针对php–处理长时间运行的重复HTTP请求和php长时间执行这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展asp.net–长时间运行HttpWebRequests、c#–中断长时间运行的
针对php – 处理长时间运行的重复HTTP请求和php长时间执行这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展asp.net – 长时间运行HttpWebRequests、c# – 中断长时间运行的方法模式、HTTP/1.0和HTTP/1.1 http2.0的区别,HTTP怎么处理长连接(阿里)、HTTP深入浅出http请求(转)-----http请求的过程和实现机制等相关知识,希望可以帮助到你。
本文目录一览:")
php – 处理长时间运行的重复HTTP请求(php长时间执行)
处理在服务器上接收重复HTTP请求的好方法是什么?
我有一个LAMP Web应用程序的报告,需要大约30秒才能在服务器上构建并返回到客户端.客户端不耐烦并在第一次完成之前再次运行报告.这让服务器陷入困境.有没有办法处理/阻止这个服务器端?
解决方法:
存储作业已在某处运行的事实.
在生成报告的代码中,检查是否已在运行报告.如果是这样,请不要再运行另一个.
当报告完成生成或某些超时到期以处理异常情况时,请取消存储该事实.
您可以使用数据库,memcached服务器,redis,文本文件,写入共享内存……

asp.net – 长时间运行HttpWebRequests
我有一个在IIS6服务器上运行的ASP.NET Web应用程序.该应用程序正在对远程计算机上的xml服务进行长时间运行的调用.远程计算机上的某些服务调用需要很长时间才能执行(有时长达4分钟).长期解决方案是使调用异步,但作为短期解决方案,我们希望增加调用的超时和整个httpRequest超时.
我担心的是,长时间运行的呼叫将填满请求队列并阻止“正常”页面请求完成.如何调整服务器,IIS和应用程序设置以临时解决问题?
目前,每分钟大约有200个页面请求,这导致270个服务请求/分钟.
>当前executionTimeout是360(6分钟)
>当前的服务呼叫超时是2分钟
解决方法
这篇关于微软知识库的文章包含了你可能需要的几乎所有信息:
* Contention,poor performance,and deadlocks when you make Web service requests from ASP.NET applications
我将就上面文章中处理的一些具体项目进行一些研究.以下信息适用于IIS6,适用于IIS7的注释.
将Processor Worker线程池从25增加到至少100
Threadpool大小的默认值为100,因为autoConfig的默认值为true.
autoConfig涵盖的值是
> maxWorkerThreads
> maxIoThreads
> maxConnection
还有一个必须更改的值是 – ASPProcessorThreadMax,这只能在IIS6中的IIS配置数据库(通过adsutil工具)中设置. [IIS7相当于processorThreadMax值]
所以我选择不更改machine.config设置,因为它们没问题,还有其他参数会受到关闭autoconfig的影响,而是通过IIS配置数据库将ASPProcessorThreadMax从25更改为100(唯一的方法是更改此设置)值).
例如
cscript %sYstemDRIVE%\Inetpub\AdminScripts\<Nowiki>adsutil.vb</Nowiki>s SET W3SVC/AspRequestQueueMax 100
每台服务器最多连接数
maxconnection
autoconfig将此值设置为12 * cpu的数量,即一次连接到的每个地址可以建立多少个连接.
调试
您可以执行以下操作:
监视请求是否在队列中等待
监控以下计数器:
>运行perfmon
>添加计数器:应用程序队列中的ASP.NET应用程序/请求
这将告诉我们,由于工人短缺,工作项目是否排队.
检查应用程序池使用的标识
>打开IIS管理器>在IIS管理器中检查站点使用的应用程序池.>选择“应用程序池”列表中使用的应用程序池,然后选择“右键单击” – >属性并查看正在使用的帐户标识.>默认情况下应该是网络服务.

c# – 中断长时间运行的方法模式
我目前正在使用这种有点乏味的模式为用户运行一些长操作生成错误消息:
string _problem;
void SomeLongRunningMethod()
{
try
{
_problem = "Method1 had problem";
Method1();
_problem = "Unexpected error during doing something in Method2";
if(Method2())
{
_problem = "Method3 fails";
Method3();
}
_problem = "Not possible to obtain data";
var somedata = Method4();
}
catch(Exception)
{
MessageBox.Show("Problem with some long running method: " + _problem);
}
}
任何一种方法都可能抛出,我想告诉用户哪一步发生故障.这是通过在运行任何一个之前设置_problem来完成的.
在某些情况下,我可以使用不同的异常类型来捕获,但这并不总是有效,例如Method1和Method2都可以抛出InvalidOperationException().
这个重复的代码看起来像一个模式.虽然我无法认出来.有任何想法吗?如何提高可读性?
解决方法
您可以在catch中使用when来区分相同的异常类型并检查哪个方法引发了此异常:
void SomeLongRunningMethod()
{
try
{
Method1();
if (Method2())
{
Method3();
}
var somedata = Method4();
}
catch (InvalidOperationException invEx) when (invEx.TargetSite?.Name == nameof(Method1))
{
// ...
}
catch (InvalidOperationException invEx) when (invEx.TargetSite?.Name == nameof(Method2))
{
// ...
}
catch (Exception ex)
{
// ...
}
}
")
HTTP/1.0和HTTP/1.1 http2.0的区别,HTTP怎么处理长连接(阿里)
HTTP1.0 HTTP 1.1主要区别
长连接
HTTP 1.0需要使用keep-alive参数来告知服务器端要建立一个长连接,而HTTP1.1默认支持长连接。
HTTP是基于TCP/IP协议的,创建一个TCP连接是需要经过三次握手的,有一定的开销,如果每次通讯都要重新建立连接的话,对性能有影响。因此最好能维持一个长连接,可以用个长连接来发多个请求。
节约带宽
HTTP 1.1支持只发送header信息(不带任何body信息),如果服务器认为客户端有权限请求服务器,则返回100,否则返回401。客户端如果接受到100,才开始把请求body发送到服务器。
这样当服务器返回401的时候,客户端就可以不用发送请求body了,节约了带宽。
另外HTTP还支持传送内容的一部分。这样当客户端已经有一部分的资源后,只需要跟服务器请求另外的部分资源即可。这是支持文件断点续传的基础。
HOST域
现在可以web server例如tomat,设置虚拟站点是非常常见的,也即是说,web server上的多个虚拟站点可以共享同一个ip和端口。
HTTP1.0是没有host域的,HTTP1.1才支持这个参数。
HTTP1.1 HTTP 2.0主要区别
多路复用
HTTP2.0使用了(类似epoll)多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比HTTP1.1大了好几个数量级。
当然HTTP1.1也可以多建立几个TCP连接,来支持处理更多并发的请求,但是创建TCP连接本身也是有开销的。
TCP连接有一个预热和保护的过程,先检查数据是否传送成功,一旦成功过,则慢慢加大传输速度。因此对应瞬时并发的连接,服务器的响应就会变慢。所以最好能使用一个建立好的连接,并且这个连接可以支持瞬时并发的请求。
数据压缩
HTTP1.1不支持header数据的压缩,HTTP2.0使用HPACK算法对header的数据进行压缩,这样数据体积小了,在网络上传输就会更快。
服务器推送
意思是说,当我们对支持HTTP2.0的web server请求数据的时候,服务器会顺便把一些客户端需要的资源一起推送到客户端,免得客户端再次创建连接发送请求到服务器端获取。这种方式非常合适加载静态资源。
服务器端推送的这些资源其实存在客户端的某处地方,客户端直接从本地加载这些资源就可以了,不用走网络,速度自然是快很多的。
1.HTTP简介
web浏览器和服务器之类的交互过程必须遵守的协议.他是tcp/ip中的一个应用协议。用来协议数据交换过程和数据本身的格式.主要的有HTTP/1.0和HTTP1.1.
HTTP/1.0和HTTP/1.1都把TCP作为底层的传输协议。
HTTP客户首先发起建立与服务器TCP连接。一旦建立连接,浏览器进程和服务器进程就可以通过各自的套接字来访问TCP。如前所述,客户端套接字是客户进程和TCP连接之间的“门”,服务器端套接字是服务器进程和同一TCP连接之间的 “门”。客户往自己的套接字发送HTTP请求消息,也从自己的套接字接收HTTP响应消息。类似地,服务器从自己的套接字接收HTTP请求消息,也往自己 的套接字发送HTTP响应消息。客户或服务器一旦把某个消息送入各自的套接字,这个消息就完全落入TCP的控制之中。
TCP给HTTP提供一个可靠的数据传输服务;这意味着由客户发出的每个HTTP请求消息最终将无损地到达服务器,由服务器发出的每个HTTP响应消息最终也将无损地到达客户。我们可从中看到分层网络体系结构的一个明显优势——HTTP不必担心数据会丢失,也无需关心TCP如何从数据的丢失和错序中恢复出来的细节。这些是TCP和协议栈中更低协议层的任务。
TCP还使用一个拥塞控制机制。该机制迫使每个新的TCP连接一开始以相对缓慢的速率传输数据,然而只要网络不拥塞,每个连接可以迅速上升到相对较高的速率。这个慢速传输的初始阶段称为缓启动(slow start)。
需要注意的是,在向客户发送所请求文件的同时,服务器并没有存储关于该客户的任何状态信息。即便某个客户在几秒钟内再次请求同一个对象,服务器也不会响应说:自己刚刚给它发送了这个对象。相反,服务器重新发送这个对象,因为它已经彻底忘记早先做过什么。既然HTTP服务器不维护客户的状态信息,我们于是 说HTTP是一个无状态的协议(stateless protocol)。
2.一个完整的HTTP请求过程
HTTP事务=请求命令+响应结果

一次完整的请求过程:
(1)域名解析
(2)建立TCP连接,三次握手
(3)Web浏览器向Web服务端发送HTTP请求报文
(4)服务器响应HTTP请求
(5)浏览器解析HTML代码,并请求HTML代码中的资源(JS,CSS,图片)(这是自动向服务器请求下载的)
(6)浏览器对页面进行渲染呈现给客户
(7)断开TCP连接

如何解析对应的IP地址?域名解析过程(注意了先走本地再走DNS)
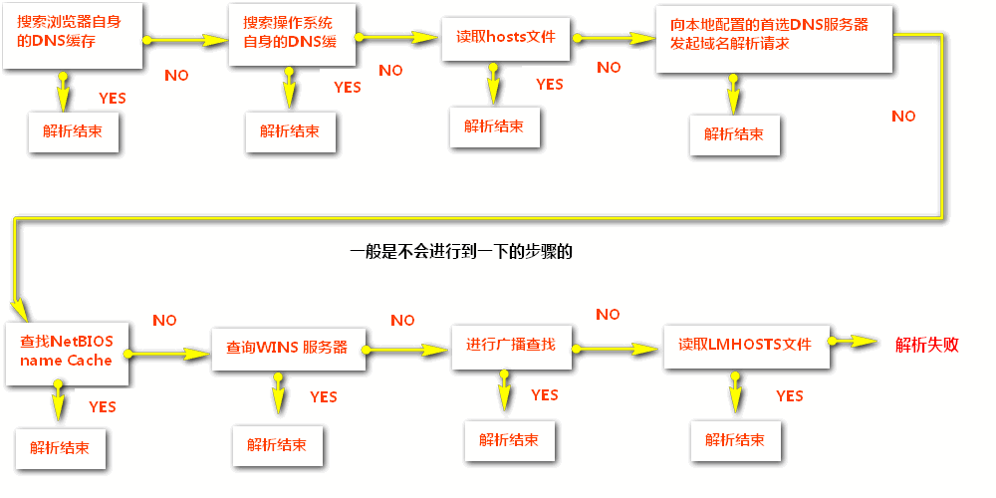
3.HTTP/1.0和HTTP/1.1的区别
HTTP 协议老的标准是HTTP/1.0,目前最通用的标准是HTTP/1.1。
在同一个tcp的连接中可以传送多个HTTP请求和响应.
多个请求和响应可以重叠,多个请求和响应可以同时进行.
更加多的请求头和响应头(比如HTTP1.0没有host的字段).
它们最大的区别:
在 HTTP/1.0 中,大多实现为每个请求/响应交换使用新的连接。HTTP 1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。
在 HTTP/1.1 中,一个连接可用于一次或多次请求/响应交换,尽管连接可能由于各种原因被关闭。HTTP 1.1支持持久连接,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟。一个包含有许多图像的网页文件的多个请求和应答可以在一个连接中传输,但每个单独的网页文件的请求和应答仍然需要使用各自的连接。HTTP 1.1还允许客户端不用等待上一次请求结果返回,就可以发出下一次请求,但服务器端必须按照接收到客户端请求的先后顺序依次回送响应结果,以保证客户端能够区分出每次请求的响应内容,这样也显著地减少了整个下载过程所需要的时间。
举例说明:
一个包含有许多图像的网页文件中并没有包含真正的图像数据内容,而只是指明了这些图像的URL地址,当WEB浏览器访问这个网页文件时,浏览器首先要发出针对该网页文件的请求,当浏览器解析WEB服务器返回的该网页文档中的HTML内容时,发现其中的<img>图像标签后,浏览器将根据<img>标签中的src属性所指定的URL地址再次向服务器发出下载图像数据的请求。
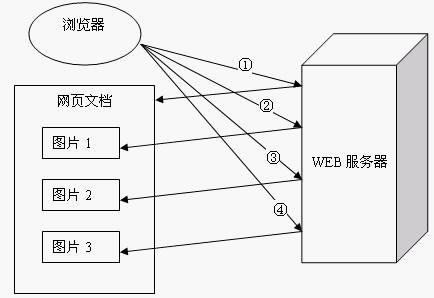
显然,访问一个包含有许多图像的网页文件的整个过程包含了多次请求和响应,每次请求和响应都需要建立一个单独的连接,每次连接只是传输一个文档和图像,上一次和下一次请求完全分离。即使图像文件都很小,但是客户端和服务器端每次建立和关闭连接却是一个相对比较费时的过程,并且会严重影响客户机和服务器的性能。当一个网页文件中包含Applet,JavaScript文件,CSS文件等内容时,也会出现类似上述的情况。
为了克服HTTP 1.0的这个缺陷,HTTP 1.1支持持久连接,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟。一个包含有许多图像的网页文件的多个请求和应答可以在一个连接中传输,但每个单独的网页文件的请求和应答仍然需要使用各自的连接。
HTTP 1.1还允许客户端不用等待上一次请求结果返回,就可以发出下一次请求,但服务器端必须按照接收到客户端请求的先后顺序依次回送响应结果,以保证客户端能够区分出每次请求的响应内容,这样也显著地减少了整个下载过程所需要的时间。
基于HTTP 1.1协议的客户机与服务器的信息交换过程,如下图所示
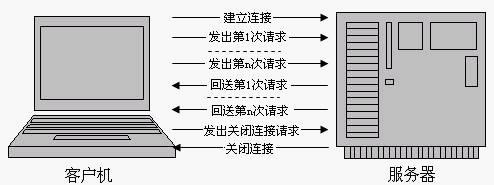
可见,HTTP 1.1在继承了HTTP 1.0优点的基础上,也克服了HTTP 1.0的性能问题。
还有哪些小的区别呢?
HTTP 1.1还通过增加更多的请求头和响应头来改进和扩充HTTP 1.0的功能。
例如,由于HTTP 1.0不支持Host请求头字段,WEB浏览器无法使用主机头名来明确表示要访问服务器上的哪个WEB站点,这样就无法使用WEB服务器在同一个IP地址和端口号上配置多个虚拟WEB站点。
在HTTP 1.1中增加Host请求头字段后,WEB浏览器可以使用主机头名来明确表示要访问服务器上的哪个WEB站点,这才实现了在一台WEB服务器上可以在同一个IP地址和端口号上使用不同的主机名来创建多个虚拟WEB站点。
HTTP 1.1的持续连接,也需要增加新的请求头来帮助实现。
例如,Connection请求头的值为Keep-Alive时,客户端通知服务器返回本次请求结果后保持连接;Connection请求头的值为close时,客户端通知服务器返回本次请求结果后关闭连接。
HTTP 1.1还提供了与身份认证、状态管理和Cache缓存等机制相关的请求头和响应头。
4.Http怎么处理长连接
基于http协议的长连接
在HTTP1.0和HTTP1.1协议中都有对长连接的支持。其中HTTP1.0需要在request中增加”Connection: keep-alive“ header才能够支持,而HTTP1.1默认支持.
http1.0请求与服务端的交互过程:
(1)客户端发出带有包含一个header:”Connection: keep-alive“的请求
(2)服务端接收到这个请求后,根据http1.0和”Connection: keep-alive“判断出这是一个长连接,就会在response的header中也增加”Connection: keep-alive“,同时不会关闭已建立的tcp连接.
(3)客户端收到服务端的response后,发现其中包含”Connection: keep-alive“,就认为是一个长连接,不关闭这个连接。并用该连接再发送request.转到(1)
http1.1请求与服务端的交互过程:
(1)客户端发出http1.1的请求
(2)服务端收到http1.1后就认为这是一个长连接,会在返回的response设置Connection: keep-alive,同时不会关闭已建立的连接.
