本文将介绍Mushkin发布RedlineVORTEX系列PCIe4.0SSD的详细情况,特别是关于nvmepcie3.0x4的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个
本文将介绍Mushkin 发布 Redline VORTEX 系列 PCIe 4.0 SSD的详细情况,特别是关于nvme pcie 3.0 x4的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于(SSL: error:0906D 06C:PEM routines:PEM_read_bio:no start line:Expecting: TRUSTED CERTIFICATE)、330-基于FMC接口的Kintex-7 XC7K325T PCIeX8 3U PXIe接口卡 光纤PCIe卡、450MB/s!Mushkin新款便携式SSD发布:最高1TB、A Survey of Machine Learning Techniques Applied to Software Defined Networking (SDN): Research Is...的知识。
本文目录一览:- Mushkin 发布 Redline VORTEX 系列 PCIe 4.0 SSD(nvme pcie 3.0 x4)
- (SSL: error:0906D 06C:PEM routines:PEM_read_bio:no start line:Expecting: TRUSTED CERTIFICATE)
- 330-基于FMC接口的Kintex-7 XC7K325T PCIeX8 3U PXIe接口卡 光纤PCIe卡
- 450MB/s!Mushkin新款便携式SSD发布:最高1TB
- A Survey of Machine Learning Techniques Applied to Software Defined Networking (SDN): Research Is...
")
Mushkin 发布 Redline VORTEX 系列 PCIe 4.0 SSD(nvme pcie 3.0 x4)
Mushkin 最近推出了一款名为 Redline VORTEX 系列的新型高性能 PCIe 4.0 SSD,面向游戏玩家和其他需要高存储性能的用户。这款 SSD 不仅提供高达 7415 MB/s 的连续读取速度,使其成为当今业界最快的PCIe 4.0 SSD 之一,而且还配备了一个纤薄的石墨烯散热器,可以安装在笔记本电脑中。同时,它还具有较低的价格,使其成为具有成本效益的存储产品。
Mushkin 的 Redline VORTEX 系列 PCIe 4.0 SSD 提供 512GB、1TB 和 2TB 三种容量,在读写方面都相当不错。由于 DRAM 缓存与 SLC 缓存相结合,它应该可以很好地用于内容创建者、游戏和与专业相关的工作负载。

Redline VORTEX系列PCIe 4.0 SSD最吸引人的地方大概就是它的价格了。512GB和1TB容量的价格分别为77.89美元和124.99美元,但2TB容量的价格还不清楚,而且性价比看起来相当高,对消费者来说还是挺有吸引力的。
")
(SSL: error:0906D 06C:PEM routines:PEM_read_bio:no start line:Expecting: TRUSTED CERTIFICATE)
nginx: [emerg] PEM_read_bio_X509_AUX("D:/es/vxmes.csr") failed (SSL: error:0906D
06C:PEM routines:PEM_read_bio:no start line:Expecting: TRUSTED CERTIFICATE)

330-基于FMC接口的Kintex-7 XC7K325T PCIeX8 3U PXIe接口卡 光纤PCIe卡
一、板卡概述 本板卡基于Xilinx公司的FPGAXC7K325T-2FFG900 芯片,pin_to_pin兼容FPGAXC7K410T-2FFG900 ,支持PCIeX8、64bit DDR3容量2GByte,HPC的FMC连接器,板卡支持PXIE标准协议,其中XJ3标准高速差分接口支持PCIeX 8。软件具有windows,Linux驱动。

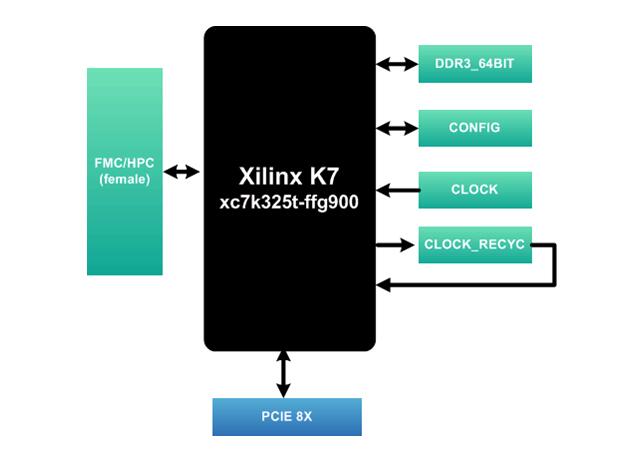
二、功能和技术指标: • 支持PXIe标准。 • 支持1路PCIe X8 支持PCI Express V1.1 V2.0标准; • 支持64bitDDR3, 容量2GByte; • 支持1个FMC HPC中LA,HA,HB全部接口和DP0~DP7 8路高速接口,兼容ML605等开发板,前面板输出; • 支持4个LED指示灯; • 支持面板显示自定义指示灯(1个); • 所有器件支持商业级,工业级。
三、软件功能: • 支持 DDR3 IP,PCIe IP开发; • 支持 Windows驱动, • Linux驱动。 • FMC上接高速ADC,DAC子卡,Camera Link 子卡等,并可提供演示程序。
四、应用领域 • 软件无线电处理平台 • 图形图像硬件加速器 • Net FPGA
五、FMC子卡搭配使用 (1)AD/DA子卡 该类AD/DA子卡模块就专门针对xilinx开发板设计的标准板卡,用于模拟信号、中频信号采集,信号发出等应用。 (2)图像子卡 该类CamerLink子卡模块就专门针对xilinx开发板设计的标准板卡,用于视频信号检测,分析等应用。 (3)DSP子卡 该类DSP子卡模块以TI强大性能DSP TMS320C6455作为主芯片,专门针对xilinx开发板设计的标准板卡,用于高速数据、视频信号检测,分析等应用。
北京太速科技有限公司
在线客服:QQ:448468544
公司网站:www.orihard.com
联系电话:15084122580

450MB/s!Mushkin新款便携式SSD发布:最高1TB
Mushkin是美国一家凭借高速存储设备而闻名的存储设备公司。
在2013年的CES大会上发布了一款Ventura Ultra系列高速U盘,U盘采用SF2281主控和MLC颗粒,实现了450M/s的读取与440M/s的写入速度。
2018年1月11日,Mushkin在CES 2018上发布了一款名为CarbonEXT的外置SSD。
CarbonEXT外置SSD外部接口为USB3.1并采用ASMedia(祥硕)的ASM1153E芯片作为USB3.1 Gen 1与SSD的数据转接芯片,而内部SSD主控则采用慧荣的SM2258XT芯片。
速度方面,新款CarbonEXT外置SSD可提供最高450MB/s的连续读写速度。外置SSD拥有120GB至1TB多种存储容量可选,便携式SSD外壳采用经喷砂工艺的金属制成,长宽高分别为93 x 50 x 13毫米。
目前官方还没有透露此款外置SSD的售价及上市时间信息,不过可以肯定的是此款硬盘将会稍高于同等容量的M.2 SATA通道的固态硬盘。


: Research Is...")
A Survey of Machine Learning Techniques Applied to Software Defined Networking (SDN): Research Is...
- 文章名称:A Survey of Machine Learning Techniques Applied to Software Defined Networking (SDN): Research Issues and Challenges
- 文章名称:应用于SDN的机器学习技术综述:研究问题与挑战
- 发表时间: 2018
- 期刊来源:IEEE Communications Surveys & Tutorials
一、摘要
- 网络和移动通信技术的快速发展->网络系统中的基础设施,设备和资源变得越来越复杂和异构。
- 为了有效地组织,管理,维护和优化网络系统,需要部署更多的智能。
- SDN的能力(例如逻辑集中控制、网络的全局视图、基于软件的流量分析和转发规则的动态更新)使得在网络内部应用机器学习技术更容易。
- 本文从流量分类,路由优化,服务质量(QoS)/体验质量(QoE)预测,资源管理和安全性的角度,回顾机器学习如何应用在SDN领域。
二、机器学习算法概述
- 机器学习算法基本上分为四类:监督,无监督,半监督和强化学习。
- 监督学习算法通常用于进行分类和回归任务,而无监督和强化学习算法分别用于进行聚类和决策任务。
1.监督学习
- 监督学习是一种标签学习技术。 给监督学习算法给出标记的训练数据集以构建表示输入和输出之间的学习关系的系统模型。 训练后,当一个新的输入被输入系统时,训练的模型可用于获得预期的输出.
