在这篇文章中,我们将为您详细介绍python常用web框架简单性能测试结果分享(包含dja的内容,并且讨论关于pythonweb框架性能对比的相关问题。此外,我们还会涉及一些关于2022XP框架开启d
在这篇文章中,我们将为您详细介绍python常用web框架简单性能测试结果分享(包含dja的内容,并且讨论关于python web框架性能对比的相关问题。此外,我们还会涉及一些关于2022XP框架开启debug模式Python常见web框架汇总-解析、400行python教你写个高性能http服务器+web框架,性能秒胜tornado uwsgi webpy django、Django-手撸简易web框架-实现动态网页-wsgiref初识-jinja2初识-python主流web框架对比-00、Django与其他Python Web框架?的知识,以帮助您更全面地了解这个主题。
本文目录一览:- python常用web框架简单性能测试结果分享(包含dja(python web框架性能对比)
- 2022XP框架开启debug模式Python常见web框架汇总-解析
- 400行python教你写个高性能http服务器+web框架,性能秒胜tornado uwsgi webpy django
- Django-手撸简易web框架-实现动态网页-wsgiref初识-jinja2初识-python主流web框架对比-00
- Django与其他Python Web框架?
")
python常用web框架简单性能测试结果分享(包含dja(python web框架性能对比)
测了一下django、flask、bottle、tornado 框架本身最简单的性能。对django的性能完全无语了。
django、flask、bottle 均使用gunicorn+gevent启动,单进程,并且关闭DEBUG,请求均只返回一个字符串ok。
tornado直接自己启动,其他内容一致。
测试软件为 siege,测试os为cenos6 64位,测试命令为:
代码如下:
siege -c 100 -r 100 -b http://127.0.0.1:5000/
django测试结果为:
代码如下:
Transactions: 10000 hits
Availability: 100.00 %
Elapsed time: 18.51 secs
Data transferred: 0.02 MB
Response time: 0.18 secs
Transaction rate: 540.25 trans/sec
Throughput: 0.00 MB/sec
Concurrency: 99.35
Successful transactions: 10000
Failed transactions: 0
Longest transaction: 0.30
Shortest transaction: 0.12
django(去掉所有middleware)测试结果为:
代码如下:
Transactions: 10000 hits
Availability: 100.00 %
Elapsed time: 12.97 secs
Data transferred: 0.02 MB
Response time: 0.13 secs
Transaction rate: 771.01 trans/sec
Throughput: 0.00 MB/sec
Concurrency: 99.41
Successful transactions: 10000
Failed transactions: 0
Longest transaction: 0.28
Shortest transaction: 0.12
flask测试结果为:
代码如下:
Transactions: 10000 hits
Availability: 100.00 %
Elapsed time: 5.47 secs
Data transferred: 0.02 MB
Response time: 0.05 secs
Transaction rate: 1828.15 trans/sec
Throughput: 0.00 MB/sec
Concurrency: 96.25
Successful transactions: 10000
Failed transactions: 0
Longest transaction: 0.11
Shortest transaction: 0.00
bottle测试结果为:
代码如下:
Transactions: 10000 hits
Availability: 100.00 %
Elapsed time: 4.55 secs
Data transferred: 0.02 MB
Response time: 0.04 secs
Transaction rate: 2197.80 trans/sec
Throughput: 0.00 MB/sec
Concurrency: 96.81
Successful transactions: 10000
Failed transactions: 0
Longest transaction: 0.09
Shortest transaction: 0.00
tornado测试结果为:
代码如下:
Transactions: 10000 hits
Availability: 100.00 %
Elapsed time: 7.06 secs
Data transferred: 0.02 MB
Response time: 0.07 secs
Transaction rate: 1416.43 trans/sec
Throughput: 0.00 MB/sec
Concurrency: 99.51
Successful transactions: 10000
Failed transactions: 0
Longest transaction: 0.09
Shortest transaction: 0.01
可见纯框架自身的性能为:
代码如下:
bottle flask tornado django
结合实际使用:
tornado 使用了异步驱动,所以在写业务代码时如果稍有同步耗时性能就会急剧下降;
bottle需要自己实现的东西太多,加上之后不知道性能会怎样;
flask性能稍微差点,但周边的支持已经很丰富了;
django就不说了,性能已经没法看了,唯一的好处就是开发的架子都已经搭好,开发速度快很多
因为最近正在为一个项目选型发愁,所以就测了一下,记录在此吧。
PS: 2014-6-23 使用 centos6 64位 重新进行了测试,得出与生产环境更匹配的结果,并修改了文章。

2022XP框架开启debug模式Python常见web框架汇总-解析

演示视频地址:
目前,有非常多的Python框架,用来帮助你更轻松的创建web应用。这些框架把相应的模块组织起来,使得构建应用的时候可以更快捷,也不用去关注一些细节(例如socket和协议),所以需要的都在框架里了。接下来我们会介绍不同的选项。
Python发源于八十年代后期。开发者是Centrum Wiskunde & informatica的Guido van Rossum,这是位于荷兰阿姆斯特丹科学园区的一个数学和计算机科学研究中心。之后Van Rossum一直是Python开发很有影响的人物。事实上,社区成员给了他一个荣誉称号:终生仁慈独裁者(BDFL)。
经过初期的不起眼,Python已经成为互联网最流行的服务端编程语言之一。根据W3Techs的统计,它被用于很多的大流量的站点,超过了ColdFusion, PHP, 和ASP.NET。其中超过98%的站点运行的是Python 2.0,只有1%多一点的站点运行3.0。
框架让开发更轻松
今天,有着大量的Python框架,它们可以让web应用的开发更轻松。这些框架把不同的模块集成在一起,让你更快的构架程序,而不用关注一些细节(例如socket和协议),框架提供了需要的所有功能。
作为分成两部分的系列文章的第一部分,我们会介绍一些最流行的Python框架。虽然大部分现代的web框架都运行在服务端,也有一些框架开始尝试与客户端代码结合,可以在客户端运行(例如Skulpt和Trinket)。Python框架通常分为全栈框架和非全栈框架。全栈框架设计从用户体验到数据库的所有技术,非全栈框架则并不包含整个开发的全部技术。
此外还有一种微框架,也属于非全栈框架,但是更轻量级。有的情况下,微框架是比较适合的,有时又适合使用全栈框架。在文章的第二部分我们会对全栈框架和微框架做一个比较。
Django

Django恐怕是最有代表性的Python框架了。它是一个遵循MMVC架构模式的开源框架。它的名字来自Django Reinhardt,一个法国作曲家和吉他演奏家,很多人认为他是历史上最伟大的吉他演奏家。位于堪萨斯洲的LaWrence城的LaWrence Journal-World报社有两位程序员,Adrian Holovaty和Simon Willison,他们在2003的时候开发出了Django,用于给报纸开发web程序。
Django内置了模板引擎,同时也通过OOTB来支持流行的Jinja2引擎。它还支持基于正则的URL分发,可以通过简单的URL来完成复杂的映射。
Django的优势之一是只需要单独的安装包来安装。其他的一些类似的框架需要下载很多组件才能开始工作。而且,Django还有完善的保持更新的文档,对于开源项目来说这通常是短板。它是一个健壮的框架,很好的集成了很多来自社区的插件和扩展。项目背后的社区看上去也组织的很好,这从它非常完善的文档和教程就可以看出来。
我学习的第一个框架就是django,方便入门,上手也比较快。个人觉得django的model不好用,主要是跨库联表不友好。 django官网
创建一个项目:
$ pip install django$ django-admin startproject djdemo cd djdemo $ django-admin startapp djapp $ tree -L 3 .├── djapp│ ├── __init__.py│ ├── admin.py│ ├── apps.py│ ├── migrations│ │ └── __init__.py│ ├── models.py│ ├── tests.py│ └── views.py├── djdemo│ ├── __init__.py│ ├── __pycache__│ │ ├── __init__.cpython-37.pyc│ │ └── settings.cpython-37.pyc│ ├── settings.py│ ├── urls.py│ └── wsgi.py└── manage.py复制代码下面我给出我一个项目的Django的目录结构。是django的经典目录结构形式:
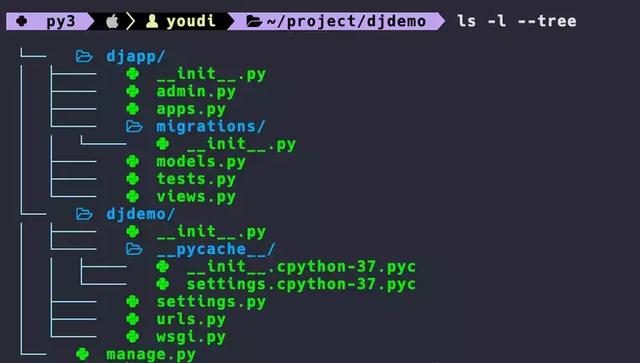
django很简单,Django生态很完备,基于django开发,一般需要的功能,都可以找到已经有的轮子。开发效率很高。django下的开发就是往框架中的填代码。另外就是不够灵活,太重。
django很多好用的脚手架
[django] check compilemessages createcachetable dbshell diffsettings dumpdata flush inspectdb loaddata makemessages makemigrations migrate runserver sendtestemail shell showmigrations sqlflush sqlmigrate sqlsequencereset squashmigrations startapp startproject test testserverturbogears

turbogears是在几个著名的Python项目上构建起来的一个框架,如sqlAlchemy,WebOb,Repoze,Genshi。在某种意义上,turbogears是将多个已经建立的开放平台粘合在一起。和Django一样,它采用MVC架构。它最近还包含一个“最小模式”,使其可以作为一个微框架。
turbogears是由Kevin Dangoor在2005年开发的。他在当年9月将其作为一个开源项目发布。2013年,项目开发人员迁移到支持Python 3,抛弃了他们曾经写的Pylons代码。turbogears的优点包括:
- 支持聚合
- 强大的对象关系映射器
- 事务系统支持多数据库间事务
- 多数据库支持
- 以可重用的代码片段为模板
- 具有很多的灵活性,可以对接非标准组件
- 支持分片
- 模板系统使设计师的设计更轻松
turbogears
turbogears官网
安装
$ pip install tg.devtools$ gearBox --helpusage: gearBox [--version] [-v | -q] [--log-file LOG_FILE] [-h] [--debug] [--relative]turbogears2 GearBox toolsetoptional arguments: --version show program's version number and exit -v, --verbose Increase verbosity of output. Can be repeated. -q, --quiet Suppress output except warnings and errors. --log-file LOG_FILE Specify a file to log output. disabled by default. -h, --help Show this help message and exit. --debug Show tracebacks on errors. --relative Load plugins and applications also from current path.Commands: help print detailed help for another command makepackage Creates a basic python package patch Patches files by replacing, appending or deleting text. quickstart Creates a new turbogears2 project scaffold Creates a new file from a scaffold template serve Serves a web application that uses a PasteDeploy configuration file setup-app Setup an application, given a config file tgext Creates a tgext.* package创建项目
$ gearBox quickstart tgdemo// 会生成很多文件.├── MANIFEST.in├── README.txt├── __pycache__│ └── setup.cpython-37.pyc├── development.ini├── migration│ ├── env.py│ ├── script.py.mako│ └── versions│ └── empty.txt├── setup.cfg├── setup.py├── test.ini├── tgdemo│ ├── __init__.py│ ├── config│ │ ├── __init__.py│ │ ├── app_cfg.py│ │ ├── environment.py│ │ └── middleware.py│ ├── controllers│ │ ├── __init__.py│ │ ├── controller.py.template│ │ ├── error.py│ │ ├── root.py│ │ └── secure.py│ ├── i18n│ │ └── ru│ ├── lib│ │ ├── __init__.py│ │ ├── app_globals.py│ │ ├── base.py│ │ └── helpers.py│ ├── model│ │ ├── __init__.py│ │ ├── auth.py│ │ └── model.py.template│ ├── public│ │ ├── css│ │ ├── favicon.ico│ │ ├── fonts│ │ ├── img│ │ └── javascript│ ├── templates│ │ ├── __init__.py│ │ ├── __pycache__│ │ ├── about.xhtml│ │ ├── data.xhtml│ │ ├── environ.xhtml│ │ ├── error.xhtml│ │ ├── index.xhtml│ │ ├── login.xhtml│ │ ├── master.xhtml│ │ └── template.xhtml.template│ ├── tests│ │ ├── __init__.py│ │ ├── functional│ │ └── models│ └── websetup│ ├── __init__.py│ ├── bootstrap.py│ └── schema.py└── tgdemo.egg-info ├── PKG-INFO ├── SOURCES.txt ├── dependency_links.txt ├── entry_points.txt ├── not-zip-safe ├── requires.txt └── top_level.txt22 directories, 48 files上面是按python包的方式生成的代码形式,方便打包分发。
用户只需要修改下面目录中的代码即可
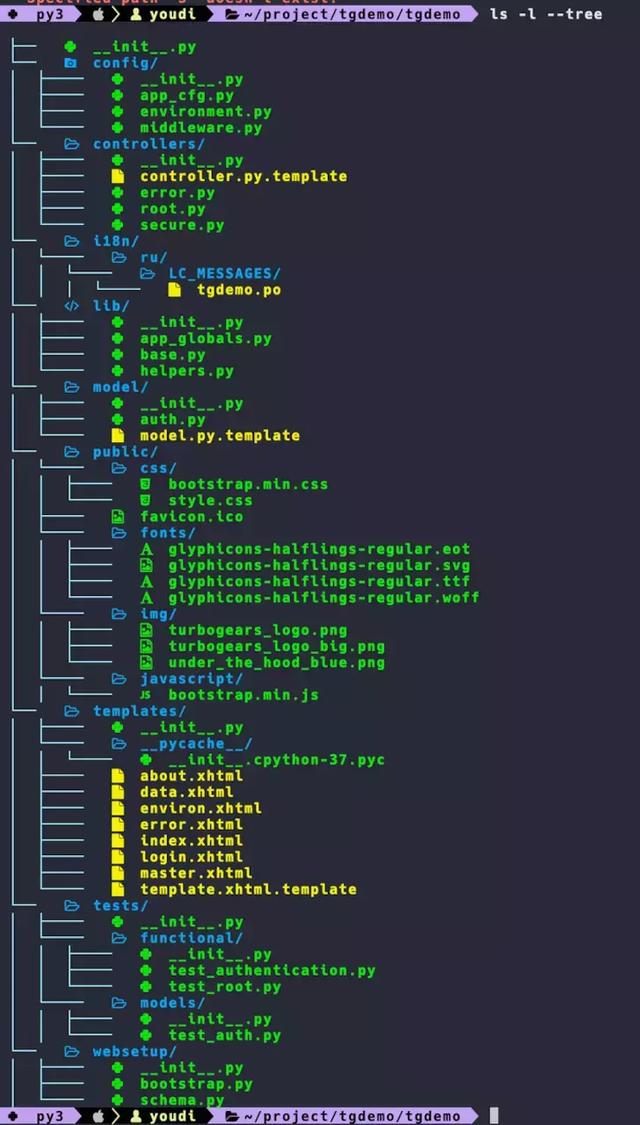
turbogears使用示例
from wsgiref.simple_server import make_server from tg import expose, TGController, AppConfig class RootController(TGController): @expose() def index(self): return "
Hello World
" config = AppConfig(minimal=True, root_controller=RootController()) print "Serving on port 8080..." httpd = make_server('', 8080, config.make_wsgi_app()) httpd.serve_forever()复制代码
web2py
web2py是一个开源框架,允许开发者快速创建动态交互式的网站。它的设计目标是消除拖慢开发的大量重复编程任务,比如创建基本的表格。它在最初是作为工具开发的。随后被Django和Ruby on Rails模仿,Ruby on Rails是个Ruby的框架。同turbogears一样,它使用MVC架构。
最开始的源代码是由Massimo DiPierro在2007年开放的。在那时,它被称为Enterprise Web Framework(EWF)。由于命名冲突,它改过好几次名字,最后在1.16版确定为当前的web2py。使用web2py开发的应用包括Movuca内容管理系统,音乐网站NoobMusic,名为LinkFindr的网络诊断工具,以及Instant Press博客平台。在2011年,web2py被评为最好的开源开发软件,荣获Bossie Award。第二年,又斩获InfoWorld的年度技术奖。
与Django一样,web2py也具有广泛的文档。新开发者和高级开发者可以免费下载它的完整开发手册。
web2py的一些优点包括:
- 容易使用——作为一个鲁棒的全栈式框架,它无需其他依赖就可以工作,容易学习和部署,安装也无需任何配置文件,一旦下载完成,安装完毕,就可以用了。开发者会获得一个数据库,一个基于web的IDE,web服务器以及一个有多个核心对象组成的强大API。
- 安全性出色——Web2py的模板语言减少了黑客使用跨站脚本的危险,抽象层在创建表单时有表单域有效性检查,避免sql注入,也阻止了跨站请求伪造攻击(csrf攻击)。会话被存储在服务器上,阻止坏的执行者把浏览器cookie弄乱,并且每个密码都是哈希后存储的。
web2py的一些缺点包括:
- 在常规基础上使用管理的接口不太容易
- 管理的接口没有权限
- 没有内建的单元测试支持
- 开发速度迅速,所有的函数都有缺省行为,表单时自动生成的,高层次的小部件和应用网格都是内建的
目录结构
project/ README LICENSE VERSION > this web2py version web2py.py > the startup script anyserver.py > to run with third party servers ... > other handlers and example files gluon/ > the core libraries packages/ > web2py submodules dal/ contrib/ > third party libraries tests/ > unittests applications/ > are the apps admin/ > web based IDE ... examples/ > examples, docs, links ... welcome/ > the scaffolding app (they all copy it) ABOUT LICENSE models/ views/ controllers/ sessions/ errors/ cache/ static/ uploads/ modules/ cron/ tests/ ... > your own apps examples/ > example config files, mv .. and customize extras/ > other files which are required for building web2py scripts/ > utility and installation scripts handlers/ wsgihandler.py > handler to connect to Wsgi ... > handlers for Fast-CGI, SCGI, Gevent, etc site-packages/ > additional optional modules logs/ > log files will go in there deposit/ > a place where web2py stores apps temporarily复制代码Flask
Flask是一个基于Jinja2和Werkzeug的python微框架,和其他框架类似,它是BSD授权的,一个有少量限制的免费软件许可。使用Flask的网站包括领英LinkedIN和Pinterest。Flask有以下特点:
- 内建的单元测试支持
- 模板使用Jinjia2
- 大量文档
- 客户端会话使用安全cookies
- 开发服务器和调试器
- Restful请求
- 与Wsgi 1.0兼容
- 基于unicode
- 大量的扩展
Flask是一个年轻的框架,2010年诞生,Flask的目标是不给程序员强加限制,允许你使用自己的数据库对象关系映射,模板引擎,会话中间件以及你的项目所需的其他组件,在我看来这就是这个微框架的用意。
我想说像Flask这样的框架更适合有经验的开发者,并不是小规模应用程序所必须的,当然,如果你只想做一个简单的REST API,那么Flask当然再好不过了。
flask我个人使用的也是比较多的。flask是微框架,比较灵活,适合小型项目。
示例代码
from flask import Flaskapp = Flask(__name__)@app.route('/')def hello(): return 'Hello, World!'复制代码flask的生态也很全,社区也是很活跃的,下面给出需要的资源。文档
Bottle

和flask一样,Bottle是一个服务器网关接口(Wsgi)网络框架。作为一个文件,它不依赖于Python标准库外的任何库。marcel Hellkamp于2009年写它的时候,它仅由包含模板、路由和一个Wsgi抽象层的最小工具开始。对于程序员寻找灵活性和基本功能、构建简单的应用程序和网站、创建一个Web API来说,这小并且强大的框架是极好的。
它的优点包括:
- 内建的快速模板引擎和对Jinja2,Mako和Cheetah的支持
- 可以访问上传,cookies,表单数据,标题,和其他元数据的大量工具
- 支持fapws3,Google App Engine,CherryPyPaste的内建HTTP开发服务器
- 支持动态URLs
Bottle的另一个优点是,它的小巧精干便于嵌入在一个较大应用程序中而不必担心系统依赖关系。如果你想用一个简单的,干净的和快速的框架并且它没有过多冗余,来创建小的应用程序,Bottle是适合你的。
示例代码:
from bottle import route, run, template@route('/hello/')def index(name): return template('Hello {{name}}!', name=name)run(host='localhost', port=8080)文档
多框架
虽然很难相信,但这些只是少数几十个开发人员可以使用Python框架,。Python.org报道,Django,turbogears和web2py是最受欢迎的完整选项。为了在框架优化方面提供一个全面的观察,这里我们添加了两个高级形态的微型框架。有着热情的追随者其他框架包括 Pyramid, web.py, Bobo, Albatross, 和 CherryPy。
找到正确的适合选择
正确框架的选择取决于项目的规模,它的通信需求,它是否是一个独立的应用程序,定制需求的级别,开销,和许多其他因素。同样重要的是,它取决于哪个框架适合你个人的工作方式。回顾这些项目并下载他们最新的版本。在计划一个主要旅行之前,试开一下确保你在一个合适的车辆中。

400行python教你写个高性能http服务器+web框架,性能秒胜tornado uwsgi webpy django
echo hello 性能压测abtest
nginx+tornado 9kqps
nginx+uwsgi 8kqps (注意:没说比nginx快,只是这几个web框架不行)
本server 3.2w qps
没用任何python加速
不相信的可以自己压测下哦
什么都不说400行代码加使用例子,欢迎吐槽,欢迎加好友一起进步
server.py
#!/usr/bin/python
#-*- coding:utf-8 -*-
# Copyright (c) 2012, Baidu.com Inc.
#
# Author : hemingzhe <512284622@qq.com>; xiaorixin <xiaorx@live.com>
# Date : Dec 20, 2012
#
import socket, logging
import select, errno
import os
import sys
import traceback
import Queue
import threading
import time
import thread
import cgi
from cgi import parse_qs
import json
import imp
from sendfile import sendfile
from os.path import join, getsize
import md5
import gzip
from StringIO import StringIO
from BaseHTTPServer import BaseHTTPRequestHandler
import re
logger = logging.getLogger("network-server")
action_dic = {}
action_time = {}
static_file_dir = "static"
static_dir = "/%s/" % static_file_dir
cache_static_dir = "cache_%s" % static_file_dir
if not os.path.exists(cache_static_dir):
os.makedirs(cache_static_dir)
filedic = {"HTM":None,"HTML":None,"CSS":None,"JS":None,"TXT":None}
def getTraceStackMsg():
tb = sys.exc_info()[2]
msg = ''''
for i in traceback.format_tb(tb):
msg += i
return msg
def md5sum(fobj):
m = md5.new()
while True:
d = fobj.read(65536)
if not d:
break
m.update(d)
return m.hexdigest()
class QuickHTTPRequest():
def __init__(self, data):
headend = data.find("\r\n\r\n")
rfile = ""
if headend > 0:
rfile = data[headend+4:]
headlist = data[0:headend].split("\r\n")
else:
headlist = data.split("\r\n")
self.rfile = StringIO(rfile)
first_line = headlist.pop(0)
self.command, self.path, self.http_version = re.split(''\s+'', first_line)
indexlist = self.path.split(''?'')
indexlist = indexlist[0].split(''/'')
while len(indexlist) != 0:
self.index = indexlist.pop()
if self.index == "":
continue
else:
self.action,self.method = os.path.splitext(self.index)
self.method = self.method.replace(''.'', '''')
break
self.headers = {}
for item in headlist:
if item.strip() == "":
continue
segindex = item.find(":")
if segindex < 0:
continue
key = item[0:segindex].strip()
value = item[segindex+1:].strip()
self.headers[key] = value
c_low = self.command.lower()
self.getdic = {}
self.form = {}
self.postdic = {}
if c_low == "get" and "?" in self.path:
self.getdic = parse_qs(self.path.split("?").pop())
elif c_low == "post" and self.headers.get(''Content-Type'',"").find("boundary") > 0:
self.form = cgi.FieldStorage(fp=self.rfile,headers=None,
environ={''REQUEST_METHOD'':self.command,''CONTENT_TYPE'':self.headers[''Content-Type''],})
if self.form == None:
self.form = {}
elif c_low == "post":
self.postdic = parse_qs(rfile)
def sendfilejob(request, data, epoll_fd, fd):
#print request.path,"3:",time.time()
try:
base_filename = request.path[request.path.find(static_dir)+1:]
cache_filename = "./cache_"+base_filename
filename = "./"+base_filename
if not os.path.exists(filename):
raise Exception("file not found")
name,ext = os.path.splitext(filename)
ext = ext.replace(''.'', '''')
iszip = False
etag = request.headers.get("If-Modified-Since", None)
#filemd5 = md5sum(file(filename))
filemd5 = str(os.path.getmtime(filename))
if ext.upper() in filedic:
if not os.path.exists(cache_filename) or (etag != None and etag != filemd5):
d,f = os.path.split(cache_filename)
try:
if not os.path.exists(d):
os.makedirs(d)
f_out = gzip.open(cache_filename, ''wb'')
f_out.write(open(filename).read())
f_out.close()
except Exception, e:
print str(e)
pass
filename = cache_filename
iszip = True
sock = data["connections"]
#sock.setblocking(1)
if etag == filemd5:
#sock.send("HTTP/1.1 304 Not Modified\r\nLast-Modified: %s\r\n\r\n" % filemd5)
data["writedata"] = "HTTP/1.1 304 Not Modified\r\nLast-Modified: %s\r\n\r\n" % filemd5
else:
data["sendfile"] = True
sock.setblocking(1)
offset = 0
filesize = os.path.getsize(filename)
f = open(filename, "rb")
if iszip:
headstr = "HTTP/1.0 200 OK\r\nContent-Length: %s\r\nLast-Modified: %s\r\nContent-Encoding: gzip\r\n\r\n" % (filesize,filemd5)
else:
headstr = "HTTP/1.0 200 OK\r\nContent-Length: %s\r\nLast-Modified: %s\r\n\r\n" % (filesize,filemd5)
sock.send(headstr)
while True:
sent = sendfile(sock.fileno(), f.fileno(), offset, 65536)
if sent == 0:
break # EOF
offset += sent
f.close()
data["writedata"] = ""
data["sendfile"] = False
#print request.path,"4:",time.time()
except Exception, e:
data["sendfile"] = False
#data["writedata"] = str(e)+getTraceStackMsg()
data["writedata"] = "file not found"
pass
try:
data["readdata"] = ""
epoll_fd.modify(fd, select.EPOLLET | select.EPOLLOUT | select.EPOLLERR | select.EPOLLHUP)
except Exception, e:
print str(e)+getTraceStackMsg()
class Worker(object):
def __init__(self):
pass
def process(self, data, epoll_fd, fd):
res = ""
add_head = ""
try:
request = QuickHTTPRequest(data["readdata"])
except Exception, e:
#return "http parser error:"+str(e)+getTraceStackMsg()
res = "http format error"
try:
headers = {}
headers["Content-Type"] = "text/html;charset=utf-8"
if request.path == "/favicon.ico":
request.path = "/"+static_file_dir+request.path
if static_dir in request.path or "favicon.ico" in request.path:
thread.start_new_thread(sendfilejob, (request,data,epoll_fd,fd))
#sendfilejob(request,data,epoll_fd,fd)
return None
action = action_dic.get(request.action, None)
if action == None:
action = __import__(request.action)
mtime = os.path.getmtime("./%s.py" % request.action)
action_time[request.action] = mtime
action_dic[request.action] = action
else:
load_time = action_time[request.action]
mtime = os.path.getmtime("./%s.py" % request.action)
if mtime>load_time:
action = reload(sys.modules[request.action])
action_time[request.action] = mtime
action_dic[request.action] = action
method = getattr(action, request.method)
res = method(request, headers)
if headers.get("Connection","") != "close":
data["keepalive"] = True
res_len = len(res)
headers["Content-Length"] = res_len
for key in headers:
add_head += "%s: %s\r\n" % (key, headers[key])
except Exception, e:
#res = str(e)+getTraceStackMsg()
res = "page no found"
try:
data["writedata"] = "HTTP/1.1 200 OK\r\n%s\r\n%s" % (add_head, res)
data["readdata"] = ""
epoll_fd.modify(fd, select.EPOLLET | select.EPOLLOUT | select.EPOLLERR | select.EPOLLHUP)
except Exception, e:
print str(e)+getTraceStackMsg()
def InitLog():
logger.setLevel(logging.DEBUG)
fh = logging.FileHandler("network-server.log")
fh.setLevel(logging.DEBUG)
ch = logging.StreamHandler()
ch.setLevel(logging.ERROR)
formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
ch.setFormatter(formatter)
fh.setFormatter(formatter)
logger.addHandler(fh)
logger.addHandler(ch)
class MyThread(threading.Thread):
ind = 0
def __init__(self, threadCondition, shareObject, **kwargs):
threading.Thread.__init__(self, kwargs=kwargs)
self.threadCondition = threadCondition
self.shareObject = shareObject
self.setDaemon(True)
self.worker = Worker()
def processer(self, args, kwargs):
try:
param = args[0]
epoll_fd = args[1]
fd = args[2]
self.worker.process(param, epoll_fd, fd)
except:
print "job error:" + getTraceStackMsg()
def run(self):
while True:
try:
args, kwargs = self.shareObject.get()
self.processer(args, kwargs)
except Queue.Empty:
continue
except :
print "thread error:" + getTraceStackMsg()
class ThreadPool:
def __init__( self, num_of_threads=10):
self.threadCondition=threading.Condition()
self.shareObject=Queue.Queue()
self.threads = []
self.__createThreadPool( num_of_threads )
def __createThreadPool( self, num_of_threads ):
for i in range( num_of_threads ):
thread = MyThread( self.threadCondition, self.shareObject)
self.threads.append(thread)
def start(self):
for thread in self.threads:
thread.start()
def add_job( self, *args, **kwargs ):
self.shareObject.put( (args,kwargs) )
def run_main(listen_fd):
try:
epoll_fd = select.epoll()
epoll_fd.register(listen_fd.fileno(), select.EPOLLIN | select.EPOLLET | select.EPOLLERR | select.EPOLLHUP)
except select.error, msg:
logger.error(msg)
tp = ThreadPool(16)
tp.start()
params = {}
def clearfd(fd):
epoll_fd.unregister(fd)
params[fd]["connections"].close()
del params[fd]
last_min_time = -1
while True:
epoll_list = epoll_fd.poll()
for fd, events in epoll_list:
cur_time = time.time()
if fd == listen_fd.fileno():
while True:
try:
conn, addr = listen_fd.accept()
#print "accept",time.time(),conn.fileno()
conn.setblocking(0)
epoll_fd.register(conn.fileno(), select.EPOLLIN | select.EPOLLET | select.EPOLLERR | select.EPOLLHUP)
conn.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
#conn.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, True)
params[conn.fileno()] = {"addr":addr,"writelen":0, "connections":conn, "time":cur_time}
except socket.error, msg:
break
elif select.EPOLLIN & events:
#print "read",time.time()
param = params[fd]
param["time"] = cur_time
datas = param.get("readdata","")
cur_sock = params[fd]["connections"]
while True:
try:
data = cur_sock.recv(102400)
if not data:
clearfd(fd)
break
else:
datas += data
except socket.error, msg:
if msg.errno == errno.EAGAIN:
#logger.debug("%s receive %s" % (fd, datas))
param["readdata"] = datas
len_s = -1
len_e = -1
contentlen = -1
headlen = -1
len_s = datas.find("Content-Length:")
if len_s > 0:
len_e = datas.find("\r\n", len_s)
if len_s > 0 and len_e > 0 and len_e > len_s+15:
len_str = datas[len_s+15:len_e].strip()
if len_str.isdigit():
contentlen = int(datas[len_s+15:len_e].strip())
headend = datas.find("\r\n\r\n")
if headend > 0:
headlen = headend + 4
data_len = len(datas)
if (contentlen > 0 and headlen > 0 and (contentlen + headlen) == data_len) or \
(contentlen == -1 and headlen == data_len):
tp.add_job(param,epoll_fd,fd)
#print "1:",time.time()
#thread.start_new_thread(process, (param,epoll_fd,fd))
break
else:
clearfd(fd)
logger.error(msg)
break
elif select.EPOLLHUP & events or select.EPOLLERR & events:
clearfd(fd)
logger.error("sock: %s error" % fd)
elif select.EPOLLOUT & events:
#print "write",time.time()
param = params[fd]
param["time"] = cur_time
sendLen = param.get("writelen",0)
writedata = param.get("writedata", "")
total_write_len = len(writedata)
cur_sock = params[fd]["connections"]
if writedata == "":
clearfd(fd)
continue
while True:
try:
sendLen += cur_sock.send(writedata[sendLen:])
if sendLen == total_write_len:
if param.get("keepalive", True):
param["readdata"] = ""
param["writedata"] = ""
param["writelen"] = 0
epoll_fd.modify(fd, select.EPOLLET | select.EPOLLIN | select.EPOLLERR | select.EPOLLHUP)
else:
clearfd(fd)
break
except socket.error, msg:
if msg.errno == errno.EAGAIN:
param["writelen"] = sendLen
break
else:
continue
#check time out
if cur_time - last_min_time > 10:
last_min_time = cur_time
objs = params.items()
for (key_fd,value) in objs:
fd_time = value.get("time", 0)
del_time = cur_time - fd_time
if del_time > 10:
sendfile = value.get("sendfile", False)
if sendfile != True:
clearfd(key_fd)
elif fd_time < last_min_time:
last_min_time = fd_time
if __name__ == "__main__":
InitLog()
port = int(sys.argv[1])
try:
listen_fd = socket.socket(socket.AF_INET, socket.SOCK_STREAM, 0)
except socket.error, msg:
logger.error("create socket failed")
try:
listen_fd.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
except socket.error, msg:
logger.error("setsocketopt SO_REUSEADDR failed")
try:
listen_fd.bind(('''', port))
except socket.error, msg:
logger.error("bind failed")
try:
listen_fd.listen(1024)
listen_fd.setblocking(0)
except socket.error, msg:
logger.error(msg)
child_num = 8
c = 0
while c < child_num:
c = c + 1
newpid = os.fork()
if newpid == 0:
run_main(listen_fd)
run_main(listen_fd)
用户文档:
1、启动:
指定监听端口即可启动
python server.py 8992
2、快速编写cgi,支持运行时修改,无需重启server
在PySvr.py同一目录下
随便建一个python 文件
例如:
example.py
定义一个tt函数:
则请求该函数的url为 http://ip:port/example.tt
修改后保存,即可访问,无需重启
example.py
def tt(request,response_head):
#print request.form
#print request.getdic
#print request.postdic
return "ccb"+request.path
函数必须带两个参数
request:表示请求的数据 默认带以下属性
headers: 头部 (字典)
form: multipart/form表单 (字典)
getdic: url参数 (字典)
postdic: httpbody参数 (字典)
rfile: 原始http content内容 (字符串)
action: python文件名 (这里为example)
method: 函数方法 (这里为tt)
command: (get or post)
path: url (字符串)
http_version: http版本号 (http 1.1)
response_head: 表示response内容的头部
例如如果要返回用gzip压缩
则增加头部
response_head["Content-Encoding"] = "gzip"
3、下载文件
默认静态文件放在static文件夹下
例如把a.jpg放到static文件夹下
访问的url为 http://ip:port/static/a.jpg
支持etag 客户端缓存功能
支持range 支持断点续传
(server 使用sendfile进行文件发送,不占内存且快速)
4、支持网页模板编写
创建一个模板 template.html
<HTML>
<HEAD><TITLE>$title</TITLE></HEAD>
<BODY>
$contents
</BODY>
</HTML>
则对应的函数:
def template(request,response_head):
t = Template(file="template.html")
t.title = "my title"
t.contents = "my contents"
return str(t)
模板实现使用了python最快速Cheetah开源模板,
性能约为webpy django thinkphp等模板的10倍以上:
http://my.oschina.net/whp/blog/112296
example.py
import os
import imp
import sys
import time
import gzip
from StringIO import StringIO
from Cheetah.Template import Template
def tt(request,response_head):
#print request.form
#print request.getdic
#print request.postdic
return "ccb"+request.path
def getdata(request,response_head):
f=open("a.txt")
content = f.read()
f.close()
response_head["Content-Encoding"] = "gzip"
return content
def template(request,response_head):
t = Template(file="template.html")
t.title = "my title"
t.contents = "my contents"
response_head["Content-Encoding"] = "gzip"
return str(t)
安装 如果需要使用web模板功能这里需要安装Cheetah
附件中有安装脚本

Django-手撸简易web框架-实现动态网页-wsgiref初识-jinja2初识-python主流web框架对比-00
[TOC]
自己动手实现一个简易版本的web框架
在了解python的三大web框架之前,我们先自己动手实现一个。
备注:
这部分重在掌握实现思路,代码不是重点
代码中也有许多细节并未考虑,重在实现思路
手撸一个web服务端
我们一般是使用浏览器当做客户端,然后基于HTTP协议自己写服务端代码作为服务端
先自行去回顾一下HTTP协议这一块儿的知识
import socket
server = socket.socket() # 基于socket通信(TCP)
server.bind((''127.0.0.1'', 8080))
server.listen(5)
while True:
conn, addr = server.accept()
data = conn.recv(2048) # 接收请求
print(str(data, encoding=''utf-8''))
conn.send(b''HTTP/1.1 200 OK\r\n\r\n'') # 依据HTTP协议,发送响应给客户端(浏览器),这里是响应首行 + 响应头 + 空行
# response = bytes(''<h3>这是响应内容</h3>'', encoding=''GBK'')
response = ''<h3>这是响应内容</h3>''.encode(''GBK'') # 我电脑上是GBK编码,所以使用GBK编码将字符串转成二进制
conn.send(response) # 继续发送响应体
conn.close() # 断开连接(无状态、无连接)
# 浏览器发过来的数据如下
''''''
GET / HTTP/1.1
Host: 127.0.0.1:8080
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: _qddaz=QD.w3c3g1.j2bfa7.jvp70drt; csrftoken=kJHVGICQOglLxJNiui0o0UyxNtR3cXbJPXqaUFs5FoxeezuskRO7jlQE0JNwYXJs
GET /favicon.ico HTTP/1.1
Host: 127.0.0.1:8080
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36
Accept: image/webp,image/apng,image/*,*/*;q=0.8
Referer: http://127.0.0.1:8080/
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: _qddaz=QD.w3c3g1.j2bfa7.jvp70drt; csrftoken=kJHVGICQOglLxJNiui0o0UyxNtR3cXbJPXqaUFs5FoxeezuskRO7jlQE0JNwYXJs
''''''
然后右键运行,在浏览器访问 127.0.0.1:8080 即可看到响应数据
关于启动服务器与页面请求(在我处理的时候,页面网络请求会经常处于 pending状态,不是很清楚原因,一般这个情况下,直接重启一下服务器即可)
根据请求 url 做不同的响应处理
上面的代码已经实现了基本请求响应,那如何根据不同的请求作出不同的响应呢?
我们输入不同的url,看看服务器端会返回什么
分析请求
浏览器访问 http://127.0.0.1:8080/index
GET /index HTTP/1.1
Host: 127.0.0.1:8080
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: _qddaz=QD.w3c3g1.j2bfa7.jvp70drt; csrftoken=kJHVGICQOglLxJNiui0o0UyxNtR3cXbJPXqaUFs5FoxeezuskRO7jlQE0JNwYXJs
浏览器访问 http://127.0.0.1:8080/home
GET /home HTTP/1.1
Host: 127.0.0.1:8080
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: _qddaz=QD.w3c3g1.j2bfa7.jvp70drt; csrftoken=kJHVGICQOglLxJNiui0o0UyxNtR3cXbJPXqaUFs5FoxeezuskRO7jlQE0JNwYXJs
原来请求首行的 GET 后面跟的就是请求我们想要信息(/index 首页、/home 家)
这些信息也是我们接收到的(data = conn.recv(2048) print(str(data, encoding=''utf-8''))),那可不可以取出来,根据值的不同作不同处理呢?
处理请求,获取 url
data = ''''''GET /home HTTP/1.1
Host: 127.0.0.1:8080
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: _qddaz=QD.w3c3g1.j2bfa7.jvp70drt; csrftoken=kJHVGICQOglLxJNiui0o0UyxNtR3cXbJPXqaUFs5FoxeezuskRO7jlQE0JNwYXJs''''''
print(data.split(''\n'')[0].split('' '')[1]) # ... ---> GET /home HTTP/1.1 --> [''GET'', ''/home'', ''HTTP/1.1''] --> /home
# /home
依据上述切割规则,我们来对不同的请求作出不同的响应
import socket
server = socket.socket()
server.bind((''127.0.0.1'', 8080))
server.listen(5)
while True:
conn, addr = server.accept()
data = conn.recv(2048).decode(''utf-8'')
data = data.split(''\n'')[0].split('' '')[1]
print(data)
conn.send(b''HTTP/1.1 200 OK\r\n\r\n'')
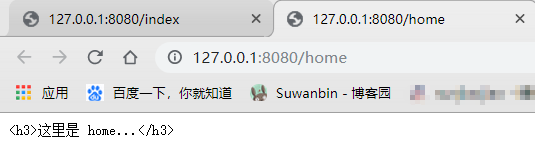
if data == ''/index'':
response = ''<h3>这里是 index...</h3>''.encode(''GBK'')
elif data == ''/home'':
response = ''<h3>这里是 home...</h3>''.encode(''GBK'')
else:
response = ''<h3>404 NOT FOUND...\n找不到您要找的资源...</h3>''.encode(''GBK'')
conn.send(response)
conn.close()
# --- 浏览器请求 http://127.0.0.1:8080/index 的打印信息
# /index
# /favicon.ico
# --- 浏览器请求 http://127.0.0.1:8080/home 的打印信息
# /home
# /favicon.ico
# --- 浏览器请求 http://127.0.0.1:8080/de2332f 的打印信息
# /de2332f
# /favicon.ico
页面成功显示不同的信息
http://127.0.0.1:8080/index

http://127.0.0.1:8080/home
http://127.0.0.1:8080/de2332f

404页面也应该算作设计网站的一部分,可以给人不一样的感觉
基于wsgiref模块实现服务端
前面处理 scoket 和 http 的那堆代码通常是不变的,且与业务逻辑没什么关系,如果每个项目都要写一遍,那岂不是很麻烦?那封装成模块嘛~
不过这个操作已经有人帮我们做了,并且封装的更加强大,就是 wsgiref 模块
用wsgiref 模块的做的两件事
- 在请求来的时候,自动解析 HTTP 数据,并打包成一个字典,便于对请求发过来的数据进行操作
- 发响应之前,自动帮忙把数据打包成符合 HTTP 协议的格式(响应数据格式,不需要再手动写
conn.send(b''HTTP/1.1 200 OK\r\n\r\n'')了),返回给服务端
from wsgiref.simple_server import make_server # 导模块
def run(env, response):
"""
先不管这里的 env 和 response 什么个情况
env:是请求相关的数据,wsgiref帮我们把请求包装成了一个大字典,方便取值
response:是响应相关的数据
"""
response(''200 OK'', [])
print(env)
current_path = env.get(''PATH_INFO'')
print(current_path)
if current_path == ''/index'':
return [''hello, there is index...''.encode(''utf-8'')]
elif current_path == ''/login'':
return [''hello, there is login...''.encode(''utf-8'')]
else:
return [''sorry... that pages you want is not found...''.encode(''utf-8'')]
if __name__ == ''__main__'':
# 实时监测 127.0.0.1:8080 地址,一旦有客户端连接,会自动加括号调用 run 方法
server = make_server(''127.0.0.1'', 8080, run)
server.serve_forever() # 启动服务器
# /index
# ---> env 的数据(手动删减了一些),可以看到其中有个 PATH_INFO 是我们要的东西(还有浏览器版本啊,USER-AGENT啊,客户端系统环境变量啊之类的信息)
''''''{''ALLUSERSPROFILE'': ''C:\\ProgramData'', ...省略部分... , ''COMSPEC'': ''C:\\Windows\\system32\\cmd.exe'', ''PROCESSOR_IDENTIFIER'': ''Intel64 Family 6 Model 60 Stepping 3, GenuineIntel'', ''PROCESSOR_LEVEL'': ''6'', ''PROCESSOR_REVISION'': ''3c03'', ''PYTHONIOENCODING'': ''UTF-8'', ''SESSIONNAME'': ''Console'', ''SYSTEMDRIVE'': ''C:'', ''SERVER_PORT'': ''8080'', ''REMOTE_HOST'': '''', ''CONTENT_LENGTH'': '''', ''SCRIPT_NAME'': '''', ''SERVER_PROTOCOL'': ''HTTP/1.1'', ''SERVER_SOFTWARE'': ''WSGIServer/0.2'', ''REQUEST_METHOD'': ''GET'', ''PATH_INFO'': ''/index'', ''QUERY_STRING'': '''', ''REMOTE_ADDR'': ''127.0.0.1'', ''CONTENT_TYPE'': ''text/plain'', ''HTTP_HOST'': ''127.0.0.1:8080'', ''HTTP_CONNECTION'': ''keep-alive'', ''HTTP_UPGRADE_INSECURE_REQUESTS'': ''1'', ''HTTP_USER_AGENT'': ''Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36'', ''HTTP_ACCEPT'': ''text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3'', csrftoken=kJHVGICQOglLxJNiui0o0UyxNtR3cXbJPXqaUFs5FoxeezuskRO7jlQE0JNwYXJs'', mode=''w'' encoding=''UTF-8''>, ''wsgi.version'': (1, 0), }''''''
伏笔

拆分服务端代码
服务端代码、路由配置、视图函数,照目前的写法全都冗在一块儿,后期功能扩展时,这个文件会变得很长,不方便维护,所以选择把他拆分开来
就是将服务端代码拆分成如下三部分:
-
server.py 放服务端代码
-
urls.py 放路由与视图函数对应关系
-
views.py 放视图函数/类(处理业务逻辑)
views.py
def index(env):
return ''index''
def login(env):
return ''login''
urls.py
from views import *
urls = [
(''/index'', index),
(''/login'', login),
]
server.py
from wsgiref.simple_server import make_server # 导模块
from urls import urls # 引入 urls.py 里的 urls列表(命名的不是很规范)
def run(env, response):
response(''200 OK'', [])
current_path = env.get(''PATH_INFO'')
func = None
for url in urls:
if current_path == url[0]:
func = url[1]
break
if func:
res = func(env)
else:
res = ''404 Not Found.''
return [res.encode(''utf-8'')] # 注意这里返回的是一个列表(可迭代对象才行),wsgiref 模块规定的,可能还有其他的用途吧
if __name__ == ''__main__'':
server = make_server(''127.0.0.1'', 8080, run)
server.serve_forever()
支持新的请求地址(添加新页面/新功能)
经过上面的拆分后,后续想要支持其他 url,只需要在 urls.py 中添加一条对应关系,在 views.py 中把该函数实现,重启服务器即可访问
以支持 http://127.0.0.1:8080/new_url 访问为例
urls.py
from views import *
urls = [
(''/index'', index),
(''/login'', login),
(''/new_url'', new_url),
]
views.py
def index(env):
return ''index''
def login(env):
return ''login''
def new_url(env):
# 这里可以写一堆逻辑代码
return ''new_url''
重启服务器,打开浏览器即可访问 http://127.0.0.1:8080/new_url
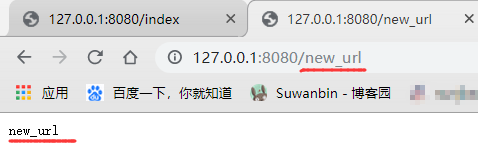
扩展性高了很多,且逻辑更清晰了,更不容易弄错(框架的好处提现,也是为什么脱离了框架不会写的原因,这块代码写的太少,不常用到,没了框架又写不出来)
动态静态网页--拆分模板文件
前面写了那么多,都只是一直在返回纯文本信息,而我们一般请求页面返回的都是浏览器渲染好的华丽的页面,那要怎么放回华丽的页面呢?
页面嘛,就是 HTML + CSS + JS 渲染出来的,所以我们也可以把 HTML文件当成数据放在响应体里直接返回回去
新建一个功能的步骤还是复习一下
- 在 urls.py 里面加一条路由与视图函数的对应关系
- 在 views.py 里面加上那个视图函数,并写好内部逻辑代码
- 重启服务器,浏览器打开页面访问
返回静态页面--案例
这里咱们就接着上面的 new_url 写,用他来返回 一个网页
新建一个 templates 文件夹,专门用来放 HTML 文件
templates/new_url.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>New URL</h1>
<h5>Wellcome!</h5>
</body>
</html>
views.py
def index(env):
return ''index''
def login(env):
return ''login''
def new_url(env):
# 读取并把 new_url 文件返回给客户端(浏览器)
with open(r''templates/new_url.html'', ''rb'') as f:
html_data = f.read()
return html_data.decode(''utf-8'') # 因为 run 函数那里做了 encode, 而二进制数据没有 encode这个方法,所以这里先解码一下,然后那边再编码一下
重启服务器,使用浏览器访问

上面提到了静态页面,那什么是静态页面?什么又是动态页面呢?
-
**静态网页:**纯html网页,数据是写死的,所有同url的请求拿到的数据都是一样的
-
**动态网页:**后端数据拼接,数据不是写死的,是动态拼接的,比如:
后端实时获取当前时间“传递”(塞)给前端页面展示
后端从数据库获取数据“传递”给前端页面展示
实现返回时间--插值思路(动态页面)
要怎么在 html 里插入时间呢?
往 html 里的插入?那替换好像也可以达到效果啊?
html_data = f.read() ? 好像 html 被读出出来了,而且还是二进制的,二进制可以 decode 变成字符串,字符串有 replace方法可以替换字符串,那我随便在网页里写点内容,然后替换成时间?
先把基础歩鄹做好
templates/get_time.html 编写展示页面
put_times_here 用来做占位符,一会儿给他替换成时间
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>北京时间:</h1>
<h1>put_time_here</h1>
</body>
</html>
urls.py 路由与视图函数对应关系
from views import *
urls = [
(''/index'', index),
(''/login'', login),
(''/new_url'', new_url),
(''/get_time'', get_time),
]
views.py 实现视图函数
def index(env):
return ''index''
def login(env):
return ''login''
def new_url(env):
# 读取并把 new_url 文件返回给客户端(浏览器)
with open(r''templates/new_url.html'', ''rb'') as f:
html_data = f.read()
return html_data
def get_time(env):
# 读取并把 get_time 文件返回给客户端(浏览器)
with open(r''templates/get_time.html'', ''rb'') as f:
html_data = f.read().decode(''utf-8'')
import time
html_data = html_data.replace(''put_time_here'', time.strftime("%Y-%m-%d %X"))
return html_data
重启服务器并打开浏览器访问 http://127.0.0.1:8080/get_time
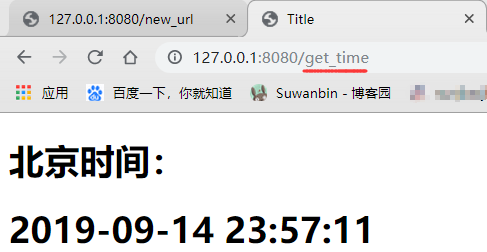
关键思路:相当于占位符,字符串替换,后期把前端要替换的字符的格式统一规定下,方便阅读与统一处理,这其实也就是目前的模版语法的雏形
我们只需要把处理好的字符串(HTML格式的)返回给浏览器,待浏览器渲染即可有页面效果
利用 jinja2 模块实现动态页面
jinja2模块有着一套 模板语法,可以帮我更方便地在 html 写代码(就想写后台代码一样),让前端也能够使用后端的一些语法操作后端传入的数据
安装 jinja2
jinja2 并不是 python 解释器自带的,所以需要我们自己安装
由于 flask 框架是依赖于 jinja2 的,所下载 flask 框架也会自带把 jinja2 模块装上
命令行执行,pip3 install jinja2 或图形化操作安装(参考 Django 的安装方法)
初步使用
这里只是知道有模板语法这么一个东西可以让我们很方便的往 html 写一些变量一样的东西,并不会讲 jinja2 的语法,后续会有的
案例--展示字典信息
urls.py
from views import *
urls = [
(''/index'', index),
(''/login'', login),
(''/new_url'', new_url),
(''/get_time'', get_time),
(''/show_dic'', show_dic),
]
views.py
def index(env):
return ''index''
def login(env):
return ''login''
def new_url(env):
# 读取并把 new_url 文件返回给客户端(浏览器)
with open(r''templates/new_url.html'', ''rb'') as f:
html_data = f.read()
return html_data
def get_time(env):
# 读取并把 get_time 文件返回给客户端(浏览器)
with open(r''templates/get_time.html'', ''rb'') as f:
html_data = f.read().decode(''utf-8'')
import time
html_data = html_data.replace(''put_time_here'', time.strftime("%Y-%m-%d %X"))
return html_data
def show_dic(env):
user = {
"username": "jason",
"age": 18,
}
with open(r''templates/show_dic.html'', ''rb'') as f:
html_data = f.read()
# 使用 jinja2 的模板语法来将数据渲染到页面上(替换占位符)
from jinja2 import Template
tmp = Template(html_data)
res = tmp.render(dic=user) # 将字典 user 传递给前端页面,前端页面通过变量名 dic 就能够获取到该字典
return res
templates/show_dic.html 写页面
jinja2 给字典扩展了点语法支持({{ dic.username }})
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>Nice to meet you~ i''m {{ dic.username }} , and i''m {{ dic.age }} years old.</h1>
<p>username: {{ dic[''username'']}}</p>
<p>age: {{ dic.get(''age'')}}</p>
</body>
</html>
重启服务器并打开浏览器访问 http://127.0.0.1:8080/show_dic

为什么说动态?
如果你改变了字典里的值,那么请求这个页面,显示的数据也会跟着改变(注意这个字典一般都是其他地方获取过来的)
模板语法(贴近python语法): 前端也能够使用后端的一些语法操作后端传入的数据
{{data.password}} # jinja2 多给字典做了 点语法支持
... 其他的语法,写法
for 循环
{%for user_dict in user_list%}
<tr>
<td>{{user_dict.id}}</td>
<td>{{user_dict.name}}</td>
<td>{{user_dict.password}}</td>
</tr>
{%endfor%}
进阶案例--渲染数据库数据到页面
思路
pymsql 从数据库取数据(指定成 列表套字典 的格式(DictCursor))
后台 python 代码处理数据
交由 jinja2 模块语法渲染到 html 页面上
数据条数不定怎么办?
有多少条记录就显示多少条呗...循环?
表格格式先写好,然后循环渲染数据到标签上(特定语法表示循环)
数据准备
创建数据库 django_test_db,然后执行如下 SQL 命令
/*
Navicat MySQL Data Transfer
Source Server : localhost-E
Source Server Type : MySQL
Source Server Version : 50645
Source Host : localhost:3306
Source Schema : django_test_db
Target Server Type : MySQL
Target Server Version : 50645
File Encoding : 65001
Date: 15/09/2019 00:41:09
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for user_info
-- ----------------------------
DROP TABLE IF EXISTS `user_info`;
CREATE TABLE `user_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`password` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
-- ----------------------------
-- Records of user_info
-- ----------------------------
INSERT INTO `user_info` VALUES (1, ''jason'', ''123'');
INSERT INTO `user_info` VALUES (2, ''tank'', ''123'');
INSERT INTO `user_info` VALUES (3, ''jerry'', ''123'');
INSERT INTO `user_info` VALUES (4, ''egon'', ''456'');
SET FOREIGN_KEY_CHECKS = 1;
配路由与视图函数
urls.py
from views import *
urls = [
(''/index'', index),
(''/login'', login),
(''/new_url'', new_url),
(''/get_time'', get_time),
(''/show_dic'', show_dic),
(''/get_users'', get_users),
]
views.py
def index(env):
return ''index''
def login(env):
return ''login''
def new_url(env):
# 读取并把 new_url 文件返回给客户端(浏览器)
with open(r''templates/new_url.html'', ''rb'') as f:
html_data = f.read()
return html_data
def get_time(env):
# 读取并把 get_time 文件返回给客户端(浏览器)
with open(r''templates/get_time.html'', ''rb'') as f:
html_data = f.read().decode(''utf-8'')
import time
html_data = html_data.replace(''put_time_here'', time.strftime("%Y-%m-%d %X"))
return html_data
def show_dic(env):
user = {
"username": "jason",
"age": 18,
}
with open(r''templates/show_dic.html'', ''rb'') as f:
html_data = f.read()
# 使用 jinja2 的模板语法来将数据渲染到页面上(替换占位符)
from jinja2 import Template
tmp = Template(html_data)
res = tmp.render(dic=user) # 将字典 user 传递给前端页面,前端页面通过变量名 dic 就能够获取到该字典
return res
# 先写个空函数在这里占位置,去把 pymysql 查数据的写了再过来完善
def get_users(env):
# 从数据库取到数据
import op_mysql
user_list = op_mysql.get_users()
with open(r''templates/get_users.html'', ''r'', encoding=''utf-8'') as f:
html_data = f.read()
from jinja2 import Template # 其实这个引入应该放在页面最上方去的,但为了渐进式演示代码推进过程,就放在这里了
tmp = Template(html_data)
res = tmp.render(user_list=user_list)
return res
**op_mysql.py **如果你的配置不一样要自己改过来
import pymysql
def get_cursor():
server = pymysql.connect(
# 根据自己电脑上 mysql 的情况配置这一块的内容
host=''127.0.0.1'',
port=3306,
user=''root'',
password=''000000'',
charset=''utf8'', # 千万注意这里是 utf8 !
database=''django_test_db'',
autocommit=True
)
cursor = server.cursor(pymysql.cursors.DictCursor)
return cursor
def get_users():
cursor = get_cursor() # 连接数据库
sql = "select * from user_info" # 把用户的所有信息查出来(一般不会把密码放回给前端的,这里只是为了做演示)
affect_rows = cursor.execute(sql)
user_list = cursor.fetchall()
return user_list
templates/get_users.html 用户信息展示页面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<!-- 引入jquery bootstrap 文件的 CDN -->
<script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.min.js"></script>
<link href="https://cdn.bootcss.com/twitter-bootstrap/3.4.1/css/bootstrap.min.css" rel="stylesheet">
<script src="https://cdn.bootcss.com/twitter-bootstrap/3.4.1/js/bootstrap.min.js"></script>
</head>
<body>
<div>
<div>
<div>
<h2>用户数据展示</h2>
<table>
<thead>
<tr>
<th>id</th>
<th>username</th>
<th>password</th>
</tr>
</thead>
<tbody>
<!-- jinja2 的模版语法(for循环) -->
{%for user_dict in user_list%}
<tr>
<td>{{user_dict.id}}</td>
<td>{{user_dict.username}}</td>
<td>{{user_dict.password}}</td>
</tr>
{%endfor%}
</tbody>
</table>
</div>
</div>
</div>
</body>
</html>
用浏览器访问 http://127.0.0.1:8080/get_users,重启服务器,在切回浏览器即可看到页面效果
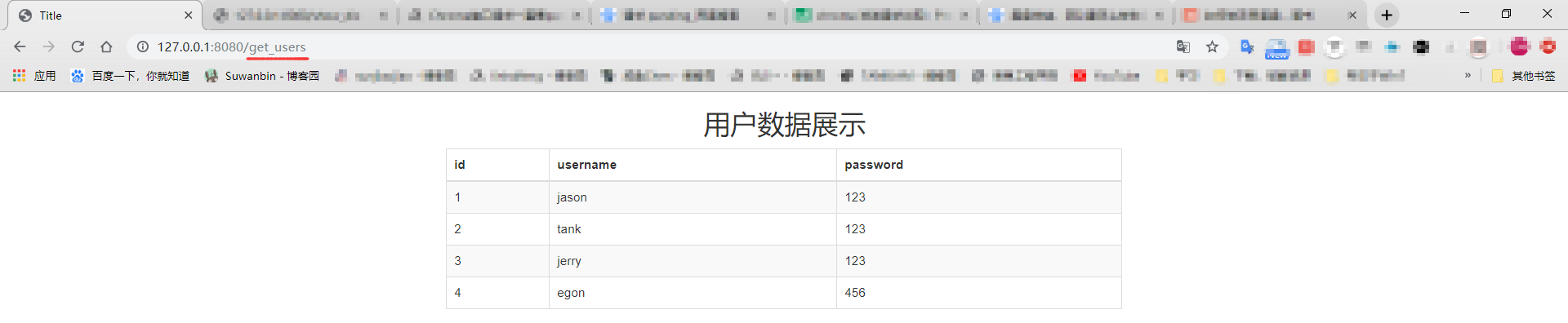
推导流程与小总结
1.纯手撸web框架
1.手动书写socket代码
2.手动处理http数据
2.基于wsgiref模块帮助我们处理scoket以及http数据(顶掉上面的歩鄹)
wsgiref模块
1.请求来的时候 解析http数据帮你打包成一个字典传输给你 便于你操作各项数据
2.响应走的时候 自动帮你把数据再打包成符合http协议格式的样子 再返回给前端
3.封装路由与视图函数对应关系 以及视图函数文件 网站用到的所有的html文件全部放在了templates文件夹下
1.urls.py 路由与视图函数对应关系
2.views.py 视图函数 (视图函数不单单指函数 也可以是类)
3.templates 模板文件夹
4.基于jinja2实现模板的渲染
模板的渲染
后端生成好数据 通过某种方式传递给前端页面使用(前端页面可以基于模板语法更加快捷简便使用后端传过来的数据)
流程图
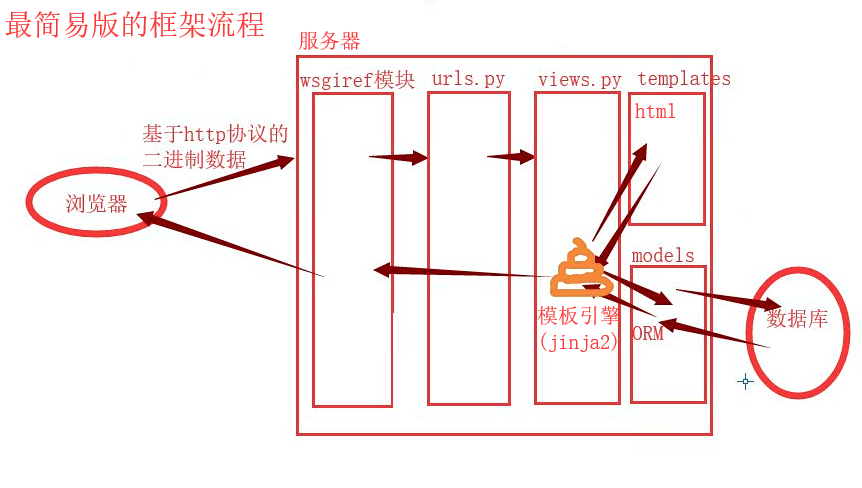
小扩展
在不知道是要 encode 还是 decode 的时候,可以用一下方法
二进制数据对应的肯定是 decode 解码 成字符串呀
字符串对应的肯定是 encode 编码成二进制数据呀
数据类型转换技巧(处理编码)(数据 + encoding)
# 转成 bytes 类型
bytes(data, encoding=''utf-8'')
# 转成 str 类型
str(data, encoding=''utf-8'')
python三大Web主流框架分析对比
Django
大而全,自带的功能特别特别多,就类似于航空母舰
**缺点:**有时过于笨重(小项目很多用不到)
Flask
短小精悍,自带的功能特别少,全都是依赖于第三方组件(模块)
第三方组件特别多 --> 如果把所有的第三方组件加起来,完全可以盖过django
**缺点:**比较受限于第三方的开发者(可能有bug等)
Tornado
天生的异步非阻塞框架,速度特别快,能够抗住高并发
可以开发游戏服务器(但开发游戏,还是 C 和C++用的多,执行效率更快)
手撸三大部分在框架中的情况对比
前面的手撸推导过程,整个框架过程大致可以分为以下三部分
A:socket处理请求的接收与响应的发送
B:路由与视图函数
C:模板语法给动态页面渲染数据
Django
A:用的<u>别人</u>的 wsgiref 模块 B:自带路由与视图函数文件 C:自带一套模板语法
Flask
A:用的<u>别人</u>的werkzeug 模块(基于 wsgiref 封装的) B:自带路由与视图函数文件 C:用的<u>别人</u>的jinja2
Tornado
A,B,C全都有自己的实现
Django的下载安装基本使用
参见我的另一篇博客:Django-下载安装-配置-创建django项目-三板斧简单使用
原文出处:https://www.cnblogs.com/suwanbin/p/11520959.html

Django与其他Python Web框架?
我已经尝试了每个存在的Python Web框架,花了很长时间我才意识到没有一个灵丹妙药的框架,每个框架都有其优点和缺点。我从Snakelets入手,非常高兴能够将几乎所有内容都控制在较低的水平上,而不必大惊小怪,但是后来我发现了TurboGears,从那时起我一直在使用它(1.x)。Catwalk和Web控制台之类的工具对我来说是无价的。
但是随着TurboGears 2的问世带来了WSGI的支持,并且在阅读了Django和WSGI阵营之间的宗教辩论之后,我真的为“以正确的方式做事”(例如学习WSGI,花费宝贵的时间编写功能)而感到困惑。在Django和其他全栈框架中已经存在,而不是使用Django或一些为我做所有事情的高级框架。我可以看到后者的缺点非常明显:
- 在此过程中我什么都没学
- 如果我需要做任何低级别的事情,那将是一件痛苦的事情
- 仅使用身份验证的基本站点所需的开销是疯狂的。(IMO)
所以,我想我的问题是,这是更好的选择,还是只是个见解,如果它以最小的麻烦实现了我想要的功能(我希望使用身份验证和CRUD接口,我的数据库)?我尝试了Werkzeug,Glashammer和朋友,但是AuthKit和Repoze吓坏了我,以及设置基本身份验证所需的步骤数。我看了看Pylons,但是似乎缺少文档,并且当引用诸如身份验证或CRUD界面之类的简单功能时,各种Wiki页面和文档似乎彼此矛盾,并且针对版本等使用了不同的技巧。
感谢S. Lott指出我还不够清楚。我的问题是:从长远来看,以下哪项是值得的,但短期内不会痛苦(例如,某种中间立场,有人吗?)-学习WSGI,还是坚持使用“含电池”框架?如果是后者,我将建议我是否应该再次尝试Django,还是坚持使用TurboGears 1.x,还是尝试其他框架。
另外,我尝试了CherryPy,但似乎找不到足够好的CRUD应用程序,因此无法立即使用它
答案1
小编典典我建议再看看TG2。我认为人们没有注意到自上一版以来取得的一些进步。除了可用的WSGI实用程序堆栈不断增长之外,还有很多TG2特定的项目需要考虑。以下是一些要点:
TurboGears管理系统 -使用声明性配置类可以完全自定义数据库的CRUD接口。它还与Dojo集成在一起,可为你提供无限滚动的表。服务器端验证也是自动的。管理界面使用RESTful网址和HTTP动词,这意味着可以很容易地通过编程连接到行业标准。
CrudRestController / RestController -TurboGears提供了一种结构化的方式来处理控制器中的服务。只需扩展我们的RestController,即可使用标准化的HTTP动词。将Sprox与CrudRestController 结合使用,你可以使用完全可自定义的自动生成的表格将Crud放置在应用程序中的任何位置。TurboGears现在支持MIME类型作为url中的文件扩展名,因此你可以让控制器使用与呈现html相同的界面来呈现.json和.xml(从控制器返回字典)
如果单击链接,你将看到我们用sphinx构建了一组新文档,该文档比过去的文档更广泛。
有了最好的Web服务器,ORM和模板系统(自行选择),就很容易看出TG对于希望快速上手并随着站点增长仍具有可伸缩性的人们有意义的原因。
人们通常认为TurboGears试图达到一个不断变化的目标,但是我们对发布保持一致,这意味着你不必担心为了获得所需的最新功能而费劲费力。面向未来:更多TurboGears扩展将使你的应用程序可以通过轻松的粘贴命令来扩展功能。
答案2
小编典典jango和WSGI阵营之间的宗教辩论
似乎你对WSGI是什么以及Django是什么有点困惑。说Django和WSGI正在竞争,就像在说C和SQL正在竞争:你正在比较苹果和桔子。
Django是框架,WSGI是服务器与框架交互的协议(受Django支持)。最重要的是,学习直接使用WSGI有点像学习程序集。这是一次很棒的学习经历,但实际上并不是你应该为生产代码执行的操作(也不打算这样做)。
无论如何,我的建议是自己解决这个问题。大多数框架都有“一小时内制作Wiki /博客/民意测验”类型的练习。与每个人花一点时间,找出最喜欢的一个。毕竟,如果你不愿意尝试这些框架,又如何决定呢?
今天关于python常用web框架简单性能测试结果分享(包含dja和python web框架性能对比的讲解已经结束,谢谢您的阅读,如果想了解更多关于2022XP框架开启debug模式Python常见web框架汇总-解析、400行python教你写个高性能http服务器+web框架,性能秒胜tornado uwsgi webpy django、Django-手撸简易web框架-实现动态网页-wsgiref初识-jinja2初识-python主流web框架对比-00、Django与其他Python Web框架?的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

