在这篇文章中,我们将带领您了解为什么MySQL在FULLOUTERJOIN上报告语法错误?的全貌,包括mysql中fulljoin的用法的相关情况。同时,我们还将为您介绍有关(转载)Mysql----
在这篇文章中,我们将带领您了解为什么MySQL在FULL OUTER JOIN上报告语法错误?的全貌,包括mysql中fulljoin的用法的相关情况。同时,我们还将为您介绍有关(转载) Mysql----Join用法(Inner join,Left join,Right join, Cross join, Union模拟Full join)及---性能优化、FULL OUTER JOIN将表与PostgreSQL合并、fulltext mysql_mysql – FULLTEXT和FULLTEXT KEY / INDEX有什么区别?、Linq表连接大全(INNER JOIN、LEFT OUTER JOIN、RIGHT OUTER JOIN、FULL OUTER JOIN、CROSS JOIN)的知识,以帮助您更好地理解这个主题。
本文目录一览:- 为什么MySQL在FULL OUTER JOIN上报告语法错误?(mysql中fulljoin的用法)
- (转载) Mysql----Join用法(Inner join,Left join,Right join, Cross join, Union模拟Full join)及---性能优化
- FULL OUTER JOIN将表与PostgreSQL合并
- fulltext mysql_mysql – FULLTEXT和FULLTEXT KEY / INDEX有什么区别?
- Linq表连接大全(INNER JOIN、LEFT OUTER JOIN、RIGHT OUTER JOIN、FULL OUTER JOIN、CROSS JOIN)
")
为什么MySQL在FULL OUTER JOIN上报告语法错误?(mysql中fulljoin的用法)
SELECT airline, airports.icao_code, continent, country, province, city, websiteFROM airlines FULL OUTER JOIN airports ON airlines.iaco_code = airports.iaco_codeFULL OUTER JOIN cities ON airports.city_id = cities.city_idFULL OUTER JOIN provinces ON cities.province_id = provinces.province_idFULL OUTER JOIN countries ON cities.country_id = countries.country_idFULL OUTER JOIN continents ON countries.continent_id = continents.continent_id它说
您的SQL语法有误;检查与您的MySQL服务器版本相对应的手册以获取正确的语法,以
airports在第4行“ airlines.iaco_code
= airport.iaco_code完全外部联接”附近使用
语法对我来说似乎正确。我以前从未做过很多联接,但是我需要一个表中的那些列,这些列被各种ID交叉引用。
答案1
小编典典FULL OUTERJOINMySQL中没有。见7.2.12。外连接简化和12.2.8.1。JOIN语法:
您可以
FULL OUTER JOIN使用UNION(从MySQL 4.0.0开始)进行仿真:有两个表t1,t2:
SELECT * FROM t1LEFT JOIN t2 ON t1.id = t2.idUNIONSELECT * FROM t1RIGHT JOIN t2 ON t1.id = t2.id有三个表t1,t2,t3:
SELECT * FROM t1LEFT JOIN t2 ON t1.id = t2.idLEFT JOIN t3 ON t2.id = t3.idUNIONSELECT * FROM t1RIGHT JOIN t2 ON t1.id = t2.idLEFT JOIN t3 ON t2.id = t3.idUNIONSELECT * FROM t1RIGHT JOIN t2 ON t1.id = t2.idRIGHT JOIN t3 ON t2.id = t3.id
 Mysql----Join用法(Inner join,Left join,Right join, Cross join, Union模拟Full join)及---性能优化")
(转载) Mysql----Join用法(Inner join,Left join,Right join, Cross join, Union模拟Full join)及---性能优化
http://blog.csdn.net/ochangwen/article/details/52346610
前期数据准备
CREATE TABLE atable(
aID int( 1 ) AUTO_INCREMENT PRIMARY KEY ,
aNum char( 20 ));
CREATE TABLE btable(
bID int( 1 ) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
bName char( 20 ) );
INSERT INTO atable
VALUES ( 1, ''a20050111'' ) , ( 2, ''a20050112'' ) , ( 3, ''a20050113'' ) , ( 4, ''a20050114'' ) , ( 5, ''a20050115'' ) ;
INSERT INTO btable
VALUES ( 1, '' 2006032401'' ) , ( 2, ''2006032402'' ) , ( 3, ''2006032403'' ) , ( 4, ''2006032404'' ) , ( 8, ''2006032408'' ) ;
-------------------------------------------------------------------------------------------
atable:左表;btable:右表。
JOIN 按照功能大致分为如下三类:
1).inner join(内连接,或等值连接):取得两个表中存在连接匹配关系的记录。
2).left join(左连接):取得左表(atable)完全记录,即是右表(btable)并无对应匹配记录。
3).right join(右连接):与 LEFT JOIN 相反,取得右表(btable)完全记录,即是左表(atable)并无匹配对应记录。
注意:mysql不支持Full join,不过可以通过 union 关键字来合并 left join 与 right join来模拟full join.
一、Inner join
内连接,也叫等值连接,inner join产生同时符合A和B的一组数据。
接下来给出一个列子用于解释下面几种分类。如下两个表(A,B)
- mysql> select * from atable inner join btable on atable.aid=btable.bid;
- +-----+-----------+-----+-------------+
- | aID | aNum | bID | bName |
- +-----+-----------+-----+-------------+
- | 1 | a20050111 | 1 | 2006032401 |
- | 2 | a20050112 | 2 | 2006032402 |
- | 3 | a20050113 | 3 | 2006032403 |
- | 4 | a20050114 | 4 | 2006032404 |
- +-----+-----------+-----+-------------+

二、Left join
left join,(或left outer join:在Mysql中两者等价,推荐使用left join.)左连接从左表(A)产生一套完整的记录,与匹配的记录(右表(B)) .如果没有匹配,右侧将包含null。
- mysql> select * from atable left join btable on atable.aid=btable.bid;
- +-----+-----------+------+-------------+
- | aID | aNum | bID | bName |
- +-----+-----------+------+-------------+
- | 1 | a20050111 | 1 | 2006032401 |
- | 2 | a20050112 | 2 | 2006032402 |
- | 3 | a20050113 | 3 | 2006032403 |
- | 4 | a20050114 | 4 | 2006032404 |
- | 5 | a20050115 | NULL | NULL |
- +-----+-----------+------+-------------+

------------------------------------------------------------------------------------------------------------
2).如果想只从左表(A)中产生一套记录,但不包含右表(B)的记录,可以通过设置where语句来执行,如下
- mysql> select * from atable left join btable on atable.aid=btable.bid
- -> where atable.aid is null or btable.bid is null;
- +-----+-----------+------+-------+
- | aID | aNum | bID | bName |
- +-----+-----------+------+-------+
- | 5 | a20050115 | NULL | NULL |
- +-----+-----------+------+-------+

-----------------------------------------------------------------------------------------
同理,还可以模拟inner join. 如下:
- mysql> select * from atable left join btable on atable.aid=btable.bid where atable.aid is not null and btable.bid is not null;
- +-----+-----------+------+-------------+
- | aID | aNum | bID | bName |
- +-----+-----------+------+-------------+
- | 1 | a20050111 | 1 | 2006032401 |
- | 2 | a20050112 | 2 | 2006032402 |
- | 3 | a20050113 | 3 | 2006032403 |
- | 4 | a20050114 | 4 | 2006032404 |
- +-----+-----------+------+-------------+
------------------------------------------------------------------------------------------
三、Right join
同Left join
- mysql> select * from atable right join btable on atable.aid=btable.bid;
- +------+-----------+-----+-------------+
- | aID | aNum | bID | bName |
- +------+-----------+-----+-------------+
- | 1 | a20050111 | 1 | 2006032401 |
- | 2 | a20050112 | 2 | 2006032402 |
- | 3 | a20050113 | 3 | 2006032403 |
- | 4 | a20050114 | 4 | 2006032404 |
- | NULL | NULL | 8 | 2006032408 |
- +------+-----------+-----+-------------+
四、差集
- mysql> select * from atable left join btable on atable.aid=btable.bid
- -> where btable.bid is null
- -> union
- -> select * from atable right join btable on atable.aid=btable.bid
- -> where atable.aid is null;
- +------+-----------+------+------------+
- | aID | aNum | bID | bName |
- +------+-----------+------+------------+
- | 5 | a20050115 | NULL | NULL |
- | NULL | NULL | 8 | 2006032408 |
- +------+-----------+------+------------+

-----------------------------------------------------------------------------------
五.Cross join
交叉连接,得到的结果是两个表的乘积,即笛卡尔积
笛卡尔(Descartes)乘积又叫直积。假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1), (b,2)}。可以扩展到多个集合的情况。类似的例子有,如果A表示某学校学生的集合,B表示该学校所有课程的集合,则A与B的笛卡尔积表示所有可能的选课情况。
- mysql> select * from atable cross join btable;
- +-----+-----------+-----+-------------+
- | aID | aNum | bID | bName |
- +-----+-----------+-----+-------------+
- | 1 | a20050111 | 1 | 2006032401 |
- | 2 | a20050112 | 1 | 2006032401 |
- | 3 | a20050113 | 1 | 2006032401 |
- | 4 | a20050114 | 1 | 2006032401 |
- | 5 | a20050115 | 1 | 2006032401 |
- | 1 | a20050111 | 2 | 2006032402 |
- | 2 | a20050112 | 2 | 2006032402 |
- | 3 | a20050113 | 2 | 2006032402 |
- | 4 | a20050114 | 2 | 2006032402 |
- | 5 | a20050115 | 2 | 2006032402 |
- | 1 | a20050111 | 3 | 2006032403 |
- | 2 | a20050112 | 3 | 2006032403 |
- | 3 | a20050113 | 3 | 2006032403 |
- | 4 | a20050114 | 3 | 2006032403 |
- | 5 | a20050115 | 3 | 2006032403 |
- | 1 | a20050111 | 4 | 2006032404 |
- | 2 | a20050112 | 4 | 2006032404 |
- | 3 | a20050113 | 4 | 2006032404 |
- | 4 | a20050114 | 4 | 2006032404 |
- | 5 | a20050115 | 4 | 2006032404 |
- | 1 | a20050111 | 8 | 2006032408 |
- | 2 | a20050112 | 8 | 2006032408 |
- | 3 | a20050113 | 8 | 2006032408 |
- | 4 | a20050114 | 8 | 2006032408 |
- | 5 | a20050115 | 8 | 2006032408 |
- +-----+-----------+-----+-------------+
- 25 rows in set (0.00 sec)
- <pre><code class="hljs cs"><span class="hljs-function">#再执行:mysql> <span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> A inner <span class="hljs-keyword">join</span> B</span>; 试一试 (与上面的结果一样)
- <span class="hljs-meta">#在执行mysql> select * from A cross join B on A.name = B.name; 试一试</span></code>
实际上,在 MySQL 中(仅限于 MySQL) CROSS JOIN 与 INNER JOIN 的表现是一样的,在不指定 ON 条件得到的结果都是笛卡尔积,反之取得两个表完全匹配的结果。 inner join 与 cross join 可以省略 inner 或 cross关键字,因此下面的 SQL 效果是一样的:
- ... FROM table1 INNER JOIN table2
- ... FROM table1 CROSS JOIN table2
- ... FROM table1 JOIN table2
六.union实现Full join
全连接产生的所有记录(双方匹配记录)在表A和表B。如果没有匹配,则对面将包含null。与差集类似。
- mysql> select * from atable left join btable on atable.aid=btable.bid
- -> union
- -> select * from atable right join btable on atable.aid=btable.bid;
- +------+-----------+------+-------------+
- | aID | aNum | bID | bName |
- +------+-----------+------+-------------+
- | 1 | a20050111 | 1 | 2006032401 |
- | 2 | a20050112 | 2 | 2006032402 |
- | 3 | a20050113 | 3 | 2006032403 |
- | 4 | a20050114 | 4 | 2006032404 |
- | 5 | a20050115 | NULL | NULL |
- | NULL | NULL | 8 | 2006032408 |
- +------+-----------+------+-------------+

--------------------------------------------------------------------------------------------------------
七.性能优化
1.显示(explicit) inner join VS 隐式(implicit) inner join
- select * from
- table a inner join table b
- on a.id = b.id;
VS
- select a.*, b.*
- from table a, table b
- where a.id = b.id;
数据库中比较(10w数据)得之,它们用时几乎相同,第一个是显示的inner join,后一个是隐式的inner join。
2.left join/right join VS inner join
尽量用inner join.避免 left join 和 null.
在使用left join(或right join)时,应该清楚的知道以下几点:
(1). on与 where的执行顺序
ON 条件(“A LEFT JOIN B ON 条件表达式”中的ON)用来决定如何从 B 表中检索数据行。如果 B 表中没有任何一行数据匹配 ON 的条件,将会额外生成一行所有列为 NULL 的数据,在匹配阶段 WHERE 子句的条件都不会被使用。仅在匹配阶段完成以后,WHERE 子句条件才会被使用。它将从匹配阶段产生的数据中检索过滤。
所以我们要注意:在使用Left (right) join的时候,一定要在先给出尽可能多的匹配满足条件,减少Where的执行。如:
- select * from A
- inner join B on B.name = A.name
- left join C on C.name = B.name
- left join D on D.id = C.id
- where C.status>1 and D.status=1;
下面这种写法更省时
- select * from A
- inner join B on B.name = A.name
- left join C on C.name = B.name and C.status>1
- left join D on D.id = C.id and D.status=1
(2).注意ON 子句和 WHERE 子句的不同
- mysql> SELECT * FROM product LEFT JOIN product_details
- ON (product.id = product_details.id)
- AND product_details.id=2;
- +----+--------+------+--------+-------+
- | id | amount | id | weight | exist |
- +----+--------+------+--------+-------+
- | 1 | 100 | NULL | NULL | NULL |
- | 2 | 200 | 2 | 22 | 0 |
- | 3 | 300 | NULL | NULL | NULL |
- | 4 | 400 | NULL | NULL | NULL |
- +----+--------+------+--------+-------+
- 4 rows in set (0.00 sec)
- mysql> SELECT * FROM product LEFT JOIN product_details
- ON (product.id = product_details.id)
- WHERE product_details.id=2;
- +----+--------+----+--------+-------+
- | id | amount | id | weight | exist |
- +----+--------+----+--------+-------+
- | 2 | 200 | 2 | 22 | 0 |
- +----+--------+----+--------+-------+
- 1 row in set (0.01 sec)
从上可知,第一条查询使用 ON 条件决定了从 LEFT JOIN的 product_details表中检索符合的所有数据行。第二条查询做了简单的LEFT JOIN,然后使用 WHERE 子句从 LEFT JOIN的数据中过滤掉不符合条件的数据行。
(3).尽量避免子查询,而用join
往往性能这玩意儿,更多时候体现在数据量比较大的时候,此时,我们应该避免复杂的子查询。如下:
- insert into t1(a1) select b1 from t2
- where not exists(select 1 from t1 where t1.id = t2.r_id);
下面这个更好
- insert into t1(a1)
- select b1 from t2
- left join (select distinct t1.id from t1 ) t1 on t1.id = t2.r_id
- where t1.id is null;

FULL OUTER JOIN将表与PostgreSQL合并
在这篇文章之后,)当我将@VaoTsun给出的答案应用于更大的数据集时,我仍然遇到一个问题,这次更大的数据集由4张表而不是上述相关文章中的2张表组成。
这是我的数据集:
-- Table 'brcht' (empty)
insee | annee | nb
-------+--------+-----
-- Table 'cana'
insee | annee | nb
-------+--------+-----
036223 | 2017 | 1
086001 | 2016 | 2
-- Table 'font' (empty)
insee | annee | nb
-------+--------+-----
-- Table 'nr'
insee | annee | nb
-------+--------+-----
036223 | 2013 | 1
036223 | 2014 | 1
086001 | 2013 | 1
086001 | 2014 | 2
086001 | 2015 | 4
086001 | 2016 | 2
这是查询:
SELECT
COALESCE(brcht.insee,cana.insee,font.insee,nr.insee) AS insee,COALESCE(brcht.annee,cana.annee,font.annee,nr.annee) AS annee,COALESCE(brcht.nb,0) AS brcht,COALESCE(cana.nb,0) AS cana,COALESCE(font.nb,0) AS font,COALESCE(nr.nb,0) AS nr,0) + COALESCE(cana.nb,0) + COALESCE(font.nb,0) + COALESCE(nr.nb,0) AS total
FROM public.brcht
FULL OUTER JOIN public.cana ON brcht.insee = cana.insee AND brcht.annee = cana.annee
FULL OUTER JOIN public.font ON cana.insee = font.insee AND cana.annee = font.annee
FULL OUTER JOIN public.nr ON font.insee = nr.insee AND font.annee = nr.annee
ORDER BY COALESCE(brcht.insee,nr.insee),nr.annee);
结果,我仍然有两行而不是一行insee='086001'(请参阅下文)。我需要每个获取一行insee,在此示例中,两个2值应该在同一行上,并且一total列显示一个4值。

