如果您对在Ubuntu上安装Discourse开发环境和ubuntu安装c++开发环境感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解在Ubuntu上安装Discourse开发环境的各种细节,并
如果您对在 Ubuntu 上安装 Discourse 开发环境和ubuntu安装c++开发环境感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解在 Ubuntu 上安装 Discourse 开发环境的各种细节,并对ubuntu安装c++开发环境进行深入的分析,此外还有关于AskTUG 论坛迁移实战:Discourse 从 PostgreSQL 到 MySQL 到 TiDB、BBS时代落幕?我们还有“下一代的论坛”——Discourse、Debian / Ubuntu 上安装 Go 开发环境、Discourse的实用技巧。
本文目录一览:- 在 Ubuntu 上安装 Discourse 开发环境(ubuntu安装c++开发环境)
- AskTUG 论坛迁移实战:Discourse 从 PostgreSQL 到 MySQL 到 TiDB
- BBS时代落幕?我们还有“下一代的论坛”——Discourse
- Debian / Ubuntu 上安装 Go 开发环境
- Discourse
")
在 Ubuntu 上安装 Discourse 开发环境(ubuntu安装c++开发环境)
本指南只针对 Discourse 开发环境的配置,如果你需要在生产环境中安装 Discourse ,请访问页面:Install Discourse in production with the official, supported instructions - sysadmin - Discourse Meta 中的内容。
有关开发环境的设置英文原文,请参考:Set up a local Discourse Development Environment? - developers - Discourse Meta 页面中的内容。
本文只针对在 Ubuntu 环境下的开发进行设置,因为 Discourse 是基于 Ruby 开发的,Ruby 的开发环境在 Ubuntu 下设置最为简便,所以 Discourse 的生产环境运行也是是官方建议在 Ubuntu 下运行的,虽然我们的社区是运行在 REHL 环境下也没有问题,因为使用了 Docker 的容器,但如果你想对 Discourse 进行开发的话,建议还是使用 Ubuntu 环境。
如果你使用的是 Windows 系统的话,你需要安装 WSL 环境。WSL 是 Windows 提供的一个基于 Ubuntu 的环境,主要用于解决 Windows 下开发Linux 应用的问题。
本文章假设你还没有在 Ubuntu 环境中安装 Ruby/Rails/Postgres/Redis 环境,让我们开始开发环境的配置吧!
尽管这个开发指南是假定你使用的是 Ubuntu 开发环境,但是任何基于 Debian 发行的 Linux 系统都是可以使用的。
本开发指南在 Ubuntu 18 上验证过不需要任何其他的步骤就可以完成开发环境设置。
基于 Ubuntu/Debian 开发环境的使用不同,你可能在对 Ubuntu/Debian 进行开发的时候需要参考下下面的信息:
有关在 Ubuntu 20.04 及其后续版本上安装 Discourse 测试环境
有关在 Ubuntu 低于 20.04版本上安装 Discourse 测试环境
根据我们进行测试的经验来看,Ubuntu 22 的版本中可能有无法编译和包找不到的情况,我们还只在 20.04 上完成本地开发环境的设置。
安装 Discourse 依赖
作为一般的用户,可以在控制台中运行下面的命令: this script 。上面的命令将会帮助你在本地的开发环境中快速设置 Rails。
运行的命令为:
bash <(wget -qO- https://raw.githubusercontent.com/discourse/install-rails/master/linux)
上面的命令将会在你的本地系统中安装下面的包:
- Git
- rbenv
- ruby-build
- Ruby (stable)
- Rails
- PostgreSQL
- SQLite
- Redis
- Bundler
- MailHog
- ImageMagick
如果在你的本地操作系统中已经安装了一些软件,或者你不希望安装所有的软件的话,请参考 script 中的内容,然后选择你不希望当前安装的软件。上面的安装脚本将会安装所有 Discourse 运行需要的软件,这些软件将会为 Discourse 的运行提供支持。
当你完成安装所有的 Discourse 依赖后,我们就可以对 Discourse 进行安装了。

上图显示的是在 Ubuntu 中安装的界面,整个软件安装的过程还是比较耗时的,可能需要5 分钟以上,与你使用的系统有关。
克隆(Clone)Discourse
克隆 Discourse 到 ~/discourse 文件夹中
git clone https://github.com/discourse/discourse.git ~/discourse
~ 定义的是当前的 Home 文件夹,这个意思是 Discourse 的程序将会复制到你的 home 文件夹下。
因为我们使用的是 WSL 子系统,因此我们实际上是把文件克隆到我的 D 盘下了。
设置(Setup) Database
创建一个 与你 ubuntu 系统用户名相同的用户:
sudo -u postgres createuser -s "$USER"
如果你在运行上面的命令的时候提示错误:
createuser: error: could not connect to database template1: could not connect to server: No such file or directory
请参考页面:Discourse 开发环境安装 PGSQL 提示错误 2 中的内容。
启动 Discourse
切换到你的 Discourse 克隆目录中:
cd ~/discourse
安装所需要的 gems
source ~/.bashrc
bundle install
同时安装所需要的 JS 依赖
yarn install
当到这一步为止,你已经安装好所有需要的 gems 和依赖,请尝试运行下面的命令:
bundle exec rake db:create
bundle exec rake db:migrate
RAILS_ENV=test bundle exec rake db:create db:migrate
如果在运行的时候出现错误,请仓库: Discourse 开发环境安装运行 bundle exec rake db:create 错误 中的内容。
