将介绍如何对MYCAT进行管理和监控。主要会涉及到MyCAT的两种主要管理方式。 一种是通过MyCAT管理端口来管理的监控MYCAT。另一种呢则是通过MyCAT-WEB。
7-1 MyCAT管理概述
7-2 MyCAT命令行
7-3 MyCATWeb
第8章 MyCAT集群优化
本章主要学习如何对MyCAT集群进行优化,使其发挥出更好的性能。
8-1 MyCAT集群优化概述
8-2 Linux优化配置
8-3 MyCAT优化配置
8-4 MysqL优化配置
第9章 MyCAT的限制
本章主要介绍MyCAT不适合处理什么样的问题。
9-1 MyCAT限制
第10章 课程总结
课程总结
10-1 –课程总结
系列三:2018最新MysqL数据库优化面试 MysqL索引面试 MysqL搜索引擎面试 MysqL面试基础知识
第1章 课程介绍
课程内容的整体介绍以及学习建议。
1-1 MysqL面试指南导学
第2章 MysqL版本类问题
在这类问题中主要涉及到了不同MysqL发行版的差别以及如何为业务场景选择不同的发行版本以及如何对现有MysqL版本进行升级这些知识点。对于不同MysqL发行版本之间的差异不仅是运维,架构师和DBA所要关心的,其实由于不同版本所支持的sql语言的功能也会有所不同,所以也是高级开发人员所要关心的 …
2-1 版本类常见问题
2-2 为什么选择某一MysqL版本
2-3 各个发行版本之间的区别和优缺点
2-4 如何对MysqL进行升级
2-5 最新的MysqL版本特性(上)
2-6 最新的MysqL版本特性(下)
第3章 用户管理类问题
在这类问题中我们所涉及到的知识点主要是如何定义和管理MysqL账号,如何管理MysqL权限密码以及如何对用户权限进行备份,等等用户相关的问题所涉及到的知识点。虽然这看似大部分是DBA的工作,但是开发人员也需要关心MysqL都支持什么样的权限,以及我们平常进行开发时需要什么样的数据库权限才能完成相应的需求。
3-1 -用户管理常见问题
3-2 -给定场景下对用户授权
3-3 -保证数据库账号安全
3-4 迁移数据库账号
第4章 服务器配置类问题
本章我们所要学习的知识点就集中在服务器配置方面,主要是MysqL的一些重要配置参数和方法的讲解。比如sqlMODE的使用以及如何在线修改服务器配置以及如何管理服务器配置等等。sqlMODE的值不仅会影响MysqL所支持的sql语法还会影响MysqL对数据合规性的检验标准,所以对于中高级开发人员来说,必需要了解这一点,才能解决在向数…
4-1 -服务器配置类问题
4-2 -sqlMode(上)
4-3 -sqlMode(中)
4-4 -sqlMode(下)
4-5 -对比运行时配制
4-6 -MysqL关键参数
第5章 在日志类问题
在本章我们所涉及到的知识点包括了MysqL常用的日志类型以及如何配置和使用这些日志的方法。DBA和运维人员可以利用错误日志来解决数据库的异常问题,开发人员则需要和DBA配合使用慢查日志来对查询进行优化。而其它的日志也各有用途,这些内容我们在下面再详细的梳理 …
5-1 -日志类问题
5-2 -错误日志(上)
5-3 -错误日志(下)
5-4 -常规日志
5-5 -慢查询日志
5-6 -二进制日志(上)
5-7 二进制日志(下)
5-8 -中继日志
5-9 -总结
第6章 存储引擎类问题
存储引擎类问题主要是涉及到了MysqL常用的存储引擎的选择以及各种存储引擎所适用的场景。当然在这一类问题中我们的重点是INNODB,做为MysqL最常用的支持事务的存储引擎无论是在开发面试还是在DBA面试中都是被关注的重点
6-1 -存储引擎类问题
6-2 MYISAM
6-3 CSV
6-4 Archive
6-5 Memory
6-6 Innodb
6-7 NDB
6-8 无法在线DDL
6-9 Innodb如何实现事务
6-10 MVCC
6-11 总结
第7章 MysqL架构类问题
本章中所涉及到的知识点比较多主要包括主从复制,高可用架构以及分库分表,数据库中间层等等,是我们课程的重中之重,也是在架构师和DBA面试中的重点内容。
7-1 -高可用架构类问题
7-2 MysqL主从复制
7-3 异步复制
7-4 半同步复制
7-5 比较GTID和日志点复制
7-6 比较MMM和MHA
7-7 MMM架构、故障转移、资源和配置
7-8 MMM优缺点和适用场景
7-9 MHA架构、资源、配置步骤
7-10 MHA部署
7-11 MHA优缺点
7-12 MHA使用场景
7-13 减少主从复制延迟
7-14 MGR复制介绍
7-15 MGR实战
7-16 说说你对MGR复制的理解
7-17 -读写负载问题
第8章 备份恢复类问题
本章内容也是在面试中也是必不可少的。在这门课程中备份恢复类问题所涉及到的知识点主要有MysqL常用的备份工具及备份类型以及如何对MysqL进行增量和指定时间点的备份恢复,如何对binlog进行备份等等,相信通过本章的学习,足以满足你在面试中和工作中所遇到的所有备份问题。 …
8-1 如何对数据库进行备分
8-2 MysqLdump实践
8-3 MysqLpump优缺点
8-4 MysqLpump实践
8-5 物理备份:xtrabackup优缺点
8-6 xtrabackup实践
8-7 如何对MysqL进行增量备份和恢复(上)
8-8 如何对MysqL进行增量备份和恢复(下)
第9章 管理及监控类问题
在这一章中,我们所涉及到的知识点主要有如何对MysqL进行监控以及需要监控那些重要指标,在这里我不会介绍某一款具体的监控工具,因为不同的企业中可能使用的监控工具并不相同,但是对于数据库的监控指标,却是基本相同的。所以我们在这里主要是要学习对关键指标进行监控的方法,知道了这些监控的方法后,放在任何工具中都…
9-1 MysqL常见监控指标
9-2 如何监控QPS
9-3 如何监控TPS和并发数
9-4 如何监控连接数和Innodb缓存命中率
9-5 如何监控数据库可用性
9-6 如何监控阻塞
9-7 如何监控慢查询
9-8 如何监控主从延迟
9-9 如何监控主从状态
9-10 如何监控死锁
第10章 异常处理类问题
这一章中内容在面试中则是来考察大家实际的问题处理能力的问题,在本课程中我会就MysqL常到的主从复制问题,性能问题等来和大家分享一下处理问题的思路和方法。
10-1 MysqL优化及异常处理
10-2 IO负载过大问题
10-3 主从数据不一致
10-4 从无法访问主
10-5 主键冲突
10-6 -RelayLog故障
10-7 -数据库优化概论
第11章 课程总结
对课程进行总结
11-1 课程总结
获取资料Q 2844366079

MySql的分布式事务:如何在分布式环境实现MySQL的事务管理
分布式系统概述
在分布式系统中,不同的计算机节点交互,共同完成一项任务。分布式系统通常比单一系统具有更高的可用性和容错性,并且可以更好地满足大规模数据处理的需求。然而,分布式系统也会带来一些挑战,例如数据一致性和事务管理的问题。
MySql事务管理
事务是指一系列的操作,这些操作要么全部执行成功,要么全部不执行。如果事务集中出现错,所有操作都需要回滚到事务开始之前的状态,以保证数据的一致性。MySQL数据库管理系统通过使用ACID事务处理模型来确保数据一致性。ACID事务处理模型包括四个关键的属性:
- 原子性(Atomicity):一次事务要么全部提交成功,要么全部回滚;
- 一致性(Consistency):事务结束后,数据库中的数据应该满足所有的约束和规则;
- 隔离性(Isolation):如果多个事务同时操作同一行数据,一定要保证数据的正确性;
- 持久性(Durability):一旦一个事务被提交,它对数据库中的数据就永久有效。
如何在分布式环境下实现MySQL的事务管理
在分布式系统中,MySQL事务管理面临着许多挑战,例如节点故障、网络分区和数据复制等。以下是在分布式环境下实现MySQL的事务管理的几个关键步骤:
- 设计数据库架构
在分布式架构中,需要分布式部署数据库服务,并使用复制和分片技术来优化性能并提高可用性。在设计数据库架构时,需要考虑以下因素:
- 数据库复制:复制数据以在多个节点上保持一致性;
- 数据库分片:将数据划分为多个分片并在多个节点上存储数据;
- 选取适当的数据库管理系统:例如MySQL Cluster或Galera Cluster;
- 合理的负载均衡,以确保各节点的性能保持在一个相对平衡的状态。
- 使用分布式锁
在分布式环境下,多个事务可能同时访问同一行数据。为了防止这种冲突,使用分布式锁可以确保在同一时间只有一个事务可以访问数据。常用的分布式锁有Zookeeper、Redis和etcd等。当多个事务同时请求一个锁时,只有一个事务能够获取锁并执行修改操作,其他事务将等待锁被释放并重新尝试。
- 选择适当的事务协议
在分布式环境下,需要选择一种适当的事务协议来实现数据一致性。根据CAP定理,一个系统不可能同时满足一致性、可用性和分区容错性,因此需要权衡这些因素。常见的分布式事务管理协议包括2PC、3PC和Paxos等。
- 处理失败的事务
在分布式环境下,可能会发生节点故障或网络分区等情况,导致事务无法正常完成。为了处理这种情况,需要使用回滚日志和重做日志等技术来实现数据恢复。
- 测试
在系统上线之前,需要对系统进行充分测试,以确保在分布式环境下MySQL的事务管理可以正常工作。测试应该包含不同负载条件的场景,并考虑系统的容错性和可用性。
结论
在分布式环境下,MySQL事务管理是一个复杂的问题,需要考虑许多因素,例如数据库架构、锁、事务协议和故障恢复等。通过设计适当的数据库架构,使用适当的分布式锁和事务协议,以及进行充分的测试,可以实现MySQL的事务管理并确保数据的一致性。
以上就是MySql的分布式事务:如何在分布式环境实现MySQL的事务管理的详细内容,更多请关注php中文网其它相关文章!
关于深入理解PHP+Mysql分布式事务与解决方案和php mysql分布式的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于MYSQL 分布式事务解决方案、MySQL分布式事务处理与并发控制的项目经验解析、mysql大型分布式集群 mysql分布式部署 Mycat分库分表 mycat读写分离 MySQL集群与优化 高可用数据架构 mysql分布式事务教程、MySql的分布式事务:如何在分布式环境实现MySQL的事务管理的相关信息,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