- 广泛使用的监督学习算法有:k-最近邻,决策树,随机森林,神经网络,支持向量机,贝叶斯理论和隐马尔可夫模型。
- k-最近邻(k-NN):基于一个未分类样本的k个最近邻居确定数据样本的分类。如果大多数k个最近邻居属于某个类,则未分类的样本将被分类到该类中。特别地,当k = 1时,被称为最近邻居算法。k值越高,噪声对分类的影响越小。距离是k-NN算法的主要度量,因此可以应用若干函数来定义未标记样本与其邻居之间的距离,
- 决策树(DT):通过学习树执行分类的分类技术之一。在树中,每个节点表示数据的特征(属性),所有分支表示导致分类的特征的连接,并且每个叶节点是类标签。可以通过将其特征值与决策树的节点进行比较来对未标记的样本进行分类。DT具有许多优点,例如直观的知识表达,简单的实现和高分类精度。ID3,C4.5和CART是三种广泛使用的决策树算法,用于自动执行训练数据集的分类,它们之间最大的区别是用于构建决策树的分裂标准。
- 随机森林:也称为随机决策森林,可用于分类和回归任务。随机森林由许多决策树组成。 为了减轻决策树方法的过度拟合并提高准确性,随机森林方法随机选择特征空间的一个子集来构造每个决策树。使用随机森林方法对新数据样本进行分类的步骤是:(a)将数据样本放入林中的每个树。(b)每棵树给出一个分类结果,即树的“投票”。(c)数据样本将被分类为投票最多的类别。
- 神经网络(NN):由大量简单处理使用激活函数组成的计算系统,以执行非线性计算。最常用的激活函数是sigmoid和双曲正切函数。模拟神经元在人脑中的连接方式。NN有很多层。第一层是输入层,最后一层是输出层。输入图层和输出图层之间的图层是隐藏图层。每层的输出是下一层的输入,最后一层的输出是结果。通过改变隐藏层的数量和每层中的节点数量,可以训练复杂模型以提高NN的性能。有许多类型的神经网络。
- 随机神经网络:随机神经网络与其他神经网络的主要区别在于随机神经网络中的神经元在概率上交换兴奋性和抑制性尖峰信号。每个神经元的电位值在接收到兴奋性尖峰信号时上升,在接收到抑制性尖峰信号时下降。(待细读)
- 深度神经网络DNN:具有单个隐藏层的神经网络通常被称为浅神经网络。相比之下,在输入层和输出层之间具有多个隐藏层的神经网络被称为DNN。在DNN中,每个层的神经元基于前一层的输出训练特征表示,这被称为特征层次。特征层次结构使DNN能够处理大型高维数据集。由于多级特征表示学习,与其他机器学习技术相比,DNN通常提供更好的性能。
- 卷积神经网络CNN:卷积神经网络和循环神经网络是两种主要类型的DNN。CNN是前馈神经网络。连续层之间的局部稀疏连接,权重共享和池化是CNN的三个基本思想。权重共享意味着同一卷积核中所有神经元的权重参数是相同的。局部稀疏连接和权重共享可以减少训练参数的数量。池化可用于减少特征尺寸,同时保持特征的不变性。这三个基本思想极大地减少了卷积神经网络的训练难度。
- 循环神经网络RNN:在前馈神经网络中,信息从输入层定向传输到输出层。但循环神经网络可以使用内部状态(内存)来处理顺序数据。**长短期记忆(LSTM)**是最常用的RNN类型,它具有捕获长期依赖性的良好能力。LSTM使用三个门(输入门、输出门和遗忘门)来计算隐藏状态。
- 支持向量机(SVM):SVM的基本思想是将输入向量映射到高维特征空间。通过应用不同的核函数(例如线性,多项式和基于径向的函数RBF)来实现该映射。核函数选择是SVM中的关键,它对分类精度有影响。核函数的选择取决于训练数据集,如果数据集是线性可分的,则线性核函数就可以很好地工作。如果数据集不是线性可分的,则多项式和RBF是两个常用的核函数。通常基于RBF的SVM分类器性能比较好。
- 隐马尔可夫模型(HMM):HMM是一种马尔可夫模型。马尔可夫模型广泛用于遵循无记忆特性的随机动态环境中。马尔可夫模型的无记忆性质意味着未来状态的条件概率分布仅与当前状态的值相关并且独立于所有先前的状态。HMM与其他模型之间的主要区别在于HMM通常应用于系统状态部分可见或根本不可见的环境中。
2.无监督学习
- 与监督学习相反,无监督学习算法被给予一组没有标签的输入。无监督学习算法旨在通过根据样本数据之间的相似性将样本数据聚类到不同的组中来找到未标记数据中的模式,结构或知识。无监督学习技术广泛用于聚类和数据聚合。广泛使用的无监督学习算法有:kmeans和自组织映射等。
- k-Means:k-means算法是一种流行的无监督学习算法,用于将一组未标记的数据识别到不同的簇中。为了实现kmeans算法,需要两个输入参数(初始数据集和期望的簇数)。如果所需的簇数是k,则使用k-means算法解决节点聚类问题的步骤是:(a)通过随机选择k个节点来初始化k个簇的质心;(b)使用距离函数用最近的质心标记每个节点;(c)根据当前节点成员资格分配新的质心;(d)如果收敛条件有效则停止算法,否则返回步骤(b)。
- 自组织映射(SOM):也称为自组织特征映射(SOFM),是最流行的无监督神经网络模型之一。SOM通常用于执行降维和数据聚类。
3.半监督学习
- 一种使用标记和未标记数据的学习方法。需要用到半监督学习的原因:a.在现实世界的许多应用中,获取标记数据是昂贵/困难的,而获取大量未标记数据相对容易且便宜。b.在训练过程中有效使用未标记的数据实际上倾向于改善训练模型的性能。为了充分利用未标记的数据,必须在半监督学习中保持假设,例如平滑假设,聚类假设,低密度分离假设和多种假设。
- 伪标签是一种简单而有效的半监督学习技术。伪标签的主要思想很简单。首先,使用标记数据来训练模型。然后,使用训练的模型来预测未标记数据的伪标签。最后,将标记数据和新伪标记数据组合以再次训练模型。
4.强化学习(RL)
- RL涉及代理,状态空间S和动作空间A。代理是一个学习实体,它与其环境相互作用以学习最大化其长期奖励的最佳动作。长期奖励是累积折扣奖励,与即时奖励和未来奖励相关。当将RL应用于SDN时,控制器通常用作代理,网络是环境。控制器监视网络状态并学习决定控制数据转发。代理的目的是学习最优行为策略π,它是从状态空间S到动作空间A(π:S→A)的直接映射,以最大化预期的长期奖励。根据行为策略π,代理可以确定给定特定状态的最佳对应动作。在RL中,值函数用于计算给定状态的动作的长期奖励。最着名的价值函数是Qfunction,Q学习用它来学习存储所有状态 - 动作对及其长期奖励的表格。
- 深度强化学习(DRL):RL的主要优点是它在没有先验知识的环境精确数学模型的情况下运行良好。然而,传统的RL方法存在一些缺点,如对最优行为策略π的收敛率低,无法解决高维状态空间和动作空间问题。DRL的关键思想是利用深度神经网络的强大函数逼近性来近似值函数。在训练深度神经网络之后,给定状态 - 动作对作为输入,DRL能够估计长期奖励。估计结果可以指导代理选择最佳动作。
三、SDN中的机器学习
1.流量分类
- 流量分类通过识别不同的流量类型提供了一种执行细粒度网络管理的方法。借助流量分类,网络运营商可以更有效地处理不同的服务并分配网络资源。
- 当前广泛使用的流量分类技术包括深度包检测DPI和机器学习。
- DPI将流量的有效载荷与预定义模式进行匹配,以识别流量流所属的应用程序。模式由正则表达式定义。基于DPI的方法通常具有高分类准确性。但是,它有一些缺点。首先,DPI只能识别其模式可用的应用程序。应用程序的指数增长使得模式更新变得困难且不切实际。其次,DPI会导致高计算成本,因为需要检查所有流量。第三,DPI无法对Internet上的加密流量进行分类。
- 基于ML的方法可以正确识别加密流量,并且比基于DPI的方法产生更低的计算成本。相关研究如下:
- 大象流感知流量分类:旨在识别大象流elephant flows和小鼠流mice flows。
- 大象流是寿命长、占用大量带宽的流量;小鼠流是短暂的、不容忍延迟的流量。但大多数字节都是在大象流中传输的。为了有效地控制数据中心的流量,有必要识别大象流量。
- 在一个例子中,提出的大象流检测策略由两个阶段组成。在第一阶段,采用头部包测量来区分可疑的大象流和小鼠流。在第二阶段,决策树被用作检测这些可疑流是否是大象流的检测方法。
- 应用感知流量分类:旨在识别流量的应用。
- 在一个侧重于通过UDP协议运行的应用程序的分类的例子中,使用了SVM算法,根据Netflow记录(如接收的分组和字节的计数)对UDP流量进行分类,分类精度超过90%。
- 在侧重于对移动应用程序进行分类的研究中,决策树、深度神经网络都有不错的效果。
- QoS感知流量分类:旨在识别流量的QoS等级。
- 随着互联网上应用程序的指数增长,识别所有应用程序是困难和不切实际的。然而,可以根据其QoS要求(例如延迟,抖动和丢失率)将应用划分为不同的QoS等级。
- 在一个例子中,通过利用半监督学习算法和DPI提出了一种QoS感知流量分类系统。DPI用于标记已知应用程序的部分流量。然后,由半监督学习算法(如Laplacian SVM)使用标记的训练数据集来对未知应用的业务流进行分类。以这种方式,已知和未知应用的业务流被分类为不同的QoS等级。
- 小结:
- 大象流感知流量分类通常应用于数据中心。数据中心的一个主要目标是快速安排流量。细粒度流量分类方法(即,应用感知和QoS感知流量分类)可能会增加流量处理延迟,因此它们不适合数据中心。
- 应用程序感知流量分类通常应用于细粒度网络管理。但是,随着Internet上应用程序的指数增长,识别所有应用程序是不切实际的。现有研究通常识别最流行的应用程序。(如识别广泛使用的八种应用、Google Play上的前40个应用程序等)。
- 网络运营商可以使用QoS感知流量分类来根据其期望的QoS对网络资源分配进行优化。
2.路由优化
- 低效的路由决策可能导致网络链路过载并增加端到端传输延迟,从而影响SDN的整体性能。因此,如何优化路由是一个重要的研究问题。
- 最短路径优先(SPF)算法和启发式算法[149]是两种广泛使用的路由优化方法。SPF算法根据跳数或延迟等简单条件路由数据包。尽管SPF算法很简单,但它是一种尽力而为的路由协议,并没有充分利用网络资源。启发式算法(例如,蚁群优化算法)是解决路由优化问题的另一种方法。高计算复杂度是启发式算法的主要缺点。
- 与启发式算法相比,机器学习算法具有一些优势。一方面,经过训练,机器学习算法可以快速提供接近最优的路由解决方案。另一方面,机器学习算法不需要底层网络的精确数学模型。路由优化问题可以被视为决策任务。因此,强化学习是一种有效的方法。许多研究也应用监督学习算法来优化路由。
- 1)基于学习的监督路由优化:网络和流量状态通常是训练数据集的输入,并且启发式算法的相应路由解决方案是输出。 参考文献[151]提出了一种NeuRoute的动态路由框架。其中,LSTM用于估计未来的网络流量。
- 2)基于RL的路由优化:RL算法通常用于解决决策问题。当应用RL算法来优化路由时,控制器作为代理工作,网络是环境。状态空间由网络和流量状态组成。行动是路由解决方案。奖励是基于诸如网络延迟的优化度量来定义的。
- 3)流量预测:旨在通过分析历史流量信息来预测流量的趋势。
- 基于流量预测结果,SDN控制器可以提前做出流量路由决策,并将主动路由策略分发到数据平面中的转发设备,以指导不久的将来的流量路由。通过这种方式,SDN控制器可以在发生流量拥塞之前采取适当的措施。此外,流量预测可以促进主动提供网络资源以改善QoS。
- [159]提出了一种负载平衡策略来优化路径负载。 SDN控制器选择四个流特征(传输跳数,传输等待时间,分组丢失率和带宽利用率),以使用神经网络模型预测每个路径的负载。然后,将选择最小负载路径作为新业务流的传输路径。
- [160]提出了一种名为NeuTM的基于LSTM的框架来预测网络流量矩阵。仿真结果表明,LSTM模型收敛速度快,预测性能良好。
- 小结:
- 监督学习算法(尤其是神经网络)可以有效地获得最佳的启发式路由解决方案。然而,主要的缺点是标记的训练数据集的获取具有高计算复杂度。
- 与监督学习算法相比,RL算法具有一些优势。一方面,RL算法不需要标记的训练数据集。另一方面,可以通过不同的奖励功能灵活地调整优化目标(例如,能量效率,吞吐量和延迟)。
- 流量预测可以促进路由预设计的实现,这是通过预先修改交换机的流表来减少数据平面中的传输延迟的有效方法。神经网络模型,尤其是LSTM,通常用于流量预测。
3.QoS服务质量/QoE体验质量预测
- 丢失率,延迟,抖动和吞吐量之类的QoS参数是面向网络的度量,网络运营商通常使用这些度量来评估网络性能。
- 另一方面,随着多媒体技术的普及和普及,用户感知和满意度对于网络运营商和服务提供商来说变得越来越重要。QoE的概念已经成为用户评估用户对服务满意度的指标。
- 基于QoS / QoE预测,网络运营商和服务提供商可以提供高质量的服务,以提高客户满意度并防止客户流失。
- 1)QoS预测:QoS参数与网络关键性能指标(KPI)相关,例如分组大小、传输速率和队列长度等。KPI与QoS之间的定量相关性参数可以通过根据KPI预测QoS参数来改善QoS管理。
- 由于QoS参数通常是连续数据,因此QoS预测问题可以被视为回归任务。因此,监督学习是一种有效的方法。
- [163]采用神经网络模型估计给定流量负载的网络延迟和覆盖路由策略,实验结果表明基于神经网络的估计器在延迟估计的精度方面比传统的M/ M/1模型具有更好的性能。
- [164]在SDN中提出了一种两阶段分析机制来改进QoS预测。首先,决策树用于发现KPI和QoS参数之间的相关性。然后,应用线性回归ML算法(即M5Rules)来执行根本原因分析并发现每个KPI的定量影响。
- [165]使用两种学习方法(随机森林和回归树)估计Videoon-Demand(VoD)应用的两个QoS度量(帧速率和响应时间),应用感知QoS估计精度超过90%。由于随机森林是一种考虑许多决策树结果的集合方法,随机森林的预测精度高于回归树。然而,回归树的复杂性低于随机森林。
- 2)QoE预测:QoE是量化服务的用户满意度的主观度量。
- 广泛使用的QoE指标是平均意见得分(MOS)。MOS将QoE值分为五个等级,包括优秀,良好,公平,差和坏。由于QoE值严重依赖于网络QoS参数(如丢失率,延迟,抖动和吞吐量),为了实时获得QoE值,理解QoS参数如何影响QoE值是非常重要的。
- 机器学习是学习QoS参数和QoE值之间关系的有效方法。由于QoE值通常是离散数据,因此可以将QoE预测问题视为分类任务。因此,进行QoE预测的最佳方式是监督学习。
- [167]的作者使用四种ML算法(即DT,神经网络,k-NN和随机森林)来预测基于视频质量参数(SSIM和VQM)的QoE值。
- 小结:
- QoS预测旨在发现KPI与QoS参数之间的定量相关性,而QoE预测旨在发现QoS参数与QoE值之间的定量相关性。在SDN中,控制器可以使用预测结果灵活地配置数据平面中的设备以提高QoS / QoE。
- QoS预测通常被视为回归任务,而QoE预测被视为分类任务。因此,监督学习技术可用于QoS / QoE预测。
4.资源管理
- 1)数据平面资源管理:
- 许多工作已经研究了单租户SDN网络中的数据平面资源分配。[170]提出了一种集成框架,通过动态分配网络,缓存和计算资源来增强软件定义的虚拟车载Adhoc网络(VANET)的性能。考虑到网络,缓存和计算的收益,资源分配问题被制定为联合优化问题。提出了一种新的DRL算法来解决复杂优化问题并获得资源分配策略。
- [172]为了降低云服务中的重新配置成本,基于RL的启发式方法旨在选择最小化网络中长期重新配置成本的配置。
- 内容分发是人们生活中最受欢迎的服务之一。内容分发优化可以提高用户满意度。 [173]呈现基于RL的上下文感知内容分发方案以改进内容分发QoS。
- 多租户SDN网络中的资源分配: [134]研究SDN / NFV系统中的网络功能分配问题。SDN / NFV系统被认为是网络功能市场,其中服务器和用户分别是网络功能的销售者和购买者。网络功能分配问题被制定为两个Stackelberg游戏,其中服务器充当领导者,用户充当追随者。服务器和用户尝试做出最佳决策,以最大限度地发挥其效用和效益。Stackelberg平衡的存在已经被证明了,RL算法被应用于收敛到均衡。
- 准入控制(AC):准入控制的目标是通过根据资源可用性接受或拒绝新的传入请求来管理大量服务请求。[178],[179]重点关注SDN的准入控制。提出了SDN控制器中基于ML的方法,以根据变化的流量状况从在线算法池中选择最合适的AC算法。
- 2)控制平面资源管理:
- 控制平面资源分配:如何在多个租户之间分配网络管理程序的有限资源,以保证每个租户的数据平面和控制平面之间的通信是一个重要的研究课题。在这种情况下,机器学习算法通常在网络管理程序上运行以优化资源分配。
- [185]中资源监视工具用于监视网络管理程序的CPU消耗,基准测试工具hvbench用于测量控制消息速率。收集的数据用于训练三种不同的回归学习模型,以学习CPU消耗和控制消息速率之间的映射。
- [186]将[185]的方法扩展到管理程序的可用计算资源波动的场景。虚拟机管理程序的可用计算资源的大的变化将使当前的映射模型无效。为了检测资源变化,连续收集CPU消耗信息和控制消息速率信息。然后,SVM用于比较收集的数据和当前的映射模型。如果一段时间内收集的大部分数据不符合当前模型,则会发生大量资源变更。在这种情况下,将使用最近收集的数据重新训练映射模型。
- 控制器放置:在SDN中,集中控制器必须处理来自部署在不同位置的大量交换机的业务流。控制器和交换机之间的长距离会增加流量处理延迟。在这种情况下,控制器的位置会对网络性能产生重大影响。因此,应该认真研究控制器放置问题。
- 启发式算法是解决此问题的一种方法。高计算复杂度是启发式算法的主要缺点。
- 在[187],[188]中,应用三种监督学习算法(即决策树,神经网络和逻辑回归)来获得最优控制器的位置。用于训练监督学习算法的训练数据集的输入是流量分配,输出是启发式算法的相应控制器放置解决方案。
- 小结:
- 数据平面资源分配问题通常被视为决策任务。在这种情况下,基于RL和ML的博弈论是两种有效的方法。 RL经常用于单租户SDN网络。在多租户SDN网络中,数据平面中的资源由多个租户共享。每个租户的效用都会受到其他租户的资源分配策略的影响。因此,基于ML的博弈论适用于解决多租户SDN网络中的数据平面资源分配问题。
- 网络管理程序通常会将控制平面资源分配视为将其有限资源分配给多个租户。资源消耗和控制消息速率之间的映射对于控制平面资源分配非常重要。映射问题通常被视为回归任务。因此,监督学习技术可用于映射任务。在虚拟机管理程序的可用资源波动的动态场景中,需要定期更新训练好的映射模型。
5.安全
- 入侵检测是网络安全的重要元素。入侵检测系统(IDS)是一种设备或软件应用程序,其目标是监视网络系统中的事件并识别可能的攻击。IDS有助于网络运营商在发生攻击之前采取适当的措施。
- 根据识别网络攻击的方式,IDS可以分为两种:基于签名的IDS和基于异常的IDS。
- 在基于签名的IDS中,需要事先创建已知攻击的签名。当流量到达时,基于签名的IDS将这些流量与已知签名进行比较,以识别可能的恶意活动。基于签名的IDS通常具有高准确度。但是存在问题:a.新攻击的增长使签名更新变得困难。b.基于签名的IDS会导致高时间消耗,因为需要比较所有签名。
- 基于异常的IDS是一种统计方法,它使用与合法用户行为相关的收集数据来创建模型。当流量到达时,将其与模型进行对比,与模型有明显偏差的行为将被标记为异常。它可以检测新类型的攻击。
- 基于签名的IDS是基于有效载荷的流量识别的类型,其需要检查分组的整个有效载荷,而基于流量的IDS是基于流-粒度信息(如分组报头信息)的基于流的流量识别的类型。
- 机器学习方法通过训练模型来识别正常活动和入侵,广泛用于基于异常的IDS。入侵检测问题可以被视为分类任务。因此,监督学习算法通常应用于入侵检测。
- 在基于ML的入侵检测系统中,数据集输入的高维度(如流特征)对ML算法的性能有影响。为了在保持高检测精度的同时加速入侵检测过程,通常进行特征减少以降低数据集输入的维数。特征选择和特征提取是两种众所周知的减少流特征维数的方法。特征选择是一种从所有流特征中选择适当特征的子集的方法。特征提取是通过从原始特征中提取一组新特征来通过特征变换来降低流特征的维度的另一种方法。
- 已经对SDN中基于ML的入侵检测进行了许多研究,例如粗粒度入侵检测,细粒度入侵检测和DDoS攻击检测。
- 1)粗粒度入侵检测:粗粒度入侵检测旨在将流量分类为正常和异常类。
- [200]提出了一种威胁感知系统,用于对SDN中的网络入侵进行检测和响应,其中应用了决策树和随机森林算法来检测恶意活动。在选择特征集时用到了前向特征选择策略。
- [201]应用HMM来预测恶意活动并增强网络安全性。HMM使用五个选定的流特征(即,分组的长度,源端口,目的地端口,源IP地址和目的地IP地址)来确定一组分组的恶意性。
- [202]提出了一个名为ATLANTIC的框架,用于在SDN中联合执行异常流量检测,分类和缓解。分为两个阶段:轻量级阶段使用信息理论来计算流表熵的偏差。重量级阶段利用SVM算法对异常流量进行分类。
- [204]利用四种ML算法(即决策树,BayesNet,决策表和朴素贝叶斯)来预测潜在的恶意连接和易受攻击的主机。 SDN控制器使用预测结果来定义安全规则,以便保护潜在的易受攻击的主机,并通过阻止整个子网来限制潜在攻击者的访问。结果表明,BayesNet具有比其他三种算法更好的性能,BayesNet实现的平均预测精度为91.68%。
- [205]通过将流量分类为正常类和异常类,在SDN中使用深度神经网络模型来检测入侵活动。基于NSL-KDD数据集训练具有输入层、三个隐藏层和输出层的深度神经网络模型。实验结果表明,深度神经网络模型在异常检测中具有良好的性能,仅使用6个基本流特征时,平均检测精度为75.75%。
- 2)细粒度入侵检测:细粒度入侵检测旨在对网络流量进行细粒度分类,并识别不同类型的攻击。
- [208]提出了一种改进的基于行为的SVM来对网络攻击进行分类。为了提高入侵检测的准确性并加快正常和侵入模式的学习,决策树被用作特征缩减方法,以超越原始特征并选择最合格的特征。这些选定的特征是用于训练SVM分类器的输入数据。
- [209]提出了一种基于深度学习的入侵检测方法NDAE。为了在保持高检测精度的同时加速入侵检测,NDAE结合了深度学习方法和随机森林,其中深度学习方法应用于特征减少,随机森林用于流量分类和入侵检测。
- 3)DDoS攻击检测:DDoS攻击是SDN中网络安全的主要威胁。 DDoS攻击的目标是通过使用许多木偶机器同时发送大量虚假请求来耗尽系统资源,以便不处理合法用户的请求。在SDN中,DDoS攻击可以耗尽数据平面和控制平面中的网络,存储和计算资源,这将使SDN网络不可用。
- [210]应用自组织映射SOM根据收集的流量特征执行DDoS攻击检测。
- [211]提出的IDS包含两个模块:签名IDS和高级IDS。签名IDS模块利用不同的ML算法,例如k-NN,Naive Bayes,k-means和k-medoids,将流量流分类为正常和异常,并找到一组具有异常行为的主机。然后,高级IDS模块将检查具有异常行为的这些主机发送的数据包,以检测主机是否异常或授权用户。这样,高级IDS模块的处理时间减少了,因为只需要分析具有异常行为的主机。
- [98]应用深度学习模型检测SDN中的DDoS攻击,其中包括循环神经网络以及卷积神经网络。在收集和分析网络流量特征信息后,深度学习模型用于特征减少和DDoS攻击检测。 -[212]从收集的网络流量中提取68个流特征,包括来自TCP流的34个特征,来自UDP流的20个特征,以及来自ICMP流的14个特征。然后使用深度学习模型来进行特征减少和DDoS攻击检测。
- 4)其他:
- [213]提出了两个应用程序故障的概念验证示例,应用ML方法检测应用程序故障。检测结果可以指导SDN控制器实时采取适当的网络响应。
- [214]专注于软件定义的防火墙,提出一个框架来快速匹配流程并有效地捕获用户行为。使用隐马尔科夫模型HMM捕获用户行为的状态信息,并识别网络连接是否合法。如果发现非法连接,防火墙可以及时阻止该连接的访问。然后,利用这些信息以及相应的分组字段来训练神经网络模型。经过训练的模型能够快速匹配流,而不是将数据包流与每个防火墙过滤规则进行比较。
- 小结:
- 细粒度入侵检测通常用于细粒度网络管理。通过识别不同类型的攻击,SDN控制器可以针对每种类型的网络攻击做出适当的反应。但是,与粗粒度入侵检测相比,细粒度入侵检测需要更复杂的标记训练数据集。
- KDD99和NSL-KDD是IDS研究的两个广泛使用的数据集。NSL-KDD是KDD99数据集的修改版本,解决了KDD99数据集的许多固有问题。因此,当研究人员想要模拟基于ML的入侵检测方法的性能时,最好使用NSL-KDD数据集。
- 为了增强网络安全性,需要实时入侵检测。减少特征是优化系统性能和加速攻击检测的有效方法。特征选择和特征提取是两种最常用的减少流特征的方法。
- 大多数相关工作根据研究人员的经验选择流特征。决策树是另一种通过分析原始特征和选择最合格的特征来选择特征的方法。深度学习是一种广泛使用的特征提取方法,因为它具有强大的特征表示能力。
- 入侵检测问题可视为分类任务,因此通常应用监督学习算法来检测异常活动。
- [200]指出随机森林的性能优于决策树。在[204]中比较和评估了四种机器学习算法(即决策树,BayesNet,决策表和朴素贝叶斯)的性能。结果表明,BayesNet具有比其他三种算法更好的性能。[211]中的实验表明,Baysian算法比k-NN具有更好的性能。[205]将深度学习算法与其他三种ML算法(即贝叶斯理论,SVM和决策树)进行比较。实验结果表明,深度学习算法具有较高的入侵检测精度。然而,深度学习算法的复杂性也更高。
- [98]中的实验表明,增加训练数据集的量虽然显着提高了深度学习模型的性能,但也增加了训练时间和复杂性。因此,在检测性能和模型复杂性之间需要权衡。
四、挑战和未来研究方向
- 高质量的训练数据集
- 分布式多控制器平台:随着网络规模和流量的增加,由于控制器的计算限制,控制器通常面临可扩展性问题,于是提出了分布式多控制器平台来解决这个问题。
- 改善网络安全
- 跨层网络优化:在传统网络中,不允许非相邻层之间的直接通信。最近的研究表明,在非相邻层之间共享信息可以显着提高网络性能。但是,跨层设计打破了模块化原则,使网络变得如此复杂,以至于传统方法不足以优化这种网络。在SDN中,控制器具有全局网络视图,并且可以从所有不同层收集跨层信息,例如物理层的信道状态信息,数据链路/网络层的分组信息和应用层的应用信息。然后,机器学习算法可以使用所收集的信息进行网络优化,例如物理层参数自适应,资源分配,拓扑结构,路由机制和拥塞控制。
- 增量部署的SDN:SDN前景广阔,但它的部署需要将现在所有的网络交换机都更新为支持SDN的。增量部署是一种可行的方案,SDN交换机和控制器在传统网络中逐步部署,并且只有部分网络流量由控制器控制。在这种情况下,如何执行有效的流量工程和优化资源分配仍然是一个积极的研究方向。一种可能的解决方案是SDN控制器与其他传统网络节点通信以交换链路权重,可用带宽和拓扑信息。通过这种方式,SDN控制器获得所需的网络信息。通过分析这些信息以及从支持SDN的交换机收集的流量统计信息,可以利用机器学习算法来创建模型,利用这些模型可以有效地执行资源分配优化和流量工程。
我们今天的关于Mushkin 发布 Redline VORTEX 系列 PCIe 4.0 SSD和nvme pcie 3.0 x4的分享就到这里,谢谢您的阅读,如果想了解更多关于(SSL: error:0906D 06C:PEM routines:PEM_read_bio:no start line:Expecting: TRUSTED CERTIFICATE)、330-基于FMC接口的Kintex-7 XC7K325T PCIeX8 3U PXIe接口卡 光纤PCIe卡、450MB/s!Mushkin新款便携式SSD发布:最高1TB、A Survey of Machine Learning Techniques Applied to Software Defined Networking (SDN): Research Is...的相关信息,可以在本站进行搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

