本篇文章给大家谈谈xp_pcre-RegularExpressionsinT-SQL,同时本文还将给你拓展7.2.re—Regularexpressionoperations正则表达式p...、Exp
本篇文章给大家谈谈xp_pcre - Regular Expressions in T-SQL,同时本文还将给你拓展7.2. re — Regular expression operations正则表达式 p...、Expresso - A Tool for Building and Testing Regular Expressions、Introduction to Regular Expressions in Mysql、ios – NSRegularExpression无法找到捕获组匹配项等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- xp_pcre - Regular Expressions in T-SQL
- 7.2. re — Regular expression operations正则表达式 p...
- Expresso - A Tool for Building and Testing Regular Expressions
- Introduction to Regular Expressions in Mysql
- ios – NSRegularExpression无法找到捕获组匹配项

xp_pcre - Regular Expressions in T-SQL
Introduction
xp_pcre is a follow-up to my extended stored procedure xp_regex. Both allow you to use regular expressions in T-SQL on Microsoft SQL Server 2000. This version was written because xp_regex uses the .NET Framework, which many people were reluctant to install on their SQL Servers. (It turns out they were the smart ones: although installing the .NET Framework on a SQL Server is no cause for concern, I''ve been informed by several people that hosting the CLR inside the SQL Server process is a Bad Idea™. Please see the warnings on the xp_regex page for more information.)
xp_pcre is so named because it uses the "Perl Compatible Regular Expressions" library. This library is available atwww.pcre.org. (You don''t need to download the PCRE library in order to use xp_pcre. The library is statically linked.)
Overview
There are six extended stored procedures in the DLL:
xp_pcre_matchxp_pcre_match_countxp_pcre_replacexp_pcre_formatxp_pcre_splitxp_pcre_show_cache
The parameters of all of these procedures can be CHAR, VARCHAR or TEXT of any SQL Server-supported length. The only exception is the @column_number parameter of xp_pcre_split, which is an INT.
If any required parameters are NULL, no matching will be performed and the output parameter will be set to NULL. (Note: This is different than the previous version which left the parameters unchanged.)
1. xp_pcre_match
Syntax:
Hide Copy Code
EXEC master.dbo.xp_pcre_match @input, @regex, @result OUTPUT@inputis the text to check.@regexis the regular expression.@resultis an output parameter that will hold either ''0'', ''1'' orNULL.
xp_pcre_match checks to see if the input matches the regular expression. If so, @result will be set to ''1''. If not,@result is set to ''0''. If either @input or @regex is NULL, or an exception occurs, @result will be set to NULL.
For example, this will determine whether the input string contains at least two consecutive digits:
Hide Copy Code
DECLARE @out CHAR(1) EXEC master.dbo.xp_pcre_match ''abc123xyz'', ''\d{2,}'', @out OUTPUT PRINT @outprints out:
Hide Copy Code
1This one will determine whether the input string is entirely comprised of at least two consecutive digits:
Hide Copy Code
DECLARE @out CHAR(1) EXEC master.dbo.xp_pcre_match ''abc123xyz'', ''^\d{2,}$'', @out OUTPUT PRINT @outprints out:
Hide Copy Code
02. xp_pcre_match_count
Syntax:
Hide Copy Code
EXEC master.dbo.xp_pcre_match_count @input, @regex, @result OUTPUT@inputis the text to check.@regexis the regular expression.@resultis an output parameter that will hold the number of times the regular expression matched the input string (orNULLin the case ofNULLinputs and/or an invalid regex).
xp_pcre_match_count tells you how many non-overlapping matches were found in the input string. The reason for making this a separate procedure than xp_pcre_match is for efficiency. In xp_pcre_match, as soon as there is one match, the procedure can return. xp_pcre_match_count needs to continually attempt a match until it reaches the end of the input string.
For example, this will determine how many times a separate series of numbers (of any length) appears in the input:
Hide Copy Code
DECLARE @out VARCHAR(20) EXEC master.dbo.xp_pcre_match_count ''123abc4567xyz'', ''\d+'', @out OUTPUT PRINT @outprints out:
Hide Copy Code
23. xp_pcre_replace
Syntax:
Hide Copy Code
EXEC master.dbo.xp_pcre_replace @input, @regex, @replacement, @result OUTPUT@inputis the text to parse.@regexis the regular expression.@replacementis what each match will be replaced with.@resultis an output parameter that will hold the result.
xp_pcre_replace is a search-and-replace function. All matches will be replaced with the contents of the@replacement parameter.
For example, this is how you would remove all white space from an input string:
Hide Copy Code
DECLARE @out VARCHAR(8000) EXEC master.dbo.xp_pcre_replace ''one two three four '', ''\s+'', '''', @out OUTPUT PRINT ''['' + @out + '']''prints out:
Hide Copy Code
[onetwothreefour]To replace all numbers (regardless of length) with "###":
Hide Copy Code
DECLARE @out VARCHAR(8000) EXEC master.dbo.xp_pcre_replace ''12345 is less than 99999, but not 1, 12, or 123'', ''\d+'', ''###'', @out OUTPUT PRINT @outprints out:
Hide Copy Code
### is less than ###, but not ###, ###, or ###Capturing parentheses is also supported. You can then use the captured text in your replacement string by using the variables $1, $2, $3, etc. For example:
Hide Copy Code
DECLARE @out VARCHAR(8000) EXEC master.dbo.xp_pcre_replace ''one two three four five six seven'', ''(\w+) (\w+)'', ''$2 $1,'', @out OUTPUT PRINT @outprints out:
Hide Copy Code
two one, four three, six five, sevenIf you need to include a literal $ in your replacement string, escape it with a \. Also, if your replacement variable needs to be followed immediately by a digit, you''ll need to put the variable number in braces. ${1}00 would result in the first capture followed by the literal characters 00. For example:
Hide Copy Code
DECLARE @out VARCHAR(8000) EXEC master.dbo.xp_pcre_replace ''75, 85, 95'', ''(\d+)'', ''\$${1}00'', @out OUTPUT PRINT @outprints out:
Hide Copy Code
$7500, $8500, $95004. xp_pcre_format
Syntax:
Hide Copy Code
EXEC master.dbo.xp_pcre_format @input, @regex, @format, @result OUTPUT@inputis the text to match.@regexis the regular expression.@formatis the format string.@resultis an output parameter that will hold the result.
xp_pcre_format behaves exactly like Regex.Result() in .NET or string interpolation in Perl (i.e.,$formatted_phone_number = "($1) $2-$3")
For example, the regex (\d{3})[^\d]*(\d{3})[^\d]*(\d{4}) will parse just about any US-phone-number-like string you throw at it:
Hide Shrink  Copy Code
Copy Code
DECLARE @out VARCHAR(100) DECLARE @regex VARCHAR(50) SET @regex = ''(\d{3})[^\d]*(\d{3})[^\d]*(\d{4})'' DECLARE @format VARCHAR(50) SET @format = ''($1) $2-$3'' EXEC master.dbo.xp_pcre_format ''(310)555-1212'', @regex, @format, @out OUTPUT PRINT @out EXEC master.dbo.xp_pcre_format ''310.555.1212'', @regex, @format, @out OUTPUT PRINT @out EXEC master.dbo.xp_pcre_format '' 310!555 hey! 1212 hey!'', @regex, @format, @out OUTPUT PRINT @out EXEC master.dbo.xp_pcre_format '' hello, ( 310 ) 555.1212 is my phone number. Thank you.'', @regex, @format, @out OUTPUT PRINT @outprints out:
Hide Copy Code
(310) 555-1212 (310) 555-1212 (310) 555-1212 (310) 555-1212The capturing and escaping conventions are the same as with xp_pcre_replace.
5. xp_pcre_split
Syntax:
Hide Copy Code
EXEC master.dbo.xp_pcre_split @input, @regex, @column_number, @result OUTPUT@inputis the text to parse.@regexis a regular expression that matches the delimiter.@column_numberindicates which column to return.@resultis an output parameter that will hold the formatted results.
Column numbers start at 1. An error will be raised if @column_number is less than 1. In the event that@column_number is greater than the number of columns that resulted from the split, @result will be set toNULL.
This function splits text data on some sort of delimiter (comma, pipe, whatever). The cool thing about a split using regular expressions is that the delimiter does not have to be as consistent as you would normally expect.
For example, take this line as your source data:
Hide Copy Code
one ,two|three : fourIn this case, our delimiter is either a comma, pipe or colon with any number of spaces either before or after (or both). In regex form, that is written: \s*[,|:]\s*.
For example:
Hide Copy Code
DECLARE @out VARCHAR(8000) DECLARE @input VARCHAR(50) SET @input = ''one ,two|three : four'' DECLARE @regex VARCHAR(50) SET @regex = ''\s*[,|:]\s*'' EXEC master.dbo.xp_pcre_split @input, @regex, 1, @out OUTPUT PRINT @out EXEC master.dbo.xp_pcre_split @input, @regex, 2, @out OUTPUT PRINT @out EXEC master.dbo.xp_pcre_split @input, @regex, 3, @out OUTPUT PRINT @out EXEC master.dbo.xp_pcre_split @input, @regex, 4, @out OUTPUT PRINT @outprints out:
Hide Copy Code
one two three four6. xp_pcre_show_cache
Syntax:
Hide Copy Code
EXEC master.dbo.xp_pcre_show_cacheIn order to prevent repeated regex recompilation, xp_pcre keeps a cache of the last 50 regular expressions it has processed. (Look at the bottom of RegexCache.h to change this hard-coded value.) xp_pcre_show_cachereturns a result set containing all of the regular expressions currently in the cache. There''s really no need to use it in the course of normal operations, but I found it useful during development. (I figured I would leave it in since it may be helpful for anyone who is looking at this to learn more about extended stored procedure programming.)
7. fn_pcre_match, fn_pcre_match_count, fn_pcre_replace, fn_pcre_format and fn_pcre_split
These are user-defined functions that wrap the stored procedures. This way you can use the function as part of aSELECT list, a WHERE clause, or anywhere else you can use an expression (like CHECK constraints!). To me, using the UDFs is a much more natural way to use this library.
Hide Copy Code
USE pubs GO SELECT master.dbo.fn_pcre_format( phone, ''(\d{3})[^\d]*(\d{3})[^\d]*(\d{4})'', ''($1) $2-$3'' ) as formatted_phone FROM authorsThis would format every phone number in the "authors" table.
Please note, you''ll either need to create the UDFs in every database that you use them in or remember to always refer to them using their fully-qualified names (i.e., master.dbo.fn_pcre_format). Alternatively, you can followbmoore86''s advice at the bottom of this page in his post entitled "You don''t have to put the functions in every database".
Also note that user-defined functions in SQL Server are not very robust when it comes to error handling. If xp_pcre returns an error, the UDF will suppress it and will return NULL. If you are using the UDFs and are gettingNULLs in unexpected situations, try running the underlying stored procedure. If xp_pcre is returning an error, you''ll be able to see it.
8. Installation
Copy xp_pcre.dll into your \Program Files\Microsoft SQL Server\MSSQL\binn directory.
Run the SQL script INSTALL.SQL. This will register the procedures and create the user-defined functions in the master database.
If you''d like to run some basic sanity checks/assertions, run TESTS.SQL and ERROR_TESTS.SQL. These scripts also serve to document the behavior of the procedures in cases of invalid input.
9. Unicode support
Unfortunately, this version does not support Unicode arguments. Potential solutions include:
Use xp_regex. Internally, the CLR and .NET Framework are 100% Unicode. This option is not recommended, however, due to the potential problems with hosting the CLR inside the SQL Server process.
Use the Boost Regex++ library. Unfortunately, this means giving up a lot of the newer regular expression functionality (zero-width assertions, cloistered pattern modifiers, etc.).
Have xp_pcre convert to UTF-8, which is supported by PCRE. Since I don''t use Unicode data in SQL Server, I haven''t implemented it. We''ll leave this as the dreaded "exercise for the reader".

Use
CAST,CONVERTor implicit conversions in the UDFs to coerce the arguments to ASCII. This probably won''t work for you because the reason you''re usingNVARCHAR/NTEXTcolumns in the first place is because your data cannot be represented using ASCII.
10. Misc
To build the code, you''ll need to have the Boost libraries installed. You can download them from www.boost.org. Just change the "Additional Include Directories" entry under the project properties in VS.NET. It''s under Configuration Properties | C/C++ | General.
Comments/corrections/additions are welcome. Feel free to email me...you can find my email address in the header of any of the source files. Thanks!
11. History
16 Mar 05 (v. 1.3.1):
Added
xp_pcre_match_countandfn_pcre_match_count.20 Feb 05 (v. 1.3):
All PCRE++ code was removed and rewritten from scratch. It wasn''t thread safe and was too inefficient (in my opinion) when doing splitting and replacing. This should hopefully improve concurrency (since I no longer have to do any locking on the PCRE objects). Also, since I started from scratch, I was able to make the behavior of splitting and replacing/formatting much closer to what Perl produces (especially in cases when there is a zero-width match.)
Added
xp_pcre_format.Parameter validation and error handling have been improved.
Updated TESTS.sql and added ERROR_TESTS.sql.
14 Feb 05 (v. 1.2):
Fixed the issue where splitting on a regex that matched a zero-width string (i.e., ''\s*'') would cause xp_pcre to loop infinitely.
Error conditions will now cause the output parameter to be set to
NULL. The old version left the value unchanged.Matching using the
pcrepp::Pcreobjects are now protected by aCRITICAL_SECTION. Although PCRE++ objects can be reused, they don''t appear thread-safe. If anyone feels this is adversely affecting scalability, please let me know. We can probably modify the cache to allow multiple instances of the same regular expression.Created TESTS.sql as a way to document/verify expected results in both normal and error conditions.
This version statically links against PCRE 5. The previous version used PCRE 4.3 DLL. I built both a Debug (pcre5_d.lib) and a Release (pcre5.lib) version of PCRE. xp_pcre will link against the appropriate version when it is built.
Parameter data types and sizes are checked both more rigorously and proactively. Previously, I just waited for a generic failure error when trying to read or write parameter values.
If the output parameter cannot hold the entire result, an error message will be returned to SQL Server indicating how large the variable is required to be. The value of the parameter will be set to
NULL.catch(...)handlers have been added where applicable to prevent an unhandled exception from propagating back to SQL Server.6 Oct 03 - Updated ZIP to include xp_pcre.dll. Mentioned the Boost requirement in the Misc section. Cleaned up the documentation a bit.
10 Aug 03 - Initial release.
大致步骤是 1. 下载他提供的那个压缩包,里面有源代码和安装脚本 2. 将 DLL 复制到 SQL Server 规定的目录 3. 运行 INSTALL.sql 这个脚本

7.2. re — Regular expression operations正则表达式 p...
文中翻译有些不到位的地方请看原文http://docs.python.org/library/re.html
另推荐有关python re的文档http://docs.python.org/howto/regex
中文翻译可参加http://www.cnblogs.com/ltang/archive/2011/07/31/2122914.html
本模块提供了那些在Perl中可找到的相似的匹配操作。被搜索的patterns和strings可以是Unicode性字符串或8位字符串。
正则表达式使用了反斜线''\''字符来指示特别的形式或允许在不使用它们特别含义的情况下使用这写特殊字符。这样会有问题,比如,为了匹配字面上的反斜线''\'',pattern可能会是''\\\\'',因为正则表达式必须是\\, 并且每一个反斜线在正常的python字面字符串必须被表示为\\。
为此的解决方案是使用python的raw string观念;在前缀''r''的反斜线不在具有特别含义所以r"\n"是包含''\''和''n''的2个字符,而"\n"本身是一个换行符是一个字符。通常,在Python代码中的patterns被表示为raw string。 明白大部分正则表示操作可在模块级函数和RegexObject方法下完成是很重要的。这些函数不需要你首先编译一个regex对象,但也失去了一些fine-tuning参数,所以是捷径。--参见 Mastering Regular Expressions 一书
7.2.1. Regular Expression Syntax
正则表达式(RE)明确了a set of strings that matches it;本模块中的函数让你检查一个特别的string是否匹配一个给出的re正则表达式(或给出的re是否匹配特别的string)
多个正则表达式可联合成新的正则表达式;如果A和B都是RE,则AB也是RE,一般来说,如果字符串P匹配A并且另一个字符串Q匹配B,则PQ将匹配AB。This holds unless A or B contain low precedence operations; boundary conditions between A and B; or have numbered group references.因此复杂的表达式可有小的简单表达式构成。
正则表达式可包含特殊和普通字符。大部分普通字符比如''A'',''B'',''C''是最简单的正则表达式;他们只是匹配他们自己 。可联合起来,所以last匹配''last''(剩下将介绍特别类型)
一些像''|'' , ''(''的特殊字符。特殊字符或者代表了普通字符类,或者影响着他们周围的正则表达式是如何别解释的。pattern不要包含null字节,但可使用\number中的null 字节比如''\x00''。
特殊字符:
''.'' :默认时匹配除换行符外的任意字符,如果明确了DOTALL标记,这匹配包含换行符在内的所有字符。
''^'' :匹配string的开始,在multiline模式下在每一行就匹配
''*'' :使前面的RE匹配0次或多次。所以 ab*将匹配''a'' , ''ab'' , ''a''并后跟任意多个''b''
''?'' : 使前面的RE匹配0次或1次。所以ab?将匹配''a'' 或''ab''
*? +? ?? : ''*'' ,''+'' ,''?''都是贪心的;他们能匹配多少就匹配多少。有时这种行为是不希望的;如果RE <.*>匹配''<H1>title</H1>''时将匹配整个字符串而不是我们想要的''<H1>''.所以,后加''?''将使非贪心或minimal模式;能够少匹配多少就匹配多少,所以, .*?将匹配''<H1>'' .
{m} :前面的RE匹配m次;比如a{6}将明确匹配6个''a''字符,而不是5次。
{m,n} :前面的RE匹配m到n次,在m到n的范围内能匹配多少就匹配多少。比如 a{3,5}将匹配从3到5次的''a''。省略m时说明从0次开始匹配,省略n时说明了上界为无穷多次的匹配。比如,a{4,}b匹配aaab好100个''a''再后接''b'',但不是''aaab''.
{m,n}? :前面的RE匹配m到n次,在m到n的范围内能少匹配多少就匹配多少。所以是非贪心的,如果string为''aaaaaa''则a{3,5}将匹配5个''a'' 而 a{3,5}?将匹配只3个''a''
''\'' :或者转义(escapes)特殊字符(即允许你匹配像''*'',''?''的特殊字符),或signals 一个特殊的字符串:
如果你不使用raw string来表示pattern,记得python也在string literals中将反斜线''\''用作转义字符;如果python语法分析器不认识转义字符,则反斜线和接下来的字符会被包含在最终结果的string中,但是,如果python识别了最终序列,则反斜线应重复2次。复杂斌难以理解,所以强烈推荐使用raw strings
[] :明确字符集
1.单独列出来的字符 [amk]将匹配''a''或 ''m''或 ''k''
2. 字符范围 [a-z]小写字母 [0-5][0-9]两位数字00-59 [0-9A-Fa-f]匹配16进制位,如果''-''被转义([a\-z])或被放在开头或结尾([a-])见匹配''-''
3. 在[]中特殊字符失去了其特殊的含义,比如[(+*)]将匹配字面上的''('' 或''+''或 ''*'' 或 '')''
4. 像\w 或\S的字符类也可放在[]中,即使匹配的字符依赖于LOCALE或UNICODE模式是否有效
5. 匹配不在[]中的字符,如果字符集中的第一个字符是''^'',则匹配字符集外的任意字符。比如[^5]将匹配除了5以外的任意字符,[^^]将匹配除了''^''外的任意字符。''^''如果不出现在字符集的第一个字符则没有特殊的含义。
6. 为了在集合中匹配'']'',前加反斜线或放在集合开头。比如 [()[\]{}]和[]()[{}]都匹配圆括号
''|'' :A|B (其中A和B可是任意的RE)创造了一个将匹配A或者B的正则表达式。任意数量的RE可由''|''方式分隔。此中方式也可在group中出现(下面)。当目标字符串被scanned时,由''|''分隔的RE从左到右一个一个被试。但有一个完全匹配时,此分支被接受。意味着一旦A匹配了,则B不会被test一遍,即使B可能会有一个更长的匹配。换句话说,''|''是非贪心的。为了匹配字母上的literal ''|'' 使用\|或放入[]中为[|]
(...) :只是将RE放入此中,以便后面引用:\number。为了匹配字面上的''''( 或'')''使用\(或\)或在字符类中:[(] 和[)]
(?...) :
(?iLnsux):
(?:...): 非捕获版的RE。匹配的字串无法在后面需要时被引用
(?P<name>...): 同(...)只是匹配后可由group名来引用。比如如果pattern是(?P<id>[a-zA-Z_]\w*),则以后可用m.group(''id'')或m.end(''id'')方式引用,
(?P=name): group名为name的RE
(?#...): 注释;圆括号中的注释被忽略
(?=...): 如果...匹配下面的时此才匹配,但不消耗任意的string。被叫做lookahead assertion。比如,Isaac(?=Asimov)只在后接''Asimov时才''将匹配''Isaac''
(?!...): 如果...不匹配下面的时此才匹配,比如 Isaac(?!Asimov)将匹配''Isaac''只在不后接''Asimov''时
(?<=...):前接...时才匹配。(?<=abc)def将在abcdef中发现一个匹配,...只能是固定长度的pattern,比如 abc或a|b可以,但a*和a{3,4}不行。
>>> import re >>> m = re.search(''(?<=abc)def'', ''abcdef'') >>> m.group(0) ''def''
此例找前跟连字号的一个word:
>>> m = re.search(''(?<=-)\w+'', ''spam-egg'') >>> m.group(0) ''egg''
(?<!...): 如果不前接...时此才匹配。同上,...比是固定长度。
(?(id/name)yes-pattern|no-pattern): 如果为id或名为name的group存在时才去匹配yes-pattern,反之,匹配no-pattern。no-pattern是可选的也就可省略。比如,(<)?(\w+@\w+(?:\. \w+)+)(?(1)>)是可poor的邮件匹配pattern,将匹配''<user@host.com>''或''user@host.com''但不会匹配''<user@host.com'' .
New in version 2.4.
\number:匹配编号为number的RE
group从1开始编号。比如(.+) \1匹配''the the ''或 ''55 55'',但不是''the end'' (注意空格).编号只能从0到99.
