在这篇文章中,我们将带领您了解在[:index]上使用动态索引进行列表切片的全貌,包括动态索引构建的相关情况。同时,我们还将为您介绍有关ES概念及动态索引结构和索引更新机制、list列表切片方法汇总、
在这篇文章中,我们将带领您了解在[:index]上使用动态索引进行列表切片的全貌,包括动态索引构建的相关情况。同时,我们还将为您介绍有关ES 概念及动态索引结构和索引更新机制、list列表切片方法汇总、Numpy 切片与列表切片、pandas:如何使用多索引进行数据透视?的知识,以帮助您更好地理解这个主题。
本文目录一览:![在[:index]上使用动态索引进行列表切片(动态索引构建)](http://www.gvkun.com/zb_users/upload/2025/02/2e067c7e-4e54-4238-ae58-4b7ea801e5c51740407780908.jpg "在[:index]上使用动态索引进行列表切片(动态索引构建)")
在[:index]上使用动态索引进行列表切片(动态索引构建)
我需要使用负动态索引([:-index])对列表进行切片。这很容易,直到我意识到如果我的动态索引的值为0,则不返回任何项目,而不是返回整个列表。如何以索引为0时返回整个字符串的方式实现此目的?我的代码很长很复杂,但是基本上这个例子显示了这个问题:
arr=''test text'' index=2 print arr[:-index] >>''test te'' #Entire string minus 2 from the right index=1 print arr[:-index] >>''test tex'' #Entire string minus 1 from the right index=0 print arr[:-index] >>'''' #I would like entire string minus 0 from the right注意:我正在使用Python 2.7。
答案1
小编典典另一个有趣的潜在解决方案。
>>> arr = [1, 2, 3]>>> index = 0>>> arr[:-index or None][1, 2, 3]>>> index = 1>>> arr[:-index or None][1, 2]为了在诸如字符串之类的不可变序列类型上获得更高的性能,可以在切片操作 之前 检查index的值来避免在index为0的情况下完全切片序列。
这里是要测试性能的三个功能:
def shashank1(seq, index): return seq[:-index or None]def shashank2(seq, index): return index and seq[:-index] or seqdef shashank3(seq, index): return seq[:-index] if index else seq后两者应当是 多 在指数是0的情况下更快,但也可以是在其它情况下更慢(或更快)。
更新的基准代码: http :
//repl.it/oA5
注意:结果在很大程度上取决于Python的实现。

ES 概念及动态索引结构和索引更新机制
搜索引擎通过分片(shard)和副本(replica)实现了高性能、高伸缩和高可用。分片技术为大规模并行索引和搜索提供了支持,极大地提高了索引和搜索的性能,极大地提高了水平扩展能力;副本技术为数据提供冗余,部分机器故障不影响系统的正常使用,保证了系统的持续高可用。
有2个分片和3份副本的索引结构如下所示:
一个完整的索引被切分为0和1两个独立部分,每一部分都有2个副本,即下面的灰色部分。
在生产环境中,随着数据规模的增大,只需简单地增加硬件机器节点即可,搜索引擎会自动地调整分片数以适应硬件的增加,当部分节点退役的时候,搜索引擎也会自动调整分片数以适应硬件的减少,同时可以根据硬件的可靠性水平及存储容量的变化随时更改副本数,这一切都是动态的,不需要重启集群,这也是高可用的重要保障。
ElasticSearch的Schema free特性给动态提取并索引网页结构化文本内容提供了支持,使用URL的hash值来作为索引的主键(实际开发中使用URL作为主键,这里使用URL的hash值是为了方便演示),当网页内容改变后,可以非常方便地更新索引。
下面演示了动态索引结构和索引更新机制:
1、提交索引:
curl -XPUT http://localhost:9200/webpage/finance/85723925 -d ''
{
"url" : "http://money.163.com/14/0523/02/9ST8D7KR00253B0H.html",
"title" : "中国非一线城市限购可退出 楼市限购或全面松绑",
"content" : "昨日有消息称,除北上广深之外,其他城市的限购政策可以自行调节,尤其是库存过大的地方。这意味着除四大一线城市之外的30多个限购城市,有可能全面松绑限购政策。"
}
''
2、服务器响应:
{"_index":"webpage","_type":"finance","_id":"85723925","_version":1,"created":true}
3、查看索引结构:
需要elasticsearch-head插件,下面是安装方法:
plugin -install mobz/elasticsearch-head
浏览器访问:
http://localhost:9200/_plugin/head/

4、再次提交同样URL的索引,内容改变了:
curl -XPUT http://localhost:9200/webpage/finance/85723925 -d ''
{
"url" : "http://money.163.com/14/0523/02/9ST8D7KR00253B0H.html",
"title" : "标题改了:中国非一线城市限购可退出 楼市限购或全面松绑",
"content" : "内容改了:昨日有消息称,除北上广深之外,其他城市的限购政策可以自行调节,尤其是库存过大的地方。这意味着除四大一线城市之外的30多个限购城市,有可能全面松绑限购政策。"
}
''
5、服务器响应:
{"_index":"webpage","_type":"finance","_id":"85723925","_version":2,"created":false}
可以看到,版本变为2,created为false,已经成功更新索引
6、再次提交同样URL的索引,不但内容改变了,而且新增了2个字段:
curl -XPUT http://localhost:9200/webpage/finance/85723925 -d ''
{
"url" : "http://money.163.com/14/0523/02/9ST8D7KR00253B0H.html",
"title" : "标题改了:中国非一线城市限购可退出 楼市限购或全面松绑",
"content" : "内容改了:昨日有消息称,除北上广深之外,其他城市的限购政策可以自行调节,尤其是库存过大的地方。这意味着除四大一线城市之外的30多个限购城市,有可能全面松绑限购政策。",
"keywords" : "试探,限购政策,淡出,一次次",
"description" : "中国非一线城市限购可退出 楼市限购或全面松绑,试探 限购政策 淡出 一次次"
}
''
7、服务器响应:
{"_index":"webpage","_type":"finance","_id":"85723925","_version":3,"created":false}
8、再次查看索引结构:
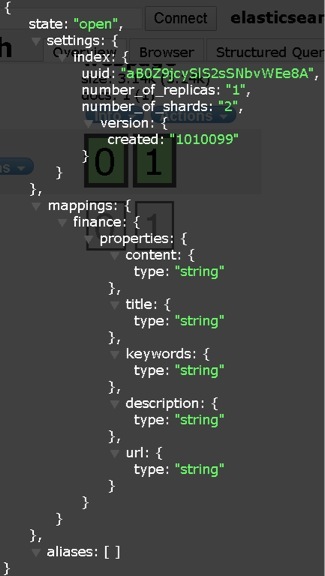
可以看到,新增的两个索引字段已经添加到索引里面了

list列表切片方法汇总
python为list列表提供了强大的切片功能,下面是一些常见功能的汇总
"""
使用模式: [start:end:step]
其中start表示切片开始的位置,默认是0
end表示切片截止的位置(不包含),默认是列表长度
step表示切片的步长,默认是1
当start是0时,可以省略;当end是列表的长度时,可以省略.
当step是1时,也可以省略,并且省略步长时可以同时省略最后一个冒号.
此外,当step为负数时,表示反向切片,这时start值应该比end值大.
注意:切片操作创建了一个新的列表.
"""
alist = [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(alist[::]) # 返回包含原列表所有元素的新列表
print(alist[::-1]) # 返回原列表的一个逆序列表
print(alist[::2]) # [1, 3, 5, 7, 9] .取列表下标偶数位元素
print(alist[1::2]) # [2, 4, 6, 8] 取列表下标奇数位元素
print(alist[3:6]) # [4, 5, 6] #取列表中下标3到6的值,步长是1
print(alist[3:6:2]) # [4, 6] #取列表中下标3到6的值,步长是2
print(alist[:10]) # [1, 2, 3, 4, 5, 6, 7, 8, 9] . end大于列表长度时,取列表中所有元素,省略了步长1.
print(alist[10:]) # [] . 表示从列表的第10位开始取,一直取到列表结果,步长是1.
alist[len(alist):] = [10] # 在列表的未尾添加一个元素
print(alist) #[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
alist[:0] = [-1,0] # 在列表的头部插入元素. alist[:0] 相当于 alist[0:0] 再相当于 alist[0:0:1]
print(alist) #[-1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
alist[5:5] = [-6] # 把列表的第6个位置替换成-6. 相当于alist[5:5:1] = [-6]
print(alist) #[-1, 0, 1, 2, 3, -6, 4, 5, 6, 7, 8, 9, 10]
alist = [1, 2, 3, 4, 5, 6, 7, 8, 9]
alist[:3] = [''A'',''B'',''C'',''D''] # 把alist的前3个元素换成[''A'',''B'',''C'',''D'']
print(alist) #[''A'', ''B'', ''C'', ''D'', 4, 5, 6, 7, 8, 9]
alist[3:] = [''E'',''F'',''G''] # 把列表第3个元素之后的元素替换成[''E'',''F'',''G'']
print(alist) # [''A'', ''B'', ''C'', ''E'', ''F'', ''G'']
alist = [1, 2, 3, 4, 5, 6]
alist[::2] = [0]*3 # 替换列表下标是偶数的前三个元素,注意使用该方法时,列表下标是偶数的元素个数必须与后面替换的元素个数相等,否则报错
print(alist) #[0, 2, 0, 4, 0, 6]
alist[::2] = [''a'',''b'',''c''] # 跟上面一样的道理,只是替换的内容不一样
print(alist) # [''a'', 2, ''b'', 4, ''c'', 6]
alist = [1, 2, 3, 4, 5, 6]
alist[:3] = [] # 删除列表中前3个元素
print(alist) # [4, 5, 6]
alist = [1, 2, 3, 4, 5, 6]
del alist[:3] # 使用del关键字删除列表前3个元素
print(alist) #[4, 5, 6]
alist = [1, 2, 3, 4, 5, 6]
del alist[::2] # 删除列表元素,下标是偶数位的元素
print(alist) #[2, 4, 6]

Numpy 切片与列表切片
如何解决Numpy 切片与列表切片?
我的清单:
a=[1,2,3,4,5]
b=a[:]
id(a)
>>2181314756864
id(b)
>>2181314855232 (different as slicing creates a new object)
id(a[0])
>>140734633334432
id(b[0])
>>140734633334432 (same)
b[0]=-1
b
>>[-1,5]
a
>>[1,5] --perfectly fine
但是在 numpy 的情况下:
import numpy as np
l=np.array([1,5])
p=l[:]
id(l)
>>2181315005136
id(p)
>>2181315019840 (different as it creates a new object,which is fine)
id(l[0])
>>2181314995440
id(p[0])
>>2181314995952 (different)
但是:
p[0]=-1
p
>>array([-1,5])
l
>>array([-1,5])
即使 numpy 数组的第一个元素的内存地址不同,l 是
也在更新。
谁能解释一下这背后的概念?
解决方法
将 id 当作内存地址来讨论有点不切实际。是的,在CPython中,它恰好是一个内存地址,但是什么的地址呢? 不是,碰巧是实际的数字数据,而是描述数字数据的 Python 对象!
在 numpy 中切片会创建一个新的 Python 对象(因此具有不同的 id),但新对象与旧对象共享实际数组的存储空间。
如果 id(A) == id(B),那么,例如,A.shape 不可能与 B.shape 不同!

pandas:如何使用多索引进行数据透视?
我想对pandas进行一次透视DataFrame,索引是两列,而不是一列。例如,一个字段用于年份,一个字段用于月份,一个“ item”字段显示“
item 1”和“ item 2”,以及一个“ value”字段和数值。我希望索引为年+月。
我设法做到这一点的唯一方法是将两个字段合并为一个,然后再次将其分开。有没有更好的办法?
最少的代码复制到下面。非常感谢!
PS:是的,我知道关键字“ pivot”和“ multi-index”还有其他问题,但是我不知道他们是否/如何帮助我解决这个问题。
import pandas as pd
import numpy as np
df= pd.DataFrame()
month = np.arange(1,13)
values1 = np.random.randint(0,100,12)
values2 = np.random.randint(200,300,12)
df['month'] = np.hstack((month,month))
df['year'] = 2004
df['value'] = np.hstack((values1,values2))
df['item'] = np.hstack((np.repeat('item 1',12),np.repeat('item 2',12)))
# This doesn't work:
# ValueError: Wrong number of items passed 24,placement implies 2
# mypiv = df.pivot(['year','month'],'item','value')
# This doesn't work,either:
# df.set_index(['year',inplace=True)
# ValueError: cannot label index with a null key
# mypiv = df.pivot(columns='item',values='value')
# This below works but is not ideal:
# I have to first concatenate then separate the fields I need
df['new field'] = df['year'] * 100 + df['month']
mypiv = df.pivot('new field','value').reset_index()
mypiv['year'] = mypiv['new field'].apply( lambda x: int(x) / 100)
mypiv['month'] = mypiv['new field'] % 100
我们今天的关于在[:index]上使用动态索引进行列表切片和动态索引构建的分享就到这里,谢谢您的阅读,如果想了解更多关于ES 概念及动态索引结构和索引更新机制、list列表切片方法汇总、Numpy 切片与列表切片、pandas:如何使用多索引进行数据透视?的相关信息,可以在本站进行搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

