以上就是给各位分享Python3-编码/解码vs字节/字符串,其中也会对python字符串编码与解码进行解释,同时本文还将给你拓展$("节点名").html("字符串")和$("节点名").text(
以上就是给各位分享Python 3-编码/解码vs字节/字符串,其中也会对python字符串编码与解码进行解释,同时本文还将给你拓展$("节点名").html("字符串")和$("节点名").text("字符串")区别、'{ 文件路径:字符串; webviewPath:字符串; }' 不可分配给“照片”类型的参数、2021-02-21:手写代码:高性能路由,也就是一个字符串和多个匹配串进行模糊匹配。一个数组arr里是[“*a*“,“moonfdd“],字符串“moonfdd“能匹配到,理由是arr里有。字符串“、CS1503 Argument1:无法从“字符串”转换为“字符串[*,*]”等相关知识,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:- Python 3-编码/解码vs字节/字符串(python字符串编码与解码)
- $("节点名").html("字符串")和$("节点名").text("字符串")区别
- '{ 文件路径:字符串; webviewPath:字符串; }' 不可分配给“照片”类型的参数
- 2021-02-21:手写代码:高性能路由,也就是一个字符串和多个匹配串进行模糊匹配。一个数组arr里是[“*a*“,“moonfdd“],字符串“moonfdd“能匹配到,理由是arr里有。字符串“
- CS1503 Argument1:无法从“字符串”转换为“字符串[*,*]”
")
Python 3-编码/解码vs字节/字符串(python字符串编码与解码)
我是python3的新手,来自python2,并且我对unicode基本概念有些困惑。我读了一些不错的文章,使事情变得更加清楚,但是我看到python
3上有2种方法可以处理编码和解码,而且我不确定要使用哪种方法。
因此,Python 3中的想法是,每个字符串都是unicode,并且可以按字节进行编码和存储,或者可以再次解码回unicode字符串。
但是有两种方法可以做到:
u'something'.encode('utf-8')会生成b'bytes',但是会生成bytes(u'something','utf-8')。
并且b'bytes'.decode('utf-8')似乎与做相同的事情str(b'','utf-8')。
现在我的问题是,为什么有2种方法似乎做同样的事情,并且要么比其他方法好(为什么?)?我一直在尝试在google上找到答案,但是没有运气。
>>> original = '27岁少妇生孩子后变老'
>>> type(original)
<class 'str'>
>>> encoded = original.encode('utf-8')
>>> print(encoded)
b'27\xe5\xb2\x81\xe5\xb0\x91\xe5\xa6\x87\xe7\x94\x9f\xe5\xad\xa9\xe5\xad\x90\xe5\x90\x8e\xe5\x8f\x98\xe8\x80\x81'
>>> type(encoded)
<class 'bytes'>
>>> encoded2 = bytes(original,'utf-8')
>>> print(encoded2)
b'27\xe5\xb2\x81\xe5\xb0\x91\xe5\xa6\x87\xe7\x94\x9f\xe5\xad\xa9\xe5\xad\x90\xe5\x90\x8e\xe5\x8f\x98\xe8\x80\x81'
>>> type(encoded2)
<class 'bytes'>
>>> print(encoded+encoded2)
b'27\xe5\xb2\x81\xe5\xb0\x91\xe5\xa6\x87\xe7\x94\x9f\xe5\xad\xa9\xe5\xad\x90\xe5\x90\x8e\xe5\x8f\x98\xe8\x80\x8127\xe5\xb2\x81\xe5\xb0\x91\xe5\xa6\x87\xe7\x94\x9f\xe5\xad\xa9\xe5\xad\x90\xe5\x90\x8e\xe5\x8f\x98\xe8\x80\x81'
>>> decoded = encoded.decode('utf-8')
>>> print(decoded)
27岁少妇生孩子后变老
>>> decoded2 = str(encoded2,'utf-8')
>>> print(decoded2)
27岁少妇生孩子后变老
>>> type(decoded)
<class 'str'>
>>> type(decoded2)
<class 'str'>
>>> print(str(b'27\xe5\xb2\x81\xe5\xb0\x91\xe5\xa6\x87\xe7\x94\x9f\xe5\xad\xa9\xe5\xad\x90\xe5\x90\x8e\xe5\x8f\x98\xe8\x80\x81','utf-8'))
27岁少妇生孩子后变老
>>> print(b'27\xe5\xb2\x81\xe5\xb0\x91\xe5\xa6\x87\xe7\x94\x9f\xe5\xad\xa9\xe5\xad\x90\xe5\x90\x8e\xe5\x8f\x98\xe8\x80\x81'.decode('utf-8'))
27岁少妇生孩子后变老

$("节点名").html("字符串")和$("节点名").text("字符串")区别
1. 经过html方法:
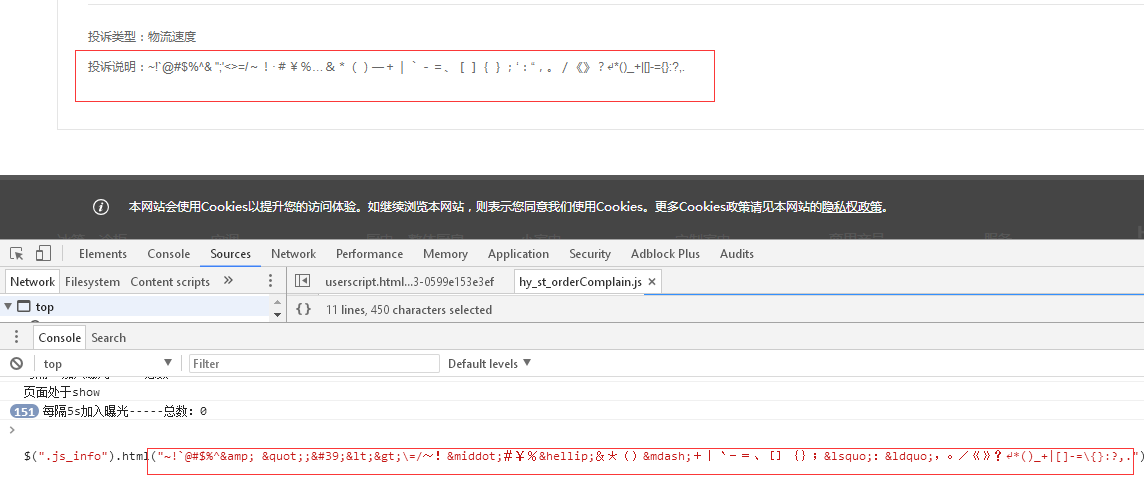
$(".js_info").html("~!`@#$%^& ";'<>\=/~!·#¥%…&*()—+|`-=、[]{};‘:“,。/《》?↵*()_+|[]-=\{}:?,.")
后台返回的字符串:~!`@#$%^& ";'<>\=/~!·#¥%…&*()—+|`-=、[]{};‘:“,。/《》?↵*()_+|[]-=\{}:?,."经过html方法,将进行转义的标签进行反转义成标签显示
1. 经过text方法:
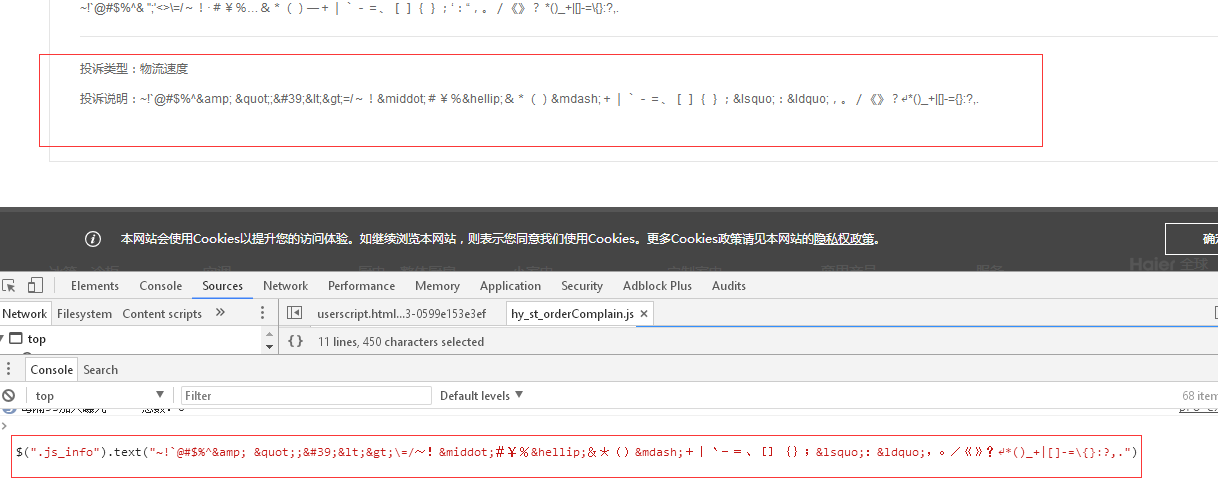
$(".js_info").text("~!`@#$%^& ";'<>\=/~!·#¥%…&*()—+|`-=、[]{};‘:“,。/《》?↵*()_+|[]-=\{}:?,.")
后台返回的字符串:~!`@#$%^& ";'<>\=/~!·#¥%…&*()—+|`-=、[]{};‘:“,。/《》?↵*()_+|[]-=\{}:?,."经过text方法,将按照返回字符串输出不进行转义

'{ 文件路径:字符串; webviewPath:字符串; }' 不可分配给“照片”类型的参数
如何解决''{ 文件路径:字符串; webviewPath:字符串; }'' 不可分配给“照片”类型的参数
所以我正在尝试为 ionic 构建照片库示例项目,但我坚持这个错误。 不知道我的意思是什么。 我尝试降级 npm 包。没用。 所有其他问题都让我更加困惑,哈哈,所以这里是完整的错误:
错误 TS2345:''{ 文件路径:字符串; webviewPath:字符串; }'' 不可分配给“照片”类型的参数。 [ng] 对象字面量只能指定已知属性,而“照片”类型中不存在“文件路径”。
![2021-02-21:手写代码:高性能路由,也就是一个字符串和多个匹配串进行模糊匹配。一个数组arr里是[“*a*“,“moonfdd“],字符串“moonfdd“能匹配到,理由是arr里有。字符串“](http://www.gvkun.com/zb_users/upload/2025/04/4a60b6bd-6274-49af-b458-0dcb9f6ed49a1745466399089.jpg "2021-02-21:手写代码:高性能路由,也就是一个字符串和多个匹配串进行模糊匹配。一个数组arr里是[“*a*“,“moonfdd“],字符串“moonfdd“能匹配到,理由是arr里有。字符串“")
2021-02-21:手写代码:高性能路由,也就是一个字符串和多个匹配串进行模糊匹配。一个数组arr里是[“*a*“,“moonfdd“],字符串“moonfdd“能匹配到,理由是arr里有。字符串“
2021-02-21:手写代码:高性能路由,也就是一个字符串和多个匹配串进行模糊匹配。一个数组arr里是[“a”,“moonfdd”],字符串"moonfdd"能匹配到,理由是arr里有。字符串"xayy"也能匹配到,理由是arr里的"a",第1个星对应"x",第2个星对应"yy"。
福哥答案2021-02-21:
1.前缀树。字符匹配和星号匹配。abcd和abcd,当左c和右对应的时候,下一步分两种情况,左d和右*对应,左c和右c对应。有代码。
2.ACOK算法。当时和面试官聊的时候,面试官说了ACOK算法,但这个算法在网上没找到。百度了一番,感觉就是Aho-Corasick automaton算法,也就是AC自动机。AC自动机,没找到解法,所以没代码。
代码用golang编写,代码如下:
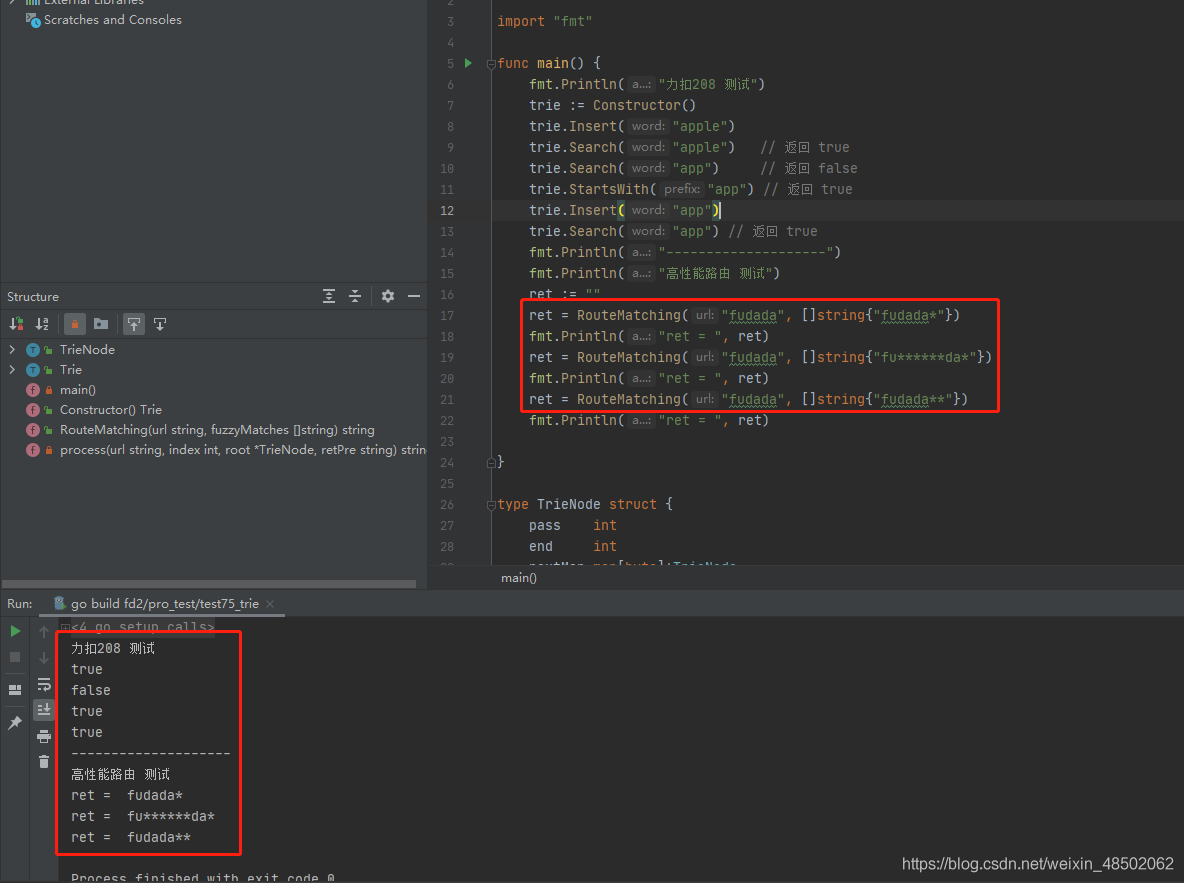
package main
import "fmt"
func main() {
fmt.Println("力扣208 测试")
trie := Constructor()
trie.Insert("apple")
trie.Search("apple") // 返回 true
trie.Search("app") // 返回 false
trie.StartsWith("app") // 返回 true
trie.Insert("app")
trie.Search("app") // 返回 true
fmt.Println("--------------------")
fmt.Println("高性能路由 测试")
ret := ""
ret = RouteMatching("fudada", []string{
"fudada*"})
fmt.Println("ret = ", ret)
ret = RouteMatching("fudada", []string{
"fu******da*"})
fmt.Println("ret = ", ret)
ret = RouteMatching("fudada", []string{
"fudada**"})
fmt.Println("ret = ", ret)
}
type TrieNode struct {
pass int
end int
nextMap map[byte]*TrieNode
}
type Trie struct {
root *TrieNode
}
/** Initialize your data structure here. */
func Constructor() Trie {
return Trie{
root: &TrieNode{
nextMap: make(map[byte]*TrieNode)}}
}
/** Inserts a word into the trie. */
func (this *Trie) Insert(word string) {
wordLen := len(word)
if wordLen == 0 {
return
}
node := this.root
node.pass++
for i := 0; i < wordLen; i++ {
// 从左往右遍历字符
if node.nextMap[word[i]] == nil {
node.nextMap[word[i]] = &TrieNode{
nextMap: make(map[byte]*TrieNode)}
}
node = node.nextMap[word[i]]
node.pass++
}
node.end++
}
/** Returns if the word is in the trie. */
func (this *Trie) Search(word string) bool {
wordLen := len(word)
if wordLen == 0 {
fmt.Println(false)
return false
}
node := this.root
for i := 0; i < wordLen; i++ {
// 从左往右遍历字符
if node.nextMap[word[i]] == nil {
fmt.Println(false)
return false
}
node = node.nextMap[word[i]]
}
fmt.Println(node.end > 0)
return node.end > 0
}
/** Returns if there is any word in the trie that starts with the given prefix. */
func (this *Trie) StartsWith(prefix string) bool {
word := prefix
wordLen := len(word)
if wordLen == 0 {
fmt.Println(false)
return false
}
node := this.root
for i := 0; i < wordLen; i++ {
// 从左往右遍历字符
if node.nextMap[word[i]] == nil {
fmt.Println(false)
return false
}
node = node.nextMap[word[i]]
}
fmt.Println(node.pass > 0)
return node.pass > 0
}
func RouteMatching(url string, fuzzyMatches []string) string {
fuzzyMatchesLen := len(fuzzyMatches)
if fuzzyMatchesLen == 0 && len(url) == 0 {
return ""
}
trie := Constructor()
for i := 0; i < fuzzyMatchesLen; i++ {
trie.Insert(fuzzyMatches[i])
}
return process(url, 0, trie.root, "")
}
func process(url string, index int, root *TrieNode, retPre string) string {
urlLen := len(url)
if index >= urlLen {
if root.end > 0 {
return retPre
} else {
if root.nextMap[''*''] != nil {
return process(url, index, root.nextMap[''*''], retPre+"*")
}
return ""
}
}
ret := ""
//1.匹配字符
if root.nextMap[url[index]] != nil {
ret = process(url, index+1, root.nextMap[url[index]], retPre+url[index:index+1])
if ret != "" {
return ret
}
}
//2.匹配*
if root.nextMap[''*''] != nil {
ret = process(url, index, root.nextMap[''*''], retPre+"*")
if ret != "" {
return ret
}
ret = process(url, index+1, root, retPre)
if ret != "" {
return ret
}
}
return ret
}执行结果如下:
左神前缀树java代码
评论
![CS1503 Argument1:无法从“字符串”转换为“字符串[*,*]”](http://www.gvkun.com/zb_users/upload/2025/04/e34ee67f-4203-43b4-bb6c-a4c5b5493e9f1745466399499.jpg "CS1503 Argument1:无法从“字符串”转换为“字符串[*,*]”")
CS1503 Argument1:无法从“字符串”转换为“字符串[*,*]”
如何解决CS1503 Argument1:无法从“字符串”转换为“字符串[*,*]”
这里是初学者。 GetFullName() ''brnd'' 和 ''nm'' 方法的参数似乎是错误的罪魁祸首-
“CS1503 Argument1(和 Argument2):无法从“字符串”转换为 ''string[,]''"
有人可以解释这个问题以及如何解决它吗?非常感谢!
if (iteminfo[row,0] == serialcheck){brnd = iteminfo[row,1];nm = iteminfo[row,2];info = GetFullName(brnd,nm);MessageBox.Show(info);return;}public string GetFullName(string[,] brandp,string[,] namep ){fullname = brandp + " - " + namep;return fullname;}
解决方法
方法 GetFullName 显然旨在对 string 值进行操作,但您已将参数声明为 string 类型的二维数组,并传递 string 值作为参数 -
info = GetFullName(brnd,nm);
这就是错误的根源。
修改方法签名为-
public string GetFullName(string brandp,string namep ){var fullname = brandp + " - " + namep;return fullname;}
关于Python 3-编码/解码vs字节/字符串和python字符串编码与解码的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于$("节点名").html("字符串")和$("节点名").text("字符串")区别、'{ 文件路径:字符串; webviewPath:字符串; }' 不可分配给“照片”类型的参数、2021-02-21:手写代码:高性能路由,也就是一个字符串和多个匹配串进行模糊匹配。一个数组arr里是[“*a*“,“moonfdd“],字符串“moonfdd“能匹配到,理由是arr里有。字符串“、CS1503 Argument1:无法从“字符串”转换为“字符串[*,*]”等相关内容,可以在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

