对于想了解在HADOOP映射中使用泛型可减少问题的读者,本文将提供新的信息,我们将详细介绍在hadoop映射中使用泛型可减少问题的方法,并且为您提供关于C#–IDataReader到使用泛型的对象映射
对于想了解在HADOOP映射中使用泛型可减少问题的读者,本文将提供新的信息,我们将详细介绍在hadoop映射中使用泛型可减少问题的方法,并且为您提供关于C# – IDataReader到使用泛型的对象映射、Hadoop (1)--- 运行 Hadoop 自带的 wordcount 出错问题。、hadoop 中利用gis-tools-for-hadoop 处理空间数据一直有问题、hadoop-使用Windows的eclipse开发Hadoop的有价值信息。
本文目录一览:- 在HADOOP映射中使用泛型可减少问题(在hadoop映射中使用泛型可减少问题的方法)
- C# – IDataReader到使用泛型的对象映射
- Hadoop (1)--- 运行 Hadoop 自带的 wordcount 出错问题。
- hadoop 中利用gis-tools-for-hadoop 处理空间数据一直有问题
- hadoop-使用Windows的eclipse开发Hadoop
")
在HADOOP映射中使用泛型可减少问题(在hadoop映射中使用泛型可减少问题的方法)
我的问题对于HADOOP用户而言似乎很愚蠢。但是我对在地图减少问题中使用泛型感到困惑,例如“ WORD COUNT”。
我知道,泛型被基本用于类型转换和类型安全。但是我不能在这里将这个概念联系起来。
在字数问题上,
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub ... } }}请任何人在这里让我明白泛型的使用 。如果我在问这个问题时犯了任何错误,请纠正我。
现在,我了解将泛型用于键值对(KEY IN,VALUE IN,KEY OUT,VALUE
OUT)。但是我仍然不清楚,为什么在这里将泛型用于键值对。没有其他方法可以做同样的事情。 在这里使用泛型有什么好处?
谢谢!
答案1
小编典典MapReduce在Mapper和Reducer中专门使用泛型来指定期望读入和写出哪种输入和输出。
在这个例子中你指定你的WordCountMapper扩展Mapper与指定的泛型类Mapper<LongWritable, Text, Text,LongWritable>,其中前两类LongWritable,并Text表示 输入键和值
映射器类期待阅读,而最后两节课Text,并LongWritable表示 输出键和值 类的map方法有望散发出来。
通过该线程讨论,可以更深入地了解为什么在MapReduce中实现了泛型。另外,此JIRA问题提供了更多信息。

C# – IDataReader到使用泛型的对象映射
例如我需要执行以下操作:
public class Mapper<T>
{
public static List<T> MapObject(IDataReader dr)
{
List<T> objects = new List<T>();
while (dr.Read())
{
//Mapping goes here...
}
return objects;
}
}
后来我需要调用这个类方法,如下所示:
IDataReder dataReader = DBUtil.Fetchdata("SELECT * FROM Book");
List<Book> bookList = Mapper<Book>.MapObject(dataReder);
foreach (Book b in bookList)
{
Console.WriteLine(b.ID + "," + b.BookName);
}
请注意,Mapper类应该能够映射由T表示的任何类型的对象.