尝试运行下面的命令:
bundle exec rake autospec
你的项目应该会通过所有的测试。
这个测试非常耗时,可以不做这个的,要不然估计几个小时就出去了。
运行下面的命令来启动服务器:
bundle exec rails server
当你完成上面的安装步骤后,你应该可以通过 http://localhost:3000 访问你本地安装的 Discourse。
从 Discourse 2.5+ 开始, 针对本地的开发环境 EmberCLI 变成必须的选项了。:
如果你直接通过界面访问 3000 端口的话,会得到下面的提示界面:
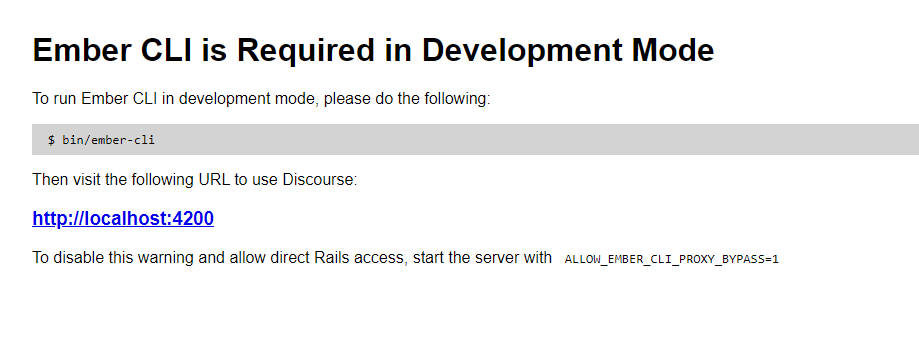
在你的控制台终端中,进入 (cd ~/discourse) 文件夹,然后运行:
bin/ember-cli
你应该可以通过访问t http://localhost:4200 地址来查看你的本地 Discourse 安装。
创建一个新的 Admin 账号
在对开发环境进行登录之前,需要创建一个管理员账号,运行下面的命令进行创建:
RAILS_ENV=development bundle exec rake admin:create
请按照命令行的提示来创建这个管理员账号。
需要输入的信息为电子邮件地址和密码。
配置邮件
运行 MailHog:
mailhog
当你完成上面的所有步骤后,你的 Discourse 本地开发环境就已经配置好了,你现在就可以以管理员账号来登录 Discourse 了。
如果你想对 Discourse 开发插件的话,请参考: Developing Discourse Plugins - Part 1 - Create a basic plugin - developers - Discourse Meta 页面中的内容指南。
https://www.ossez.com/t/ubuntu-discourse/14239

AskTUG 论坛迁移实战:Discourse 从 PostgreSQL 到 MySQL 到 TiDB
原文来源:https://tidb.net/blog/1b70463f
作者:Hooopo
AskTUG 论坛迁移实战:Discourse 从 PostgreSQL 到 MySQL 到 TiDB
AskTUG.com 技术问答网站相信大家都不陌生,但除了日常熟知的前端页面外,背后支撑其运行的数据库还有一个不为人知的故事。本文由 AskTUG.com 的作者之一王兴宗老师分享,揭秘 AskTUG.com 从诞生于 Discourse 的 AskTUG.com ,到从 PostgreSQL 迁移到 MySQL 最后稳定运行在 TiDB 的奇妙故事。
一个广告:AskTUG.com 是 TiDB User、Contributor、合作伙伴的聚集地,在这里你可以找到所有 TiDB 相关问题的答案。欢迎大家注册体验~
链接:https://asktug.com/
一、背景
“通过一个平台,一定能找到 TiDB 所有问题的满意答案。”
因为这样的愿望,TiDB 生态中的用户、Contributor、合作伙伴一起建立了 AskTUG.com 技术问答网站,并于 2019 年 8 月正式公开上线。作为 TUG 成员学习、分享的“聚集地”,TiDB 用户可以在这里提出、解答问题,相互交流探讨,这里汇集 TiDB 用户的集体智慧。自上线以来,AskTUG.com 逐渐吸引了越来越多用户的关注,截止 2021 年 6 月底,AskTUG.com 已有 7000+ 注册用户,沉淀了 1.6w+ 问题和 300+ 技术文章。
很多小伙伴都已经发现,AskTUG.com 的后端程序是一个 Discourse 程序。 关于 Discourse 是 Stack Overflow 的联合创始人 Jeff Atwood 推出的一个新的开源论坛项目,其目的是为了改变十年未变的论坛软件。在 AskTUG.com 建立之初,从以下几个角度确定使用 Discourse:
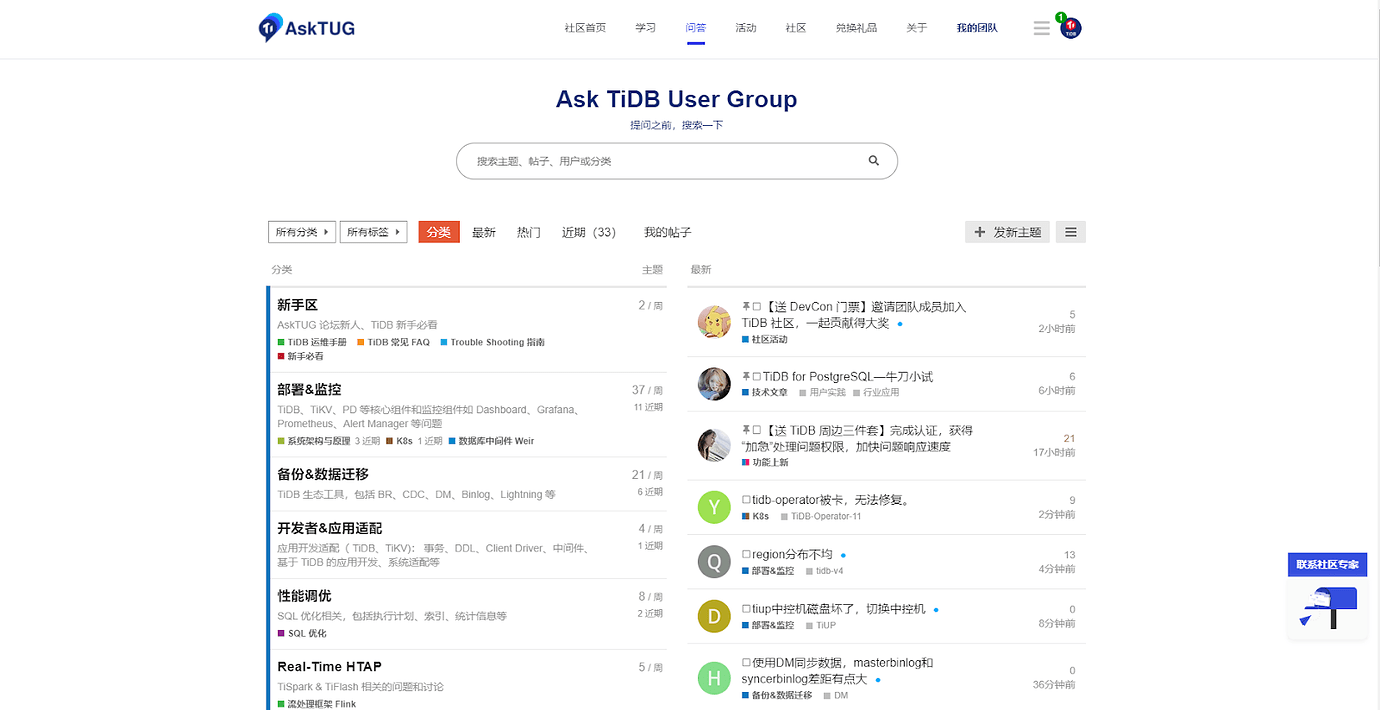
- 功能强大:Discourse 特性丰富,可定制性强,是论坛界的 WordPress。与其他传统的论坛相比, Discourse 简化了传统论坛的分类,取而代之是热贴,这点有点像问答,它可以避免用户进入传统论坛后找不到方向的迷茫,这个特性从 AskTUG.com 的页面便可见一斑:
-
受众广泛:大部分流行的开源项目都选择使用 Discourse 来搭建自己的社区,包括:
- Docker:https://forums.docker.com/
- Github Atom:https://discuss.atom.io/
- Mozilla:https://discourse.mozilla.org/
- TiDB:https://asktug.com/
- Discourse:https://meta.discourse.org/
- Rust:https://users.rust-lang.org/
- 更多:https://discourse.org/customers

- 易用性好:Discourse 的帖子是气泡形式展现,全部 Ajax 加载,有电脑和移动版,论坛采用了瀑布流的设计,自动加载下一页,无需手动翻页,简单来说这是一个很赞的系统。
二、为什么要迁移
到现在为止,Everything is Good,除了一点:Discourse 官方只支持 PostgreSQL 这一种数据库。
作为一家开源数据库厂商,我们有极大的热情和充分的理由让 AskTUG.com 跑在自己的数据库 TiDB 上,最初有这个想法时,当然是找有没有已经将 Discourse port 到 MySQL 的方案,结果是问的人多,行动的没有。
于是我们决定自己来做 Discourse 数据库改造这件事情。原因有二:
- 吃自己的狗粮,验证 TiDB 的兼容性
- Discourse 是一个典型的 HTAP 型应用,它的管理后台有很复杂的报表查询,随着论坛数据量增加,单机 PostgreSQL 很容易出现性能瓶颈。而 TiDB 5.0 引入的 TiFlash MPP 计算模型正好满足了这种应用场景需求。通过引入 TiFlash 节点,对一些复杂的统计分析类查询做并行处理,达到加速的效果。并且不需要改动 SQL 和复杂的 ETL 流程。
三、迁移实践
前面我们讲述了做 AskTUG & Discourse 数据库改造项目的原因始末,接来下,则会细致地讲下从 PostgreSQL 迁移到 MySQL / TiDB 踩过的“坑”,如果有从 PG 迁移到 MySQL 的朋友可以拿来参考。
TiDB 同时兼容 MySQL 协议和生态,迁移便捷,运维成本极低。因此,Discourse 从 PG 迁移到 TiDB 大致分为两步:
第一步:将 Discourse 迁移到 MySQL;
第二步:适配 TiDB;
Migrate to MySQL 5.7
mini_sql
mini_sql 是一个轻量级的 sql wraper,方便做一些 ORM 不擅长的查询,并且可以防止 SQL 注入。之前只支持 PG 和 sqlite。 Discourse 的代码依赖 mini_sql 的地方非常多,重写的话工作量巨大,patch mini_sql 来支持 MySQL 是能够迁移完成的一个重要步骤:https://github.com/discourse/mini_sql/pull/5
schema migration
Rails 的 schema migration 用来维护 DDL,反映的是数据库 schema 的变化过程,对于迁移来说,其实增加了工作量,解决办法是,先生成一份最终的 schema.rb 文件,在最终结果上做修改,生成一份新的 migration 文件。中间过程产生的 migration 文件删掉就可以了。
character set utf8mb4
database.yml
development:
prepared_statements: false
encoding: utf8mb4
socket: /tmp/mysql.sock
adapter: mysql2
/etc/mysql/my.cnf
[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld]
character-set-client-handshake = FALSE
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
MySQL can index only the first N chars of a BLOB or TEXT column
PG 的所有类型都是可以索引的,MySQL 不能索引 text 类型,解决办法是,索引的时候指定长度:
t.index ["error"], name: "index_incoming_emails_on_error", length: 100
但对于组合索引的情况更复杂,只能忽略带 text 类型的,好在索引不影响功能。
data migration
pg2mysql 可以把 pgdump 出来的 insert 语句转换成兼容 MySQL 语法的形式,但只限于简单的形式,一些带有 array 和 json 的格式会乱掉,但这部分用 Ruby 处理起来是正确的,分成两部分处理,首先 pg2mysql 来处理排除一些转换出错的表,比如 user_options、site_settings 等:
PGPASSWORD=yourpass pg_dump discourse_development -h localhost
--quote-all-identifiers
--quote-all-identifiers
--inserts
--disable-dollar-quoting
--column-inserts
--exclude-table-data user_options
--exclude-table-data user_api_keys
--exclude-table-data reviewable_histories
--exclude-table-data reviewables
--exclude-table-data notifications
--exclude-table-data site_settings
--exclude-table-data reviewables
--no-acl
--no-owner
--format p
--data-only -f pgfile.sql
剩下一部分数据使用 seed_dump 来迁移:
bundle exec rake db:seed:dump
MODELS=UserApiKey,UserOption,ReviewableHistory,
Reviewable,Notification,SiteSetting
EXCLUDE=[] IMPORT=true
distinct on
PG 有一个 distinct on 的用法,等价于 MySQL ONLY_FULL_GROUP_BY 参数关闭时的效果,但从 MySQL 5.7 开始,这个参数默认已经开启了。所以解决办法一个是关掉 ONLY_FULL_GROUP_BY 参数,另一个是用 GROUP 和聚合函数模拟:
# postgresql
SELECT DISTINCT ON (pr.user_id) pr.user_id, pr.post_id, pr.created_at granted_at
FROM post_revisions pr
JOIN badge_posts p on p.id = pr.post_id
WHERE p.wiki
AND NOT pr.hidden
AND (:backfill OR p.id IN (:post_ids))
# mysql
SELECT pr.user_id, MIN(pr.post_id) AS post_id, MIN(pr.created_at) AS granted_at
FROM post_revisions pr
JOIN badge_posts p on p.id = pr.post_id
WHERE p.wiki
AND NOT pr.hidden
AND (:backfill OR p.id IN (:post_ids))
GROUP BY pr.user_id
returning
PG 的 UPDATE、DELETE、INSERT 语句都可以带一个 returning 关键词,用来返回修改/插入之后的结果。对于 UPDATE 和 DELETE 语句,MySQL 改起来比较容易,只需要拆成两步,先查出主键,再更新或删除:
update users set updated_at = now() where id = 801 returning id,updated_at ;
id | updated_at
-----+---------------------------
801 | 2019-12-30 15:43:35.81969
MySQL 版本:
update users set updated_at = now() where id = 801;
select id, updated_at from users where id = 801;
+-----+---------------------+
| id | updated_at |
+-----+---------------------+
| 801 | 2019-12-30 15:45:46 |
+-----+---------------------+
对于单条 INSERT 情况,需要使用 last_insert_id() 函数:
PG 版本:
insert into category_users(user_id, category_id, notification_level) values(100,100,1) returning id, user_id, category_id;
id | user_id | category_id
----+---------+-------------
59 | 100 | 100
改成 MySQL 版本:
insert into category_users(user_id, category_id, notification_level) values(100,100,1);
select id, category_id, user_id from category_users where id = last_insert_id();
+----+-------------+---------+
| id | category_id | user_id |
+----+-------------+---------+
| 48 | 100 | 100 |
+----+-------------+---------+
对于批量插入,需要改成单条 INSERT,再使用 last_insert_id() 函数,因为 MySQL 没有提供 last_insert_ids() 函数:
ub_ids = records.map do |ub|
DB.exec(
"INSERT IGNORE INTO user_badges(badge_id, user_id, granted_at, granted_by_id, post_id)
VALUES (:badge_id, :user_id, :granted_at, :granted_by_id, :post_id)",
badge_id: badge.id,
user_id: ub.user_id,
granted_at: ub.granted_at,
granted_by_id: -1,
post_id: ub.post_id
)
DB.raw_connection.last_id
end
DB.query("SELECT id, user_id, granted_at FROM user_badges WHERE id IN (:ub_ids)", ub_ids: ub_ids)
insert into on conflict do nothing
PG 9.5 开始支持 upsert,MySQL 也有同样的功能,只是写法不一致:
# postgresql
DB.exec(<<~SQL, args)
INSERT INTO post_timings (topic_id, user_id, post_number, msecs)
SELECT :topic_id, :user_id, :post_number, :msecs
ON CONFLICT DO NOTHING
SQL
# MySQL
DB.exec(<<~SQL, args)
INSERT IGNORE INTO post_timings (topic_id, user_id, post_number, msecs)
SELECT :topic_id, :user_id, :post_number, :msecs
SQL
select without from
PG 里允许这样的语法: select 1 where 1=2;
但在 MySQL 里这是不合法的,因为没有 FROM 子句,解决办法很 trick,手动建一个只有一条数据的表,专门用来兼容这个语法。
execute("create table one_row_table (id int)")
execute("insert into one_row_table values (1)")
MySQL使用:
# MySQL
select 1 from one_row_table where 1=2;
full outer join
MySQL 不支持 full outer join,需要使用 LEFT JOIN + RIGHT JOIN + UNION 来模拟:
# MySQL
SELECT * FROM t1
LEFT JOIN t2 ON t1.id = t2.id
UNION
SELECT * FROM t1
RIGHT JOIN t2 ON t1.id = t2.id
recursive cte
MySQL 8.0 之前不支持 CTE/Recursive CTE,结构简单的 CTE 可以直接改成子查询,除了可读性差以外,功能上没任何影响。recursive CTE 可以用 User-defined variables 来模拟。Discourse 里有一个嵌套回复的查询:
WITH RECURSIVE breadcrumb(id, level) AS (
SELECT 8543, 0
UNION
SELECT reply_id, level + 1
FROM post_replies AS r
JOIN breadcrumb AS b ON (r.post_id = b.id)
WHERE r.post_id <> r.reply_id
AND b.level < 1000
), breadcrumb_with_count AS (
SELECT
id,
level,
COUNT(*) AS count
FROM post_replies AS r
JOIN breadcrumb AS b ON (r.reply_id = b.id)
WHERE r.reply_id <> r.post_id
GROUP BY id, level
)
SELECT id, level
FROM breadcrumb_with_count
ORDER BY id
使用 MySQL 5.7 来兼容:
# MySQL
SELECT id, level FROM (
SELECT id, level, count(*) as count FROM (
SELECT reply_id AS id, length(@pv) - length((replace(@pv, '','', ''''))) AS level
FROM (
SELECT * FROM post_replies ORDER BY post_id, reply_id) pr,
(SELECT @pv := 8543) init
WHERE find_in_set(post_id, @pv)
AND length(@pv := concat(@pv, '','', reply_id))
) tmp GROUP BY id, level
) tmp1
WHERE (count = 1)
ORDER BY id
PG 的 cte 是可以嵌套的,比如 Discourse 里这段查询,注 WITH period_actions 是嵌套在flag_count 里面的:
WITH mods AS (
SELECT
id AS user_id,
username_lower AS username,
uploaded_avatar_id
FROM users u
WHERE u.moderator = ''true''
AND u.id > 0
),
time_read AS (
SELECT SUM(uv.time_read) AS time_read,
uv.user_id
FROM mods m
JOIN user_visits uv
ON m.user_id = uv.user_id
WHERE uv.visited_at >= ''#{report.start_date}''
AND uv.visited_at <= ''#{report.end_date}''
GROUP BY uv.user_id
),
flag_count AS (
WITH period_actions AS (
SELECT agreed_by_id,
disagreed_by_id
FROM post_actions
WHERE post_action_type_id IN (#{PostActionType.flag_types_without_custom.values.join('','')})
AND created_at >= ''#{report.start_date}''
AND created_at <= ''#{report.end_date}''
),
agreed_flags AS (
SELECT pa.agreed_by_id AS user_id,
COUNT(*) AS flag_count
FROM mods m
JOIN period_actions pa
ON pa.agreed_by_id = m.user_id
GROUP BY agreed_by_id
),
disagreed_flags AS (
SELECT pa.disagreed_by_id AS user_id,
COUNT(*) AS flag_count
FROM mods m
JOIN period_actions pa
ON pa.disagreed_by_id = m.user_id
GROUP BY disagreed_by_id
)
这种用子查询模拟起来就非常复杂,可以使用临时表来兼容,查询部分不需要任何修改,只需要按依赖顺序把 WITH 部分换成临时表:
DB.exec(<<~SQL)
CREATE TEMPORARY TABLE IF NOT EXISTS mods AS (
SELECT
id AS user_id,
username_lower AS username,
uploaded_avatar_id
FROM users u
WHERE u.moderator = true
AND u.id > 0
)
SQL
DB.exec(<<~SQL)
CREATE TEMPORARY TABLE IF NOT EXISTS time_read AS (
SELECT SUM(uv.time_read) AS time_read,
uv.user_id
FROM mods m
JOIN user_visits uv
ON m.user_id = uv.user_id
WHERE uv.visited_at >= ''#{report.start_date.to_s(:db)}''
AND uv.visited_at <= ''#{report.end_date.to_s(:db)}''
GROUP BY uv.user_id
)
SQL
delete & update
PG 和 MySQL 的 update/delete 语句写法是不一样的,使用 ORM 会自动处理,但 Discourse 里大量代码是使用 mini_sql 手写的 SQL,需要逐个替换。
PG 的 update 语句写法:
# postgresql
UPDATE employees
SET department_name = departments.name
FROM departments
WHERE employees.department_id = departments.id
MySQL 的 update 语句写法:
# MySQL
UPDATE employees
LEFT JOIN departments ON employees.department_id = departments.id
SET department_name = departments.name
delete 语句也类似。
You can’t specify target table xx for update in FROM clause
从 PG 迁到 MySQL 之后,很多语句会报这样一个错误:You can’t specify target table ‘users’ for update in FROM clause。
# MySQL
update users set updated_at = now() where id in (
select id from users where id < 10
);
# You can''t specify target table ''users'' for update in FROM clause
解决办法是子查询里再用derived table:
# MySQL
update users set updated_at = now() where id in (
select id from (select * from users) u where id < 10
);
MySQL doesn’t yet support ‘LIMIT & IN/ALL/ANY/SOME subquery’
还拿上面的查询举例,子查询如果带 LIMIT:
# MySQL
update users set updated_at = now() where id in (
select id from (select * from users) u where id < 10 limit 10
);
# MySQL doesn''t yet support ''LIMIT & IN/ALL/ANY/SOME subquery''
最简单的解决办法是再 derived 一次:
# MySQL
update users set updated_at = now() where id in (
select id from (
select id from (select * from users) u where id < 10 limit 10
) u1
);
window function
MySQL 8.0 之前没有窗口函数,可以使用 User-Defined Variables 替代:
# postgresql
WITH ranked_requests AS (
SELECT row_number() OVER (ORDER BY count DESC) as row_number, id
FROM web_crawler_requests
WHERE date = ''#{1.day.ago.strftime("%Y-%m-%d")}''
)
DELETE FROM web_crawler_requests
WHERE id IN (
SELECT ranked_requests.id
FROM ranked_requests
WHERE row_number > 10
)
# MySQL
DELETE FROM web_crawler_requests
WHERE id IN (
SELECT ranked_requests.id
FROM (
SELECT @r := @r + 1 as row_number, id
FROM web_crawler_requests, (SELECT @r := 0) t
WHERE date = ''#{1.day.ago.strftime("%Y-%m-%d")}''
ORDER BY count DESC
) ranked_requests
WHERE row_number > 10
)
swap columns
MySQL 和 PG 在处理 update 语句时,column 的引用行为是不一致的,PG 引用的是原始值,而 MySQL 引用的是更新后的值,举个例子:
# postgresql
create table tmp (id integer primary key, c1 varchar(10), c2 varchar(10));
insert into tmp values (1,2,3);
insert into tmp values (2,4,5);
select * from tmp;
id | c1 | c2
----+----+----
1 | 3 | 2
2 | 5 | 4
update tmp set c1=c2,c2=c1;
select * from tmp;
id | c1 | c2
----+----+----
1 | 3 | 2
2 | 5 | 4
# MySQL
create table tmp (id integer primary key, c1 varchar(10), c2 varchar(10));
insert into tmp values (1,2,3);
insert into tmp values (2,4,5);
select * from tmp;
+----+------+------+
| id | c1 | c2 |
+----+------+------+
| 1 | 2 | 3 |
| 2 | 4 | 5 |
+----+------+------+
update tmp set c1=c2,c2=c1;
select * from tmp;
+----+------+------+
| id | c1 | c2 |
+----+------+------+
| 1 | 3 | 3 |
| 2 | 5 | 5 |
+----+------+------+
function
PG 和 MySQL 的一些内置函数名称和行为会有一些不一致:
- regexp_replace -> replace
- pg_sleep -> sleep
- ilike -> lower + like
- ~* -> regexp
- || -> concat
- set local statement_timeout -> set session statement_timeout
- offset a limit b -> limit a offset b
- @ -> ABS
- interval -> date_add 或者 datediff
- extract epoch from -> unix_timestimp
- unnest -> union all
- json语法:json->> ‘username’ to json ->> ‘$.username’
- position in -> locate
- generate_series -> union
- greatest & least -> greatest/least + coalesce
type & casting
MySQL 使用 cast 函数,PG 也支持同样的语法,不过更常用的是四个点::,比如 SELECT 1::varchar,MySQL 的转换类型只能是下面5种:CHAR[(N)]、 DATE、DATETIME、DECIMAL、SIGNED、TIME。
select cast(‘1’ as signed);
Rails 里 string 类型,PG 映射成 varchar,MySQL 映射成 varchar(255),而 PG 的 varchar 其实是可以存储超过 255 的,Discourse 里一些使用 string 类型的数据会超过 255 ,转成 MySQL 以后会被截断,解决办法是对这部分列使用 text 类型。
keywords
MySQL 和 PG 的 keywords 列表并不完全一致,比如 read 在 MySQL 里是关键字,在 PG 里并不是。对于 ORM 生产的 SQL 已经处理好了,一些手写的 SQL 需要自己去 quote,PG 使用"",MySQL 使用``。
expression index
PG 支持表达式索引:
CREATE INDEX test1_lower_col1_idx ON test1 (lower(col1));
Discourse 里面一些功能会在表达式索引上面加唯一约束,MySQL 没有直接的对应,但是可以使用 Stored Generated Column 来模拟,先冗余一个 Stored Generated Column,再在上面加唯一约束,达到了同样的效果。
Rails 也支持:
t.virtual "virtual_parent_category_id", type: :string, as: "COALESCE(parent_category_id, ''-1'')", stored: true
t.index "virtual_parent_category_id, name", name: "unique_index_categories_on_name", unique: true
array && json
PG 支持 array 和 json 类型,MySQL 5.7 已结有了 JSON,Discourse 里,ARRAY 和 JSON 的使用场景比较单一,都是用来存储,没有高级检索需求,直接使用 JSON 可以替代 PG 的 array 和 json。但 MySQL 的 JSON 和 text 都不支持 default value,只能在应用层设置,可以使用:https://github.com/FooBarWidget/default_value_for
适配 TiDB
TiDB 支持 MySQL 传输协议及其绝大多数的语法,但是一些特性由于在分布式环境下没法很好地实现,所以在部分特性的表现仍然与 MySQL 有一些差异,详见文档 https://pingcap.com/docs-cn/stable/reference/mysql-compatibility/,接下来我们主要看一下本次迁移中涉及到的一些小问题。
TiDB 保留关键字
TiDB 在新版本(本次迁移使用 v3.0.7) 中支持了 Window Function ,引入了 group、rank、row_number 等函数,但比较特殊的是上述函数名都会被 TiDB 当做关键词处理,所以我们在开启窗口函数的时候需要修改命名与窗口函数名类似的 SQL,将相关的关键字用反引号包住。
TiDB 保留关键字:https://pingcap.com/docs-cn/stable/reference/sql/language-structure/keywords-and-reserved-words/
TiDB 窗口函数: https://pingcap.com/docs-cn/stable/reference/sql/functions-and-operators/window-functions/
Insert into select 语法不兼容
TiDB 暂时不支持该语法,可以使用 insert into select from dual 绕过:
invalid: insert into t1 (i) select 1;
valid: insert into t1 (i) select 1 from dual;
嵌套事务 & savepoint
TiDB 不支持嵌套事务,同样也不支持 savepoint。但是 Rails ActiveRecord 在数据库是 MySQL 或者 PostgreSQL 时,使用 savepoint 来模拟嵌套事务,并使用 requires_new 选项来控制,文档: https://api.rubyonrails.org/classes/ActiveRecord/Transactions/ClassMethods.html。
所以在数据库迁移到 TiDB 后,我们需要调整业务代码,将原有涉及到 嵌套事务 的逻辑,调整为单层事务,遇到异常统一回滚,同时在 discourse 中取消使用 requires_new 选项。
四、TiDB 强大的兼容性
TiDB 100% 兼容 MySQL 5.7 协议。除此之外,还支持了 MySQL 5.7 常用的功能及语法。MySQL 5.7 生态中的系统工具(PHPMyAdmin、Navicat、MySQL Workbench、mysqldump、Mydumper/Myloader)、客户端等均适用于 TiDB。同时,TiDB 5.0 之后,很多新的特性也将陆续发布,比如表达式索引、CTE、临时表等,新版本的 TiDB 兼容性越来越好,从 MySQL 或 PostgreSQL 迁移到 TiDB 也会变得越来越容易。
五、总结
该项目已经 100% 完成,且目前 AskTUG 网站(https://asktug.com)已经平稳地运行在 TiDB(当前版本:tidb-v5.0.x)上已一年有余。是的,在没改变体验的情况下,谁也没有发现数据库已经悄悄改变了~证明了跑在 PG 上的业务迁移到 TiDB 的可行性。
项目的地址是:https://github.com/tidb-incubator/discourse/tree/my-2.3.3,可以通过 fork & 提 PR 的方式来参与改进并关注该项目的进展,也非常欢迎 Ruby 社区,Ruby On Rails 社区,Discourse 社区的小伙伴来感受下来自 TiDB 社区的善意。
? 小伙伴们注意啦~
为了可以给 TiDB 社区 的小伙伴提供更加好的体验,我们开通认证入口啦~完成认证,即可获得**“加急**”处理问题权限,加快问题响应速度:https://tidb.io/account/organization/new
完成团队认证,还可以获得 +200 经验值,+200 积分 ,并授予 “认证会员” 徽章!
详情了解:【已结束】完成认证抽“周边三件套”,解锁“加急”处理问题权限

BBS时代落幕?我们还有“下一代的论坛”——Discourse
在中国有着20年历史的网易论坛本周宣布将在下个月关闭服务,很多媒体称此举预示着中国传统BBS时代的日渐沉沦,还有网友担心天涯、豆瓣、西祠还能坚持多久? 
在互联网刚兴起的年代,论坛是重要的娱乐和信息来源,而随着互联网的发展,传统PC产物逐渐没落。很多人分析自从微博出现,论坛用户就被冲散了很多,所以微博也就被扣上了“终结BBS时代”的大帽子。 然而小R则觉得,微博简单粗暴、信息量大确实很受欢迎,但是随着微博上骂战四起,网络暴力、道德绑架横行,一定会有很多小伙伴会重新回归论坛。而且目前很多专业技术讨论和企业内部都还在使用论坛交流,所以BBS时代终结从何说起? 
说到论坛,小R今天为大家推荐一个搭建论坛的“工具”——Discourse。Discourse是 Stack Overflow 的联合创始人 Jeff Atwood 推出的一个新的开源论坛项目,其目的是为了改变十年未变的论坛软件,而且Discourse还声称要打造“下一代的论坛”。那今天小R就带大家走进这个“夸下海口”的Discourse…… 官方网站:https://www.discourse.org/Github项目:https://github.com/discourse/discourse 
Discourse之前,国内论坛用到最多的便是dvbbs和discuz,同国外受欢迎的phpbb相比要好用很多,而且功能也很多。与两位“前辈”不同,Discourse在设计上奉行简约而不简单,有很多细节:
弱化分类 在旧式论坛系统的设计中分类非常复杂称为版块(小R以前还是版主哦!),很多论坛版块分得太细而且多级分层很容易让初入论坛的用户头晕。分类多的情况实际操作起来也有很多困难,无论是对于网站管理员还是发帖者。而Discourse在这一点则更友好,它的首页会展示全站热帖,而不是分类目录。 
简化发布 编辑器相当简洁,而且好像是(又不完全是)Markdown的格式,方便后期格式化展示。目前其他论坛的编辑器多为html所见即所得编辑器(用Markdown的也一般有预览),编辑后还要点“预览”才能看到最终呈现方式。
简化功能 除了可以上传图片外,不能发其他附件。其实论坛内的附件真的很鸡肋,基本上所有用户都使用网盘互相分享文件,对于较大的文件国内论坛各种限制大小,还得分卷压缩下载,很是麻烦! 
简化展示 帖子以气泡的形式展示,更像我们平时用到的聊天工具。由于微博兴起,大家都习惯了碎片化阅读,很少有人会在论坛发长文(天涯上的小说除外)。而以往的论坛帖子展示太过繁琐(下图),浪费空间,不方便阅读。
其他细节 Discourse不同以往论坛帖子内容是一页一页的,而是一直向下滚动加载的实时内容流,而且它会记录你上次浏览记录;帖子中各楼的互动回复关联也更紧密,可立即展开查看;增加了社交网络里大家喜爱的点“赞”特性(再也不需要“顶楼主”了)。 
整体上来说,Discourse去掉了很多中看不中用的东西,回归简洁,迎合大众简单粗暴的获取信息方式。而这也是很多企业在建立内部论坛时喜欢使用Discourse的原因,更简单高效,在管理上也更便捷。而搭建Discourse也不会很复杂,在“好雨云市”上可以一键部署,而且还是免费试用哦!来,让小R带你一起领略云服务……

PS:小R给大家推荐几个用Discourse搭建的论坛,大家可以参考一下……
游戏氪:游戏圈内人吐槽,爆料,交流,学习,资源共享的社区 http://uxkkk.com/
GitHub中国开发者社区: http://ask.githuber.cn/
小众软件官方论坛 https://meta.appinn.com/

Debian / Ubuntu 上安装 Go 开发环境

Go 也被称为 Golang,它是由 Robert Griesemer、Rob Pike 和 Ken Thompson 在谷歌设计的一种免费的开源编程语言。由于它的简单性、效率和并发性,它是许多开发人员眼中的苹果。它的并发特性意味着它能够同时运行多个任务。
它主要用于后端目的,如服务器端编程。它主要用于游戏和云原生开发、命令行工具的开发、数据科学等等。
在本指南中,我们将逐步介绍如何在 Ubuntu Linux 上安装 Go 开发环境。
在 Linux 中安装 Go 有三种主要方式
- 使用官方二进制包安装
- 使用 APT 包管理器安装 (Debian / Ubuntu)
- 使用 Snap 包管理器安装
使用官方二进制包安装 Go
这是最受欢迎的安装方法,因为它提供了最新版本的 Go,并且适用于所有 Linux 发行版。
Step 1: 更新系统
登录到服务器并更新本地包索引
$ sudo apt updateStep 2: 下载 Go 二进制包
使用 wget 命令下载最新的 tarball 文件,在撰写本文时,Go 的最新版本是 v1.20.1
$ wget https://go.dev/dl/go1.20.1.linux-amd64.tar.gz
Step 3: 解压文件并将其移至 /usr/local 目录
使用如下命令,把文件解压到 /usr/local 目录
$ sudo tar -C /usr/local -xzf go1.20.1.linux-amd64.tar.gz-C 选项解压文件到 /usr/local 目录,查看 /usr/local/go 目录的内容
$ ls /usr/local/go
Step 4: 将 Go 二进制文件添加到 $PATH 环境变量中
打开 .bashrc 或者 .bash_profile 文件
$ nano ~/.bash_profile粘贴如下行
export PATH=$PATH:/usr/local/go/bin保存更改并退出文件

重新加载 .bashrc 或者 .bash_profile 文件
$ source ~/.bash_profileStep 5: 查看 GO 版本
使用 go version 命令查看版本号
$ go version
使用 APT 包管理器安装 Go
如果您正在运行 Debian / Ubuntu 发行版,并且不需要安装最新版本的 GO,使用 APT 包管理器安装是非常好的选择。
更新包索引
$ sudo apt update您可以先搜索 golang-go 软件包
$ apt search golang-go
使用如下命令安装 Go
$ sudo apt install golang-go
安装完成后,查看 go 版本
$ go version
使用 Snap 包管理器安装 Go
从 snap 安装 Go 非常简单。首先,您需要确保系统上已经启用了 snap。接下来,按照如下方式安装。
$ sudo snap install go --classic安装完成后,查看 GO 版本
$ /snap/bin/go version
测试 Go 安装
在本节中,我们将创建一个简单的 Go 程序并测试它,看看我们的安装是否有效。
为我们的项目创建一个单独的目录,如下所示
$ mkdir -p ~/go_projects/test接下来,切换到该目录
$ cd ~/go_projects/test创建一个名为 greetings 的简单程序,在终端上打印出一条简单的信息。
$ nano greetings.go将以下代码行复制并粘贴到文件中
package main
import "fmt"
func main() {
fmt.Printf("Congratulations! Go has successfully been installed on your system\n")
}保存并退出,然后运行程序,如下所示
$ go run greetings.go
我的开源项目

- course-tencent-cloud(酷瓜云课堂 - gitee仓库)
- course-tencent-cloud(酷瓜云课堂 - github仓库)

Discourse
Discourse 支持http://iosre.com/t/topic/2910/5 的访问

今天关于在 Ubuntu 上安装 Discourse 开发环境和ubuntu安装c++开发环境的介绍到此结束,谢谢您的阅读,有关AskTUG 论坛迁移实战:Discourse 从 PostgreSQL 到 MySQL 到 TiDB、BBS时代落幕?我们还有“下一代的论坛”——Discourse、Debian / Ubuntu 上安装 Go 开发环境、Discourse等更多相关知识的信息可以在本站进行查询。
本文标签:




