针对Hadoop2.6.0浏览文件系统Java和hadoop浏览器访问这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展008-004配置javaapihadoopfsclient操作,had
针对Hadoop 2.6.0浏览文件系统Java和hadoop浏览器访问这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展008-004 配置 java api hadoop fs client 操作,hadoop 客户端 文件命令的maven配置、Big Data(二)分布式文件系统那么多,为什么hadoop还需要一个hdfs文件系统?、Hadoop API操作文件系统方法有哪些、hadoop fs(HDFS文件系统命令)等相关知识,希望可以帮助到你。
本文目录一览:- Hadoop 2.6.0浏览文件系统Java(hadoop浏览器访问)
- 008-004 配置 java api hadoop fs client 操作,hadoop 客户端 文件命令的maven配置
- Big Data(二)分布式文件系统那么多,为什么hadoop还需要一个hdfs文件系统?
- Hadoop API操作文件系统方法有哪些
- hadoop fs(HDFS文件系统命令)
")
Hadoop 2.6.0浏览文件系统Java(hadoop浏览器访问)
我在CentOS
6.6上安装了一个基本的hadoop集群,并想编写一些基本程序(浏览文件系统,删除/添加文件等),但是我仍在努力使最基本的应用程序正常工作。
当运行一些基本代码以将目录的内容列出到控制台时,出现以下错误:
Exception in thread "main" java.lang.NoSuchMethodError: org.apache.hadoop.ipc.RPC.getProxy(Ljava/lang/Class;JLjava/net/InetSocketAddress;Lorg/apache/hadoop/security/UserGroupInformation;Lorg/apache/hadoop/conf/Configuration;Ljavax/net/SocketFactory;ILorg/apache/hadoop/io/retry/RetryPolicy;Z)Lorg/apache/hadoop/ipc/VersionedProtocol; at org.apache.hadoop.hdfs.DFSClient.createRPCNamenode(DFSClient.java:135) at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:280) at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:245) at org.apache.hadoop.hdfs.DistributedFileSystem.initialize(DistributedFileSystem.java:100) at mapreducetest.MapreduceTest.App.main(App.java:36)我的pom.xml依赖项
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-core</artifactId> <version>1.2.1</version> </dependency> </dependencies>代码:
import java.io.IOException;import java.net.URI;import java.net.URISyntaxException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileStatus;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.hdfs.DistributedFileSystem;public class App { public static void main( String[] args ) throws IOException, URISyntaxException { Configuration conf = new Configuration(); FileSystem fs = new DistributedFileSystem(); fs.initialize(new URI("hdfs://localhost:9000/"), conf); for (FileStatus f :fs.listStatus(new Path("/"))) { System.out.println(f.getPath().getName()); } fs.close(); }}调用fs.initialize()后将引发错误。我真的不确定这是什么问题。我是否缺少依赖关系?他们是错误的版本吗?
答案1
小编典典我通过调用“ java -jar app.jar .... etc”来运行它,我应该一直在使用“ hadoop jar app.jar”。
当我正确运行它时,按预期工作。

008-004 配置 java api hadoop fs client 操作,hadoop 客户端 文件命令的maven配置
<dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>RELEASE</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.8.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> <version>1.8</version> <scope>system</scope> <systemPath>C:/Program Files/Java/jdk1.8.0_162/lib/tools.jar</systemPath> </dependency> </dependencies>
分布式文件系统那么多,为什么hadoop还需要一个hdfs文件系统?")
Big Data(二)分布式文件系统那么多,为什么hadoop还需要一个hdfs文件系统?
提纲
- 存储模型
- 架构设计
- 角色功能
- 元数据持久化
- 安全模式
- 副本放置策略
- 读写流程
- 安全策略
存储模型
- 文件线性按字节切割成块(block),具有offset,id
- 文件与文件的block大小可以不一样
- 一个文件除最后一个block,其他block大小一致
- block的大小依据硬件的I/O特性调整
- block被分散存放在集群的节点中,具有location
- Block具有副本(replication),没有主从概念,副本不能出现在同一个节点
- 副本是满足可靠性和性能的关键
- 文件上传可以指定block大小和副本数,上传后只能修改副本数
- 一次写入多次读取,不支持修改
- 支持追加数据
架构设计
- HDFS是一个主从(Master/Slaves)架构
- 由一个NameNode和一些DataNode组成
- 面向文件包含:文件数据(data)和文件元数据(metadata)
- NameNode负责存储和管理文件元数据,并维护了一个层次型的文件目录树
- DataNode负责存储文件数据(block块),并提供block的读写
- DataNode与NameNode维持心跳,并汇报自己持有的block信息
- Client和NameNode交互文件元数据和DataNode交互文件block数据
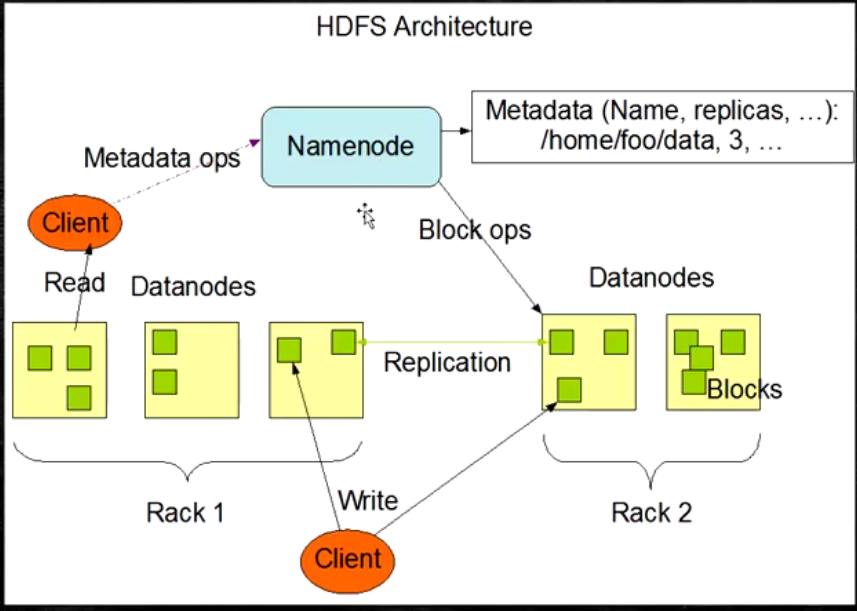
HDFS的架构图

角色功能
- NameNode
- 完全基于内存存储文件、目录结构,文件block的映射
- 需要持久化方案保证数据的可靠性
- 提供副本放置策略
- DataNode
- 基于本地磁盘存储block(文件的形式)
- 保存block的校验和数据保证block的可靠性
- 与NameNode保持心跳,汇报block列表状态
元数据持久化
- 任何对文件系统元数据产生修改的操作,NameNode都会生成一个EditLog的事务进行记录下来
- 使用FsImage存储所有元数据的状态
- 使用本地磁盘保存EditLog和FsImage
- EditLog具有完整性,数据丢失少,但恢复速度慢,并且有提及膨胀风险
- FsImage具有恢复速度快,提及与内存数据相当,但不能实时保存,数据丢失多
- NameNode使用了FsImage+EditLog整合方案:
- 滚动将增量的EditLog更新到FsImage,以保证更近时点的FsImage和更小的EditLog体积
(科普:EditsLog:log恢复日志,FsImage:镜像,快照恢复,HDFS采用FsImage+增量的EditLog进行记录)
安全模式
- HDFS搭建时会格式化,格式化操作会产生一个空的FsImage
- 当NameNode启动时,它从磁盘中读取EditLog和FsImage
- 将所有EditLog中的事务作用在内存中的FsImage上
- 并且将新版本的FsImage从内存中保存在磁盘上
- 删除旧的EditLog,因为这个旧的EditLog的事务已经作用在了FsImage上了
- NameNode启动后会进行一个称为安全模式的特殊状态
- 处于安全模式的NameNode是不会进行数据块的复制的
- NameNode从所有的DataNode接收心跳信号和状态报告
- 每当NameNode检测确认某个数据块的副本数目达到这个最小值,那么该数据库会被认为是副本安全(safely replicated)的
- 在一定百分比的数据被NameNode检测确认是安全之后,NameNode将会退出安全模式状态
- 接下来它会确定还有哪些数据库的副本没有达到指定书目,并将数据块复制到DataNode上
HDFS中的SNN
SecondaryNameNode(SNN)
- 在非Ha模式下,SNN一般是独立的节点,周期完成对NN的EditLog向FsImage合并,减少EditLog大小,减少NN启动时间
- 根据配置文件设置的时间间隔fs.checkpoint.period默认3600秒
- 根据配置文件设置edits log大小fs.checkpoint.size规定edits文件的最大值默认是64MB
(1.x无Ha模式,2.x开始有Ha模式,Ha模式下2个NameNode,NameNode的个数与版本没有任何关系)
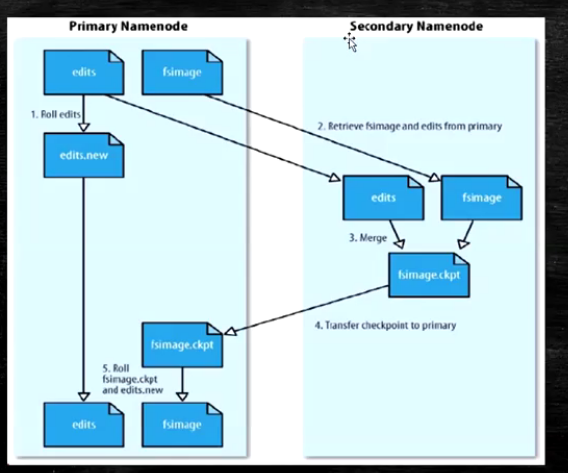
SecondaryNameNode功能图
服务器科普:

塔式服务器(Tower servers )

机架服务器(Rack server )

刀片服务器(blade Server)
关于服务器选择,PC一般选择塔式服务器。机架服务器一般用于公司,公司中使用多台机架服务器进行叠加,使用交换机来进行交换讯息。刀片服务器最贵,用于大型企业或者特殊服务
副本放置策略
- 第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点
- 第二个副本:放在于第一个副本不同的机架的节点
- 第三个副本:与第二个副本相同机架的节点
- 更多副本:随机节点

HDFS的读写流程
HDFS的写流程

- Client和NN连接创建文件元数据
- NN判定元数据是否有效
- NN触发副本放置策略,返回一个有序的DN列表
- Client和DN简历Pipeline连接
- Client将块分成packet(64KB),并使用chunk(512B)
- Client将packet发送队列dataqueue中,并向第一个DN发送
- 第一个DN收到packet后本地保存发送给第二个DN
- 第二个DN收到packet后本地保存并发给第三个DN
- 这个过程中,上游节点同时同时发送下一个packet
- 类似工厂流水线
- HDFS使用这种传输方式,副本数对于Client是透明的
- 当block传输完成,DN分别向各自的NN汇报,同时Client继续传输下一个blcok
- 所以client传输和block汇报也是并行的
HDFS读流程
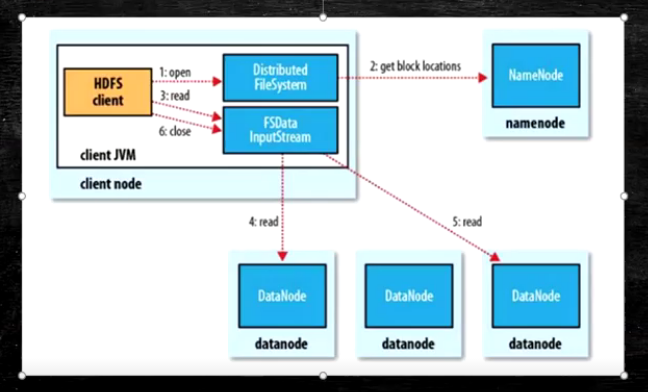
- 为了降低整体的带宽消耗和读延迟,HDFS会尽量让读取程序读取离他最近的副本
- 如果再读取程序的同一个机架上有一个副本,那么就读该副本
- 如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本
- 语义:
- download a file
- Client和NN交互文件元数据获取fileBlockLocation
- NN按距离策略排序返回
- Client尝试下载Block并且校验数据完整性(校验盒校验)
- 语义:下载一个文件其实是获取文件的所有的Block元数据,那么子集获取block应该成立
- Hdfs支持Client输出文件的offset自定义连接哪些Block的DN,自定义获取数据
- 这个是支持计算层的分治,并行计算的核心(牢记)

Hadoop API操作文件系统方法有哪些
这篇文章主要介绍“Hadoop API操作文件系统方法有哪些”,在日常操作中,相信很多人在Hadoop API操作文件系统方法有哪些问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Hadoop API操作文件系统方法有哪些”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
##Maven配置
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.3</version> </dependency> </dependencies>
创建文件夹
Configuration config = new Configuration(); try { FileSystem fs = FileSystem.get(new URI("hdfs://localhost:9000"),config); boolean result =fs.mkdirs(new Path("/api/test")); System.out.println(result); }catch (Exception e){ e.printstacktrace(); }
####读取文件
FSDataInputStream in = fileSystem.open(new Path("/hadoop.txt")); IoUtils.copyBytes(in,System.out,1024);
####创建文件
FSDataOutputStream out = fileSystem.create(new Path("/hello.txt"));out.writeUTF("hello world");out.flush();out.close();
####重命名文件
fileSystem.rename(new Path("/hello.txt"),new Path("/new.txt"));
####拷贝本地文件到hdfs
fileSystem.copyFromLocalFile(new Path("./pom.xml"),new Path("/pom.xml"));
####下载hdfs文件到本地
fileSystem.copyToLocalFile(new Path("/hadoop.txt"),new Path("hadoop.txt"));
到此,关于“Hadoop API操作文件系统方法有哪些”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注小编网站,小编会继续努力为大家带来更多实用的文章!
")
hadoop fs(HDFS文件系统命令)
Hadoop的HDFS操作命令
HDFS是存取数据的分布式文件系统,那么对HDFS的操作就是对文件系统的操作,比如文件的创建、修改、删除;文件夹的创建、修改、删除。Hadoop作者认为大家对linux文件系统的命令很熟悉,于是借鉴了linux文件系统的命令来作为HDFS的操作命令。
(1)查看帮助
hadoop fs -help
(2)查看目录信息
hadoop fs -ls /
(3)递归查看目录信息
hadoop fs -ls -R /
(4)上传文件到HDFS
hadoop fs -put /本地路径 /hdfs路径
(5)下载文件到本地
hadoop fs -get /hdfs路径 /本地路径
(6)剪切文件到hdfs
hadoop fs -moveFromLocal /本地路径 /hdfs路径
(7)剪切文件到本地
hadoop fs -moveToLocal /hdfs路径 /本地路径
(8)创建文件夹
hadoop fs -moveToLocal /hdfs路径 /本地路径
(9)创建多级文件夹
hadoop fs -mkdir -p /hello/hdp
(10)移动hdfs文件
hadoop fs -mv /hdfs路径 /hdfs路径
(11)复制hdfs文件
hadoop fs -cp /hdfs路径 /hdfs路径
(12)删除hdfs文件
hadoop fs -rm /文件路径
(13)删除hdfs文件夹
hadoop fs -rm -r /文件夹路径
(14)查看hdfs文件
hadoop fs -cat /文件路径
hadoop fs -tail -f /文件
(15)查看文件夹里有多少个文件
hadoop fs -count /文件夹
(16)查看hdfs的总空间
hadoop fs -df /
hadoop fs -df -h /
我们今天的关于Hadoop 2.6.0浏览文件系统Java和hadoop浏览器访问的分享已经告一段落,感谢您的关注,如果您想了解更多关于008-004 配置 java api hadoop fs client 操作,hadoop 客户端 文件命令的maven配置、Big Data(二)分布式文件系统那么多,为什么hadoop还需要一个hdfs文件系统?、Hadoop API操作文件系统方法有哪些、hadoop fs(HDFS文件系统命令)的相关信息,请在本站查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