\A :只匹配string的开头。
\b : 匹配空字符串,但仅仅在word的开头或结尾。一个word被定义为有字母,数字,或下划线组成的序列,所以word的端(end)是空格或非字母,非数字,非下划线。\b被定义为\w 和\W字符之间的boundary(反之,也成立),或\w和string的开始端或结束端之间,比如,r''\bfoo\b''匹配''foo'',''foo.'' ''(foo)'', ''bar foo baz''但不会匹配''foobar''或 ''foo3''.为了兼容python的string,在字符范围内\b代表backspace字符。
\B : 匹配空字符,但仅仅但它不在word的开头或结尾时。这意味着r''py\B''将匹配''python'',''py3'',''py2'',而不会匹配''py'',''py.'',''py!''. \B是\b的反面,所以is also subject to the settings of LOCALE and UNICDOE.
\d : 当没有明确UNICODE标志位时,将匹配任意的decimal数字;这等同于[0-9].有了UNICODE时,将匹配whatever is classified as a decimal digit in the Unicode character properties database.
\D: 当没有明确UNICODE标志位时,将匹配任意的非decimal数字;这等同于[^0-9].有了UNICODE时,将匹配anything other than character marked as digits in the Unicode character properties database.
\s: 当没有明确UNICODE标志位时,将匹配任意的非空格字符;这等同于[^\t\n\r\f\v]....
\S:
\w:这等同于[a-zA-Z0-9]
\W:
\Z:
7.2.2. Module Contents
本模块定义了一些函数,常量,和异常。一些函数是。。。的简化版本。大部分应用都使用complied形式。
re.compile(pattern,flags=0)
编译一个正则表达式pattern为正则表达式对象,可利用此对象的match()和search()方法。
RE的行为可由flags改变。其值可为下面变量的任何一个,或使用|的OR操作混合起来。
prog = re.compile(pattern) result = prog.match(string)
等价于:
result = re.match(pattern, string)
但使用re.compile()为了重用而保存最终的正则表达式对象是更有效的。
re.DEBUG:显示有关compiled expression的调试信息。
re.I re.IGNORECASE: 完成大小写无关匹配;所以,像[A-Z]的表达式也将匹配小写字母。这不受current locale影响。
re.L re.LOCALE: 使得\w \W \b \B \s \S依赖与current locale
re.M re.MULTILINE: 明确此时,pattern字符''^''匹配string的开头并且在每一行的开头;''$''匹配string的结尾并且在每一行的结尾。默认情况下,''^''只匹配string的开头,''$''只匹配string的结尾。
re.S re.DOTALL: 使得''.''将匹配包含换行符在内的任意字符,没有此flag时匹配除换行符外的任意字符。
re.U re.UNICODE:使得\w \W \b \B \s \S依赖与Unicode character properties database.
re.X re.VERBOSE: 此flag可使你写出好看的RE。除了字符类的空格和preceded by unescaped backslash的空格外其他的在pattern中的空格会被忽略,
意味着下面等价:
a = re.compile(r"""\d + # the integral part \. # the decimal point \d * # some fractional digits""", re.X) b = re.compile(r"\d+\.\d*")
re.search(pattern,string,flags=0)
扫描string从中找到pattern匹配的位置,并返回相应的MatchObject实例对象。如果没有匹配返回None;注意这不同于在string中找到0长度的匹配。
re.match(pattern,string,flags=0)
如果在string的开始有0或多个字符匹配pattern,并返回相应的MatchObject实例对象。如果没有匹配返回None;注意这不同于在string中找到0长度的匹配。
注意甚至在multiline模式下,re.match()将仅仅匹配string的开头而不是每一行的开头。
如果你想要在string的任何地方locate a match,使用search()。
re.split(pattern,string ,maxsplit=0,flags=0)
split string by the occurrence of pattern。如果pattern加了圆括号,则所有pattern里所有groups的内容作为最终结果的list被返回。如果maxsplit非0,则最多maxsplit个分片发生,并且string中剩下的内容作为list中最后的元素。
>>> re.split(''\W+'', ''Words, words, words.'') [''Words'', ''words'', ''words'', ''''] >>> re.split(''(\W+)'', ''Words, words, words.'') [''Words'', '', '', ''words'', '', '', ''words'', ''.'', ''''] >>> re.split(''\W+'', ''Words, words, words.'', 1) [''Words'', ''words, words.''] >>> re.split(''[a-f]+'', ''0a3B9'', flags=re.IGNORECASE) [''0'', ''3'', ''9'']
如果有捕获groups(pattern或某个子pattern被圆括号括起来) in the seaparator并且它匹配字符串的开头,结果将以空字符串开头,空字符串结尾:
>>> re.split(''(\W+)'', ''...words, words...'') ['''', ''...'', ''words'', '', '', ''words'', ''...'', '''']
注意split绝不会在不匹配时split字符串:
>>> re.split(''x*'', ''foo'') [''foo''] >>> re.split("(?m)^$", "foo\n\nbar\n") [''foo\n\nbar\n'']
re.findall(pattern,string,flags = 0)
以list的形式返回string中所有的非重叠的匹配,每一个匹配时list的一个元素。string被从左到右扫描,匹配。如果一个或多个groups被发现,则返回返回元素为tuple的list。
re.finditer(pattern,string,flags = 0)
对每一个非重叠匹配返回MatchObject实例的inerator。
re.sub(pattern,repl,string,count = 0,flags = 0)
返回由repl替代string中每一个非重叠匹配的字串后的string。如果没有匹配被发现,则原string被返回。repl可以是string或函数,如果是string,则转义字符被使用,比如\n是一个换行符,\r是carriage return,等等。不被识别的转义字符\j are left alone.后向引用是\6表示group号为6的被匹配的字串:
>>> re.sub(r''def\s+([a-zA-Z_][a-zA-Z_0-9]*)\s*\(\s*\):'', ... r''static PyObject*\npy_\1(void)\n{'', ... ''def myfunc():'') ''static PyObject*\npy_myfunc(void)\n{''
如果repl是函数,则对每一个非重叠的引用此函数被调用一次。此函数把每个MatchObject对象作为函数参数,sub返回替换之后的字符串:
>>> def dashrepl(matchobj):
... if matchobj.group(0) == ''-'': return '' ''
... else: return ''-'' >>> re.sub(''-{1,2}'', dashrepl, ''pro----gram-files'') ''pro--gram files''
>>> re.sub(r''\sAND\s'', '' & '', ''Baked Beans And Spam'', flags=re.IGNORECASE)
''Baked Beans & Spam''
pattern可以是string或RE对象
可选的参数count是被替换的最大数;是非负值。如果此参数别省略或为0,则所有匹配被替换。仅当not adjacent to a previous match 是empty matchs被替换:sub(''x*'',''-'',''abc'')返回''-a-b-c-''.
除了字符转义和后向引用外,\g<name>将使用被匹配的group名为name的字串,此group定义为(?P<name>...).\g<number>也使用了相应的group数;\g<2>等价于\2,但不与替换中的比如\g<2>0混淆。\20被解释为对group 20的引用,不是group 2的引用并后跟字面字符''0''。后向引用\g<0>替换了整个匹配的字串。
re.subn(pattern,repl,string ,count = 0,flags = 0)
完成与sub同样的操作,但返回一个tuple (new_string,number_of_subs_made).
re.escape(string)
返回所有non-alphanumerics backslashed字串;
re.purge()
清除RE缓存
exception re.error
但一个无效的RE被传递给函数时Exception被raised(比如,可能包含了unmatched parentheses)或在编译或匹配时发生的错误。但如果string不匹配RE是不会发生error的
7.2.3. Regular Expression Objects
class re.RegexObject
RegexObject类支持下面的方法和属性:
search(string[, pos[, endpos]])
扫描此string并找RE匹配此string的位置,并返回相应的MatchObject对象。如果不匹配返回None;注意这不同于找到0长度的match。
第二个可选的参数pos给在出string中匹配开始的索引位置;默认是0即从头开始匹配。这不完全同于对string的分片操作;''^''匹配string的开头或newline的后面位置,但...
可选的参数endpos限制了string被搜索多远;就好像string只有endpos长,所以对匹配来讲仅仅有pos 到endpos-1的字符被搜索。如果endpos小于pos,不会有匹配,否则,如果rx被编译成了RE对象,re.search(string,0,50)等价于rx.search(string[:50],0)。
>>> pattern = re.compile("d") >>> pattern.search("dog") # Match at index 0 <_sre.SRE_Match object at ...> >>> pattern.search("dog", 1) # No match; search doesn''t include the "d"
match(string[,pos[,endpos]])
如果在string的开头有0个或多个字符匹配此RE,则返回相应的MatchObject实例对象。如果没有匹配则返回None;注意,这不同于0长度匹配。
可选的pos和endpos同search()。
>>> pattern = re.compile("o") >>> pattern.match("dog") # No match as "o" is not at the start of "dog". >>> pattern.match("dog", 1) # Match as "o" is the 2nd character of "dog". <_sre.SRE_Match object at ...>
如果你想要在string中定位一个match,使用search()而不是match()
split(string,maxsplit = 0)
等同于split()函数,使用compiled pattern
findall(string[, pos[, endpos]])
相似与findall()函数,使用compiled pattern,但也接受可选的参数,此些参数同match()中。
finditer(string[, pos[, endpos]])
相似与finditer()函数,使用compiled pattern,但也接受可选的参数,此些参数同match()中。
sub(repl,string,count = 0)
等价于sub()函数,使用compiled pattern。
subn(repl,string,count = 0)
等价于subn()函数,使用compiled pattern
flags
regex匹配flags。
groups
patten中被捕获的groups数
groupindex
一个字典,此字典将由(?P<id>)定义的group名与group数一一对应。如果在patter中没有使用
groups(pattern或某个 子pattern没有被圆括号括起来)则此字典为empty
pattern
the pattern string from which the RE object was compiled
7.2.4. Match Objects
class re.MatchObject
MatchObject总是有值为True的布尔值,所以你可以测试比如matct()
expand(template)
返回对template字符串进行backlash替换之后而获得的字符串,正如sub()方法那样。转义比如\n被转换为恰当的字符,数字后引用(\1 ,\2)和有名后引用(\g<1>,\g<name>)被相应group的内容所替换。
group([group1, ...])
返回匹配的一个或多个的子group。如果有一个参数,则结果是一个单string,如果有多个参数,结果是每个参数为一个item的tuple。没有参数时,group1默认为0(整个匹配被返回)。如果groupN为0,相应的返回值是整个匹配的string;如果参数在[1..99]范围内,结果是匹配相应的group的string。如果group number为负或大于patter中定义的group number,则raise一个IndexError异常。如果一个group包含在pattern中且没有匹配,则相应的结果为None。如果一个group包含在pattern中且多次被匹配,则最后那次匹配被返回。
>>> m = re.match(r"(\w+) (\w+)", "Isaac Newton, physicist") >>> m.group(0) # The entire match ''Isaac Newton'' >>> m.group(1) # The first parenthesized subgroup. ''Isaac'' >>> m.group(2) # The second parenthesized subgroup. ''Newton'' >>> m.group(1, 2) # Multiple arguments give us a tuple. (''Isaac'', ''Newton'')
如果RE使用了(?P<name>...)语法,则groupN参数也可以是个string,此string由group name给出。如果string参数不被用作pattern中的group名,raise一个IndexError。
一个适度复杂的例子:
>>> m = re.match(r"(?P<first_name>\w+) (?P<last_name>\w+)", "Malcolm Reynolds") >>> m.group(''first_name'') ''Malcolm'' >>> m.group(''last_name'') ''Reynolds''
有名的groups也可由index来引用:
>>> m.group(1) ''Malcolm'' >>> m.group(2) ''Reynolds''
如果一个group匹配了多次,只是最后那次匹配 is accessible:
>>> m = re.match(r"(..)+", "a1b2c3") # Matches 3 times. >>> m.group(1) # Returns only the last match. ''c3''
groups([default])
返回所有由subgroup匹配形成的tuple,从1到开始。default参数不会参与匹配;默认为None
比如:
>>> m = re.match(r"(\d+)\.(\d+)", "24.1632") >>> m.groups() (''24'', ''1632'')
不是所有的group会参与到匹配中。如果默认值未给出则groups将默认为None,否则值为默认值:
>>> m = re.match(r"(\d+)\.?(\d+)?", "24") >>> m.groups() # Second group defaults to None. (''24'', None) >>> m.groups(''0'') # Now, the second group defaults to ''0''. (''24'', ''0'')
groupdict([default])
返回一个字典,此字典包含了key为subgroup名 value为相应的匹配字串。如果默认值未给出则groups将默认为None,否则值为默认值:
>>> m = re.match(r"(?P<first_name>\w+) (?P<last_name>\w+)", "Malcolm Reynolds") >>> m.groupdict(){''first_name'': ''Malcolm'', ''last_name'': ''Reynolds''}
start([group])
end([group])
返回每个匹配的group的开始和结束位置;group默认为0(即整个匹配的字串)。如果group存在但没有匹配时返回-1.对一个match对象m,一个group g满足一个匹配,则g匹配的字串(m.group(g))为:
m.string[m.start(g):m.end(g)]
注意:m.start(group)在group匹配一个null字符串时将等同于m.end(group)。比如,m = re.search(''b(c?)'',''cba'')执行后,m.start(0)是1,m.end(0)是2,m.start(1)和m.end(1)都是2,m.start(2)将raise一个IndexError异常。
一个将从email地址中删除remove_this的例子:
>>> email = "tony@tiremove_thisger.net" >>> m = re.search("remove_this", email) >>> email[:m.start()] + email[m.end():] ''tony@tiger.net''
span([group])
对MatchObject m来说,返回一个(m.start(group), m,end(group))的tuple。注意,如果group不匹配,结果是(-1, -1)
group默认为0,整个匹配。
pos
此值传给RegexObject对象的search()或match()方法。这是RE引擎开始匹配的index的开始位置
endpos
此值传给RegexObject对象的search()或match()方法。这是RE引擎开始匹配的index的结束位置
lastindex
lastgroup
re
string
7.2.5. Examples
7.2.5.1. Checking For a Pair
在整个例子中,我们将使用下面的helpler函数显示math objects,使之结果更美观:
def displaymatch(match): if match is None: return None return ''<Match: %r, groups=%r>'' % (match.group(), match.groups())
假设你正在写一个扑克程序,此程序中每个玩家的手由5个字符的字符串代表,其中每一个字符代表一个卡片,''a''代表ace,''k''代表king, ''q''代表queen, ''j''代表jack, ''t''代表10以及2到9代表了卡的值。
为了查看一个给出的string是否是个有效地hand,可以如下怎么做:
>>> valid = re.compile(r"^[a2-9tjqk]{5}$") >>> displaymatch(valid.match("akt5q")) # Valid. "<Match: ''akt5q'', groups=()>" >>> displaymatch(valid.match("akt5e")) # Invalid. >>> displaymatch(valid.match("akt")) # Invalid. >>> displaymatch(valid.match("727ak")) # Valid. "<Match: ''727ak'', groups=()>"
最后一个hand, "727ak",包含了一对或2个相同值的卡。可使用后向引用:
>>> pair = re.compile(r".*(.).*\1") >>> displaymatch(pair.match("717ak")) # Pair of 7s. "<Match: ''717'', groups=(''7'',)>" >>> displaymatch(pair.match("718ak")) # No pairs. >>> displaymatch(pair.match("354aa")) # Pair of aces. "<Match: ''354aa'', groups=(''a'',)>"
7.2.5.2. Simulating scanf()
Python中当前没有相等价的scanf()函数,RE一般比scanf()格式更强大,也更啰嗦,下表或多或少提供了一些等价于scanf()函数的RE格式
| scanf() Token |
Regular Expression |
| %c |
. |
| %5c |
.{5} |
| %d |
[-+]?\d+ |
| %e, %E, %f, %g |
[-+]?(\d+(\.\d*)?|\.\d+)([eE][-+]?\d+)? |
| %i |
[-+]?(0[xX][\dA-Fa-f]+|0[0-7]*|\d+) |
| %o |
0[0-7]* |
| %s |
\S+ |
| %u |
\d+ |
| %x, %X |
0[xX][\dA-Fa-f]+ |
为了从像下面的string中提取文件名和数字:
usr/sbin/sendmail - 0 errors, 4 warnings
你会像下面这样使用scanf()格式:
%s - %d errors, %d warnings
而等价的RE会是:
(\S+) - (\d+) errors, (\d+) warnings
7.2.5.3. search() vs. match()¶
Python提供了2个不同的基于RE的基本操作:re.match()用来仅仅检查string的开头,而re.search()检查string中任何一个位置开始的匹配(perl默认就是这样)比如:
>>> re.match("c", "abcdef") # No match >>> re.search("c", "abcdef") # Match <_sre.SRE_Match object at ...>
以''^''开始的RE可被用在search()中以便来约束在string开头处的匹配:
>>> re.match("c", "abcdef") # No match >>> re.search("^c", "abcdef") # No match >>> re.search("^a", "abcdef") # Match <_sre.SRE_Match object at ...>
但,在MULTILINE模式下,match()函数仅仅匹配string的开头,但以''^''开头的RE的search()函数可匹配每行的开头。
>>> re.match(''X'', ''A\nB\nX'', re.MULTILINE) # No match >>> re.search(''^X'', ''A\nB\nX'', re.MULTILINE) # Match <_sre.SRE_Match object at ...>
7.2.5.4. Making a Phonebook
split()函数以pattern将string分隔形成一个list。此方法在将文本数据转化为易读易修改的数据结构时显得很与价值。
首先,输入正常意义下来自于文件,这里我们使用triple-quoted字符串语法:
>>> text = """Ross McFluff: 834.345.1254 155 Elm Street ... ... Ronald Heathmore: 892.345.3428 436 Finley Avenue ... Frank Burger: 925.541.7625 662 South Dogwood Way ... ... ... Heather Albrecht: 548.326.4584 919 Park Place"""
字符串给一个或多个空行分隔开。现在我们将string转化为每一个非空行是list中一个元素而形成的list:
>>> entries = re.split("\n+", text) >>> entries [''Ross McFluff: 834.345.1254 155 Elm Street'', ''Ronald Heathmore: 892.345.3428 436 Finley Avenue'', ''Frank Burger: 925.541.7625 662 South Dogwood Way'', ''Heather Albrecht: 548.326.4584 919 Park Place'']
最后,将每一行在split成一个first-name last-name telephone-number 和 address构成的list。使用maxsplit参数,因为address占有空间:
>>> [re.split(":? ", entry, 3) for entry in entries] [[''Ross'', ''McFluff'', ''834.345.1254'', ''155 Elm Street''], [''Ronald'', ''Heathmore'', ''892.345.3428'', ''436 Finley Avenue''], [''Frank'', ''Burger'', ''925.541.7625'', ''662 South Dogwood Way''], [''Heather'', ''Albrecht'', ''548.326.4584'', ''919 Park Place'']]
'':?''匹配last-name的冒号。如果maxsplit为4我们可以从street-name中分隔出housr-number:
>>> [re.split(":? ", entry, 4) for entry in entries]
[[''Ross'', ''McFluff'', ''834.345.1254'', ''155'', ''Elm Street''],
[''Ronald'', ''Heathmore'', ''892.345.3428'', ''436'', ''Finley Avenue''],
[''Frank'', ''Burger'', ''925.541.7625'', ''662'', ''South Dogwood Way''],
[''Heather'', ''Albrecht'', ''548.326.4584'', ''919'', ''Park Place'']]
7.2.5.5. Text Munging
sub()用string或函数的结果替换每一次pattern的匹配。这个例子显示了使用sub()函数repl为一个函数,在此函数中"munge" text,或者随机化除了第一个和最后一个字符外的字符:
>>> def repl(m):
... inner_word = list(m.group(2))
... random.shuffle(inner_word)
... return m.group(1) + "".join(inner_word) + m.group(3)
>>> text = "Professor Abdolmalek, please report your absences promptly."
>>> re.sub(r"(\w)(\w+)(\w)", repl, text)
''Poefsrosr Aealmlobdk, pslaee reorpt your abnseces plmrptoy.''
>>> re.sub(r"(\w)(\w+)(\w)", repl, text)
''Pofsroser Aodlambelk, plasee reoprt yuor asnebces potlmrpy.''
7.2.5.6. Finding all Adverbs
findall()匹配所有的pattern,不仅仅是search()那样子匹配第一个。比如,如果某个作家想要在文本中找到所有的动词,他或她可像如下这样使用:
>>> text = "He was carefully disguised but captured quickly by police."
>>> re.findall(r"\w+ly", text)
[''carefully'', ''quickly'']
7.2.5.7. Finding all Adverbs and their Positions
如果某人想要得到有关匹配更多的信息,finditer()是很有用的,因为它提供了MathcObject实例对象。接着前面的例子,如果某个作家想要在某个文本中找到动词以及出现的位置,可使用finditer():
>>> text = "He was carefully disguised but captured quickly by police."
>>> for m in re.finditer(r"\w+ly", text):
... print ''%02d-%02d: %s'' % (m.start(), m.end(), m.group(0))
07-16: carefully
40-47: quickly
7.2.5.8. Raw String Notation
raw stirng概念(r"text")使得RE健全。没有此,每个在RE中的反斜线''\''可能必须要前缀另一个反斜线来转义它,下面代码功能上等价:
>>> re.match(r"\W(.)\1\W", " ff ")
<_sre.SRE_Match object at ...>
>>> re.match("\\W(.)\\1\\W", " ff ")
<_sre.SRE_Match object at ...>
当某人想要匹配一个字面上的反斜线是,必须在RE中转义。有了raw string后即r"\\"。没有raw string时必须使用"\\\\",下面代码等价:
>>> re.match(r"\\", r"\\")
<_sre.SRE_Match object at ...>
>>> re.match("\\\\", r"\\")
<_sre.SRE_Match object at ...>

Expresso - A Tool for Building and Testing Regular Expressions
- Download Installation File - 88 Kb
- Download Source Code - 91 Kb
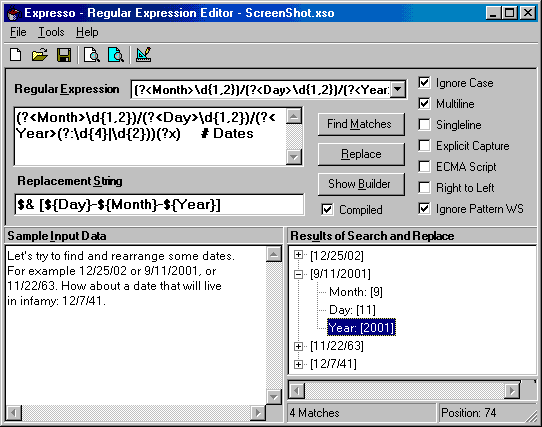
Introduction
The .NET framework provides a powerful class Regex for creating and using Regular Expressions. While regular expressions are a powerful way to parse, edit, and replace text, the complex syntax makes them hard to understand and prone to errors, even for the experienced user. When developing code that uses regular expressions, I have found it very helpful to create and debug my expressions in a separate tool to avoid time consuming compile/debug cycles. Expresso enables me to do the following:
-
Build complex regular expressions by selecting components from a palette
-
Test expressions against real or sample input data
-
Display all matches in a tree structure showing captured groups, and all captures within a group
-
Build replacement strings and test the match and replace functionality
-
Highlight matched text in the input data
-
Automatically test for syntax errors
-
Generate Visual Basic or C# code that can be incorporated directly into programs
-
Read or save regular expressions and input data
Background
Regular expressions are a sophisticated generalization of the "wildcard" syntax that users of Unix, MSDOS, Perl, AWK, and other systems are already familiar with. For example, in MSDOS, one can say:
dir *.exeto list all of the files with the exe extension. Here the asterisk is a wildcard that matches any character string and the period is a literal that matches only a period. For decades, much more complex systems have been used to great advantage whenever it is necessary to search text for complex patterns in order to extract or edit parts of that text. The .NET framework provides a class called Regex that can be used to do search and replace operations using regular expressions. In .NET, for example, suppose we want to find all the words in a text string. The expression \wwill match any alphanumeric character (and also the underscore). The asterisk character can be appended to \w to match an arbitrary number of repetitions of \w, thus \w* matches all words of arbitrary length that include only alphanumeric characters (and underscores).
Expresso provides a toolbox with which one can build regular expressions using a set of tab pages from which any of the syntactical elements can be selected. After building an expression, sample data can be read or entered manually, and the regular expression can be run against that data. The results of the search are then displayed, showing the hierarchy of named groups that Regex supports. The tool also allows testing of replacement strings and generation of code to be inserted directly into a C# or Visual Basic .NET program.
The purpose of this article is not to give a tutorial on the use of regular expressions, but rather to provide a tool for both experienced and novice users of regular expressions. Much of the complex behavior of regular expressions can be learned by experimenting with Expresso.
The reader may also find it helpful to explore some of the code within Expresso to see examples of the use of regular expressions and the Regexclass.
Using Expresso to Build and Test Regular Expressions on Sample Input Data
To use Expresso, download and run the executable file, which requires the .NET Framework. If you want to explore the code, download and extract the source files, open the solution within Visual Studio .NET, then compile and run the program. Expresso will start with sample data preloaded into the "Input Data" box (refer to the figure above). Create your own regular expression or select one of the examples from the list box. Click "Find Matches" to test the regular expression. The matches are shown in a tree structure in the "Results" box. Multiple groups and captures can be displayed by expanding the plus sign as shown above.
To begin experimenting with your own regular expressions, click the "Show Builder" button. It will display a set of tab pages as shown here:

In this example, the expression \P{IsGreek}{4,7}? has been generated by setting options that specify: match strings of four to seven characters, but with as few repetitions as possible, of any characters other than Greek letters. By clicking the "Insert" button, this expression will be inserted into the regular expression that is being constructed in the text box that contains the regular expression that will be used by the "FindMatch" or "Replace" buttons. Using the other tab pages, all of the syntactical elements of .NET regular expressions can be tested.
The Regex class supports a number of options such as ignoring the case of characters. These options can be specified using check boxes on the main form of the application.
Replacement strings may be built using the various expressions found on the "Substitutions" tab. To test a replacement pattern, enter a regular expression, a replacement string, some input data, and then click the "Replace" button. The output will be shown in the "Results" box.
Using Expresso to Generate Code
Once a regular expression has been thoroughly debugged, code can be generated by selecting the appropriate option in the "Code" menu. For example, to generate code for a regular expression to find dates, create the following regular expression (or select this example from the drop down list):
(?<Month>\d{1,2})/(?<Day>\d{1,2})/(?<Year>(?:\d{4}|\d{2}))By selecting the "Make C# Code" from the "Code" menu, the following code is generated. It can be saved to a file or cut and pasted into a C# program to create a Regex object that encapsulates this particular regular expression. Note that the regular expression itself and all the selected options are built into the constructor for the new object:
using System.Text.RegularExpressions;
Regex regex = new Regex(
@"(?<Month>\d{1,2})/(?<Day>\d{1,2})/(?<Yea"
+ @"r>(?:\d{4}|\d{2}))",
RegexOptions.IgnoreCase
| RegexOptions.Multiline
| RegexOptions.IgnorePatternWhitespace
| RegexOptions.Compiled
);Points of Interest
After creating this tool, I discovered the Regex Workbench by Eric Gunnerson, which was designed for the same purpose. Expresso provides more help in building expressions and gives a more readable display of matches (in my humble opinion), but Eric''s tool has a nice feature that shows Tooltips that decode the meaning of subexpressions within an expression. If you are serious about regular expressions, try both of these tools!
History
Original Version: 2/17/03
Version 1.0.1148: 2/22/03 - Added a few additional features including the ability to create an assembly file and registration of a new file type (*.xso) to support Expresso Project Files.
Version 1.0.1149: 2/23/03 - Added a toolbar.
My brother John doesn''t like the name Expresso, since he says too many people are already confused about the proper spelling and pronunciation of Espresso. Somehow, I doubt this program will have any impact on the declining literacy of America, but who knows. John prefers my earlier name "Mr. Mxyzptlk", after the Superman character with the unpronounceable name.
For the latest information on Expresso (if any), see http://www.ultrapico.com/ .
License
This article has no explicit license attached to it but may contain usage terms in the article text or the download files themselves. If in doubt please contact the author via the discussion board below.
A list of licenses authors might use can be found here
About the Author
| Jim Hollenhorst
Researcher
 United States United States
Member |
Ultrapico Website: http://www.ultrapico.com Download Expresso 3.0, the latest version of the award-winning regular expression development tool. |

Introduction to Regular Expressions in Mysql
A regular expression is a special string that describes a search pattern.
It is a powerful tool that gives us a concise and flexible strings of text e.g. characters, and words based on patterns.
For example, we can use regular expressions to search for email, IP address, phone number social security number or anything that has a specific pattern.
The advantage of using regular expression is that you are not limited to search for a string based on a fixed pattern with the percent sign (%) and underscore (_) in the LIKE operator. The regular expressions have more meta-characters to construct flexible patterns.
The following illustrates the syntax of the REGEXP operator in the WHERE clause:
SELECT
column_list
FROM
table_name
WHERE
string_column REGEXP pattern;If a value in the string_column matches the pattern, the expression in the WHERE clause returns true, otherwise it returns false.
If either string_column or pattern is NULL, the result is NULL.
In addition to the REGEXP operator, you can use the RLIKE operator, which is the synonym of the REGEXP operator.
Examples 1 , Start with.

Code for the answer:
SELECT distinct
City
FROM
Station
WHERE
City REGEXP ''^(a|e|i|o|u)''
Example 2. End with
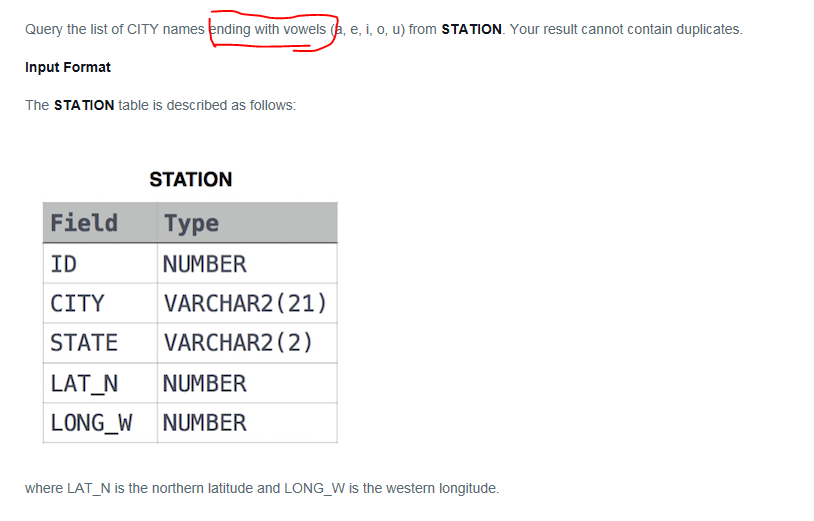
Code Answer
SELECT distinct
City
FROM
station
WHERE
city REGEXP ''[a|e|i|o|u]$''
Example 3 . Begin and End with.
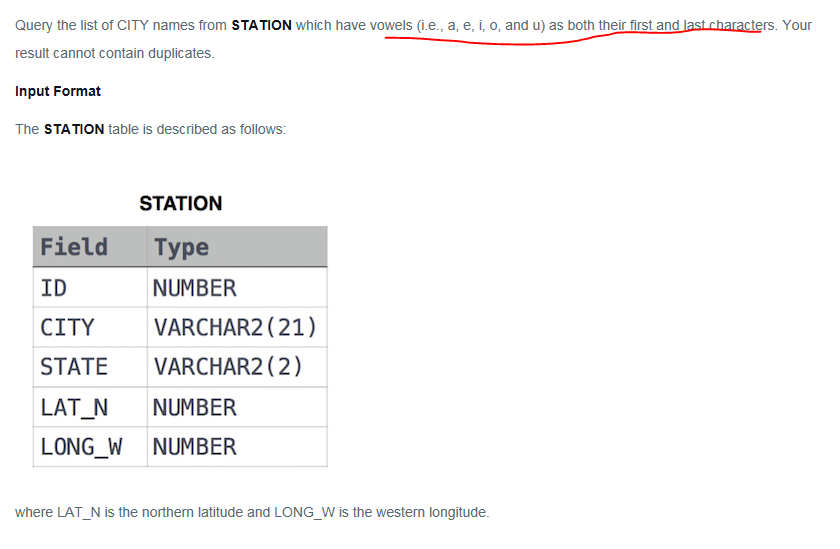
Answer code:
. means : matches any single character
* means : matches the preceding character zero or more times
SELECT distinct
City
FROM
station
WHERE
city REGEXP ''^(a|e|i|o|u).*[a|e|i|o|u]$''
- Round a value to a scale of decimal places.
SELECT ROUND(135.375, 2);- Truncate()
MySQL TRUNCATE() returns a number after truncated to certain decimal places. The number and the number of decimal places are specified as arguments of the TRUNCATE function.
Syntax:
TRUNCATE(N, D);
Example.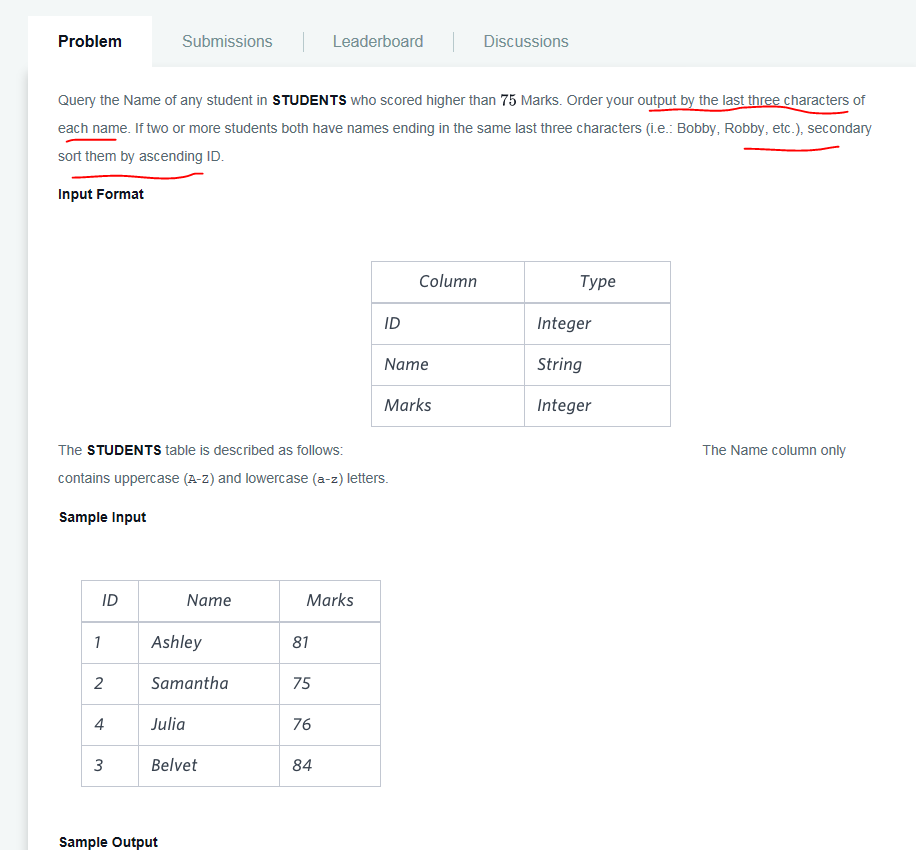
Answer to the question.
select name from students where marks > 75 order by substring(name,-3,3) , id asckey: SUBSTRING(string, start, length),
if start = 1, then it means start from the left first character,
if starte = -1, then it means start from the right first charcter.

ios – NSRegularExpression无法找到捕获组匹配项
这是模式:
(\")(.+)(\")\s*(\{)
这是要解析的文本:
"base" {
我想找到这4个捕获组:
1. "
2. base
3. "
4. {
我正在使用以下代码尝试捕获这些组
class func matchesInCapturingGroups(text: String,pattern: String) -> [String] {
var results = [String]()
let textRange = NSMakeRange(0,count(text))
var index = 0
if let matches = regexp(pattern)?.matchesInString(text,options: NSMatchingOptions.ReportCompletion,range: textRange) as? [NSTextCheckingResult] {
for match in matches {
// this match = <NSExtendedRegularExpressionCheckingResult: 0x7fac3b601fd0>{0,8}{<NSRegularExpression: 0x7fac3b70b5b0> (")(.+)(")\s*(\{) 0x1}
results.append(self.substring(text,range: match.range))
}
}
return results
}
不幸的是,它只能找到一个范围(0,8)的组,它等于:“base”{.所以它找到一个组,它是整个字符串而不是4个组.
甚至可以使用NSRegularExpression来获取这些组吗?
解决方法
func matchesInCapturingGroups(text: String,text.lengthOfBytesUsingEncoding(NSUTF8StringEncoding))
do {
let regex = try NSRegularExpression(pattern: pattern,options: [])
let matches = regex.matchesInString(text,range: textRange)
for index in 1..<matches[0].numberOfRanges {
results.append((text as Nsstring).substringWithRange(matches[0].rangeAtIndex(index)))
}
return results
} catch {
return []
}
}
let pattern = "(\")(.+)(\")\\s*(\\{)"
print(matchesInCapturingGroups("\"base\" {",pattern: pattern))
你实际上只得到1场比赛.你必须进入那场比赛,在那里你会找到被捕获的组.请注意,我省略了第一个组,因为第一个组代表整个匹配.
这将输出
[“””,“base”,“””,“{“]
请注意转义的正则表达式字符串,并确保您使用相同的字符串.
今天关于xp_pcre - Regular Expressions in T-SQL的讲解已经结束,谢谢您的阅读,如果想了解更多关于7.2. re — Regular expression operations正则表达式 p...、Expresso - A Tool for Building and Testing Regular Expressions、Introduction to Regular Expressions in Mysql、ios – NSRegularExpression无法找到捕获组匹配项的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