再次感谢您的帮助!
以下是可以轻松创建上述表的SQL脚本:
CREATE TABLE public.brcht (insee CHARACTER VARYING(10),annee INTEGER,nb INTEGER);
CREATE TABLE public.cana (insee CHARACTER VARYING(10),nb INTEGER);
CREATE TABLE public.font (insee CHARACTER VARYING(10),nb INTEGER);
CREATE TABLE public.nr (insee CHARACTER VARYING(10),nb INTEGER);
INSERT INTO public.cana (insee,annee,nb) VALUES ('036223',2017,1),('086001',2016,2);
INSERT INTO public.nr(insee,2013,('036223',2014,2),2015,4),2);

fulltext mysql_mysql – FULLTEXT和FULLTEXT KEY / INDEX有什么区别?
MysqL文档提供了这种格式来创建FULLTEXT索引:
| {FULLTEXT|SPATIAL} [INDEX|KEY] [index_name] (index_col_name,…)
[index_option]
要使用MysqL实现全文搜索,您可以通过编写来创建索引:
CREATE TABLE posts (
id int(4) NOT NULL AUTO_INCREMENT,
title varchar(255) NOT NULL,
content text,
PRIMARY KEY (id),
FULLTEXT (title, content)
) ENGINE=MyISAM;
要么
CREATE TABLE posts (
id int(4) NOT NULL AUTO_INCREMENT,
title varchar(255) NOT NULL,
content text,
PRIMARY KEY (id),
FULLTEXT KEY my_index_name (title, content)
) ENGINE=MyISAM;
my_index_name是用户定义的名称而不是字段名称.
>他们之间有什么区别?
>系统本身和开发人员是否有任何后果?
我无法在文档中找到任何线索:
解决方法:
省略索引名称
如果添加索引/键
对于表,MysqL将在指定的列(列集)上存储其他信息以加快搜索速度.
在您的第一个示例中,MysqL将生成一个索引并为其命名
my_index_name.如果省略名称,MysqL将为您选择一个.我找不到关于如何选择名称的文档,但根据我的经验,第一列的名称通常被重用作索引名称.
对于本部分讨论,全文选项无关紧要.它只定义了您要创建的索引/键的类型:
You can create special FULLTEXT indexes, which are used for full-text searches.
省略index / key关键字
仅提供全文就足够了:
| {FULLTEXT|SPATIAL} [INDEX|KEY] [index_name] (index_col_name,…)
[index_option] …
但是使用全文索引表格可能是一个好主意,因为读者会被提醒索引.
index和key是同义词
请注意,索引和键之间没有区别(请参阅create table):
KEY is normally a synonym for INDEX. The key attribute PRIMARY KEY can also be specified as just KEY when given in a column deFinition. This was implemented for compatibility with other database systems.
例
use test;
create table u (
id int primary key,
a varchar(10),
b varchar(10),
fulltext index (a, b)
);
show index from u;
将打印(我已从此输出中省略了主索引以及一些
附加栏目):
table key_name seq_in_index column_name
u a 1 a
u a 2 b
例如,如果要删除它,则需要索引名称:
alter table u
drop index a;
参考
标签:MysqL,full-text-indexing
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/223789.html原文链接:https://javaforall.cn
")
Linq表连接大全(INNER JOIN、LEFT OUTER JOIN、RIGHT OUTER JOIN、FULL OUTER JOIN、CROSS JOIN)
1、先创建两个表Group、User,两表的关系是N:N


1 CREATE TABLE [dbo].[Group](
2 [Id] [int] IDENTITY(1,1) NOT NULL,
3 [GroupName] [nvarchar](50) NULL,
4 CONSTRAINT [PK_Group] PRIMARY KEY CLUSTERED
5 (
6 [Id] ASC
7 )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
8 ) ON [PRIMARY]
9
10 CREATE TABLE [dbo].[User](
11 [Id] [int] IDENTITY(1,1) NOT NULL,
12 [UserName] [nvarchar](50) NULL,
13 [GroupId] [int] NULL,
14 CONSTRAINT [PK_User] PRIMARY KEY CLUSTERED
15 (
16 [Id] ASC
17 )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
18 ) ON [PRIMARY]2、测试数据


1 INSERT [dbo].[User] ([Id], [UserName], [GroupId]) VALUES (1, N''张1'', 1)
2 INSERT [dbo].[User] ([Id], [UserName], [GroupId]) VALUES (2, N''张2'', 2)
3 INSERT [dbo].[User] ([Id], [UserName], [GroupId]) VALUES (3, N''张3'', 4)
4
5 INSERT [dbo].[Group] ([Id], [GroupName]) VALUES (1, N''A'')
6 INSERT [dbo].[Group] ([Id], [GroupName]) VALUES (2, N''B'')
7 INSERT [dbo].[Group] ([Id], [GroupName]) VALUES (3, N''C'')3、连接大全


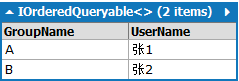
Sql:
SELECT [t0].[GroupName], [t1].[UserName]
FROM [Group] AS [t0]
INNER JOIN [User] AS [t1] ON ([t0].[Id]) = [t1].[GroupId]
Linq to Sql:
from g in Groups
join u in Users
on g.Id equals u.GroupId
select new { GroupName=g.GroupName, UserName=u.UserName}
Lambda:
Groups.Join
(
Users,
g => (Int32?)(g.Id),
u => u.GroupId,
(g, u) =>
new
{
GroupName = g.GroupName,
UserName = u.UserName
}
)


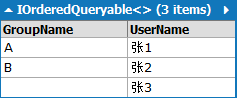
Sql:
-- Region Parameters
DECLARE @p0 NVarChar(1000) = ''''
-- EndRegion
SELECT [t0].[GroupName],
(CASE
WHEN [t2].[test] IS NULL THEN CONVERT(NVarChar(50),@p0)
ELSE [t2].[UserName]
END) AS [UserName]
FROM [Group] AS [t0]
LEFT OUTER JOIN (
SELECT 1 AS [test], [t1].[UserName], [t1].[GroupId]
FROM [User] AS [t1]
) AS [t2] ON ([t0].[Id]) = [t2].[GroupId]
Linq to Sql:
from g in Groups
join u in Users
on g.Id equals u.GroupId
into Grp
from grp in Grp.DefaultIfEmpty()
select new { GroupName=g.GroupName, UserName=(grp==null)?"":grp.UserName}
Lambda:
Groups.GroupJoin (
Users,
g => (Int32?)(g.Id),
u => u.GroupId,
(g, Grp) =>
new
{
g = g,
Grp = Grp
}
) .SelectMany (
temp0 => temp0.Grp.DefaultIfEmpty (),
(temp0, grp) =>
new
{
GroupName = temp0.g.GroupName,
UserName = (grp == null) ? "" : grp.UserName
}
)


Sql:
-- Region Parameters
DECLARE @p0 NVarChar(1000) = ''''
-- EndRegion
SELECT
(CASE
WHEN [t2].[test] IS NULL THEN CONVERT(NVarChar(50),@p0)
ELSE [t2].[GroupName]
END) AS [GroupName], [t0].[UserName]
FROM [User] AS [t0]
LEFT OUTER JOIN (
SELECT 1 AS [test], [t1].[Id], [t1].[GroupName]
FROM [Group] AS [t1]
) AS [t2] ON [t0].[GroupId] = ([t2].[Id])
Linq to Sql:
from u in Users
join g in Groups
on u.GroupId equals g.Id
into Grp
from grp in Grp.DefaultIfEmpty()
select new { GroupName=(grp==null)?"":grp.GroupName, UserName=u.UserName}
Lambda:
Users.GroupJoin (
Groups,
u => u.GroupId,
g => (Int32?)(g.Id),
(u, Grp) =>
new
{
u = u,
Grp = Grp
}
).SelectMany (
temp0 => temp0.Grp.DefaultIfEmpty (),
(temp0, grp) =>
new
{
GroupName = (grp == null) ? "" : grp.GroupName,
UserName = temp0.u.UserName
}
)


Sql:
-- Region Parameters
DECLARE @p0 NVarChar(1000) = ''''
DECLARE @p1 NVarChar(1000) = ''''
-- EndRegion
SELECT DISTINCT [t7].[GroupName], [t7].[value] AS [UserName]
FROM (
SELECT [t6].[GroupName], [t6].[value]
FROM (
SELECT [t0].[GroupName],
(CASE
WHEN [t2].[test] IS NULL THEN CONVERT(NVarChar(50),@p0)
ELSE [t2].[UserName]
END) AS [value]
FROM [Group] AS [t0]
LEFT OUTER JOIN (
SELECT 1 AS [test], [t1].[UserName], [t1].[GroupId]
FROM [User] AS [t1]
) AS [t2] ON ([t0].[Id]) = [t2].[GroupId]
UNION ALL
SELECT
(CASE
WHEN [t5].[test] IS NULL THEN CONVERT(NVarChar(50),@p1)
ELSE [t5].[GroupName]
END) AS [value], [t3].[UserName]
FROM [User] AS [t3]
LEFT OUTER JOIN (
SELECT 1 AS [test], [t4].[Id], [t4].[GroupName]
FROM [Group] AS [t4]
) AS [t5] ON [t3].[GroupId] = ([t5].[Id])
) AS [t6]
) AS [t7]
Linq to Sql:
var a=from g in Groups
join u in Users
on g.Id equals u.GroupId
into Grp
from grp in Grp.DefaultIfEmpty()
select new { GroupName=g.GroupName, UserName=(grp==null)?"":grp.UserName};
var b=from u in Users
join g in Groups
on u.GroupId equals g.Id
into Grp
from grp in Grp.DefaultIfEmpty()
select new { GroupName=(grp==null)?"":grp.GroupName, UserName=u.UserName};
var c=a.Concat(b).Distinct();
c.Dump();
Lambda:
Groups
.GroupJoin (
Users,
g => (Int32?)(g.Id),
u => u.GroupId,
(g, Grp) =>
new
{
g = g,
Grp = Grp
}
)
.SelectMany (
temp0 => temp0.Grp.DefaultIfEmpty (),
(temp0, grp) =>
new
{
GroupName = temp0.g.GroupName,
UserName = (grp == null) ? "" : grp.UserName
}
)
.Concat (
Users
.GroupJoin (
Groups,
u => u.GroupId,
g => (Int32?)(g.Id),
(u, Grp) =>
new
{
u = u,
Grp = Grp
}
)
.SelectMany (
temp2 => temp2.Grp.DefaultIfEmpty (),
(temp2, grp) =>
new
{
GroupName = (grp == null) ? "" : grp.GroupName,
UserName = temp2.u.UserName
}
)
)
.Distinct ()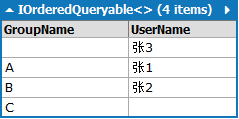


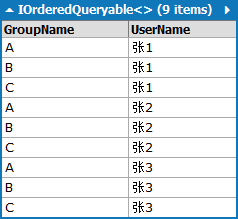
Sql:
SELECT [t0].[GroupName], [t1].[UserName]
FROM [Group] AS [t0], [User] AS [t1]
Linq to Sql:
from g in Groups
from u in Users
select new { GroupName=g.GroupName, UserName=u.UserName}
Lambda:
Groups.SelectMany
(
g => Users,
(g, u) =>
new
{
GroupName = g.GroupName,
UserName = u.UserName
}
)
今天关于为什么MySQL在FULL OUTER JOIN上报告语法错误?和mysql中fulljoin的用法的讲解已经结束,谢谢您的阅读,如果想了解更多关于(转载) Mysql----Join用法(Inner join,Left join,Right join, Cross join, Union模拟Full join)及---性能优化、FULL OUTER JOIN将表与PostgreSQL合并、fulltext mysql_mysql – FULLTEXT和FULLTEXT KEY / INDEX有什么区别?、Linq表连接大全(INNER JOIN、LEFT OUTER JOIN、RIGHT OUTER JOIN、FULL OUTER JOIN、CROSS JOIN)的相关知识,请在本站搜索。
本文标签:




