在本文中,我们将带你了解随机顺序和分页Elasticsearch在这篇文章中,我们将为您详细介绍随机顺序和分页Elasticsearch的方方面面,并解答随机分页不重复常见的疑惑,同时我们还将给您一些
在本文中,我们将带你了解随机顺序和分页Elasticsearch在这篇文章中,我们将为您详细介绍随机顺序和分页Elasticsearch的方方面面,并解答随机分页不重复常见的疑惑,同时我们还将给您一些技巧,以帮助您实现更有效的docker 部署 elasticsearch + elasticsearch-head + elasticsearch-head 跨域问题 + IK 分词器、Docker部署ElasticSearch和ElasticSearch-Head、Docker部署ElasticSearch和ElasticSearch-Head的实现、Elastic 网络研讨会 - Elasticsearch 大数据搜索和分析应用。
本文目录一览:- 随机顺序和分页Elasticsearch(随机分页不重复)
- docker 部署 elasticsearch + elasticsearch-head + elasticsearch-head 跨域问题 + IK 分词器
- Docker部署ElasticSearch和ElasticSearch-Head
- Docker部署ElasticSearch和ElasticSearch-Head的实现
- Elastic 网络研讨会 - Elasticsearch 大数据搜索和分析应用
")
随机顺序和分页Elasticsearch(随机分页不重复)
在此问题中,
有一个功能要求,要求使用可选种子进行订购,以允许随机订购。
我需要能够对随机排序的结果进行分页。用Elasticsearch 0.19.1怎么做?
谢谢。
答案1
小编典典您可以使用唯一字段(例如id)和随机盐的哈希函数进行排序。根据结果的真实程度,您可以执行以下原始操作:
{ "query" : { "query_string" : {"query" : "*:*"} }, "sort" : { "_script" : { "script" : "(doc[''_id''].value + salt).hashCode()", "type" : "number", "params" : { "salt" : "some_random_string" }, "order" : "asc" } }}或像
{ "query" : { "query_string" : {"query" : "*:*"} }, "sort" : { "_script" : { "script" : "org.elasticsearch.common.Digest.md5Hex(doc[''_id''].value + salt)", "type" : "string", "params" : { "salt" : "some_random_string" }, "order" : "asc" } }}第二个示例将产生更多随机结果,但速度会稍慢。
为了使这种方法起作用_id,必须存储字段。否则,查询将失败NullPointerException。

docker 部署 elasticsearch + elasticsearch-head + elasticsearch-head 跨域问题 + IK 分词器
0. docker pull 拉取 elasticsearch + elasticsearch-head 镜像
1. 启动 elasticsearch Docker 镜像
docker run -di --name tensquare_elasticsearch -p 9200:9200 -p 9300:9300 elasticsearch![]()
对应 IP:9200 ---- 反馈下边 json 数据,表示启动成功

2. 启动 elasticsearch-head 镜像
docker run -d -p 9100:9100 elasticsearch-head![]()
对应 IP:9100 ---- 得到下边页面,即启动成功
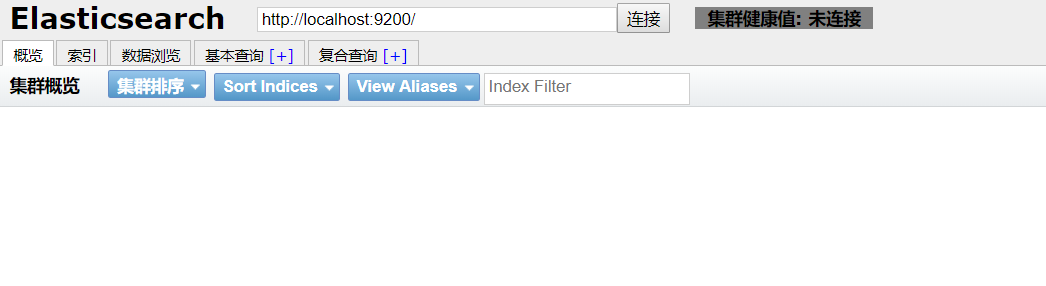
3. 解决跨域问题
进入 elasticsearch-head 页面,出现灰色未连接状态 , 即出现跨域问题

1. 根据 docker ps 得到 elasticsearch 的 CONTAINER ID
2. docker exec -it elasticsearch 的 CONTAINER ID /bin/bash 进入容器内
3. cd ./config
4. 修改 elasticsearch.yml 文件
echo "
http.cors.enabled: true
http.cors.allow-origin: ''*''" >> elasticsearch.yml
4. 重启 elasticsearch
docker restart elasticsearch的CONTAINER ID重新进入 IP:9100 进入 elasticsearch-head, 出现绿色标注,配置成功 !