解决方法
我这样做:
while (dr.Read())
{
var o = new User();
o.InjectFrom<DataReaderInjection>(dr);
yield return o;
}
你会需要这个ValueInjection来工作:
public class DataReaderInjection : KNownSourceValueInjection<IDataReader>
{
protected override void Inject(IDataReader source,object target,PropertyDescriptorCollection targetProps)
{
for (var i = 0; i < source.FieldCount; i++)
{
var activeTarget = targetProps.GetByName(source.GetName(i),true);
if (activeTarget == null) continue;
var value = source.GetValue(i);
if (value == dbnull.Value) continue;
activeTarget.SetValue(target,value);
}
}
}
--- 运行 Hadoop 自带的 wordcount 出错问题。")
Hadoop (1)--- 运行 Hadoop 自带的 wordcount 出错问题。
在 hadoop2.9.0 版本中,对 namenode、yarn 做了 ha,随后在某一台 namenode 节点上运行自带的 wordcount 程序出现偶发性的错误(有时成功,有时失败),错误信息如下:
18/08/16 17:02:42 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
18/08/16 17:02:42 INFO input.FileInputFormat: Total input files to process : 1
18/08/16 17:02:42 INFO mapreduce.JobSubmitter: number of splits:1
18/08/16 17:02:42 INFO Configuration.deprecation: yarn.resourcemanager.zk-address is deprecated. Instead, use hadoop.zk.address
18/08/16 17:02:42 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
18/08/16 17:02:42 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1534406793739_0005
18/08/16 17:02:42 INFO impl.YarnClientImpl: Submitted application application_1534406793739_0005
18/08/16 17:02:43 INFO mapreduce.Job: The url to track the job: http://HLJRslog2:8088/proxy/application_1534406793739_0005/
18/08/16 17:02:43 INFO mapreduce.Job: Running job: job_1534406793739_0005
18/08/16 17:02:54 INFO mapreduce.Job: Job job_1534406793739_0005 running in uber mode : false
18/08/16 17:02:54 INFO mapreduce.Job: map 0% reduce 0%
18/08/16 17:02:54 INFO mapreduce.Job: Job job_1534406793739_0005 failed with state FAILED due to: Application application_1534406793739_0005 failed 2 times due to AM Container for appattempt_1534406793739_0005_000002 exited with exitCode: 1
Failing this attempt.Diagnostics: [2018-08-16 17:02:48.561]Exception from container-launch.
Container id: container_e27_1534406793739_0005_02_000001
Exit code: 1
[2018-08-16 17:02:48.562]
[2018-08-16 17:02:48.574]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
log4j:WARN No appenders could be found for logger (org.apache.hadoop.mapreduce.v2.app.MRAppMaster).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
[2018-08-16 17:02:48.575]
[2018-08-16 17:02:48.575]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
log4j:WARN No appenders could be found for logger (org.apache.hadoop.mapreduce.v2.app.MRAppMaster).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.分析与解决:
网上对类似问题解决办法,主要就是添加对应的 classpath,测试了一遍,都不好使,说明上诉问题并不是 classpath 造成的,出错的时候也查看了 classpath,都有对应的值,这里贴一下添加 classpath 的方法。
1、# yarn classpath 注:查看对应的 classpath 的值
/data1/hadoop/hadoop/etc/hadoop:/data1/hadoop/hadoop/etc/hadoop:/data1/hadoop/hadoop/etc/hadoop:/data1/hadoop/hadoop/share/hadoop/common/lib/*:/data1/hadoop/hadoop/share/hadoop/common/*:/data1/hadoop/hadoop/share/hadoop/hdfs:/data1/hadoop/hadoop/share/hadoop/hdfs/lib/*:/data1/hadoop/hadoop/share/hadoop/hdfs/*:/data1/hadoop/hadoop/share/hadoop/yarn:/data1/hadoop/hadoop/share/hadoop/yarn/lib/*:/data1/hadoop/hadoop/share/hadoop/yarn/*:/data1/hadoop/hadoop/share/hadoop/mapreduce/lib/*:/data1/hadoop/hadoop/share/hadoop/mapreduce/*:/data1/hadoop/hadoop/contrib/capacity-scheduler/*.jar:/data1/hadoop/hadoop/share/hadoop/yarn/*:/data1/hadoop/hadoop/share/hadoop/yarn/lib/*如果是上述类变量为空,可以通过下面三个步骤添加 classpath。
2. 修改 mapred.site.xml
添加:
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
3.yarn.site.xml
添加:
<property>
<name>yarn.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
4. 修改环境变量
#vim ~/.bashrc
在文件最后添加下述环境变量:
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native5. source ~/.bashrc
解决报错问题:
从日志可以看出,发现是由于跑 AM 的 container 退出了,并没有为任务去 RM 获取资源,怀疑是 AM 和 RM 通信有问题;一台是备 RM, 一台活动的 RM,在 yarn 内部,当 MR 去活动的 RM 为任务获取资源的时候当然没问题,但是去备 RM 获取时就会出现这个问题了。
修改 vim yarn-site.xml
<property>
<!-- 客户端通过该地址向RM提交对应用程序操作 -->
<name>yarn.resourcemanager.address.rm1</name>
<value>master:8032</value>
</property>
<property>
<!--ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等。 -->
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>master:8030</value>
</property>
<property>
<!-- RM HTTP访问地址,查看集群信息-->
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master:8088</value>
</property>
<property>
<!-- NodeManager通过该地址交换信息 -->
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>master:8031</value>
</property>
<property>
<!--管理员通过该地址向RM发送管理命令 -->
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>master:23142</value>
</property>
<!--
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>slave1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>slave1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>slave1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>slave1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>slave1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>slave1:23142</value>
</property>
-->注:标红的地方就是 AM 向 RM 申请资源的 rpc 端口,出错问题就在这里。
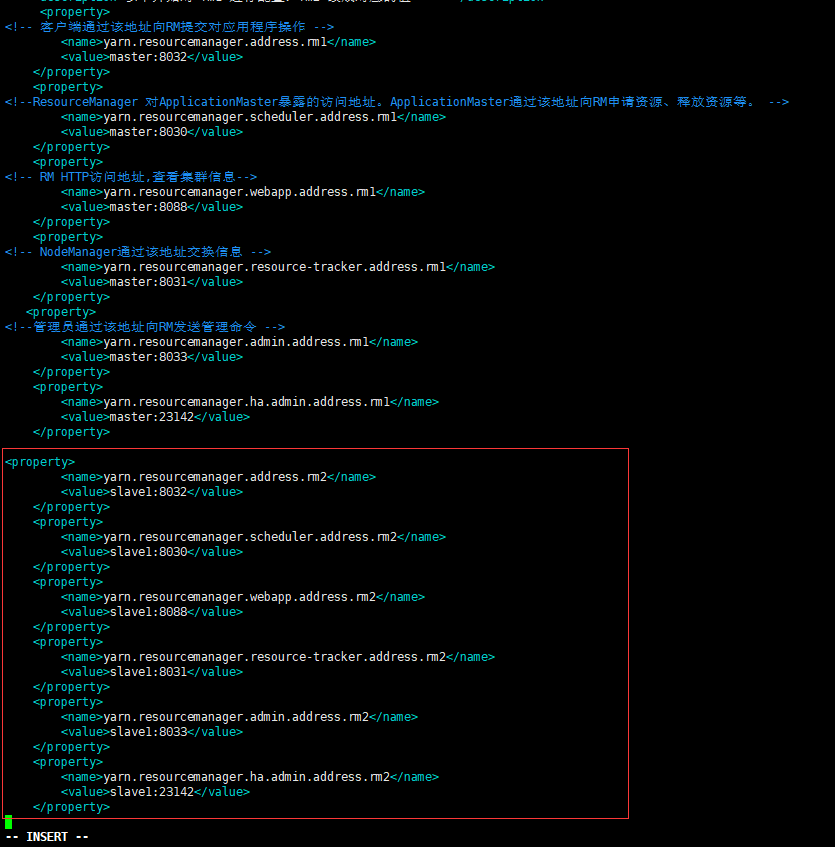
红框里面是我在 rm1 机器(也就是 master)上的 yarn 文件添加的;当然,如果是在 slave1 里面添加的话就是添加红框上面以.rm1 结尾的那几行,其实,说白点,就是要在 yarn-site.xml 这个配置文件里面添加所有 resourcemanager 机器的通信主机与端口。然后拷贝到其他机器,重新启动 yarn。最后在跑 wordcount 或者其他程序没在出错。其实这就是由于 MR 与 RM 通信的问题,所以在配置 yarn-site.xml 文件的时候,最好把主备的通信端口都配置到改文件,防止出错。

hadoop 中利用gis-tools-for-hadoop 处理空间数据一直有问题
在Hadoop集群中运行esri 的一个gis-tools-for-hadoop 里面的一个示例。结果在MapReduce阶段一直报错
java.lang.RuntimeExption: Error in configuring object
& Error: java.lang.ClassNotFoundException: org.codehaus.jackson.ObjectCodec
ps:其他数据我在hive中可以处理,当处理空间 数据引入‘com.esri.hadoop.hive.serde.JsonSerde''等类似的空间Jar就会报错。

hadoop-使用Windows的eclipse开发Hadoop
1、复制hadoop-eclipse-plugin-1.2.1.jar包到eclipse的plugin文件夹,版本最好跟安装的hadoop版本一致
2、配置hadoop路径,Windows->preference
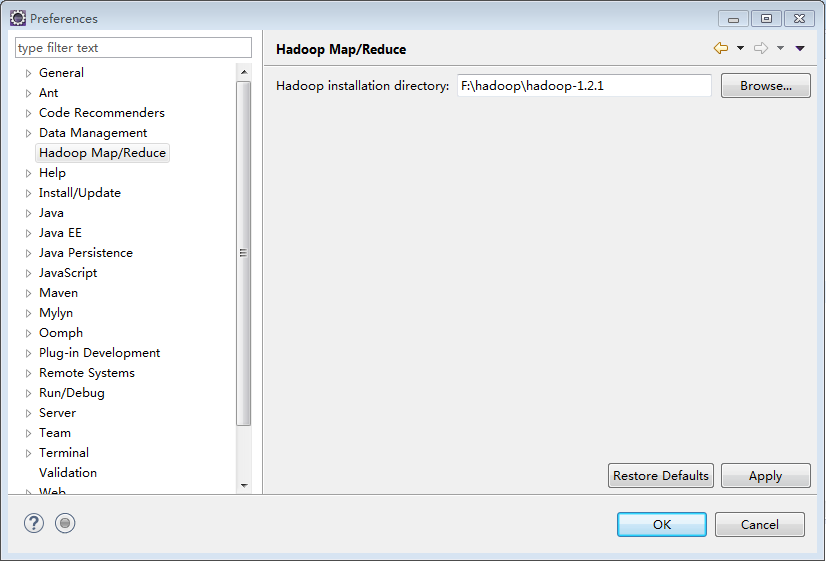
这里的hadoop文件夹是虚拟机上linux安装的压缩包解压出来的
3、配置hadoop location
按照linux上安装的hadoop配置core-size.xml hdfs-size.xml mapred-size.xml
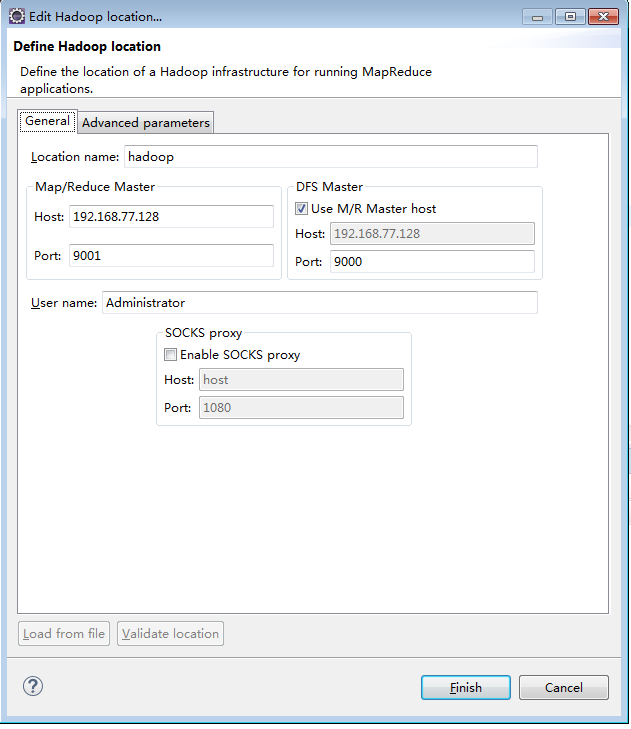
这里也要配置跟配置文件上的数据(具体哪几个忘记了,都配就行)
今天关于在HADOOP映射中使用泛型可减少问题和在hadoop映射中使用泛型可减少问题的方法的分享就到这里,希望大家有所收获,若想了解更多关于C# – IDataReader到使用泛型的对象映射、Hadoop (1)--- 运行 Hadoop 自带的 wordcount 出错问题。、hadoop 中利用gis-tools-for-hadoop 处理空间数据一直有问题、hadoop-使用Windows的eclipse开发Hadoop等相关知识,可以在本站进行查询。
本文标签:




