在这里,我们将给大家分享关于rabbitmq-web-stomp优化过程的知识,让您更了解rabbitmq优化配置的本质,同时也会涉及到如何更有效地1、RabbitMQ入门秘籍,三分钟带你快速了解Ra
在这里,我们将给大家分享关于rabbitmq-web-stomp 优化过程的知识,让您更了解rabbitmq优化配置的本质,同时也会涉及到如何更有效地1、RabbitMQ 入门秘籍,三分钟带你快速了解 RabbitMQ、CentOS 6 RabbitMQ 服务器搭建 PHP 客户端 C 扩展 AMQP 安装 rabbitmq-c 安装 PHP 多版本编译安装 C 扩展、CentOS-Docker 安装 RabbitMQ 集群 (rabbitmq:3.7.16-management)、Docker 下 RabbitMQ 四部曲之二:细说 RabbitMQ 镜像制作的内容。
本文目录一览:- rabbitmq-web-stomp 优化过程(rabbitmq优化配置)
- 1、RabbitMQ 入门秘籍,三分钟带你快速了解 RabbitMQ
- CentOS 6 RabbitMQ 服务器搭建 PHP 客户端 C 扩展 AMQP 安装 rabbitmq-c 安装 PHP 多版本编译安装 C 扩展
- CentOS-Docker 安装 RabbitMQ 集群 (rabbitmq:3.7.16-management)
- Docker 下 RabbitMQ 四部曲之二:细说 RabbitMQ 镜像制作
")
rabbitmq-web-stomp 优化过程(rabbitmq优化配置)
rabbitmq-web-stomp 优化过程
基础环境
- OS Centos 7 x86_64
- Erlang 19.0.3
- Rabbitmq 3.6.5
症状
-
OA系统显示有2200个人在线,但是Rabbitmq的连接数一直小于1300
-
IE8下会频繁出现连接错误的异常,重启rabbitmq后能够正常运行30分钟左右,问题重复出现
参考代码:
var stompClient=null;
function stompConnect(){
var ws=new SockJS(''http://localhost:15674/stomp'');
stompClient=Stomp.over(ws);
stompClient.connect(''guest'',''guest'',on_connected,on_error,''test'');
}
var on_connected=function(result){
if(stompClient!=null){
stompClient.subscribe(pattern,function(body){
//todo
})
}
}
var on_error=function(x){
setTimeout(stompConnect,10000);
}
stompConnect();
当用户少的时候可能正常运行到on_connected,随着用户的增加部分用户会丢失与rabbitmq的连接,频繁的执行on_error方法
优化过程
- 查看系统的并发数量
root@alice:~ # netstat -an | awk ''/^tcp/ { ++S[$NF]} END { for (a in S) print a, S[a]}''
LISTEN 19
ESTABLISHED 1674
FIN_WAIT1 1
FIN_WAIT2 537
TIME_WAIT 5295
并发数比较符合预期,OA系统的在线用户数在2200左右
- 查看15674端口打开的文件数数量
与15674端口建立连接的数量,OA系统的用户是通过web_stomp与rabbitmq进行交互
root@alice:~# lsof -i:5674|grep ''TCP''|wc -l
1034
经过多次执行 lsof -i:5674|wc -l 发现这个数字永远小于等于1034,以OA系统2200在线用户的规模应该有可能会超过这个数值才对(猜测)
- 查看
rabbitmq的错误日志
root@alice:~# tail /data/rabbitmq_server-3.6.5/var/log/rabbitmq/rabbit@alice.log -n 1000|grep ''ERROR'' -B 2 -A 2
Error in process <0.12547.685> on node ''rabbit@alice'' with exit value: {[{reason,{badmatch,{error,timeout}}},{mfa,{sockjs_cowboy_handler,handle,2}},{stacktrace,[{sockjs_http,body,1,[{file,"src/sockjs_http.erl"},{line,36}]},{sockjs_action,xhr_send,4,[{file,"src/sockjs_action.erl"},{line,144}]},{sockjs_handler...
官方文档描述了有关的web stomp和Ranch的配置,怀疑是不是因为Ranch的参数配置导致15674端口使用最大只能有1034个连接

Ranch配置有关的配置项似乎没有与连接数有关的配置。
Ranch 1.3 User Guide关于concurrent connections描述了最大连接数的限制
The max_connections transport option allows you to limit the number of concurrent connections.
It defaults to 1024. Its purpose is to prevent your system from being overloaded and
ensuring all the connections are handled optimally.
Customizing the maximum number of concurrent connections
{ok, _} = ranch:start_listener(tcp_echo, 100,
ranch_tcp, [{port, 5555}, {max_connections, 100}],
echo_protocol, []
).
You can disable this limit by setting its value to the atom infinity.
Disabling the limit for the number of connections
{ok, _} = ranch:start_listener(tcp_echo, 100,
ranch_tcp, [{port, 5555}, {max_connections, infinity}],
echo_protocol, []
).
The maximum number of connections is a soft limit. In practice,
it can reach max_connections + the number of acceptors.
When the maximum number of connections is reached, Ranch will stop accepting connections.
This will not result in further connections being rejected, as the kernel option allows queueing incoming connections.
The size of this queue is determined by the backlog option and defaults to 1024. Ranch does not know about the number of
connections that are in the backlog.
