如何解决百度spider无法抓取的问题?(如何解决百度spider无法抓取的问题)
29
如果您对如何解决百度spider无法抓取的问题?感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于如何解决百度spider无法抓取的问题?的详细内容,我们还将为您解答如何解决百
如果您对如何解决百度spider无法抓取的问题?感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于如何解决百度spider无法抓取的问题?的详细内容,我们还将为您解答如何解决百度spider无法抓取的问题的相关问题,并且为您提供关于.net 解决spider多次和重复抓取的方案、Baiduspider无法正常抓取、CURL抓取的网页中,通过相对路径引用了其他页面,如何解决cookie问题?、Fiddler无法抓到https的解决方法的有价值信息。
本文目录一览:")
如何解决百度spider无法抓取的问题?(如何解决百度spider无法抓取的问题)
Shanks 提问于 1年 之前
zac您好,网站能够正常访问,但是无法被百度蜘蛛抓取,做百度推广创意审核老是被拒,显示落地页无法访问,求支持,谢谢!
1 个回答
Zac 管理员 回答于 1年 之前
从描述和抓图看,基本可以肯定是服务器设置技术问题。这种问题作为用户访问网站是看不出源头的,只能技术人员仔细查服务器设置和网站程序。
比如,检查服务器或程序的什么地方是否屏蔽了百度蜘蛛IP或用户代理?
检查服务器原始日志,看看报错到底是什么?是4XX还是5XX?还是压根儿请求被拒绝?百度资源平台抓取诊断部分显示的是什么报错?
网站程序对用户和搜索引擎蜘蛛是否做不同处理?为什么要做不同处理?我访问网站时是被转向到另一个域名的,但从抓图看,百度蜘蛛并没有检测到转向,所以大概率服务器端针对不同访问设备做了不同处理,做了什么不同处理,只有程序员才能查看了。

.net 解决spider多次和重复抓取的方案
原因:
早期由于搜索引擎蜘蛛的不完善,蜘蛛在爬行动态的url的时候很容易由于网站程序的不合理等原因造成蜘蛛迷路死循环。
所以蜘蛛为了避免之前现象就不读取动态的url,特别是带?的url
解决方案:
1):配置路由
复制代码 代码如下:
routes.MapRoute("RentofficeList",
"rentofficelist/{AredId}-{PriceId}-{AcreageId}-{SortId}-{SortNum}.html",
new { controller = "Home", action = "RentOfficeList" },
new[] { "Mobile.Controllers" });
第一个参数是路由名称
第二个参数是路由的Url模式,参数之间用{}-{}方式分隔
第三个参数是一个包含默认路由的对象
第四个参数是应用程序的一组命名空间
2):设置连接
<a href="@Url.Action("RentofficeList",new RouteValueDictionary { { "AredId",0},{"PriceId",0},{"AcreageId",0},{"SortId",0},{"SortNum",0}})">默认排序</a>
对照上面的Url模式,依次写入参数赋值
3):获取参数
复制代码 代码如下:
int areaId = GetRouteInt("AredId");//获取参数
/// <summary>
/// 获得路由中的值
/// </summary>
/// <param name="key">键</param>
/// <param name="defaultValue">默认值</param>
/// <returns></returns>
protected int GetRouteInt(string key, int defaultValue)
{
return Convert.ToInt32(RouteData.Values[key], defaultValue);
}
/// <summary>
/// 获得路由中的值
/// </summary>
/// <param name="key">键</param>
/// <returns></returns>
protected int GetRouteInt(string key)
{
return GetRouteInt(key, 0);
}
根据上面3个步骤操作,显示的url地址为:
http://localhost:3841/rentofficelist/3-0-0-0-0.html
这样就可以避免静态页面上使用动态参数,显示的页面都为静态页面
您可能感兴趣的文章:- javascript SpiderMonkey中的函数序列化如何进行

Baiduspider无法正常抓取
安小雨 提问于 3年 之前
Baiduspider无法正常抓取,服务器错误:爬虫发起抓取,httpcode返回码是5XX
1 个回答
Zac 管理员 回答于 3年 之前
这个貌似没什么好回答的。
500或5XX错误就是服务器错误,检查服务器,问工程师、程序员啊,为什么会返回5XX错误。这个和搜索引擎算法、和SEO都没有别的关系了,完全是服务器问题。

CURL抓取的网页中,通过相对路径引用了其他页面,如何解决cookie问题?
curl 相对路径 cookie
例如,用curl抓取页面A,页面A通过相对路径引用了页面B,页面B有Set-Cookie的头部,而页面A没有Set-Cooike。
我只能curl抓取页面A,但是抓不到cookie,因为cookie是在页面B设置的。求高手解决问题!万分感激!
回复讨论(解决方案)
分两次/多次抓取
其实对于ajax/验证码等等都是这样做的
header("Content-type:text/html;charset=utf-8"); function request_by_curl($remote_server, $post_string) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $remote_server); curl_setopt($ch, CURLOPT_POSTFIELDS, $post_string); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_NOBODY, false); curl_setopt($ch, CURLOPT_HEADER,true); curl_setopt($ch, CURLOPT_HTTPHEADER, array()); $data = curl_exec($ch); curl_close($ch); return $data; } //获取验证码 file_get_contents("http://jysx.scnu.edu.cn/VerifyImg.aspx"); $cookie = $http_response_header[6]; $code = substr($cookie,23,4); echo $code."<br>"; //post登录 $remote_server = "http://jysx.scnu.edu.cn/login.aspx"; $post_string = ''act=login&type=ajax&name=20102301025&pass=523523&verify=''.$code; echo request_by_curl($remote_server,$post_string);登录后复制
这是我模拟登录华南师范大学抢实习的php代码,好像不行啊 可以了!!!!!
为什么这个网站会把验证码写到头信息里??

Fiddler无法抓到https的解决方法
1:请在“运行”,即下面这个地方输入certmgr.msc并回车,打开证书管理。
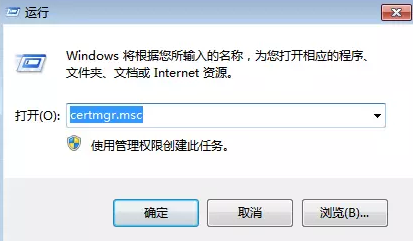
打开后,请点击操作--查找证书,如下所示:
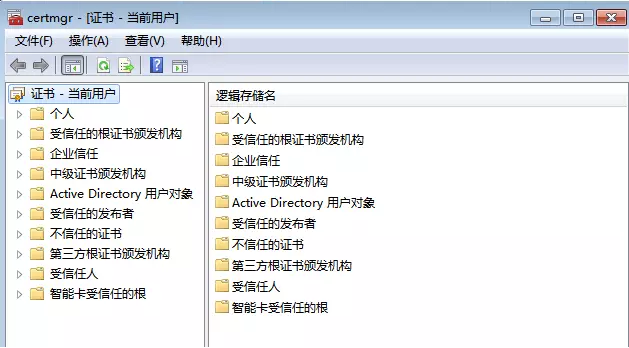
然后输入“fiddler”查找所有相关证书,如下所示:
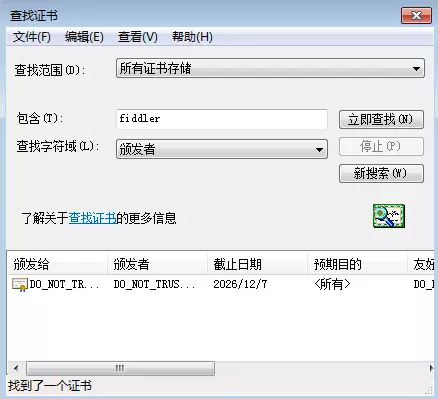
可以看到,我们找到一个,您可能会找到多个,不要紧,有多少个删多少个,全删之后,这一步完成
2:再接下来,打开火狐浏览器,进入选项-高级-证书-查看证书,然后找以DO_NOT开头的关于Fiddler的证书,以字母排序的,所以你可以很快找到。找到多少个还是删除多少个, 特别注意,请如图中【个人、服务器、证书机构、其他】等标签依次查找,以免遗漏,切记切记!
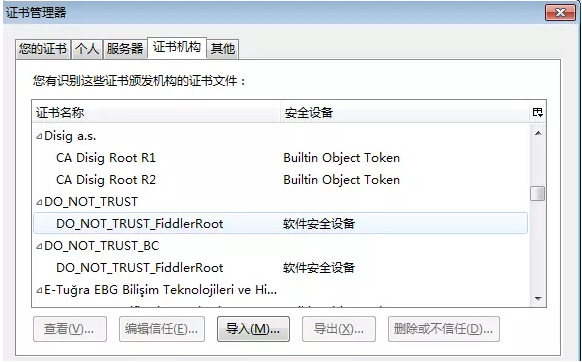
3:下载 FiddlerCertMaker.exe,可以去官网找,下载了这个之后,直接安装,直到如下
然后点击确定,关掉它。
4:有了证书之后,请重启Fiddler(关掉再开),重启之后,访问https的网站,比如淘宝首页,有可能成功了,但你也有可能会发现如下错误:"你的连接并不安全" 等类似提示。见到这里,你应该开心,离成功近了。
5:果断的,打开fiddler,“Tools--Fiddler Options--HTTPS”,然后把下图中同样的地方勾上(注意一致),然后点击actions,然后先点击Trust Root…,然后,再点击Export Root…,此时,导出成功的话,在桌面就有你的证书了。 务必注意:这一步成功的话,把第(6)步跳过,不要做了,直接进入第(7)步, 如失败,请继续第(6步)。
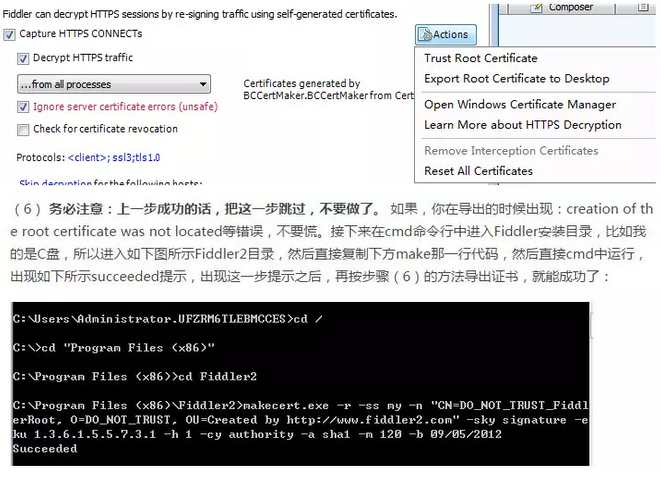
makecert.exe -r -ss my -n "CN=DO_NOT_TRUST_FiddlerRoot, O=DO_NOT_TRUST, OU=Created by http://www.fiddler2.com " -sky signature -eku 1.3.6.1.5.5.7.3.1 -h 1 -cy authority -a sha1 -m 120 -b 09/05/2012
7:好,证书从fiddler导入到桌面后,再打开火狐浏览器,然后进入:选项-高级-证书-查看证书-导入-选择刚导出的桌面的证书-确定。
8:随后,Fiddler重启,火狐浏览器也重启一下,然后开始抓HTTPS的包,此时你会发现“ 你的连接并不安全" 等类似提示已经消失,并且已经能够抓包了。
我们今天的关于如何解决百度spider无法抓取的问题?和如何解决百度spider无法抓取的问题的分享就到这里,谢谢您的阅读,如果想了解更多关于.net 解决spider多次和重复抓取的方案、Baiduspider无法正常抓取、CURL抓取的网页中,通过相对路径引用了其他页面,如何解决cookie问题?、Fiddler无法抓到https的解决方法的相关信息,可以在本站进行搜索。


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

