本文将带您了解关于iPhone/iPadIOSApp仪器内存计数与task_info内存计数的新内容,同时我们还将为您解释iphone内存计算错误的相关知识,另外,我们还将为您提供关于2013Stan
本文将带您了解关于iPhone / iPad IOS App仪器内存计数与task_info内存计数的新内容,同时我们还将为您解释iphone内存计算错误的相关知识,另外,我们还将为您提供关于2013 Stanford公开课 Developing iOS 7 Apps for iPhone and iPad 讲义分享、Apache Hive 走向内存计算,性能提升26倍、Apache Hive走向内存计算,性能提升26倍{转}、Apache Ignite 2.9.0 版本发布,内存计算平台的实用信息。
本文目录一览:- iPhone / iPad IOS App仪器内存计数与task_info内存计数(iphone内存计算错误)
- 2013 Stanford公开课 Developing iOS 7 Apps for iPhone and iPad 讲义分享
- Apache Hive 走向内存计算,性能提升26倍
- Apache Hive走向内存计算,性能提升26倍{转}
- Apache Ignite 2.9.0 版本发布,内存计算平台
")
iPhone / iPad IOS App仪器内存计数与task_info内存计数(iphone内存计算错误)
但是,当使用task_info时,它会报告更大的内存量,如10-20 meg.
我想我只想确认task_info正在返回某种总内存,包括堆栈/等,其中泄漏测试仪只报告Malloc / Alloc内存.
另外,为什么在应用程序期间,当泄漏测试仪没有增加那么多时,task_info数量会增加很多….
struct task_basic_info info;
mach_msg_type_number_t size = sizeof(info);
kern_return_t kerr = task_info(mach_task_self(),TASK_BASIC_INFO,(task_info_t)&info,&size);
if( kerr == KERN_SUCCESS ) {
NSLog(@"Memory in use (in bytes): %u",info.resident_size);
} else {
NSLog(@"Error with task_info(): %s",mach_error_string(kerr));
}
解决方法
需要注意的重要一点是,在程序中,进程可用的内存(以任何方式:只读,读/写,可执行或不可执行)和由您分配的内存之间存在概念差异.并非所有可用内存都连接到您所执行的实际分配(例如,共享库),并且您分配的所有内存都不一定驻留在内存中(例如,大型malloc不会立即为您保留物理内存,但只会尽快为您保留物理内存用来).
您可以使用以下方法映射内存(或文件)的匿名区域来测试其影响:
#include <sys/mman.h> // allocate anonymous region of memory (1 mb) char *p = mmap(NULL,1024*1024,PROT_WRITE|PROT_READ,MAP_PRIVATE|MAP_ANON,0); // actually access the memory,or it will not be resident int sum=0; for(int i=0;i<1024*1024;i++ ) sum += p[i];
通过将fd传递给mmap并将MAP_ANON更改为MAP_FILE,可以轻松地将其更改为mmap文件.
此外,据推测,泄漏测试仪从malloc(库)调用向前看直到相应的空闲,而实际的存储器预留仅在低一级进行,例如,使用mmap(系统)调用就像上面那样.

2013 Stanford公开课 Developing iOS 7 Apps for iPhone and iPad 讲义分享
itunes上已经更新了2013年最新的基于iOS7的公开课,依旧是斯坦福的公开课,讲师也依旧是哪位性感小白胡须的小老头。
视频太大啦。家里宽带拙计。建议各位客观去itunes观看吧,itunes的下载速度基本都能达到峰值,因为现在苹果再国内貌似是建立的有数据中心。但是如果很慢的话,建议你配置一下DNS就可以了。 到这里:http://dns.v2ex.com/ 用它的DNS。实测还是速度很好的。
建议再itunes里看还有一个原因就是,带有英文的字幕。基本8090%应该是能看懂的。
我用的上海长城宽带,没有特地配置DNS,速度都是峰值。还不错。
讲义下载地址:
http://pan.baidu.com/s/1zit3q

Apache Hive 走向内存计算,性能提升26倍
Apache Hive 2.1已于几个月前发布,它引入了内存计算,这使得Hive计算性能得到极大提升,这将会影响SQL On Hadoop目前的竞争局面。据测试,其性能提高约26倍。
Apache Hive 2.1新引入了6大性能,包括:
(1)LLAP。Apache Hive 2.0引入了LLAP(Live Long And Process),而2.1则对其进行了极大的优化,相比于Apache Hive 1,其性能提升约25倍;
(2)更鲁邦的SQL ACID支持;
(3)2X ETL性能提升。引入更智能的CBO(Cost Based Optimizer),更快的类型转换以及动态分区优化;
(4)支持存储过程。加大简化了从EDW迁移到Hive的流程。这是通过开源项目HPL/SQL(Apache开源协议,http://www.hplsql.org/)实现的,HPL/SQL的目的是为Apache Hive,SparkSQL, Impala 以及其他SQL-on-Hadoop 实现, 任何 NoSQL和 RDBMS增加存储过程的实现;
(5)对文本格式数据增加向量化计算的支持;
(6)引入新的诊断和监控工具,包括新的HiveServer2 UI,LLAPUI和改进的Tez UI。
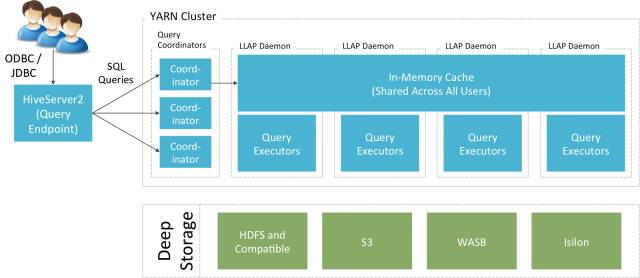
接下来详细介绍对Apache Hive 2.1性能提升至关重要的优化:LLAP。LLAP是“Live Long and Process”的简写,它引入了分布式持久化查询服务,并结合经优化的数据缓存机制,可快速启动查询计算作业并避免无需的磁盘IO操作。简而言之,LLAP是下一代分布式计算架构,它能够智能地将数据缓存到多台机器内存中,并允许所有客户端共享这些缓存的数据,同时保留了弹性伸缩能力。
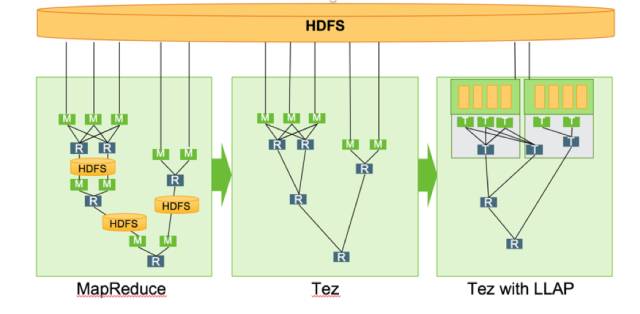
相比于Hive 1 + Tez,Hive2+ Tez+LLAP性能提升约26倍,测试结果如下图所示(测试结果是通过https://github.com/hortonworks/hive-testbench得到的):
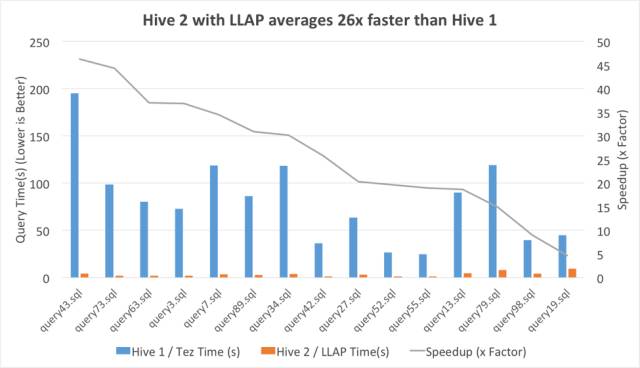
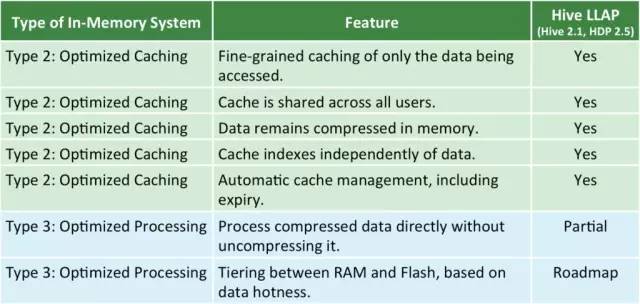
Hive2 LLAP的引入,标志着Apache Hive进入内存计算时代。总结起来,内存计算类型可分为以下三类:
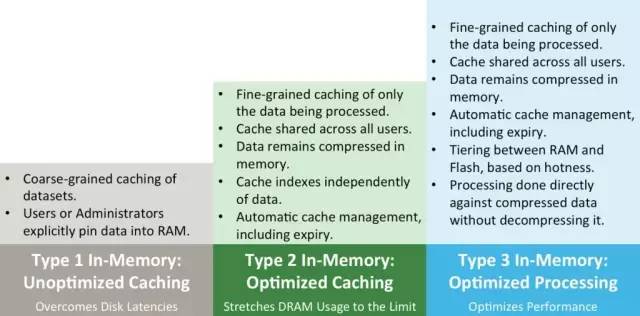
其中,Type1已被Apache hadoop生态系统证明其性能不会太高,因而Hive直接进入Type2,目前对Type2中所有特性均支持地很好,包括分布式内存管理和优化,内存数据共享等。此外,Apache Hive正进一步优化性能,包括支持新型存储介质Flash,扩展LLAP能力,使其可以直接处理压缩数据而无需事先解压。
稿源:hadoop123

Apache Hive走向内存计算,性能提升26倍{转}
Apache Hive 2.1已于几个月前发布,它引入了内存计算,这使得Hive计算性能得到极大提升,这将会影响SQL On Hadoop目前的竞争局面。据测试,其性能提高约26倍。
Apache Hive 2.1新引入了6大性能,包括:
(1)LLAP。Apache Hive 2.0引入了LLAP(Live Long And Process),而2.1则对其进行了极大的优化,相比于Apache Hive 1,其性能提升约25倍;
(2)更鲁邦的SQL ACID支持;
(3)2X ETL性能提升。引入更智能的CBO(Cost Based Optimizer),更快的类型转换以及动态分区优化;
(4)支持存储过程。加大简化了从EDW迁移到Hive的流程。这是通过开源项目HPL/SQL(Apache开源协议,http://www.hplsql.org/)实现的,HPL/SQL的目的是为Apache Hive,SparkSQL, Impala 以及其他SQL-on-Hadoop 实现, 任何 NoSQL和 RDBMS增加存储过程的实现;
(5)对文本格式数据增加向量化计算的支持;
(6)引入新的诊断和监控工具,包括新的HiveServer2 UI,LLAPUI和改进的Tez UI。
接下来详细介绍对Apache Hive 2.1性能提升至关重要的优化:LLAP。LLAP是“Live Long and Process”的简写,它引入了分布式持久化查询服务,并结合经优化的数据缓存机制,可快速启动查询计算作业并避免无需的磁盘IO操作。简而言之,LLAP是下一代分布式计算架构,它能够智能地将数据缓存到多台机器内存中,并允许所有客户端共享这些缓存的数据,同时保留了弹性伸缩能力。
![]()
相比于Hive 1 + Tez,Hive2+ Tez+LLAP性能提升约26倍,测试结果如下图所示(测试结果是通过https://github.com/hortonworks/hive-testbench得到的):
![]()
Hive2 LLAP的引入,标志着Apache Hive进入内存计算时代。总结起来,内存计算类型可分为以下三类:
其中,Type1已被Apache hadoop生态系统证明其性能不会太高,因而Hive直接进入Type2,目前对Type2中所有特性均支持地很好,包括分布式内存管理和优化,内存数据共享等。此外,Apache Hive正进一步优化性能,包括支持新型存储介质Flash,扩展LLAP能力,使其可以直接处理压缩数据而无需事先解压。
参考资料:
http://hortonworks.com/blog/announcing-apache-hive-2-1-25x-faster-queries-much/
http://hortonworks.com/blog/apache-hive-going-memory-computing/

Apache Ignite 2.9.0 版本发布,内存计算平台
Apache Ignite 2.9 版本更新说明如下:
Ignite 核心
* 持久化缓存新增集群快照功能;
* 事务、发现、交换和通信组件支持跟踪;
* 新增集群只读状态:在这个状态中缓存只允许进行读操作,对缓存进行数据修改(更新、删除、清理、创建、销毁等)都是不允许的;
* 透明数据加密新增主键旋转功能;
* 新增在沙箱中运行用户代码的功能;
* 新增集群ID和标签属性,用于标示集群;
* 原生客户端新增与服务端的单向连接支持;
* 对于原生客户端的接入连接,新增不开启服务端套接字的功能;
* 新增管理API,用于取消用户提供的任务和查询;
* 新增分区状态和空闲列表系统视图;
* 新增txKeyCollisions缓存指标;
* 缓存指标新增OffHeapEntriesCount、OffHeapBackupEntriesCount、OffHeapPrimaryEntriesCount、HeapEntriesCount、CacheSize;
* 新增查询线程池饥饿监控;
* HTTP-REST接口新增支持写入非基本数据类型的功能;
* 缓存级支持使用CACHE_CREATE和CACHE_DESTROY权限;
* 新增限制访问Ignite的内部包的能力;
* 新增集群组的节点缓存;
* 新增当将无序集合传入类putAll批量操作时的死锁警告;
* 瘦客户端连接新增配置自定义属性的功能;
* 针对集群状态变更新增一个新的开放API(激活/冻结等);
* 新增EVT_BASELINE_...、EVT_CLUSTER_STATE_CHANGE_STARTED、EVT_PAGE_REPLACEMENT_STARTED事件;
* 日志、异常和工具输出新增隐藏敏感数据的功能(配置IGNITE_TO_STRING_INCLUDE_SENSITIVE系统属性);
* 新增在运行时调整长期运行操作超时的功能;
* 新增用于创建和重建索引的专用线程池;
* 新增将客户端SSL证书传递给安全插件的功能(针对客户端:JDBC Thin模式、瘦客户端、原生客户端、REST);
* Apache Ignite新增精简二进制包,只包含必要的模块;
* JDBC CacheStore新增配置fetchSize属性的功能;
* 新增支持使用AWS ALB的节点发现;
* AWS模块的Bouncy Castle依赖更新至1.60版本;
* 修正了远程过滤器和监听器的安全上下文传播(面向持续查询、IgniteMessaging和IgniteEvents);
* 修正了开启持续查询DEBUG日志时的ConcurrentModificationException;
* 修正了瘦客户端服务端线程的严重错误处理;
* 修正了持续查询处理器的内存泄露问题;
* 修正了数据流线程池MXBean(从ThreadPoolMXBean到StripedExecutorMXBean);
* 修正了MVCC处理器的内存泄露问题;
* 修正了同一个缓存的并发removeAll()操作的死锁问题;
* 修正了诊断交换日志消息的敏感用户数据泄露问题;
* 修正了索引删除期间的检查点阻塞问题;
* 修正了LOG-ONLY/FSYNC模式和空的刷新指针时的WAL刷新问题;
* 修正了Ignite线程的线程组,不再使用专用线程组;
* 修正了创建二进制对象的字符串表示时的异常问题;
* 修正了基于ZooKeeper的集群发现中潜在的分区映射交换故障问题;
* 修正了检查点线程的空指针问题;
* 修正了开启通读时乐观序列化事务失败的问题;
* 修正了事件驱动服务处理时的服务部署问题;
* 修正了协调器收集缓存配置时的不正确问题;
* 修正了当DistributedProcess无法向协调器发送单个消息时的节点故障问题;
* 调整了二进制元数据的文件夹,目前移动到了PDS存储文件夹;
* 修正了EVT_CACHE_STOPPED事件的本地监听器问题;
* 修正了TcpDiscoverySpi的故障检测超时处理,如果一个节点无法发送消息或者ping,那么现在在超时时间范围内将严格断开当前连接并以更快的速度创建新的连接;
* 修正了可以将WAL段数量配置为小于2的功能;
* 修正了拓扑更新和持续查询注册期间的死锁问题;
* 修正了客户端重连后缓存操作可能的空指针问题;
* 修正了当包名以`class`开始时的类加载异常;
* 修正了客户端节点中缓存组指标的ClassCastException异常问题;
* 修正了当IgniteLock在使用前就删除时的空指针问题;
* 修正了TcpDiscoverySpi的连接恢复超时处理,如果节点失去了连接, 那么将严格地通过一个新的连接接入集群;
* 修正了扫描查询转换器类的P2P部署问题;
* 修正了推送指标导出器初始化过程中的异常问题;
* 修正了在非激活的集群中从MBean中获取缓存大小时的AssertionError错误;
* 修正了启动脚本中的JVM参数,用以支持在Java11及以后的版本中支持CPU负载指标;
* 修正了损坏的Redis mget命令;
* 改进了拓扑变更是的事务恢复机制;
* 改进了检查点逻辑,首先写入检查点缓冲区页面以避免限流;
* 通过并行执行分区状态恢复阶段改进了节点恢复时间;
* 改进了节点启动和周期性指标日志;
* 改进了再平衡调度(首先进行SYNC模式缓存再平衡);
* 改进了节点主机地址解析(当将IP配置为localhost时不再尝试解析主机名);
* 改进了数据丢失处理;
* 大量的稳定性和性能改进;
* 在Docker环境中将ignite.sh调用改为直接JVM调用;
* 废弃了IGFS和Hadoop加速器组件。
SQL
* 可以在已有的缓存上创建表;
* 新增指标:sql.parser.cache.hits - 查询缓存的命中数, sql.parser.cache.misses - 查询缓存的未命中数
* 新增SQL查询的成功数和失败数指标;
* 通过@QuerySqlEntity注解新增字段名唯一性验证,之前缓存可以启动没有错误,但是字段无法查询;
* 新增了一个选项,用于在键值插入时根据SQL模式验证字段类型;
* 新增了单独的SQL配置;
* 修正了SQL模式名验证(模式名不能为空);
* 修正了通过"create table"语句的重复列名定义;
* 修正了SQL通配符到Java正则表达式的转换;
* 修正了自定义GROUP_CONCAT的分隔符支持;
* 修正了获取索引重建状态时的数据争用;
* 修正了主键字段非空约束的不正确检查;
* 修正了在数据类型无效的字段上创建索引时的节点故障问题;
* 修正了QuerySqlField注解的"name"属性验证;
* 修正了不正确的索引使用,主键索引创建时没有与字段枚举一起使用;
* 修正了用无效字段顺序创建主键时出现的问题;
* 改进了行计数统计计算(索引扫描替换为缓存localSize);
* 改进了JavaObject的索引,现在只存储散列字节,这减少了索引的大小并减少了对象比较的时间。
Ignite .Net
* 新增了IgniteLock;
* 新增了ICache.EnableStatistics、ICluster.EnableStatistics;
* 新增了原生的平台缓存;
* 新增了使用平台缓存执行本地ScanQuery分区的功能;
* 新增了从Java端调用.NET服务的能力;
* FieldsQueryCursor新增了获取元数据的功能;
* 新增了基于分区的AffinityCall和AffinityRun,修正了已有的AffinityCall和AffinityRun以保留分区;
* ContinuousQuery.InitialQuery新增了对SqlFieldsQuery的支持;
* 修正了查询游标的线程安全性;
* 修正了在Linux上的Mono中启动Ignite的问题;
* 修正了带有自定义类型数组参数的服务方法的搜索;
* 修正了从.NET端调用带有自定义类型数组参数的服务方法的内存溢出异常问题;
* 修正了只读缓存操作的TransactionScope行为;
* 修正了客户端重连后的本地节点信息过时问题。
Ignite C++
* 新增了CMake构建支持;
* 修正了boost版本大于1.70时的兼容性问题;
* Removed autotools build support
JDBC
* 支持连接的故障转移;
* 新增了`connectionTimeout`和`queryTimout`属性;
* 新增了SSL CipherSuites支持;
* 新增了最优映射模式下的单独重连的支持;
* 新增了控制关联缓存大小的功能;
* 新增了对自定义Java对象的支持;
* 修正了当缓存没有显式配置查询实体时通过JDBC连接获取元数据错误的问题;
Java 瘦客户端
* 新增了集群API支持;
* 新增了集群组API支持;
* 新增了对计算的支持;
* 新增了对Ignite服务的支持;
* 修正了对象的Collections/Arrays解组后的大小开销;
* 修正了开启CompactFooter后嵌套对象的二进制类型模式注册的问题。
.Net瘦客户端
* 新增了集群API支持;
* 新增了集群组API支持;
* 新增了对计算的支持;
* 新增了对服务端节点自动发现的支持;
Python 瘦客户端
* 新增了指定keyfile密码的功能;
* 修正了当字段数大于10时查询字段顺序错误的问题;
控制工具
* control.sh命令行工具新增了命令用于管理集群的二进制元数据;
* 新增了命令用于查看和变更集群的ID和标签;
* `deactivate`和`set-state`命令新增了`--force`标志;
* `validate_indexes`命令新增了`--check-crc`标志;
* 新增了`--verbose`选项,用于输出堆栈跟踪错误;
* `validate_indexes`命令新增了`--check-sizes`选项,用于检查索引和缓存大小是否一致;
* 新增了`--cache check_index_inline_sizes`命令,用于检查集群所有节点的索引内联值是否一致;
* 修正了keystore和truststore要求2次密码的问题;
* 修正了损坏索引监测功能;
* 修正了各种错误之后的GridClient实例泄漏问题。
Spring Data集成
* 新增了同一JVM下的多Ignite实例支持(@RepositoryConfig);
* 在@Query注解中新增了查询调整参数支持;
* 新增了投影的支持;
* 新增了Page和Stream的响应支持;
* 新增了SQL字段查询结果集转换到领域实体的支持;
* 新增了对SQL查询命名参数`:myParam`的支持(通过@Param("myParam")声明);
* SQL查询新增了高级参数绑定和SpEL表达式支持;
* 文本查询(TextQuery)新增了对SpEL表达式的支持;
* 修正了spring-data中的findAllById(ids)和deleteAllById(ids)方法对于不可比较主键的不正确处理;
* 修正了通过spring-data执行查询时RunningQueryManager的游标泄漏问题。
Web控制台
* 移动到了单独的仓库。
今天关于iPhone / iPad IOS App仪器内存计数与task_info内存计数和iphone内存计算错误的讲解已经结束,谢谢您的阅读,如果想了解更多关于2013 Stanford公开课 Developing iOS 7 Apps for iPhone and iPad 讲义分享、Apache Hive 走向内存计算,性能提升26倍、Apache Hive走向内存计算,性能提升26倍{转}、Apache Ignite 2.9.0 版本发布,内存计算平台的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