(3)客户端收到服务端的response后,发现其中包含”Connection: keep-alive“,就认为是一个长连接,不关闭这个连接。并用该连接再发送request.转到(1)
基于http协议的长连接减少了请求,减少了建立连接的时间,但是每次交互都是由客户端发起的,客户端发送消息,服务端才能返回客户端消息。因为客户端也不知道服务端什么时候会把结果准备好,所以客户端的很多请求是多余的,仅是维持一个心跳,浪费了带宽。
栗子:下列哪些http方法对于服务端和用户端一定是安全的?(C)
A.GET
B.HEAD
C.TRACE
D.OPTIONS
E.POST
TRACE: 这个方法用于返回到达最后服务器的请求的报文,这个方法对服务器和客户端都没有什么危险。
HTTP是无状态的
也就是说,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。如果客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源,如JavaScript文件、图像文件、CSS文件等;当浏览器每遇到这样一个Web资源,就会建立一个HTTP会话
HTTP1.1和HTTP1.0相比较而言,最大的区别就是增加了持久连接支持(貌似最新的 http1.0 可以显示的指定 keep-alive),但还是无状态的,或者说是不可以信任的。
如果浏览器或者服务器在其头信息加入了这行代码
Connection:keep-alive
TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了带宽。
实现长连接要客户端和服务端都支持长连接。
如果web服务器端看到这里的值为“Keep-Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接),它就可以利用持久连接的优点,当页面包含多个元素时(例如Applet,图片),显著地减少下载所需要的时间。要实现这一点, web服务器需要在返回给客户端HTTP头信息中发送一个Content-Length(返回信息正文的长度)头,最简单的实现方法是:先把内容写入ByteArrayOutputStream,然 后在正式写出内容之前计算它的大小
无论客户端浏览器 (Internet Explorer) 还是 Web 服务器具有较低的 KeepAlive 值,它都将是限制因素。例如,如果客户端的超时值是两分钟,而 Web 服务器的超时值是一分钟,则最大超时值是一分钟。客户端或服务器都可以是限制因素
在header中加入 --Connection:keep-alive
在HTTp协议请求和响应中加入这条就能维持长连接。
再封装HTTP消息数据体的消息应用就显的非常简单易用
Http Keep-Alive seems to be massively misunderstood. Here''s a short description of how it works, under both 1.0 and 1.1
HTTP/1.0
Under HTTP 1.0, there is no official specification for how keepalive operates. It was, in essence, tacked on to an existing protocol. If the browser supports keep-alive, it adds an additional header to the request:
Connection: Keep-Alive
Then, when the server receives this request and generates a response, it also adds a header to the response:
Connection: Keep-Alive
Following this, the connection is NOT dropped, but is instead kept open. When the client sends another request, it uses the same connection. This will continue until either the client or the server decides that the conversation is over, and one of them drops the connection.
HTTP/1.1
Under HTTP 1.1, the official keepalive method is different. All connections are kept alive, unless stated otherwise with the following header:
Connection: close
The Connection: Keep-Alive header no longer has any meaning because of this.
Additionally, an optional Keep-Alive: header is described, but is so underspecified as to be meaningless. Avoid it.
Not reliable
HTTP is a stateless protocol - this means that every request is independent of every other. Keep alive doesn’t change that. Additionally, there is no guarantee that the client or the server will keep the connection open. Even in 1.1, all that is promised is that you will probably get a notice that theconnection is being closed. So keepalive is something you should not write your application to rely upon.
KeepAlive and POST
The HTTP 1.1 spec states that following the body of a POST, there are to be no additional characters. It also states that "certain" browsers may not follow this spec, putting a CRLF after the body of the POST. Mmm-hmm. As near as I can tell, most browsers follow a POSTed body with a CRLF. There are two ways of dealing with this: Disallow keepalive in the context of a POST request, or ignore CRLF on a line by itself. Most servers deal with this in the latter way, but there''s no way to know how a server will handle it without testing.
Java应用
client用apache的commons-httpclient来执行method 。
用 method.setRequestHeader("Connection" , "Keep-Alive" or "close") 来控制是否保持连接。
常用的apache、resin、tomcat等都有相关的配置是否支持keep-alive。
tomcat中可以设置:maxKeepAliveRequests
The maximum number of HTTP requests which can be pipelined until the connection is closed by the server. Setting this attribute to 1 will disable HTTP/1.0 keep-alive, as well asHTTP/1.1 keep-alive and pipelining. Setting this to -1 will allow an unlimited amount of pipelined or keep-alive HTTP requests. If not specified, this attribute is set to 100.
解释1
所谓长连接指建立SOCKET连接后不管是否使用都保持连接,但安全性较差,
所谓短连接指建立SOCKET连接后发送后接收完数据后马上断开连接,一般银行都使用短连接
解释2
长连接就是指在基于tcp的通讯中,一直保持连接,不管当前是否发送或者接收数据。
而短连接就是只有在有数据传输的时候才进行连接,客户-服务器通信/传输数据完毕就关闭连接。
解释3
长连接和短连接这个概念好像只有移动的CMPP协议中提到了,其他的地方没有看到过。
通信方式
各网元之间共有两种连接方式:长连接和短连接。所谓长连接,指在一个TCP连接上可以连续发送多个数据包,在TCP连接保持期间,如果没有数据包发送,需要双方发检测包以维持此连接。短连接是指通信双方有数据交互时,就建立一个TCP连接,数据发送完成后,则断开此TCP连接,即每次TCP连接只完成一对 CMPP消息的发送。
现阶段,要求ISMG之间必须采用长连接的通信方式,建议SP与ISMG之间采用长连接的通信方式。
解释4
短连接:比如http的,只是连接、请求、关闭,过程时间较短,服务器若是一段时间内没有收到请求即可关闭连接。
长连接:有些服务需要长时间连接到服务器,比如CMPP,一般需要自己做在线维持。
最近在看“服务器推送技术”,在B/S结构中,通过某种magic使得客户端不需要通过轮询即可以得到服务端的最新信息(比如股票价格),这样可以节省大量的带宽。
传统的轮询技术对服务器的压力很大,并且造成带宽的极大浪费。如果改用ajax轮询,可以降低带宽的负荷(因为服务器返回的不是完整页面),但是对服务器的压力并不会有明显的减少。
而推技术(push)可以改善这种情况。但因为
HTTP连接的特性(短暂,必须由客户端发起),使得推技术的实现比较困难,常见的做法是通过延长http连接的寿命,来实现push。
接下来自然该讨论如何延长
http连接的寿命,最简单的自然是死循环法:
【servlet代码片段】
public void doGet(Request req, Response res) {
PrintWriter out = res.getWriter();
……
正常输出页面
……
out.flush();
while (true) {
out.print("输出更新的内容");
out.flush();
Thread.sleep(3000);
}
}
如果使用观察者模式则可以进一步提高性能。
但是这种做法的缺点在于客户端请求了这个servlet后,web服务器会开启一个线程执行servlet的代码,而servlet由迟迟不肯结束,造成该线程也无法被释放。于是乎,一个客户端一个线程,当客户端数量增加时,服务器依然会承受很大的负担。
要从根本上改变这个现象比较复杂,目前的趋势是从web服务器内部入手,用
nio(JDK 1.4提出的java.nio包)改写request/response的实现,再利用线程池增强服务器的资源利用率,从而解决这个问题,目前支持这一非J2EE官方技术的服务器有
Glassfish和
Jetty(后者只是听说,没有用过)。
目前也有一些框架/工具可以帮助你实现推功能,比如pushlets。不过没有深入研究。
这两天准备学习一下Glassfish中对Comet(彗星:某人给服务器推送技术起的名字)的支持,呵呵。
poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标。如果对课程感兴趣,请大家咨询qq:908821478,咨询电话010-84505200。
HTTP是一个构建在传输层的TCP协议之上的应用层的协议,在这个层的协议,是一种网络交互需要遵守的一种协议规范。
HTTP1.0的短连接
HTTP 1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。这个过程大概可以描述为:
1、建立连接:首先DNS解析过程。如把域名变成一个ip,如果url不包含端口号,则会使用该协议的默认端口号,HTTP协议的默认端口号为80。然后三次握手建立一个TCP连接;
2、请求:连接成功后,开始向web服务器发送请求,这个请求一般是GET或POST请求。
3、应答:web服务器收到这个请求,进行处理。web服务器会把文件内容传送给响应的web浏览器。包括:HTTP头信息,体信息。
4、关闭连接:当应答结束后,web浏览器与web服务器必须四次握手断开连接,以保证其它web浏览器能够与web服务器建立连接。
HTTP1.1的长连接
但是HTTP1.1开始默认建立的是长连接,即一旦浏览器发起HTTP请求,建立的连接不会请求应答之后立刻断掉。
1、 一个复杂的具备很多HTTP资源的网页会建立多少TCP连接,如何使用这些连接?
2、 已经建立的TCP连接是否会自动断开,时间是多久?
对于第一个问题。现在浏览器都有最大并发连接数限制,应该说如果需要,就会尽量在允许范围内建立更多的TCP持久连接来处理HTTP请求,同样滴,一个TCP持久连接可以不断传输多个HTTP请求,但是如果上一个请求的响应还未收到,则不能处理下一个请求(Pipeling管道技术可以解决这个问题从而进一步提升性能),所以说很多浏览器其实都可以修改允许最大并发连接数以提升浏览网页的速度。
对于第二个问题。问题在于服务器端对于长连接的实现,特别是在对长连接的维护上。FTP协议及SMTP协议中有NOOP消息,这个就可以认为是心跳报文,但HTTP协议没有类似的消息,这样服务器端只能使用超时断开的策略来维护连接。设想超时时间非常短,那么有效空闲时间就非常短,换句话讲:一旦链路上没有数据发送,服务器端很快就关闭连接。
也就是说其实HTTP的长连接很容易在空闲后自动断开,一般来说这个时间是300s左右。
参考:HTTP/1.0和HTTP/1.1的区别,HTTP怎么处理长连接
参考:HTTP实现长连接(TTP1.1和HTTP1.0相比较而言,最大的区别就是增加了持久连接支持Connection: keep-alive)
参考:老李谈HTTP1.1的长连接
参考:HTTP1.0 HTTP 1.1 HTTP 2.0主要区别
参考:HTTP1.0和HTTP1.1的区别
参考:HTTP 1.1与HTTP 1.0的比较
-----http请求的过程和实现机制")
HTTP深入浅出http请求(转)-----http请求的过程和实现机制
摘要:此文章大概讲明了http请求的过程和实现机制,可以作为了解,至于请求头和响应头的具体信息需要查看下一篇随笔:Http请求详解(转)----请求+响应各字段详解
HTTP(HyperText Transfer Protocol)是一套计算机通过网络进行通信的规则。计算机专家设计出HTTP,使HTTP客户(如Web浏览器)能够从HTTP服务器(Web服务器)请求信息和服务,HTTP目前协议的版本是1.1.HTTP是一种无状态的协议,无状态是指Web浏览器和Web服务器之间不需要建立持久的连接,这意味着当一个客户端向服务器端发出请求,然后Web服务器返回响应(response),连接就被关闭了,在服务器端不保留连接的有关信息.HTTP遵循请求(Request)/应答(Response)模型。Web浏览器向Web服务器发送请求,Web服务器处理请求并返回适当的应答。所有HTTP连接都被构造成一套请求和应答。
HTTP使用内容类型,是指Web服务器向Web浏览器返回的文件都有与之相关的类型。所有这些类型在MIME Internet邮件协议上模型化,即Web服务器告诉Web浏览器该文件所具有的种类,是HTML文档、GIF格式图像、声音文件还是独立的应用程序。大多数Web浏览器都拥有一系列的可配置的辅助应用程序,它们告诉浏览器应该如何处理Web服务器发送过来的各种内容类型。
HTTP通信机制是在一次完整的HTTP通信过程中,Web浏览器与Web服务器之间将完成下列7个步骤:
(1)
建立TCP连接
在HTTP工作开始之前,Web浏览器首先要通过网络与Web服务器建立连接,该连接是通过TCP来完成的,该协议与IP协议共同构建Internet,即著名的TCP/IP协议族,因此Internet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议,根据规则,只有低层协议建立之后才能,才能进行更层协议的连接,因此,首先要建立TCP连接,一般TCP连接的端口号是80
(2) Web浏览器向Web服务器发送请求命令
一旦建立了TCP连接,Web浏览器就会向Web服务器发送请求命令
例如:GET/sample/hello.jsp HTTP/1.1
(3) Web浏览器发送请求头信息
浏览器发送其请求命令之后,还要以头信息的形式向Web服务器发送一些别的信息,之后浏览器发送了一空白行来通知服务器,它已经结束了该头信息的发送。
(4) Web服务器应答
客户机向服务器发出请求后,服务器会客户机回送应答,
HTTP/1.1 200 OK
应答的第一部分是协议的版本号和应答状态码
(5) Web服务器发送应答头信息
正如客户端会随同请求发送关于自身的信息一样,服务器也会随同应答向用户发送关于它自己的数据及被请求的文档。
(6) Web服务器向浏览器发送数据
Web服务器向浏览器发送头信息后,它会发送一个空白行来表示头信息的发送到此为结束,接着,它就以Content-Type应答头信息所描述的格式发送用户所请求的实际数据
(7) Web服务器关闭TCP连接
一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,然后如果浏览器或者服务器在其头信息加入了这行代码
Connection:keep-alive
TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。
HTTP请求格式
当浏览器向Web服务器发出请求时,它向服务器传递了一个数据块,也就是请求信息,HTTP请求信息由3部分组成:
l 请求方法URI协议/版本
l 请求头(Request Header)
l 请求正文
下面是一个HTTP请求的例子:
GET/sample.jspHTTP/1.1
Accept:image/gif.image/jpeg,*/*
Accept-Language:zh-cn
Connection:Keep-Alive
Host:localhost
User-Agent:Mozila/4.0(compatible;MSIE5.01;Window NT5.0)
Accept-Encoding:gzip,deflate
username=jinqiao&password=1234
(1) 请求方法URI协议/版本
请求的第一行是“方法URL议/版本”:GET/sample.jsp HTTP/1.1
以上代码中“GET”代表请求方法,“/sample.jsp”表示URI,“HTTP/1.1代表协议和协议的版本。
根据HTTP标准,HTTP请求可以使用多种请求方法。例如:HTTP1.1支持7种请求方法:GET、POST、HEAD、OPTIONS、PUT、DELETE和TARCE。在Internet应用中,最常用的方法是GET和POST。
URL完整地指定了要访问的网络资源,通常只要给出相对于服务器的根目录的相对目录即可,因此总是以“/”开头,最后,协议版本声明了通信过程中使用HTTP的版本。
(2) 请求头(Request Header)
请求头包含许多有关的客户端环境和请求正文的有用信息。例如,请求头可以声明浏览器所用的语言,请求正文的长度等。
Accept:image/gif.image/jpeg.*/*
Accept-Language:zh-cn
Connection:Keep-Alive
Host:localhost
User-Agent:Mozila/4.0(compatible:MSIE5.01:Windows NT5.0)
Accept-Encoding:gzip,deflate.
(3) 请求正文
请求头和请求正文之间是一个空行,这个行非常重要,它表示请求头已经结束,接下来的是请求正文。请求正文中可以包含客户提交的查询字符串信息:
username=jinqiao&password=1234
在以上的例子的HTTP请求中,请求的正文只有一行内容。当然,在实际应用中,HTTP请求正文可以包含更多的内容。
HTTP请求方法我这里只讨论GET方法与POST方法
l GET方法
GET方法是默认的HTTP请求方法,我们日常用GET方法来提交表单数据,然而用GET方法提交的表单数据只经过了简单的编码,同时它将作为URL的一部分向Web服务器发送,因此,如果使用GET方法来提交表单数据就存在着安全隐患上。例如
Http://127.0.0.1/login.jsp?Name=zhangshi&Age=30&Submit=%cc%E+%BD%BB
从上面的URL请求中,很容易就可以辩认出表单提交的内容。(?之后的内容)另外由于GET方法提交的数据是作为URL请求的一部分所以提交的数据量不能太大
l POST方法
POST方法是GET方法的一个替代方法,它主要是向Web服务器提交表单数据,尤其是大批量的数据。POST方法克服了GET方法的一些缺点。通过POST方法提交表单数据时,数据不是作为URL请求的一部分而是作为标准数据传送给Web服务器,这就克服了GET方法中的信息无法保密和数据量太小的缺点。因此,出于安全的考虑以及对用户隐私的尊重,通常表单提交时采用POST方法。
从编程的角度来讲,如果用户通过GET方法提交数据,则数据存放在QUERY_STRING环境变量中,而POST方法提交的数据则可以从标准输入流中获取。
HTTP应答与HTTP请求相似,HTTP响应也由3个部分构成,分别是:
l 协议状态版本代码描述
l 响应头(Response Header)
l 响应正文
下面是一个HTTP响应的例子:
HTTP/1.1 200 OK
Server:Apache Tomcat/5.0.12
Date:Mon,6Oct2003 13:23:42 GMT
Content-Length:112
<html>
<head>
<title>HTTP响应示例<title>
</head>
<body>
Hello HTTP!
</body>
</html>
协议状态代码描述HTTP响应的第一行类似于HTTP请求的第一行,它表示通信所用的协议是HTTP1.1服务器已经成功的处理了客户端发出的请求(200表示成功):
HTTP/1.1 200 OK
响应头(Response Header)响应头也和请求头一样包含许多有用的信息,例如服务器类型、日期时间、内容类型和长度等:
Server:Apache Tomcat/5.0.12
Date:Mon,6Oct2003 13:13:33 GMT
Content-Type:text/html
Last-Moified:Mon,6 Oct 2003 13:23:42 GMT
Content-Length:112
响应正文响应正文就是服务器返回的HTML页面:
<html>
<head>
<title>HTTP响应示例<title>
</head>
<body>
Hello HTTP!
</body>
</html>
响应头和正文之间也必须用空行分隔。
l HTTP应答码
HTTP应答码也称为状态码,它反映了Web服务器处理HTTP请求状态。HTTP应答码由3位数字构成,其中首位数字定义了应答码的类型:
1XX-信息类(Information),表示收到Web浏览器请求,正在进一步的处理中
2XX-成功类(Successful),表示用户请求被正确接收,理解和处理例如:200 OK
3XX-重定向类(Redirection),表示请求没有成功,客户必须采取进一步的动作。
4XX-客户端错误(Client Error),表示客户端提交的请求有错误例如:404 NOT
Found,意味着请求中所引用的文档不存在。
5XX-服务器错误(Server Error)表示服务器不能完成对请求的处理:如500
对于我们Web开发人员来说掌握HTTP应答码有助于提高Web应用程序调试的效率和准确性。
安全连接
Web应用最常见的用途之一是电子商务,可以利用Web服务器端程序使人们能够网络购物,需要指出一点是,缺省情况下,通过Internet发送信息是不安全的,如果某人碰巧截获了你发给朋友的一则消息,他就能打开它,假想在里面有你的信用卡号码,这会有多么糟糕,幸运的是,很多Web服务器以及Web浏览器都有创立安全连接的能力,这样它们就可以安全的通信了。
通过Internet提供安全连接最常见的标准是安全套接层(Secure Sockets layer,SSl)协议。SSL协议是一个应用层协议(和HTTP一样),用于安全方式在Web上交换数据,SSL使用公开密钥编码系统。从本质讲,这意味着业务中每一方都拥有一个公开的和一个私有的密钥。当一方使用另一方公开密钥进行编码时,只有拥有匹配密钥的人才能对其解码。简单来讲,公开密钥编码提供了一种用于在两方之间交换数据的安全方法,SSL连接建立之后,客户和服务器都交换公开密钥,并在进行业务联系之前进行验证,一旦双方的密钥都通过验证,就可以安全地交换数据。
-
- GET
通过请求 URI得到资源
- POST,
用于添加新的内容
- PUT
用于修改某个内容
- DELETE,
删除某个内容
- CONNECT,
用于代理进行传输,如使用SSL
- OPTIONS
询问可以执行哪些方法
- PATCH,
部分文档更改
- PROPFIND, (wedav)
查看属性
- PROPPATCH, (wedav)
设置属性
- MKCOL, (wedav)
创建集合(文件夹)
- COPY, (wedav)
拷贝
- MOVE, (wedav)
移动
- LOCK, (wedav)
加锁
- UNLOCK (wedav)
解锁
- TRACE
用于远程诊断服务器
- HEAD
类似于GET,但是不返回body信息,用于检查对象是否存在,以及得到对象的元数据
apache2中,可使用Limit,LimitExcept进行访问控制的
方法
包括:
GET
,
POST
,
PUT
,
DELETE
,
CONNECT
,
OPTIONS
,
PATCH
,
PROPFIND
,
PROPPATCH
,
MKCOL
,
COPY
,
MOVE
,
LOCK
,和
UNLOCK
.
其中, HEAD GET POST OPTIONS PROPFIND是和读取相关的
方法
,MKCOL PUT DELETE LOCK UNLOCK COPY MOVE PROPPATCH是和修改相关的
方法
part of
Hypertext Transfer Protocol -- HTTP/1.1
RFC 2616 Fielding, et al.
9 Method Definitions
The set of common methods for HTTP/1.1 is defined below. Although this set can be expanded, additional methods cannot be assumed to share the same semantics for separately extended clients and servers.
The Host request-header field (section
14.23
) MUST accompany all HTTP/1.1 requests.
9.1 Safe and Idempotent Methods
9.1.1 Safe Methods
Implementors should be aware that the software represents the user in their interactions over the Internet, and should be careful to allow the user to be aware of any actions they might take which may have an unexpected significance to themselves or others.
In particular, the convention has been established that the GET and HEAD methods SHOULD NOT have the significance of taking an action other than retrieval. These methods ought to be considered "safe". This allows user agents to represent other methods, such as POST, PUT and DELETE, in a special way, so that the user is made aware of the fact that a possibly unsafe action is being requested.
Naturally, it is not possible to ensure that the server does not generate side-effects as a result of performing a GET request; in fact, some dynamic resources consider that a feature. The important distinction here is that the user did not request the side -effects, so therefore cannot be held accountable for them.
9.1.2 Idempotent Methods
Methods can also have the property of "idempotence" in that (aside from error or expiration issues) the side-effects of N > 0 identical requests is the same as for a single request. The methods GET, HEAD, PUT and DELETE share this property. Also, the methods OPTIONS and TRACE SHOULD NOT have side effects, and so are inherently idempotent.
However, it is possible that a sequence of several requests is non- idempotent, even if all of the methods executed in that sequence are idempotent. (A sequence is idempotent if a single execution of the entire sequence always yields a result that is not changed by a reexecution of all, or part, of that sequence.) For example, a sequence is non-idempotent if its result depends on a value that is later modified in the same sequence.
A sequence that never has side effects is idempotent, by definition (provided that no concurrent operations are being executed on the same set of resources).
9.2 OPTIONS
The OPTIONS method represents a request for information about the communication options available on the request/response chain identified by the Request-URI. This method allows the client to determine the options and/or requirements associated with a resource, or the capabilities of a server , without implying a resource action or initiating a resource retrieval.
Responses to this method are not cacheable.
If the OPTIONS request includes an entity-body (as indicated by the presence of Content-Length or Transfer-Encoding), then the media type MUST be indicated by a Content-Type field. Although this specification does not define any use for such a body, future extensions to HTTP might use the OPTIONS body to make more detailed queries on the server. A server that does not support such an extension MAY discard the request body.
If the Request-URI is an asterisk ("*"), the OPTIONS request is intended to apply to the server in general rather than to a specific resource. Since a server''s communication options typically depend on the resource, the "*" request is only useful as a "ping" or "no-op" type of method; it does nothing beyond allowing the client to test the capabilities of the server. For example, this can be used to test a proxy for HTTP/1.1 compliance (or lack thereof).
If the Request-URI is not an asterisk, the OPTIONS request applies only to the options that are available when communicating with that resource.
A 200 response SHOULD include any header fields that indicate optional features implemented by the server and applicable to that resource (eg, Allow), possibly including extensions not defined by this specification. The response body, if any, SHOULD also include information about the communication options. The format for such a
body is not defined by this specification, but might be defined by future extensions to HTTP. Content negotiation MAY be used to select the appropriate response format. If no response body is included, the response MUST include a Content-Length field with a field- value of "0".
The Max-Forwards request-header field MAY be used to target a specific proxy in the request chain. When a proxy receives an OPTIONS request on an absoluteURI for which request forwarding is permitted, the proxy MUST check for a Max-Forwards field. If the Max-Forwards field-value is zero ("0"), the proxy MUST NOT forward the message; instead, the proxy SHOULD respond with its own communication options. If the Max-Forwards field-value is an integer greater than zero, the proxy MUST decrement the field-value when it forwards the request. If no Max-Forwards field is present in the request, then the forwarded request MUST NOT include a Max-Forwards field.
9.3 GET
The GET method means retrieve whatever information (in the form of an entity) is identified by the Request-URI. If the Request-URI refers to a data-producing process, it is the produced data which shall be returned as the entity in the response and not the source text of the process, unless that text happens to be the output of the process.
The semantics of the GET method change to a "conditional GET" if the request message includes an If-Modified-Since, If-Unmodified-Since, If-Match, If-None-Match, or If-Range header field. A conditional GET method requests that the entity be transferred only under the circumstances described by the conditional header field(s). The conditional GET method is intended to reduce unnecessary network usage by allowing cached entities to be refreshed without requiring multiple requests or transferring data already held by the client.
The semantics of the GET method change to a "partial GET" if the request message includes a Range header field. A partial GET requests that only part of the entity be transferred, as described in section
14.35
. The partial GET method is intended to reduce unnecessary network usage by allowing partially-retrieved entities to be completed without transferring data already held by the client.
The response to a GET request is cacheable if and only if it meets the requirements for HTTP caching described in section 13.
See section
15.1.3
for security considerations when used for forms.
9.4 HEAD
The HEAD method is identical to GET except that the server MUST NOT return a message-body in the response. The metainformation contained in the HTTP headers in response to a HEAD request SHOULD be identical to the information sent in response to a GET request. This method can be used for obtaining metainformation about the entity implied by the request without transferring the entity-body itself. This method is often used for testing hypertext links for validity, accessibility, and recent modification.
The response to a HEAD request MAY be cacheable in the sense that the information contained in the response MAY be used to update a previously cached entity from that resource. If the new field values indicate that the cached entity differs from the current entity (as would be indicated by a change in Content-Length, Content-MD5, ETag or Last-Modified), then the cache MUST treat the cache entry as stale.
9.5 POST
The POST method is used to request that the origin server accept the entity enclosed in the request as a new subordinate of the resource identified by the Request-URI in the Request-Line. POST is designed to allow a uniform method to cover the following functions :
- Annotation of existing resources;
- Posting a message to a bulletin board, newsgroup, mailing list, or similar group of articles;
- Providing a block of data, such as the result of submitting a form, to a data-handling process;
- Extending a database through an append operation.
The actual function performed by the POST method is determined by the server and is usually dependent on the Request-URI. The posted entity is subordinate to that URI in the same way that a file is subordinate to a directory containing it, a news article is subordinate to a newsgroup to which it is posted, or a record is subordinate to a database.
The action performed by the POST method might not result in a resource that can be identified by a URI. In this case, either 200 (OK) or 204 (No Content) is the appropriate response status, depending on whether or not the response includes an entity that describes the result.
If a resource has been created on the origin server, the response SHOULD be 201 (Created) and contain an entity which describes the status of the request and refers to the new resource, and a Location header (see section
14.30
).
Responses to this method are not cacheable, unless the response includes appropriate Cache-Control or Expires header fields. However, the 303 (See Other) response can be used to direct the user agent to retrieve a cacheable resource.
POST requests MUST obey the message transmission requirements set out in section 8.2.
See section
15.1.3
for security considerations.
9.6 PUT
The PUT method requests that the enclosed entity be stored under the supplied Request-URI. If the Request-URI refers to an already existing resource, the enclosed entity SHOULD be considered as a modified version of the one residing on the origin server. If the Request-URI does not point to an existing resource, and that URI is capable of being defined as a new resource by the requesting user agent, the origin server can create the resource with that URI. If a new resource is created, the origin server MUST inform the user agent via the 201 (Created) response. If an existing resource is modified, either the 200 (OK) or 204 (No Content) response codes SHOULD be sent to indicate successful completion of the request. If the resource could not be created or modified with the Request-URI,an appropriate error response SHOULD be given that reflects the nature of the problem. The recipient of the entity MUST NOT ignore any Content-* (eg Content-Range) headers that it does not understand or implement and MUST return a 501 (Not Implemented) response in such cases.
If the request passes through a cache and the Request-URI identifies one or more currently cached entities, those entries SHOULD be treated as stale. Responses to this method are not cacheable.
The fundamental difference between the POST and PUT requests is reflected in the different meaning of the Request-URI. The URI in a POST request identifies the resource that will handle the enclosed entity. That resource might be a data-accepting process, a gateway to some other protocol, or a separate entity that accepts annotations. In contrast, the URI in a PUT request identifies the entity enclosed with the request -- the user agent knows what URI is intended and the server MUST NOT attempt to apply the request to some other resource. If the server desires that the request be applied to a different URI,
it MUST send a 301 (Moved Permanently) response; the user agent MAY then make its own decision regarding whether or not to redirect the request.
A single resource MAY be identified by many different URIs. For example, an article might have a URI for identifying "the current version" which is separate from the URI identifying each particular version. In this case, a PUT request on a general URI might result in several other URIs being defined by the origin server.
HTTP/1.1 does not define how a PUT method affects the state of an origin server.
PUT requests MUST obey the message transmission requirements set out in section 8.2.
Unless otherwise specified for a particular entity-header, the entity-headers in the PUT request SHOULD be applied to the resource created or modified by the PUT.
9.7 DELETE
The DELETE method requests that the origin server delete the resource identified by the Request-URI. This method MAY be overridden by human intervention (or other means) on the origin server. The client cannot be guaranteed that the operation has been carried out, even if the status code returned from the origin server indicates that the action has been completed successfully. However, the server SHOULD NOT indicate success unless, at the time the response is given, it intends to delete the resource or move it to an inaccessible location.
A successful response SHOULD be 200 (OK) if the response includes an entity describing the status, 202 (Accepted) if the action has not yet been enacted, or 204 (No Content) if the action has been enacted but the response does not include an entity.
If the request passes through a cache and the Request-URI identifies one or more currently cached entities, those entries SHOULD be treated as stale. Responses to this method are not cacheable.
9.8 TRACE
The TRACE method is used to invoke a remote, application-layer loop- back of the request message. The final recipient of the request SHOULD reflect the message received back to the client as the entity-body of a 200 (OK) response. The final recipient is either the
origin server or the first proxy or gateway to receive a Max-Forwards value of zero (0) in the request (see section 14.31). A TRACE request MUST NOT include an entity.
TRACE allows the client to see what is being received at the other end of the request chain and use that data for testing or diagnostic information. The value of the Via header field (section
14.45
) is of particular interest, since it acts as a trace of the request chain. Use of the Max-Forwards header field allows the client to limit the length of the request chain, which is useful for testing a chain of proxies forwarding messages in an infinite loop.
If the request is valid, the response SHOULD contain the entire request message in the entity-body, with a Content-Type of "message/http". Responses to this method MUST NOT be cached.
9.9 CONNECT
This specification reserves the method name CONNECT for use with a proxy that can dynamically switch to being a tunnel (eg SSL tunneling
[44]
).
今天关于php – 处理长时间运行的重复HTTP请求和php长时间执行的分享就到这里,希望大家有所收获,若想了解更多关于asp.net – 长时间运行HttpWebRequests、c# – 中断长时间运行的方法模式、HTTP/1.0和HTTP/1.1 http2.0的区别,HTTP怎么处理长连接(阿里)、HTTP深入浅出http请求(转)-----http请求的过程和实现机制等相关知识,可以在本站进行查询。


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

