在这篇文章中,我们将为您详细介绍请求将其他两个请求的结果与SQLServer2005中的GROUPBY子句一起加入的内容,并且讨论关于写出将请求转发到服务器上的welcome.jsp的语句的相关问题。
在这篇文章中,我们将为您详细介绍请求将其他两个请求的结果与SQL Server 2005中的GROUP BY子句一起加入的内容,并且讨论关于写出将请求转发到服务器上的welcome.jsp的语句的相关问题。此外,我们还会涉及一些关于jmeter 如何将上一个请求的结果作为下一个请求的参数――使用正则提取器、JMeter 如何把上一个请求的结果作为下一个请求的参数 —— 使用正则提取器、jmeter如何将上一个请求的结果作为下一个请求的参数——使用正则提取器、Mysql查询语句的 where子句、group by子句、having子句、order by子句、limit子句的知识,以帮助您更全面地了解这个主题。
本文目录一览:- 请求将其他两个请求的结果与SQL Server 2005中的GROUP BY子句一起加入(写出将请求转发到服务器上的welcome.jsp的语句)
- jmeter 如何将上一个请求的结果作为下一个请求的参数――使用正则提取器
- JMeter 如何把上一个请求的结果作为下一个请求的参数 —— 使用正则提取器
- jmeter如何将上一个请求的结果作为下一个请求的参数——使用正则提取器
- Mysql查询语句的 where子句、group by子句、having子句、order by子句、limit子句
")
请求将其他两个请求的结果与SQL Server 2005中的GROUP BY子句一起加入(写出将请求转发到服务器上的welcome.jsp的语句)
我经常发现自己在sql server 2005中按照以下几行做一些事情:
步骤1:
create view view1 as select count(*) as delivery_count, clientid from deliveries group by clientid;第2步:
create view view2 as select count(*) as action_count, clientid from routeactions group by clientid;第三步:
select * from view1 inner join view2 on view1.clientid = view2.clientid是否可以仅通过一条语句获得相同的最终结果,而避免创建视图?
答案1
当然,请使用嵌套查询:
select *from (select count(*) as delivery_count, clientid from deliveries group by clientid) AS view1inner join (select count(*) as action_count, clientid from routeactions group by clientid) AS view2 on view1.clientid = view2.clientid或者使用新的CTE语法,您可以:
WITH view1 AS ( select count(*) as delivery_count, clientid from deliveries group by clientid), view2 AS ( select count(*) as action_count, clientid from routeactions group by clientid)select * from view1 inner join view2 on view1.clientid = view2.clientid
jmeter 如何将上一个请求的结果作为下一个请求的参数――使用正则提取器
1、简介
Apache JMeter是Apache组织开发的基于Java的压力测试工具。用于对软件做压力测试,它最初被设计用于Web应用测试但后来扩展到其他测试领域。 它可以用于测试静态和动态资源例如静态文件、Java小服务程序、CGI 脚本、Java 对象、数据库, FTP 服务器, 等等。JMeter 可以用于对服务器、网络或对象模拟巨大的负载,来自不同压力类别下测试它们的强度和分析整体性能。另外,JMeter能够对应用程序做功能/回归测试,通过创建带有断言的脚本来验证你的程序返回了你期望的结果。为了最大限度的灵活性,JMeter允许使用正则表达式创建断言。
Apache jmeter 可以用于对静态的和动态的资源(文件,Servlet,Perl脚本,java 对象,数据库和查询,FTP服务器等等)的性能进行测试。它可以用于对服务器,网络 或对象模拟繁重的负载来测试它们的强度或分析不同压力类型下的整体性能。你可以使用它做性能的图形分析或在大并发负载测试你的服务器/脚本/对象。
2、用途
1.能够对HTTP和FTP服务器进行压力和性能测试, 也可以对任何数据库进行同样的测试(通过JDBC)。
2.完全的可移植性和100% 纯java。
3.完全 Swing 和轻量组件支持(预编译的JAR使用 javax.swing.*)包。
4.完全多线程 框架允许通过多个线程并发取样和 通过单独的线程组对不同的功能同时取样。
5.精心的GUI设计允许快速操作和更精确的计时。
6.缓存和离线分析/回放测试结果。
3、下载、简单应用
下载、简单应用可参照:http://www.cnblogs.com/0201zcr/p/5046193.html
4、如何将上一个请求的结果作为下一个请求的参数
在压力测试的时候,经常要将几个流程串联起来才能将程序测试通过。如:我现在用户首先要登录,获得我登录的凭证(tokenId),之后我的请求其他的资源的时候需要带上这个凭证。才能识别你是否是合法的用户。
1)、创建一个线程租
 30172256135-1264294797.png">
30172256135-1264294797.png">
2)、创建一个获取凭证的请求
30172758104-1954551713.png">
3)、创建后置处理器
JMeter GUI 视图中右击该采样器打开右键菜单 -> 添加 -> 后置处理器 -> 正则表达式提取器,打开"正则表达式提取器"会话页面并编辑其内容如下:
后置处理器是当这个请求返回后要做得事情,我这里是要从返回的内容中将我们要的tokenId获取出来。这里使用“正则表达式提取器”,用正则表达式,将我们要的内容获取出来。
30172916214-1312901607.png">
4)、正则表达式提取器配置
30173227417-201912192.png">
引用名称是下个请求将要引用到的变量名;
正则表达式是提取你想要内容的正则表达式,小括号()表示提取,也就是说对于你想要提取的内容需要用它括起来;
模板是使用提取到的第几个值。因为可能有多个值匹配,所以要使用模板。从 1 开始匹配,依次类推。这里只有一个,所以填写 $1$ 即可;
匹配数字表示如何取值。0 代表随机取值,1 代表全部取值。这里只有一个,填 1 即可;
缺省值表示参数没有取到值的话,默认给它的值。一般不填。
这个请求返回的数据如下:
{"message":"success","statusCode":200,"registerDay":"20","tokenId":"bf1017bc1bb495ae31764b306a3422885f5"}
我们现在要获取的是上面这个json字符串中tokenId的值,即 bf1017bc1bb495ae31764b306a3422885f5 。
5)、添加下一个请求
在这个请求中,我们要将上面的tokenId作为一个参数一并发送。
同上2)、添加一个http请求(线程租右键――》添加――》Sampler――》HTTP请求)
30174402448-1317616101.png">
6)、添加查看结果树
30174507182-1643117876.png">
7)、执行后,即可通过”查看结果树“查询
30174725948-1350995317.png">
致谢:感谢您的阅读!

JMeter 如何把上一个请求的结果作为下一个请求的参数 —— 使用正则提取器
有这样一个压力测试环境,有一个上传页面,上传成功之后服务器会返回一些上传信息(比如文件的 id 或者保存路径之类的信息),然后压力机会继续下一个请求,比如调整 id 为 xx 的文件的一些信息等等。问题来了:JMeter 是不知道上传后文件的 id 的,第二个请求势必从第一个请求的返回结果中提取出文件 id,然后依此为参数发起第二次请求。那么 JMeter 如何把上一个请求的结果作为下一个请求的参数呢?本文将介绍如何使用正则提取器解决这个问题。1. 提参采样器添加正则表达式提取器
比如上传采样器是 /upload/batchImport/merAdd/20141124/1(因为我们需要从其返回数据中提取我们需要的参数,本文我们称之为"提参采样器"),文件修改请求采样器是 /merServPlat/merInfo/import/add.json(因为它将要使用我们提取的参数,即参数化,本文我们称之为"用参采样器")。
/upload/batchImport/merAdd/20141124/1 上传文件成功之后,服务器会返回 /batchImport/merAdd/20141124/1/201411201455.xls:
JMeter GUI 视图中右击该采样器打开右键菜单 -> 添加 -> 后置处理器 -> 正则表达式提取器,打开"正则表达式提取器"会话页面并编辑其内容如下:
- 引用名称是 /merServPlat/merInfo/import/add.json 请求将要引用到的变量名;
- 正则表达式是提取你想要内容的正则表达式,小括号()表示提取,也就是说对于你想要提取的内容需要用它括起来;
- 模板是使用提取到的第几个值。因为可能有多个值匹配,所以要使用模板。从 1 开始匹配,依次类推。这里只有一个,所以填写 $1$ 即可;
- 匹配数字表示如何取值。0 代表随机取值,1 代表全部取值。这里只有一个,填 1 即可;
- 缺省值表示参数没有取到值的话,默认给它的值。一般不填。
比如文件修改请求采样器 /merServPlat/merInfo/import/add.json 的请求是 /merServPlat/merInfo/import/add.json?file=%2FbatchImport%2FmerAdd%2F20141124%2F1%2F0000000.xls。
中间带有的 %2F 是将 / 转义处理。我们只需要把第一步提取到的参数放进去即可:/merServPlat/merInfo/import/add.json?file=%2FbatchImport%2FmerAdd%2F20141124%2F1%2F${anycall}.xls
3. 添加 Debug Sampler 以对正则提取器进行调试
JMeter GUI 视图中右击 Thread Group 打开其右键菜单 -> 添加 -> Sampler -> Debug Sampler。
4. 添加察看结果树以监听观测执行情况
JMeter GUI 视图中右击 Thread Group 打开其右键菜单 -> 添加 -> 监听器 -> 察看结果树
5. 执行线程组以调试验证正则提取器
CTRL + R 执行线程组,察看结果树的相关报告如下。
提参采样器 /upload/batchImport/merAdd/20141124/1 响应数据:
用参采样器 /merServPlat/merInfo/import/add.json 的请求:
Debug Sampler 的跟踪情况:
证明我们的正则表达式提取参数成功。
后记
除了正则提取器,对于返回结果为 xml 或者 json 内容的请求,JMeter 分别有 XPath Extractor、JSON Path Extractor 等提取器进行提取。
参考资料
- http://jmeter.apache.org/usermanual/regular_expressions.html
- http://blazemeter.com/blog/using-xpath-extractor-jmeter-0

jmeter如何将上一个请求的结果作为下一个请求的参数——使用正则提取器
转载地址:
http://www.cnblogs.com/0201zcr/p/5089620.html
http://www.cnblogs.com/whitewasher/p/6762793.html
相关搜索:https://www.baidu.com/s?ie=UTF-8&wd=Jmeter%E5%A6%82%E4%BD%95%E5%B0%86%E4%B8%8A%E4%B8%80%E4%B8%AA%E8%AF%B7%E6%B1%82%E7%9A%84%E7%BB%93%E6%9E%9C%E4%BD%9C%E4%B8%BA%E4%B8%8B%E4%B8%80%E4%B8%AA%E8%AF%B7%E6%B1%82%E7%9A%84%E5%8F%82%E6%95%B0
【第一篇】
1、简介
- 引用名称是下个请求将要引用到的变量名;
- 正则表达式是提取你想要内容的正则表达式,小括号()表示提取,也就是说对于你想要提取的内容需要用它括起来;
- 模板是使用提取到的第几个值。因为可能有多个值匹配,所以要使用模板。从 1 开始匹配,依次类推。这里只有一个,所以填写 $1$ 即可;
- 匹配数字表示如何取值。0 代表随机取值,1 代表全部取值。这里只有一个,填 1 即可;
- 缺省值表示参数没有取到值的话,默认给它的值。一般不填。
这个请求返回的数据如下:
{"message":"success","statusCode":200,"registerDay":"20","tokenId":"bf1017bc1bb495ae31764b306a3422885f5"}
正则表达式提取器是一个后置处理器,作用是在请求完成后,从响应数据中截取一部分字符串保存到变量中,以便下一个请求使用,下面我们就来做一个简单的例子吧
1.首先在线程组下添加两个HTTP请求,
2.添加好两个HTTP请求后,在每个HTTP请求下添加一个查看结果数
3.在第一个HTTP请求下添加正则表达式提取器
4.在第一个HTTP请求添加好IP地址,路径,端口号,协议,方法,如果有参数,还需要添加参数,我这里没有参数所以就不添加了
5.点击绿色箭头启动,查看第一个HTTP请求完成后的响应数据
6.第一个HTTP请求完成后的响应数据的url是随机变化的,每次HTTP请求完成后的响应数据的url是不同的,现在需要获取第一个HTTP请求完成后的响应数据的url作为第二个HTTP请求的IP地址,这个时候就需要用到正则表达式提取器,正则表达式提取器是一个后置处理器,作用是在请求完成后,从响应数据中截取一部分字符串保存到变量中,以便下一个请求使用。
7.现在编辑正则表达式提取器
8.说明:
(1)引用名称:作为下一个请求要引用的参数名称,如填写myurl,则可用${myurl}引用它来作为第二个HTTP请求的IP地址
(2)正则表达式用""包起来,如第一个HTTP请求完成后的响应数据{"status":"ok","message":"创建房间成功","data":{"url":"https://www.pp2pp.xyz/room/58ff022f5cd4c32ae9a7f457"}} 我们只需要URL,所以正则表达式为 "url":"https://(.+?)"
() 表示括起来的部分就是要提取的。

Mysql查询语句的 where子句、group by子句、having子句、order by子句、limit子句
Mysql的各个查询语句
一、where子句
语法:select *|字段列表 from 表名 where 表达式。where子句后面往往配合MySQL运算符一起使用(做条件判断)
作用:通过限定的表达式的条件对数据进行过滤,得到我们想要的结果。
1.MYSQL运算符:
MySQL支持以下的运算符:
关系运算符
< >
<= >=
= !=(<>)
注意:这里的等于是一个等号
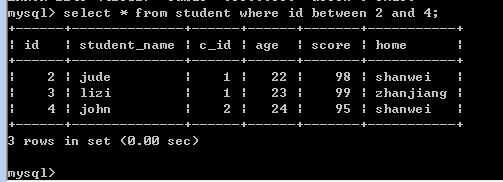
between and
做数值范围限定,相当于数学上的闭区间!
比如:
between A and B相当于 [A,B]
in和not in
语法形式:in|not in(集合)
表示某个值出现或没出现在一个集合之中!

逻辑运算符
&& and
|| or
! not

where子句的其他形式
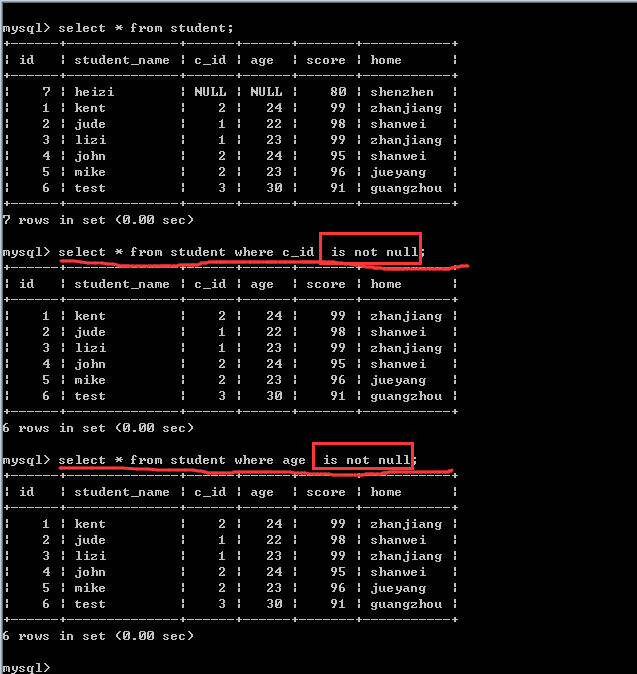
空值查询
select *|字段列表 from 表名 where 字段名 is [not] null
模糊查询
也就是带有like关键字的查询,常见的语法形式是:
select *|字段列表from 表名 where 字段名 [not] like ‘通配符字符串’;
所谓的通配符字符串,就是含有通配符的字符串!
MySQL中的通配符有两个:
_ :代表任意的单个字符
% :代表任意的字符
案例一:
查找student表中student_name字段以“j”开头的学生信息!

案例二:
查找student表中student_name字段以“j”开头以“n”结尾的学生信息!
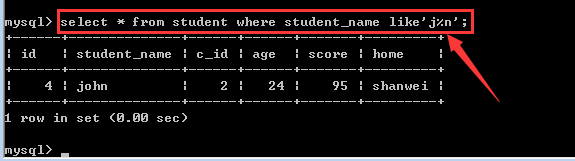
案例三:
查找student表中student_name字段含有“n”字的学生信息
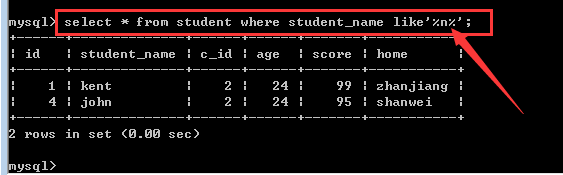
案例四:
查找student表中student_name以“j”开头含有四个字母的名字的学生信息

案例五:
查找student表中stu_name含有_或含有%的学生信息
由于%和_都具有特殊的含义,所以如果确实想查询某个字段中含有%或_的记录,需要对它们进行转义!
也就是查找 \_ 和 \%

二、group by子句
也叫作分组统计查询语句!
语法
group by 字段1[,字段2]……
从形式上看,就是通过表内的某个或某些字段进行分组:
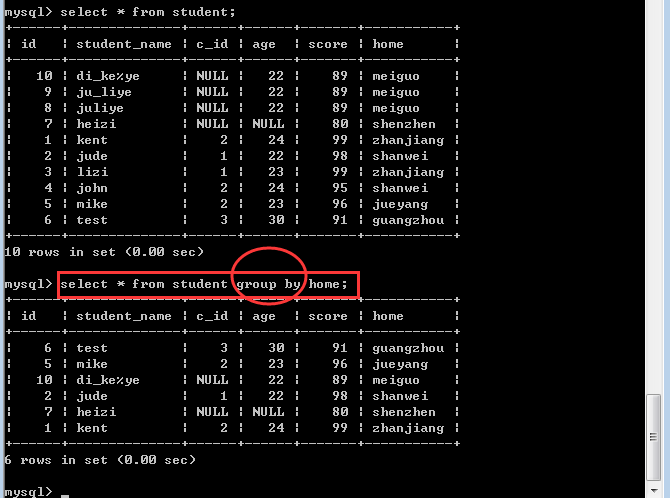
所以,分组之后,只会从每一个组内取出第一条记录,这种查询结果毫无意义!
因为分组统计查询的主要作用不是分组,而是统计!或者说分组的目的就是针对每一个分组进行相关的统计!
此时,就需要使用系统中的一些统计函数!
统计函数(聚合函数)
sum():求和,就是将某个分组内的某个字段的值全部相加

等于做了以前的两件事情:
1, 先按home字段对整个的表进行分组!(分成了4组)
2, 再把每一个组内的所有记录的age字段的值全部相加

max():求某个组内某个字段的最大值
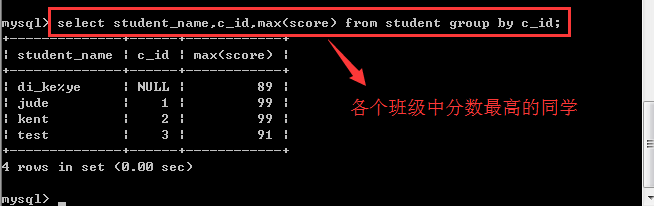
min():求某个组内某个字段的最小值

avg():求某个组内某个字段的平均值
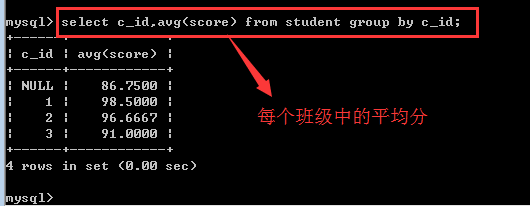
count():统计某个组内非null记录的个数,通常就是用count(*)来表示!


注意:
统计函数都是可以单独的使用的!但是,只要使用统计函数,系统默认的就是需要分组,如果没有group by子句,默认的就是把整个表中的数据当成一组!
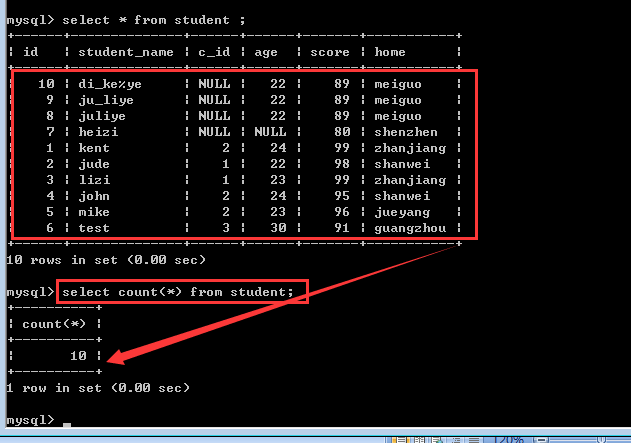
多字段分组
group by 字段1[,字段2]……
作用是:先根据字段1进行分组,然后再根据字段2进行分组!

所以,多字段分组的结果就是分组变多了!
回溯(su)统计
回溯统计就是向上统计!
在进行分组统计的时候,往往需要做上级统计!
比如,先统计各个班的总人数,然后各个班的总人数再相加,就可以得到一个年级的总人数!
再比如,先统计各个班的最高分,然后各个班的最高分再进行比较,就可以得到一个年级的最高分!
如何实现?
答:在MySQL中,其实就是在语句的后面加上with rollup即可!

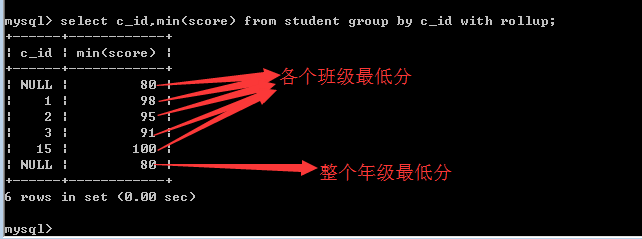

注意:
既然group by子句出现在where子句之后,说明了,我们可以先将整个数据源进行筛选,然后再进行分组统计!
三、having子句
having子句和where子句一样,也是用来筛选数据的,通常是对group by之后的统计结果再次进行筛选!

那么,having子句和where子句到底有什么区别呢?
二者的比较:
1, 如果语句中只有having子句或只有where子句的时候,此时,它们的作用基本是一样的!
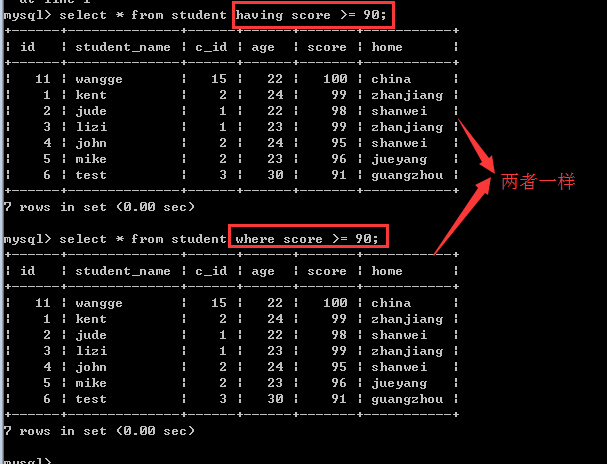
2, 二者的本质区别是:where子句是把磁盘上的数据筛选到内存上,而having子句是把内存中的数据再次进行筛选!
3, where子句的后面不能使用统计函数,而having子句可以!因为只有在内存中的数据才可以进行运算统计!

四、order by子句
语法
根据某个字段进行排序,有升序和降序!
语法形式为:
order by 字段1[asc|desc]
默认的是asc,也就是升序!如果要降序排序,需要加上desc!
①根据id排序

②根据成绩排序
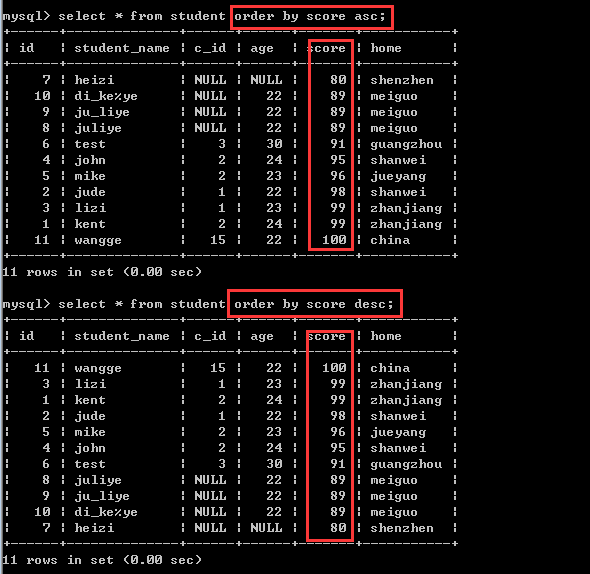
思考:
假如现在有若干个学生的成绩score是一样的,怎么办?
此时,可以使用多字段排序!
多字段排序
order by 字段1[asc|desc],字段2[asc|desc]……
比如:order by score asc,age desc
也就是说,先按分数进行升序排序,如果分数一样的时候,再按年龄进行降序排序!
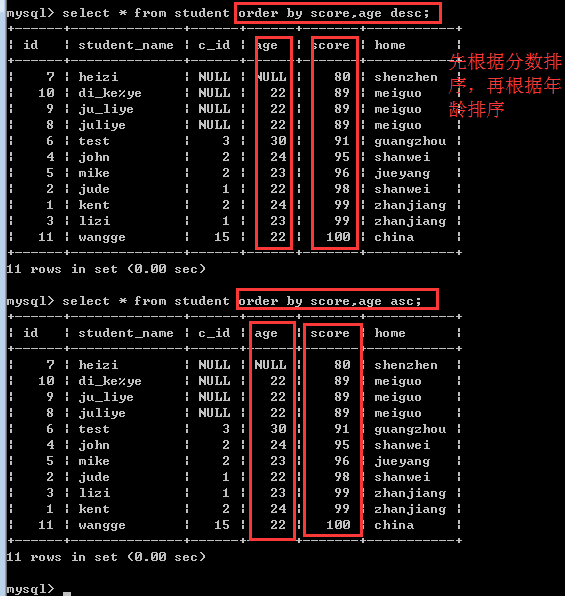
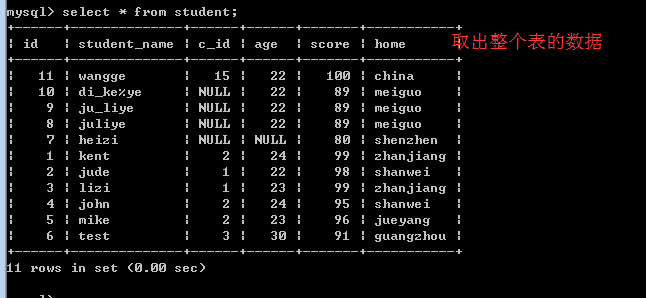
五、limit子句
limit就是限制的意思,所以,limit子句的作用就是限制查询记录的条数!
语法
limit offset,length
其中,offset是指偏移量,默认为0,而length是指需要显示的记录数!
思考:
limit子句为什么排在最后?
因为前面所有的限制条件都处理完了,只剩下需要显示多少条记录的问题了!
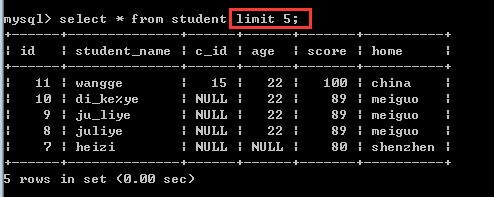
思考:
假如现在想显示记录的第4条到第8条,limit子句应该怎么写?
limit 3,5;

注意:这里的偏移量offset可以省略的!缺省值就代表0!
分页原理
假如在项目中,需要使用分页的效果,就应该使用limit子句!
比如,每页显示10条记录:
第1页:limit 0,10
第2页:limit 10,10
第3页:limit 20,10
如果用$pageNum代表第多少页,用$rowsPerPage代表每页显示的长度
limit ($pageNum - 1)*$rowsPerPage, $rowsPerPage
今天的关于请求将其他两个请求的结果与SQL Server 2005中的GROUP BY子句一起加入和写出将请求转发到服务器上的welcome.jsp的语句的分享已经结束,谢谢您的关注,如果想了解更多关于jmeter 如何将上一个请求的结果作为下一个请求的参数――使用正则提取器、JMeter 如何把上一个请求的结果作为下一个请求的参数 —— 使用正则提取器、jmeter如何将上一个请求的结果作为下一个请求的参数——使用正则提取器、Mysql查询语句的 where子句、group by子句、having子句、order by子句、limit子句的相关知识,请在本站进行查询。
本文标签:




