本文将带您了解关于prometheus:celery,redis-export的新内容,另外,我们还将为您提供关于grafana+prometheus+node_exporter、istioprome
本文将带您了解关于prometheus: celery, redis-export的新内容,另外,我们还将为您提供关于grafana+prometheus+node_exporter、istio prometheus 预警 Prometheus AlertManager 安装 -- 误区、istio prometheus预警Prometheus AlertManager、jvm-exporter整合k8s+prometheus监控报警的实用信息。
本文目录一览:- prometheus: celery, redis-export
- grafana+prometheus+node_exporter
- istio prometheus 预警 Prometheus AlertManager 安装 -- 误区
- istio prometheus预警Prometheus AlertManager
- jvm-exporter整合k8s+prometheus监控报警

prometheus: celery, redis-export
https://github.com/nlighten/tomcat_exporter
https://github.com/prometheus/jmx_exporter
https://vexxhost.com/resources/tutorials/how-to-use-prometheus-to-monitor-your-centos-7-server/
./redis_exporter -redis.addr redis://cache2.w95akh.ng.0001.cnn1.cache.amazonaws.com.cn:6379 -web.listen-address :19121
启动一个celery worker,即RabbitMQ Broker:
celery broker: rabbitmq
docker run --link rabbitmq1:rabbit --name some-celery -d celery:latest
检查集群状态:docker run --link rabbitmq1:rabbit --rm celery celery status
启动一个celery worker,即Redis Broker:
$ docker run --link some-redis:redis -e CELERY_BROKER_URL=redis://redis --name some-celery -d celery检查集群状态:
$ docker run --link some-redis:redis -e CELERY_BROKER_URL=redis://redis --rm celery celery status
grafana+prometheus+node_exporter
背景
玩一玩
由于都是non-root启动,所以,都是:
- 先下载压缩包
- 配置systemctl服务配置文件
- systemctl start/status/stop {服务名}
grafana
下载:https://grafana.com/grafana/download
需要使用non-root启动的话,下载Standalone Linux Binaries
解压
配置systemctl:
[root@localhost system]# cat grafana-server.service
[Unit]
Description=grafana - enables you to query, visualize, alert on, and explore your metrics, logs, and traces wherever they are stored.
Documentation=https://grafana.com/docs/grafana/latest/introduction/
After=network-online.target
[Service]
Type=simple
ExecStart=/home/sysadmin/monitor/grafana-v10.2.2/bin/grafana server \
--homepath /home/sysadmin/monitor/grafana-v10.2.2 \
--config /home/sysadmin/monitor/grafana-v10.2.2/conf/custom.ini
Restart=on-failure
User=sysadmin
Group=sysadmin
[Install]
WantedBy=multi-user.target
[root@localhost system]# 启动:
[root@localhost system]# systemctl start grafana-server.service
[root@localhost system]# systemctl status grafana-server.service
● grafana-server.service - grafana - enables you to query, visualize, alert on, and explore your metrics, logs, and traces wherever they are stored.
Loaded: loaded (/etc/systemd/system/grafana-server.service; disabled; vendor preset: disabled)
Active: active (running) since Mon 2023-12-11 17:49:29 CST; 7s ago
Docs: https://grafana.com/docs/grafana/latest/introduction/
Main PID: 2548 (grafana)
Tasks: 21 (limit: 100057)
Memory: 102.2M
CGroup: /system.slice/grafana-server.service
└─2548 /home/sysadmin/monitor/grafana-v10.2.2/bin/grafana server --homepath /home/sysadmin/monitor/grafana-v10.2.2 --config /home/sysadmin/monitor/grafana-v10.2.2/conf/custom.ini
12月 11 17:49:33 localhost.localdomain grafana[2548]: logger=sqlstore.transactions t=2023-12-11T17:49:33.234603441+08:00 level=info msg="Database locked, sleeping then retrying" error="database is lo>
12月 11 17:49:33 localhost.localdomain grafana[2548]: logger=ngalert.migration t=2023-12-11T17:49:33.339105773+08:00 level=info msg=Starting
12月 11 17:49:33 localhost.localdomain grafana[2548]: logger=ngalert.migration t=2023-12-11T17:49:33.339602491+08:00 level=info msg="No migrations to run"
12月 11 17:49:33 localhost.localdomain grafana[2548]: logger=http.server t=2023-12-11T17:49:33.388485736+08:00 level=info msg="HTTP Server Listen" address=[::]:3000 protocol=http subUrl=/grafana sock>
12月 11 17:49:33 localhost.localdomain grafana[2548]: logger=ngalert.state.manager t=2023-12-11T17:49:33.644194974+08:00 level=info msg="State cache has been initialized" states=0 duration=421.887563>
12月 11 17:49:33 localhost.localdomain grafana[2548]: logger=ngalert.scheduler t=2023-12-11T17:49:33.644248371+08:00 level=info msg="Starting scheduler" tickInterval=10s
12月 11 17:49:33 localhost.localdomain grafana[2548]: logger=ticker t=2023-12-11T17:49:33.644342054+08:00 level=info msg=starting first_tick=2023-12-11T17:49:40+08:00
12月 11 17:49:33 localhost.localdomain grafana[2548]: logger=ngalert.multiorg.alertmanager t=2023-12-11T17:49:33.644355847+08:00 level=info msg="Starting MultiOrg Alertmanager"
12月 11 17:49:33 localhost.localdomain grafana[2548]: logger=plugins.update.checker t=2023-12-11T17:49:33.666795693+08:00 level=info msg="Update check succeeded" duration=443.293369ms
12月 11 17:49:34 localhost.localdomain grafana[2548]: logger=grafana.update.checker t=2023-12-11T17:49:34.026805884+08:00 level=info msg="Update check succeeded" duration=803.690713ms
[root@localhost system]# ps -ef |grep grafana
sysadmin 2548 1 15 17:49 ? 00:00:02 /home/sysadmin/monitor/grafana-v10.2.2/bin/grafana server --homepath /home/sysadmin/monitor/grafana-v10.2.2 --config /home/sysadmin/monitor/grafana-v10.2.2/conf/custom.ini
root 2572 1942 0 17:49 pts/1 00:00:00 grep --color=auto grafana
[root@localhost system]# 检查停止:
[root@localhost system]# systemctl stop grafana-server.service
[root@localhost system]# systemctl status grafana-server.service
● grafana-server.service - grafana - enables you to query, visualize, alert on, and explore your metrics, logs, and traces wherever they are stored.
Loaded: loaded (/etc/systemd/system/grafana-server.service; disabled; vendor preset: disabled)
Active: inactive (dead)
Docs: https://grafana.com/docs/grafana/latest/introduction/
12月 11 17:49:33 localhost.localdomain grafana[2548]: logger=ngalert.multiorg.alertmanager t=2023-12-11T17:49:33.644355847+08:00 level=info msg="Starting MultiOrg Alertmanager"
12月 11 17:49:33 localhost.localdomain grafana[2548]: logger=plugins.update.checker t=2023-12-11T17:49:33.666795693+08:00 level=info msg="Update check succeeded" duration=443.293369ms
12月 11 17:49:34 localhost.localdomain grafana[2548]: logger=grafana.update.checker t=2023-12-11T17:49:34.026805884+08:00 level=info msg="Update check succeeded" duration=803.690713ms
12月 11 17:50:22 localhost.localdomain grafana[2548]: logger=infra.usagestats t=2023-12-11T17:50:22.23100276+08:00 level=info msg="Usage stats are ready to report"
12月 11 17:50:56 localhost.localdomain systemd[1]: Stopping grafana - enables you to query, visualize, alert on, and explore your metrics, logs, and traces wherever they are stored....
12月 11 17:50:56 localhost.localdomain grafana[2548]: logger=server t=2023-12-11T17:50:56.762804431+08:00 level=info msg="Shutdown started" reason="System signal: terminated"
12月 11 17:50:56 localhost.localdomain grafana[2548]: logger=tracing t=2023-12-11T17:50:56.763057587+08:00 level=info msg="Closing tracing"
12月 11 17:50:56 localhost.localdomain grafana[2548]: logger=ticker t=2023-12-11T17:50:56.763272714+08:00 level=info msg=stopped last_tick=2023-12-11T17:50:50+08:00
12月 11 17:50:56 localhost.localdomain systemd[1]: grafana-server.service: Succeeded.
12月 11 17:50:56 localhost.localdomain systemd[1]: Stopped grafana - enables you to query, visualize, alert on, and explore your metrics, logs, and traces wherever they are stored..
[root@localhost system]# 配置开机启动:
[root@localhost system]# systemctl enable grafana-server.service
Created symlink /etc/systemd/system/multi-user.target.wants/grafana-server.service → /etc/systemd/system/grafana-server.service.
[root@localhost system]# systemctl start grafana-server.serviceprometheus
下载:https://prometheus.io/download/#prometheus
解压
prometheus启动参数:https://prometheus.io/docs/prometheus/latest/command-line/pro...
配置systemctl:
[root@localhost system]# cat prometheus.service
[Unit]
Description=prometheus - open-source systems monitoring and alerting toolkit
Documentation=https://prometheus.io/docs/introduction/overview/
After=network-online.target
[Service]
Type=simple
PIDFile=/home/sysadmin/monitor/prometheus-2.48.0.linux-amd64/prometheus.pid
ExecStart=/home/sysadmin/monitor/prometheus-2.48.0.linux-amd64/prometheus \
--config.file=/home/sysadmin/monitor/prometheus-2.48.0.linux-amd64/prometheus.yml \
--storage.tsdb.retention.time=15d \
--storage.tsdb.path=/home/sysadmin/monitor/prometheus-2.48.0.linux-amd64/data/ \
--web.max-connections=512 \
--web.read-timeout=5m \
--query.max-concurrency=20 \
--query.timeout=2m
ExecReload=/bin/sh -c "/bin/kill -s HUP $(/bin/cat /home/sysadmin/monitor/prometheus-2.48.0.linux-amd64/prometheus.pid)"
ExecStop=/bin/sh -c "/bin/kill -s TERM $(/bin/cat /home/sysadmin/monitor/prometheus-2.48.0.linux-amd64/prometheus.pid)"
User=sysadmin
Group=sysadmin
[Install]
WantedBy=multi-user.target
[root@localhost system]# pwd
/etc/systemd/system
[root@localhost system]# 启动:systemctl start prometheus:
[root@localhost system]# vi prometheus.service
[root@localhost system]# systemctl start prometheus
Warning: The unit file, source configuration file or drop-ins of prometheus.service changed on disk. Run ''systemctl daemon-reload'' to reload units.
[root@localhost system]# systemctl daemon-reload
[root@localhost system]# systemctl start prometheus
[root@localhost system]# systemctl status prometheus.service
● prometheus.service - prometheus - open-source systems monitoring and alerting toolkit
Loaded: loaded (/etc/systemd/system/prometheus.service; disabled; vendor preset: disabled)
Active: active (running) since Mon 2023-12-11 15:55:42 CST; 6s ago
Docs: https://prometheus.io/docs/introduction/overview/
Main PID: 2111 (prometheus)
Tasks: 10 (limit: 100057)
Memory: 30.4M
CGroup: /system.slice/prometheus.service
└─2111 /home/sysadmin/monitor/prometheus-2.48.0.linux-amd64/prometheus --config.file=/home/sysadmin/monitor/prometheus-2.48.0.linux-amd64/prometheus.yml --storage.tsdb.retention.time=15d ->
12月 11 15:55:42 localhost.localdomain prometheus[2111]: ts=2023-12-11T07:55:42.428Z caller=head.go:761 level=info component=tsdb msg="WAL segment loaded" segment=10 maxSegment=12
12月 11 15:55:42 localhost.localdomain prometheus[2111]: ts=2023-12-11T07:55:42.449Z caller=head.go:761 level=info component=tsdb msg="WAL segment loaded" segment=11 maxSegment=12
12月 11 15:55:42 localhost.localdomain prometheus[2111]: ts=2023-12-11T07:55:42.449Z caller=head.go:761 level=info component=tsdb msg="WAL segment loaded" segment=12 maxSegment=12
12月 11 15:55:42 localhost.localdomain prometheus[2111]: ts=2023-12-11T07:55:42.450Z caller=head.go:798 level=info component=tsdb msg="WAL replay completed" checkpoint_replay_duration=1.520374ms wal_>
12月 11 15:55:42 localhost.localdomain prometheus[2111]: ts=2023-12-11T07:55:42.452Z caller=main.go:1045 level=info fs_type=XFS_SUPER_MAGIC
12月 11 15:55:42 localhost.localdomain prometheus[2111]: ts=2023-12-11T07:55:42.452Z caller=main.go:1048 level=info msg="TSDB started"
12月 11 15:55:42 localhost.localdomain prometheus[2111]: ts=2023-12-11T07:55:42.452Z caller=main.go:1229 level=info msg="Loading configuration file" filename=/home/sysadmin/monitor/prometheus-2.48.0.>
12月 11 15:55:42 localhost.localdomain prometheus[2111]: ts=2023-12-11T07:55:42.453Z caller=main.go:1266 level=info msg="Completed loading of configuration file" filename=/home/sysadmin/monitor/prome>
12月 11 15:55:42 localhost.localdomain prometheus[2111]: ts=2023-12-11T07:55:42.453Z caller=main.go:1009 level=info msg="Server is ready to receive web requests."
12月 11 15:55:42 localhost.localdomain prometheus[2111]: ts=2023-12-11T07:55:42.453Z caller=manager.go:1012 level=info component="rule manager" msg="Starting rule manager..."
lines 1-20/20 (END) 检查进程在:
[root@localhost system]# ps -ef |grep prometheus
sysadmin 2111 1 0 15:55 ? 00:00:00 /home/sysadmin/monitor/prometheus-2.48.0.linux-amd64/prometheus --config.file=/home/sysadmin/monitor/prometheus-2.48.0.linux-amd64/prometheus.yml --storage.tsdb.retention.time=15d --storage.tsdb.path=/home/sysadmin/monitor/prometheus-2.48.0.linux-amd64/data/ --web.max-connections=512 --web.read-timeout=5m --query.max-concurrency=20 --query.timeout=2m
root 2160 1942 0 16:04 pts/1 00:00:00 grep --color=auto prometheus检查停止正常:
[root@localhost system]# systemctl stop prometheus.service
[root@localhost system]# systemctl status prometheus.service
● prometheus.service - prometheus - open-source systems monitoring and alerting toolkit
Loaded: loaded (/etc/systemd/system/prometheus.service; enabled; vendor preset: disabled)
Active: failed (Result: exit-code) since Mon 2023-12-11 16:06:38 CST; 5s ago
Docs: https://prometheus.io/docs/introduction/overview/
Process: 2182 ExecStop=/bin/sh -c /bin/kill -s TERM $(/bin/cat /home/sysadmin/monitor/prometheus-2.48.0.linux-amd64/prometheus.pid) (code=exited, status=1/FAILURE)
Process: 2111 ExecStart=/home/sysadmin/monitor/prometheus-2.48.0.linux-amd64/prometheus --config.file=/home/sysadmin/monitor/prometheus-2.48.0.linux-amd64/prometheus.yml --storage.tsdb.retention.ti>
Main PID: 2111 (code=exited, status=0/SUCCESS)
12月 11 16:06:38 localhost.localdomain prometheus[2111]: ts=2023-12-11T08:06:38.036Z caller=manager.go:1036 level=info component="rule manager" msg="Rule manager stopped"
12月 11 16:06:38 localhost.localdomain prometheus[2111]: ts=2023-12-11T08:06:38.036Z caller=main.go:934 level=info msg="Stopping scrape manager..."
12月 11 16:06:38 localhost.localdomain prometheus[2111]: ts=2023-12-11T08:06:38.036Z caller=main.go:879 level=info msg="Scrape discovery manager stopped"
12月 11 16:06:38 localhost.localdomain prometheus[2111]: ts=2023-12-11T08:06:38.036Z caller=main.go:893 level=info msg="Notify discovery manager stopped"
12月 11 16:06:38 localhost.localdomain prometheus[2111]: ts=2023-12-11T08:06:38.036Z caller=main.go:926 level=info msg="Scrape manager stopped"
12月 11 16:06:38 localhost.localdomain prometheus[2111]: ts=2023-12-11T08:06:38.095Z caller=notifier.go:604 level=info component=notifier msg="Stopping notification manager..."
12月 11 16:06:38 localhost.localdomain prometheus[2111]: ts=2023-12-11T08:06:38.095Z caller=main.go:1155 level=info msg="Notifier manager stopped"
12月 11 16:06:38 localhost.localdomain prometheus[2111]: ts=2023-12-11T08:06:38.095Z caller=main.go:1167 level=info msg="See you next time!"
12月 11 16:06:38 localhost.localdomain systemd[1]: prometheus.service: Failed with result ''exit-code''.
12月 11 16:06:38 localhost.localdomain systemd[1]: Stopped prometheus - open-source systems monitoring and alerting toolkit.
[root@localhost system]# ps -ef |grep prometheus
root 2191 1942 0 16:06 pts/1 00:00:00 grep --color=auto prometheus
[root@localhost system]# 配置开机启动:
[root@localhost system]# systemctl enable prometheus.service
Created symlink /etc/systemd/system/multi-user.target.wants/prometheus.service → /etc/systemd/system/prometheus.service.
[root@localhost system]# node_exporter
下载:https://prometheus.io/download/#node_exporter
解压
配置systemctl:
[root@localhost system]# cat node_exporter.service
[Unit]
Description=node_exporter - Prometheus exporter for hardware and OS metrics
Documentation=https://github.com/prometheus/node_exporter; https://prometheus.io/docs/guides/node-exporter/;
After=network-online.target
[Service]
Type=simple
ExecStart=/home/sysadmin/monitor/node_exporter-1.7.0.linux-amd64/node_exporter
Restart=on-failure
User=sysadmin
Group=sysadmin
[Install]
WantedBy=multi-user.target
[root@localhost system]# 启动:
[root@localhost system]# systemctl start node_exporter.service
[root@localhost system]# systemctl status node_exporter.service
● node_exporter.service - node_exporter - Prometheus exporter for hardware and OS metrics
Loaded: loaded (/etc/systemd/system/node_exporter.service; disabled; vendor preset: disabled)
Active: active (running) since Mon 2023-12-11 16:19:44 CST; 4s ago
Docs: https://github.com/prometheus/node_exporter;
https://prometheus.io/docs/guides/node-exporter/;
Main PID: 2231 (node_exporter)
Tasks: 6 (limit: 100057)
Memory: 18.6M
CGroup: /system.slice/node_exporter.service
└─2231 /home/sysadmin/monitor/node_exporter-1.7.0.linux-amd64/node_exporter
12月 11 16:19:45 localhost.localdomain node_exporter[2231]: ts=2023-12-11T08:19:45.017Z caller=node_exporter.go:117 level=info collector=thermal_zone
12月 11 16:19:45 localhost.localdomain node_exporter[2231]: ts=2023-12-11T08:19:45.017Z caller=node_exporter.go:117 level=info collector=time
12月 11 16:19:45 localhost.localdomain node_exporter[2231]: ts=2023-12-11T08:19:45.017Z caller=node_exporter.go:117 level=info collector=timex
12月 11 16:19:45 localhost.localdomain node_exporter[2231]: ts=2023-12-11T08:19:45.017Z caller=node_exporter.go:117 level=info collector=udp_queues
12月 11 16:19:45 localhost.localdomain node_exporter[2231]: ts=2023-12-11T08:19:45.017Z caller=node_exporter.go:117 level=info collector=uname
12月 11 16:19:45 localhost.localdomain node_exporter[2231]: ts=2023-12-11T08:19:45.017Z caller=node_exporter.go:117 level=info collector=vmstat
12月 11 16:19:45 localhost.localdomain node_exporter[2231]: ts=2023-12-11T08:19:45.017Z caller=node_exporter.go:117 level=info collector=xfs
12月 11 16:19:45 localhost.localdomain node_exporter[2231]: ts=2023-12-11T08:19:45.017Z caller=node_exporter.go:117 level=info collector=zfs
12月 11 16:19:45 localhost.localdomain node_exporter[2231]: ts=2023-12-11T08:19:45.017Z caller=tls_config.go:274 level=info msg="Listening on" address=[::]:9100
12月 11 16:19:45 localhost.localdomain node_exporter[2231]: ts=2023-12-11T08:19:45.017Z caller=tls_config.go:277 level=info msg="TLS is disabled." http2=false address=[::]:9100
[root@localhost system]# ps -ef |grep node_exporter
sysadmin 2231 1 0 16:19 ? 00:00:00 /home/sysadmin/monitor/node_exporter-1.7.0.linux-amd64/node_exporter
root 2240 1942 0 16:20 pts/1 00:00:00 grep --color=auto node_exporter
[root@localhost system]# 检查停止正常:
[root@localhost system]# systemctl stop node_exporter.service
[root@localhost system]# ps -ef |grep node
root 2249 1942 0 16:23 pts/1 00:00:00 grep --color=auto node
[root@localhost system]# systemctl status node_exporter.service
● node_exporter.service - node_exporter - Prometheus exporter for hardware and OS metrics
Loaded: loaded (/etc/systemd/system/node_exporter.service; disabled; vendor preset: disabled)
Active: inactive (dead)
Docs: https://github.com/prometheus/node_exporter;
https://prometheus.io/docs/guides/node-exporter/;
12月 11 16:19:45 localhost.localdomain node_exporter[2231]: ts=2023-12-11T08:19:45.017Z caller=node_exporter.go:117 level=info collector=udp_queues
12月 11 16:19:45 localhost.localdomain node_exporter[2231]: ts=2023-12-11T08:19:45.017Z caller=node_exporter.go:117 level=info collector=uname
12月 11 16:19:45 localhost.localdomain node_exporter[2231]: ts=2023-12-11T08:19:45.017Z caller=node_exporter.go:117 level=info collector=vmstat
12月 11 16:19:45 localhost.localdomain node_exporter[2231]: ts=2023-12-11T08:19:45.017Z caller=node_exporter.go:117 level=info collector=xfs
12月 11 16:19:45 localhost.localdomain node_exporter[2231]: ts=2023-12-11T08:19:45.017Z caller=node_exporter.go:117 level=info collector=zfs
12月 11 16:19:45 localhost.localdomain node_exporter[2231]: ts=2023-12-11T08:19:45.017Z caller=tls_config.go:274 level=info msg="Listening on" address=[::]:9100
12月 11 16:19:45 localhost.localdomain node_exporter[2231]: ts=2023-12-11T08:19:45.017Z caller=tls_config.go:277 level=info msg="TLS is disabled." http2=false address=[::]:9100
12月 11 16:23:22 localhost.localdomain systemd[1]: Stopping node_exporter - Prometheus exporter for hardware and OS metrics...
12月 11 16:23:22 localhost.localdomain systemd[1]: node_exporter.service: Succeeded.
12月 11 16:23:22 localhost.localdomain systemd[1]: Stopped node_exporter - Prometheus exporter for hardware and OS metrics.
[root@localhost system]# 配置开机启动:
[root@localhost system]# systemctl enable node_exporter.service
Created symlink /etc/systemd/system/multi-user.target.wants/node_exporter.service → /etc/systemd/system/node_exporter.service.
[root@localhost system]# 成果
忘记grafana密码了:
[sysadmin@localhost bin]$ ls -l
总用量 194400
-rwxr-xr-x 1 sysadmin sysadmin 195352632 11月 20 21:24 grafana
-rwxr-xr-x 1 sysadmin sysadmin 1851408 11月 20 21:24 grafana-cli
-rwxr-xr-x 1 sysadmin sysadmin 1851408 11月 20 21:24 grafana-server
[sysadmin@localhost bin]$ ./grafana-cli admin reset-admin-password monitor
Deprecation warning: The standalone ''grafana-cli'' program is deprecated and will be removed in the future. Please update all uses of ''grafana-cli'' to ''grafana cli''
INFO [12-11|17:56:36] Starting Grafana logger=settings version= commit= branch= compiled=1970-01-01T08:00:00+08:00
INFO [12-11|17:56:36] Config loaded from logger=settings file=/home/sysadmin/monitor/grafana-v10.2.2/conf/defaults.ini
INFO [12-11|17:56:36] Config loaded from logger=settings file=/home/sysadmin/monitor/grafana-v10.2.2/conf/custom.ini
INFO [12-11|17:56:36] Target logger=settings target=[all]
INFO [12-11|17:56:36] Path Home logger=settings path=/home/sysadmin/monitor/grafana-v10.2.2
INFO [12-11|17:56:36] Path Data logger=settings path=/home/sysadmin/monitor/grafana-v10.2.2/data
INFO [12-11|17:56:36] Path Logs logger=settings path=/home/sysadmin/monitor/grafana-v10.2.2/data/log
INFO [12-11|17:56:36] Path Plugins logger=settings path=/home/sysadmin/monitor/grafana-v10.2.2/data/plugins
INFO [12-11|17:56:36] Path Provisioning logger=settings path=/home/sysadmin/monitor/grafana-v10.2.2/conf/provisioning
INFO [12-11|17:56:36] App mode production logger=settings
INFO [12-11|17:56:36] Connecting to DB logger=sqlstore dbtype=sqlite3
INFO [12-11|17:56:36] Starting DB migrations logger=migrator
INFO [12-11|17:56:36] migrations completed logger=migrator performed=0 skipped=608 duration=545.03µs
INFO [12-11|17:56:36] Validated license token logger=licensing appURL=http://localhost:3000/grafana/ source=disk status=NotFound
INFO [12-11|17:56:36] Envelope encryption state logger=secrets enabled=true current provider=secretKey.v1
Admin password changed successfully ✔
[sysadmin@localhost bin]$ 创建一个dashboard:


istio prometheus 预警 Prometheus AlertManager 安装 -- 误区
误区:因为 prometheus 是一个 pod 不能重启,所以此方案适用于单独非容器安装的 prometheus。
1. 进入 pod
kubectl exec -n istio-system -it grafana-694477c588-8rbvc /bin/bash
2. 下载安装 Prometheus AlertManager
grafana-cli plugins install camptocamp-prometheus-alertmanager-datasource
3.restart grafana service
service grafana-server restart

4. 查看错误原因
grafana-server -homepath /usr/share/grafana
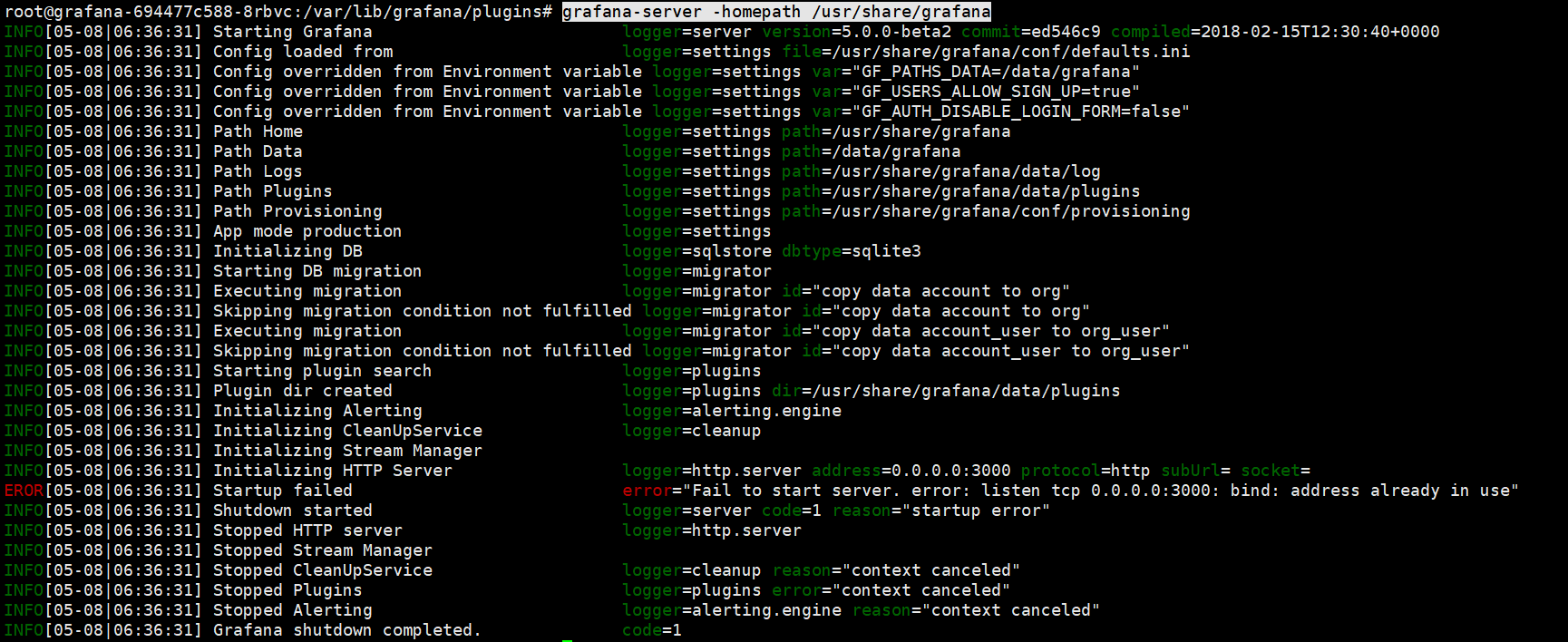
Right. Something is already using port 3000.
Stop the grafana services
systemctl stop grafana.service -l
do a ps aux |grep grafana and kill if any process exits
Then start grafana using
systemctl stop grafana.service -l
Tailf for grafana logs
tailf /var/log/grafana/grafana.log
5. 查看本地安装的 Plugin
grafana-cli plugins ls

service grafana-server restart

istio prometheus预警Prometheus AlertManager
1.安装alertmanager
kubectl create -f 以下文件
alertmanager-templates.yaml、configmap.yaml、deployment.yaml、service.yaml


apiVersion: v1
data:
default.tmpl: |
{{ define "__alertmanager" }}AlertManager{{ end }}
{{ define "__alertmanagerURL" }}{{ .ExternalURL }}/#/alerts?receiver={{ .Receiver }}{{ end }}
{{ define "__subject" }}[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ .GroupLabels.SortedPairs.Values | join " " }} {{ if gt (len .CommonLabels) (len .GroupLabels) }}({{ with .CommonLabels.Remove .GroupLabels.Names }}{{ .Values | join " " }}{{ end }}){{ end }}{{ end }}
{{ define "__description" }}{{ end }}
{{ define "__text_alert_list" }}{{ range . }}Labels:
{{ range .Labels.SortedPairs }} - {{ .Name }} = {{ .Value }}
{{ end }}Annotations:
{{ range .Annotations.SortedPairs }} - {{ .Name }} = {{ .Value }}
{{ end }}Source: {{ .GeneratorURL }}
{{ end }}{{ end }}
{{ define "slack.default.title" }}{{ template "__subject" . }}{{ end }}
{{ define "slack.default.username" }}{{ template "__alertmanager" . }}{{ end }}
{{ define "slack.default.fallback" }}{{ template "slack.default.title" . }} | {{ template "slack.default.titlelink" . }}{{ end }}
{{ define "slack.default.pretext" }}{{ end }}
{{ define "slack.default.titlelink" }}{{ template "__alertmanagerURL" . }}{{ end }}
{{ define "slack.default.iconemoji" }}{{ end }}
{{ define "slack.default.iconurl" }}{{ end }}
{{ define "slack.default.text" }}{{ end }}
{{ define "hipchat.default.from" }}{{ template "__alertmanager" . }}{{ end }}
{{ define "hipchat.default.message" }}{{ template "__subject" . }}{{ end }}
{{ define "pagerduty.default.description" }}{{ template "__subject" . }}{{ end }}
{{ define "pagerduty.default.client" }}{{ template "__alertmanager" . }}{{ end }}
{{ define "pagerduty.default.clientURL" }}{{ template "__alertmanagerURL" . }}{{ end }}
{{ define "pagerduty.default.instances" }}{{ template "__text_alert_list" . }}{{ end }}
{{ define "opsgenie.default.message" }}{{ template "__subject" . }}{{ end }}
{{ define "opsgenie.default.description" }}{{ .CommonAnnotations.SortedPairs.Values | join " " }}
{{ if gt (len .Alerts.Firing) 0 -}}
Alerts Firing:
{{ template "__text_alert_list" .Alerts.Firing }}
{{- end }}
{{ if gt (len .Alerts.Resolved) 0 -}}
Alerts Resolved:
{{ template "__text_alert_list" .Alerts.Resolved }}
{{- end }}
{{- end }}
{{ define "opsgenie.default.source" }}{{ template "__alertmanagerURL" . }}{{ end }}
{{ define "victorops.default.message" }}{{ template "__subject" . }} | {{ template "__alertmanagerURL" . }}{{ end }}
{{ define "victorops.default.from" }}{{ template "__alertmanager" . }}{{ end }}
{{ define "email.default.subject" }}{{ template "__subject" . }}{{ end }}
{{ define "email.default.html" }}
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<!--
Style and HTML derived from https://github.com/mailgun/transactional-email-templates
The MIT License (MIT)
Copyright (c) 2014 Mailgun
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
-->
<html xmlns="http://www.w3.org/1999/xhtml" xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta name="viewport" content="width=device-width"/>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/>
<title>{{ template "__subject" . }}</title>
</head>
<body itemscope="" itemtype="http://schema.org/EmailMessage"bgcolor="#f6f6f6">
<tablebgcolor="#f6f6f6">
<tr>
<tdvalign="top"></td>
<td width="600"valign="top">
<div>
<table width="100%" cellpadding="0" cellspacing="0"bgcolor="#fff">
<tr>
<tdalign="center" bgcolor="#E6522C" valign="top">
{{ .Alerts | len }} alert{{ if gt (len .Alerts) 1 }}s{{ end }} for {{ range .GroupLabels.SortedPairs }}
{{ .Name }}={{ .Value }}
{{ end }}
</td>
</tr>
<tr>
<tdvalign="top">
<table width="100%" cellpadding="0" cellspacing="0">
<tr>
<tdvalign="top">
<a href="{{ template "__alertmanagerURL" . }}">View in {{ template "__alertmanager" . }}</a>
</td>
</tr>
{{ if gt (len .Alerts.Firing) 0 }}
<tr>
<tdvalign="top">
<strong>[{{ .Alerts.Firing | len }}] Firing</strong>
</td>
</tr>
{{ end }}
{{ range .Alerts.Firing }}
<tr>
<tdvalign="top">
<strong>Labels</strong><br/>
{{ range .Labels.SortedPairs }}{{ .Name }} = {{ .Value }}<br/>{{ end }}
{{ if gt (len .Annotations) 0 }}<strong>Annotations</strong><br/>{{ end }}
{{ range .Annotations.SortedPairs }}{{ .Name }} = {{ .Value }}<br/>{{ end }}
<a href="{{ .GeneratorURL }}">Source</a><br/>
</td>
</tr>
{{ end }}
{{ if gt (len .Alerts.Resolved) 0 }}
{{ if gt (len .Alerts.Firing) 0 }}
<tr>
<tdvalign="top">
<br/>
<hr/>
<br/>
</td>
</tr>
{{ end }}
<tr>
<tdvalign="top">
<strong>[{{ .Alerts.Resolved | len }}] Resolved</strong>
</td>
</tr>
{{ end }}
{{ range .Alerts.Resolved }}
<tr>
<tdvalign="top">
<strong>Labels</strong><br/>
{{ range .Labels.SortedPairs }}{{ .Name }} = {{ .Value }}<br/>{{ end }}
{{ if gt (len .Annotations) 0 }}<strong>Annotations</strong><br/>{{ end }}
{{ range .Annotations.SortedPairs }}{{ .Name }} = {{ .Value }}<br/>{{ end }}
<a href="{{ .GeneratorURL }}">Source</a><br/>
</td>
</tr>
{{ end }}
</table>
</td>
</tr>
</table>
<div>
<table width="100%">
<tr>
<tdalign="center" valign="top"><a href="{{ .ExternalURL }}">Sent by {{ template "__alertmanager" . }}</a></td>
</tr>
</table>
</div></div>
</td>
<tdvalign="top"></td>
</tr>
</table>
</body>
</html>
{{ end }}
{{ define "pushover.default.title" }}{{ template "__subject" . }}{{ end }}
{{ define "pushover.default.message" }}{{ .CommonAnnotations.SortedPairs.Values | join " " }}
{{ if gt (len .Alerts.Firing) 0 }}
Alerts Firing:
{{ template "__text_alert_list" .Alerts.Firing }}
{{ end }}
{{ if gt (len .Alerts.Resolved) 0 }}
Alerts Resolved:
{{ template "__text_alert_list" .Alerts.Resolved }}
{{ end }}
{{ end }}
{{ define "pushover.default.url" }}{{ template "__alertmanagerURL" . }}{{ end }}
slack.tmpl: |
{{ define "slack.devops.text" }}
{{range .Alerts}}{{.Annotations.DESCRIPTION}}
{{end}}
{{ end }}
kind: ConfigMap
metadata:
creationTimestamp: null
name: alertmanager-templates
namespace: monitoring

kind: ConfigMap
apiVersion: v1
metadata:
name: alertmanager
namespace: monitoring
data:
config.yml: |-
global:
# ResolveTimeout is the time after which an alert is declared resolved
# if it has not been updated.
resolve_timeout: 5m
# The smarthost and SMTP sender used for mail notifications.
smtp_smarthost: ''smtp.126.com:25''
smtp_from: ''xxx@126.com''
smtp_auth_username: ''xxx@126.com''
smtp_auth_password: ''xxx''
# The API URL to use for Slack notifications.
slack_api_url: ''https://hooks.slack.com/services/some/api/token''
# # The directory from which notification templates are read.
templates:
- ''/etc/alertmanager-templates/*.tmpl''
# The root route on which each incoming alert enters.
route:
# The labels by which incoming alerts are grouped together. For example,
# multiple alerts coming in for cluster=A and alertname=LatencyHigh would
# be batched into a single group.
group_by: [''alertname'', ''cluster'', ''service'']
# When a new group of alerts is created by an incoming alert, wait at
# least ''group_wait'' to send the initial notification.
# This way ensures that you get multiple alerts for the same group that start
# firing shortly after another are batched together on the first
# notification.
group_wait: 30s
# When the first notification was sent, wait ''group_interval'' to send a batch
# of new alerts that started firing for that group.
group_interval: 5m
# If an alert has successfully been sent, wait ''repeat_interval'' to
# resend them.
#repeat_interval: 1m
repeat_interval: 15m
# A default receiver
# If an alert isn''t caught by a route, send it to default.
receiver: default
# All the above attributes are inherited by all child routes and can
# overwritten on each.
# The child route trees.
routes:
# Send severity=slack alerts to slack.
# - match:
# severity: slack
# receiver: slack_alert
- match:
severity: email
receiver: email_alert
receivers:
- name: ''default''
slack_configs:
- channel: ''#alertmanager-test''
text: ''<!channel>{{ template "slack.devops.text" . }}''
send_resolved: true
- name: ''slack_alert''
slack_configs:
- channel: ''#alertmanager-test''
send_resolved: true
- name: live-monitoring
email_configs:
- to: xxx@ultrapower.com.cn #接收邮箱地址

apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: alertmanager
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager
template:
metadata:
name: alertmanager
labels:
app: alertmanager
spec:
containers:
- name: alertmanager
image: quay.io/prometheus/alertmanager:v0.7.1
args:
- ''-config.file=/etc/alertmanager/config.yml''
- ''-storage.path=/alertmanager''
ports:
- name: alertmanager
containerPort: 9093
volumeMounts:
- name: config-volume
mountPath: /etc/alertmanager
- name: templates-volume
mountPath: /etc/alertmanager-templates
- name: alertmanager
mountPath: /alertmanager
volumes:
- name: config-volume
configMap:
name: alertmanager
- name: templates-volume
configMap:
name: alertmanager-templates
- name: alertmanager
emptyDir: {}

apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: ''true''
prometheus.io/path: ''/metrics''
labels:
name: alertmanager
name: alertmanager
namespace: monitoring
spec:
selector:
app: alertmanager
type: NodePort
ports:
- name: alertmanager
protocol: TCP
port: 9093
targetPort: 9093
2.配置prometheus对alertmanager的链接
编辑prometheus.yaml文件,新增
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093

3.配置预警rules
编辑prometheus.yaml文件,新增以下代码
rule_files:
- "/data/istio/prometheus-rules/*.rules.yml"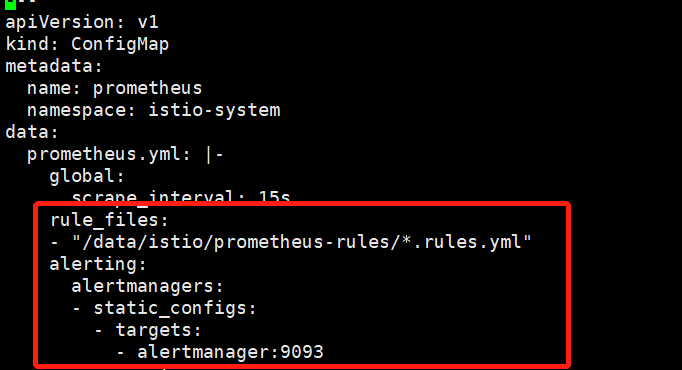
挂载规则文件:
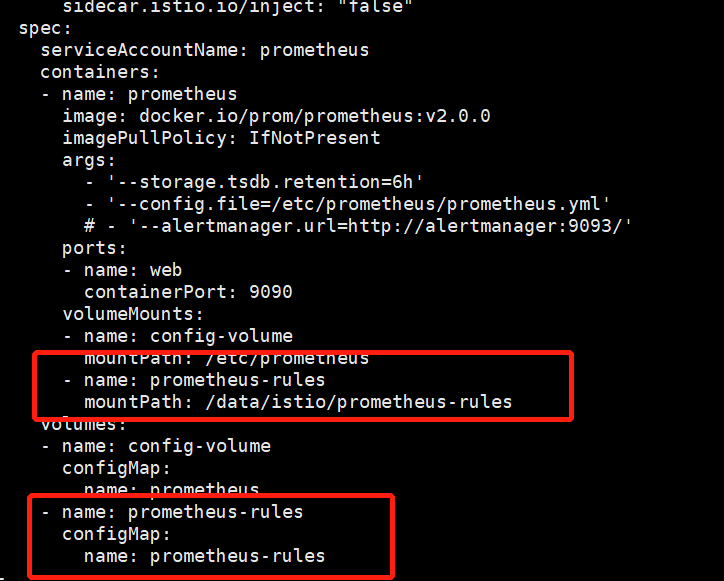
根据文件生成configMap:
kubectl create configmap prometheus-rules --from-file=prometheus-rules -o yaml --namespace=istio-system
注意:rules文件夹名称为prometheus-rules,rules文件为yml格式,如:
test.rules.yml
groups:
- name: my-group-name
interval: 30s # defaults to global interval
rules:
- record: instance:errors:rate5m
expr: rate(errors_total[5m])
- record: instance:requests:rate5m
expr: rate(requests_total[5m])
- alert: HighErrors
# Expressions remain PromQL as before and can be spread over
# multiple lines via YAML’s multi-line strings.
expr: |
sum without(instance) (instance:errors:rate5m)
/
sum without(instance) (instance:requests:rate5m)
for: 5m
labels:
severity: critical
annotations:
description: "stuff''s happening with {{ $labels.service }}"

jvm-exporter整合k8s+prometheus监控报警
文章背景:使用Prometheus+Grafana监控JVM,这片文章中介绍了怎么用jvm-exporter监控我们的java应用,在我们的使用场景中需要监控k8s集群中的jvm,接下来谈谈k8s和Prometheus的集成扩展使用,假设我们已经成功将Prometheus部署到我们的k8s集群中了kubernetes集成prometheus+grafana监控,但是kube-prometheus并没有集成jvm-exporter,这就需要我们自己操作。
将jvm-exporter整合进我们的应用
整合过程很简单,只需要将jvm-exporter作为javaagent加入到我们的java启动命令就可以了,详细见使用Prometheus+Grafana监控JVM
配置Prometheus服务自动发现
对于有Service暴露的服务我们可以用 prometheus-operator 项目定义的ServiceMonitorCRD来配置服务发现,配置模板如下:
--- # ServiceMonitor 服务自动发现规则
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor # prometheus-operator 定义的CRD
metadata:
name: jmx-metrics
namespace: monitoring
labels:
k8s-apps: jmx-metrics
spec:
jobLabel: metrics #监控数据的job标签指定为metrics label的值,即加上数据标签job=jmx-metrics
selector:
matchLabels:
metrics: jmx-metrics # 自动发现 label中有metrics: jmx-metrics 的service
namespaceSelector:
matchNames: # 配置需要自动发现的命名空间,可以配置多个
- my-namespace
endpoints:
- port: http-metrics # 拉去metric的端口,这个写的是 service的端口名称,即 service yaml的spec.ports.name
interval: 15s # 拉取metric的时间间隔
--- # 服务service模板
apiVersion: v1
kind: Service
metadata:
labels:
metrics: jmx-metrics # ServiceMonitor 自动发现的关键label
name: jmx-metrics
namespace: my-namespace
spec:
ports:
- name: http-metrics #对应 ServiceMonitor 中spec.endpoints.port
port: 9093 # jmx-exporter 暴露的服务端口
targetPort: http-metrics # pod yaml 暴露的端口名
selector:
metrics: jmx-metrics # service本身的标签选择器以上配置了my-namespace命名空间的 jmx-metrics Service的服务自动发现,Prometheus会将这个service 的所有关联pod自动加入监控,并从apiserver获取到最新的pod列表,这样当我们的服务副本扩充时也能自动添加到监控系统中。
那么对于没有创建 Service 的服务,比如以HostPort对集群外暴露服务的实例,我们可以使用 PodMonitor 来做服务发现,相关样例如下:
--- # PodMonitor 服务自动发现规则,最新的版本支持,旧版本可能不支持
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor # prometheus-operator 定义的CRD
metadata:
name: jmx-metrics
namespace: monitoring
labels:
k8s-apps: jmx-metrics
spec:
jobLabel: metrics #监控数据的job标签指定为metrics label的值,即加上数据标签job=jmx-metrics
selector:
matchLabels:
metrics: jmx-metrics # 自动发现 label中有metrics: jmx-metrics 的pod
namespaceSelector:
matchNames: # 配置需要自动发现的命名空间,可以配置多个
- my-namespace
podMetricsEndpoints:
- port: http-metrics # Pod yaml中 metric暴露端口的名称 即 spec.ports.name
interval: 15s # 拉取metric的时间间隔
--- # 需要监控的Pod模板
apiVersion: v1
kind: Pod
metadata:
labels:
metrics: jmx-metrics
name: jmx-metrics
namespace: my-namespace
spec:
containers:
- image: tomcat:9.0
name: tomcat
ports:
- containerPort: 9093
name: http-metrics- 为Prometheus serviceAccount 添加对应namespace的权限
--- # 在对应的ns中创建角色
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: prometheus-k8s
namespace: my-namespace
rules:
- apiGroups:
- ""
resources:
- services
- endpoints
- pods
verbs:
- get
- list
- watch
--- # 绑定角色 prometheus-k8s 角色到 Role
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: prometheus-k8s
namespace: my-namespace
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: prometheus-k8s
subjects:
- kind: ServiceAccount
name: prometheus-k8s # Prometheus 容器使用的 serviceAccount,kube-prometheus默认使用prometheus-k8s这个用户
namespace: monitoring在Prometheus管理页面中查看服务发现
服务发现配置成功后会出现在Prometheus的管理界面中:

添加报警规则
新建报警规则文件:jvm-alert-rules.yaml,填入以下内容
apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: labels: prometheus: k8s role: alert-rules name: jvm-metrics-rules namespace: monitoring spec: groups: - name: jvm-metrics-rules rules: # 在5分钟里,GC花费时间超过10% - alert: GcTimeTooMuch expr: increase(jvm_gc_collection_seconds_sum[5m]) > 30 for: 5m labels: severity: red annotations: summary: "{{ $labels.app }} GC时间占比超过10%" message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} GC时间占比超过10%,当前值({{ $value }}%)" # GC次数太多 - alert: GcCountTooMuch expr: increase(jvm_gc_collection_seconds_count[1m]) > 30 for: 1m labels: severity: red annotations: summary: "{{ $labels.app }} 1分钟GC次数>30次" message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} 1分钟GC次数>30次,当前值({{ $value }})" # FGC次数太多 - alert: FgcCountTooMuch expr: increase(jvm_gc_collection_seconds_count{gc="ConcurrentMarkSweep"}[1h]) > 3 for: 1m labels: severity: red annotations: summary: "{{ $labels.app }} 1小时的FGC次数>3次" message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} 1小时的FGC次数>3次,当前值({{ $value }})" # 非堆内存使用超过80% - alert: NonheapUsageTooMuch expr: jvm_memory_bytes_used{job="jmx-metrics", area="nonheap"} / jvm_memory_bytes_max * 100 > 80 for: 1m labels: severity: red annotations: summary: "{{ $labels.app }} 非堆内存使用>80%" message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} 非堆内存使用率>80%,当前值({{ $value }}%)" # 内存使用预警 - alert: HeighMemUsage expr: process_resident_memory_bytes{job="jmx-metrics"} / os_total_physical_memory_bytes * 100 > 85 for: 1m labels: severity: red annotations: summary: "{{ $labels.app }} rss内存使用率大于85%" message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} rss内存使用率大于85%,当前值({{ $value }}%)"执行
kubectl apply -f jvm-alert-rules.yaml使规则生效添加报警接收人
编辑接受人配置:
global:
resolve_timeout: 5m
route:
group_by: [''job'', ''alertname'', ''pod'']
group_interval: 2m
receiver: my-alert-receiver
routes:
- match:
job: jmx-metrics
receiver: my-alert-receiver
repeat_interval: 3h
receivers:
- name: my-alert-receiver
webhook_configs:
- url: http://mywebhook.com/
max_alerts: 1
send_resolved: true使用工具转换为base64编码,填入alert-manager对应的配置Secret中kubectl edit -n monitoring Secret alertmanager-main
apiVersion: v1
data:
alertmanager.yaml: KICAgICJyZWNlaXZlciI6ICJudWxsIg== # base64填入这里
kind: Secret
metadata:
name: alertmanager-main
namespace: monitoring
type: Opaque退出编辑后稍等一会儿生效。
自此,jvm监控系统配置完成。
附jvm-exporter接口返回参数示例,可以根据需要自取其中的metric
# HELP jvm_threads_current Current thread count of a JVM
# TYPE jvm_threads_current gauge
jvm_threads_current 218.0
# HELP jvm_threads_daemon Daemon thread count of a JVM
# TYPE jvm_threads_daemon gauge
jvm_threads_daemon 40.0
# HELP jvm_threads_peak Peak thread count of a JVM
# TYPE jvm_threads_peak gauge
jvm_threads_peak 219.0
# HELP jvm_threads_started_total Started thread count of a JVM
# TYPE jvm_threads_started_total counter
jvm_threads_started_total 249.0
# HELP jvm_threads_deadlocked Cycles of JVM-threads that are in deadlock waiting to acquire object monitors or ownable synchronizers
# TYPE jvm_threads_deadlocked gauge
jvm_threads_deadlocked 0.0
# HELP jvm_threads_deadlocked_monitor Cycles of JVM-threads that are in deadlock waiting to acquire object monitors
# TYPE jvm_threads_deadlocked_monitor gauge
jvm_threads_deadlocked_monitor 0.0
# HELP jvm_threads_state Current count of threads by state
# TYPE jvm_threads_state gauge
jvm_threads_state{state="NEW",} 0.0
jvm_threads_state{state="RUNNABLE",} 49.0
jvm_threads_state{state="TIMED_WAITING",} 141.0
jvm_threads_state{state="TERMINATED",} 0.0
jvm_threads_state{state="WAITING",} 28.0
jvm_threads_state{state="BLOCKED",} 0.0
# HELP jvm_info JVM version info
# TYPE jvm_info gauge
jvm_info{version="1.8.0_261-b12",vendor="Oracle Corporation",runtime="Java(TM) SE Runtime Environment",} 1.0
# HELP jvm_memory_bytes_used Used bytes of a given JVM memory area.
# TYPE jvm_memory_bytes_used gauge
jvm_memory_bytes_used{area="heap",} 1.553562144E9
jvm_memory_bytes_used{area="nonheap",} 6.5181496E7
# HELP jvm_memory_bytes_committed Committed (bytes) of a given JVM memory area.
# TYPE jvm_memory_bytes_committed gauge
jvm_memory_bytes_committed{area="heap",} 4.08027136E9
jvm_memory_bytes_committed{area="nonheap",} 6.8747264E7
# HELP jvm_memory_bytes_max Max (bytes) of a given JVM memory area.
# TYPE jvm_memory_bytes_max gauge
jvm_memory_bytes_max{area="heap",} 4.08027136E9
jvm_memory_bytes_max{area="nonheap",} 1.317011456E9
# HELP jvm_memory_bytes_init Initial bytes of a given JVM memory area.
# TYPE jvm_memory_bytes_init gauge
jvm_memory_bytes_init{area="heap",} 4.294967296E9
jvm_memory_bytes_init{area="nonheap",} 2555904.0
# HELP jvm_memory_pool_bytes_used Used bytes of a given JVM memory pool.
# TYPE jvm_memory_pool_bytes_used gauge
jvm_memory_pool_bytes_used{pool="Code Cache",} 2.096832E7
jvm_memory_pool_bytes_used{pool="Metaspace",} 3.9320064E7
jvm_memory_pool_bytes_used{pool="Compressed Class Space",} 4893112.0
jvm_memory_pool_bytes_used{pool="Par Eden Space",} 1.71496168E8
jvm_memory_pool_bytes_used{pool="Par Survivor Space",} 7.1602832E7
jvm_memory_pool_bytes_used{pool="CMS Old Gen",} 1.310463144E9
# HELP jvm_memory_pool_bytes_committed Committed bytes of a given JVM memory pool.
# TYPE jvm_memory_pool_bytes_committed gauge
jvm_memory_pool_bytes_committed{pool="Code Cache",} 2.3396352E7
jvm_memory_pool_bytes_committed{pool="Metaspace",} 4.0239104E7
jvm_memory_pool_bytes_committed{pool="Compressed Class Space",} 5111808.0
jvm_memory_pool_bytes_committed{pool="Par Eden Space",} 1.718091776E9
jvm_memory_pool_bytes_committed{pool="Par Survivor Space",} 2.14695936E8
jvm_memory_pool_bytes_committed{pool="CMS Old Gen",} 2.147483648E9
# HELP jvm_memory_pool_bytes_max Max bytes of a given JVM memory pool.
# TYPE jvm_memory_pool_bytes_max gauge
jvm_memory_pool_bytes_max{pool="Code Cache",} 2.5165824E8
jvm_memory_pool_bytes_max{pool="Metaspace",} 5.36870912E8
jvm_memory_pool_bytes_max{pool="Compressed Class Space",} 5.28482304E8
jvm_memory_pool_bytes_max{pool="Par Eden Space",} 1.718091776E9
jvm_memory_pool_bytes_max{pool="Par Survivor Space",} 2.14695936E8
jvm_memory_pool_bytes_max{pool="CMS Old Gen",} 2.147483648E9
# HELP jvm_memory_pool_bytes_init Initial bytes of a given JVM memory pool.
# TYPE jvm_memory_pool_bytes_init gauge
jvm_memory_pool_bytes_init{pool="Code Cache",} 2555904.0
jvm_memory_pool_bytes_init{pool="Metaspace",} 0.0
jvm_memory_pool_bytes_init{pool="Compressed Class Space",} 0.0
jvm_memory_pool_bytes_init{pool="Par Eden Space",} 1.718091776E9
jvm_memory_pool_bytes_init{pool="Par Survivor Space",} 2.14695936E8
jvm_memory_pool_bytes_init{pool="CMS Old Gen",} 2.147483648E9
# HELP jmx_config_reload_failure_total Number of times configuration have failed to be reloaded.
# TYPE jmx_config_reload_failure_total counter
jmx_config_reload_failure_total 0.0
# HELP os_free_physical_memory_bytes FreePhysicalMemorySize (java.lang<type=OperatingSystem><>FreePhysicalMemorySize)
# TYPE os_free_physical_memory_bytes gauge
os_free_physical_memory_bytes 9.1234304E8
# HELP os_committed_virtual_memory_bytes CommittedVirtualMemorySize (java.lang<type=OperatingSystem><>CommittedVirtualMemorySize)
# TYPE os_committed_virtual_memory_bytes gauge
os_committed_virtual_memory_bytes 2.2226296832E10
# HELP os_total_swap_space_bytes TotalSwapSpaceSize (java.lang<type=OperatingSystem><>TotalSwapSpaceSize)
# TYPE os_total_swap_space_bytes gauge
os_total_swap_space_bytes 0.0
# HELP os_max_file_descriptor_count MaxFileDescriptorCount (java.lang<type=OperatingSystem><>MaxFileDescriptorCount)
# TYPE os_max_file_descriptor_count gauge
os_max_file_descriptor_count 1048576.0
# HELP os_system_load_average SystemLoadAverage (java.lang<type=OperatingSystem><>SystemLoadAverage)
# TYPE os_system_load_average gauge
os_system_load_average 4.97
# HELP os_total_physical_memory_bytes TotalPhysicalMemorySize (java.lang<type=OperatingSystem><>TotalPhysicalMemorySize)
# TYPE os_total_physical_memory_bytes gauge
os_total_physical_memory_bytes 1.073741824E10
# HELP os_system_cpu_load SystemCpuLoad (java.lang<type=OperatingSystem><>SystemCpuLoad)
# TYPE os_system_cpu_load gauge
os_system_cpu_load 1.0
# HELP os_free_swap_space_bytes FreeSwapSpaceSize (java.lang<type=OperatingSystem><>FreeSwapSpaceSize)
# TYPE os_free_swap_space_bytes gauge
os_free_swap_space_bytes 0.0
# HELP os_available_processors AvailableProcessors (java.lang<type=OperatingSystem><>AvailableProcessors)
# TYPE os_available_processors gauge
os_available_processors 6.0
# HELP os_process_cpu_load ProcessCpuLoad (java.lang<type=OperatingSystem><>ProcessCpuLoad)
# TYPE os_process_cpu_load gauge
os_process_cpu_load 0.14194299011052938
# HELP os_open_file_descriptor_count OpenFileDescriptorCount (java.lang<type=OperatingSystem><>OpenFileDescriptorCount)
# TYPE os_open_file_descriptor_count gauge
os_open_file_descriptor_count 717.0
# HELP jmx_scrape_duration_seconds Time this JMX scrape took, in seconds.
# TYPE jmx_scrape_duration_seconds gauge
jmx_scrape_duration_seconds 0.004494197
# HELP jmx_scrape_error Non-zero if this scrape failed.
# TYPE jmx_scrape_error gauge
jmx_scrape_error 0.0
# HELP jmx_scrape_cached_beans Number of beans with their matching rule cached
# TYPE jmx_scrape_cached_beans gauge
jmx_scrape_cached_beans 0.0
# HELP jvm_buffer_pool_used_bytes Used bytes of a given JVM buffer pool.
# TYPE jvm_buffer_pool_used_bytes gauge
jvm_buffer_pool_used_bytes{pool="direct",} 2.3358974E7
jvm_buffer_pool_used_bytes{pool="mapped",} 0.0
# HELP jvm_buffer_pool_capacity_bytes Bytes capacity of a given JVM buffer pool.
# TYPE jvm_buffer_pool_capacity_bytes gauge
jvm_buffer_pool_capacity_bytes{pool="direct",} 2.3358974E7
jvm_buffer_pool_capacity_bytes{pool="mapped",} 0.0
# HELP jvm_buffer_pool_used_buffers Used buffers of a given JVM buffer pool.
# TYPE jvm_buffer_pool_used_buffers gauge
jvm_buffer_pool_used_buffers{pool="direct",} 61.0
jvm_buffer_pool_used_buffers{pool="mapped",} 0.0
# HELP jvm_gc_collection_seconds Time spent in a given JVM garbage collector in seconds.
# TYPE jvm_gc_collection_seconds summary
jvm_gc_collection_seconds_count{gc="ParNew",} 77259.0
jvm_gc_collection_seconds_sum{gc="ParNew",} 2399.831
jvm_gc_collection_seconds_count{gc="ConcurrentMarkSweep",} 1.0
jvm_gc_collection_seconds_sum{gc="ConcurrentMarkSweep",} 0.29
# HELP jmx_config_reload_success_total Number of times configuration have successfully been reloaded.
# TYPE jmx_config_reload_success_total counter
jmx_config_reload_success_total 0.0
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
process_cpu_seconds_total 1759604.89
# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.
# TYPE process_start_time_seconds gauge
process_start_time_seconds 1.608630226597E9
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
process_open_fds 717.0
# HELP process_max_fds Maximum number of open file descriptors.
# TYPE process_max_fds gauge
process_max_fds 1048576.0
# HELP process_virtual_memory_bytes Virtual memory size in bytes.
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 2.2226292736E10
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
process_resident_memory_bytes 4.644765696E9
# HELP jmx_exporter_build_info A metric with a constant ''1'' value labeled with the version of the JMX exporter.
# TYPE jmx_exporter_build_info gauge
jmx_exporter_build_info{version="0.14.0",name="jmx_prometheus_javaagent",} 1.0
# HELP jvm_memory_pool_allocated_bytes_total Total bytes allocated in a given JVM memory pool. Only updated after GC, not continuously.
# TYPE jvm_memory_pool_allocated_bytes_total counter
jvm_memory_pool_allocated_bytes_total{pool="Par Survivor Space",} 1.42928399936E11
jvm_memory_pool_allocated_bytes_total{pool="CMS Old Gen",} 2.862731656E9
jvm_memory_pool_allocated_bytes_total{pool="Code Cache",} 2.8398656E7
jvm_memory_pool_allocated_bytes_total{pool="Compressed Class Space",} 4912848.0
jvm_memory_pool_allocated_bytes_total{pool="Metaspace",} 3.9438872E7
jvm_memory_pool_allocated_bytes_total{pool="Par Eden Space",} 1.32737951722432E14
# HELP jvm_classes_loaded The number of classes that are currently loaded in the JVM
# TYPE jvm_classes_loaded gauge
jvm_classes_loaded 7282.0
# HELP jvm_classes_loaded_total The total number of classes that have been loaded since the JVM has started execution
# TYPE jvm_classes_loaded_total counter
jvm_classes_loaded_total 7317.0
# HELP jvm_classes_unloaded_total The total number of classes that have been unloaded since the JVM has started execution
# TYPE jvm_classes_unloaded_total counter
jvm_classes_unloaded_total 35.0
关于prometheus: celery, redis-export的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于grafana+prometheus+node_exporter、istio prometheus 预警 Prometheus AlertManager 安装 -- 误区、istio prometheus预警Prometheus AlertManager、jvm-exporter整合k8s+prometheus监控报警等相关知识的信息别忘了在本站进行查找喔。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