文中描述了max_connections是一个软的限制,实际限制是max_connections+acceptors的数量,acceptors默认是10所以通过
lsof -i:15674|grep TCP|wc -l
获取的值是1034
1034=1024(max_connections)+10(acceptors)
至此,可以通过设定max_connections来增加rabbitmq_web_stomp的并发限制
[
{rabbit,[
{hipe_compile,true},
{dis_free_limit,"5GB"}
]
},
{rabbitmq_web_stomp,[
{tcp_config,[
{backlog,3000},
{max_connections,5000}
]}
]
}
].
将最大连接数增加到5000,比较遗憾的是Ranch配置选项中没有明确指出max_connectioins的配置,导致走了不少弯路
优化结果
修改配置重启RabbitMQ服务后,不断监控日志的情况及15674端口的连接数量,比较正常
lsof -i:15674|grep TCP|wc -l
1683
root@alice:~# tail /data/rabbitmq_server-3.6.5/var/log/rabbitmq/rabbit@alice.log -n 1000|grep ''ERROR'' -B 2 -A 2
无错误信息
总结
- 新系统上线对负载预估不足
- 对RabbitMQ熟悉程度有待加强

1、RabbitMQ 入门秘籍,三分钟带你快速了解 RabbitMQ
一、前言
刚开始接触 RabbitMQ 的时候,有些概念那理解起来简直是像风像雨又像雾,晦涩难懂。 这篇文章用尽可能浅显的语言来解释 RabbitMQ 的入门知识。毕竟是入门课程,并没有对很多概念进行深入说明,如果你想更深入的了解 RabbitMQ,可以继续关注本头条号后续发布的文章或者自己从网上搜寻了资料,自己探索研究。
二、RabbitMQ 是什么
官方定义:RabbitMQ 是一种消息中间件,用于处理来自客户端的异步消息。服务端将要发送的消息放入到队列池中。接收端可以根据 RabbitMQ 配置的转发机制接收服务端发来的消息。RabbitMQ 依据指定的转发规则进行消息的转发、缓冲和持久化操作,主要用在多服务器间或单服务器的子系统间进行通信,是分布式系统标准的配置。 趣味定义:兔子行动非常迅速而且繁殖起来也非常疯狂,用 Rabbit 来命名这个分布式软件,呼应了 RabbitMQ 的主要任务是处理海量的信息
三、安装
1、安装 erlang
下载地址:http://erlang.org/download/otp_win64_21.0.1.exe
2、安装 rabbitmq
下载地址:https://dl.bintray.com/rabbitmq/all/rabbitmq-server/3.7.7/rabbitmq-server-3.7.7.exe 如果你要安装其它版本,注意版本对应:https://www.rabbitmq.com/which-erlang.html
3、开启 web 访问
Windows 下:打开 CMD 进入 rabbitmq 的安装目录 执行 rabbitmq-plugins enable rabbitmq_management 命令 该命令,仅在首次运行 RMQ 时使用!!!目的就是加载 Web 插件!!! 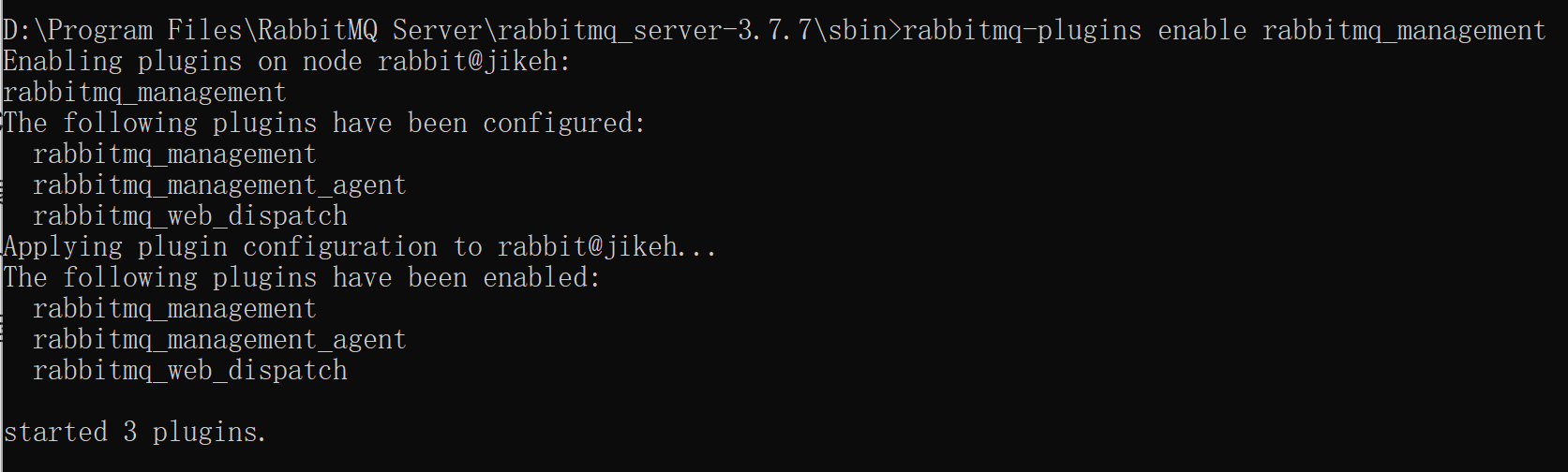
4、访问测试:http://localhost:15672/
默认用户名:guest 默认密码:guest 
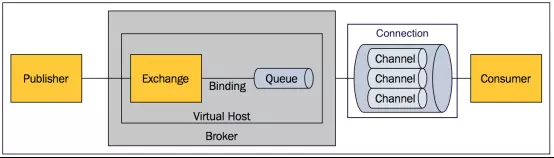
四、核心概念

 https://content.pivotal.io/rabbitmq/understanding-when-to-use-rabbitmq-or-apache-kafka
https://content.pivotal.io/rabbitmq/understanding-when-to-use-rabbitmq-or-apache-kafka
- RabbitMQ broker,原话是 RabbitMQ isn’t a food truck, it’s a delivery service,其实说白了,就是一种传输服务。
- Exchange: 接受生产者发送的消息,并根据 Binding 规则将消息路由给服务器中的队列。ExchangeType 决定了 Exchange 路由消息的行为。在 RabbitMQ 中,ExchangeType 常用的有 direct、Fanout 和 Topic 三种,在第三部分会详细介绍。
- Message Queue: 消息队列。我们发送给 RabbitMQ 的消息最后都会到达各种 queue,并且存储在其中 (如果路由找不到相应的 queue 则数据会丢失),等待消费者来取。
- Binding Key:它表示的是 Exchange 与 Message Queue 是通过 binding key 进行联系的,这个关系是固定的,初始化的时候,我们就会建立该队列。
- Routing Key:生产者在将消息发送给 Exchange 的时候,一般会指定一个 routing key,来指定这个消息的路由规则。这个 routing key 需要与 Exchange Type 及 binding key 联合使用才能生,我们的生产者只需要通过指定 routing key 来决定消息流向哪里。
- 我的注释:初始化的时候,exchange 与各个队列的绑定关系是通过 binding key 进行绑定的;发送消息的时候,使用的 routing key 就是 binding key 的某一个(实质,两者是一个含义,角度不同,名称含义不同) 对于消费端来说,只用知道 MQ 的 virtual host 和 queue 的名称就可以了。而对于发送端,则需要知道 exchange 和 routing key 的名称,相对而言 queue 的名称就不那么重要了(不过也要依 Exchange Type 而定)。
以下是 RabbitMQ 最简单的流程图,相信看到这里的你,对 MQ 的运作流程应该会有个基本的了解了: 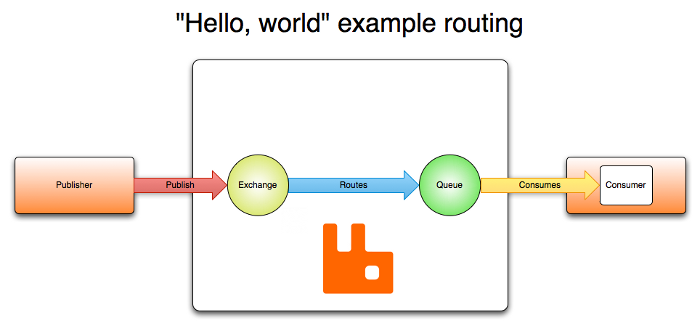
五、三种 ExchangeType
http://www.rabbitmq.com/tutorials/amqp-concepts.html 这里介绍三种最主要的类型的 exchange:direct、fanout 和 topic。
1、direct 交换器
 Direct 交换器很简单,如果是 Direct 类型,就会将消息中的 RoutingKey 与该 Exchange 关联的所有 Binding 中的 BindingKey 进行比较,如果相等,则发送到该 Binding 对应的 Queue 中。有一个需要注意的地方:如果找不到指定的 exchange,就会报错。但 routing key 找不到的话,不会报错,这条消息会直接丢失,所以此处要小心。
Direct 交换器很简单,如果是 Direct 类型,就会将消息中的 RoutingKey 与该 Exchange 关联的所有 Binding 中的 BindingKey 进行比较,如果相等,则发送到该 Binding 对应的 Queue 中。有一个需要注意的地方:如果找不到指定的 exchange,就会报错。但 routing key 找不到的话,不会报错,这条消息会直接丢失,所以此处要小心。
2、fanout 交换器
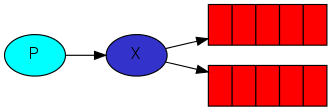 Fanout 扇出,顾名思义,就是像风扇吹面粉一样,吹得到处都是。如果使用 fanout 类型的 exchange,那么 routing key 就不重要了。因为凡是绑定到这个 exchange 的 queue,都会受到消息。
Fanout 扇出,顾名思义,就是像风扇吹面粉一样,吹得到处都是。如果使用 fanout 类型的 exchange,那么 routing key 就不重要了。因为凡是绑定到这个 exchange 的 queue,都会受到消息。
3、topic 交换器
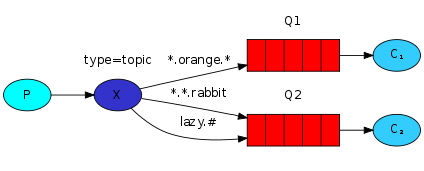
- direct 是将消息放到 exchange 绑定的一个 queue 里(一对一);
- fanout 是将消息放到 exchange 绑定的所有 queue 里(一对所有) 那可不可以把消息放到 exchange 绑定的一部分 queue 里,或者多个 routing key 可以路由到一个 queue 里呢?
- topic 类型的 exchange 就可以实现(一对部分)。
- topic 应用场景:打印不同级别的错误日志 例如,我们的系统出错后会根据不同的错误级别生成 error_levelX.log 日志,我们在后台首先要把所有的 error 保存在一个总的 queue(绑定了一个 *.error 的路由键)里,然后再按 level 分别存放在不同的 queue。
routing key 绑定如下图: 
更多资料分享,问题咨询,可以入群讨论:375412858 请入群索要代码 

CentOS 6 RabbitMQ 服务器搭建 PHP 客户端 C 扩展 AMQP 安装 rabbitmq-c 安装 PHP 多版本编译安装 C 扩展
背景
基于 CentOS 6 环境安装 RabbitMQ 3.7.24
步骤
服务端
安装
yum install build-essential openssl openssl-devel unixODBC unixODBC-devel make gcc gcc-c++ kernel-devel m4 ncurses-devel tk tc xz unixODBC unixODBC-devel wxBase wxGTK SDL wxGTK-gl socat cmake
wget https://packages.erlang-solutions.com/erlang/rpm/centos/6/x86_64/esl-erlang_21.0.5-1\~centos\~6_amd64.rpm
wget https://raw.githubusercontent.com/jasonmcintosh/esl-erlang-compat/master/rpmbuild/RPMS/noarch/esl-erlang-compat-R14B-1.el6.noarch.rpm
wget https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.7.24/rabbitmq-server-3.7.24-1.el6.noarch.rpm
rpm -ivh esl-erlang_21.0.5-1\~centos\~6_amd64.rpm
rpm -ivh esl-erlang-compat-R14B-1.el6.noarch.rpm
rpm -ivh rabbitmq-server-3.7.24-1.el6.noarch.rpm
rabbitmq-server start &
rabbitmq-plugins enable rabbitmq_management
netstat -tunlp |grep 5672
账户
rabbitmqctl add_user admin 123456
rabbitmqctl set_user_tags admin administrator
rabbitmqctl set_permissions -p / admin ''.*'' ''.*'' ''.*''
rabbitmqctl delete_user guest
访问
浏览器直接访问控制面板:http://XXXXXXXX:15672/ 。
客户端
wget https://github.com/alanxz/rabbitmq-c/archive/v0.10.0.tar.gz
tar zxvf v0.10.0.tar.gz
cd rabbitmq-c-0.10.0
mkdir build && cd build
cmake ..
cmake --build .
make
make install
wget https://github.com/pdezwart/php-amqp/archive/v1.9.4.tar.gz
tar zxvf v1.9.4.tar.gz
cd php-amqp-1.9.4
/usr/bin/phpize #PHP多版本编译安装扩展核心所在 1/2
./configure -with-php-config=/usr/bin/php-config --with-librabbitmq-dir=/usr/local/ #PHP多版本编译安装扩展核心所在 2/2
make
make install
ln -s /usr/local/lib64/librabbitmq.so.4 /usr/lib64/librabbitmq.so.4
vim /etc/php.ini
[amqp]
extension=amqp.so
sudo service php-fpm56 restart
结束。
")
CentOS-Docker 安装 RabbitMQ 集群 (rabbitmq:3.7.16-management)
准备工作
1. 机器资源 (分别安装 docker 环境)
建议机器配置: centos7.x 4G 及以上 100GB 及以上 2 核及以上
192.168.1.101
192.168.1.102
192.168.1.103
2. 分别配置 hosts 文件,追加
$ vim /home/rabbitmq/hosts
192.168.1.101 rabbit1 rabbit1
192.168.1.102 rabbit2 rabbit2
192.168.1.103 rabbit3 rabbit3
下载镜像(每台机器)
$ docker pull rabbitmq:3.7.16-management
创建目录 (每台机器)
$ mkdir -p /home/rabbitmq
运行镜像(每台机器)
创建容器 (rabbit1)
$ docker run --restart=unless-stopped -h rabbit1 -d -p 5672:5672 -p 15672:15672 -p 25672:25672 -p 4369:4369 --name myrabbit1 \
-v /home/rabbitmq:/var/lib/rabbitmq:z -v /home/rabbitmq/hosts:/etc/hosts \
-e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=123456 -e RABBITMQ_ERLANG_COOKIE=''xxx_2019'' rabbitmq:3.7.16-management
创建容器 (rabbit2)
$ docker run --restart=unless-stopped -h rabbit2 -d -p 5672:5672 -p 15672:15672 -p 25672:25672 -p 4369:4369 --name myrabbit2 \
-v /home/rabbitmq:/var/lib/rabbitmq:z -v /home/rabbitmq/hosts:/etc/hosts \
-e RABBITMQ_ERLANG_COOKIE=''xxx_2019'' rabbitmq:3.7.16-management
创建容器 (rabbit3)
$ docker run --restart=unless-stopped -h rabbit3 -d -p 5672:5672 -p 15672:15672 -p 25672:25672 -p 4369:4369 --name myrabbit3 \
-v /home/rabbitmq:/var/lib/rabbitmq:z -v /home/rabbitmq/hosts:/etc/hosts \
-e RABBITMQ_ERLANG_COOKIE=''xxx_2019'' rabbitmq:3.7.16-management
参数说明
#容器后台运行
-d
#容器的主机名为 rabbit_master,容器内部的 hostname
--hostname rabbit_master
#将宿主机目录 /home/rabbitmq 挂载到容器的 /var/lib/rabbitmq 目录。z 是一个标记,在 selinux 环境下使用。
-v /home/rabbitmq:/var/lib/rabbitmq:z
#设置 rabbitmq 的 cookie 可以自定义为其他文本,三个容器保持一致即可。
-e RABBITMQ_ERLANG_COOKIE=''xxx_2019''
绑定集群
将 myrabbit1 节点重置
$ docker exec -it myrabbit1 bash
$ rabbitmqctl stop_app && \
rabbitmqctl reset && \
rabbitmqctl start_app
将 myrabbit2 节点加入集群
$ docker exec -it myrabbit2 bash
$ rabbitmqctl stop_app && \
rabbitmqctl reset && \
rabbitmqctl join_cluster rabbit@rabbit1 && \
rabbitmqctl start_app
将 myrabbit3 节点加入集群
$ docker exec -it myrabbit3 bash
$ rabbitmqctl stop_app && \
rabbitmqctl reset && \
rabbitmqctl join_cluster rabbit@rabbit2 && \
rabbitmqctl start_app
查询集群状态
$ rabbitmqctl cluster_status
故障节点的处理
$ docker exec -it rabbit2 /bin/bash
$ rabbitmqctl stop_app
#在一个正常的节点上移除有问题的节点
$ docker exec -it rabbit1 /bin/bash
$ rabbitmqctl forget_cluster_node rabbit@rabbit2
使用说明
springboot 集成
spring.rabbitmq.addresses=192.168.1.101:5672,192.168.1.102:5672,192.168.1.103:5672
spring.rabbitmq.username=admin
spring.rabbitmq.password=123456
spring.rabbitmq.virtual-host=/#支持手动 ack 模式
spring.rabbitmq.listener.simple.acknowledge-mode=manual
#每个并发的预取条数
spring.rabbitmq.listener.simple.prefetch=10
#并发数
spring.rabbitmq.listener.simple.concurrency=3
#最大并发数
spring.rabbitmq.listener.simple.max-concurrency=10
spring.rabbitmq.listener.direct.acknowledge-mode=manual
队列模式分为普通模式和镜像模式,集群模式建议直接使用镜像队列
1. 全部节点镜像策略创建
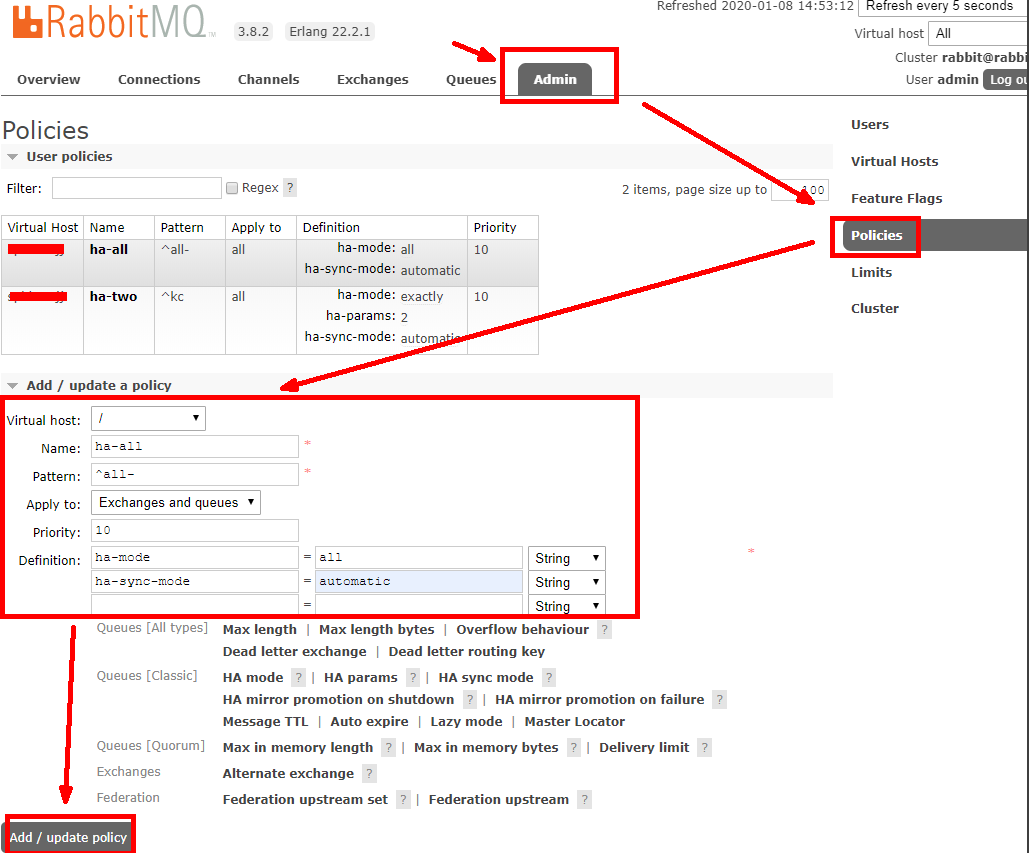
2. 指定节点数镜像策略创建
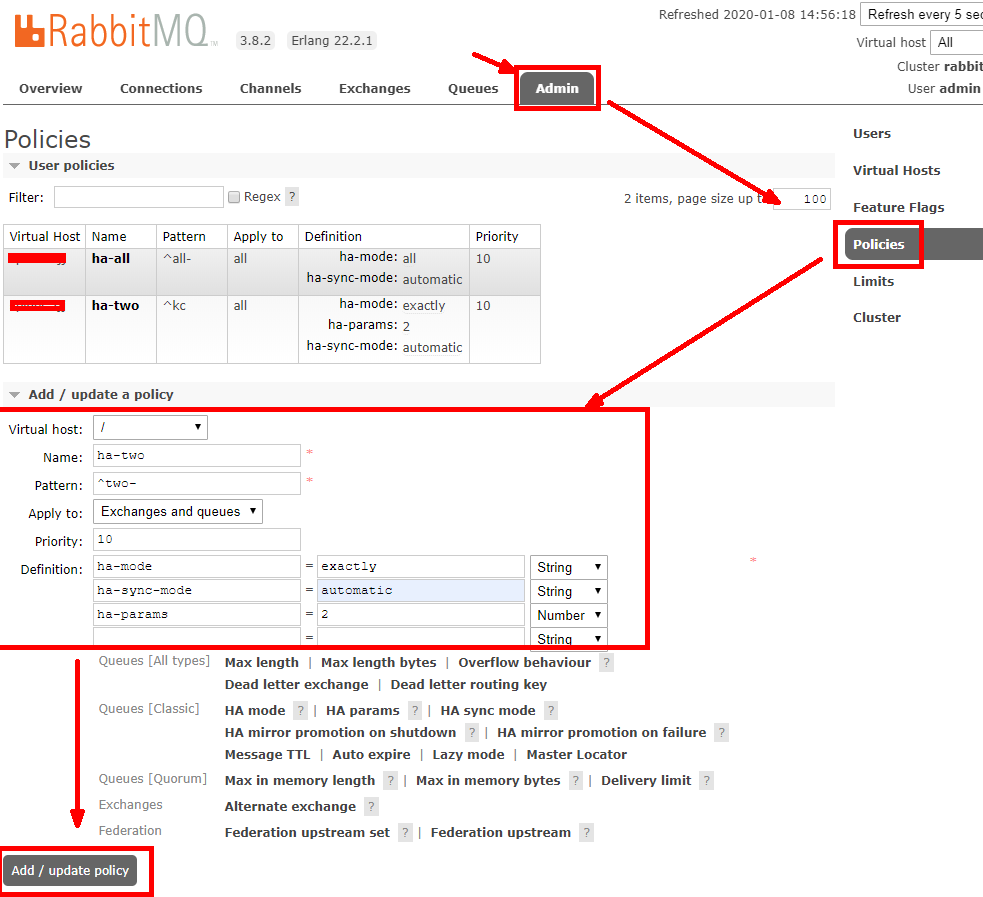
参数说明
Pattern 模式:"^" 为全部;"^all-" 为所有 all - 开头
Priority 优先级:建议 10,比较耗费资源
Definition 定义参数:
ha-mode=all 或 exactly;
ha-sync-mode=automatic;
ha-params=2(ha-mode=exactly);

Docker 下 RabbitMQ 四部曲之二:细说 RabbitMQ 镜像制作
本章是《Docker 下 RabbitMQ 四部曲》系列的第二篇,将详细简述 Docker 下制作 RabbitMQ 镜像的技术细节,包括以下内容:
- 列举制作 RabbitMQ 镜像时用到的所有材料;
- 编写 Dockerfile;
- 编写容器启动时执行的脚本 startrabbit.sh;
- 单机版 RabbtiMQ 环境的 docker-compose.yml 说明;
- 集群版 RabbitMQ 环境的 docker-compose.yml 说明;
原文地址:https://blog.csdn.net/boling_cavalry/article/details/80297358
文件和源码下载
您可以在 GitHub 下载本文涉及到的文件和源码,地址和链接信息如下表所示:
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在 GitHub 上的主页 |
| git 仓库地址 (https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https 协议 |
| git 仓库地址 (ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh 协议 |
这个 git 项目中有多个文件夹,本章所需的内容在 rabbitmq_docker_files 文件夹,如下图红框所示:
接下来开始镜像制作吧;
RabbitMQ 镜像要做的事情
先整理出我们需要一个什么样的镜像:
- 基础镜像为 centos:7;
- 时区:Asia/Shanghai;
- 编码:zh_CN.UTF-8;
- 装好了 Erlang;
- 装好了 RabbitMQ;
- 集群时候各个 RabbitMQ 机器之间的访问权限是通过 erlang.cookie 来控制的,所以在镜像中提前准备好 erlang.cookie,这样使用该镜像的所有容器由于 erlang.cookie 相同,就有了相互访问的权限;
- 创建容器时,可以通过参数来控制容器身份,例如集群版的主或者从,如果是身份是从,还要让从知道主的地址;
- 创建容器时,可以通过参数设置 RabbitMQ,例如用户名和密码、是否是内存节点、是否是高可用的镜像队列;
以上就是 RabbitMQ 镜像所具备的功能,其中 1-6 都可以在 Dockerfile 中实现,7 和 8 是在容器启动后要做的事情,所以要做个 shell 脚本来完成,容器创建时自动执行这个脚本;
准备镜像制作材料
根据前面列出的功能点,我们需要准备下面以下材料来制作镜像:
- Dockerfile:制作 Docker 镜像必须的脚本文件
- erlang.cookie:允许多个 RabbitMQ 容器相互访问的权限文件
- rabbitmq.config:RabbitMQ 配置文件
- startrabbit.sh:容器创建时执行的脚本
这些材料在 github 上都能获取到,地址:https://github.com/zq2599/blog_demos/tree/master/rabbitmq_docker_files/image
erlang.cookie 和 rabbitmq.config 很简单不需多说,我们细看 Dockerfile 和 startrabbit.sh;
Dockerfile
Dockerfile 是制作镜像时执行的脚本,内容如下:
# Docker file for rabbitmq single or cluster from bolingcavalry
# VERSION 0.0.3
# Author: bolingcavalry
#基础镜像
FROM centos:7
#作者
MAINTAINER BolingCavalry <zq2599@gmail.com>
#定义时区参数
ENV TZ=Asia/Shanghai
#设置时区
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo ''$TZ'' > /etc/timezone
#设置编码为中文
RUN yum -y install kde-l10n-Chinese glibc-common
RUN localedef -c -f UTF-8 -i zh_CN zh_CN.utf8
ENV LC_ALL zh_CN.utf8
#安装wget工具
RUN yum install -y wget unzip tar
#安装erlang
RUN rpm -Uvh https://github.com/rabbitmq/erlang-rpm/releases/download/v19.3.6.5/erlang-19.3.6.5-1.el7.centos.x86_64.rpm
RUN yum install -y erlang
#安装rabbitmq
RUN rpm --import http://www.rabbitmq.com/rabbitmq-signing-key-public.asc
RUN yum install -y https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.7.5-rc.1/rabbitmq-server-3.7.5.rc.1-1.el7.noarch.rpm
RUN /usr/sbin/rabbitmq-plugins list <<<''y''
#安装常用插件
RUN /usr/sbin/rabbitmq-plugins enable --offline rabbitmq_mqtt rabbitmq_stomp rabbitmq_management rabbitmq_management_agent rabbitmq_federation rabbitmq_federation_management <<<''y''
#添加配置文件
ADD rabbitmq.config /etc/rabbitmq/
#添加cookie,使集群环境中的机器保持互通
ADD erlang.cookie /var/lib/rabbitmq/.erlang.cookie
#添加启动容器时执行的脚本,主要根据启动时的入参做集群设置
ADD startrabbit.sh /opt/rabbit/
#给相关资源赋予权限
RUN chmod u+rw /etc/rabbitmq/rabbitmq.config \
&& chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie \
&& chmod 400 /var/lib/rabbitmq/.erlang.cookie \
&& mkdir -p /opt/rabbit \
&& chmod a+x /opt/rabbit/startrabbit.sh
#暴露常用端口
EXPOSE 5672
EXPOSE 15672
EXPOSE 25672
EXPOSE 4369
EXPOSE 9100
EXPOSE 9101
EXPOSE 9102
EXPOSE 9103
EXPOSE 9104
EXPOSE 9105
#设置容器创建时执行的脚本
CMD /opt/rabbit/startrabbit.sh
如上所示,每个功能都有对应的注释,就不再赘述了;
容器启动后执行的脚本 startrabbit.sh
startrabbit.sh 内容如下:
#!/bin/bash
change_default_user() {
if [ -z $RABBITMQ_DEFAULT_USER ] && [ -z $RABBITMQ_DEFAULT_PASS ]; then
echo "Maintaining default ''guest'' user"
else
echo "Removing ''guest'' user and adding ${RABBITMQ_DEFAULT_USER}"
rabbitmqctl delete_user guest
rabbitmqctl add_user $RABBITMQ_DEFAULT_USER $RABBITMQ_DEFAULT_PASS
rabbitmqctl set_user_tags $RABBITMQ_DEFAULT_USER administrator
rabbitmqctl set_permissions -p / $RABBITMQ_DEFAULT_USER ".*" ".*" ".*"
fi
}
HOSTNAME=`env hostname`
if [ -z "$CLUSTERED" ]; then
# if not clustered then start it normally as if it is a single server
/usr/sbin/rabbitmq-server &
rabbitmqctl wait /var/lib/rabbitmq/mnesia/rabbit\@$HOSTNAME.pid
change_default_user
tail -f /var/log/rabbitmq/rabbit\@$HOSTNAME.log
else
if [ -z "$CLUSTER_WITH" ]; then
# If clustered, but cluster with is not specified then again start normally, could be the first server in the
# cluster
/usr/sbin/rabbitmq-server&
rabbitmqctl wait /var/lib/rabbitmq/mnesia/rabbit\@$HOSTNAME.pid
tail -f /var/log/rabbitmq/rabbit\@$HOSTNAME.log
else
/usr/sbin/rabbitmq-server &
rabbitmqctl wait /var/lib/rabbitmq/mnesia/rabbit\@$HOSTNAME.pid
rabbitmqctl stop_app
if [ -z "$RAM_NODE" ]; then
rabbitmqctl join_cluster rabbit@$CLUSTER_WITH
else
rabbitmqctl join_cluster --ram rabbit@$CLUSTER_WITH
fi
rabbitmqctl start_app
# If set ha flag, enable here
if [ -z "$HA_ENABLE" ]; then
echo "Running with normal cluster mode"
else
rabbitmqctl set_policy HA ''^(?!amq\.).*'' ''{"ha-mode": "all"}''
echo "Running wiht HA cluster mode"
fi
# Tail to keep the a foreground process active..
tail -f /var/log/rabbitmq/rabbit\@$HOSTNAME.log
fi
fi
这个脚本有以下几点需要注意:
- if [ -z “$CLUSTERED” ] 表示如果环境变量中没有 CLUSTERED 这个参数;
- 如果环境变量中没有 CLUSTERED 这个参数,当前容器的身份就是主,会调用 change_default_user 方法,这个方法中检查是否输入了用户名和密码,如果有就创建用户,并赋予管理员权限,再把原有的 guest 账号删除;
- 如果环境变量中有 CLUSTERED 这个参数,当前容器身份就是从,会执行 rabbitmqctl join_cluster 命令加入到集群中去;
- 如果环境变量中有 RAM_NODE 这个参数,会在 rabbitmqctl join_cluster 命令中带上 ram 参数,表示当前节点为内存节点;
- 如果环境变量中有 HA_ENABLE 这个参数,就在启动 RabbitMQ 之后执行命令 rabbitmqctl set_policy,将集群中的队列变为镜像队列,实现集群高可用;
构建镜像
以上就是制作镜像前的准备工作,完成之后在 Dockerfile 文件所在目录下执行命令 docker build -t bolingcavalry/rabbitmq-server:0.0.3 .,即可构建镜像;
单机版的 docker-compose.yml
这个 docker-compose.yml 在上一章我们用过,内容如下:
rabbitmq:
image: bolingcavalry/rabbitmq-server:0.0.3
hostname: rabbitmq
ports:
- "15672:15672"
environment:
- RABBITMQ_DEFAULT_USER=admin
- RABBITMQ_DEFAULT_PASS=888888
producer:
image: bolingcavalry/rabbitmqproducer:0.0.2-SNAPSHOT
hostname: producer
links:
- rabbitmq:rabbitmqhost
ports:
- "18080:8080"
environment:
- mq.rabbit.address=rabbitmqhost:5672
- mq.rabbit.username=admin
- mq.rabbit.password=888888
consumer:
image: bolingcavalry/rabbitmqconsumer:0.0.3-SNAPSHOT
hostname: consumer
links:
- rabbitmq:rabbitmqhost
environment:
- mq.rabbit.address=rabbitmqhost:5672
- mq.rabbit.username=admin
- mq.rabbit.password=888888
- mq.rabbit.queue.name=consumer.queue
producer 和 consumer 的配置我们下一章再看,现在重点关注 rabbitmq 的配置:
- 没有 CLUSTERED 参数,表示该容器以主的身份运行;
- RABBITMQ_DEFAULT_USER、RABBITMQ_DEFAULT_PASS 这两个参数设定了此 RabbitMQ 的管理员权限的账号和密码;
集群版的 docker-compose.yml
内容如下:
version: ''2''
services:
rabbit1:
image: bolingcavalry/rabbitmq-server:0.0.3
hostname: rabbit1
ports:
- "15672:15672"
environment:
- RABBITMQ_DEFAULT_USER=admin
- RABBITMQ_DEFAULT_PASS=888888
rabbit2:
image: bolingcavalry/rabbitmq-server:0.0.3
hostname: rabbit2
depends_on:
- rabbit1
links:
- rabbit1
environment:
- CLUSTERED=true
- CLUSTER_WITH=rabbit1
- RAM_NODE=true
ports:
- "15673:15672"
rabbit3:
image: bolingcavalry/rabbitmq-server:0.0.3
hostname: rabbit3
depends_on:
- rabbit2
links:
- rabbit1
- rabbit2
environment:
- CLUSTERED=true
- CLUSTER_WITH=rabbit1
ports:
- "15675:15672"
producer:
image: bolingcavalry/rabbitmqproducer:0.0.2-SNAPSHOT
hostname: producer
depends_on:
- rabbit3
links:
- rabbit1:rabbitmqhost
ports:
- "18080:8080"
environment:
- mq.rabbit.address=rabbitmqhost:5672
- mq.rabbit.username=admin
- mq.rabbit.password=888888
consumer1:
image: bolingcavalry/rabbitmqconsumer:0.0.3-SNAPSHOT
hostname: consumer1
depends_on:
- producer
links:
- rabbit2:rabbitmqhost
environment:
- mq.rabbit.address=rabbitmqhost:5672
- mq.rabbit.username=admin
- mq.rabbit.password=888888
- mq.rabbit.queue.name=consumer1.queue
consumer2:
image: bolingcavalry/rabbitmqconsumer:0.0.3-SNAPSHOT
hostname: consumer2
depends_on:
- consumer1
links:
- rabbit3:rabbitmqhost
environment:
- mq.rabbit.address=rabbitmqhost:5672
- mq.rabbit.username=admin
- mq.rabbit.password=888888
- mq.rabbit.queue.name=consumer2.queue
这个脚本有以下几点需要注意:
- rabbit1 是主节点;
- rabbit2 和 rabbit3 由于设置了 CLUSTERED,身份成为从节点,在 startrabbit.sh 脚本中,会通过 rabbitmqctl join_cluster 命令加入到主节点的集群中去,加入时如何找到主节点呢?用的是 CLUSTER_WITH 参数,而 CLUSTER_WITH 参数的值,在 docker-compose.yml 中通过 link 参数设置为 rabbit1;
- rabbit2 设置了 RAM_NODE,所以是个内存节点;
至此,整个 RabbitMQ 镜像制作和使用的详细分析就结束了,您也可以自行实战,在 Dockerfile 和 startrabbit.sh 中增加一些命令来对 RabbitMQ 做更多个性化的设置,下一章,我们开发两个基于 SpringBoot 的工程,分别用来生产和消费消息;
参考并致敬:https://github.com/bijukunjummen/docker-rabbitmq-cluster
欢迎关注我的公众号:程序员欣宸

本文分享 CSDN - 程序员欣宸。
如有侵权,请联系 support@oschina.cn 删除。
本文参与 “OSC 源创计划”,欢迎正在阅读的你也加入,一起分享。
关于rabbitmq-web-stomp 优化过程和rabbitmq优化配置的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于1、RabbitMQ 入门秘籍,三分钟带你快速了解 RabbitMQ、CentOS 6 RabbitMQ 服务器搭建 PHP 客户端 C 扩展 AMQP 安装 rabbitmq-c 安装 PHP 多版本编译安装 C 扩展、CentOS-Docker 安装 RabbitMQ 集群 (rabbitmq:3.7.16-management)、Docker 下 RabbitMQ 四部曲之二:细说 RabbitMQ 镜像制作等相关内容,可以在本站寻找。
本文标签:




