本文的目的是介绍Win下执行kettle的trans和job的批处理示例的详细情况,特别关注kettle执行ktr的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您呈现一个全面的了解Wi
本文的目的是介绍Win下执行kettle的trans和job的批处理示例的详细情况,特别关注kettle执行ktr的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您呈现一个全面的了解Win下执行kettle的trans和job的批处理示例的机会,同时也不会遗漏关于.net中的CreateJobObject / SetInformationJobObject pinvoke的工作示例?、android view之getLeft(),getRight(),getTop(),getBottom(),getX(),getY(),getRawX(),getRawY(),getTrans...、ETL 技术 (Extract-Transform-Load) 数据仓库技术 - 比如 kettle、Flink1.7.2 sql 批处理示例的知识。
本文目录一览:- Win下执行kettle的trans和job的批处理示例(kettle执行ktr)
- .net中的CreateJobObject / SetInformationJobObject pinvoke的工作示例?
- android view之getLeft(),getRight(),getTop(),getBottom(),getX(),getY(),getRawX(),getRawY(),getTrans...
- ETL 技术 (Extract-Transform-Load) 数据仓库技术 - 比如 kettle
- Flink1.7.2 sql 批处理示例
")
Win下执行kettle的trans和job的批处理示例(kettle执行ktr)
第一步:定义一个trans示例

第二步:做成bat批处理文件,如下:
set panpath=C:\pdi-ce-5.4.0.1-130\data-integration
set kpath=D:\03works\ZYWSPT\kettle
c:
cd %panpath%
pan /file %kpath%\test.ktr
注意:等号的两边不能有空格,不然,会出错。
第三步:定义计划任务

单独创建一个文件夹,存放个人的计划任务

按步骤提示完成。
收工!

.net中的CreateJobObject / SetInformationJobObject pinvoke的工作示例?
我正在努力拼凑一个拼凑的CreateJobObject和SetInformationJobObject的工作示例。通过各种Google搜索(包括俄语和中文帖子!),我将以下代码拼凑在一起。我认为JOBOBJECT_BASIC_LIMIT_INFORMATION的定义根据平台(32/64位)而变化。CreateJobObject
/ AssignProcessToJobObject 似乎 可以工作。SetInformationJobObject失败-错误24或87。
Process myProcess // POPULATED SOMEWHERE ELSE// Create Job & assign this process and another process to the jobIntPtr jobHandle = CreateJobObject( null , null );AssignProcessToJobObject( jobHandle , myProcess.Handle );AssignProcessToJobObject( jobHandle , Process.GetCurrentProcess().Handle );// Ensure that killing one process kills the others JOBOBJECT_BASIC_LIMIT_INFORMATION limits = new JOBOBJECT_BASIC_LIMIT_INFORMATION();limits.LimitFlags = (short)LimitFlags.JOB_OBJECT_LIMIT_KILL_ON_JOB_CLOSE;IntPtr pointerToJobLimitInfo = Marshal.AllocHGlobal( Marshal.SizeOf( limits ) );Marshal.StructureToPtr( limits , pointerToJobLimitInfo , false ); SetInformationJobObject( job , JOBOBJECTINFOCLASS.JobObjectBasicLimitInformation , pionterToJobLimitInfo , ( uint )Marshal.SizeOf( limits ) )... [DllImport( "kernel32.dll" , EntryPoint = "CreateJobObjectW" , CharSet = CharSet.Unicode )] public static extern IntPtr CreateJobObject( SecurityAttributes JobAttributes , string lpName ); public class SecurityAttributes { public int nLength; //Useless field = 0 public IntPtr pSecurityDescriptor; //хз)) public bool bInheritHandle; //Возможность наследования public SecurityAttributes() { this.bInheritHandle = true; this.nLength = 0; this.pSecurityDescriptor = IntPtr.Zero; } } [DllImport( "kernel32.dll" )] static extern bool SetInformationJobObject( IntPtr hJob , JOBOBJECTINFOCLASS JobObjectInfoClass , IntPtr lpJobObjectInfo , uint cbJobObjectInfoLength ); public enum JOBOBJECTINFOCLASS { JobObjectAssociateCompletionPortInformation = 7 , JobObjectBasicLimitInformation = 2 , JobObjectBasicUIRestrictions = 4 , JobObjectEndOfJobTimeInformation = 6 , JobObjectExtendedLimitInformation = 9 , JobObjectSecurityLimitInformation = 5 } [StructLayout( LayoutKind.Sequential )] struct JOBOBJECT_BASIC_LIMIT_INFORMATION { public Int64 PerProcessUserTimeLimit; public Int64 PerJobUserTimeLimit; public Int16 LimitFlags; public UIntPtr MinimumWorkingSetSize; public UIntPtr MaximumWorkingSetSize; public Int16 ActiveProcessLimit; public Int64 Affinity; public Int16 PriorityClass; public Int16 SchedulingClass; } public enum LimitFlags { JOB_OBJECT_LIMIT_ACTIVE_PROCESS = 0x00000008 , JOB_OBJECT_LIMIT_AFFINITY = 0x00000010 , JOB_OBJECT_LIMIT_BREAKAWAY_OK = 0x00000800 , JOB_OBJECT_LIMIT_DIE_ON_UNHANDLED_EXCEPTION = 0x00000400 , JOB_OBJECT_LIMIT_JOB_MEMORY = 0x00000200 , JOB_OBJECT_LIMIT_JOB_TIME = 0x00000004 , JOB_OBJECT_LIMIT_KILL_ON_JOB_CLOSE = 0x00002000 , JOB_OBJECT_LIMIT_PRESERVE_JOB_TIME = 0x00000040 , JOB_OBJECT_LIMIT_PRIORITY_CLASS = 0x00000020 , JOB_OBJECT_LIMIT_PROCESS_MEMORY = 0x00000100 , JOB_OBJECT_LIMIT_PROCESS_TIME = 0x00000002 , JOB_OBJECT_LIMIT_SCHEDULING_CLASS = 0x00000080 , JOB_OBJECT_LIMIT_SILENT_BREAKAWAY_OK = 0x00001000 , JOB_OBJECT_LIMIT_WORKINGSET = 0x00000001 } [DllImport( "kernel32.dll" )] [return: MarshalAs( UnmanagedType.Bool )] static extern bool AssignProcessToJobObject( IntPtr hJob , IntPtr hProcess ); [StructLayout( LayoutKind.Sequential )] public struct SECURITY_ATTRIBUTES { public int nLength; public IntPtr lpSecurityDescriptor; public int bInheritHandle; }答案1
小编典典这可能会晚一点,但仍然如此。
我在这里尝试了所有示例,但是没有人同时在32位和64位模式下为我工作。最后,我需要亲自检查所有签名并创建相应的PInvoke例程。我认为,其他人可能会发现这很有帮助。
免责声明:解决方案基于 Matt Howells的答案。
using System;using System.Diagnostics;using System.Runtime.InteropServices;namespace JobManagement{ public class Job : IDisposable { [DllImport("kernel32.dll", CharSet = CharSet.Unicode)] static extern IntPtr CreateJobObject(IntPtr a, string lpName); [DllImport("kernel32.dll")] static extern bool SetInformationJobObject(IntPtr hJob, JobObjectInfoType infoType, IntPtr lpJobObjectInfo, UInt32 cbJobObjectInfoLength); [DllImport("kernel32.dll", SetLastError = true)] static extern bool AssignProcessToJobObject(IntPtr job, IntPtr process); [DllImport("kernel32.dll", SetLastError = true)] [return: MarshalAs(UnmanagedType.Bool)] static extern bool CloseHandle(IntPtr hObject); private IntPtr handle; private bool disposed; public Job() { handle = CreateJobObject(IntPtr.Zero, null); var info = new JOBOBJECT_BASIC_LIMIT_INFORMATION { LimitFlags = 0x2000 }; var extendedInfo = new JOBOBJECT_EXTENDED_LIMIT_INFORMATION { BasicLimitInformation = info }; int length = Marshal.SizeOf(typeof(JOBOBJECT_EXTENDED_LIMIT_INFORMATION)); IntPtr extendedInfoPtr = Marshal.AllocHGlobal(length); Marshal.StructureToPtr(extendedInfo, extendedInfoPtr, false); if (!SetInformationJobObject(handle, JobObjectInfoType.ExtendedLimitInformation, extendedInfoPtr, (uint)length)) throw new Exception(string.Format("Unable to set information. Error: {0}", Marshal.GetLastWin32Error())); } public void Dispose() { Dispose(true); GC.SuppressFinalize(this); } private void Dispose(bool disposing) { if (disposed) return; if (disposing) { } Close(); disposed = true; } public void Close() { CloseHandle(handle); handle = IntPtr.Zero; } public bool AddProcess(IntPtr processHandle) { return AssignProcessToJobObject(handle, processHandle); } public bool AddProcess(int processId) { return AddProcess(Process.GetProcessById(processId).Handle); } } #region Helper classes [StructLayout(LayoutKind.Sequential)] struct IO_COUNTERS { public UInt64 ReadOperationCount; public UInt64 WriteOperationCount; public UInt64 OtherOperationCount; public UInt64 ReadTransferCount; public UInt64 WriteTransferCount; public UInt64 OtherTransferCount; } [StructLayout(LayoutKind.Sequential)] struct JOBOBJECT_BASIC_LIMIT_INFORMATION { public Int64 PerProcessUserTimeLimit; public Int64 PerJobUserTimeLimit; public UInt32 LimitFlags; public UIntPtr MinimumWorkingSetSize; public UIntPtr MaximumWorkingSetSize; public UInt32 ActiveProcessLimit; public UIntPtr Affinity; public UInt32 PriorityClass; public UInt32 SchedulingClass; } [StructLayout(LayoutKind.Sequential)] public struct SECURITY_ATTRIBUTES { public UInt32 nLength; public IntPtr lpSecurityDescriptor; public Int32 bInheritHandle; } [StructLayout(LayoutKind.Sequential)] struct JOBOBJECT_EXTENDED_LIMIT_INFORMATION { public JOBOBJECT_BASIC_LIMIT_INFORMATION BasicLimitInformation; public IO_COUNTERS IoInfo; public UIntPtr ProcessMemoryLimit; public UIntPtr JobMemoryLimit; public UIntPtr PeakProcessMemoryUsed; public UIntPtr PeakJobMemoryUsed; } public enum JobObjectInfoType { AssociateCompletionPortInformation = 7, BasicLimitInformation = 2, BasicUIRestrictions = 4, EndOfJobTimeInformation = 6, ExtendedLimitInformation = 9, SecurityLimitInformation = 5, GroupInformation = 11 } #endregion},getRight(),getTop(),getBottom(),getX(),getY(),getRawX(),getRawY(),getTrans...")
android view之getLeft(),getRight(),getTop(),getBottom(),getX(),getY(),getRawX(),getRawY(),getTrans...
自定义view时使经常使用到的view距离及坐标记录
如下
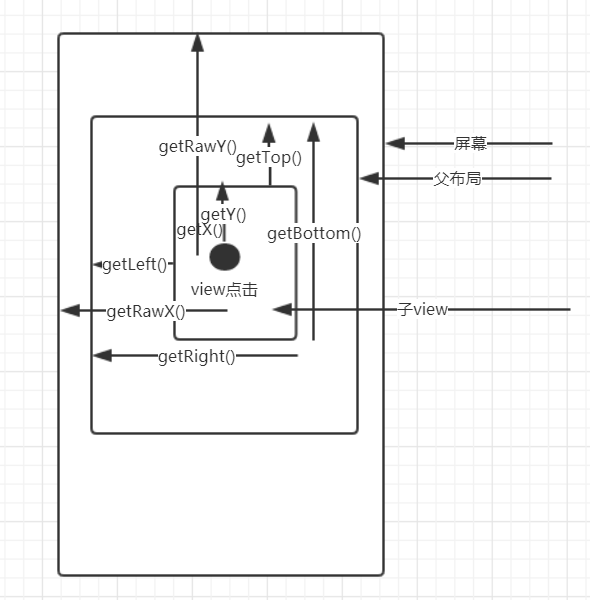
第一:view中一般用于获取view宽高
getLeft() view本身左侧 距离父布局左侧 的距离
getRight() view本身右侧 距离父布局左边侧 的距离
getTop() view本身顶部 距离父布局顶部 的距离
getBottom() view本身底部 距离父布局顶部 的距离
View的 Height = view.getBottom() - view.getTop();
View的 Width = view.getRight() - view.getLeft();
移动view时 可以通过变化 getLeft() getRight() getTop() getBottom() 改变view的位置
view.layout(left,top,right,bottom)
第二:MotionEvent当中的方法 doTouchEvent 点击view
getY() 点击事件距离view本身左边的距离
getY() 点击事件距离view本身顶边的距离
getRawX() 点击事件距离整个屏幕左边的距离
getRawY() 点击事件距离整个屏幕顶边的距离
一般用于move view时 通过移动的距离加getLeft等变更view的位置
第三:相对于view原始位置移动的偏移量
getTranslationX() 设置view横向移动的偏移距离
getTranslationY() 设置view竖向移动的偏移距离
 数据仓库技术 - 比如 kettle")
ETL 技术 (Extract-Transform-Load) 数据仓库技术 - 比如 kettle
每次面试,互联网的面试官,经常问我有没有用过 ETL, 每次我都懵逼,说没用过,觉得是多么高大上的东东,数据仓储
今天查了一下,我晕,自己天天用的 Kettle 就是最典型的 ETL,
可以实现不同数据库之间的数据抽取,转换,只需要你有相应的数据库 driver 即可
查了一下资料记录一下:
工具应用
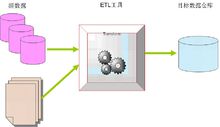
编辑体系结构
编辑ETL 架构
-
ETL 可以分担数据库系统的负载(采用单独的硬件服务器)
-
ETL 相对于 EL-T 架构可以实现更为复杂的数据转化逻辑
-
ETL 采用单独的硬件服务器。.
-
ETL 与底层的数据库数据存储无关。
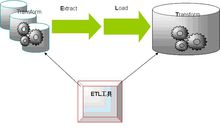
ELT 架构
-
ELT 主要通过数据库引擎来实现系统的可扩展性(尤其是当数据加工过程在晚上时,可以充分利用数据库引擎的资源)
-
ELT 可以保持所有的数据始终在数据库当中,避免数据的加载和导出,从而保证效率,提高系统的可监控性。
-
ELT 可以根据数据的分布情况进行并行处理优化,并可以利用数据库的固有功能优化磁盘 I/O。
-
ELT 的可扩展性取决于数据库引擎和其硬件服务器的可扩展性。
-
通过对相关数据库进行性能调优,ETL 过程获得 3 到 4 倍的效率提升一般不是特别困难。
注意事项
编辑特色功能
编辑管理简单
标准定义数据
拓展新型应用
ETL 是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。 ETL 是 BI 项目重要的一个环节。 通常情况下,在 BI 项目中 ETL 会花掉整个项目至少 1/3 的时间,ETL 设计的好坏直接关接到 BI 项目的成败。
ETL 的设计分三部分:数据抽取、数据的清洗转换、数据的加载。在设计 ETL 的时候我们也是从这三部分出发。数据的抽取是从各个不同的数据源抽取到 ODS (Operational Data Store,操作型数据存储) 中 —— 这个过程也可以做一些数据的清洗和转换),在抽取的过程中需要挑选不同的抽取方法,尽可能的提高 ETL 的运行效率。ETL 三个部分中,花费时间最长的是 “T”(Transform,清洗、转换) 的部分,一般情况下这部分工作量是整个 ETL 的 2/3。数据的加载一般在数据清洗完了之后直接写入 DW (Data Warehousing,数据仓库) 中去。
ETL 的实现有多种方法,常用的有三种。一种是借助 ETL 工具 (如 Oracle 的 OWB、SQL Server 2000 的 DTS、SQL Server2005 的 SSIS 服务、Informatic 等) 实现,一种是 SQL 方式实现,另外一种是 ETL 工具和 SQL 相结合。前两种方法各有各的优缺点,借助工具可以快速的建立起 ETL 工程,屏蔽了复杂的编码任务,提高了速度,降低了难度,但是缺少灵活性。SQL 的方法优点是灵活,提高 ETL 运行效率,但是编码复杂,对技术要求比较高。第三种是综合了前面二种的优点,会极大地提高 ETL 的开发速度和效率。
一、 数据的抽取(Extract)
这一部分需要在调研阶段做大量的工作,首先要搞清楚数据是从几个业务系统中来,各个业务系统的数据库服务器运行什么 DBMS, 是否存在手工数据,手工数据量有多大,是否存在非结构化的数据等等,当收集完这些信息之后才可以进行数据抽取的设计。
1、对于与存放 DW 的数据库系统相同的数据源处理方法
这一类数据源在设计上比较容易。一般情况下,DBMS (SQLServer、Oracle) 都会提供数据库链接功能,在 DW 数据库服务器和原业务系统之间建立直接的链接关系就可以写 Select 语句直接访问。
2、对于与 DW 数据库系统不同的数据源的处理方法
对于这一类数据源,一般情况下也可以通过 ODBC 的方式建立数据库链接 —— 如 SQL Server 和 Oracle 之间。如果不能建立数据库链接,可以有两种方式完成,一种是通过工具将源数据导出成.txt 或者是.xls 文件,然后再将这些源系统文件导入到 ODS 中。另外一种方法是通过程序接口来完成。
3、对于文件类型数据源 (.txt,.xls),可以培训业务人员利用数据库工具将这些数据导入到指定的数据库,然后从指定的数据库中抽取。或者还可以借助工具实现。
4、增量更新的问题
对于数据量大的系统,必须考虑增量抽取。一般情况下,业务系统会记录业务发生的时间,我们可以用来做增量的标志,每次抽取之前首先判断 ODS 中记录最大的时间,然后根据这个时间去业务系统取大于这个时间所有的记录。利用业务系统的时间戳,一般情况下,业务系统没有或者部分有时间戳。
二、数据的清洗转换(Cleaning、Transform)
一般情况下,数据仓库分为 ODS、DW 两部分。通常的做法是从业务系统到 ODS 做清洗,将脏数据和不完整数据过滤掉,在从 ODS 到 DW 的过程中转换,进行一些业务规则的计算和聚合。
1、 数据清洗
数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。
不符合要求的数据主要是有不完整的数据、错误的数据、重复的数据三大类。
(1) 不完整的数据:这一类数据主要是一些应该有的信息缺失,如供应商的名称、分公司的名称、客户的区域信息缺失、业务系统中主表与明细表不能匹配等。对于这一类数据过滤出来,按缺失的内容分别写入不同 Excel 文件向客户提交,要求在规定的时间内补全。补全后才写入数据仓库。
(2) 错误的数据:这一类错误产生的原因是业务系统不够健全,在接收输入后没有进行判断直接写入后台数据库造成的,比如数值数据输成全角数字字符、字符串数据后面有一个回车操作、日期格式不正确、日期越界等。这一类数据也要分类,对于类似于全角字符、数据前后有不可见字符的问题,只能通过写 SQL 语句的方式找出来,然后要求客户在业务系统修正之后抽取。日期格式不正确的或者是日期越界的这一类错误会导致 ETL 运行失败,这一类错误需要去业务系统数据库用 SQL 的方式挑出来,交给业务主管部门要求限期修正,修正之后再抽取。
(3) 重复的数据:对于这一类数据 —— 特别是维表中会出现这种情况 —— 将重复数据记录的所有字段导出来,让客户确认并整理。
数据清洗是一个反复的过程,不可能在几天内完成,只有不断的发现问题,解决问题。对于是否过滤,是否修正一般要求客户确认,对于过滤掉的数据,写入 Excel 文件或者将过滤数据写入数据表,在 ETL 开发的初期可以每天向业务单位发送过滤数据的邮件,促使他们尽快地修正错误,同时也可以做为将来验证数据的依据。数据清洗需要注意的是不要将有用的数据过滤掉,对于每个过滤规则认真进行验证,并要用户确认。
2、 数据转换
数据转换的任务主要进行不一致的数据转换、数据粒度的转换,以及一些商务规则的计算。
(1) 不一致数据转换:这个过程是一个整合的过程,将不同业务系统的相同类型的数据统一,比如同一个供应商在结算系统的编码是 XX0001, 而在 CRM 中编码是 YY0001,这样在抽取过来之后统一转换成一个编码。
(2) 数据粒度的转换:业务系统一般存储非常明细的数据,而数据仓库中数据是用来分析的,不需要非常明细的数据。一般情况下,会将业务系统数据按照数据仓库粒度进行聚合。
(3) 商务规则的计算:不同的企业有不同的业务规则、不同的数据指标,这些指标有的时候不是简单的加加减减就能完成,这个时候需要在 ETL 中将这些数据指标计算好了之后存储在数据仓库中,以供分析使用。
三、ETL 日志、警告发送
1、 ETL 日志
ETL 日志分为三类。
一类是执行过程日志,这一部分日志是在 ETL 执行过程中每执行一步的记录,记录每次运行每一步骤的起始时间,影响了多少行数据,流水账形式。
一类是错误日志,当某个模块出错的时候写错误日志,记录每次出错的时间、出错的模块以及出错的信息等。
第三类日志是总体日志,只记录 ETL 开始时间、结束时间是否成功信息。如果使用 ETL 工具,ETL 工具会自动产生一些日志,这一类日志也可以作为 ETL 日志的一部分。
记录日志的目的是随时可以知道 ETL 运行情况,如果出错了,可以知道哪里出错。
2、 警告发送
如果 ETL 出错了,不仅要形成 ETL 出错日志,而且要向系统管理员发送警告。发送警告的方式多种,一般常用的就是给系统管理员发送邮件,并附上出错的信息,方便管理员排查错误。
ETL 是 BI 项目的关键部分,也是一个长期的过程,只有不断的发现问题并解决问题,才能使 ETL 运行效率更高,为 BI 项目后期开发提供准确与高效的数据。
后记
做数据仓库系统,ETL 是关键的一环。说大了,ETL 是数据整合解决方案,说小了,就是倒数据的工具。回忆一下工作这么长时间以来,处理数据迁移、转换的工作倒还真的不少。但是那些工作基本上是一次性工作或者很小数据量。可是在数据仓库系统中,ETL 上升到了一定的理论高度,和原来小打小闹的工具使用不同了。究竟什么不同,从名字上就可以看到,人家已经将倒数据的过程分成 3 个步骤,E、T、L 分别代表抽取、转换和装载。
其实 ETL 过程就是数据流动的过程,从不同的数据源流向不同的目标数据。但在数据仓库中,
ETL 有几个特点,
一是数据同步,它不是一次性倒完数据就拉到,它是经常性的活动,按照固定周期运行的,甚至现在还有人提出了实时 ETL 的概念。
二是数据量,一般都是巨大的,值得你将数据流动的过程拆分成 E、T 和 L。
现在有很多成熟的工具提供 ETL 功能,且不说他们的好坏。从应用角度来说,ETL 的过程其实不是非常复杂,这些工具给数据仓库工程带来和很大的便利性,特别是开发的便利和维护的便利。但另一方面,开发人员容易迷失在这些工具中。举个例子,VB 是一种非常简单的语言并且也是非常易用的编程工具,上手特别快,但是真正 VB 的高手有多少?微软设计的产品通常有个原则是 “将使用者当作傻瓜”,在这个原则下,微软的东西确实非常好用,但是对于开发者,如果你自己也将自己当作傻瓜,那就真的傻了。ETL 工具也是一样,这些工具为我们提供图形化界面,让我们将主要的精力放在规则上,以期提高开发效率。从使用效果来说,确实使用这些工具能够非常快速地构建一个 job 来处理某个数据,不过从整体来看,并不见得他的整体效率会高多少。问题主要不是出在工具上,而是在设计、开发人员上。他们迷失在工具中,没有去探求 ETL 的本质。可以说这些工具应用了这么长时间,在这么多项目、环境中应用,它必然有它成功之处,它必定体现了 ETL 的本质。如果我们不透过表面这些工具的简单使用去看它背后蕴涵的思想,最终我们作出来的东西也就是一个个独立的 job,将他们整合起来仍然有巨大的工作量。大家都知道 “理论与实践相结合”,如果在一个领域有所超越,必须要在理论水平上达到一定的高度.
下面是 ETL 工具 Kettle 的使用
参考:ETL 工具之 Kettle 的简单使用一 (不同数据库之间的数据抽取 - 转换 - 加载)
本文参考了:
参考:ETL(数据仓库技术)
参考:ETL 讲解(很详细!!!)

Flink1.7.2 sql 批处理示例
Flink1.7.2 sql 批处理示例
源码
- https://github.com/opensourceteams/flink-maven-scala
概述
- 本文为Flink sql Dataset 示例
- 主要操作包括:Scan / Select,as (table),as (column),limit,Where / Filter,between and (where),Sum,min,max,avg, sum (group by ),group by having,distinct,INNER JOIN,left join,right join,full outer join,union,unionAll,INTERSECT in,EXCEPT,insert into
SELECT
Scan / Select
- 功能描述: 查询一个表中的所有数据
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.scan
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements(("小明",15,"男"),("小王",45,"男"),("小李",25,"女"),("小慧",35,"女"))
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user1",dataSet,''name,''age,''sex)
tableEnv.sqlQuery(s"select name,age FROM user1")
.first(100).print()
/**
* 输出结果
*
* 小明,15
* 小王,45
* 小李,25
* 小慧,35
*/
}
}
- 输出结果
小明,15
小王,45
小李,25
小慧,35
as (table)
- 功能描述: 给表名取别称
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.scan
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements(("小明",15,"男"),("小王",45,"男"),("小李",25,"女"),("小慧",35,"女"))
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user1",dataSet,''name,''age,''sex)
tableEnv.sqlQuery(s"select t1.name,t1.age FROM user1 as t1")
.first(100).print()
/**
* 输出结果
*
* 小明,15
* 小王,45
* 小李,25
* 小慧,35
*/
}
}
- 输出结果
小明,15
小王,45
小李,25
小慧,35
as (column)
- 功能描述: 给表名取别称
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.scan
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements(("小明",15,"男"),("小王",45,"男"),("小李",25,"女"),("小慧",35,"女"))
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user1",dataSet,''name,''age,''sex)
tableEnv.sqlQuery(s"select name a,age as b FROM user1 ")
.first(100).print()
/**
* 输出结果
*
* 小明,15
* 小王,45
* 小李,25
* 小慧,35
*/
}
}
- 输出结果
小明,15
小王,45
小李,25
小慧,35
limit
-
功能描述:查询一个表的数据,只返回指定的前几行(争对并行度而言,所以并行度不一样,结果不一样)
-
scala 程序
package com.opensourceteams.mo`dule.bigdata.flink.example.sql.dataset.operations.limit
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
env.setParallelism(2)
val dataSet = env.fromElements(("小明",15,"男"),("小王",45,"男"),("小李",25,"女"),("小慧",35,"女"))
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user1",dataSet,''name,''age,''sex)
/**
* 先排序,按age的降序排序,输出前100位结果,注意是按同一个并行度中的数据进行排序,也就是同一个分区
*/
tableEnv.sqlQuery(s"select name,age FROM user1 ORDER BY age desc LIMIT 100 ")
.first(100).print()
/**
* 输出结果 并行度设置为2
*
* 小明,15
* 小王,45
* 小慧,35
* 小李,25
*/
/**
* 输出结果 并行度设置为1
*
* 小王,45
* 小慧,35
* 小李,25
* 小明,15
*/
}
}
- 输出结果
小明,15
小王,45
小慧,35
小李,25
Where / Filter
- 功能描述:列加条件过滤表中的数据
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.where
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements(("小明",15,"男"),("小王",45,"男"),("小李",25,"女"),("小慧",35,"女"))
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user1",dataSet,''name,''age,''sex)
tableEnv.sqlQuery(s"select name,age,sex FROM user1 where sex = ''女''")
.first(100).print()
/**
* 输出结果
*
* 小李,25,女
* 小慧,35,女
*/
}
}
- 输出结果
小李,25,女
小慧,35,女
between and (where)
- 功能描述: 过滤列中的数据, 开始数据 <= data <= 结束数据
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.whereBetweenAnd
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements(("小明",15,"男"),("小王",45,"男"),("小李",25,"女"),("小慧",35,"女"))
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user1",dataSet,''name,''age,''sex)
tableEnv.sqlQuery(s"select name,age,sex FROM user1 where age between 20 and 35")
.first(100).print()
/**
* 结果
*
* 小李,25,女
* 小慧,35,女
*/
}
}
- 输出结果
小李,25,女
小慧,35,女
Sum
- 功能描述: 求和所有数据
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.aggregations.sum
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements(("小明",15,"男",1500),("小王",45,"男",4000),("小李",25,"女",800),("小慧",35,"女",500))
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user1",dataSet,''name,''age,''sex,''salary)
//汇总所有数据
tableEnv.sqlQuery(s"select sum(salary) FROM user1")
.first(100).print()
/**
* 输出结果
*
* 6800
*/
}
}
- 输出结果
6800
max
- 功能描述: 求最大值
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.aggregations.max
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements(("小明",15,"男",1500),("小王",45,"男",4000),("小李",25,"女",800),("小慧",35,"女",500))
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user1",dataSet,''name,''age,''sex,''salary)
//汇总所有数据
tableEnv.sqlQuery(s"select max(salary) FROM user1 ")
.first(100).print()
/**
* 输出结果
*
* 4000
*/
}
}
- 输出结果
4000
min
- 功能描述: 求最小值
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.aggregations.min
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements(("小明",15,"男",1500),("小王",45,"男",4000),("小李",25,"女",800),("小慧",35,"女",500))
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user1",dataSet,''name,''age,''sex,''salary)
tableEnv.sqlQuery(s"select min(salary) FROM user1 ")
.first(100).print()
/**
* 输出结果
*
* 500
*/
}
}
- 输出结果
500
sum (group by )
- 功能描述: 按性别分组求和
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.aggregations.group
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements(("小明",15,"男",1500),("小王",45,"男",4000),("小李",25,"女",800),("小慧",35,"女",500))
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user1",dataSet,''name,''age,''sex,''salary)
//汇总所有数据
tableEnv.sqlQuery(s"select sex,sum(salary) FROM user1 group by sex")
.first(100).print()
/**
* 输出结果
*
* 女,1300
* 男,5500
*/
}
}
- 输出结果
女,1300
男,5500
group by having
- 功能描述:
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.aggregations.group_having
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements(("小明",15,"男",1500),("小王",45,"男",4000),("小李",25,"女",800),("小慧",35,"女",500))
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user1",dataSet,''name,''age,''sex,''salary)
//分组统计,having是分组条件查询
tableEnv.sqlQuery(s"select sex,sum(salary) FROM user1 group by sex having sum(salary) >1500")
.first(100).print()
/**
* 输出结果
*
*
*/
}
}
- 输出结果
男,5500
distinct
- 功能描述: 去重一列或多列
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.aggregations.distinct
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements(("a",15,"male"),("a",45,"female"),("d",25,"male"),("c",35,"female"))
val tableEnv = TableEnvironment.getTableEnvironment(env)
tableEnv.registerDataSet("user1",dataSet,''name,''age,''sex)
/**
* 对数据去重
*/
tableEnv.sqlQuery("select distinct name FROM user1 ")
.first(100).print()
/**
* 输出结果
*
* a
* c
* d
*/
}
}
- 输出结果
a
c
d
join
INNER JOIN
- 功能描述: 连接两个表,按指定的列,两列都存在值才输出
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.join.innerJoin
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))
val dataSetGrade = env.fromElements((1,"语文",100),(2,"数学",80),(1,"外语",50) )
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user",dataSet,''id,''name,''age,''sex,''salary)
tableEnv.registerDataSet("grade",dataSetGrade,''userId,''name,''fraction)
//内连接,两个表
// tableEnv.sqlQuery("select * FROM `user` INNER JOIN grade on `user`.id = grade.userId ")
tableEnv.sqlQuery("select `user`.*,grade.name,grade.fraction FROM `user` INNER JOIN grade on `user`.id = grade.userId ")
.first(100).print()
/**
* 输出结果
* 2,小王,45,男,4000,数学,80
* 1,小明,15,男,1500,语文,100
* 1,小明,15,男,1500,外语,50
*/
}
}
- 输出结果
2,小王,45,男,4000,数学,80
1,小明,15,男,1500,语文,100
1,小明,15,男,1500,外语,50
left join
- 功能描述:连接两个表,按指定的列,左表中存在值就一定输出,右表如果不存在,就显示为空
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.join.leftJoin
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))
val dataSetGrade = env.fromElements((1,"语文",100),(2,"数学",80),(1,"外语",50) )
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user",dataSet,''id,''name,''age,''sex,''salary)
tableEnv.registerDataSet("grade",dataSetGrade,''userId,''name,''fraction)
//左连接,拿左边的表中的每一行数据,去关联右边的数据,如果有相同的匹配数据,就都匹配出来,如果没有,就匹配一条,不过右边的数据为空
tableEnv.sqlQuery("select `user`.*,grade.name,grade.fraction FROM `user` LEFT JOIN grade on `user`.id = grade.userId ")
.first(100).print()
/**
* 输出结果
*
* 1,小明,15,男,1500,语文,100
* 1,小明,15,男,1500,外语,50
* 2,小王,45,男,4000,数学,80
* 4,小慧,35,女,500,null,null
* 3,小李,25,女,800,null,null
*
*
*/
}
}
- 输出结果
1,小明,15,男,1500,语文,100
1,小明,15,男,1500,外语,50
2,小王,45,男,4000,数学,80
4,小慧,35,女,500,null,null
3,小李,25,女,800,null,null
right join
- 功能描述:连接两个表,按指定的列,右表中存在值就一定输出,左表如果不存在,就显示为空
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.join.rightJoin
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))
val dataSetGrade = env.fromElements((1,"语文",100),(2,"数学",80),(1,"外语",50),(10,"外语",90) )
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user",dataSet,''id,''name,''age,''sex,''salary)
tableEnv.registerDataSet("grade",dataSetGrade,''userId,''name,''fraction)
//左连接,拿左边的表中的每一行数据,去关联右边的数据,如果有相同的匹配数据,就都匹配出来,如果没有,就匹配一条,不过右边的数据为空
tableEnv.sqlQuery("select `user`.*,grade.name,grade.fraction FROM `user` RIGHT JOIN grade on `user`.id = grade.userId ")
.first(100).print()
/**
* 输出结果
*
* 1,小明,15,男,1500,外语,50
* 1,小明,15,男,1500,语文,100
* 2,小王,45,男,4000,数学,80
* null,null,null,null,null,外语,90
*
*
*/
}
}
- 输出结果
1,小明,15,男,1500,外语,50
1,小明,15,男,1500,语文,100
2,小王,45,男,4000,数学,80
null,null,null,null,null,外语,90
full outer join
- 功能描述: 连接两个表,按指定的列,只要有一表中存在值就一定输出,另一表如果不存在就显示为空
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.join.fullOuterJoin
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))
val dataSetGrade = env.fromElements((1,"语文",100),(2,"数学",80),(1,"外语",50),(10,"外语",90) )
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user",dataSet,''id,''name,''age,''sex,''salary)
tableEnv.registerDataSet("grade",dataSetGrade,''userId,''name,''fraction)
//左,右,全匹配所有数据
tableEnv.sqlQuery("select `user`.*,grade.name,grade.fraction FROM `user` FULL OUTER JOIN grade on `user`.id = grade.userId ")
.first(100).print()
/**
* 输出结果
*
*
* 3,小李,25,女,800,null,null
* 1,小明,15,男,1500,外语,50
* 1,小明,15,男,1500,语文,100
* 2,小王,45,男,4000,数学,80
* 4,小慧,35,女,500,null,null
* null,null,null,null,null,外语,90
*
*
*
*/
}
}
- 输出结果
3,小李,25,女,800,null,null
1,小明,15,男,1500,外语,50
1,小明,15,男,1500,语文,100
2,小王,45,男,4000,数学,80
4,小慧,35,女,500,null,null
null,null,null,null,null,外语,90
Set Operations
union
- 功能描述: 连接两个表中的数据,会去重
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.setOperations.union
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))
val dataSet2 = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(30,"小李",25,"女",800),(40,"小慧",35,"女",500))
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user",dataSet,''id,''name,''age,''sex,''salary)
tableEnv.registerDataSet("t2",dataSet2,''id,''name,''age,''sex,''salary)
/**
* union 连接两个表,会去重
*/
tableEnv.sqlQuery(
"select * from ("
+"select t1.* FROM `user` as t1 ) " +
+ " UNION "
+ " ( select t2.* FROM t2 )"
)
.first(100).print()
/**
* 输出结果
*
* 30,小李,25,女,800
* 40,小慧,35,女,500
* 2,小王,45,男,4000
* 4,小慧,35,女,500
* 3,小李,25,女,800
* 1,小明,15,男,1500
*
*/
}
}
- 输出结果
30,小李,25,女,800
40,小慧,35,女,500
2,小王,45,男,4000
4,小慧,35,女,500
3,小李,25,女,800
1,小明,15,男,1500
unionAll
- 功能描述: 连接两表中的数据,不会去重
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.setOperations.unionAll
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))
val dataSet2 = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(30,"小李",25,"女",800),(40,"小慧",35,"女",500))
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user",dataSet,''id,''name,''age,''sex,''salary)
tableEnv.registerDataSet("t2",dataSet2,''id,''name,''age,''sex,''salary)
/**
* union 连接两个表,不会去重
*/
tableEnv.sqlQuery(
"select * from ("
+"select t1.* FROM `user` as t1 ) " +
+ " UNION ALL "
+ " ( select t2.* FROM t2 )"
)
.first(100).print()
/**
* 输出结果
*
* 1,小明,15,男,1500
* 2,小王,45,男,4000
* 3,小李,25,女,800
* 4,小慧,35,女,500
* 1,小明,15,男,1500
* 2,小王,45,男,4000
* 30,小李,25,女,800
* 40,小慧,35,女,500
*
*/
}
}
- 输出结果
1,小明,15,男,1500
2,小王,45,男,4000
3,小李,25,女,800
4,小慧,35,女,500
1,小明,15,男,1500
2,小王,45,男,4000
30,小李,25,女,800
40,小慧,35,女,500
INTERSECT
- 功能描述: INTERSECT 连接两个表,找相同的数据(相交的数据,重叠的数据)
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.setOperations.intersect
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))
val dataSet2 = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(30,"小李",25,"女",800),(40,"小慧",35,"女",500))
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user",dataSet,''id,''name,''age,''sex,''salary)
tableEnv.registerDataSet("t2",dataSet2,''id,''name,''age,''sex,''salary)
/**
* INTERSECT 连接两个表,找相同的数据(相交的数据,重叠的数据)
*/
tableEnv.sqlQuery(
"select * from ("
+"select t1.* FROM `user` as t1 ) " +
+ " INTERSECT "
+ " ( select t2.* FROM t2 )"
)
.first(100).print()
/**
* 输出结果
*
* 1,小明,15,男,1500
* 2,小王,45,男,4000
*
*/
}
}
- 输出结果
1,小明,15,男,1500
2,小王,45,男,4000
in
- 功能描述: 子查询
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.setOperations.in
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))
val dataSet2 = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(30,"小李",25,"女",800),(40,"小慧",35,"女",500))
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user",dataSet,''id,''name,''age,''sex,''salary)
tableEnv.registerDataSet("t2",dataSet2,''id,''name,''age,''sex,''salary)
/**
* in ,子查询
*/
tableEnv.sqlQuery(
"select t1.* FROM `user` t1 where t1.id in " +
" (select t2.id from t2) "
)
.first(100).print()
/**
* 输出结果
*
* 1,小明,15,男,1500
* 2,小王,45,男,4000
*
*/
}
}
- 输出结果
1,小明,15,男,1500
2,小王,45,男,4000
EXCEPT
- 功能描述: EXCEPT 连接两个表,找不相同的数据(不相交的数据,不重叠的数据)
- scala 程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.setOperations.except
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(3,"小李",25,"女",800),(4,"小慧",35,"女",500))
val dataSet2 = env.fromElements((1,"小明",15,"男",1500),(2,"小王",45,"男",4000),(30,"小李",25,"女",800),(40,"小慧",35,"女",500))
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user",dataSet,''id,''name,''age,''sex,''salary)
tableEnv.registerDataSet("t2",dataSet2,''id,''name,''age,''sex,''salary)
/**
* EXCEPT 连接两个表,找不相同的数据(不相交的数据,不重叠的数据)
*/
tableEnv.sqlQuery(
"select * from ("
+"select t1.* FROM `user` as t1 ) " +
+ " EXCEPT "
+ " ( select t2.* FROM t2 )"
)
.first(100).print()
/**
* 输出结果
*
* 3,小李,25,女,800
* 4,小慧,35,女,500
*
*/
}
}
- 输出结果
3,小李,25,女,800
4,小慧,35,女,500
DML
insert into
- 功能描述:将一个表中的数据(source),插入到 csv文件中(sink)
- scala程序
package com.opensourceteams.module.bigdata.flink.example.sql.dataset.operations.insert
import org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.core.fs.FileSystem.WriteMode
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
import org.apache.flink.api.scala._
import org.apache.flink.table.sinks.CsvTableSink
import org.apache.flink.api.common.typeinfo.TypeInformation
object Run {
def main(args: Array[String]): Unit = {
//得到批环境
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet = env.fromElements(("小明",15,"男"),("小王",45,"男"),("小李",25,"女"),("小慧",35,"女"))
//得到Table环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
//注册table
tableEnv.registerDataSet("user1",dataSet,''name,''age,''sex)
// create a TableSink
val csvSink = new CsvTableSink("sink-data/csv/a.csv",",",1,WriteMode.OVERWRITE);
val fieldNames = Array("name", "age", "sex")
val fieldTypes: Array[TypeInformation[_]] = Array(Types.STRING, Types.INT, Types.STRING)
tableEnv.registerTableSink("t2",fieldNames,fieldTypes,csvSink)
tableEnv.sqlUpdate(s" insert into t2 select name,age,sex FROM user1 ")
env.execute()
/**
* 输出结果
* a.csv
*
* 小明,15,男
* 小王,45,男
* 小李,25,女
* 小慧,35,女
*/
}
}
- 输出数据 a.csv
小明,15,男
小王,45,男
小李,25,女
小慧,35,女
Scan
- 功能描述:
- scala 程序
- 输出结果
关于Win下执行kettle的trans和job的批处理示例和kettle执行ktr的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于.net中的CreateJobObject / SetInformationJobObject pinvoke的工作示例?、android view之getLeft(),getRight(),getTop(),getBottom(),getX(),getY(),getRawX(),getRawY(),getTrans...、ETL 技术 (Extract-Transform-Load) 数据仓库技术 - 比如 kettle、Flink1.7.2 sql 批处理示例的相关知识,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

