以上就是给各位分享使用双线性插值旋转图像-仿射变换Python,其中也会对双线性插值实现图像旋转进行解释,同时本文还将给你拓展10、图像的几何变换——平移、镜像、缩放、旋转、仿射变换、CMake不断从
以上就是给各位分享使用双线性插值旋转图像 - 仿射变换 Python,其中也会对双线性插值实现图像旋转进行解释,同时本文还将给你拓展10、图像的几何变换——平移、镜像、缩放、旋转、仿射变换、CMake 不断从 cygwin python 中获取 Python,如何从 Windows 安装的 Python 中获取、Core Python | 2 - Core Python: Getting Started | 2.5 - Modularity | 2.5.5 - The Python Execution Mod、c语言数字图像处理(三):仿射变换等相关知识,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:- 使用双线性插值旋转图像 - 仿射变换 Python(双线性插值实现图像旋转)
- 10、图像的几何变换——平移、镜像、缩放、旋转、仿射变换
- CMake 不断从 cygwin python 中获取 Python,如何从 Windows 安装的 Python 中获取
- Core Python | 2 - Core Python: Getting Started | 2.5 - Modularity | 2.5.5 - The Python Execution Mod
- c语言数字图像处理(三):仿射变换
")
使用双线性插值旋转图像 - 仿射变换 Python(双线性插值实现图像旋转)
如何解决使用双线性插值旋转图像 - 仿射变换 Python
到目前为止,我已经实现了自己的代码来执行给定图像的旋转,但使用整数来舍入像素,我想实现双线性插值来完成这项工作,但我不确定如何,这是我的函数,它接收源图像和 2drotation 矩阵。
import numpy as np
import cv2
def rotation(img,rot_matrix):
h,w = img.shape
rot_img= np.zeros((h,w,3),dtype=np.uint8)
for i in range(w):
for j in range(h):
x = i*rot_matrix[0,0]+j*rot_matrix[0,1]+rot_matrix[0,2]
y = i*rot_matrix[1,0]+j*rot_matrix[1,1]+rot_matrix[1,2]
# i would like tu use bilinear intp here
x = int(x)
y = int(y)
if 0 < x < w and 0 < y < h:
n_coord = img[y,x]
rot_img[j,i] = n_coord
return rot_img
img = cv2.imread(''cran.jpg'',0)
w,h = img.shape
center = (w // 2,h // 2)
angle = 30
scale = 1
M = cv2.getRotationMatrix2D(center,angle,scale)
f = rotation(img,M)
cv2.imshow('''',f)
cv2.waitKey(0)
图片 https://i.ibb.co/bL9wPjv/cran.jpg

10、图像的几何变换——平移、镜像、缩放、旋转、仿射变换
1.几何变换的基本概念
图像几何变换又称为图像空间变换,它将一副图像中的坐标位置映射到另一幅图像中的新坐标位置。我们学习几何变换就是确定这种空间映射关系,以及映射过程中的变化参数。图像的几何变换改变了像素的空间位置,建立一种原图像像素与变换后图像像素之间的映射关系,通过这种映射关系能够实现下面两种计算:
- 原图像任意像素计算该像素在变换后图像的坐标位置
- 变换后图像的任意像素在原图像的坐标位置
对于第一种计算,只要给出原图像上的任意像素坐标,都能通过对应的映射关系获得到该像素在变换后图像的坐标位置。将这种输入图像坐标映射到输出的过程称为“向前映射”。反过来,知道任意变换后图像上的像素坐标,计算其在原图像的像素坐标,将输出图像映射到输入的过程称为“向后映射”。但是,在使用向前映射处理几何变换时却有一些不足,通常会产生两个问题:映射不完全,映射重叠
- 映射不完全
输入图像的像素总数小于输出图像,这样输出图像中的一些像素找不到在原图像中的映射。
上图只有(0,0),(0,2),(2,0),(2,2)四个坐标根据映射关系在原图像中找到了相对应的像素,其余的12个坐标没有有效值。 - 映射重叠
根据映射关系,输入图像的多个像素映射到输出图像的同一个像素上。
上图左上角的四个像素(0,0),(0,1),(1,0),(1,1)都会映射到输出图像的(0,0)上,那么(0,0)究竟取那个像素值呢?
要解决上述两个问题可以使用“向后映射”,使用输出图像的坐标反过来推算改坐标对应于原图像中的坐标位置。这样,输出图像的每个像素都可以通过映射关系在原图像找到唯一对应的像素,而不会出现映射不完全和映射重叠。所以,一般使用向后映射来处理图像的几何变换。从上面也可以看出,向前映射之所以会出现问题,主要是由于图像像素的总数发生了变化,也就是图像的大小改变了。在一些图像大小不会发生变化的变换中,向前映射还是很有效的。
2.图像平移
图像的平移变换就是将图像所有的像素坐标分别加上指定的水平偏移量和垂直偏移量。平移变换根据是否改变图像大小分为两种,直接丢弃或者通过加目标图像尺寸的方法使图像能够包含这些点。
2.1平移变换原理
假设原来的像素的位置坐标为(x0,y0),经过平移量(△x,△y)后,坐标变为(x1,y1),如下所示:
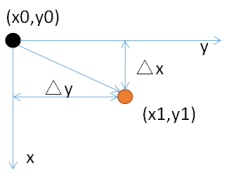
用数学式子表示可以表示为:
x1 = x0 + △x,
y1 = y0 + △y;
用矩阵表示为:
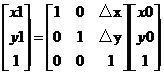
本来使用二维矩阵就可以了的,但是为了适应像素、拓展适应性,这里使用三维的向量。
式子中,矩阵:
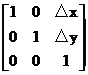
称为平移变换矩阵(因子),△x和△y为平移量。
2.2 基于OpenCV的实现
图像的平移变换实现还是很简单的,这里不再赘述.
平移后图像的大小不变

void GeometricTrans::translateTransform(cv::Mat const& src, cv::Mat& dst, int dx, int dy)
{
CV_Assert(src.depth() == CV_8U);
const int rows = src.rows;
const int cols = src.cols;
dst.create(rows, cols, src.type());
Vec3b *p;
for (int i = 0; i < rows; i++)
{
p = dst.ptr<Vec3b>(i);
for (int j = 0; j < cols; j++)
{
//平移后坐标映射到原图像
int x = j - dx;
int y = i - dy;
//保证映射后的坐标在原图像范围内
if (x >= 0 && y >= 0 && x < cols && y < rows)
p[j] = src.ptr<Vec3b>(y)[x];
}
}
}
平移后图像的大小变化

void GeometricTrans::translateTransformSize(cv::Mat const& src, cv::Mat& dst, int dx, int dy)
{
CV_Assert(src.depth() == CV_8U);
const int rows = src.rows + abs(dy); //输出图像的大小
const int cols = src.cols + abs(dx);
dst.create(rows, cols, src.type());
Vec3b *p;
for (int i = 0; i < rows; i++)
{
p = dst.ptr<Vec3b>(i);
for (int j = 0; j < cols; j++)
{
int x = j - dx;
int y = i - dy;
if (x >= 0 && y >= 0 && x < src.cols && y < src.rows)
p[j] = src.ptr<Vec3b>(y)[x];
}
}
}
ps:这里图像变换的代码以三通道图像为例,单通道的于此类似,代码中没有做处理。
示例:
#include "stdafx.h"
#include <iostream>
#include <opencv2\core\core.hpp>
#include <opencv2\highgui\highgui.hpp>
#include <opencv2\imgproc\imgproc.hpp>
using namespace std;
using namespace cv;
void translateTransform(cv::Mat const& src, cv::Mat& dst, int dx, int dy)//平移后大小不变
{
CV_Assert(src.depth() == CV_8U);
const int rows = src.rows;
const int cols = src.cols;
dst.create(rows, cols, src.type());
Vec3b *p;
for (int i = 0; i < rows; i++)
{
p = dst.ptr<Vec3b>(i);
for (int j = 0; j < cols; j++)
{
//平移后坐标映射到原图像
int x = j - dx;
int y = i - dy;
//保证映射后的坐标在原图像范围内
if (x >= 0 && y >= 0 && x < cols && y < rows)
p[j] = src.ptr<Vec3b>(y)[x];
}
}
}
void translateTransformSize(cv::Mat const& src, cv::Mat& dst, int dx, int dy)//平移后大小变化
{
CV_Assert(src.depth() == CV_8U);
const int rows = src.rows + abs(dy); //输出图像的大小
const int cols = src.cols + abs(dx);
dst.create(rows, cols, src.type());
Vec3b *p;
for (int i = 0; i < rows; i++)
{
p = dst.ptr<Vec3b>(i);
for (int j = 0; j < cols; j++)
{
int x = j - dx;
int y = i - dy;
if (x >= 0 && y >= 0 && x < src.cols && y < src.rows)
p[j] = src.ptr<Vec3b>(y)[x];
}
}
}
int main()
{
Mat srcImage, dstImage0, dstImage1, dstImage2;
int xOffset, yOffset; //x和y方向的平移量
srcImage = imread("111.jpg");
if (!srcImage.data)
{
cout << "读入图片错误!" << endl;
return -1;
}
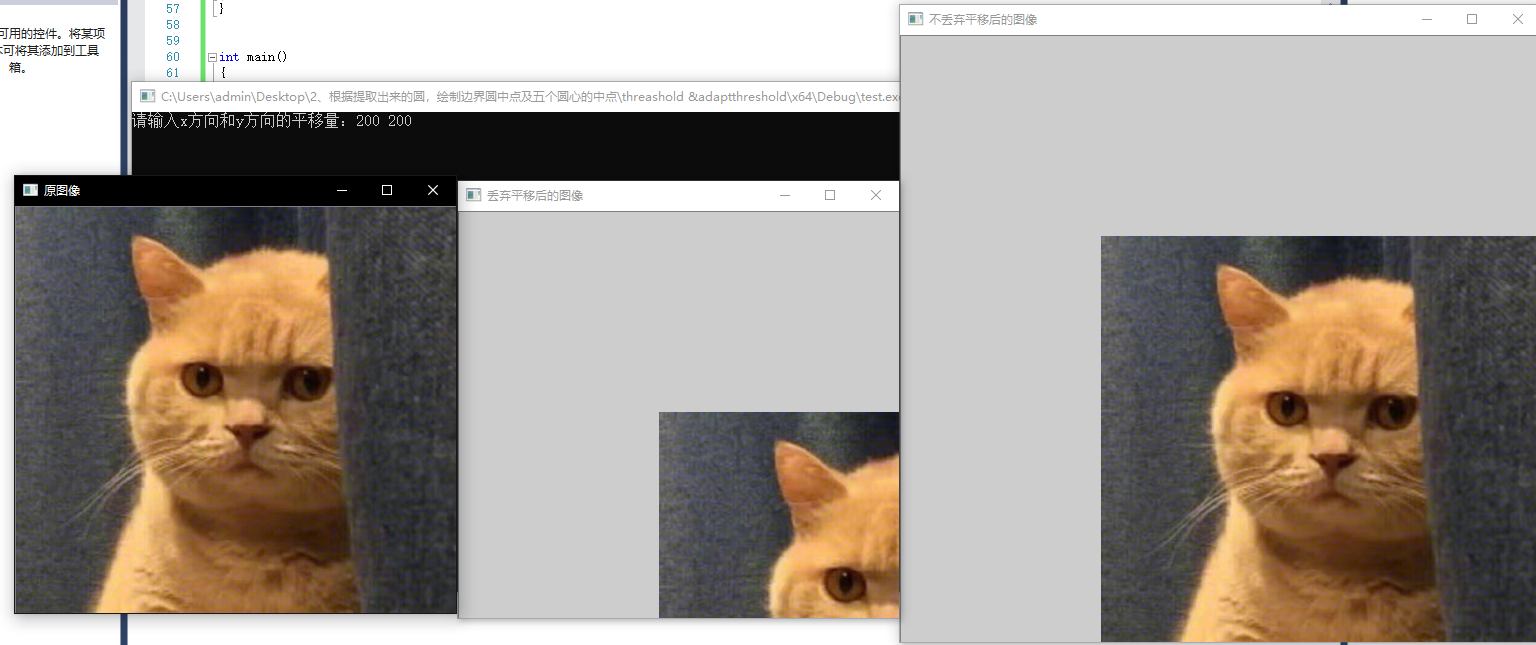
cout << "请输入x方向和y方向的平移量:";
cin >> xOffset >> yOffset;
int rowNumber = srcImage.rows;
int colNumber = srcImage.cols;
translateTransform(srcImage, dstImage0, xOffset, yOffset);
translateTransformSize(srcImage, dstImage1, xOffset, yOffset);
imshow("原图像", srcImage);
imshow("不丢弃平移后的图像", dstImage0);
imshow("丢弃平移后的图像", dstImage1);
waitKey();
return 0;
}在输入框输入200,200后结果为
3.图像的镜像变换
图像的镜像变换分为两种:水平镜像和垂直镜像。水平镜像以图像垂直中线为轴,将图像的像素进行对换,也就是将图像的左半部和右半部对调。垂直镜像则是以图像的水平中线为轴,将图像的上半部分和下班部分对调。
3.1变换原理
- 水平变换
 向前映射
向前映射
其逆变换为  向后映射
向后映射
2.垂直镜像变换 
其逆变换为 
3.2基于OpenCV的实现
水平镜像的实现

void GeometricTrans::hMirrorTrans(const Mat &src, Mat &dst)
{
CV_Assert(src.depth() == CV_8U);
dst.create(src.rows, src.cols, src.type());
int rows = src.rows;
int cols = src.cols;
switch (src.channels())
{
case 1:
const uchar *origal;
uchar *p;
for (int i = 0; i < rows; i++){
origal = src.ptr<uchar>(i);
p = dst.ptr<uchar>(i);
for (int j = 0; j < cols; j++){
p[j] = origal[cols - 1 - j];
}
}
break;
case 3:
const Vec3b *origal3;
Vec3b *p3;
for (int i = 0; i < rows; i++) {
origal3 = src.ptr<Vec3b>(i);
p3 = dst.ptr<Vec3b>(i);
for(int j = 0; j < cols; j++){
p3[j] = origal3[cols - 1 - j];
}
}
break;
default:
break;
}
}
分别对三通道图像和单通道图像做了处理,由于比较类似以后的代码只处理三通道图像,不再做特别说明。
在水平镜像变换时,遍历了整个图像,然后根据映射关系对每个像素都做了处理。实际上,水平镜像变换就是将图像坐标的列换到右边,右边的列换到左边,是可以以列为单位做变换的。同样垂直镜像变换也如此,可以以行为单位进行变换。
垂直镜像变换

void GeometricTrans::vMirrorTrans(const Mat &src, Mat &dst)
{
CV_Assert(src.depth() == CV_8U);
dst.create(src.rows, src.cols, src.type());
int rows = src.rows;
for (int i = 0; i < rows; i++)
src.row(rows - i - 1).copyTo(dst.row(i));
}
上面一行代码是变换的核心代码,从原图像中取出第i行,并将其复制到目标图像。
示例:
#include "stdafx.h"
#include <iostream>
#include <opencv2\core\core.hpp>
#include <opencv2\highgui\highgui.hpp>
#include <opencv2\imgproc\imgproc.hpp>
using namespace std;
using namespace cv;
void hMirrorTrans(const Mat &src, Mat &dst)
{
CV_Assert(src.depth() == CV_8U);
dst.create(src.rows, src.cols, src.type());
int rows = src.rows;
int cols = src.cols;
switch (src.channels())
{
case 1:
const uchar *origal;
uchar *p;
for (int i = 0; i < rows; i++) {
origal = src.ptr<uchar>(i);
p = dst.ptr<uchar>(i);
for (int j = 0; j < cols; j++) {
p[j] = origal[cols - 1 - j];
}
}
break;
case 3:
const Vec3b *origal3;
Vec3b *p3;
for (int i = 0; i < rows; i++) {
origal3 = src.ptr<Vec3b>(i);
p3 = dst.ptr<Vec3b>(i);
for (int j = 0; j < cols; j++) {
p3[j] = origal3[cols - 1 - j];
}
}
break;
default:
break;
}
}
void vMirrorTrans(const Mat &src, Mat &dst)
{
CV_Assert(src.depth() == CV_8U);
dst.create(src.rows, src.cols, src.type());
int rows = src.rows;
for (int i = 0; i < rows; i++)
src.row(rows - i - 1).copyTo(dst.row(i));
}
int main()
{
Mat srcImage, dstImage, dstImage1;;
srcImage = imread("111.jpg");
if (!srcImage.data)
{
cout << "读入图片错误!" << endl;
return -1;
}
hMirrorTrans(srcImage, dstImage);
vMirrorTrans(srcImage, dstImage1);
imshow("原图像", srcImage);
imshow("水平镜像后的图像", dstImage);
imshow("垂直镜像后的图像", dstImage1);
waitKey();
return 0;
}程序运行结果如下:

3.图像缩放
图像的缩放指的是将图像的尺寸变小或变大的过程,也就是减少或增加原图像数据的像素个数。简单来说,就是通过增加或删除像素点来改变图像的尺寸。当图像缩小时,图像会变得更加清晰,当图像放大时,图像的质量会有所下降,因此需要进行插值处理。
3.1 缩放原理
设水平缩放系数为sx,垂直缩放系数为sy,(x0,y0)为缩放前坐标,(x,y)为缩放后坐标,其缩放的坐标映射关系: ![]()
矩阵表示的形式为:
")
这是向前映射,在缩放的过程改变了图像的大小,使用向前映射会出现映射重叠和映射不完全的问题,所以这里更关心的是向后映射,也就是输出图像通过向后映射关系找到其在原图像中对应的像素。
向后映射关系:

3.2基于OpenCV的缩放实现
在用前一篇文章讲到利用resize函数的进行图像的缩放操作,函数的原型为:
resize( InputArray src, OutputArray dst,Size dsize, double fx=0, double fy=0,int interpolation=INTER_LINEAR );这里当然可以用resize进行缩放,但是为了更好的理解缩放原理,这里利用向后映射进行图像缩放,过程为:
首先进行计算新图像的大小,在这里设newWidth和newHeight分别表示新图像的宽度和高度,width和height表示原始图像的宽度和高度,
在图像缩放的时首先需要计算缩放后图像的大小,设newWidth,newHeight为缩放后的图像的宽和高,width,height为原图像的宽度和高度,那么有:

然后再进行枚举新图像每个像素的坐标,通过向后映射计算出该像素映射在原始图像的坐标位置,再进行获取该像素的值。
根据上面公式可知,缩放后图像的宽和高用原图像宽和高和缩放因子相乘即可。
int rows = static_cast<int>(src.rows * xRatio + 0.5);
int cols = static_cast<int>(src.cols * yRatio + 0.5);需要注意的是,在进行后向映射的过程中可能会产生浮点数坐标,但是数字图像是以离散型整数存储数据的,所以无法得到浮点数坐标对应的像素值,这里就需要进行插值算法计算坐标是浮点型的像素值。这里使用最邻近插值和双线性插值来处理。
3.3插值算法
0、什么叫插值
数学的数值分析领域中,内插或称插值(英语:interpolation)是一种通过已知的、离散的数据点,在范围内推求新数据点的过程或方法。
一组离散数据点在一个外延的插值。曲线中实际已知数据点是红色的;连接它们的蓝色曲线即为插值。在一个函数里面,自变量是离散有间隔的,插值就是往自变量的间隔之间插入新的自变量,然后求解新的自变量函数值。
常见的插值算法有最邻近插值法、双线性插值法,双三次插值法等。双三次插值法由于计算量较大,这里不做详细讲解,有兴趣的可以看参考资料中的实现opencv中常用的三种插值算法
1、最邻近插值
最近邻域是三种插值之中最简单的一种,原理就是选取距离插入的像素点(x+u, y+v)【注:x,y为整数, u,v为小数】最近的一个像素点,用它的像素点的灰度值代替插入的像素点。

void nearestIntertoplation(cv::Mat& src, cv::Mat& dst, const int rows, const int cols)
{
//比例尺
const double scale_row = static_cast<double>(src.rows) / rows;
const double scale_col = static_cast<double>(src.rows) / cols;
//扩展src到dst
dst = cv::Mat(rows, cols, src.type());
assert(src.channels() == 1 && dst.channels() == 1);
for (int i = 0; i < rows; ++i)//dst的行
for (int j = 0; j < cols; ++j)//dst的列
{
//求插值的四个点
double y = (i + 0.5) * scale_row + 0.5;
double x = (j + 0.5) * scale_col + 0.5;
int x1 = static_cast<int>(x);//col对应x
if (x1 >= (src.cols - 2)) x1 = src.cols - 2;//防止越界
int x2 = x1 + 1;
int y1 = static_cast<int>(y);//row对应y
if (y1 >= (src.rows - 2)) y1 = src.rows - 2;
int y2 = y1 + 1;
//根据目标图像的像素点(浮点坐标)找到原始图像中的4个像素点,取距离该像素点最近的一个原始像素值作为该点的值。
assert(0 < x2 && x2 < src.cols && 0 < y2 && y2 < src.rows);
std::vector<double> dist(4);
dist[0] = distance(x, y, x1, y1);
dist[1] = distance(x, y, x2, y1);
dist[2] = distance(x, y, x1, y2);
dist[3] = distance(x, y, x2, y2);
int min_val = dist[0];
int min_index = 0;
for (int i = 1; i < dist.size(); ++i)
if (min_val > dist[i])
{
min_val = dist[i];
min_index = i;
}
switch (min_index)
{
case 0:
dst.at<uchar>(i, j) = src.at<uchar>(y1, x1);
break;
case 1:
dst.at<uchar>(i, j) = src.at<uchar>(y1, x2);
break;
case 2:
dst.at<uchar>(i, j) = src.at<uchar>(y2, x1);
break;
case 3:
dst.at<uchar>(i, j) = src.at<uchar>(y2, x2);
break;
default:
assert(false);
}
}
}
double distance(const double x1, const double y1, const double x2, const double y2)//两点之间距离,这里用欧式距离
{
return (x1 - x2)*(x1 - x2) + (y1 - y2)*(y1 - y2);//只需比较大小,返回距离平方即可
}最邻近插值只需要对浮点坐标“四舍五入”运算。但是在四舍五入的时候有可能使得到的结果超过原图像的边界(只会比边界大1),所以要进行下修正。
最邻近插值几乎没有多余的运算,速度相当快。但是这种邻近取值的方法是很粗糙的,会造成图像的马赛克、锯齿等现象。
双线性插值
双线性插值的精度要比最邻近插值好很多,相对的其计算量也要大的多。双线性插值的主要思想是计算出浮点坐标像素近似值。那么要如何计算浮点坐标的近似值呢。一个浮点坐标必定会被四个整数坐标所包围,将这个四个整数坐标的像素值按照一定的比例混合就可以求出浮点坐标的像素值。混合比例为距离浮点坐标的距离。 双线性插值使用浮点坐标周围四个像素的值按照一定的比例混合近似得到浮点坐标的像素值。
首先看看线性插值
下面通过一个例子进行理解:
假设要求坐标为(2.4,3)的像素值P,该点在(2,3)和(3,3)之间,如下图 
u和v分别是距离浮点坐标最近两个整数坐标像素在浮点坐标像素所占的比例
P(2.4,3) = u * P(2,3) + v * P(3,3),混合的比例是以距离为依据的,那么u = 0.4,v = 0.6。
接下来看看二维中的双线性插值
首先在x方向上面线性插值,得到R2、R1
然后以R2,R1在y方向上面再次线性插值
同样,通过一个实例进行理解
进行双线性插值运算 
(2.4,3)的像素值 F1 = m * T1 + (1 – m) * T2
(2.4,4)的像素值 F2 = m * T3 + (1 – m ) * T4
(2.4,3.5)的像素值 F = n * F1 + (1 – n) * F2
这样就可以求得浮点坐标(2.4,3.5)的像素值了。
求浮点坐标像素F,设该浮点坐标周围的4个像素值分别为T1,T2,T3,T4,并且浮点坐标距离其左上角的横坐标的差为m,纵坐标的差为n。 故有
F1 = m * T1 + (1 – m) * T2
F2 = m * T3 + (1 – m) *T4
F = n * F1 + (1 – n) * F2
上面就是双线性插值的基本公式,可以看出,计算每个像素像素值需要进行6次浮点运算。而且,由于浮点坐标有4个坐标近似求得,如果这个四个坐标的像素值差别较大,插值后,会使得图像在颜色分界较为明显的地方变得比较模糊。
OpenCV实现如下:
void bilinearIntertpolatioin(cv::Mat& src, cv::Mat& dst, const int rows, const int cols)
{
//比例尺
const double scale_row = static_cast<double>(src.rows) / rows;
const double scale_col = static_cast<double>(src.rows) / cols;
//扩展src到dst
dst = cv::Mat(rows, cols, src.type());
assert(src.channels() == 1 && dst.channels() == 1);
for(int i = 0; i < rows; ++i)//dst的行
for (int j = 0; j < cols; ++j)//dst的列
{
//求插值的四个点
double y = (i + 0.5) * scale_row + 0.5;
double x = (j + 0.5) * scale_col + 0.5;
int x1 = static_cast<int>(x);//col对应x
if (x1 >= (src.cols - 2)) x1 = src.cols - 2;//防止越界
int x2 = x1 + 1;
int y1 = static_cast<int>(y);//row对应y
if (y1 >= (src.rows - 2)) y1 = src.rows - 2;
int y2 = y1 + 1;
assert(0 < x2 && x2 < src.cols && 0 < y2 && y2 < src.rows);
//插值公式,参考维基百科矩阵相乘的公式https://zh.wikipedia.org/wiki/%E5%8F%8C%E7%BA%BF%E6%80%A7%E6%8F%92%E5%80%BC
cv::Matx12d matx = { x2 - x, x - x1 };
cv::Matx22d matf = { static_cast<double>(src.at<uchar>(y1, x1)), static_cast<double>(src.at<uchar>(y2, x1)),
static_cast<double>(src.at<uchar>(y1, x2)), static_cast<double>(src.at<uchar>(y2, x2)) };
cv::Matx21d maty = {
y2 - y,
y - y1
};
auto val = (matx * matf * maty);
dst.at<uchar>(i, j) = val(0,0);
}
}3.3示例
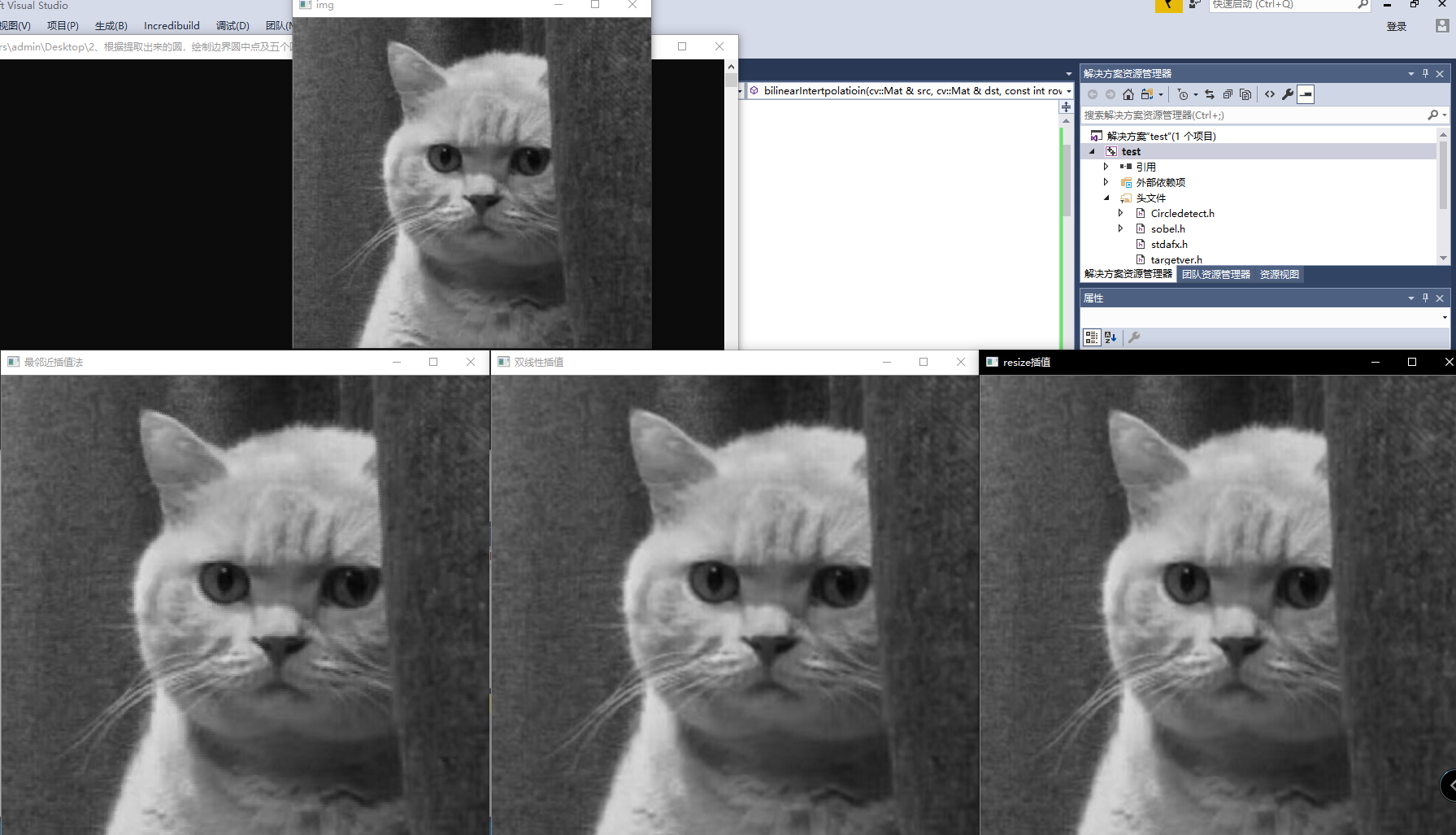
这里用resize、最近邻域插值和双线性插值(这里给出的两种实现都是基于灰度图的)
#include "stdafx.h"
#include<opencv2/opencv.hpp>
#include<opencv2\highgui\highgui.hpp>
#include<cassert>
double distance(const double x1, const double y1, const double x2, const double y2)//两点之间距离,这里用欧式距离
{
return (x1 - x2)*(x1 - x2) + (y1 - y2)*(y1 - y2);//只需比较大小,返回距离平方即可
}
void nearestIntertoplation(cv::Mat& src, cv::Mat& dst, const int rows, const int cols)
{
//比例尺
const double scale_row = static_cast<double>(src.rows) / rows;
const double scale_col = static_cast<double>(src.rows) / cols;
//扩展src到dst
dst = cv::Mat(rows, cols, src.type());
assert(src.channels() == 1 && dst.channels() == 1);
for (int i = 0; i < rows; ++i)//dst的行
for (int j = 0; j < cols; ++j)//dst的列
{
//求插值的四个点
double y = (i + 0.5) * scale_row + 0.5;
double x = (j + 0.5) * scale_col + 0.5;
int x1 = static_cast<int>(x);//col对应x
if (x1 >= (src.cols - 2)) x1 = src.cols - 2;//防止越界
int x2 = x1 + 1;
int y1 = static_cast<int>(y);//row对应y
if (y1 >= (src.rows - 2)) y1 = src.rows - 2;
int y2 = y1 + 1;
//根据目标图像的像素点(浮点坐标)找到原始图像中的4个像素点,取距离该像素点最近的一个原始像素值作为该点的值。
assert(0 < x2 && x2 < src.cols && 0 < y2 && y2 < src.rows);
std::vector<double> dist(4);
dist[0] = distance(x, y, x1, y1);
dist[1] = distance(x, y, x2, y1);
dist[2] = distance(x, y, x1, y2);
dist[3] = distance(x, y, x2, y2);
int min_val = dist[0];
int min_index = 0;
for (int i = 1; i < dist.size(); ++i)
if (min_val > dist[i])
{
min_val = dist[i];
min_index = i;
}
switch (min_index)
{
case 0:
dst.at<uchar>(i, j) = src.at<uchar>(y1, x1);
break;
case 1:
dst.at<uchar>(i, j) = src.at<uchar>(y1, x2);
break;
case 2:
dst.at<uchar>(i, j) = src.at<uchar>(y2, x1);
break;
case 3:
dst.at<uchar>(i, j) = src.at<uchar>(y2, x2);
break;
default:
assert(false);
}
}
}
void bilinearIntertpolatioin(cv::Mat& src, cv::Mat& dst, const int rows, const int cols)
{
//比例尺
const double scale_row = static_cast<double>(src.rows) / rows;
const double scale_col = static_cast<double>(src.rows) / cols;
//扩展src到dst
dst = cv::Mat(rows, cols, src.type());
assert(src.channels() == 1 && dst.channels() == 1);
for (int i = 0; i < rows; ++i)//dst的行
for (int j = 0; j < cols; ++j)//dst的列
{
//求插值的四个点
double y = (i + 0.5) * scale_row + 0.5;
double x = (j + 0.5) * scale_col + 0.5;
int x1 = static_cast<int>(x);//col对应x
if (x1 >= (src.cols - 2)) x1 = src.cols - 2;//防止越界
int x2 = x1 + 1;
int y1 = static_cast<int>(y);//row对应y
if (y1 >= (src.rows - 2)) y1 = src.rows - 2;
int y2 = y1 + 1;
assert(0 < x2 && x2 < src.cols && 0 < y2 && y2 < src.rows);
//插值公式,参考维基百科矩阵相乘的公式https://zh.wikipedia.org/wiki/%E5%8F%8C%E7%BA%BF%E6%80%A7%E6%8F%92%E5%80%BC
cv::Matx12d matx = { x2 - x, x - x1 };
cv::Matx22d matf = { static_cast<double>(src.at<uchar>(y1, x1)), static_cast<double>(src.at<uchar>(y2, x1)),
static_cast<double>(src.at<uchar>(y1, x2)), static_cast<double>(src.at<uchar>(y2, x2)) };
cv::Matx21d maty = {
y2 - y,
y - y1
};
auto val = (matx * matf * maty);
dst.at<uchar>(i, j) = val(0, 0);
}
}
int main()
{
cv::Mat img = cv::imread("111.jpg", 0);
if (img.empty()) return -1;
cv::Mat dst,dst1,dst2;
nearestIntertoplation(img, dst, 600, 600);
bilinearIntertpolatioin(img, dst1, 600, 600);
resize(img, dst2, dst1.size());
cv::imshow("img", img);
cv::imshow("最邻近插值法", dst);
cv::imshow("双线性插值", dst1);
cv::imshow("resize插值", dst2);
cv::waitKey(0);
return 0;
return 0;
}//main
4.图像旋转
4.1旋转原理
图像的旋转就是让图像按照某一点旋转指定的角度。图像旋转后不会变形,但是其垂直对称抽和水平对称轴都会发生改变,旋转后图像的坐标和原图像坐标之间的关系已不能通过简单的加减乘法得到,而需要通过一系列的复杂运算。而且图像在旋转后其宽度和高度都会发生变化,其坐标原点会发生变化。
图像所用的坐标系不是常用的笛卡尔,其左上角是其坐标原点,X轴沿着水平方向向右,Y轴沿着竖直方向向下。而在旋转的过程一般使用旋转中心为坐标原点的笛卡尔坐标系,所以图像旋转的第一步就是坐标系的变换。设旋转中心为(x0,y0),(x’,y’)是旋转后的坐标,(x,y)是旋转后的坐标,则坐标变换如下:

矩阵表示为:

在最终的实现中,常用到的是有缩放后的图像通过映射关系找到其坐标在原图像中的相应位置,这就需要上述映射的逆变换

坐标系变换到以旋转中心为原点后,接下来就要对图像的坐标进行变换。

上图所示,将坐标(x0,y0)顺时针方向旋转a,得到(x1,y1)。
旋转前有:

旋转a后有:

矩阵的表示形式:

其逆变换:

由于在旋转的时候是以旋转中心为坐标原点的,旋转结束后还需要将坐标原点移到图像左上角,也就是还要进行一次变换。这里需要注意的是,旋转中心的坐标(x0,y0)实在以原图像的左上角为坐标原点的坐标系中得到,而在旋转后由于图像的宽和高发生了变化,也就导致了旋转后图像的坐标原点和旋转前的发生了变换。


上边两图,可以清晰的看到,旋转前后图像的左上角,也就是坐标原点发生了变换。
在求图像旋转后左上角的坐标前,先来看看旋转后图像的宽和高。从上图可以看出,旋转后图像的宽和高与原图像的四个角旋转后的位置有关。
设top为旋转后最高点的纵坐标,down为旋转后最低点的纵坐标,left为旋转后最左边点的横坐标,right为旋转后最右边点的横坐标。
旋转后的宽和高为newWidth,newHeight,则可得到下面的关系:

也就很容易的得出旋转后图像左上角坐标(left,top)(以旋转中心为原点的坐标系)
故在旋转完成后要将坐标系转换为以图像的左上角为坐标原点,可由下面变换关系得到:

矩阵表示:

其逆变换:

综合以上,也就是说原图像的像素坐标要经过三次的坐标变换:
- 将坐标原点由图像的左上角变换到旋转中心
- 以旋转中心为原点,图像旋转角度a
- 旋转结束后,将坐标原点变换到旋转后图像的左上角
可以得到下面的旋转公式:(x’,y’)旋转后的坐标,(x,y)原坐标,(x0,y0)旋转中心,a旋转的角度(顺时针)

这种由输入图像通过映射得到输出图像的坐标,是向前映射。常用的向后映射是其逆运算

4.2基于OpenCV的实现
得到了上述的旋转公式,实现起来就不是很困难了.
Mat nearestNeighRotate(cv::Mat img, float angle)
{
int len = (int)(sqrtf(pow(img.rows, 2) + pow(img.cols, 2)) + 0.5);
Mat retMat = Mat::zeros(len, len, CV_8UC3);
float anglePI = angle * CV_PI / 180;
int xSm, ySm;
for (int i = 0; i < retMat.rows; i++)
for (int j = 0; j < retMat.cols; j++)
{
xSm = (int)((i - retMat.rows / 2)*cos(anglePI) - (j - retMat.cols / 2)*sin(anglePI) + 0.5);
ySm = (int)((i - retMat.rows / 2)*sin(anglePI) + (j - retMat.cols / 2)*cos(anglePI) + 0.5);
xSm += img.rows / 2;
ySm += img.cols / 2;
if (xSm >= img.rows || ySm >= img.cols || xSm <= 0 || ySm <= 0) {
retMat.at<Vec3b>(i, j) = Vec3b(0, 0);
}
else {
retMat.at<Vec3b>(i, j) = img.at<Vec3b>(xSm, ySm);
}
}
return retMat;
}示例
#include "stdafx.h"
#include<opencv2/opencv.hpp>
#include<opencv2\highgui\highgui.hpp>
#include<cassert>
using namespace std;
using namespace cv;
Mat nearestNeighRotate(cv::Mat img, float angle)
{
int len = (int)(sqrtf(pow(img.rows, 2) + pow(img.cols, 2)) + 0.5);
Mat retMat = Mat::zeros(len, len, CV_8UC3);
float anglePI = angle * CV_PI / 180;
int xSm, ySm;
for (int i = 0; i < retMat.rows; i++)
for (int j = 0; j < retMat.cols; j++)
{
xSm = (int)((i - retMat.rows / 2)*cos(anglePI) - (j - retMat.cols / 2)*sin(anglePI) + 0.5);
ySm = (int)((i - retMat.rows / 2)*sin(anglePI) + (j - retMat.cols / 2)*cos(anglePI) + 0.5);
xSm += img.rows / 2;
ySm += img.cols / 2;
if (xSm >= img.rows || ySm >= img.cols || xSm <= 0 || ySm <= 0) {
retMat.at<Vec3b>(i, j) = Vec3b(0, 0);
}
else {
retMat.at<Vec3b>(i, j) = img.at<Vec3b>(xSm, ySm);
}
}
return retMat;
}
int main()
{
Mat img = imread("111.jpg");
Mat retImg;
retImg = nearestNeighRotate(img, 45.f);
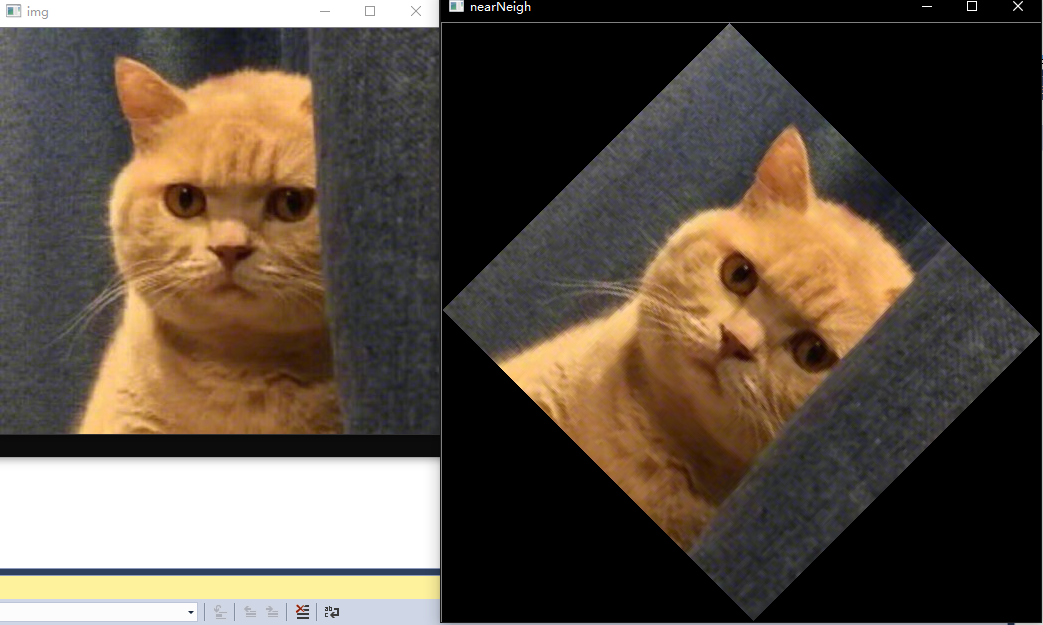
imshow("img", img);
imshow("nearNeigh", retImg);
waitKey();
cvDestroyAllWindows();
return 0;
}运行结果如下:
2.3 仿射变换
我们除了自己写相关函数外,OpenCV还提供了对应的仿射变换的API接口函数warpAffine,仿射变换是指在向量空间中进行一次线性变换(乘以一个矩阵)并加上一个平移(加上一个向量),变换为另一个向量空间的过程。在有限维的情况下,每个仿射变换可以由一个矩阵A和一个向量b给出,它可以写作A和一个附加的列b。一个仿射变换对应于一个矩阵和一个向量的乘法,而仿射变换的复合对应于普通的矩阵乘法,只要加入一个额外的行到矩阵的底下,这一行全部是0除了最右边是一个1,而列向量的底下要加上一个1.
实际上,仿射变换代表的是两幅图之间的关系,我们通常使用2x3矩阵来表示仿射变换如下:
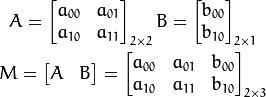
考虑到我们要使用矩阵A和B对二维向量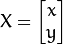 做变换,所以也能表示为下列形式:
做变换,所以也能表示为下列形式:
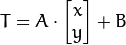 或
或 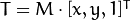
得到如下结果:
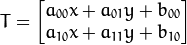
应用图像仿射变换矩阵,可以得到大部分的几何变换结果,例如之前提到的平移变换等,根据平移变换矩阵可以很容易的得到实现平移功能的仿射变换矩阵,如下所示:
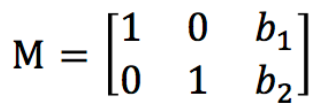
对于图像缩放来说,设水平方向的缩放因子为a,垂直方向缩放因子为b,则用仿射矩阵实现图缩放功能的仿射矩阵为:
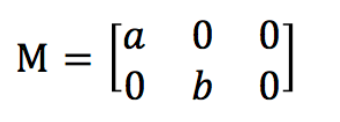
而对于图像旋转来说,设旋转角度为θ,利用仿射变换实现图像旋转操作的仿射矩阵为:
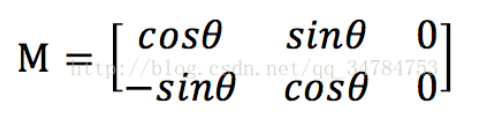
而对于较为特殊的斜切变换,同样的,设斜切的角度为θ,则仿射矩阵为:
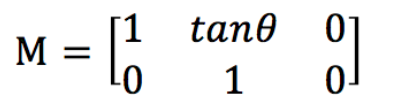
需要注意的是,在OpenCV中使用仿射变换函数时,通常会先计算一个仿射变换矩阵,以此来获得仿射变换矩阵,为了实现这个功能,常常使用getRotationMatrix2D()函数用来计算二维旋转矩阵,这个变换会将旋转中心映射到它自身。这里给出它的函数声明:
Mat getRotationMatrix2D( Point2f center, double angle, double scale ); 这个函数中有三个参数,第一个参数是Point2f类型的center,也就是原图像的旋转中心;第二个参数是double 类型的angle,也就是我们说的旋转角度,值得一提的是,当angle的值为正时,表示的是逆时针旋转,当angle的值为负时,表示的是顺时针旋转。第三个参数scale表示的是缩放系数,在这个函数计算的是下面这个矩阵: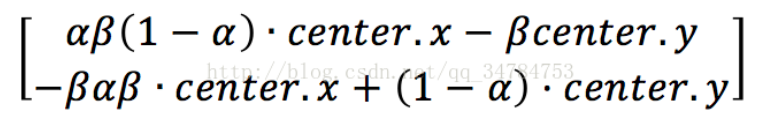
其中
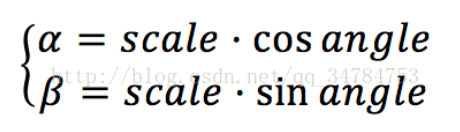
得到仿射变换矩阵后,即可调用仿射函数,仿射映射函数声明为:
void cv::warpAffine (
InputArray src,
OutputArray dst,
InputArray M,
Size dsize,
int flags = INTER_LINEAR,
int borderMode = BORDER_CONSTANT,
const Scalar & borderValue = Scalar()
)参数解释
. src: 输入图像
. dst: 输出图像,尺寸由dsize指定,图像类型与原图像一致
. M: 2X3的变换矩阵
. dsize: 指定图像输出尺寸
. flags: 插值算法标识符,有默认值INTER_LINEAR,如果插值算法为WARP_INVERSE_MAP, warpAffine函数使用如下矩阵进行图像转换
常用的插值算法如下:
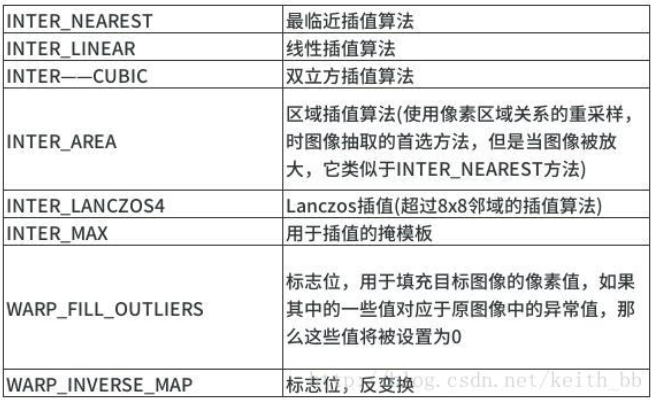
. borderMode: 边界像素模式,有默认值BORDER_CONSTANT
. borderValue: 边界取值,有默认值Scalar()即0
示例:
#include "stdafx.h"
#include<opencv2/opencv.hpp>
#include<opencv2\highgui\highgui.hpp>
#include<cassert>
#include <iostream>
#include <opencv2\core\core.hpp>
#include <opencv2\highgui\highgui.hpp>
#include <opencv2\imgproc\imgproc.hpp>
using namespace std;
using namespace cv;
int main()
{
Mat srcImage, dstImage;
srcImage = imread("111.jpg");
if (!srcImage.data)
{
cout << "读入图片有误!" << endl;
return -1;
}
imshow("原图像", srcImage);
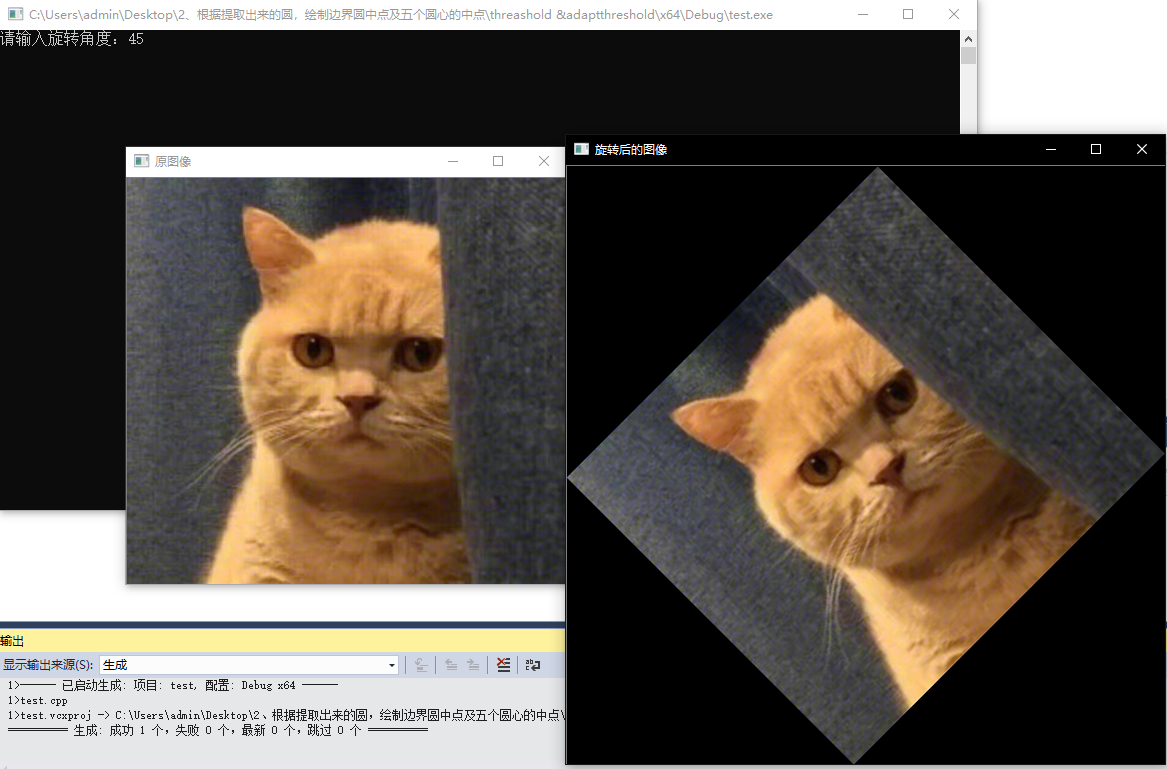
dstImage.create(srcImage.size(), srcImage.type());
double degree;
cout << "请输入旋转角度:";
cin >> degree;
double a = sin(degree * CV_PI / 180);
double b = cos(degree * CV_PI / 180);
int width = srcImage.cols;
int height = srcImage.rows;
int rotate_width = int(height * fabs(a) + width * fabs(b));
int rotate_height = int(width * fabs(a) + height * fabs(b));
Point center = Point(srcImage.cols / 2, srcImage.rows / 2);
Mat map_matrix = getRotationMatrix2D(center, degree, 1.0);
map_matrix.at<double>(0, 2) += (rotate_width - width) / 2; // 修改坐标偏移
map_matrix.at<double>(1, 2) += (rotate_height - height) / 2; // 修改坐标偏移
warpAffine(srcImage, dstImage, map_matrix, { rotate_width, rotate_height }, CV_INTER_CUBIC);
imshow("旋转后的图像", dstImage);
waitKey();
return 0;
} 
至此,图像的几何变换基本就完毕了,这里还是推荐使用OpenCV官方提供的函数API来进行基本的几何变换,但是对于学习来说,知道其原理还是十分重要的,所以这里参考其他人的博客资料集合了一篇完整的解读。希望能够对你有点帮助。
参考资料
数字图像处理与机器视觉Visual C与Matlab实现
几何图像变换
OpenCV2:图像的几何变换,平移、镜像、缩放、旋转(1)
OpenCV2:图像的几何变换,平移、镜像、缩放、旋转(2)
数字图像处理笔记与体会(三)——图像的几何变换
【OpenCV图像处理】四、图像的几何变换(上)
【OpenCV图像处理】五、图像的几何变换(下)
OpenCV中resize函数五种插值算法的实现过程
OpenCV ——双线性插值(Bilinear interpolation)
双线性插值算法进行图像缩放及性能效果优化
双线性插值原理及其实现--基于OpenCV实现
实现opencv中常用的三种插值算法
opencv学习(三十五)之仿射变换warpAffine

CMake 不断从 cygwin python 中获取 Python,如何从 Windows 安装的 Python 中获取
如何解决CMake 不断从 cygwin python 中获取 Python,如何从 Windows 安装的 Python 中获取
我有一个看起来像这样的 CMake 脚本:
find_program(PYTHON_COMMAND NAMES python3 python)
问题是它检测到安装在 Cygwin 安装中的 python。 输出总是:
-- PYTHON_PATH:C:/cygwin64/bin/python3
我希望它取自:
c:\\python36-64\\python
在windows PATH变量中,Cygwin bin在路径的最后一个,windows安装在第一个
但它只检测到 Cygwin python,
怎么改?

Core Python | 2 - Core Python: Getting Started | 2.5 - Modularity | 2.5.5 - The Python Execution Mod
It's important to understand the Python execution model and precisely when function deFinitions and other important events occur when a module is imported or executed. Here, we show execution of our Python module as it's imported in a graphical debugging environment. We step through the top‑level statements in the module. What's important to realize here is that the def used for the fetch_words function isn't merely a declaration. It's actually a statement, which when executed in sequence with the other top‑level model scope code, causes the code within the function to be bound to the name of the function. When modules are imported or run, all of the top‑level statements are run, and this is the means by which the function within the module namespace are defined. We are sometimes asked about the difference between Python modules, Python scripts, and Python programs. Any .py file constitutes a Python module. But as we've seen, modules can be written for convenient import, convenient execution, or using the if dunder name = dunder main idiom, both. We strongly recommend making even simple scripts importable since it eases development and testing so much if you can access your code from within the REPL. Likewise, even modules, which are only ever meant to be imported in production settings, benefit from having executable test code. For this reason, nearly all modules we create have this form of defining one or more importable functions with a postscript to facilitate execution. Whether you consider a module to be a Python script or Python program is a matter of context and usage. It's certainly wrong to consider Python to be merely a scripting tool, in the vein of Windows batch files or UNIX Shell scripts, as many large and complex applications are built exclusively with python.
- def不仅仅是一个declaration声明,更是一条statement语句。它将其中的python代码于函数名绑定在一起
- 一个py文件就是一个模块,这个模块包含类或函数。你写python,要尽量将代码包装成函数和类,方便各种import
- 一个py文件也可看作是一个脚本,在系统命令行中运行
- python不仅仅是脚本语言,很多大型程序都是用python构建的
:仿射变换")
c语言数字图像处理(三):仿射变换
仿射变换及坐标变换公式
几何变换改进图像中像素间的空间关系。这些变换通常称为橡皮模变换,因为它们可看成是在一块橡皮模上印刷一幅图像,然后根据预定的一组规则拉伸该薄膜。在数字图像处理中,几何变换由两个基本操作组成:
(1)坐标的空间变换
(2)灰度内插,即对变换后的像素赋灰度值
坐标变换公式
(x,y) = T{(v, w)}
其中,(v, w)是原图像中像素的坐标,(x, y)是变换后图像中像素的坐标。最常用的空间坐标变换之一是仿射变换
基于上式的仿射变换公式

实际上,我们可以用两种方法来使用上式。第一种方法称为向前映射,它由扫描输入图像的像素,并在每个位置(v, w)用上式直接计算输出图像中相应像素的空间位置(x, y)组成。向前映射算法的一个问题是输入图像中的两个或更多个像素可被变换到输出图像的同一位置,这就产生了如何把多个输出值合并到一个输出像素的问题。第二种方法,反向映射,扫描输出像素的位置,并在每一个位置(x, y)使用(v, w) = T-1(x, y)计算输入图像中的相应位置。然后通过内插决定输出像素的灰度值。本篇文章使用反向映射。
<以上基础知识来源于 《数字图像处理》冈萨雷斯 P50-P51 读者可自行查阅>
在上一篇文章中,主要是图片的放大与缩小,在灰度内插的过程中也涉及到目标图像到原图像的坐标变换,代码如下
1 void bilinera_interpolation(short** in_array, short height, short width,
2 short** out_array, short out_height, short out_width)
3 {
4 double h_times = (double)out_height / (double)height,
5 w_times = (double)out_width / (double)width;
6 short x1, y1, x2, y2, f11, f12, f21, f22;
7 double x, y;
8
9 for (int i = 0; i < out_height; i++){
10 for (int j = 0; j < out_width; j++){
11 x = j / w_times;
12 y = i / h_times;
13 x1 = (short)(x - 1);
14 x2 = (short)(x + 1);
15 y1 = (short)(y + 1);
16 y2 = (short)(y - 1);
17 f11 = is_in_array(x1, y1, height, width) ? in_array[y1][x1] : 0;
18 f12 = is_in_array(x1, y2, height, width) ? in_array[y2][x1] : 0;
19 f21 = is_in_array(x2, y1, height, width) ? in_array[y1][x2] : 0;
20 f22 = is_in_array(x2, y2, height, width) ? in_array[y2][x2] : 0;
21 out_array[i][j] = (short)(((f11 * (x2 - x) * (y2 - y)) +
22 (f21 * (x - x1) * (y2 - y)) +
23 (f12 * (x2 - x) * (y - y1)) +
24 (f22 * (x - x1) * (y - y1))) / ((x2 - x1) * (y2 - y1)));
25 }
26 }
27 }其中,第11,12行为目标图像到原图像的坐标变换,接下来根据仿射变换公式对图像做进一步处理
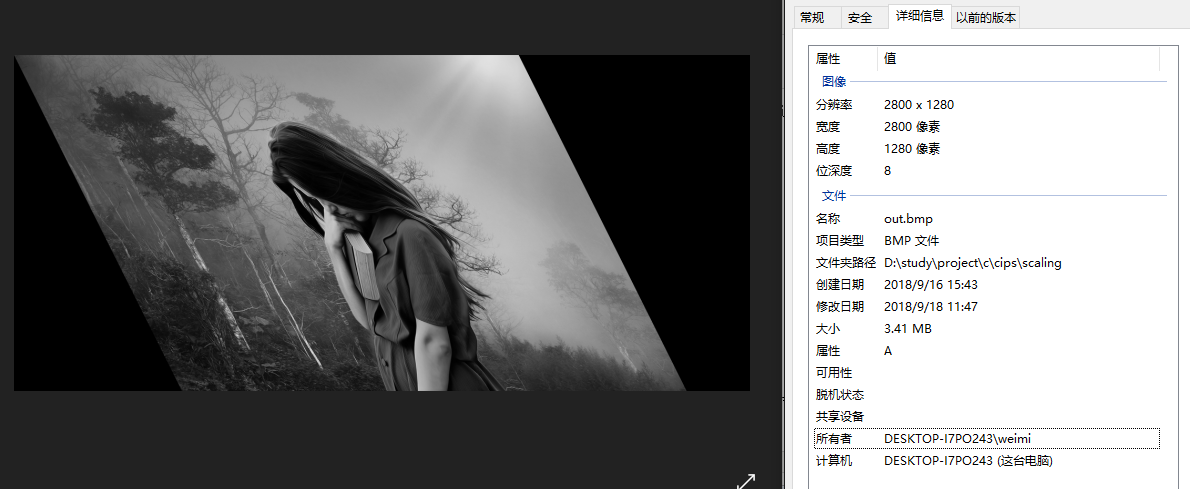
水平偏移变换
水平偏移变换公式为
x = v
y = Sh * v + w
反解上述公式得
v = x
w = y - Sh * v
结果为目标图像到原图像的坐标变换,令Sh = 0.5,并对应用到上述代码11,12行,同时将图像扩大到2800*1280,结果为
旋转变换
旋转变换公式
x = vcosθ - wsinθ
y = vsinθ + wcosθ
令θ = ∏/4,反解得
v = x/√2 + y/√2
w = y/√2 - x/√2
将图像扩大为2000*2000,但是这个时候得到的图像为
为了解决这一问题,使旋转后的图像位于中央,我将所得图片右移m_w, 下移m_h,则公式变为
x = vcosθ - wsinθ + m_w
y = vsinθ + wcosθ + m_h
令θ = ∏/4,反解得
v = (x + y - m_h - m_w)/√2
w = (y - x - m_h + m_w)/√2
结果为

其余变换原理基本相同,因此不再进行演示
今天关于使用双线性插值旋转图像 - 仿射变换 Python和双线性插值实现图像旋转的讲解已经结束,谢谢您的阅读,如果想了解更多关于10、图像的几何变换——平移、镜像、缩放、旋转、仿射变换、CMake 不断从 cygwin python 中获取 Python,如何从 Windows 安装的 Python 中获取、Core Python | 2 - Core Python: Getting Started | 2.5 - Modularity | 2.5.5 - The Python Execution Mod、c语言数字图像处理(三):仿射变换的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

