如果您想了解为JDBCElasticsearchRiver设置映射和jdbctemplate映射的知识,那么本篇文章将是您的不二之选。我们将深入剖析为JDBCElasticsearchRiver设置映
如果您想了解为JDBC Elasticsearch River设置映射和jdbctemplate映射的知识,那么本篇文章将是您的不二之选。我们将深入剖析为JDBC Elasticsearch River设置映射的各个方面,并为您解答jdbctemplate映射的疑在这篇文章中,我们将为您介绍为JDBC Elasticsearch River设置映射的相关知识,同时也会详细的解释jdbctemplate映射的运用方法,并给出实际的案例分析,希望能帮助到您!
本文目录一览:- 为JDBC Elasticsearch River设置映射(jdbctemplate映射)
- docker 部署 elasticsearch + elasticsearch-head + elasticsearch-head 跨域问题 + IK 分词器
- ElasticSearch (一) ElasticSearch 的应用场景及为什么要选择 ElasticSearch?
- elasticsearch 2.2.0支持的Elastic river-mongodb插件的替代方案是什么?
- Elasticsearch 2.3.3 搜索引擎的elasticsearch-jdbc插件安装
")
为JDBC Elasticsearch River设置映射(jdbctemplate映射)
我正在将ES 0.20.6与elasticsearch -river-
jdbc插件一起使用。我使用以下方法创建了一条河:
SQL="SELECT ..."curl -XPUT ''localhost:9200/_river/myindex_river/_meta'' -d ''{ "type" : "jdbc", "jdbc" : { "driver" : "org.postgresql.Driver", "url" : "jdbc:postgresql://localhost:5432/mydb_db", "user" : "myuser", "password" : "mypassword", "sql" : "''"$SQL"''" }, "index" : { "index" : "myindex", "type" : "mytype", "type_mapping" : null }}''现在,我要添加的类型映射为插件文档中定义的选项。但我真的无法弄清楚语法,总是会收到以下错误("Source:"部分内容因我的尝试而异)
org.elasticsearch.index.mapper.MapperParsingException: Failed to parse mapping definition at org.elasticsearch.index.mapper.DocumentMapperParser.extractMapping(DocumentMapperParser.java:237) at org.elasticsearch.index.mapper.DocumentMapperParser.parse(DocumentMapperParser.java:147) at org.elasticsearch.index.mapper.MapperService.parse(MapperService.java:379) at org.elasticsearch.index.mapper.MapperService.parse(MapperService.java:375) at org.elasticsearch.cluster.metadata.MetaDataMappingService$4.execute(MetaDataMappingService.java:309) at org.elasticsearch.cluster.service.InternalClusterService$2.run(InternalClusterService.java:223) at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908) at java.lang.Thread.run(Thread.java:662)Caused by: org.elasticsearch.common.jackson.core.JsonParseException: Unexpected character (''='' (code 61)): was expecting a colon to separate field name and value at [Source: {mytype={properties={active={index_analyzer=standard, store=yes, type=boolean}}}}; line: 1, column: 9] at org.elasticsearch.common.jackson.core.JsonParser._constructError(JsonParser.java:1378) at org.elasticsearch.common.jackson.core.base.ParserMinimalBase._reportError(ParserMinimalBase.java:599) at org.elasticsearch.common.jackson.core.base.ParserMinimalBase._reportUnexpectedChar(ParserMinimalBase.java:520) at org.elasticsearch.common.jackson.core.json.ReaderBasedJsonParser.nextToken(ReaderBasedJsonParser.java:616) at org.elasticsearch.common.xcontent.json.JsonXContentParser.nextToken(JsonXContentParser.java:48) at org.elasticsearch.common.xcontent.support.XContentMapConverter.readMap(XContentMapConverter.java:70) at org.elasticsearch.common.xcontent.support.XContentMapConverter.readOrderedMap(XContentMapConverter.java:60) at org.elasticsearch.common.xcontent.support.AbstractXContentParser.mapOrdered(AbstractXContentParser.java:116) at org.elasticsearch.index.mapper.DocumentMapperParser.extractMapping(DocumentMapperParser.java:235) ... 8 more答案1
小编典典我认为您提交的东西甚至都不是正确的json对象。我可以想象到type_mapping对象必须包含映射,与使用put映射api或创建索引所提交的映射几乎相同。

docker 部署 elasticsearch + elasticsearch-head + elasticsearch-head 跨域问题 + IK 分词器
0. docker pull 拉取 elasticsearch + elasticsearch-head 镜像
1. 启动 elasticsearch Docker 镜像
docker run -di --name tensquare_elasticsearch -p 9200:9200 -p 9300:9300 elasticsearch![]()
对应 IP:9200 ---- 反馈下边 json 数据,表示启动成功

2. 启动 elasticsearch-head 镜像
docker run -d -p 9100:9100 elasticsearch-head![]()
对应 IP:9100 ---- 得到下边页面,即启动成功
3. 解决跨域问题
进入 elasticsearch-head 页面,出现灰色未连接状态 , 即出现跨域问题

1. 根据 docker ps 得到 elasticsearch 的 CONTAINER ID
2. docker exec -it elasticsearch 的 CONTAINER ID /bin/bash 进入容器内
3. cd ./config
4. 修改 elasticsearch.yml 文件
echo "
http.cors.enabled: true
http.cors.allow-origin: ''*''" >> elasticsearch.yml
4. 重启 elasticsearch
docker restart elasticsearch的CONTAINER ID重新进入 IP:9100 进入 elasticsearch-head, 出现绿色标注,配置成功 !

5. ik 分词器的安装
将在 ik 所在的文件夹下,拷贝到 /usr/share/elasticsearch/plugins --- 注意: elasticsearch 的版本号必须与 ik 分词器的版本号一致
docker cp ik elasticsearch的CONTAINER ID:/usr/share/elasticsearch/plugins
重启elasticsearch
docker restart elasticsearch
未添加ik分词器:http://IP:9200/_analyze?analyzer=chinese&pretty=true&text=我爱中国
添加ik分词器后:http://IP:9200/_analyze?analyzer=ik_smart&pretty=true&text=我爱中国 ElasticSearch 的应用场景及为什么要选择 ElasticSearch?")
ElasticSearch (一) ElasticSearch 的应用场景及为什么要选择 ElasticSearch?
先了解一下数据的分类
结构化数据
又可以称之为行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据。其实就是可以能够用数据或者统一的结构加以表示的数据。比如在数据表存储商品的库存,可以用整型表示,存储价格可以用浮点型表示,再比如给用户存储性别,可以用枚举表示,这都是结构化数据。
非结构化数据
无法用数字或者统一的结构表示的数据,称之为飞结构化数据。如:文本、图像、声音、网页。
其实结构化数据又数据非结构化数据。商品标题、描述、文章描述都是文本,其实文本就是非结构化数据。那么就可以说非结构化数据即为全文数据。
什么是全文检索?
一种将文件或者数据库中所有文本与检索项相匹配的文字资料检索方法,称之为全文检索。
全文检索的两种方法
顺序扫描法:将数据表的所有数据逐个扫描,再对文字描述扫描,符合条件的筛选出来,非常慢!
索引扫描法:全文检索的基本思路,也就是将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对快的目的。
全文检索的过程:
先索引的创建,然后索引搜索
为什么要选择用 ElasticSearch?
全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选。
Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。
分布式的实时文件存储,每个字段都被索引可被搜索。
分布式的实时分析搜索引擎。
可以扩展到上百台服务器,处理 PB 级别结构化或者非结构化数据。
所有功能集成在一个服务器里,可以通过 RESTful API、各种语言的客户端甚至命令与之交互。
上手容易,提供了很多合理的缺省值,开箱即用,学习成本低。
可以免费下载、使用和修改。
配置灵活,比 Sphinx 灵活的多。

elasticsearch 2.2.0支持的Elastic river-mongodb插件的替代方案是什么?
在升级elasticsearch时,需要替换river-mongodb插件。由于mongodb河已经过时,因此需要您的帮助来找出替代方案。我们需要索引整个mongodb集合。

Elasticsearch 2.3.3 搜索引擎的elasticsearch-jdbc插件安装
Elasticsearch 2.3.3的jdbc插件安装跟之前的版本是不一样的,之前的版本,网上的内容介绍的都是elasticsearch使用river同步mysql数据 ,哪些都是老的文章了,最新的版本是不适用的。那么我们如何从数据库导入数据呢?其实安装 Elasticsearch 2.3.3 的JDBC插件很简单,只不过,安装完以后的配置,稍微有些麻烦。
第一步:下载JDBC链接包
具体可以执行下面的命令:
wget http://xbib.org/repository/org/xbib/elasticsearch/importer/elasticsearch-jdbc/2.3.3.0/elasticsearch-jdbc-2.3.3.0-dist.zip
第二步: 解压 elasticsearch-jdbc-2.3.3.0-dist.zip
unzip elasticsearch-jdbc-2.3.3.0-dist.zip
第三步:进入elasticsearch-jdbc-2.3.3.0/bin目录
我们看到下面有很多链接数据库的样例文件。
我们以MSYQL为例,做一个基本的介绍。
第四步:编辑mysql-blog.sh,修改成如下的样子。
#!/bin/sh
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
bin=${DIR}/../bin
lib=${DIR}/../lib
echo ''
{
"type" : "jdbc",
"jdbc" : {
"url" : "jdbc:mysql://192.168.1.100:3306/hotel?useUnicode=true&characterEncoding=gbk",
"statefile" : "statefile.json",
"user" : "root",
"password" : "root",
"sql" : "select * from hotel",
"index" : "hotel",
"type" : "hotel",
"elasticsearch" : {
"cluster" : "elasticsearch",
"host" : "192.168.133.134",
"port" : 9300
}
}
}
'' | java \
-cp "${lib}/*" \
-Dlog4j.configurationFile=${bin}/log4j2.xml \
org.xbib.tools.Runner \
org.xbib.tools.JDBCImporter
上述脚本的意思是:链接192.168.1.100这个机器上的hotel数据库,将此数据库中的hotel数据全部导入到hotel索引中。导入的集群名称是elasticsearch,搜索引擎访问地址是192.168.133.132.
第五步,结合之前的内容,我们搭建了 elasticsearch 集群,但是没有建立索引。
我们可以再head插件中新建索引.
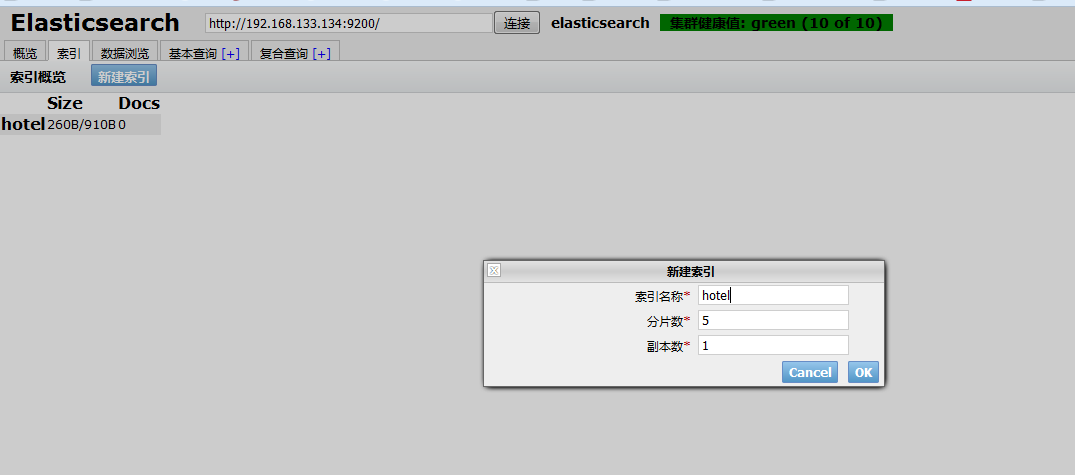
索引创建成功后,我们可以在 “概览”里面看到新建的索引。

暂且不表分片和复制。我们看到我们成功了创建了一个hotel索引,目前索引中文档个数为0.
第六步,执行刚才修改的mysql-blog.sh脚本。
执行之前确定你的Mysql数据库已经启动,并且数据库的链接账号和密码存在。
我的数据库中是5W条酒店的数据。

脚本执行完成后,5W条数据从导入到索引创建完成,大约是2分钟,速度还是蛮快的。,我们再次查看head插件,可以看到,文件个数已经发生了变化。

好了,本篇文章就写到这里,其实ElasticSerach-jdbc导入数据还有很多的参数。
大家可以看https://github.com/jprante/elasticsearch-jdbc 文章,或者点击链接观看 数航教育的在线视频教程
今天关于为JDBC Elasticsearch River设置映射和jdbctemplate映射的分享就到这里,希望大家有所收获,若想了解更多关于docker 部署 elasticsearch + elasticsearch-head + elasticsearch-head 跨域问题 + IK 分词器、ElasticSearch (一) ElasticSearch 的应用场景及为什么要选择 ElasticSearch?、elasticsearch 2.2.0支持的Elastic river-mongodb插件的替代方案是什么?、Elasticsearch 2.3.3 搜索引擎的elasticsearch-jdbc插件安装等相关知识,可以在本站进行查询。
本文标签:




