本文的目的是介绍如何使用Graphviz在JupyterNotebook中实现创建某些边缘的功能?的详细情况,特别关注jupyter安装graphviz的相关信息。我们将通过专业的研究、有关数据的分析
本文的目的是介绍如何使用Graphviz在Jupyter Notebook中实现创建某些边缘的功能?的详细情况,特别关注jupyter安装graphviz的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您呈现一个全面的了解如何使用Graphviz在Jupyter Notebook中实现创建某些边缘的功能?的机会,同时也不会遗漏关于Jupyter notebook 工具栏隐藏和 jupyter notebook 主题更改、Jupyter Notebook 遇上 NebulaGraph,可视化探索图数据库、jupyter notebook中使用mpld3进行交互、Jupyter Notebook中的快捷键的知识。
本文目录一览:- 如何使用Graphviz在Jupyter Notebook中实现创建某些边缘的功能?(jupyter安装graphviz)
- Jupyter notebook 工具栏隐藏和 jupyter notebook 主题更改
- Jupyter Notebook 遇上 NebulaGraph,可视化探索图数据库
- jupyter notebook中使用mpld3进行交互
- Jupyter Notebook中的快捷键
")
如何使用Graphviz在Jupyter Notebook中实现创建某些边缘的功能?(jupyter安装graphviz)
graphviz docs是必经之路。还要查看示例。

Jupyter notebook 工具栏隐藏和 jupyter notebook 主题更改
有趣的事,Python 永远不会缺席!
如需转发,请注明出处:小婷儿的 python https://www.cnblogs.com/xxtalhr/p/10747200.html
注:有时候 jupyter 输出后,需要滚动条才能看全,执行下列命令,修改输出段的字号大小,就不需要滚动条了。


1 #jt -t monokai -f fira -fs 13 -cellw 90% -ofs 11 -dfs 11 -T -N
2
3 #-f(字体) -fs(字体大小) -cellw(占屏比或宽度) -ofs(输出段的字号) -T(显示工具栏) -N(显示自己主机名)
4
5 jt -t gruvboxl -f fira -fs 13 -cellw 90% -ofs 11 -dfs 11 -T -N

一、问题
Jupyter notebook 安装完扩展包后,工具栏不见了?如下图:

二、解决办法
安装主题包: >>> pip install --upgrade jupyterthemes
查看主题: >>> jt -l
设定主题: >>> jt -t chesterish -T
Available Themes:
1 chesterish
2 grade3
3 gruvboxd
4 gruvboxl
5 monokai
6 oceans16
7 onedork
8 solarizedd
9 solarizedl
Available Themes:
1 chesterish 黑色
2 grade3 白灰相间
3 gruvboxd 深焦黄色,还行
4 gruvboxl 护眼浅黄色
5 monokai 黑色,还行
6 oceans16 深灰色
7 onedork 少浅暗灰色
8 solarizedd 墨蓝色
9 solarizedl 正常护眼色
三、工具栏界面出现
完美!!!

结果
Successfully !!!
有趣的事,Python 永远不会缺席!还不来加我,瞅什么瞅。


Jupyter Notebook 遇上 NebulaGraph,可视化探索图数据库

在之前的《手把手教你用 NebulaGraph AI 全家桶跑图算法》中,除了介绍了 ngai 这个小工具之外,还提到了一件事有了 Jupyter Notebook 插件: https://github.com/wey-gu/ipython-ngql,可以更便捷地操作 NebulaGraph。
本文就手把手教你咋在 Jupyter Notebook 中,愉快地玩图数据库。
只要你仔细读完本文,一条 %ngql MATCH p=(n:player)->() RETURN p 命令就可以直接查询出数据,再接上 %ng_draw 就可以画出返回结果。
下面,进入今天的主菜——Jupyter Notebook 扩展:ipython-ngql。
其实,ipython-ngql 这个扩展断断续续地开发了两年,我一直没有开发完成。恰好之前有空,并完成了一直以来的心愿,把 ipython-ngql 重构并正式发布了。它除了完全适配 NebulaGrpah 3.x 所有查询之外,还支持了 Notebook 内的返回结果可视化。
在介绍 ipython-ngql 是什么之前,我先做个简单的 Jupyter Notebook 介绍,虽然大多数的 Python 开发都知道。
什么是 Jupyter Notebook
Jupyter Notebook / Jupyter Labs 项目最初起源自 IPython 这个项目,后者是一个命令行上的交互式 Python 解释环境。因为有很好的补全、高亮和丰富的扩展能力,IPython 很快就成为了 Python 的第一 IDLE 替代项目,并且后来衍生出来了可以在浏览器里做更多事情的笔记本模式。
Jupyter 的笔记本模式改变了数据科学和相关科研、工业领域里人们协作、开发、分享面向数据的工作方式。有了它,我们可以在一个笔记本中可复现、可分享地进行代码执行、科学计算、数据可视化等等操作,是数据科学家、科研工作者的非常喜欢的工具,而且它还早就引入了 Python 之外的很多其他语言作为执行内核支持。
因为在 Jupyter Notebook 中进行 NebulaGraph 的查询、计算、可视化一直是很多社区同学的心愿,在前阵子 NebulaGrpah AI Suite 的开发过程中,我并实现了 Jupyter 中方便进行 NetworkX / PySpark 的计算。既然有图计算了,索性我就把相关的查询、可视化功能一起做掉,并作为 Jupyter 的扩展一起发布出来给大家使用啦。
ipython-ngql 的安装
因为 ipython-ngql 本文就是一个基于 Jupyter Notebook 的扩展,所以它的安装非常简单。只需要在 Jupyter Notebook 中执行 %pip install ipython-ngql ,再加载它就好:
%pip install ipython-ngql
%load_ext ngql然后,我们就可以用 %ngql 这个 Jupyter Magic word 连接 NebulaGraph 了:
%ngql --address 127.0.0.1 --port 9669 --user root --password nebula #填入 ip 地址和 graphd 的端口号当成功连接服务之后,SHOW SPACES 的结果会返回在 notebook cell 下。
除了上面的扩展安装方法之外,你可以从 Docker 桌面版的扩展市场里搜索 NebulaGraph,一键安装本地开发环境。安装完毕之后,进入 NebulaGraph Docker 扩展内部,点击 NebulaGraph AI ,点击 Install NX Mode 安装本地的 NebulaGraph + Jupyter Notebook 开发环境。

数据查询
ipython-ngql 现在支持两种语法 %ngql 接单行查询和 %%ngql 接多行查询。
单行查询
例如:
%ngql USE basketballplayer;
%ngql MATCH (v:player{name:"Tim Duncan"})-->(v2:player) RETURN v2.player.name AS Name;多行查询
例如:
%%ngql
ADD HOSTS "storaged3":9779,"storaged4":9779;
SHOW HOSTS;渲染结果
在任意一个查询后面紧跟着一个 %ng_draw 指令,就可以把结果可视化渲染出来。像是这样:
# one query
%ngql GET SUBGRAPH 2 STEPS FROM "player101" YIELD VERTICES AS nodes, EDGES AS relationships;
%ng_draw
# another query
%ngql match p=(:player)-[]->() return p LIMIT 5
%ng_draw效果:

此外,你的渲染的结果还会被保存为单文件 html ,方便我们可以内嵌到任意网页中。
像是下面,其实就是一个内嵌的页面:

高阶用法
下面,我们来展示一些便捷的高阶用法。比如 %ngql help,可以获得更多帮助信息。
操作查询结果为 pandas DF
你的每次查询,返回的结果会被存到 _ 变量中,方便我们对它进行读取。像是这样:

返回原始 ResultSet
ipython-ngql 默认返回的结果格式是 pandas DF,如果我们想在 Jupyter Notebook 中交互地调试 Python 的 NebulaGraph 应用代码,可以将返回结果设置为原始的 ResultSet 格式,方便直观进行 query 与结果解析。例如:
In [1] : %config IPythonNGQL.ngql_result_In [2] : %%ngql USE pokemon_club;
...: GO FROM "Tom" OVER owns_pokemon YIELD owns_pokemon._dst as pokemon_id
...: | GO FROM $-.pokemon_id OVER owns_pokemon REVERSELY YIELD owns_pokemon._dst AS Trainer_Name;
...:
...:
Out[3]:
ResultSet(ExecutionResponse(
error_code=0,
latency_in_us=3270,
data=DataSet(
column_names=[b''Trainer_Name''],
rows=[Row(
values=[Value(
sVal=b''Tom'')]),
...
Row(
values=[Value(
sVal=b''Wey'')])]),
space_name=b''pokemon_club''))
In [4]: r = _
In [5]: r.column_values(key=''Trainer_Name'')[0].cast()
Out[5]: ''Tom''查询模板
除了上面那些功能,我还支持了模板功能,语法沿用了 Jinja2 的 {{ variable }}。详见这个例子:

未来
后续,我打算增强可视化的自定义选项,也欢迎社区里的大伙来贡献新的 feature、idea。
项目的 repo 在 https://github.com/wey-gu/ipython-ngql
谢谢你读完本文 (///▽///)
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、(^з^)-☆ star 它 -> GitHub;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下「你的名片」一起玩耍呀~

jupyter notebook中使用mpld3进行交互
用pycharm进行远程服务器debug可以说是非常的爽了,但是设置远程的图片在本地显示会非常的麻烦
jupyter可以用%matplotlib inline 来远程plt.show图片,但是有一个问题是不能够交互,比如说我画了一堆散点图,我想分析散点图的局部信息,用matplotlib inline显示的图片是inline的png格式的图片,不能够进行缩放查看局部信息
所以有没有一种,用jupyter远程服务器,并且画出来的图像也能够进行交互呢?
是有的,mpld3库
mpld3库安装也很简单,首先安装依赖库
pip install Jinja2然后安装mpld3库
pip install mpld3安装完成之后,在使用的时候可能会出现这样一个问题
mpld3.display(fig) Object of type ''ndarray'' is not JSON serializable
这是mpld3中的一个问题,需要给安装好的mpld3打补丁
python -m pip install --user "git+https://github.com/javadba/mpld3@display_fix"然后就可以愉快的使用啦
这里给出官方的一个例子,https://mpld3.github.io/notebooks/mpld3_demo.html
用
mpld3.enable_notebook()可以全局设置绘制的所有图有简单的交互功能,具体是含有哪些简单的交互功能呢
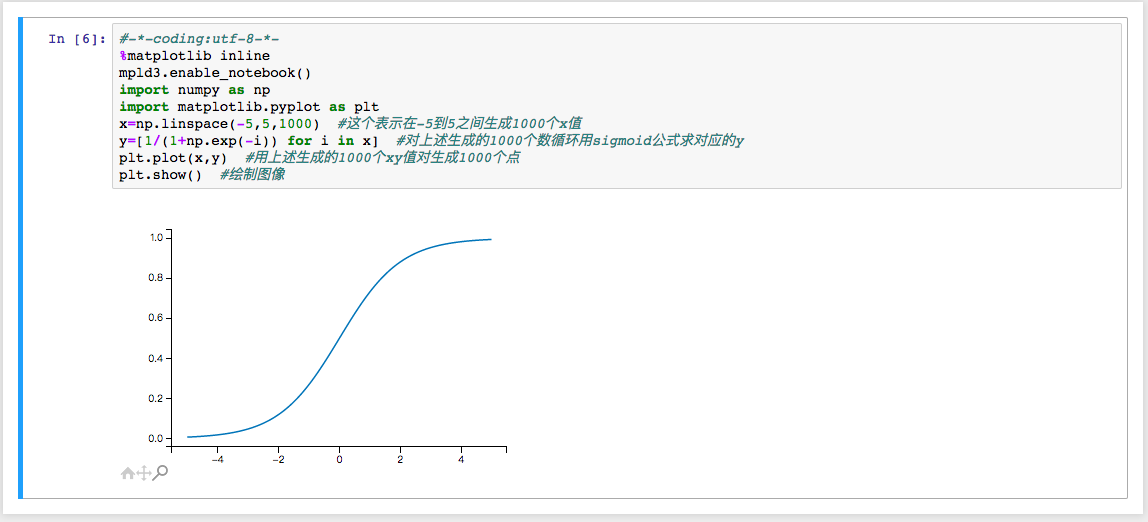
注意看图片左下角的放大以及拖放以及返回到主页的功能,

Jupyter Notebook中的快捷键
1.快捷键
Jupyter Notebook 有两种键盘输入模式。编辑模式,允许你往单元中键入代码或文本;这时的单元框线是绿色的。命令模式,键盘输入运行程序命令;这时的单元框线是灰色。
命令模式 (按键 Esc 开启)
- Enter : 转入编辑模式
- Shift-Enter : 运行本单元,选中下个单元
- Ctrl-Enter : 运行本单元
- Alt-Enter : 运行本单元,在其下插入新单元
- Y : 单元转入代码状态
- M :单元转入markdown状态
- R : 单元转入raw状态
- 1 : 设定 1 级标题
- 2 : 设定 2 级标题
- 3 : 设定 3 级标题
- 4 : 设定 4 级标题
- 5 : 设定 5 级标题
- 6 : 设定 6 级标题
- Up : 选中上方单元
- K : 选中上方单元
- Down : 选中下方单元
- J : 选中下方单元
- Shift-K : 扩大选中上方单元
- Shift-J : 扩大选中下方单元
- A : 在上方插入新单元
- B : 在下方插入新单元
- X : 剪切选中的单元
- C : 复制选中的单元
- Shift-V : 粘贴到上方单元
- V : 粘贴到下方单元
- Z : 恢复删除的最后一个单元
- D,D : 删除选中的单元
- Shift-M : 合并选中的单元
- Ctrl-S : 文件存盘
- S : 文件存盘
- L : 转换行号
- O : 转换输出
- Shift-O : 转换输出滚动
- Esc : 关闭页面
- Q : 关闭页面
- H : 显示快捷键帮助
- I,I : 中断Notebook内核
- 0,0 : 重启Notebook内核
- Shift : 忽略
- Shift-Space : 向上滚动
- Space : 向下滚动
编辑模式 ( Enter 键启动)
- Tab : 代码补全或缩进
- Shift-Tab : 提示
- Ctrl-] : 缩进
- Ctrl-[ : 解除缩进
- Ctrl-A : 全选
- Ctrl-Z : 复原
- Ctrl-Shift-Z : 再做
- Ctrl-Y : 再做
- Ctrl-Home : 跳到单元开头
- Ctrl-Up : 跳到单元开头
- Ctrl-End : 跳到单元末尾
- Ctrl-Down : 跳到单元末尾
- Ctrl-Left : 跳到左边一个字首
- Ctrl-Right : 跳到右边一个字首
- Ctrl-Backspace : 删除前面一个字
- Ctrl-Delete : 删除后面一个字
- Esc : 进入命令模式
- Ctrl-M : 进入命令模式
- Shift-Enter : 运行本单元,选中下一单元
- Ctrl-Enter : 运行本单元
- Alt-Enter : 运行本单元,在下面插入一单元
- Ctrl-Shift-- : 分割单元
- Ctrl-Shift-Subtract : 分割单元
- Ctrl-S : 文件存盘
- Shift : 忽略
- Up : 光标上移或转入上一单元
- Down :光标下移或转入下一单元
2.变量的完美显示
有一点已经众所周知。把变量名称或没有定义输出结果的语句放在cell的最后一行,无需print语句,Jupyter也会显示变量值。当使用Pandas DataFrames时这一点尤其有用,因为输出结果为整齐的表格。
鲜为人知的是,你可以通过修改内核选项ast_note_interactivity,使得Jupyter对独占一行的所有变量或者语句都自动显示,这样你就可以马上看到多个语句的运行结果了。
In [1]: from IPython.core.interactiveshell import InteractiveShellInteractiveShell.ast_node_interactivity = "all"In [2]: from pydataset import dataquakes = data(''quakes'')quakes.head()quakes.tail()Out[2]:lat long depth mag stations1 -20.42 181.62 562 4.8 412 -20.62 181.03 650 4.2 153 -26.00 184.10 42 5.4 434 -17.97 181.66 626 4.1 195 -20.42 181.96 649 4.0 11Out[2]:lat long depth mag stations996 -25.93 179.54 470 4.4 22997 -12.28 167.06 248 4.7 35998 -20.13 184.20 244 4.5 34999 -17.40 187.80 40 4.5 141000 -21.59 170.56 165 6.0 119
如果你想在各种情形下(Notebook和Console)Jupyter都同样处理,用下面的几行简单的命令创建文件~/.ipython/profile_default/ipython_config.py即可实现:
c = get_config()# Run all nodes interactivelyc.InteractiveShell.ast_node_interactivity = "all"
3、轻松链接到文档
在Help 菜单下,你可以找到常见库的在线文档链接,包括Numpy,Pandas,Scipy和Matplotlib等。
另外,在库、方法或变量的前面打上?,即可打开相关语法的帮助文档。
In [3]: ?str.replace()
Docstring:
S.replace(old, new[, count]) -> str
Return a copy of S with all occurrences of substring
old replaced by new. If the optional argument count is
given, only the first count occurrences are replaced.
Type: method_descriptor
4、 在notebook里作图
在notebook里作图,有多个选择:
- matplotlib (事实标准),可通过%matplotlib inline 激活,详细链接
- %matplotlib notebook 提供交互性操作,但可能会有点慢,因为响应是在服务器端完成的。
- mpld3 提供matplotlib代码的替代性呈现(通过d3),虽然不完整,但很好。
- bokeh 生成可交互图像的更好选择。
- plot.ly 可以生成非常好的图,可惜是付费服务。
5、 Jupyter Magic命令
上文提到的%matplotlib inline 是Jupyter Magic命令之一。
推荐阅读Jupyter magic命令的相关文档,它一定会对你很有帮助。下面是我最爱的几个:
6、 Jupyter Magic-%env:设置环境变量
不必重启jupyter服务器进程,也可以管理notebook的环境变量。有的库(比如theano)使用环境变量来控制其行为,%env是最方便的途径。
In [55]: # Running %env without any arguments
# lists all environment variables
# The line below sets the environment
# variable OMP_NUM_THREADS
%env OMP_NUM_THREADS=4
env: OMP_NUM_THREADS=4
7、Jupyter Magic - %run: 运行python代码
%run 可以运行.py格式的python代码——这是众所周知的。不那么为人知晓的事实是它也可以运行其它的jupyter notebook文件,这一点很有用。
注意:使用%run 与导入一个python模块是不同的。
In [56]: # this will execute and show the output from
# all code cells of the specified notebook
%run ./two-histograms.ipynb

8、Jupyter Magic -%load:从外部脚本中插入代码
该操作用外部脚本替换当前cell。可以使用你的电脑中的一个文件作为来源,也可以使用URL。
In [ ]: # Before Running
%load ./hello_world.py
In [61]: # After Running
# %load ./hello_world.py
if __name__ == "__main__":
print("Hello World!")
Hello World!
9、Jupyter Magic - %store: 在notebook文件之间传递变量
%store 命令可以在两个notebook文件之间传递变量。
In [62]: data = ''this is the string I want to pass to different notebook''
%store data
del data # This has deleted the variable
Stored ''data'' (str)
现在,在一个新的notebook文档里……
In [1]: %store -r data
print(data)
this is the string I want to pass to different notebook
10、Jupyter Magic - %who: 列出所有的全局变量
不加任何参数, %who 命令可以列出所有的全局变量。加上参数 str 将只列出字符串型的全局变量。
In [1]: one = "for the money"
two = "for the show"
three = "to get ready now go cat go"
%who str
one three two
11、Jupyter Magic – 计时
有两种用于计时的jupyter magic命令: %%time 和 %timeit.当你有一些很耗时的代码,想要查清楚问题出在哪时,这两个命令非常给力。
仔细体会下我的描述哦。
%%time 会告诉你cell内代码的单次运行时间信息。
In [4]: %%time
import time
for _ in range(1000):
time.sleep(0.01)# sleep for 0.01 seconds
CPU times: user 21.5 ms, sys: 14.8 ms, total: 36.3 ms
Wall time: 11.6 s
%%timeit 使用了Python的 timeit 模块,该模块运行某语句100,000次(默认值),然后提供最快的3次的平均值作为结果。
In [3]: import numpy
%timeit numpy.random.normal(size=100)
The slowest run took 7.29 times longer than the fastest. This could mean that an intermediate result is being cached.
100000 loops, best of 3: 5.5 µs per loop
12、Jupyter Magic - %%writefile and %pycat:导出cell内容/显示外部脚本的内容
使用%%writefile magic可以保存cell的内容到外部文件。 而%pycat功能相反,把外部文件语法高亮显示(以弹出窗方式)。
In [7]: %%writefile pythoncode.py
import numpy
def append_if_not_exists(arr, x):
if x not in arr:
arr.append(x)
def some_useless_slow_function():
arr = list()
for i in range(10000):
x = numpy.random.randint(0, 10000)
append_if_not_exists(arr, x)
Writing pythoncode.py
In [8]: %pycat pythoncode.py
import numpy
def append_if_not_exists(arr, x):
if x not in arr:
arr.append(x)
def some_useless_slow_function():
arr = list()
for i in range(10000):
x = numpy.random.randint(0, 10000)
append_if_not_exists(arr, x)
13、Jupyter Magic - %prun: 告诉你程序中每个函数消耗的时间
使用%prun+函数声明会给你一个按顺序排列的表格,显示每个内部函数的耗时情况,每次调用函数的耗时情况,以及累计耗时。
In [47]: %prun some_useless_slow_function()
26324 function calls in 0.556 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
10000 0.527 0.000 0.528 0.000 <ipython-input-46-b52343f1a2d5>:2(append_if_not_exists)
10000 0.022 0.000 0.022 0.000 {method ''randint'' of ''mtrand.RandomState'' objects}
1 0.006 0.006 0.556 0.556 <ipython-input-46-b52343f1a2d5>:6(some_useless_slow_function)
6320 0.001 0.000 0.001 0.000 {method ''append'' of ''list'' objects}
1 0.000 0.000 0.556 0.556 <string>:1(<module>)
1 0.000 0.000 0.556 0.556 {built-in method exec}
1 0.000 0.000 0.000 0.000 {method ''disable'' of ''_lsprof.Profiler'' objects}
14、Jupyter Magic –用%pdb调试程序
Jupyter 有自己的调试界面The Python Debugger (pdb),使得进入函数内部检查错误成为可能。
Pdb中可使用的命令见链接
In [ ]: %pdb
def pick_and_take():
picked = numpy.random.randint(0, 1000)
raise NotImplementedError()
pick_and_take()
Automatic pdb calling has been turned ON
---------------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
<ipython-input-24-0f6b26649b2e> in <module>()
5 raise NotImplementedError()
6
----> 7 pick_and_take()
<ipython-input-24-0f6b26649b2e> in pick_and_take()
3 def pick_and_take():
4 picked = numpy.random.randint(0, 1000)
----> 5 raise NotImplementedError()
6
7 pick_and_take()
NotImplementedError:
> <ipython-input-24-0f6b26649b2e>(5)pick_and_take()
3 def pick_and_take():
4 picked = numpy.random.randint(0, 1000)
----> 5 raise NotImplementedError()
6
7 pick_and_take()
ipdb>
15、末句函数不输出
有时候不让末句的函数输出结果比较方便,比如在作图的时候,此时,只需在该函数末尾加上一个分号即可。
In [4]: %matplotlib inline
from matplotlib import pyplot as plt
import numpy
x = numpy.linspace(0, 1, 1000)**1.5
In [5]: # Here you get the output of the function
plt.hist(x)
Out[5]:
(array([ 216., 126., 106., 95., 87., 81., 77., 73., 71., 68.]),
array([ 0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1. ]),
<a list of 10 Patch objects>)In [6]: # By adding a semicolon at the end, the output is suppressed.
plt.hist(x);16、运行Shell命令
在notebook内部运行shell命令很简单,这样你就可以看到你的工作文件夹里有哪些数据集。
In [7]: !ls *.csv
nba_2016.csv titanic.csv
pixar_movies.csv whitehouse_employees.csv
17、用LaTex 写公式
当你在一个Markdown单元格里写LaTex时,它将用MathJax呈现公式:如
$$ P(A \mid B) = \frac{P(B \mid A) , P(A)}{P(B)} $$
会变成
18、在notebook内用不同的内核运行代码
如果你想要,其实可以把不同内核的代码结合到一个notebook里运行。
只需在每个单元格的起始,用Jupyter magics调用kernal的名称:
- %%bash
- %%HTML
- %%python2
- %%python3
- %%ruby
-
%%perl
In [6]: %%bash for i in {1..5} do echo "i is $i" done
i is 1
i is 2
i is 3
i is 4
i is 5
19、给Jupyter安装其他的内核
Jupyter的优良性能之一是可以运行不同语言的内核。下面以运行R内核为例说明:
简单的方法:通过Anaconda安装R内核
conda install -c r r-essentials
稍微麻烦的方法:手动安装R内核
如果你不是用Anaconda,过程会有点复杂,首先,你需要从CRAN安装R。
之后,启动R控制台,运行下面的语句:
install.packages(c(''repr'', ''IRdisplay'', ''crayon'', ''pbdZMQ'', ''devtools''))
devtools::install_github(''IRkernel/IRkernel'')
IRkernel::installspec() # to register the kernel in the current R installation
20、在同一个notebook里运行R和Python
要这么做,最好的方法事安装rpy2(需要一个可以工作的R),用pip操作很简单:
pip install rpy2
然后,就可以同时使用两种语言了,甚至变量也可以在二者之间公用:
In [1]: %load_ext rpy2.ipython
In [2]: %R require(ggplot2)
Out[2]: array([1], dtype=int32)
In [3]: import pandas as pd
df = pd.DataFrame({
''Letter'': [''a'', ''a'', ''a'', ''b'', ''b'', ''b'', ''c'', ''c'', ''c''],
''X'': [4, 3, 5, 2, 1, 7, 7, 5, 9],
''Y'': [0, 4, 3, 6, 7, 10, 11, 9, 13],
''Z'': [1, 2, 3, 1, 2, 3, 1, 2, 3]
})
In [4]: %%R -i df
ggplot(data = df) + geom_point(aes(x = X, y= Y, color = Letter, size = Z))21、用其他语言写函数
有时候numpy的速度有点慢,我想写一些更快的代码。
原则上,你可以在动态库里编译函数,用python来封装…
但是如果这个无聊的过程不用自己干,岂不更好?
你可以在cython或fortran里写函数,然后在python代码里直接调用。
首先,你要先安装:
!pip install cython fortran-magic
In [ ]: %load_ext Cython
In [ ]: %%cython
def myltiply_by_2(float x):
return 2.0 * x
In [ ]: myltiply_by_2(23.)
我个人比较喜欢用Fortran,它在写数值计算函数时十分方便。更多的细节在这里。
In [ ]: %load_ext fortranmagic
In [ ]: %%fortran
subroutine compute_fortran(x, y, z)
real, intent(in) :: x(:), y(:)
real, intent(out) :: z(size(x, 1))
z = sin(x + y)
end subroutine compute_fortran
In [ ]: compute_fortran([1, 2, 3], [4, 5, 6])
还有一些别的跳转系统可以加速python 代码。更多的例子见链接:
22、支持多指针
Jupyter支持多个指针同步编辑,类似Sublime Text编辑器。按下Alt键并拖拽鼠标即可实现。
23、Jupyter外接拓展
Jupyter-contrib extensions是一些给予Jupyter更多更能的延伸程序,包括jupyter spell-checker和code-formatter之类.
下面的命令安装这些延伸程序,同时也安装一个菜单形式的配置器,可以从Jupyter的主屏幕浏览和激活延伸程序。
!pip install https://github.com/ipython-contrib/jupyter_contrib_nbextensions/tarball/master
!pip install jupyter_nbextensions_configurator
!jupyter contrib nbextension install --user
!jupyter nbextensions_configurator enable --user24、从Jupyter notebook创建演示稿
Damian Avila的RISE允许你从已有的notebook创建一个powerpoint形式的演示稿。
你可以用conda来安装RISE:
conda install -c damianavila82 rise
或者用pip安装:
pip install RISE
然后运行下面的代码来安装和激活延伸程序:
jupyter-nbextension install rise --py --sys-prefix
jupyter-nbextension enable rise --py --sys-prefix
25、Jupyter输出系统
Notebook本身以HTML的形式显示,单元格输出也可以是HTML形式的,所以你可以输出任何东西:视频/音频/图像。
这个例子是浏览我所有的图片,并显示前五张图的缩略图。
In [12]: import os
from IPython.display import display, Image
names = [f for f in os.listdir(''../images/ml_demonstrations/'') if f.endswith(''.png'')]
for name in names[:5]:
display(Image(''../images/ml_demonstrations/'' + name, width=100))我们也可以用bash命令创建一个相同的列表,因为magics和bash运行函数后返回的是python 变量:
In [10]: names = !ls ../images/ml_demonstrations/*.png
names[:5]
Out[10]: [''../images/ml_demonstrations/colah_embeddings.png'',
''../images/ml_demonstrations/convnetjs.png'',
''../images/ml_demonstrations/decision_tree.png'',
''../images/ml_demonstrations/decision_tree_in_course.png'',
''../images/ml_demonstrations/dream_mnist.png'']
26、大数据分析
很多方案可以解决查询/处理大数据的问题:
- ipyparallel(之前叫 ipython cluster) 是一个在python中进行简单的map-reduce运算的良好选择。我们在rep中使用它来并行训练很多机器学习模型。
- pyspark
- spark-sql magic %%sql
27、分享notebook
分享notebook最方便的方法是使用notebook文件(.ipynb),但是对那些不使用notebook的人,你还有这些选择:
- 通过File > Download as > HTML 菜单转换到html文件。
- 用gists或者github分享你的notebook文件。这两个都可以呈现notebook,示例见链接
- 如果你把自己的notebook文件上传到github的仓库,可以使用很便利的Mybinder服务,允许另一个人进行半个小时的Jupyter交互连接到你的仓库。
- 用jupyterhub建立你自己的系统,这样你在组织微型课堂或者工作坊,无暇顾及学生们的机器时就非常便捷了。
- 将你的notebook存储在像dropbox这样的网站上,然后把链接放在nbviewer,nbviewer可以呈现任意来源的notebook。
- 用菜单File > Download as > PDF 保存notebook为PDF文件。如果你选择本方法,我强烈建议你读一读Julius Schulz的文章
- 用Pelican从你的notebook创建一篇博客。
关于如何使用Graphviz在Jupyter Notebook中实现创建某些边缘的功能?和jupyter安装graphviz的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于Jupyter notebook 工具栏隐藏和 jupyter notebook 主题更改、Jupyter Notebook 遇上 NebulaGraph,可视化探索图数据库、jupyter notebook中使用mpld3进行交互、Jupyter Notebook中的快捷键的相关知识,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

