对于想了解从整个PythonPandasDataframe删除美元符号的读者,本文将提供新的信息,我们将详细介绍pythondataframe删除指定行,并且为您提供关于Python处理PandasD
对于想了解从整个Python Pandas Dataframe删除美元符号的读者,本文将提供新的信息,我们将详细介绍python dataframe删除指定行,并且为您提供关于Python 处理 Pandas DataFrame 中的行和列、python dataframe删除指定的行、Python Pandas -- DataFrame、Python pandas dataframe的有价值信息。
本文目录一览:- 从整个Python Pandas Dataframe删除美元符号(python dataframe删除指定行)
- Python 处理 Pandas DataFrame 中的行和列
- python dataframe删除指定的行
- Python Pandas -- DataFrame
- Python pandas dataframe
")
从整个Python Pandas Dataframe删除美元符号(python dataframe删除指定行)
我希望删除不起作用的美元符号。我相信这是因为正则表达式将美元符号视为字符串的结尾,但是我不确定该怎么做。到目前为止,这是我创建的:
dftest = pd.DataFrame({''A'':[1,2,3], ''B'':[4,5,6], ''C'':[''f;'',''$d:'',''sda%;sd$''], ''D'':[''s%'',''d;'',''d;p$''], ''E'':[5,3,6], ''F'':[7,4,3]})给出输出:
In [155]: dftestOut[155]: A B C D E F0 1 4 f; s% 5 71 2 5 $d: d; 3 42 3 6 sda%;sd$ d;p$ 6 3然后,我尝试删除美元符号,如下所示:
colstocheck = dftest.columnsdftest[colstocheck] = dftest[colstocheck].replace({''$'':''''}, regex = True)那不会删除美元符号,但是此代码会删除百分比符号:
dftest[colstocheck] = dftest[colstocheck].replace({''%'':''''}, regex = True)因此,我不确定如何替换美元符号。
答案1
小编典典您需要$通过\以下方式逃脱:
dftest[colstocheck] = dftest[colstocheck].replace({''\$'':''''}, regex = True)print (dftest) A B C D E F0 1 4 f; s% 5 71 2 5 d: d; 3 42 3 6 sda%;sd d;p 6 3
Python 处理 Pandas DataFrame 中的行和列
前言:
数据框是一种二维数据结构,即数据以表格的方式在行和列中对齐。我们可以对行/列执行基本操作,例如选择、删除、添加和重命名。在本文中,我们使用的是nba.csv文件。
处理列
为了处理列,我们对列执行基本操作,例如选择、删除、添加和重命名。
列选择:为了在 Pandas DataFrame 中选择一列,我们可以通过列名调用它们来访问这些列。
# Import pandas package
import pandas as pd
# 定义包含员工数据的字典
data = {''Name'':[''Jai'', ''Princi'', ''Gaurav'', ''Anuj''],
''Age'':[27, 24, 22, 32],
''Address'':[''Delhi'', ''Kanpur'', ''Allahabad'', ''Kannauj''],
''Qualification'':[''Msc'', ''MA'', ''MCA'', ''Phd'']}
# 将字典转换为 DataFrame
df = pd.DataFrame(data)
# 选择两列
print(df[[''Name'', ''Qualification'']])输出:

列添加:为了在 Pandas DataFrame 中添加列,我们可以将新列表声明为列并添加到现有数据框。
# Import pandas package
import pandas as pd
# 定义包含学生数据的字典
data = {''Name'': [''Jai'', ''Princi'', ''Gaurav'', ''Anuj''],
''Height'': [5.1, 6.2, 5.1, 5.2],
''Qualification'': [''Msc'', ''MA'', ''Msc'', ''Msc'']}
# 将字典转换为 DataFrame
df = pd.DataFrame(data)
# 声明要转换为列的列表
address = [''Delhi'', ''Bangalore'', ''Chennai'', ''Patna'']
# 使用“地址”作为列名并将其等同于列表
df[''Address''] = address
# 观察结果
print(df)输出:

有关更多示例,请参阅在 Pandas列删除中向现有 DataFrame 添加新列:为了删除 Pandas DataFrame 中的列,我们可以使用该方法。通过删除具有列名的列来删除列。drop()
# importing pandas module
import pandas as pd
# 从csv文件制作数据框
data = pd.read_csv("nba.csv", index_col ="Name" )
# 删除通过的列
data.drop(["Team", "Weight"], axis = 1, inplace = True)
# 展示
print(data)输出:如输出图像所示,新输出没有传递的列。这些值被删除,因为轴设置为等于 1,并且由于 inplace 为 True,因此在原始数据框中进行了更改。
删除列之前的数据框- 删除列:
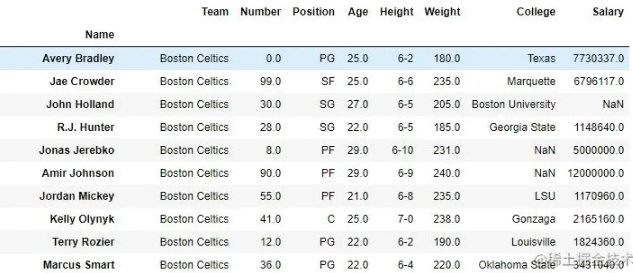
之后的数据框:

处理行
为了处理行,我们可以对行执行基本的操作,例如选择、删除、添加和重命名。
行选择Pandas 提供了一种从数据框中检索行的独特方法。DataFrame.loc[]方法用于从 Pandas DataFrame 中检索行。也可以通过将整数位置传递给 iloc[] 函数来选择行。
# importing pandas package
import pandas as pd
# 从csv文件制作数据框
data = pd.read_csv("nba.csv", index_col ="Name")
# 通过 loc 方法检索行
first = data.loc["Avery Bradley"]
second = data.loc["R.J. Hunter"]
print(first, "\n\n\n", second)输出:如输出图像所示,由于两次都只有一个参数,因此返回了两个系列。
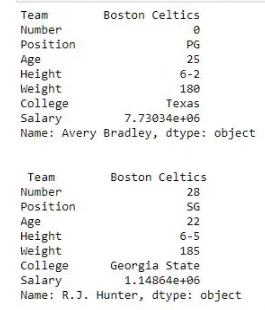
有关更多示例,请参阅Pandas 使用 .loc Row Addition提取行:为了在 Pandas DataFrame 中添加一行,我们可以将旧数据帧与新数据帧连接。
# importing pandas module
import pandas as pd
# 制作数据框
df = pd.read_csv("nba.csv", index_col ="Name")
df.head(10)
new_row = pd.DataFrame({''Name'':''Geeks'', ''Team'':''Boston'', ''Number'':3,
''Position'':''PG'', ''Age'':33, ''Height'':''6-2'',
''Weight'':189, ''College'':''MIT'', ''Salary'':99999},
index =[0])
# 简单地连接两个数据框
df = pd.concat([new_row, df]).reset_index(drop = True)
df.head(5)输出:添加行前的数据框- 添加行
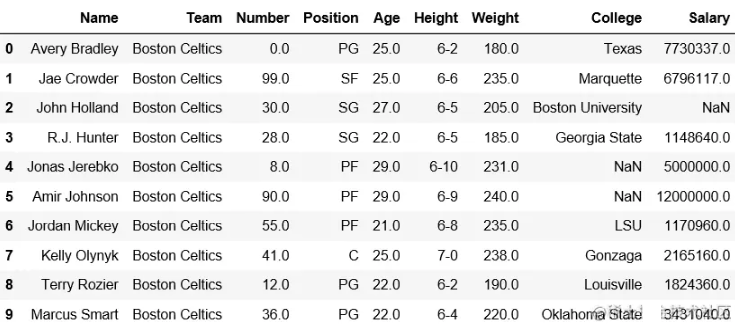
后的数据框-

删除行:为了删除 Pandas DataFrame 中的一行,我们可以使用 drop() 方法。通过按索引标签删除行来删除行。
# importing pandas module
import pandas as pd
# 从csv文件制作数据框
data = pd.read_csv("nba.csv", index_col ="Name" )
# 删除传递的值
data.drop(["Avery Bradley", "John Holland", "R.J. Hunter",
"R.J. Hunter"], inplace = True)
# 展示
data输出:如输出图像所示,新输出没有传递的值。由于 inplace 为 True,因此删除了这些值并在原始数据框中进行了更改。
删除值之前的数据框- 删除值

后的数据框:
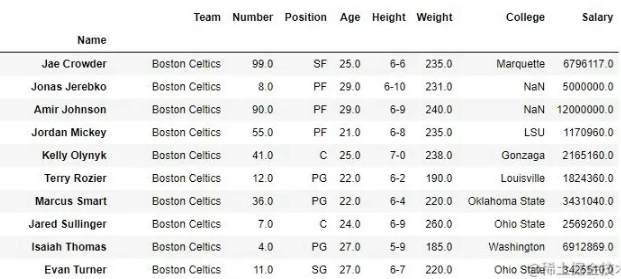
到此这篇关于Python 处理 Pandas DataFrame 中的行和列的文章就介绍到这了,更多相关Python Pandas DataFrame 内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
- Python pandas按行、按列遍历DataFrame的几种方式
- Python Pandas 修改表格数据类型 DataFrame 列的顺序案例
- python读取和保存为excel、csv、txt文件及对DataFrame文件的基本操作指南
- python Dataframe 合并与去重详情
- 解读Python中的frame是什么

python dataframe删除指定的行
网上关于dataframe删除指定行的博文较少,看到一篇不错的,转载一下,原文地址:https://blog.csdn.net/shuihupo/article/details/82842524
遇到清洗数据的问题,需要把某一列数据中,那些为指定元素的数据,整行去除
尝试了drop却不能到达理想的效果,drop仅仅删除了第一个。
isin效果理想。
data.name.isin([筛选元素])
对dataframe的某列(name为列名)进行筛选,加负号的原因是想删除符合条件的行,不写负号是筛选出符合条件的行

Python Pandas -- DataFrame
pandas.DataFrame
-
class
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)[source] -
Two-dimensional size-mutable, potentially heterogeneous tabular data structure with labeled axes (rows and columns). Arithmetic operations align on both row and column labels. Can be thought of as a dict-like container for Series objects. The primary pandas data structure
Parameters: data : numpy ndarray (structured or homogeneous), dict, or DataFrame
Dict can contain Series, arrays, constants, or list-like objects
index : Index or array-like
Index to use for resulting frame. Will default to np.arange(n) if no indexing information part of input data and no index provided
columns : Index or array-like
Column labels to use for resulting frame. Will default to np.arange(n) if no column labels are provided
dtype : dtype, default None
Data type to force. Only a single dtype is allowed. If None, infer
copy : boolean, default False
Copy data from inputs. Only affects DataFrame / 2d ndarray input
See also
-
DataFrame.from_records - constructor from tuples, also record arrays
-
DataFrame.from_dict - from dicts of Series, arrays, or dicts
-
DataFrame.from_items - from sequence of (key, value) pairs
pandas.read_csv,pandas.read_table,pandas.read_clipboard1. 先来个小菜
基于dictionary创建
from pandas import Series, DataFrame import pandas as pd import numpy as np d = {''col1'':[1,2],''col2'':[3,4]} df = pd.DataFrame(data=d) print(df) print(df.dtypes) # col1 col2 #0 1 3 #1 2 4 #col1 int64 #col2 int64 #dtype: object基于Numy的ndarrary
df2 = pd.DataFrame(np.random.randint(low=0, high=10, size=(5, 5)),columns=[''a'', ''b'', ''c'', ''d'', ''e'']) print (df2) # a b c d e #0 0 2 4 7 0 #1 6 7 3 4 1 #2 5 3 3 8 7 #3 0 9 4 3 4 #4 7 4 7 0 0 -

Python pandas dataframe
dataframe 列类型
df['客户id'] = df['客户id'].apply(pd.to_numeric)
df = pd.DataFrame(a, dtype='float') #示例1
df = pd.DataFrame(data=d, dtype=np.int8) #示例2
df = pd.read_csv("somefile.csv", dtype = {'column_name' : str})df[['col2','col3']] = df[['col2','col3']].apply(pd.to_numeric)df[['two', 'three']] = df[['two', 'three']].astype(float)df.dtypes
type(mydata[0][0])
维度查看:df.shape
数据表基本信息(维度、列名称、数据格式、所占空间等):df.info()
每一列数据的格式:df.dtypes
某一列格式:df['B'].dtype
文件操作
DataFrame 数据的保存和读取
- df.to_csv 写入到 csv 文件
- pd.read_csv 读取 csv 文件
- df.to_json 写入到 json 文件
- pd.read_json 读取 json 文件
- df.to_html 写入到 html 文件
- pd.read_html 读取 html 文件
- df.to_excel 写入到 excel 文件
- pd.read_excel 读取 excel 文件
pandas.DataFrame.to_csv
将 DataFrame 写入到 csv 文件
DataFrame.to_csv(path_or_buf=None, sep=', ', na_rep='', float_format=None, columns=None, header=True, index=True,
index_label=None, mode='w', encoding=None, compression=None, quoting=None, quotechar='"',
line_terminator='\n', chunksize=None, tupleize_cols=None, date_format=None, doublequote=True,
escapechar=None, decimal='.')
参数:
path_or_buf : 文件路径,如果没有指定则将会直接返回字符串的 json
sep : 输出文件的字段分隔符,默认为 “,”
na_rep : 用于替换空数据的字符串,默认为''
float_format : 设置浮点数的格式(几位小数点)
columns : 要写的列
header : 是否保存列名,默认为 True ,保存
index : 是否保存索引,默认为 True ,保存
index_label : 索引的列标签名
条件筛选
单条件筛选
多条件筛选
索引筛选
切片操作
loc函数[行用序号,列用名称]
iloc函数[行用序号,列用序号]
使用方法同loc函数,但是不再输入列名,而是输入列的index: data.iloc[row_index,col_index]
ix函数
at函数
iat函数
df.set_index('month')
df.set_index(['year','month'])
DataFrame.columns = [newName]
df['Hour'] = pd.to_datetime(df['report_date'])
df.rename(index = str,column = new_names)
删除列:
#通过特征选取
data = data[['age']]
#通过del 关键字
del data['name']
#通过drop函数
data.drop(['name'],axis=1, inplace=True)
#通过pop
data.pop('name')
df = pd.read_csv(INPUTFILE, encoding = "utf-8")
df_bio = pd.read_csv(INPUTFILE, encoding = "utf-8", header=None) # header=None, header=0
显示前几行
df.head()
显示后几行
df.tail()
删除重复的数据isDuplicated=df.duplicated() #判断重复数据记录
print(isDuplicated)
0 False
1 False
2 True
3 False
dtype: bool
#删除重复的数据
print(df.drop_duplicates()) #删除所有列值相同的记录,index为2的记录行被删除
col1 col2
0 a 3
1 b 2
3 c 2
print(df.drop_duplicates(['col1'])) #删除col1列值相同的记录,index为2的记录行被删除
col1 col2
0 a 3
1 b 2
3 c 2
print(df.drop_duplicates(['col2'])) #删除col2列值相同的记录,index为2和3的记录行被删除
col1 col2
0 a 3
1 b 2
print(df.drop_duplicates(['col1','col2'])) #删除指定列(col1和col2)值相同的记录,index为2的记录行被删除
col1 col2
0 a 3
1 b 2
3 c 2df 某一列字母转大写小写
df['列名'] = df['列名'].str.upper()
df['列名'] = df['列名'].str.lower()
REF
https://www.cnblogs.com/aro7/p/9748202.html
https://www.cnblogs.com/hankleo/p/11462532.html
今天关于从整个Python Pandas Dataframe删除美元符号和python dataframe删除指定行的讲解已经结束,谢谢您的阅读,如果想了解更多关于Python 处理 Pandas DataFrame 中的行和列、python dataframe删除指定的行、Python Pandas -- DataFrame、Python pandas dataframe的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

