此处将为大家介绍关于greenplumjdbcreadmebypivotal的详细内容,此外,我们还将为您介绍关于ADBPG&Greenplum成本优化之磁盘水位管理、DeepgreenDB是什么(含
此处将为大家介绍关于greenplum jdbc readme by pivotal的详细内容,此外,我们还将为您介绍关于ADBPG&Greenplum成本优化之磁盘水位管理、Deepgreen DB 是什么(含Deepgreen和Greenplum下载地址)、Deepgreen(Greenplum) DBA常用运维SQL、Deepgreen/Greenplum 删除节点步骤的有用信息。
本文目录一览:- greenplum jdbc readme by pivotal
- ADBPG&Greenplum成本优化之磁盘水位管理
- Deepgreen DB 是什么(含Deepgreen和Greenplum下载地址)
- Deepgreen(Greenplum) DBA常用运维SQL
- Deepgreen/Greenplum 删除节点步骤

greenplum jdbc readme by pivotal
README Progress(R) DataDirect(R) DataDirect Connect(R) for JDBC DataDirect Connect XE (Extended Edition) for JDBC Release 5.1.4 December 2015
Copyright (c) 1994-2015 Progress Software Corporation and/or its subsidiaries or affiliates. All Rights Reserved.
CONTENTS
Requirements Installation Directory Changes since Service Pack 4 Changes for Service Pack 4 Changes for Service Pack 3 Changes for Service Pack 2 Changes for Service Pack 1 Release 5.1.0 Features Installation/Uninstallation Available DataDirect Connect Series for JDBC Drivers Notes, Known Problems, and Restrictions Using the Documents DataDirect Connect Series for JDBC Files Third Party Acknowledgements
Requirements
Java SE 5 or higher must be installed and the JVM must be defined on your system path.
Installation Directory
The default installation directory for DataDirect Connect for JDBC and DataDirect Connect XE for JDBC is:
-
Windows: C:\Program Files\Progress\DataDirect\Connect_for_JDBC_51
-
UNIX/Linux: /opt/Progress/DataDirect/Connect_for_JDBC_51
Changes since Service Pack 4
Driver for Apache Hive
The driver''s Kerberos functionality has been enhanced to support SASL-QOP data integrity and confidentiality. Hence, in addition to supporting the auth value, the driver now supports the auth-int and auth-conf values. SASL-QOP values are defined as follows:
- auth: authentication only (default)
- auth-int: authentication with integrity protection
- auth-conf: authentication with confidentiality protection
Note that SASL-QOP is configured on the server side as a part of HiveServer2 Kerberos configuration. When Kerberos authentication is enabled through the driver (AuthenticationMethod=kerberos), the driver automatically detects and abides by the server''s SASL-QOP configuration at connection time.
Certifications
-
The Salesforce driver has been certified with versions 33 and 34 of the Salesforce API.
-
The driver for Apache Hive has been certified with Apache Hive 1.0.0 and 1.1.0.
-
The driver for Apache Hive has been certified with the following distributions:
- Hortonworks (HDP) 2.3 with Apache Hive 1.2
- IBM BigInsights 3.0 with Apache Hive 0.12
- Pivotal (PHD) 2.1 with Apache Hive 0.12
- Cloudera (CDH) 5.3 with Apache Hive 0.13
- Amazon (AMI) 3.7 with Apache Hive 0.13
Statement Pooling
Added the RegisterStatementPoolMonitorMBean connection property. Note that the driver no longer registers the Statement Pool Monitor as a JMX MBean by default. You must set RegisterStatementPoolMonitorMBean to true to register the Statement Pool Monitor and manage statement pooling with standard JMX API calls. See "Notes, Known Problems, and Restrictions" for details.
DB2 Driver
Added support for cursor type OUT parameters for DB2 for Linux, UNIX, Windows stored procedures. See "Notes, Known Problems, and Restrictions" for details.
Oracle Driver
The LOBPrefetchSize connection property has been added to the driver and is supported for Oracle database versions 12.1.0.1 and higher. This connection property allows you to specify the size of prefetch data the driver returns for BLOBs and CLOBs. With LOB prefetch enabled, the driver can return LOB meta-data and the beginning of LOB data along with the LOB locator during a fetch operation. This can have significant performance impact, especially for small LOBs which can potentially be entirely prefetched, because the data is available without having to go through the LOB protocol. See "Notes, Known Problems, and
Restrictions" for details.
Changes for Service Pack 4
Certifications
-
The OpenEdge driver has been certified with Progress OpenEdge 11.4 and 11.5.
-
The PostgreSQL driver has been certified with PostgreSQL 9.3 and 9.4.
-
The Greenplum driver has been certified with Greenplum 4.3 and Pivotal HAWQ 1.2.
-
The DB2 driver has been certified with DB2 for i 7.2.
-
The driver for Apache Hive has been certified with Apache Hive 0.13 and 0.14.
-
The driver for Apache Hive has been certified with the following distributions:
- Hortonworks (HDP) 2.2 with Apache Hive 0.14
- Cloudera (CDH) 5.2 with Apache Hive 0.13
- Amazon (AMI) 3.2-3.3.1 with Apache Hive 0.13
- Hortonworks (HDP) 2.1 with Apache Hive 0.13
- Cloudera (CDH) 5.0 and 5.1 Apache Hive 0.12
-
The Sybase driver has been certified with SAP Adaptive Server Enterprise 16.0 (formerly Sybase Adaptive Server Enterprise 16.0).
DB2 Driver
The connection properties RandomGenerator and SecureRandomAlgorithm have been added to the driver.
-
RandomGenerator allows you to specify the type of random number generator (RNG) the database uses for secure seeding.
-
SecureRandomAlgorithm can be used to specify the SecureRandom number generation algorithm used for secure seeding with implementations of JDK 8 or higher when RandomGenerator is set to secureRandom.
Oracle Driver
-
The SDUSize connection property has been added to the driver. This connection property allows you to specify the size in bytes of the Session Data Unit (SDU) that the driver requests when connecting to the server.
-
The SupportBinaryXML connection property has been added to the driver. This connection property enables the driver to support XMLType with binary storage on servers running Oracle 12C and higher.
-
The connection properties RandomGenerator and SecureRandomAlgorithm have been added to the driver.
- RandomGenerator allows you to specify the type of random number generator (RNG) the database uses for secure seeding.
- SecureRandomAlgorithm can be used to specify the SecureRandom number generation algorithm used for secure seeding with implementations of JDK 8 or higher when RandomGenerator is set to secureRandom.
SQL Server
Support for NTLMv2 has been added to the driver. You can use the AuthenticationMethod connection property to specify that the driver use NTLMv2 authentication when establishing a connection.
Driver for Apache Hive
-
Support for row-level inserts has been added to the driver.
-
The driver has been enhanced to support the Char, Decimal, Date, and Varchar data types.
CryptoProtocolVersion Connection Property
To avoid vulnerabilities associated with SSLv3 and SSLv2, including the POODLE vulnerability, this connection property can be used with any of the following drivers.
- DB2 driver - PostgreSQL driver
- Greenplum driver - Progress OpenEdge driver
- MySQL driver - Microsoft SQL Server driver
- Oracle driver - Sybase driver
Result Set Holdability
Support for result set holdability has been added to the driver.
Changes for Service Pack 3
Certifications
-
The DB2 driver has been certified with DB2 V11 for z/OS.
-
The SQL Server driver has been certified with Microsoft SQL Server 2014.
-
The Salesforce driver has been certified with Salesforce API Version 29.
Changes for Service Pack 2
Certifications
-
The driver for Apache Hive has been certified with Apache Hive 0.11 and 0.12.
-
The driver for Apache Hive has been certified with the following distributions:
- Amazon EMR with Apache Hive 0.11
- Apache Hadoop Hive with Apache Hive 0.11 and 0.12
- Cloudera (CDH) 4.3, 4.4, and 4.5 with Apache Hive 0.10, 0.11, and 0.12
- Hortonworks (HDP) 1.3 with Apache Hive 0.11
- Hortonworks (HDP) 2.0 with Apache Hive 0.12
-
The DB2 driver has been certified with DB2 V10.5 for Linux/UNIX/Windows.
-
The Greenplum driver has been certified with Pivotal HAWQ 1.1.
-
The Informix driver has been certified with Informix 12.10.
-
The OpenEdge driver has been certified with Progress OpenEdge 11.1, 11.2, and 11.3.
-
The Oracle driver has been certified with Oracle 12c.
-
The Salesforce driver has been certified with Salesforce API Version 28.
Driver for Apache Hive
Added support for the Kerberos authentication protocol with the following connection properties:
-
AuthenticationMethod
-
ServicePrincipalName
Greenplum Driver
-
Added SSL support for Greenplum 4.2, incorporating eight additional connection properties
-
Added SupportsCatalogs connection property, which enables driver support for catalog calls
-
Added four connection properties to handle VARCHAR, LONGVARCHAR, and NUMERIC data types: MaxVarcharSize, MaxLongVarcharSize, MaxNumericPrecision, and MaxNumericScale
Oracle Driver
Modified to support all Oracle 11gR2 Kerberos encryption algorithms
PostgreSQL Driver
-
Added SupportsCatalogs connection property, which enables driver support for catalog calls
-
Added four connection properties to handle VARCHAR, LONGVARCHAR, and NUMERIC data types: MaxVarcharSize, MaxLongVarcharSize, MaxNumericPrecision, and MaxNumericScale
Changes for Service Pack 1
New Drivers
-
Driver for Apache Hive(TM)
- Supports Apache Hive 0.8.0 and higher
- Supports HiveServer1 and HiveServer2 protocols
- Supports Hive distributions:
- Amazon Elastic MapReduce (Amazon EMR)
- Apache Hadoop Hive
- Cloudera’s Distribution Including Apache Hadoop (CDH)
- MapR Distribution for Apache Hadoop (MapR)
- Returns result set metadata for parameterized statements that have been prepared but not yet executed
- Supports connection pooling
- Includes the LoginTimeout connection property which allows you to specify the amount of time the driver waits for a connection to be established before timing out the connection request
- Includes the TransactionMode connection property which allows you to configure the driver to report that it supports transactions, even though Hive does not support transactions. This provides a workaround for applications which do not operate with a driver that reports transactions are not supported.
- The driver provides support for the following standard SQL functionality:
- Create Table and Create View
- Insert
- Drop Table and Drop View
- Batches in HiveServer2 connections
-
Greenplum Driver
- Supports Greenplum database versions 4.2, 4.1, 4.0, 3.3, 3.2
- Supports connection pooling
- Supports the DataDirect Bulk Load API
- Includes the TransactionErrorBehavior connection property which determines how the driver handles errors that occur within a transaction
- Includes the LoginTimeout connection property which allows you to specify the amount of time the driver waits for a connection to be established before timing out the connection request
-
PostgreSQL Driver
- Supports PostgreSQL database versions 9.2, 9.1, 9.0, 8.4, 8.3, 8.2
- Supports SSL protocol for sending encrypted data
- Supports connection pooling
- Supports the DataDirect Bulk Load API
- Includes the TransactionErrorBehavior connection property which determines how the driver handles errors that occur within a transaction
- Includes the LoginTimeout connection property which allows you to specify the amount of time the driver waits for a connection to be established before timing out the connection request
Certifications
-
The Salesforce driver has been certified with Salesforce API Version 27.
-
The MySQL driver has been certified with MySQL 5.6.
DataDirect Spy
Enhanced to throw warning when EnableBulkLoad fails in Oracle, SQL Server, Sybase, and Salesforce drivers.
Oracle Driver
Added support for Oracle Wallet
SQL Server Driver
-
Added ApplicationIntent connection property, which enables you to request read-only routing and connect to read-only database replicas.
-
Enhanced drivers so that transaction isolation level may only be changed before the transaction is started.
Sybase Driver
Enhanced AuthenticationMethod connection property to allow for the driver to send a user ID in clear text and an encrypted password to the server for authentication.
Release 5.1.0 Features
Certifications
-
The DB2 driver has been certified with DB2 V10.1 for Linux/UNIX/Windows.
-
The DB2 driver has been certified with DB2 pureScale.
-
The Salesforce driver has been certified with Salesforce API Version 26.
-
The SQL Server driver has been certified with Microsoft SQL Server 2012.
-
The SQL Server driver has been certified Microsoft Windows Azure SQL Database.
Oracle Driver
Support for the Oracle Advanced Security (OAS) data encryption and data integrity feature, including support for the following new connection properties:
-
DataIntegrityLevel sets the level of OAS data integrity used for data sent between the driver and database server.
-
DataIntegrityTypes specifies one or multiple algorithms to protect against attacks that intercept and modify data being transmitted between the client and server when OAS data integrity is enabled using the DataIntegrityLevel property.
-
EncryptionLevel determines whether data is encrypted and decrypted when transmitted over the network between the driver and database server using OAS encryption.
-
EncryptionTypes specifies one or multiple algorithms to use if OAS encryption is enabled using the EncryptionLevel property.
Salesforce Driver
-
The new KeywordConflictSuffix keyword=value pair for the ConfigOptions property allows you to specify a string that the driver appends to any object or field name that conflicts with a SQL engine keyword. For example, if you specify KeywordConflictSuffix=TAB, the driver maps the Case object in Salesforce to CASETAB.
-
The new RefreshSchema connection property specifies whether the driver automatically refreshes the remote object mapping and other information contained in a remote schema the first time a user connects to an embedded database.
Installation/Uninstallation
Installing
A complete installation of both DataDirect Connect for JDBC and DataDirect Connect XE for JDBC requires approximately 67 MB of hard disk space.
Java SE 5 or higher is required to use DataDirect Connect Series for JDBC. Standard installations of Java SE on some platforms do not include the jar file containing the extended encoding set that is required to support some of the less common database code pages. To verify whether your Java SE version provides extended code page support, make sure that the charsets.jar file is installed in the \lib subdirectory of your Java SE installation directory. If you do not have the charsets.jar file, install the international version of Java SE.
The installer accepts multiple product license keys. For details, refer to the DATADIRECT CONNECT SERIES FOR JDBC INSTALLATION GUIDE.
Uninstalling on Windows
When you connect with the Salesforce driver, the driver creates multiple local Salesforce files in the <install_dir>\testforjdbc subdirectory, where <install_dir> is your product installation directory. If you connect using the default Salesforce driver URL jdbc:datadirect:sforce://login.salesforce.com, the names of these files are associated with your user name. For example, if your user name is test01@xyz.com, the local Salesforce files that are created would be:
<install_dir>\testforjdbc\ddsforce.log <install_dir>\testforjdbc\test01.app.log <install_dir>\testforjdbc\test01.config <install_dir>\testforjdbc\test01.log <install_dir>\testforjdbc\test01.properties <install_dir>\testforjdbc\test01.SFORCE.map <install_dir>\testforjdbc\test01.SFORCE.native
When you run the Windows uninstaller, these files are not removed. You can explicitly delete them.
Available DataDirect Connect(R) Series for JDBC Drivers
See http://www.datadirect.com/products/jdbc/matrix/jdbcpublic.htm for a complete list of supported databases/sources.
DataDirect Connect for JDBC Drivers
DB2 (db2.jar) Informix (informix.jar) MySQL (mysql.jar) Oracle (oracle.jar) PostgreSQL (postgresql.jar) Progress OpenEdge (openedgewp.jar) SQL Server (sqlserver.jar) Sybase (sybase.jar)
DataDirect Connect XE for JDBC Drivers
Apache Hive (hive.jar) Greenplum (greenplum.jar) Salesforce (sforce.jar)
Notes, Known Problems, and Restrictions
The following are notes, known problems, or restrictions with Release 5.1.4 of DataDirect Connect Series for JDBC.
Salesforce JVM Modification
Salesforce has replaced their HTTPS certificates signed with SHA-1 with HTTPS certificates signed with the SHA-256 hash algorithm. As a result, if you are using JRE 1.6.0_18 or earlier, the connection may fail and the driver may throw an SSLHandshakeException. To avoid this issue, you must modify your JVM in one of the following ways:
-
Upgrade your JRE to version 1.6.0_19 or higher.
-
Import the "VeriSign Class 3 Public Primary Certification Authority - G5" root certificate into the lib/security/cacerts file using Java''s keytool: keytool -import -keystore ../lib/security/cacerts -file "VeriSign-Class 3-Public-Primary-Certification-Authority-G5.pem" -alias vsignc3g5 -storepass changeit