5. ik 分词器的安装
将在 ik 所在的文件夹下,拷贝到 /usr/share/elasticsearch/plugins --- 注意: elasticsearch 的版本号必须与 ik 分词器的版本号一致
docker cp ik elasticsearch的CONTAINER ID:/usr/share/elasticsearch/plugins
重启elasticsearch
docker restart elasticsearch
未添加ik分词器:http://IP:9200/_analyze?analyzer=chinese&pretty=true&text=我爱中国
添加ik分词器后:http://IP:9200/_analyze?analyzer=ik_smart&pretty=true&text=我爱中国
Docker部署ElasticSearch和ElasticSearch-Head
Docker部署ElasticSearch和ElasticSearch-Head
本篇主要讲解使用Docker如何部署ElasticSearch:6.8.4 版本,讲解了从Docker拉取到最终运行ElasticSearch 以及 安装 ElasticSearch-Head 用来管理ElasticSearch相关信息的一个小工具,本博客系统首页的搜索正是使用了ElasticSearch来实现的,由于ElasticSearch 更新太快 以至于SpringData-ElasticSearch都跟不上 Es的更新 我也是一开始下载8.x的版本 导致SpringData-ElasticSearch 报错 最终我选择了6.8.4 在此记录一下
1.Docker部署ElasticSearch:6.8.4版本
1.1 拉取镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.8.4
1.2 运行容器
ElasticSearch的默认端口是9200,我们把宿主环境9200端口映射到Docker容器中的9200端口,就可以访问到Docker容器中的ElasticSearch服务了,同时我们把这个容器命名为es。
docker run -d --name es -p 9200:9200 -p 9300:9300
-e "discovery.type=single-node"
-e ES_JAVA_OPTS="-Xms=256m -Xms=256m"
docker.elastic.co/elasticsearch/elasticsearch:6.8.4
说明:
-e discovery.type=single-node :表示单节点启动
-e ES_JAVA_OPTS="-Xms=256m -Xms=256m" :表示设置es启动的内存大小,这个真的要设置,不然后时候会内存不够,比如我自己的辣鸡服务器!
1.3 内存不足问题
centos下载完elasticsearch并修改完配置后运行docker命令:
发现没有启动成功,去除命令的-d后打印错误如下
Java HotSpot(TM) 64-Bit Server VM warning: INFO:
os::commit_memory(0x0000000085330000, 2060255232, 0) failed;
error=’Cannot allocate memory’ (errno=12)
经过一番查找发现这是由于elasticsearch6.0默认分配jvm空间大小为2g,内存不足以分配导致。
解决方法就是修改jvm空间分配
运行命令:
find /var/lib/docker/overlay/ -name jvm.options
查找jvm.options文件,找到后进入使用vi命令打开jvm.options如下:
将
-Xms2g
-Xmx2g
修改为
-Xms512m
-Xmx512m
保存退出即可。再次运行创建运行elasticsearch命令,成功启动。
2.Docker部署ElasticSearch-Heard
2.1 拉取镜像
docker pull mobz/elasticsearch-head:52.2 运行容器
docker create --name elasticsearch-head -p 9100:9100 mobz/elasticsearch-head:5
2.3 启动容器
docker start elasticsearch-head
2.4 打开浏览器: http://IP:9100
发现连接不上,是因为有跨域问题,因为前后端分离开发的所以需要设置一下es
2.5 进入刚刚启动的 es 容器,容器name = es
docker exec -it es /bin/bash
2.6 修改elasticsearch.yml文件
vi config/elasticsearch.yml
添加
http.cors.enabled: true
http.cors.allow-origin: "*"
其实就是SpringBoot的yml文件 添加跨域支持
2.7 退出容器 并重启
exit
docker restart es
2.8 访问http://localhost:9100

总结:
本篇只是简单的讲解了如何用Docker安装ElasticSearch 并且会遇到的坑,包括内存不足,或者版本太高等问题,以及ElasticSearch-Heard的安装和跨域的配置 ,下一篇将讲解ElasticSearch如何安装中文分词器
个人博客网站 https://www.askajohnny.com 欢迎来访问!
本文由博客一文多发平台 OpenWrite 发布!

Docker部署ElasticSearch和ElasticSearch-Head的实现
本篇主要讲解使用Docker如何部署ElasticSearch:6.8.4 版本,讲解了从Docker拉取到最终运行ElasticSearch 以及 安装 ElasticSearch-Head 用来管理ElasticSearch相关信息的一个小工具,本博客系统首页的搜索正是使用了ElasticSearch来实现的,由于ElasticSearch 更新太快 以至于SpringData-ElasticSearch都跟不上 Es的更新 我也是一开始下载8.x的版本 导致SpringData-ElasticSearch 报错 最终我选择了6.8.4 在此记录一下
1.Docker部署ElasticSearch:6.8.4版本
1.1 拉取镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.8.4
1.2 运行容器
ElasticSearch的默认端口是9200,我们把宿主环境9200端口映射到Docker容器中的9200端口,就可以访问到Docker容器中的ElasticSearch服务了,同时我们把这个容器命名为es。
docker run -d --name es -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms=256m -Xms=256m" docker.elastic.co/elasticsearch/elasticsearch:6.8.4
说明:
-e discovery.type=single-node :表示单节点启动
-e ES_JAVA_OPTS="-Xms=256m -Xms=256m" :表示设置es启动的内存大小,这个真的要设置,不然后时候会内存不够,比如我自己的辣鸡服务器!
1.3 内存不足问题
centos下载完elasticsearch并修改完配置后运行docker命令:
发现没有启动成功,去除命令的-d后打印错误如下
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x0000000085330000, 2060255232, 0) failed; error=''Cannot allocate memory'' (errno=12)
经过一番查找发现这是由于elasticsearch6.0默认分配jvm空间大小为2g,内存不足以分配导致。
解决方法就是修改jvm空间分配
运行命令:
find /var/lib/docker/overlay/ -name jvm.options 查找jvm.options文件,找到后进入使用vi命令打开jvm.options如下: 将 -Xms2g -Xmx2g 修改为 -Xms512m -Xmx512m
保存退出即可。再次运行创建运行elasticsearch命令,成功启动。
2.Docker部署ElasticSearch-Heard
2.1 拉取镜像
docker pull mobz/elasticsearch-head:5
2.2 运行容器
docker create --name elasticsearch-head -p 9100:9100 mobz/elasticsearch-head:5
2.3 启动容器
docker start elasticsearch-head
2.4 打开浏览器: http://IP:9100
发现连接不上,是因为有跨域问题,因为前后端分离开发的所以需要设置一下es
2.5 进入刚刚启动的 es 容器,容器name = es
docker exec -it es /bin/bash
2.6 修改elasticsearch.yml文件
vi config/elasticsearch.yml
添加
http.cors.enabled: true http.cors.allow-origin: "*"
其实就是SpringBoot的yml文件 添加跨域支持
2.7 退出容器 并重启
exit docker restart es
2.8 访问http://localhost:9100

总结:
本篇只是简单的讲解了如何用Docker安装ElasticSearch 并且会遇到的坑,包括内存不足,或者版本太高等问题,以及ElasticSearch-Heard的安装和跨域的配置 ,下一篇将讲解ElasticSearch如何安装中文分词器
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
- Docker安装ElasticSearch和Kibana的问题及处理方法
- docker安装Elasticsearch7.6集群并设置密码的方法步骤
- 一文搞定Docker安装ElasticSearch的过程
- 在Docker中安装Elasticsearch7.6.2的教程
- 教你使用docker安装elasticsearch和head插件的方法

Elastic 网络研讨会 - Elasticsearch 大数据搜索和分析应用
Elasticsearch 在当今大数据搜索和分析领域热度非常之高,稳居 DB-Engine 搜索引擎排行榜首,本次研讨会为你讲解 Elasticsearch 搜索能力的演进,强大的搜索和聚合能力,适用的大数据应用场景,和 Hadoop 生态的配合使用,使用高级安全特性保护您的大数据安全。并邀请我们合作伙伴云科凯创介绍相关行业应用案
预约报名

演讲者:朱杰
Jerry 现在是 Elastic 解决方案架构师,专注于 Elastic Stack 的解决方案的设计和咨询。在加入 Elastic 之前,Jerry 有十五年软件开发经验,涉及服务器端程序、Web、移动开发等多个领域。在大数据分析领域也有十年实践经验,熟悉 Hadoop 生态、Elastic Stack。

演讲者:李季
北京云科创凯信息技术有限公司董事长兼 CEO,公司创始人,保险业务专家,计算机技术专家。曾在 PICC 总部研发中心任主管项目经理,负责保险核心业务系统研发管理工作。10 年 + 信息技术公司运营管理经验。
今天关于随机顺序和分页Elasticsearch和随机分页不重复的讲解已经结束,谢谢您的阅读,如果想了解更多关于docker 部署 elasticsearch + elasticsearch-head + elasticsearch-head 跨域问题 + IK 分词器、Docker部署ElasticSearch和ElasticSearch-Head、Docker部署ElasticSearch和ElasticSearch-Head的实现、Elastic 网络研讨会 - Elasticsearch 大数据搜索和分析应用的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