For further information, see Salesforce Article 000206493 "HTTPS Security Certificate Change from SHA-1 to SHA-256 hash algorithms."
Statement Pooling
Added the RegisterStatementPoolMonitorMBean connection property. Note that the driver no longer registers the Statement Pool Monitor as a JMX MBean by default. Here is the description of RegisterStatementPoolMonitorMBean:
- Registers the Statement Pool Monitor as a JMX MBean when statement pooling has been enabled with MaxPooledStatements. This allows you to manage statement pooling with standard JMX API calls and to use JMX-compliant tools, such as JConsole.
- Valid Values are true | false
- If set to true, the driver registers an MBean for the Statement Pool Monitor for each statement pool. This gives applications access to the Statement Pool Monitor through JMX when statement pooling is enabled.
- If set to false, the driver does not register an MBean for the Statement Pool Monitor for any statement pool.
- Registering the MBean exports a reference to the Statement Pool Monitor. The exported reference can prevent garbage collection on connections if the connections are not properly closed. When garbage collection does not take place on these connections, out of memory errors can occur.
- The default is false.
- The data type is boolean.
DB2 for Linux, UNIX, Windows Stored Procedure Cursor Type OUT Parameters
Support for cursor type OUT parameters for DB2 for Linux, UNIX, Windows stored procedures has been added to the driver. To retrieve data from cursor output parameters with the driver, take the following steps:
- Define a ResultSet object for each OUT parameter with the cursor data type.
- Invoke the Connection.prepareCall method with the CALL statement as its argument to create a CallableStatement object.
- Invoke the CallableStatement.registerOutParameter method to register the data types of parameters that are defined as OUT in the CREATE PROCEDURE statement. The driver data type for cursor type output parameters is com.ddtek.jdbc.extensions.ExtTypes.CURSOR.
- Call the stored procedure.
- Invoke the CallableStatement.getObject method to retrieve the ResultSet for each OUT cursor parameter. Calling CallableStatement.getString returns a name that is associated with the result set that is returned for the parameter. You can call only CallableStatement.getObject or CallableStatement.getString on a cursor parameter.
- Retrieve rows from the ResultSet object for each OUT cursor parameter.
- Close the ResultSet.
Oracle LOBPrefetchSize Connection Property
The LOBPrefetchSize connection property has been added to the driver and is supported for Oracle database versions 12.1.0.1 and higher.
- LOBPrefetchSize specifies the size of prefetch data the driver returns for BLOBs and CLOBs.
- Valid Values are -1 | 0 | <x> where <x> is a positive integer that represents the size of a BLOB in bytes or the size of a CLOB in characters.
- If set to -1, the property is disabled.
- If set to 0, the driver returns only LOB meta-data such as LOB length and chunk size with the LOB locator during a fetch operation.
- If set to <x>, the driver returns LOB meta-data and the beginning of LOB data with the LOB locator during a fetch operation. This can have significant performance impact, especially for small LOBs which can potentially be entirely prefetched, because the data is available without having to go through the LOB protocol.
- The default is 4000.
- The data type is int.
Using the XMLType Data Type with the Oracle Driver
The default XML storage type was changed from CLOB to BINARY in Oracle 11.2.0.2. For Oracle 11.2.0.1 and earlier database versions, the driver fully supports the XML storage type with CLOB. For Oracle 12c and later, you can enable the driver to support XML storage with BINARY by setting the SupportBinaryXML connection property to true.
For database versions that fall between Oracle 11.2.0.1 and 12c, columns created simply as "XMLType" are not supported by the driver. An attempt to obtain the value of such a column through the driver results in the exception "This column type is not currently supported by this driver." To avoid this exception, change the XML storage type to CHARACTER (CLOB) or use the TO_CLOB Oracle function to cast the column.
Using Kerberos Authentication with DB2 V10.5 for Linux, UNIX, and Windows
The DB2 driver cannot authenticate with Keberos due to the behavior of the DB2 V10.5 for Linux, UNIX, and Windows server. The issue has been opened with IBM: PMR 06453,756,000.
Stored Procedures and Updates/Deletes for Pivotal HAWQ 1.1
The Greenplum driver does not support stored procedures and updates/deletes for Pivotal HAWQ 1.1.
Oracle 12c Server Issues
The following issues were discovered during certification with Oracle 12c.
-
Kerberos cannot be configured successfully with Oracle 12c. This server issue has been reported to Oracle. Oracle has acknowledged the defect: Bug 17497520 - KERBEROS CONNECTIONS USING A 12C CLIENT AND THE OKINIT REQUESTED TGT ARE FAILING.
-
When using the DataIntegrity (checksums) Oracle Advanced Security feature with Oracle 12c, the server may unexpectedly drop the connection with the driver. This server issue has been reported to Oracle: SR 3-7971196511.
-
The newPassword connection property is only supported when connecting to an Oracle server earlier than Oracle 12c. If the newPassword connection property is specified when attempting to connect to an Oracle 12c server, the driver throws a “No Matching Authentication Protocol” exception.
Using Bulk Load with PosgreSQL and Greenplum
If the driver throws the error "The specified connection object is not valid for creation of a bulk load object" while you are attempting to use the DataDirect Bulk Load API, ensure that postgresql.jar (or greenplum.jar) is listed before any other DataDirect drivers on your classpath.
JAXB API for Salesforce with Java SE 6
The Salesforce driver uses the Java Architecture for XML Binding (JAXB) 2.2 API. Some older versions of Java SE 6 use a version of the JAXB API that is incompatible with that used by the Salesforce driver. If you receive the following exception, update your JVM to the latest version:
JAXB 2.1 API is being loaded from the bootstrap classloader, but this RI (from <driver location>) needs 2.2 API.
If for some reason updating to the latest version is not possible, you can override the JAXB jar file in your JVM with a compatible JAXB jar file. You can download the latest JAXB API jar file from http://jaxb.java.net.
You can override the JAXB jar file in your JVM using either of the following methods:
-
Copy the downloaded JAXB jar file to the endorsed directory as described in http://docs.oracle.com/javase/6/docs/technotes/guides/standards/index.html.
-
Add the downloaded JAXB jar file to the boot classpath when launching your application using the JVM argument:
-Xbootclasspath/p:<jaxb_jar_file>
where jaxb_jar_file is the path and filename of the JAXB jar file you downloaded.
For example, if the following command is used to launch your application:
java MyApp arg1 arg2
You can modify that command to:
Windows Example:
java -Xbootclasspath/p:C:\jaxb\jaxb-api-2.2.3.jar MyApp arg1 arg2
UNIX/Linux Example:
java -Xbootclasspath/p:/usr/lib/jaxb/jaxb-api-2.2.3.jar MyApp arg1 arg2
Using the SELECT...INTO Statement with the Salesforce Driver
The SELECT...INTO statement is supported for local tables only. The source and destination tables must both be local tables. Creating remote tables in Salesforce or loading from remote Salesforce tables using SELECT…INTO is not supported. Additionally, the option to create the destination table as a temporary table does not currently work.
Stored Procedures Not Supported for Database.com
The Salesforce driver incorrectly reports that it supports stored procedures for Database.com (for example, using DatabaseMetadata.supportsStoredProcedures()). Stored procedures for Database.com are not supported.
Using Bulk Load with Oracle
For the best performance when using the bulk load protocol against Oracle, an application can specify "enableBulkLoad=true" and perform its batches of parameterized inserts within a manual transaction. Using the bulk load protocol can impact the behavior of the driver. The application should do nothing else within the transaction. If another operation is performed BEFORE the inserts, the driver is unable to use the bulk load protocol and will choose a different approach. If some other "execute" is performed AFTER the inserts, the driver throws the following exception:
An execute operation is not allowed at this time, due to unfinished bulk loads. Please perform a "commit" or "rollback".
Using Bulk Load with Microsoft SQL Server 2000 and Higher
For optimal performance, minimal logging and table locking must be enabled. Refer to the following Web sites for more information about enabling minimal logging:
http://msdn.microsoft.com/en-us/library/ms190422.aspx http://msdn.microsoft.com/en-us/library/ms190203.aspx
Table locking, a bulk load option, is enabled by default. Table locking prevents other transactions from accessing the table you are loading to during the bulk load. See the description of the BulkLoadOptions connection property in the DATADIRECT CONNECT FOR JDBC USER''S GUIDE for information about enabling and disabling bulk load options.
Starting the Performance Tuning Wizard
-
When starting the Performance Tuning Wizard, security features set in your browser can prevent the Performance Wizard from launching. A security warning message is displayed. Often, the warning message provides instructions for unblocking the Performance Wizard for the current session. To allow the Performance Wizard to launch without encountering a security warning message, the security settings in your browser can be modified. Check with your system administrator before disabling any security features.
-
The Performance Wizard does not automatically launch from the installer when the installer is run on the Macintosh operating system. You can start the Performance Wizard by executing the install_dir/wizards/index.html file.
Executing Scripts (for UNIX Users)
If you receive an error message when executing any DataDirect Connect for JDBC shell script, make sure that the file has EXECUTE permission. To do this, use the chmod command. For example, to grant EXECUTE permission to the testforjdbc.sh file, change to the directory containing testforjdbc.sh and enter:
chmod +x testforjdbc.sh
Distributed Transactions Using JTA
If you are using JTA for distributed transactions, you may encounter problems when performing certain operations, as shown in the following examples:
SQL SERVER 7
- Problem: SQL Server 7 does not allow resource sharing because it cannot release the connection to a transaction until it commits or rolls back.
xaResource.start(xid1, TMNOFLAGS) ... xaResource.end(xid1, TMSUCCESS) xaResource.start(xid2, TMNOFLAGS) ---> fail
- Problem: Table2 insert rolls back. It should not roll back because it is outside of the transaction scope.
xaResource.start(xid1, TMNOFLAGS) stmt.executeUpdate("insert into table1 values (1)"); xaResource.end(xid1, TMSUCCESS)
stmt.executeUpdate("insert into table2 values (2)");
xaResource.prepare(xid1); xaResource.rollback(xid1);
SQL SERVER 7 and SQL SERVER 2000
- Problem: Recover should not return xid1 because it is not yet prepared.
xaResource.start(xid1, TMNOFLAGS) xaResource.recover(TMSTARTRSCAN) ---> returns xid1 transaction
This problem has been resolved in DTC patch QFE28, fix number winse#47009, "In-doubt transactions are not correct removed from the in-doubt transactions list".
This Microsoft issue is documented at http://support.microsoft.com/default.aspx?scid=kb;en-us;828748.
All Drivers
-
The DataDirect Connect Series for JDBC drivers allow PreparedStatement.setXXX methods and ResultSet.getXXX methods on Blob/Clob data types, in addition to the functionality described in the JDBC specification. The supported conversions typically are the same as those for LONGVARBINARY/LONGVARCHAR, except where limited by database support.
-
Calling CallableStatement.registerOutputParameter(parameterIndex, sqlType) with sqlType Types.NUMERIC or Types.DECIMAL sets the scale of the output parameter to zero (0). According to the JDBC specification, calling CallableStatement.registerOutputParameter(parameterIndex, sqlType, scale) is the recommended method for registering NUMERIC or DECIMAL output parameters.
-
When attempting to create an updatable, scroll-sensitive result set for a query that contains an expression as one of the columns, the driver cannot satisfy the scroll-sensitive request. The driver downgrades the type of the result returned to scroll-insensitive.
-
The DataDirect Connect Series for JDBC drivers support retrieval of output parameters from a stored procedure before all result sets and/or update counts have been completely processed. When CallableStatement.getXXX is called, result sets and update counts that have not yet been processed by the application are discarded to make the output parameter data available. Warnings are generated when results are discarded.
-
The preferred method for executing a stored procedure that generates result sets and update counts is using CallableStatement.execute(). If multiple results are generated using executeUpdate, the first update count is returned. Any result sets prior to the first update count are discarded. If multiple results are generated using executeQuery, the first result set is returned. Any update counts prior to the first result set are discarded. Warnings are generated when result sets or update counts are discarded.
-
The ResultSet methods getTimestamp(), getDate(), and getTime() return references to mutable objects. If the object reference returned from any of these methods is modified, re-fetching the column using the same method returns the modified value. The value is only modified in memory; the database value is not modified.
Driver for Apache Hive
The following are notes, known problems, and restrictions with the driver. These restrictions are based on using Apache Hive 0.9; other versions of Apache Hive will have their own restrictions. You may find a more complete listing of Apache Hive known issues and limitations for your version of Apache Hive in the Apache Hive user documentation here: https://cwiki.apache.org/confluence/display/Hive/Home
-
OLTP Workloads
- Note that Apache Hive is not designed for OLTP workloads and does not offer real-time queries or row-level updates. Apache Hive is instead designed for batch type jobs over large data sets with high latency.
-
Known Issues for Apache Hive
- No support for row-level updates or deletes
- No difference exists between "NULL" and null values
- For HiveServer1 connections, no support for user-level authentication
- For HiveServer1 connections, no support for canceling a running query
- For HiveServer1 connections, no support for multiple simultaneous connections per port
-
HiveQL
- Apache Hive uses HiveQL, which provides much of the functionality of SQL, but has some limitation syntax differences. For more information, refer to the Hive Language Manual at https://cwiki.apache.org/confluence/display/Hive/LanguageManual.
- A single quote within a string literal must be escaped using a \ instead of using a single quote.
- Numeric values specified in scientific notation are not supported in Hive 0.8.0.
- Apache Hive supports UNION ALL statements only when embedded in a subquery. For example: SELECT * FROM (SELECT integercol FROM itable UNION ALL SELECT integercol FROM gtable2) result_table
- Subqueries are supported, but they can only exist in the From clause.
- Join support is limited to equi-joins.
- Apache Hive uses HiveQL, which provides much of the functionality of SQL, but has some limitation syntax differences. For more information, refer to the Hive Language Manual at https://cwiki.apache.org/confluence/display/Hive/LanguageManual.
-
Transactions
- Apache Hive does not support transactions, and by default, the Driver for Apache Hive reports that transactions are not supported. However, some applications will not operate with a driver that reports transactions are not supported. The TransactionMode connection property allows you to configure the driver to report that it supports transactions. In this mode, the driver ignores requests to enter manual commit mode, start a transaction, or commit a transaction and return success. Requests to rollback a transaction return an error regardless of the transaction mode specified.
DB2 Driver
-
Unlike previous versions of the DB2 driver, the 5.1.0 version of the driver does not buffer the input stream if a parameter is a BLOB, CLOB, or DBCLOB type.
-
The ResultSetMetaData.getObject method returns a Long object instead of a BigDecimal object when called on BIGINT columns. In versions previous to DataDirect Connect Series for JDBC 3.5, the DataDirect Connect for JDBC DB2 driver returned a BigDecimal object.
-
Scroll-sensitive result sets are not supported. Requests for scroll-sensitive result sets are downgraded to scroll-insensitive result sets when possible. When this happens, a warning is generated.
-
The DB2 driver must be able to determine the data type of the column or stored procedure argument to implicitly convert the parameter value. Not all DB2 database versions support getting parameter metadata for prepared statements. Implicit conversions are not supported for database versions that do not provide parameter metadata for prepared statements.
Oracle Driver
-
For database versions prior to Oracle 12c, the newPassword connection property is supported only when connecting to servers for which the ALLOWED_LOGON_VERSION parameter is either not specified or is specified with a value of 8. If the newPassword connection property is specified when attempting to connect to an Oracle server for which the ALLOWED_LOGON_VERSION parameter is specified with a value greater than 8, the driver throws a “No Matching Authentication Protocol” exception. The newPassword connection property is not supported for Oracle 12c.
-
When connecting to Oracle instances running in restricted mode using a tnsnames.ora file, you must connect using a service name instead of a SID.
-
If using Select failover and a result set contains LOBs, the driver cannot recover work in progress for the last Select statement for that result set. You must explicitly restart the Select statement if a failover occurs. The driver will successfully recover work in progress for any result sets that do not contain LOBs.
-
If you install the Oracle driver and want to take advantage of JDBC distributed transactions through JTA, you must install Oracle8i R3 (8.1.7) or higher.
-
Because JDBC does not support a cursor data type, the Oracle driver returns REF CURSOR output parameters to the application as result sets. For details about using REF CURSOR output parameters with the driver, refer to the DATADIRECT CONNECT SERIES FOR JDBC USER''S GUIDE.
-
By default, values for TIMESTAMP WITH TIME ZONE columns cannot be retrieved using the ResultSet.getTimestamp() method because the time zone information is lost. The Oracle driver returns NULL when the getTimestamp() method is called on a TIMESTAMP WITH TIME ZONE column and generates an exception. For details about using the TIMESTAMP WITH TIME ZONE data type with the driver, refer to the DATADIRECT CONNECT SERIES FOR JDBC USER''S GUIDE.
-
The Oracle driver describes columns defined as FLOAT or FLOAT(n) as a DOUBLE SQL type. Previous to DataDirect Connect Series for JDBC 3.5, the driver described these columns as a FLOAT SQL type. Both the DOUBLE type and the FLOAT type represent a double precision floating point number. This change provides consistent functionality with the DataDirect Connect Series for ODBC Oracle driver. The TYPE_NAME field that describes the type name on the Oracle database server was changed from number to float to better describe how the column was created.
SQL Server Driver
-
Microsoft SQL Server 7 and SQL Server 2000 Only: Although the SQL Server driver fully supports the auto-generated keys feature as described in the Microsoft SQL Server chapter of the DATADIRECT CONNECT FOR JDBC USER''S GUIDE, some third-party products provide an implementation that, regardless of the column name specified, cause the driver to return the value of the identity column for the following methods:
Connection.prepareStatement(String sql, int[] columnIndexes) Connection.prepareStatement(String sql, String[] columnNames)
Statement.execute(String sql, int[] columnIndexes) Statement.execute(String sql, String[] columnNames)
Statement.executeUpdate(String sql, int[] columnIndexes) Statement.executeUpdate(String sql, String[] columnNames)
To workaround this problem, set the WorkArounds connection property to 1. When Workarounds=1, calling any of the auto-generated keys methods listed above returns the value of the identity column regardless of the name or index of the column specified to the method. If multiple names or indexes are specified, the driver throws an exception indicating that multiple column names or indexes cannot be specified if connected to Microsoft SQL Server 7 or SQL Server 2000.
-
In some cases, when using Kerberos authentication, Windows XP and Windows Server 2003 clients appear to use NTLM instead of Kerberos to authenticate the user with the domain controller. In these cases, user credentials are not stored in the local ticket cache and cannot be obtained by the SQL Server driver, causing the Windows Authentication login to fail. This is caused by a known problem in the Sun 1.4.x JVM. As a workaround, the "os.name" system property can be set to "Windows 2000" when running on a Windows XP or Windows Server 2003 machine. For example:
Dos.name="Windows 2000"
-
To ensure correct handling of character parameters, install Microsoft SQL Server 7 Service Pack 2 or higher.
-
Because of the way CHAR, VARCHAR, and LONGVARCHAR data types are handled internally by the driver, parameters of these data types exceeding 4000 characters in length cannot be compared or sorted, except when using the IS NULL or LIKE operators.
Help System Compatibility
-
When viewing the installed help system, please note that Google Chrome version 45 is not yet fully supported. When using Google Chrome 45, the table of contents does not synchronize with the pages when using the Next and Previous buttons to page through the help system, and the Next and Previous buttons appear inactive. To avoid this issue, you can view the installed help with a certified browser or use the online version of the help: http://media.datadirect.com/download/docs/jdbc/alljdbc/help.html
The certified web browsers and versions for using this help system are:
- Google Chrome 44.x and earlier
- Internet Explorer 7.x, 8.x, 9.x, 10.x, 11.x
- Firefox 3.x - 39.x
- Safari 5.x
-
Internet Explorer with the Google Toolbar installed sometimes displays the following error when the browser is closed: "An error has occurred in the script on this page." This is a known issue with the Google Toolbar and has been reported to Google. When closing the driver''s help system, this error may display.
Documentation Errata for DATADIRECT CONNECT SERIES FOR JDBC USER''S GUIDE
-
The OpenEdge driver chapter incorrectly indicates support for auto-generated keys. The OpenEdge driver does not in fact support auto-generated keys.
-
In the Salesforce driver chapter, the "ConfigOptions" topic incorrectly states that the default for the AuditColumns configuration option is All. The default for AuditColumns is None (the driver does not add the audit columns or the MasterRecordId column in its table definitions).
-
The "BulkLoadOptions" topic in the Oracle driver chapter incorrectly indicates that None is the default setting for the BulkLoadOptions connection property. The default is 0 (the bulk load operation continues even if a value that can cause an index to be invalidated is loaded).
Documentation Errata for DATADIRECT CONNECT SERIES FOR JDBC REFERENCE
-
The "DataDirect Spy Attributes" topic incorrectly identifies "loglob" as the attribute for specifying whether DataDirect Spy logs activity on BLOB and CLOB objects. The correct attribue name is "logLobs".
Using the Documents
The DataDirect Connect Series for JDBC guides are provided in PDF and HTML.
The HTML help system is installed in the help subdirectory of your product installation directory.
The PDF and HTML versions of the guides, including the HTML help system, are available on: http://www.progress.com/resources/documentation
You can view the PDF versions using Adobe Reader. To download Adobe Reader, visit the Adobe Web site: http://www.adobe.com.
DataDirect Connect Series for JDBC Files
When you extract the contents of the installation download package to your installer directory, you will notice the following files that are required to install DataDirect Connect Series for JDBC:
Windows: PROGRESS_DATADIRECT_CONNECT_JDBC_5.1.4_WIN.zip Non-Windows: PROGRESS_DATADIRECT_CONNECT_JDBC_5_1_4.jar
When you install DataDirect Connect Series for JDBC, the installer creates the following directories and files in the product installation directory (as determined by the user), represented by INSTALL_DIR.
INSTALL_DIR:
BrandingTool.jar Standalone branding tool (OEM installs only)
BuildAdapters.jar File used to create resource adapters
DDProcInfo.exe Windows executable to start the Processor Information Utility
DDProcInfo UNIX/Linux script to start the Processor Information Utility
fixes.txt File describing fixes
jdbcreadme.txt This file
LicenseTool.jar File required to extend an evaluation installation
NOTICES.txt Third-Party vendor license agreements
INSTALL_DIR/DB2/bind:
iSeries/. Files for explicitly creating DB2 packages on DB2 for i
LUW/. Files for explicitly creating DB2 packages on Linux/UNIX/Windows
zOS/. Files for explicitly creating DB2 packages on z/OS
INSTALL_DIR/Examples/bulk:
Load From File/bulkLoadFileDemo.java Java source example for bulk loading from a CSV file
Load From File/load.txt Sample data for the example
Streaming/bulkLoadStreamingDemo.java Java source example for bulk loading from a result set
Threaded Streaming/bulkLoadThreadedStreamingDemo.java Java source example for multi-threaded bulk loading from a result set
Threaded Streaming/README.txt Instructions on how to use the thread.properties file
Threaded Streaming/thread.properties Properties file for the example
INSTALL_DIR/Examples/connector:
ConnectorSample.ear J2EE Application Enterprise Archive file containing the ConnectorSample application
connectorsample.htm "Using DataDirect Connect for JDBC Resource Adapters" document
graphics/. Images referenced by the "Using DataDirect Connect for JDBC Resource Adapters" document
src/ConnectorSample.jsp Source for the JavaServer Page used to access the ConnectorSample application
src/connectorsample/ConnectorSample.java
Java source file defining the remote interface for the ConnectorSample EJB
src/connectorsample/ConnectorSampleBean.java
Java source file defining the home interface for the ConnectorSample EJB
src/connectorsample/ConnectorSampleHome.java
Java source file containing the implementation for the ConnectorSample EJB
INSTALL_DIR/Examples/JNDI:
JNDI_FILESYSTEM_Example.java Example Java(TM) source file
JNDI_LDAP_Example.java Example Java source file
INSTALL_DIR/Examples/SforceSamples:
buildsamples.bat Batch file to build the Salesforce example
buildsamples.sh Shell script to build the Salesforce example
ddlogging.properties Logging properties file
runsalesforceconnectsample.bat Batch file to run the Salesforce example
runsalesforceconnectsample.sh Shell script to run the Salesforce example
bin/com/ddtek/jdbc/samples/SalesforceConnectSample.class Java example class
bin/com/ddtek/jdbc/samples/SampleException.class Java example class
src/com/ddtek/jdbc/samples/SalesforceConnectSample.java Java source example
INSTALL_DIR/Help:
index.html HTML help system entry file /* Support files and folders for the HTML help system
INSTALL_DIR/lib:
db2.jar DB2 Driver and DataSource classes
db2.rar DB2 resource archive file
greenplum.jar Greenplum Driver and DataSource classes
hive.jar Driver for Apache Hive and DataSource classes
informix.jar Informix Driver and DataSource classes
informix.rar Informix resource archive file
mysql.jar MySQL Driver and DataSource classes
mysql.rar MySQL resource archive file
openedgewp.jar Progress OpenEdge Driver and DataSource classes
oracle.jar Oracle Driver and DataSource classes
oracle.rar Oracle resource archive file
postgresql.jar PostgreSQL Driver and DataSource classes
sforce.jar Salesforce Driver and DataSource classes
sqlserver.jar SQL Server Driver and DataSource classes
sqlserver.rar SQL Server resource archive file
sybase.jar Sybase Driver and DataSource classes
sybase.rar Sybase resource archive file
db2packagemanager.jar DataDirect DB2 Package Manager jar file
DDJDBCAuthxx.dll Windows DLL that provides support for NTLM authentication (32-bit), where xx is the Build number of the DLL
DDJDBC64Authxx.dll Windows DLL that provides support for NTLM authentication (Itanium 64-bit), where xx is the Build number of the DLL
DDJDBCx64Authxx.dll Windows DLL that provides support for NTLM authentication (AMD64 and Intel EM64T 64-bit), where xx is the Build number of the DLL
DB2PackageManager.bat Batch file to start the DataDirect DB2 Package Manager
DB2PackageManager.sh Shell script to start the DataDirect DB2 Package Manager
JDBCDriver.policy Security policy file listing permissions that must be granted to the driver to use Kerberos authentication with a Security Manager
JDBCDriverLogin.conf Configuration file that instructs the driver to use the Kerberos login module for authentication
krb5.conf Kerberos configuration file
INSTALL_DIR/lib/JCA/META-INF:
db2.xml DB2 resource adapter deployment descriptor
informix.xml Informix resource adapter deployment descriptor
mysql.xml MySQL resource adapter deployment descriptor
oracle.xml Oracle resource adapter deployment descriptor
sqlserver.xml SQL Server resource adapter deployment descriptor
sybase.xml Sybase resource adapter deployment descriptor
MANIFEST.MF Manifest file
INSTALL_DIR/pool manager:
pool.jar All DataDirect Connection Pool Manager classes
INSTALL_DIR/SQLServer JTA/32-bit:
instjdbc.sql File for installing JTA stored procedures
sqljdbc.dll File for use with JTA stored procedures (32-bit version)
INSTALL_DIR/SQLServer JTA/64-bit:
instjdbc.sql File for installing JTA stored procedures
sqljdbc.dll File for use with JTA stored procedures (Itanium 64-bit version)
INSTALL_DIR/SQLServer JTA/x64-bit:
instjdbc.sql File for installing JTA stored procedures
sqljdbc.dll File for use with JTA stored Procedures (AMD64 and Intel EM64T 64-bit version)
INSTALL_DIR/testforjdbc:
Config.txt Configuration file for DataDirect Test
ddlogging.properties Logging properties file
testforjdbc.bat Batch file to start DataDirect Test
testforjdbc.sh Shell script to start DataDirect Test
lib/testforjdbc.jar DataDirect Test classes
INSTALL_DIR/UninstallerData:
resource/. Resource files for the Windows
uninstaller
.com.zerog.registry.xml Support file for the uninstaller
InstallScript.iap_xml Support file for the uninstaller
installvariables.properties Support file for the Windows uninstaller
Uninstall Progress DataDirect Connect (R) and Connect XE for JDBC 5.1 SP4.exe Windows uninstaller
Uninstall Progress DataDirect Connect (R) and Connect XE for JDBC 5.1 SP4.lax Support file for the Windows uninstaller
uninstaller.jar Java uninstaller
INSTALL_DIR/UninstallerData/Logs:
Progress_DataDirect_Connect_(R)_for_JDBC_5.1_SP4_InstallLog.log Log file created by the Windows installer
INSTALL_DIR/wizards:
index.html HTML file to launch the Performance Tuning Wizard applet
JDBCPerf.jar Jar file containing the classes for the Performance Tuning Wizard applet
images/. Graphic files used by the Performance Tuning Wizard applet
Third Party Acknowledgements
One or more products in the Progress DataDirect Connect for JDBC v5.1.4 and Progress DataDirect Connect XE for JDBC v5.1.4 releases include third party components covered by licenses that require that the following documentation notices be provided. If changes in third party components occurred for the current release of the Product, the following Third Party Acknowledgements may contain notice updates to any earlier versions provided in documentation or README file.
Progress DataDirect Connect for JDBC v5.1.4 and Progress DataDirect Connect XE for JDBC v5.1.4 incorporate HyperSQL database v1.8.0.10 from The HSQL Development Group. Such technology is subject to the following terms and conditions: Copyright (c) 2001-2005, The HSQL Development Group All rights reserved. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. Neither the name of the HSQL Development Group nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission. THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL HSQL DEVELOPMENT GROUP, HSQLDB.ORG, OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
9 December 2015
End of README

ADBPG&Greenplum成本优化之磁盘水位管理
简介:本文我们将通过一个实际的磁盘空间优化案例来说明,如何帮助客户做成本优化。

一 背景描述
目前,企业的核心数据一般都以二维表的方式存储在数据库中。在核心技术自主可控的大环境下,政企行业客户都在纷纷尝试使用国产数据库或开源数据库,尤其在数据仓库OLAP领域的步伐更快,Greenplum的应用越来越广泛,阿里云ADB PG的市场机会也越来越多。另外,随着近年来数据中台的价值被广泛认可,企业建设数据中台的需求也非常迫切,数据中台的很多场景都会用到Greenplum或ADB PG。因此,今年阿里云使用ADB PG帮助很多客户升级了核心数仓。我们发现,客户往往比较关注使用云原生数仓的成本。究竟如何帮助客户节约成本,便值得我们去探索和落地。
ADB PG全称云原生数据仓库AnalyticDB PostgreSQL版,它是一款大规模并行处理(MPP)架构的数据库,是阿里云基于开源Greenplum优化后的云原生数据仓库,因此本文探讨的成本优化方法也适用于Greenplum开源版。图1是ADB PG的架构示意图(Greenplum亦如此),Master负责接受连接请求,SQL解析、优化、事务等处理,并分发任务到Segment执行;并协调每一个Segment返回的结果以及把最终结果呈现给客户端程序。Segment是一个独立的PostgreSQL数据库,负责业务数据的存储和计算,每个Segment位于不同的独立物理机上,存储业务数据的不同部分,多个Segment组成计算集群;集群支持横向扩展。从架构上很清楚,节约Greenplum的成本,最重要的是要尽可能节约Segment的服务器数,但既要保证整体MPP的算力,也要能满足数据对存储空间的需求。通常,数据仓库中的数据是从企业各个领域的上游生产系统同步而来,这些数据在分析领域有生命周期,很多数据需要反应历史变化,因此数据仓库中数据的特点是来源多、历史数据多、数据量比较大。数据量大,必然消耗存储空间,在MPP架构下就是消耗服务器成本。帮客户优化成本,节约存储空间是首当其冲的。
图1:ADB PG的架构示意图

下面,我们将通过一个实际的磁盘空间优化案例来说明,如何帮助客户做成本优化。
二 ADB PG & Greenplum的磁盘管理简介
1 ADB PG磁盘管理的关键技术点
ADB PG是基于Greenplum(简称“GP”)内核修改的MPP数据库,对于磁盘空间管理来讲,有几个技术点与Greenplum是通用的:
(1)业务数据主要分布在Segment节点;
(2)Segment有Primary和Mirror节点,因此,业务可用空间是服务器总空间的1/2;
(3)Greenplum的MVCC机制,导致表数据发生DML后产生垃圾数据dead tuples;
(4)复制表(全分布表)会在每个Segment上存储相同的数据拷贝;分布表会根据分布键打散存储数据到各个Segment。
(5)Greenplum有Append Only类型的表,支持压缩存储,可以节约空间;当然用户访问时,解压缩需要时间,所以需要在性能和空间之间取得平衡。
云原生数据库的特点是不再单独提供数据库存储和计算的内核,也会配套运维管理平台,简称“数据库管控”。搞清楚ADB PG磁盘管理原理后,我们需要了解数据库管控在磁盘水位管理方面的设计。
2 数据库管控的磁盘预留机制
我们看下某数仓实验环境的各个Segment节点的磁盘占用示意图。
图2:Segment维度的磁盘占用示意图

上图第一个百分比是Segment所在物理机的磁盘使用百分比;第二个百分比是数据库管控的磁盘使用百分比。管控的数据为啥要跟服务器实际占用不一致呢?其实就是水位管理中第一个很重要的预防性措施:空间预留。即,ADB的管控在创建Segment实例时,根据服务器的空间,进行了一定的预留,占比大概是12%,即20T的服务器,管控认为业务最大可用17.6T,这个逻辑会通知监控系统。所以计算磁盘占比时,监控系统的分母不是20T,而是17.6T。这是第一级保护措施。
预留空间,还有重要的一点原因是数据库本身有WAL事务日志、错误日志等也占用空间。因此,磁盘的空间有一部分需要给日志使用,客户的业务数据无法使用100%的服务器空间,这就是为何图2中,会显示两个空间百分比的原因。
3 数据库管控的“锁定写” 保护机制
第二级保护措施是“磁盘满锁定写”。在17.6T的基础上,管控并不让业务完全写满,写满容易造成数据文件损坏,带来数据库宕机及无法恢复的灾难。因此,这里有第二个阈值,即当磁盘写到90%时,数据库管控的自动巡检任务会启动“锁定写”的操作,此时所有请求ADB的DML都会失败。这是一个重要的保护机制。如下图3所示,如果达到阈值,会提示“need to lock”。 阈值可以配置,如果磁盘空间紧张,可以根据实际情况适当调大阈值。
图3:数据库管控的自动化锁盘日志示例

以上数据库管控的两个机制可以有效保障磁盘在安全水位下运行。这些设计,是我们做成本优化的基础,磁盘的成本优化意味着服务器的磁盘尽可能物尽其用。节约磁盘空间,就必须要在相对较高的磁盘水位运行(这里是指数据量确实很大的情况),因此,磁盘有效管理,及时的问题监控发现的机制非常重要。
三 磁盘空间优化方案
下面我们以某客户的案例来说明磁盘空间优化方法。该客户数据仓库中的数据(含索引)大于1.5PB,但客户一期为ADB数仓采购了40台机器,约800T总容量。客户明确要求阿里云需要配合业务方做好数仓设计,帮其节约成本。客户把成本优化的KPI已经定好了,需要阿里云通过技术去落实。我们协同业务方在设计阶段做了一些预案,技术上主要从表压缩和冷热数据分离的角度去做考虑;业务上,让开发商从设计上,尽量缩减在ADB中的存量数据。最终,开发商预估大概有360T左右的热数据从旧的数仓迁移到ADB。上线前,开发商需要把必要的基础业务数据(比如贴源层,中间层),从DB2迁移到ADB PG。迁移完成,业务进行试运行期,我们发现空间几乎占满(如图2)。空间优化迫在眉睫,于是我们发起了磁盘空间优化治理。图4是磁盘空间治理优化的框架。
图4:磁盘水位优化框架

接下来,我们展开做一下说明。
1 表的存储格式及压缩
表的压缩存储可以有效保障客户节约存储空间。Greenplum支持行存、Append-only行存、Append-only列存等存储格式。若希望节约存储空间,Append-only列存表是较好的选择,它较好的支持数据压缩,可以在建表时指定压缩算法和压缩级别。合适的压缩算法和级别,可以节约数倍存储空间。建表示例语句如下:
CREATE TABLE bar (id integer, name text)
WITH(appendonly=true, orientation=column, COMPRESSTYPE=zstd, COMPRESSLEVEL=5)
DISTRIBUTED BY (id);列存表必须是Append-only类型,创建列存表时,用户可以通过指定COMPRESSTYPE字段来指定压缩的类型,如不指定则数据不会进行压缩。目前支持三种压缩类型:
zstd、zlib和lz4,zstd算法在压缩速度、解压缩度和压缩率三个维度上比较均衡,实践上推荐优先考虑采用zstd算法。zlib算法主要是为了兼容一些已有的数据,一般新建的表不采用zlib算法。lz4算法的压缩速度和压缩率不如zstd,但是解压速度明显优于zstd算法,因此对于查询性能要求严格的场景,推荐采用lz4算法。
用户可以通过指定COMPRESSLEVEL字段来决定压缩等级,数值越大压缩率越高,取值范围为1-19,具体压缩等级并不是数字越大越好,如上文所述,解压缩也消耗时间,压缩率高,则解压缩会相对更慢。因此,需要根据业务实际测试来选定,一般5-9都是有实际生产实践的压缩级别。
2 冷热数据分层存储
在大型企业的数据仓库设计中,MPP数据库(ADB属于MPP)只是其中一种数据存储,而且是偏批处理、联机查询、adHoc查询的场景使用较多;还有很多冷数据、归档数据,其实一般都会规划类似Hadoop、MaxCompute甚至OSS进行存储;另外,近年来兴起的流数据的计算和存储,需求也非常强烈,可以通过Kafka、Blink、Storm来解决。因此,当MPP数据库空间告急时,我们也可以做冷热数据分级存储的方案。ADB PG的分级存储方案,大致有两种:1是业务方自己管理冷数据和热数据;2是利用ADB PG冷热数据分层存储和转换功能。
业务方通过PXF外表访问HDFS冷数据
业务方把部分冷数据以文件的方式存到HDFS或Hive,可以在ADB创建PXF外部表进行访问;外部表不占用ADB PG的磁盘空间。PXF作为Greenplum与Hadoop集群数据交互的并行通道框架,在Greenplum中通过PXF可以并行加载和卸载Hadoop平台数据。具体使用方法如下:
(1)控制台开通PXF服务
· 登录ADB管控台,访问ADB PG实例外部表页面,点击开通新服务
图5:PXF外表服务

填写详细的Hadoop的服务信息后(涉及kerberos认证,非此文重点),PXF服务会启动,启动成功后如上图。
(2)创建PXF扩展
`-- 管理员执行
create extension pxf_fdw;`
(3)创建PXF外表
CREATE EXTERNAL TABLE pxf_hdfs_textsimple(location text, month text, num_orders int, total_sales float8)
LOCATION (''pxf://data/pxf_examples/pxf_hdfs_simple.txt?PROFILE=hdfs:text&SERVER=23'')
FORMAT ''TEXT'' (delimiter=E'','');说明:Location是hdfs源文件信息,/data/pxf_examples/pxf_hdfs_simple.txt,即业务访问的外部冷数据文件;SERVER=23指明了Hadoop外表的地址信息,其中23是集群地址信息的存放目录,在图8中可以根据PXF服务查到。
(4)访问外部表
访问外部表就和访问普通表没有区别
图6:外部表访问示例

ADB PG冷热数据分层存储方案
上面的pxf外表访问,有一个弊端,是如果冷数据(外表)要和热数据join,效率较差,原因是数据要从HDFS加载到ADB,再和ADB的表进行Join,徒增大量IO。因此,ADB PG在Greenplum的PXF外表的基础上,提供了冷热数据转换的功能,业务方可以在需要Join外表和普通表分析时,把外部表先转换为ADB的普通表数据,再做业务查询,整体方案称为冷热数据分层存储。由于都是利用PXF外表服务,3.4.1中的第1和第2步骤可以复用。额外的配置方法如下:
(1) 配置分层存储默认使用刚才的Foreign Server
用超级管理员执行
ALTER DATABASE postgres SET RDS_DEF_OPT_COLD_STORAGE TO ''server "23",resource "/cold_data", format "text",delimiter ","'';注意,这里需要将postgres替换为实际的数据库名,并将/cold_data替换为实际在HDFS上需要用来存储冷数据的路径。
(2) 重启数据库实例后执行检查
SHOW RDS_DEF_OPT_COLD_STORAGE;
验证是否配置成功。
(3) 创建测试表,并插入少量测试数据
create table t1(a serial) distributed by (a);
insert into t1 select nextval(''t1_a_seq'') from generate_series(1,100);
postgres=# select sum(a) from t1;
sum
------
5050
(1 row)此时,t1表的数据是存在ADB的本地存储中的,属于热数据。
(4) 将表数据迁移到冷存HDFS
alter table t1 set (storagepolicy=cold);
图7:转换数据为冷数据

注意这个NOTICE在当前版本中是正常的,因为在冷存上是不存在所谓分布信息的,或者说分布信息是外部存储(HDFS)决定。
(5) 验证冷数据表的使用
首先,通过查看表的定义,验证表已经迁移到冷存
图8:冷存表的定义

然后正常查询表数据;
postgres=# select sum(a) from t1;
sum
------
5050
(1 row)(6) 将数据迁回热存
alter table t1 set (storagepolicy=hot);
图9:数据迁回热存

注意:迁移回热存后,distributed信息丢失了,这是当前版本的限制。如果表有索引,则索引在迁移后会丢失,需要补建索引。以上两个方案,都能一定程度上把冷数据从ADB PG中迁移到外部存储,节约ADB PG的空间。
方案1,Join效率低,不支持冷热数据转换,但不再占用ADB的空间;
方案2,Join效率高,支持冷热数据转换,部分时间需要占用ADB的空间。
两个方案各有利弊,实际上项目中,根据业务应用来定。在该客户案例中,冷热数据分层存储方案,为整体ADB节约了数百T空间,这数百T空间中,大部分是设计阶段解决的,少部分是试运行期间进一步优化的。
3 垃圾数据vacuum
由于GP内核的MVCC管理机制,一个表的DML(t2时刻)提交后的数据元组,实际上并没有立即删除,而是一直与该表的正常元组存储在一起,被标记为dead tuples;这会导致表膨胀而占用额外空间。垃圾数据回收有两个方法:内核自动清理、SQL手动清理。自动清理的机制是:表的dead tuples累积到一定百分比,且所有查询该表的事务(t1时刻<t2时刻)都已经结束,内核会自动auto vacuum垃圾数据。这个机制,本身没有问题,但是在大库和大表场景下有一定问题,一个大表上T,数据变化10G才1%,多个大表一起变化,就会累计给整体空间带来问题,因此必须辅以手动回收。
手动回收方法
(1)统计出系统的top大表;
select *,pg_size_pretty(size) from
(select oid,relname,pg_relation_size(oid) as size from pg_class where relkind = ''r'' order by 3 desc limit 100)t;
-- limit 100表示top100(2)查询大表的dead tuple占比和空间;
-- 根据统计信息查询膨胀率大于20%的表
SELECT ((btdrelpages/btdexppages)-1)*100||''%'', b.relname FROM gp_toolkit.gp_bloat_expected_pages a
join pg_class b on a.btdrelid=b.oid
where btdrelpages/btdexppages>1.2;(3)使用pg_cron定时任务帮助业务回收垃圾数据
vacuum tablename;
或
vacuum analyze tablename;-- 先执行一个VACUUM 然后是给每个选定的表执行一个ANALYZE或
vacuum full tablename;
这里需要与业务沟通清楚执行时间,具体vacuum时,虽然不影响读写,但还是有额外的IO消耗。vacuum full tablename要慎重使用,两者的区别要重点说明一下:简单的VACUUM(没有FULL)只是回收表的空间并且令原表可以再次使用。这种形式的命令和表的普通读写可以并发操作,因为没有请求排他锁。然而,额外的空间并不返回给操作系统;仅保持在相同的表中可用。VACUUM FULL将表的全部内容重写到一个没有任何垃圾数据的新文件中(占用新的磁盘空间,然后删除旧表的文件释放空间),相当于把未使用的空间返回到操作系统中。这种形式要慢许多并且在处理的时候需要在表上施加一个排它锁。因此影响业务使用该表。
(4)vacuum加入业务代码的恰当环节进行回收
如果某些表,更新频繁,每日都会膨胀,则可以加入到业务的代码中进行vacuum,在每次做完频繁DML变更后,立即回收垃圾数据。
系统表也需要回收
这是一个极其容易忽视的点。特别是在某些数据仓库需要频繁建表、改表(临时表也算)的场景下,很多存储元数据的系统表也存在膨胀的情况,而且膨胀率跟DDL频繁度正相关。某客户出现过pg_attribute膨胀到几百GB,pg_class膨胀到20倍的情况。以下表,是根据实际总结出来比较容易膨胀的pg系统表。
pg_attribute -- 存储表字段详情
pg_attribute_encoding -- 表字段的扩展信息
pg_class -- 存储pg的所有对象
pg_statistic -- 存储pg的数据库内容的统计数
图10:pg_class膨胀率示例

手动Vacuum的限制
手动做vacuum有一定的限制,也要注意。
(1)不要在IO使用率高的期间执行vacuum;
(2)vacuum full需要额外的磁盘空间才能完成。
如果磁盘水位高,剩余空间少,可能不够vacuum full大表;可以采取先删除一些历史表,腾出磁盘空间,再vacuum full目标table。
(3)必须先结束目标table上的大事务
有一次例行大表维护时,一个表做了一次vacuum,膨胀的空间并没有回收,仔细一查pg_stat_activity,发现这个表上有一个大事务(启动时间比手动vacuum启动更早)还没结束,这个时候,内核认为旧的数据还可能被使用,因此还不能回收,手动也不能。
4 冗余索引清理
索引本身也占用空间,尤其大表的索引。索引是数据库提高查询效率比较常用又基础的方式,用好索引不等于尽可能多的创建索引,尤其在大库的大表上。空间紧张,可以试着查一下是否有冗余索引可以清理。
排查思路
(1)是否有包含“异常多”字段的复合索引;
(2)是否有存在前缀字段相同的多个复合索引;
(3)是否存在优化器从来不走的索引。
排查方法与例子
首先,我们从第1个思路开始,查询索引包含字段大于等于4个列的表。SQL如下:
with t as (select indrelid, indkey,count(distinct unnest_idx) as unnest_idx_count
from pg_catalog.pg_index, unnest(indkey) as unnest_idx group by 1,2
having count(distinct unnest_idx)>=4 order by 3 desc)
select relname tablename,t.unnest_idx_count idx_cnt from pg_class c ,t where c.oid=t.indrelid;某个客户,就建了很多10个字段以上的复合索引,如下图所示:
图11:按索引列数排序的复合索引

一般超过6个字段的复合索引,在生产上都很少见,因此我们初步判断是建表时,业务方创建了冗余的索引;接下来,可以按照索引的大小排序后输出冗余索引列表。SQL如下:
with t as (select indrelid,indexrelid, indkey,count(distinct unnest_idx) as unnest_idx_count
from pg_catalog.pg_index, unnest(indkey) as unnest_idx group by 1,2,3
having count(distinct unnest_idx)>=3 order by 3 desc
)
select relname tablename,(pg_relation_size(indexrelid))/1024/1024/1024 indexsize,
t.unnest_idx_count idx_cnt from pg_class c ,t where c.oid=t.indrelid order by 2 desc;
图12:按大小排序的复合索引

这里,我们很清楚发现,部分索引的大小都在500G以上,有10多个索引的size超过1TB,看到这些信息时,我们震惊又开心,开心的是应该可以回收很多空间。接下来,需要跟业务方去沟通,经过业务方确认不需要再删除。
在这个客户案例中,我们删除了200多个冗余索引,大小达24T,直接释放了7%的业务空间!非常可观的空间优化效果。这次优化也非常及时,我记得优化在11月底完成;接着正好12月初高峰来临,业务方又写入了20TB新数据,如果没有这次索引优化,毫不夸张:12月初该客户的ADB集群撑不住了!
第(2)个思路(是否有存在前缀字段相同的多个复合索引),排查SQL如下。最好把索引及包含的字段元数据导出到其他GP库去分析,因为涉及到索引数据的分析对比(涉及向量转字符数组,以及子集与超集的计算),比较消耗性能;
select idx1.indrelid::regclass,idx1.indexrelid::regclass, string_to_array(idx1.indkey::text, '' '') as multi_index1,string_to_array(idx2.indkey::text, '' '') as multi_index2,idx2.indexrelid::regclass
from pg_index idx1 , pg_index idx2 where idx1.indrelid= idx2.indrelid
and idx1.indexrelid!=idx2.indexrelid and idx1.indnatts > 1
and string_to_array(idx1.indkey::text, '' '') <@ string_to_array(idx2.indkey::text, '' '');以下是排查例子user_t上复合第2个问题的索引,如下:

以下是查询结果

以上例子结果解释:multi_index1是multi_index2的子集,前者的索引列已经在后者中做了索引,因此,multi_index1属于冗余索引。
第(3)个思路:是否存在优化器从来不走的索引,排查的SQL如下:
SELECT
PSUI.indexrelid::regclass AS IndexName
,PSUI.relid::regclass AS TableName
FROM pg_stat_user_indexes AS PSUI
JOIN pg_index AS PI
ON PSUI.IndexRelid = PI.IndexRelid
WHERE PSUI.idx_scan = 0
AND PI.indisunique IS FALSE;下面以一个测试表,讲述排查例子

执行SQL可以查到idx_scan=0的索引idx_b

另外,有一个很重要的知识点,Append-Only列存表上的索引扫描只支持bitmap scan方式,如果Greenplum关闭了bitmap scan的索引扫描方式,那么所有AO列存表的访问都会全表扫描,即理论上AO列存表上的所有非唯一索引都无法使用,可以全部drop掉。当然,这个操作风险很高,要求整个database里使用AO列存表的业务几乎都只做批处理,不存在点查或范围查找的业务。综上,删除冗余索引,可以帮助客户节约磁盘空间。
5 复制表修改为分布表
众所周知,ADB PG的表分布策略有DISTRIBUTED BY(哈希分布),DISTRIBUTED RANDOMLY(随机分布),或DISTRIBUTED REPLICATED(全分布或复制表)。前两种的表会根据指定的分布键,把数据按照hash算法,打散分布到各个Segment上;复制表,则会在每个Segment上存放完整的数据拷贝。复制表分布策略(DISTRIBUTED REPLICATED)应该在小表上使用。将大表数据复制到每个节点上无论在存储还是维护上都是有很高代价的。查询全分布表的SQL如下:
select n.nspname AS "schemaname",c.relname AS "tablename",case when p.policytype=''p'' then ''parted'' when p.policytype=''r'' then ''replicated'' else ''normal'' end as "distrb_type", pg_size_pretty(pg_relation_size(c.oid))
from pg_class c
left join gp_distribution_policy p on c.oid=p.localoid
left join pg_namespace n on c.relnamespace=n.oid
where n.nspname=''public''
and c.relkind=''r''
and p.policytype=''r''
order by 4 desc;查询结果如下图,找到了大概10TB的全分布表,前3个表较大可以修改为哈希分布表,大概可以节约7T空间。
图13:业务库中的复制表

6 临时表空间独立存放
我们知道,Greenplum的默认表空间有两个

如果建表不指定表空间,默认会放到pg_default表空间,包含堆表、AO表、列存表、临时表等。具体到Segment的文件目录,则是每个Segment服务器上的~/data/Segment/${Segment_id}/base/${database_oid}目录下。同时,Greenplum在多种场景都会产生临时表,如:
(1)sql中order by、group by等操作;
(2)GP引擎由于数据读取或shuffle的需要,创建的临时表;
(3)业务方在ETL任务中创建的临时表。
这样存在一个问题,就是业务运行产生的临时表也会占用空间,但这部分不是业务表的数据占用,不方便精确管理大库的磁盘空间;因此我们把临时表的表空间独立出来,在服务器文件层面也独立出来,方便与业务数据进行分别精细化管理。好处还有:我们可以分别监控临时表空间、数据表空间、wal日志、错误日志,知道各个部分占用情况,如果磁盘空间告警,可以针对性采取措施。Greenplum创建临时表空间的方法,比较标准,如下:
查看临时表的表空间现状,发现都在base目录下,即与数据目录共用
postgres=# select * from pg_relation_filepath(''tmp_jc'');
pg_relation_filepath
----------------------
base/13333/t_845345
#查询实例的Segment的所有hosts,用于创建临时表空间目录
psql -d postgres -c ''select distinct address from gp_Segment_configuration order by 1'' -t > sheng_seg_hosts
#创建临时表空间的文件目录
gpssh -f sheng_seg_hosts -e "ls -l /home/adbpgadmin/tmptblspace"
gpssh -f sheng_seg_hosts -e "mkdir -p /home/adbpgadmin/tmptblspace"
~$ gpssh -f dg_seg_hosts -e "ls -l /home/adbpgadmin/tmptblspace"
# 创建临时表空间
postgres=# create tablespace tmp_tblspace location ''/home/adbpgadmin/tmptblspace'';
postgres=# select * from pg_tablespace;
spcname | spcowner | spcacl | spcoptions
--------------+----------+--------+------------
pg_default | 10 | |
pg_global | 10 | |
tmp_tblspace | 10 | |
(3 rows)
#修改角色的临时表空间
postgres=# alter role all set temp_tablespaces=''tmp_tblspace'';
#退出psql,然后重新登录
#创建临时表进行验证
create temp table tmp_jc2(id int);
insert into tmp_jc2 select generate_series(1,10000);
#查看表的filepath,发现临时表空间的文件路径不是base目录了
select * from pg_relation_filepath(''tmp_jc2'');
---------------------------------------------------
pg_tblspc/2014382/GPDB_6_301908232/13333/t_845369表空间独立后,监控可以区分临时表空间、数据表空间、WAL日志、错误日志进行独立监控和告警,以下是监控采集输出的样例:
~$ sh check_disk_data_size.sh
usage: sh check_disk_data_size.sh param1 param2, param1 is file recording Segment hosts; param2 data, xlog, log or temp监控输出的效果如下
图14:监控采集输出示意图

这样可以很清楚的了解业务数据或临时表数据在每个节点上的实际size,以及是否存在数据倾斜情况(超过平均值的10%)单独提醒,非常实用。
7 其他优化方案
除了上面详述的优化方案,一般来讲,Greenplum还有一些通用的处理方法:扩容Segment计算节点、业务数据裁剪、备份文件清理。计算节点扩容是最有效的。一般来讲,不管是阿里自己的业务,还是外部客户的业务,数据库的磁盘占用达到60%,考虑业务增量便会规划扩容,这些“基本实践”我们需要告诉客户。
业务数据裁剪,除了冷数据外,有一些中间表和历史表,我们也可以推动业务方做好数据生命周期管理,及时删除或转存归档。另外,对于临时运维操作,留下的备份文件,在操作完后需要及时进行清理,这个简单的习惯是非常容易忽略的,需要注意。在大库的磁盘管理中,任何小问题都会放大。
四 优化收益
1 为客户节约服务器成本
本案例,客户原DB2的数据量大于1PB,而我们通过上述方法综合优化,在ADB中只保存了300多T的数据,就让整体业务完整的运行起来。为客户节约了大概100台服务器及相关软件license费用,约合金额千万级别。
2 避免磁盘水位过高造成次生灾害
磁盘水位高会带来很多问题,通过磁盘空间优化方案,可以避免这些问题的发生。包括:
1.业务稍微增长,可能导致磁盘占满,发生“写锁定”,数据库临时罢工;
2.磁盘空间不足时,运维人员定位问题无法创建临时表;
3.ADB的大表维护,例如vacuum full,无空余磁盘空间使用。
以上磁盘空间优化方法不一定非常全面,希望对读者有所帮助。如果文中有疏漏或读者有补充,欢迎多多交流,一起探讨上云成本优化。
名词解释
业务方:指使用Greenplum做业务开发或数据分析的用户,通常是客户或客户的开发商。
OLAP:指联机分析处理型系统,是数据仓库系统最主要的应用,专门设计用于支持复杂的大数据量的分析查询处理,并快速返回直观易懂的结果。
DML:指增加、删除、修改、合并表数据的SQL,在数据库领域叫DML型SQL。
PB:1PB=1024TB=1024 * 1024 GB
原文链接
本文为阿里云原创内容,未经允许不得转载。
")
Deepgreen DB 是什么(含Deepgreen和Greenplum下载地址)

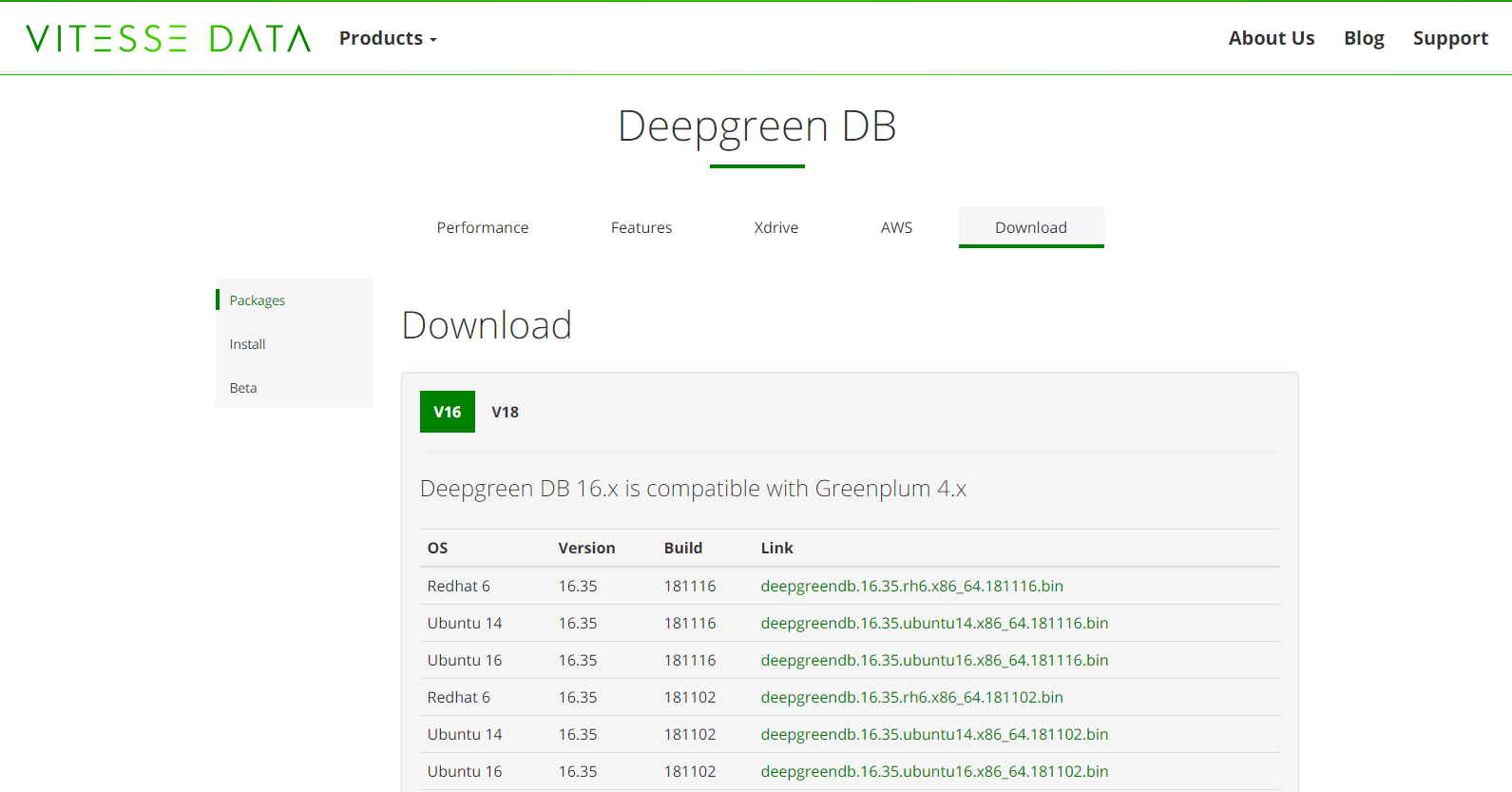
Deepgreen官网下载地址:http://vitessedata.com/products/deepgreen-db/download/ 不需要注册
Greenplum官网下载地址:https://network.pivotal.io/products/pivotal-gpdb/#/releases/118806/file_groups/1022 需要注册
- 优越的连接和聚合算法
- 新的溢出处理子系统
- 基于JIT的查询优化、矢量扫描和数据路径优化
- 除了以quicklz方式压缩的数据需要修改外,其他数据无需重新装载
- DML和DDL语句没有任何改变
- UDF(用户定义函数)语法没有任何改变
- 存储过程语法没有任何改变
- JDBC/ODBC等连接和授权协议没有任何改变
- 运行脚本没有任何改变(例如备份脚本)
这两个数据类型需要在数据库初始化以后,通过命令加载到需要的数据库中:
dgadmin@flash:~$ source deepgreendb/greenplum_path.sh
dgadmin@flash:~$ cd $GPHOME/share/postgresql/contrib/
dgadmin@flash:~/deepgreendb/share/postgresql/contrib$ psql postgres -f pg_decimal.sql使用语句:select avg(x), sum(2*x) from table
数据量:100万
dgadmin@flash:~$ psql -d postgres
psql (8.2.15)
Type "help" for help.
postgres=# drop table if exists tt;
NOTICE: table "tt" does not exist, skipping
DROP TABLE
postgres=# create table tt(
postgres(# ii bigint,
postgres(# f64 double precision,
postgres(# d64 decimal64,
postgres(# d128 decimal128,
postgres(# n numeric(15, 3))
postgres-# distributed randomly;
CREATE TABLE
postgres=# insert into tt
postgres-# select i,
postgres-# i + 0.123,
postgres-# (i + 0.123)::decimal64,
postgres-# (i + 0.123)::decimal128,
postgres-# i + 0.123
postgres-# from generate_series(1, 1000000) i;
INSERT 0 1000000
postgres=# \timing on
Timing is on.
postgres=# select count(*) from tt;
count
---------
1000000
(1 row)
Time: 161.500 ms
postgres=# set vitesse.enable=1;
SET
Time: 1.695 ms
postgres=# select avg(f64),sum(2*f64) from tt;
avg | sum
------------------+------------------
500000.622996815 | 1000001245993.63
(1 row)
Time: 45.368 ms
postgres=# select avg(d64),sum(2*d64) from tt;
avg | sum
------------+-------------------
500000.623 | 1000001246000.000
(1 row)
Time: 135.693 ms
postgres=# select avg(d128),sum(2*d128) from tt;
avg | sum
------------+-------------------
500000.623 | 1000001246000.000
(1 row)
Time: 148.286 ms
postgres=# set vitesse.enable=1;
SET
Time: 11.691 ms
postgres=# select avg(n),sum(2*n) from tt;
avg | sum
---------------------+-------------------
500000.623000000000 | 1000001246000.000
(1 row)
Time: 154.189 ms
postgres=# set vitesse.enable=0;
SET
Time: 1.426 ms
postgres=# select avg(n),sum(2*n) from tt;
avg | sum
---------------------+-------------------
500000.623000000000 | 1000001246000.000
(1 row)
Time: 296.291 ms45ms - 64位float
136ms - decimal64
148ms - decimal128
154ms - deepgreen numeric
296ms - greenplum numericdgadmin@flash:~$ psql postgres -f $GPHOME/share/postgresql/contrib/json.sqldgadmin@flash:~$ psql postgres
psql (8.2.15)
Type "help" for help.
postgres=# select ''[1,2,3]''::json->2;
?column?
----------
3
(1 row)
postgres=# create temp table mytab(i int, j json) distributed by (i);
CREATE TABLE
postgres=# insert into mytab values (1, null), (2, ''[2,3,4]''), (3, ''[3000,4000,5000]'');
INSERT 0 3
postgres=#
postgres=# insert into mytab values (1, null), (2, ''[2,3,4]''), (3, ''[3000,4000,5000]'');
INSERT 0 3
postgres=# select i, j->2 from mytab;
i | ?column?
---+----------
2 | 4
2 | 4
1 |
3 | 5000
1 |
3 | 5000
(6 rows)- zstd主页 http://facebook.github.io/zstd/
- lz4主页 http://lz4.github.io/lz4/
postgres=# create temp table ttnone (
postgres(# i int,
postgres(# t text,
postgres(# default column encoding (compresstype=none))
postgres-# with (appendonly=true, orientation=column)
postgres-# distributed by (i);
CREATE TABLE
postgres=# \timing on
Timing is on.
postgres=# create temp table ttzlib(
postgres(# i int,
postgres(# t text,
postgres(# default column encoding (compresstype=zlib, compresslevel=1))
postgres-# with (appendonly=true, orientation=column)
postgres-# distributed by (i);
CREATE TABLE
Time: 762.596 ms
postgres=# create temp table ttzstd (
postgres(# i int,
postgres(# t text,
postgres(# default column encoding (compresstype=zstd, compresslevel=1))
postgres-# with (appendonly=true, orientation=column)
postgres-# distributed by (i);
CREATE TABLE
Time: 827.033 ms
postgres=# create temp table ttlz4 (
postgres(# i int,
postgres(# t text,
postgres(# default column encoding (compresstype=lz4))
postgres-# with (appendonly=true, orientation=column)
postgres-# distributed by (i);
CREATE TABLE
Time: 845.728 ms
postgres=# insert into ttnone select i, ''user ''||i from generate_series(1, 100000000) i;
INSERT 0 100000000
Time: 104641.369 ms
postgres=# insert into ttzlib select i, ''user ''||i from generate_series(1, 100000000) i;
INSERT 0 100000000
Time: 99557.505 ms
postgres=# insert into ttzstd select i, ''user ''||i from generate_series(1, 100000000) i;
INSERT 0 100000000
Time: 98800.567 ms
postgres=# insert into ttlz4 select i, ''user ''||i from generate_series(1, 100000000) i;
INSERT 0 100000000
Time: 96886.107 ms
postgres=# select pg_size_pretty(pg_relation_size(''ttnone''));
pg_size_pretty
----------------
1708 MB
(1 row)
Time: 83.411 ms
postgres=# select pg_size_pretty(pg_relation_size(''ttzlib''));
pg_size_pretty
----------------
374 MB
(1 row)
Time: 4.641 ms
postgres=# select pg_size_pretty(pg_relation_size(''ttzstd''));
pg_size_pretty
----------------
325 MB
(1 row)
Time: 5.015 ms
postgres=# select pg_size_pretty(pg_relation_size(''ttlz4''));
pg_size_pretty
----------------
785 MB
(1 row)
Time: 4.483 ms
postgres=# select sum(length(t)) from ttnone;
sum
------------
1288888898
(1 row)
Time: 4414.965 ms
postgres=# select sum(length(t)) from ttzlib;
sum
------------
1288888898
(1 row)
Time: 4500.671 ms
postgres=# select sum(length(t)) from ttzstd;
sum
------------
1288888898
(1 row)
Time: 3849.648 ms
postgres=# select sum(length(t)) from ttlz4;
sum
------------
1288888898
(1 row)
Time: 3160.477 ms- SELECT {select-clauses} LIMIT SAMPLE {n} ROWS;
- SELECT {select-clauses} LIMIT SAMPLE {n} PERCENT;
postgres=# select count(*) from ttlz4;
count
-----------
100000000
(1 row)
Time: 903.661 ms
postgres=# select * from ttlz4 limit sample 0.00001 percent;
i | t
----------+---------------
3442917 | user 3442917
9182620 | user 9182620
9665879 | user 9665879
13791056 | user 13791056
15669131 | user 15669131
16234351 | user 16234351
19592531 | user 19592531
39097955 | user 39097955
48822058 | user 48822058
83021724 | user 83021724
1342299 | user 1342299
20309120 | user 20309120
34448511 | user 34448511
38060122 | user 38060122
69084858 | user 69084858
73307236 | user 73307236
95421406 | user 95421406
(17 rows)
Time: 4208.847 ms
postgres=# select * from ttlz4 limit sample 10 rows;
i | t
----------+---------------
78259144 | user 78259144
85551752 | user 85551752
90848887 | user 90848887
53923527 | user 53923527
46524603 | user 46524603
31635115 | user 31635115
19030885 | user 19030885
97877732 | user 97877732
33238448 | user 33238448
20916240 | user 20916240
(10 rows)
Time: 3578.031 msGreenplum使用TPC-H测试过程及结果 :
https://blog.csdn.net/xfg0218/article/details/82785187
原文链接
 DBA常用运维SQL")
Deepgreen(Greenplum) DBA常用运维SQL
摘要: 1.查看对象大小(表、索引、数据库等) select pg_size_pretty(pg_relation_size(’$schema.$table’)); 示例: tpch=# select pg_size_pretty(pg_relation_size(''public.
1.查看对象大小(表、索引、数据库等)
select pg_size_pretty(pg_relation_size(’$schema.$table’));
示例:
tpch=# select pg_size_pretty(pg_relation_size(''public.customer''));
pg_size_pretty
----------------
122 MB
(1 row)2.查看用户(非系统)表和索引
tpch=# select * from pg_stat_user_tables;
relid | schemaname | relname | seq_scan | seq_tup_read | idx_scan | idx_tup_fetch | n_tup_ins | n_tup_upd | n_tup_del | last_vacuum | last_autovacuum | last_analyze
| last_autoanalyze
-------+------------+----------------------+----------+--------------+----------+---------------+-----------+-----------+-----------+-------------+-----------------+--------------
+------------------
17327 | public | partsupp | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | |
|
17294 | public | customer | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | |
|
17158 | public | part | 0 | 0 | | | 0 | 0 | 0 | | |
|
17259 | public | supplier | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | |
|
16633 | gp_toolkit | gp_disk_free | 0 | 0 | | | 0 | 0 | 0 | | |
|
17394 | public | lineitem | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | |
|
17361 | public | orders | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | |
|
16439 | gp_toolkit | __gp_masterid | 0 | 0 | | | 0 | 0 | 0 | | |
|
49164 | public | number_xdrive | 0 | 0 | | | 0 | 0 | 0 | | |
|
17193 | public | region | 0 | 0 | | | 0 | 0 | 0 | | |
|
49215 | public | number_gpfdist | 0 | 0 | | | 0 | 0 | 0 | | |
|
16494 | gp_toolkit | __gp_log_master_ext | 0 | 0 | | | 0 | 0 | 0 | | |
|
40972 | public | number | 0 | 0 | | | 0 | 0 | 0 | | |
|
16413 | gp_toolkit | __gp_localid | 0 | 0 | | | 0 | 0 | 0 | | |
|
16468 | gp_toolkit | __gp_log_segment_ext | 0 | 0 | | | 0 | 0 | 0 | | |
|
17226 | public | nation | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | |
|
(16 rows)
tpch=# select * from pg_stat_user_indexes;
relid | indexrelid | schemaname | relname | indexrelname | idx_scan | idx_tup_read | idx_tup_fetch
-------+------------+------------+----------+-------------------------+----------+--------------+---------------
17259 | 17602 | public | supplier | idx_supplier_nation_key | 0 | 0 | 0
17327 | 17623 | public | partsupp | idx_partsupp_partkey | 0 | 0 | 0
17327 | 17644 | public | partsupp | idx_partsupp_suppkey | 0 | 0 | 0
17294 | 17663 | public | customer | idx_customer_nationkey | 0 | 0 | 0
17361 | 17684 | public | orders | idx_orders_custkey | 0 | 0 | 0
17394 | 17705 | public | lineitem | idx_lineitem_orderkey | 0 | 0 | 0
17394 | 17726 | public | lineitem | idx_lineitem_part_supp | 0 | 0 | 0
17226 | 17745 | public | nation | idx_nation_regionkey | 0 | 0 | 0
17394 | 17766 | public | lineitem | idx_lineitem_shipdate | 0 | 0 | 0
17361 | 17785 | public | orders | idx_orders_orderdate | 0 | 0 | 0
(10 rows)3.查看表分区
select b.nspname||''.''||a.relname as tablename, d.parname as partname from pg_class a, pg_namespace b, pg_partition c,pg_partition_rule d where a.relnamespace = b.oid and b.nspname = ''public'' and a.relname = ''customer'' and a.oid = c.parrelid and c.oid = d.paroid order by parname;
tablename | partname
-----------+----------
(0 rows)4.查看Distributed key
tpch=# select b.attname from pg_class a, pg_attribute b, pg_type c, gp_distribution_policy d, pg_namespace e where d.localoid = a.oid and a.relnamespace = e.oid and e.nspname = ''public'' and a.relname= ''customer'' and a.oid = b.attrelid and b.atttypid = c.oid and b.attnum > 0 and b.attnum = any(d.attrnums) order by attnum;
attname
-----------
c_custkey
(1 row)5.查看当前存活的查询
select procpid as pid, sess_id as session, usename as user, current_query as query, waiting,date_trunc(''second'',query_start) as start_time, client_addr as useraddr from pg_stat_activity where datname =''$PGDATABADE''
and current_query not like ''%from pg_stat_activity%where datname =%'' order by start_time;
示例:
tpch=# select procpid as pid, sess_id as session, usename as user, current_query as query, waiting,date_trunc(''second'',query_start) as start_time, client_addr as useraddr from pg_stat_activity where datname =''tpch''
tpch-# and current_query not like ''%from pg_stat_activity%where datname =%'' order by start_time;
pid | session | user | query | waiting | start_time | useraddr
-----+---------+------+-------+---------+------------+----------
(0 rows)
Deepgreen/Greenplum 删除节点步骤
Deepgreen/Greenplum 删除节点步骤
Greenplum 和 Deepgreen 官方都没有给出删除节点的方法和建议,但实际上,我们可以对节点进行删除。由于不确定性,删除节点极有可能导致其他的问题,所以还行做好备份,谨慎而为。下面是具体的步骤:
1. 查看数据库当前状态(12 个实例)
[gpadmin@sdw1 ~]$ gpstate
20170816:12:53:25:097578 gpstate:sdw1:gpadmin-[INFO]:-Starting gpstate with args:
20170816:12:53:25:097578 gpstate:sdw1:gpadmin-[INFO]:-local Greenplum Version: ''postgres (Greenplum Database) 4.3.99.00 build Deepgreen DB''
20170816:12:53:25:097578 gpstate:sdw1:gpadmin-[INFO]:-master Greenplum Version: ''PostgreSQL 8.2.15 (Greenplum Database 4.3.99.00 build Deepgreen DB) on x86_64-unknown-linux-gnu, compiled by GCC gcc (GCC) 4.9.2 20150212 (Red Hat 4.9.2-6) compiled on Jul 6 2017 03:04:10''
20170816:12:53:25:097578 gpstate:sdw1:gpadmin-[INFO]:-Obtaining Segment details from master...
20170816:12:53:25:097578 gpstate:sdw1:gpadmin-[INFO]:-Gathering data from segments...
..
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:-Greenplum instance status summary
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:-----------------------------------------------------
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:- Master instance = Active
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:- Master standby = No master standby configured
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:- Total segment instance count from metadata = 12
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:-----------------------------------------------------
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:- Primary Segment Status
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:-----------------------------------------------------
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:- Total primary segments = 12
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:- Total primary segment valid (at master) = 12
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:- Total primary segment failures (at master) = 0
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:- Total number of postmaster.pid files missing = 0
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:- Total number of postmaster.pid files found = 12
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:- Total number of postmaster.pid PIDs missing = 0
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:- Total number of postmaster.pid PIDs found = 12
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:- Total number of /tmp lock files missing = 0
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:- Total number of /tmp lock files found = 12
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:- Total number postmaster processes missing = 0
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:- Total number postmaster processes found = 12
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:-----------------------------------------------------
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:- Mirror Segment Status
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:-----------------------------------------------------
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:- Mirrors not configured on this array
20170816:12:53:27:097578 gpstate:sdw1:gpadmin-[INFO]:-----------------------------------------------------
2. 并行备份数据库
使用 gpcrondump 命令备份数据库,这里不赘述,不明白的可以翻看文档。
3. 关闭当前数据库
[gpadmin@sdw1 ~]$ gpstop -M fast
20170816:12:54:10:097793 gpstop:sdw1:gpadmin-[INFO]:-Starting gpstop with args: -M fast
20170816:12:54:10:097793 gpstop:sdw1:gpadmin-[INFO]:-Gathering information and validating the environment...
20170816:12:54:10:097793 gpstop:sdw1:gpadmin-[INFO]:-Obtaining Greenplum Master catalog information
20170816:12:54:10:097793 gpstop:sdw1:gpadmin-[INFO]:-Obtaining Segment details from master...
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:-Greenplum Version: ''postgres (Greenplum Database) 4.3.99.00 build Deepgreen DB''
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:---------------------------------------------
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:-Master instance parameters
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:---------------------------------------------
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- Master Greenplum instance process active PID = 31250
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- Database = template1
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- Master port = 5432
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- Master directory = /hgdata/master/hgdwseg-1
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- Shutdown mode = fast
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- Timeout = 120
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- Shutdown Master standby host = Off
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:---------------------------------------------
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:-Segment instances that will be shutdown:
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:---------------------------------------------
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- Host Datadir Port Status
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg0 25432 u
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg1 25433 u
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg2 25434 u
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg3 25435 u
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg4 25436 u
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg5 25437 u
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg6 25438 u
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg7 25439 u
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg8 25440 u
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg9 25441 u
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg10 25442 u
20170816:12:54:11:097793 gpstop:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg11 25443 u
Continue with Greenplum instance shutdown Yy|Nn (default=N):
> y
20170816:12:54:12:097793 gpstop:sdw1:gpadmin-[INFO]:-There are 0 connections to the database
20170816:12:54:12:097793 gpstop:sdw1:gpadmin-[INFO]:-Commencing Master instance shutdown with mode=''fast''
20170816:12:54:12:097793 gpstop:sdw1:gpadmin-[INFO]:-Master host=sdw1
20170816:12:54:12:097793 gpstop:sdw1:gpadmin-[INFO]:-Detected 0 connections to database
20170816:12:54:12:097793 gpstop:sdw1:gpadmin-[INFO]:-Using standard WAIT mode of 120 seconds
20170816:12:54:12:097793 gpstop:sdw1:gpadmin-[INFO]:-Commencing Master instance shutdown with mode=fast
20170816:12:54:12:097793 gpstop:sdw1:gpadmin-[INFO]:-Master segment instance directory=/hgdata/master/hgdwseg-1
20170816:12:54:13:097793 gpstop:sdw1:gpadmin-[INFO]:-Attempting forceful termination of any leftover master process
20170816:12:54:13:097793 gpstop:sdw1:gpadmin-[INFO]:-Terminating processes for segment /hgdata/master/hgdwseg-1
20170816:12:54:13:097793 gpstop:sdw1:gpadmin-[INFO]:-No standby master host configured
20170816:12:54:13:097793 gpstop:sdw1:gpadmin-[INFO]:-Commencing parallel segment instance shutdown, please wait...
20170816:12:54:13:097793 gpstop:sdw1:gpadmin-[INFO]:-0.00% of jobs completed
20170816:12:54:23:097793 gpstop:sdw1:gpadmin-[INFO]:-100.00% of jobs completed
20170816:12:54:23:097793 gpstop:sdw1:gpadmin-[INFO]:-----------------------------------------------------
20170816:12:54:23:097793 gpstop:sdw1:gpadmin-[INFO]:- Segments stopped successfully = 12
20170816:12:54:23:097793 gpstop:sdw1:gpadmin-[INFO]:- Segments with errors during stop = 0
20170816:12:54:23:097793 gpstop:sdw1:gpadmin-[INFO]:-----------------------------------------------------
20170816:12:54:23:097793 gpstop:sdw1:gpadmin-[INFO]:-Successfully shutdown 12 of 12 segment instances
20170816:12:54:23:097793 gpstop:sdw1:gpadmin-[INFO]:-Database successfully shutdown with no errors reported
20170816:12:54:23:097793 gpstop:sdw1:gpadmin-[INFO]:-Cleaning up leftover gpmmon process
20170816:12:54:23:097793 gpstop:sdw1:gpadmin-[INFO]:-No leftover gpmmon process found
20170816:12:54:23:097793 gpstop:sdw1:gpadmin-[INFO]:-Cleaning up leftover gpsmon processes
20170816:12:54:23:097793 gpstop:sdw1:gpadmin-[INFO]:-No leftover gpsmon processes on some hosts. not attempting forceful termination on these hosts
20170816:12:54:23:097793 gpstop:sdw1:gpadmin-[INFO]:-Cleaning up leftover shared memory
4. 以管理模式启动数据库
[gpadmin@sdw1 ~]$ gpstart -m
20170816:12:54:40:098061 gpstart:sdw1:gpadmin-[INFO]:-Starting gpstart with args: -m
20170816:12:54:40:098061 gpstart:sdw1:gpadmin-[INFO]:-Gathering information and validating the environment...
20170816:12:54:40:098061 gpstart:sdw1:gpadmin-[INFO]:-Greenplum Binary Version: ''postgres (Greenplum Database) 4.3.99.00 build Deepgreen DB''
20170816:12:54:40:098061 gpstart:sdw1:gpadmin-[INFO]:-Greenplum Catalog Version: ''201310150''
20170816:12:54:40:098061 gpstart:sdw1:gpadmin-[INFO]:-Master-only start requested in configuration without a standby master.
Continue with master-only startup Yy|Nn (default=N):
> y
20170816:12:54:41:098061 gpstart:sdw1:gpadmin-[INFO]:-Starting Master instance in admin mode
20170816:12:54:42:098061 gpstart:sdw1:gpadmin-[INFO]:-Obtaining Greenplum Master catalog information
20170816:12:54:42:098061 gpstart:sdw1:gpadmin-[INFO]:-Obtaining Segment details from master...
20170816:12:54:42:098061 gpstart:sdw1:gpadmin-[INFO]:-Setting new master era
20170816:12:54:42:098061 gpstart:sdw1:gpadmin-[INFO]:-Master Started...
5. 登陆管理数据库
[gpadmin@sdw1 ~]$ PGOPTIONS="-c gp_session_role=utility" psql -d postgres
psql (8.2.15)
Type "help" for help.
6. 删除 segment
postgres=# select * from gp_segment_configuration;
dbid | content | role | preferred_role | mode | status | port | hostname | address | replication_port | san_mounts
------+---------+------+----------------+------+--------+-------+----------+---------+------------------+------------
1 | -1 | p | p | s | u | 5432 | sdw1 | sdw1 | |
2 | 0 | p | p | s | u | 25432 | sdw1 | sdw1 | |
3 | 1 | p | p | s | u | 25433 | sdw1 | sdw1 | |
4 | 2 | p | p | s | u | 25434 | sdw1 | sdw1 | |
5 | 3 | p | p | s | u | 25435 | sdw1 | sdw1 | |
6 | 4 | p | p | s | u | 25436 | sdw1 | sdw1 | |
7 | 5 | p | p | s | u | 25437 | sdw1 | sdw1 | |
8 | 6 | p | p | s | u | 25438 | sdw1 | sdw1 | |
9 | 7 | p | p | s | u | 25439 | sdw1 | sdw1 | |
10 | 8 | p | p | s | u | 25440 | sdw1 | sdw1 | |
11 | 9 | p | p | s | u | 25441 | sdw1 | sdw1 | |
12 | 10 | p | p | s | u | 25442 | sdw1 | sdw1 | |
13 | 11 | p | p | s | u | 25443 | sdw1 | sdw1 | |
(13 rows)
postgres=# set allow_system_table_mods=''dml'';
SET
postgres=# delete from gp_segment_configuration where dbid=13;
DELETE 1
postgres=# select * from gp_segment_configuration;
dbid | content | role | preferred_role | mode | status | port | hostname | address | replication_port | san_mounts
------+---------+------+----------------+------+--------+-------+----------+---------+------------------+------------
1 | -1 | p | p | s | u | 5432 | sdw1 | sdw1 | |
2 | 0 | p | p | s | u | 25432 | sdw1 | sdw1 | |
3 | 1 | p | p | s | u | 25433 | sdw1 | sdw1 | |
4 | 2 | p | p | s | u | 25434 | sdw1 | sdw1 | |
5 | 3 | p | p | s | u | 25435 | sdw1 | sdw1 | |
6 | 4 | p | p | s | u | 25436 | sdw1 | sdw1 | |
7 | 5 | p | p | s | u | 25437 | sdw1 | sdw1 | |
8 | 6 | p | p | s | u | 25438 | sdw1 | sdw1 | |
9 | 7 | p | p | s | u | 25439 | sdw1 | sdw1 | |
10 | 8 | p | p | s | u | 25440 | sdw1 | sdw1 | |
11 | 9 | p | p | s | u | 25441 | sdw1 | sdw1 | |
12 | 10 | p | p | s | u | 25442 | sdw1 | sdw1 | |
(12 rows)
7. 删除 filespace
postgres=# select * from pg_filespace_entry;
fsefsoid | fsedbid | fselocation
----------+---------+---------------------------
3052 | 1 | /hgdata/master/hgdwseg-1
3052 | 2 | /hgdata/primary/hgdwseg0
3052 | 3 | /hgdata/primary/hgdwseg1
3052 | 4 | /hgdata/primary/hgdwseg2
3052 | 5 | /hgdata/primary/hgdwseg3
3052 | 6 | /hgdata/primary/hgdwseg4
3052 | 7 | /hgdata/primary/hgdwseg5
3052 | 8 | /hgdata/primary/hgdwseg6
3052 | 9 | /hgdata/primary/hgdwseg7
3052 | 10 | /hgdata/primary/hgdwseg8
3052 | 11 | /hgdata/primary/hgdwseg9
3052 | 12 | /hgdata/primary/hgdwseg10
3052 | 13 | /hgdata/primary/hgdwseg11
(13 rows)
postgres=# delete from pg_filespace_entry where fsedbid=13;
DELETE 1
postgres=# select * from pg_filespace_entry;
fsefsoid | fsedbid | fselocation
----------+---------+---------------------------
3052 | 1 | /hgdata/master/hgdwseg-1
3052 | 2 | /hgdata/primary/hgdwseg0
3052 | 3 | /hgdata/primary/hgdwseg1
3052 | 4 | /hgdata/primary/hgdwseg2
3052 | 5 | /hgdata/primary/hgdwseg3
3052 | 6 | /hgdata/primary/hgdwseg4
3052 | 7 | /hgdata/primary/hgdwseg5
3052 | 8 | /hgdata/primary/hgdwseg6
3052 | 9 | /hgdata/primary/hgdwseg7
3052 | 10 | /hgdata/primary/hgdwseg8
3052 | 11 | /hgdata/primary/hgdwseg9
3052 | 12 | /hgdata/primary/hgdwseg10
(12 rows)
8. 退出管理模式,正常启动数据库
[gpadmin@sdw1 ~]$ gpstop -m
20170816:12:56:52:098095 gpstop:sdw1:gpadmin-[INFO]:-Starting gpstop with args: -m
20170816:12:56:52:098095 gpstop:sdw1:gpadmin-[INFO]:-Gathering information and validating the environment...
20170816:12:56:52:098095 gpstop:sdw1:gpadmin-[INFO]:-Obtaining Greenplum Master catalog information
20170816:12:56:52:098095 gpstop:sdw1:gpadmin-[INFO]:-Obtaining Segment details from master...
20170816:12:56:52:098095 gpstop:sdw1:gpadmin-[INFO]:-Greenplum Version: ''postgres (Greenplum Database) 4.3.99.00 build Deepgreen DB''
20170816:12:56:52:098095 gpstop:sdw1:gpadmin-[INFO]:-There are 0 connections to the database
20170816:12:56:52:098095 gpstop:sdw1:gpadmin-[INFO]:-Commencing Master instance shutdown with mode=''smart''
20170816:12:56:52:098095 gpstop:sdw1:gpadmin-[INFO]:-Master host=sdw1
20170816:12:56:52:098095 gpstop:sdw1:gpadmin-[INFO]:-Commencing Master instance shutdown with mode=smart
20170816:12:56:52:098095 gpstop:sdw1:gpadmin-[INFO]:-Master segment instance directory=/hgdata/master/hgdwseg-1
20170816:12:56:53:098095 gpstop:sdw1:gpadmin-[INFO]:-Attempting forceful termination of any leftover master process
20170816:12:56:53:098095 gpstop:sdw1:gpadmin-[INFO]:-Terminating processes for segment /hgdata/master/hgdwseg-1
[gpadmin@sdw1 ~]$ gpstart
20170816:12:57:02:098112 gpstart:sdw1:gpadmin-[INFO]:-Starting gpstart with args:
20170816:12:57:02:098112 gpstart:sdw1:gpadmin-[INFO]:-Gathering information and validating the environment...
20170816:12:57:02:098112 gpstart:sdw1:gpadmin-[INFO]:-Greenplum Binary Version: ''postgres (Greenplum Database) 4.3.99.00 build Deepgreen DB''
20170816:12:57:02:098112 gpstart:sdw1:gpadmin-[INFO]:-Greenplum Catalog Version: ''201310150''
20170816:12:57:02:098112 gpstart:sdw1:gpadmin-[INFO]:-Starting Master instance in admin mode
20170816:12:57:03:098112 gpstart:sdw1:gpadmin-[INFO]:-Obtaining Greenplum Master catalog information
20170816:12:57:03:098112 gpstart:sdw1:gpadmin-[INFO]:-Obtaining Segment details from master...
20170816:12:57:03:098112 gpstart:sdw1:gpadmin-[INFO]:-Setting new master era
20170816:12:57:03:098112 gpstart:sdw1:gpadmin-[INFO]:-Master Started...
20170816:12:57:03:098112 gpstart:sdw1:gpadmin-[INFO]:-Shutting down master
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:---------------------------
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:-Master instance parameters
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:---------------------------
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:-Database = template1
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:-Master Port = 5432
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:-Master directory = /hgdata/master/hgdwseg-1
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:-Timeout = 600 seconds
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:-Master standby = Off
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:---------------------------------------
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:-Segment instances that will be started
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:---------------------------------------
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:- Host Datadir Port
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg0 25432
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg1 25433
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg2 25434
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg3 25435
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg4 25436
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg5 25437
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg6 25438
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg7 25439
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg8 25440
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg9 25441
20170816:12:57:05:098112 gpstart:sdw1:gpadmin-[INFO]:- sdw1 /hgdata/primary/hgdwseg10 25442
Continue with Greenplum instance startup Yy|Nn (default=N):
> y
20170816:12:57:07:098112 gpstart:sdw1:gpadmin-[INFO]:-Commencing parallel segment instance startup, please wait...
.......
20170816:12:57:14:098112 gpstart:sdw1:gpadmin-[INFO]:-Process results...
20170816:12:57:14:098112 gpstart:sdw1:gpadmin-[INFO]:-----------------------------------------------------
20170816:12:57:14:098112 gpstart:sdw1:gpadmin-[INFO]:- Successful segment starts = 11
20170816:12:57:14:098112 gpstart:sdw1:gpadmin-[INFO]:- Failed segment starts = 0
20170816:12:57:14:098112 gpstart:sdw1:gpadmin-[INFO]:- Skipped segment starts (segments are marked down in configuration) = 0
20170816:12:57:14:098112 gpstart:sdw1:gpadmin-[INFO]:-----------------------------------------------------
20170816:12:57:14:098112 gpstart:sdw1:gpadmin-[INFO]:-
20170816:12:57:14:098112 gpstart:sdw1:gpadmin-[INFO]:-Successfully started 11 of 11 segment instances
20170816:12:57:14:098112 gpstart:sdw1:gpadmin-[INFO]:-----------------------------------------------------
20170816:12:57:14:098112 gpstart:sdw1:gpadmin-[INFO]:-Starting Master instance sdw1 directory /hgdata/master/hgdwseg-1
20170816:12:57:15:098112 gpstart:sdw1:gpadmin-[INFO]:-Command pg_ctl reports Master sdw1 instance active
20170816:12:57:15:098112 gpstart:sdw1:gpadmin-[INFO]:-No standby master configured. skipping...
20170816:12:57:15:098112 gpstart:sdw1:gpadmin-[INFO]:-Database successfully started
9. 将删除节点的备份文件使用 psql 恢复到当前数据库
psql -d postgres -f xxxx.sql #这里不赘述恢复过程
备注:
1)本文使用的是只恢复删除节点的数据。
2)本文的过程,逆向执行,可以将删除的节点重新添加回来,但是数据恢复起来比较耗时,与重新建库恢复差不多。
转载自:https://www.sypopo.com/post/M95Rm39Or7/
今天关于greenplum jdbc readme by pivotal的分享就到这里,希望大家有所收获,若想了解更多关于ADBPG&Greenplum成本优化之磁盘水位管理、Deepgreen DB 是什么(含Deepgreen和Greenplum下载地址)、Deepgreen(Greenplum) DBA常用运维SQL、Deepgreen/Greenplum 删除节点步骤等相关知识,可以在本站进行查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

