如果您对KafkaReplication:ThecaseforMirrorMaker2.0感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解KafkaReplication:ThecaseforM
如果您对Kafka Replication: The case for MirrorMaker 2.0感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解Kafka Replication: The case for MirrorMaker 2.0的各种细节,此外还有关于 java.lang.NoClassDefFoundError: org/apache/spark/streaming/kafka/KafkaUtils、Apache Kafka(八)- Kafka Delivery Semantics for Consumers、Apache Kafka(十)Partitions与Replication Factor 调整准则、Caused by: java.lang.ClassNotFoundException: org.apache.spark.streaming.kafka.KafkaUtils的实用技巧。
本文目录一览:- Kafka Replication: The case for MirrorMaker 2.0
- java.lang.NoClassDefFoundError: org/apache/spark/streaming/kafka/KafkaUtils
- Apache Kafka(八)- Kafka Delivery Semantics for Consumers
- Apache Kafka(十)Partitions与Replication Factor 调整准则
- Caused by: java.lang.ClassNotFoundException: org.apache.spark.streaming.kafka.KafkaUtils

Kafka Replication: The case for MirrorMaker 2.0
Apache Kafka has become an essential component of enterprise data pipelines and is used for tracking clickstream event data, collecting logs, gathering metrics, and being the enterprise data bus in a microservices based architectures. Kafka is essentially a highly available and highly scalable distributed log of all the messages flowing in an enterprise data pipeline. Kafka supports internal replication to support data availability within a cluster. However, enterprises require that the data availability and durability guarantees span entire cluster and site failures.
The solution, thus far, in the Apache Kafka community was to use MirrorMaker, an external utility, that helped replicate the data between two Kafka clusters within or across data centers. MirrorMaker is essentially a Kafka high-level consumer and producer pair, efficiently moving data from the source cluster to the destination cluster and not offering much else. The initial use case that MirrorMaker was designed for was to move data from clusters to an aggregate cluster within a data center or to another data center to feed batch or streaming analytics pipelines. Enterprises have a much broader set of use cases and requirements on replication guarantees.
Multiple vendors and Internet service companies have their own proprietary solutions (Brooklin MirrorMaker from Linkedin, Mirus from Salesforce, uReplicator from Uber, Confluent Replicator from Confluent) for cross-cluster replication that points to the need for the community Apache Kafka to have an enterprise ready cross-cluster replication solution too.

Typical MirrorMaker Use Cases
There are many uses cases why data in one Kafka cluster needs to be replicated to another cluster. Some of the common ones are:
Aggregation for Analytics
A common use case is to aggregate data from multiple streaming pipelines possibly across multiple data centers to run batch analytics jobs that provide a holistic view across the enterprise, for example, a completeness check that all customer requests had been processed..
Data Deployment after Analytics
This is the opposite of the aggregation use case in which the data generated by the analytics application in one cluster (say the aggregate cluster) is broadcast to multiple clusters possibly across data centers for end user consumption.
Isolation
Sometimes access to data in a production environment is restricted for performance or security reasons and data is replicated between different environments to isolate access. In many deployments the ingestion cluster is isolated from the consumption clusters.
Disaster Recovery
One of the most common enterprise use cases for cross-cluster replication is for guaranteeing business continuity in the presence of cluster or data center-wide outages. This would require application and the producers and consumers of the Kafka cluster to failover to the replica cluster.
Geo Proximity
In geographically distributed access patterns where low latency is required, replication is used to move data closer to the access location.
Cloud Migration
As more enterprises have an on prem and cloud presence Kafka replication can be used to migrate data to the public or private cloud and back.
Legal and Compliance
Much like the isolation uses case, a policy driven replication is used to limit what data is accessible in a cluster to meet legal and compliance requirements.
Limitations of MirrorMaker v1
MirrorMaker is widely deployed in production but has serious limitations for enterprises looking for a flexible, high performing and resilient mirroring pipeline. Here are some of the concerns:
Static Whitelists and Blacklists
To control what topics get replicated between the source and destination cluster MirrorMaker uses whitelists and blacklists with regular expressions or explicit topic listings. But these are statically configured. Mostly when new topics are created that match the whitelist the new topic gets created at the destination and the replication happens automatically. However, when the whitelist itself has to be updated, it requires MirrorMaker instances to be bounced. Restarting MirrorMaker each time the list changes creates backlogs in the replication pipeline causing operational pain points.
No Syncing of Topic Properties
Using MMv1, a new or existing topic at the source cluster is automatically created at the destination cluster either directly by the Kafka broker, if auto.create.topics is enabled, or by MirrorMaker enhancements directly using the Kafka admin client API. The problem happens with the configuration of the topic at the destination. MMv1 does not promise the topic properties from the source will be maintained as it relies on the cluster defaults at the destination. Say a topic A had a partition count of 10 on the source cluster and the destination cluster default was 8, the topic A will get created on the destination with 8 partitions. If an application was relying on message ordering within a partition to be carried over after replication then all hell breaks loose. Similarly, the replication factor could be different on the destination cluster changing the availability guarantees of the replicated data. Even if the initial topic configuration was duplicated by an admin, any dynamic changes to the topic properties are not going to be automatically reflected. These differences become an operational nightmare very quickly.
Manual Topic Naming to avoid Cycles
By default, MirrorMaker creates a topic on the destination cluster with the same name as that on the source cluster. This works fine if the replication was a simple unidirectional pipeline between a source and destination cluster. A bidirectional active-active setup where all topics in cluster A are replicated to cluster B and vice versa would create an infinite loop which MirrorMaker cannot prevent without explicit naming conventions to break the cycle. Typically the cluster name is added in each topic name as a prefix with a blacklist to not replicate topics that had the same prefix as the destination cluster. In large enterprises with multiple clusters in multiple data centers it is easy to create a loop in the pipeline if care is not taken to set the naming conventions correctly.
Scalability and Throughput Limitations due to Rebalances
Internally, MirrorMaker uses the high-level consumer to fetch data from the source cluster where the partitions are assigned to the consumers within a consumer group via a group coordinator (or earlier via Zookeeper). Each time there is a change in topics, say when a new topic is created or an old topic is deleted, or a partition count is changed, or when MirrorMaker itself is bounced for a software upgrade, it triggers a consumer rebalance which stalls the mirroring process and creates a backlog in the pipeline and increases the end to end latency observed by the downstream application. Such constant hiccups violate any latency driven SLAs that a service dependent on mirrored pipeline needs to offer.
Lack of Monitoring and Operational Support
MirrorMaker provides minimal monitoring and management functions to configure, launch and monitor the state of the pipeline and has no ability to trigger alerts when there is a problem. Most enterprises require more than just the basic scripts to start and stop a replication pipeline.
No Disaster Recovery Support
A common enterprise requirement is to maintain service availability in the event of a catastrophic failure such as the loss of the entire cluster or an entire data center. Ideally in such an event, the consumers and producers reading and writing to a cluster should seamlessly failover to the destination cluster and failback when the source cluster comes back up. MirrorMaker doesn’t support this seamless switch due to a fundamental limitation in offset management. The offsets of a topic in the source cluster and the offset of the replica topic can be completely different based on the point in the topic lifetime the replication began. Thus the committed offsets in the consumer offsets topic are tracking a completely different location at the source than at the destination. If the consumers make a switch to the destination cluster they cannot simply use the value of the last committed offset at the source to continue. One approach to deal with this offset mismatch is to rely on timestamps (assuming time is relatively in sync across clusters). But timestamps get messy too and we will discuss that at length in the next blog in the series, “A look inside MirrorMaker 2.
Lack of Exactly Once Guarantees
MirrorMaker is not setup to utilize the support for exactly once processing semantics in Kafka and follows the default at least once semantics provided by Kafka. Thus duplicate messages can show up in the replicated topic especially after failures, as the produce to the replicated topic at the destination cluster and the update to the __consumer_offsetstopic at the source cluster are not executed together in one transaction to get exactly once replication. Mostly it is a problem left to the downstream application to handle duplicates correctly.
Too many MirrorMaker Clusters
Traditionally a MirrorMaker cluster is paired with the destination cluster. Thus there is a mirroring cluster for each destination cluster following a remote-consume and local-produce pattern. For example, for 2 data centers with 8 clusters each and 8 bidirectional replication pairs there are 16 MirrorMaker clusters. For large data centers this can significantly increase the operational cost. Ideally there should be one MirrorMaker cluster per destination data center. Thus in the above example there would be 2 MirrorMaker clusters, one in each data center.
What is coming in MirrorMaker 2
MirrorMaker 2 was designed to address the limitations of MirrorMaker 1 listed above. MM2 is based on the Kafka Connect framework and has the ability to dynamically change configurations, keep the topic properties in sync across clusters and improve performance significantly by reducing rebalances to a minimum. Moreover, handling active-active clusters and disaster recovery are use cases that MM2 supports out of the box. MM2 (KIP-382) is accepted as part of Apache Kafka. If you’re interested in learning more, take a look at Ryanne Dolan’s talk at Kafka Summit, and standby for the next blog in this series for “A Look inside MirrorMaker 2”.

java.lang.NoClassDefFoundError: org/apache/spark/streaming/kafka/KafkaUtils
WARN streaming.StreamingContext: spark.master should be set as local[n], n > 1 in local mode if you have receivers to get data, otherwise Spark jobs will not get resources to process the received data.
java.lang.NoClassDefFoundError: org/apache/spark/streaming/kafka/KafkaUtils
at org.apache.spark.examples.streaming.JavaKafkaWordCount.main(JavaKafkaWordCount.java:95)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:738)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:187)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:212)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:126)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.streaming.kafka.KafkaUtils
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 10 more
17/06/29 18:33:37 INFO spark.SparkContext: Invoking stop() from shutdown hook
17/06/29 18:33:37 INFO server.ServerConnector: Stopped ServerConnector@2a76b80a{HTTP/1.1}{0.0.0.0:4040}
17/06/29 18:33:37 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@1601e47{/stages/stage/kill,null,UN
- Kafka Delivery Semantics for Consumers")
Apache Kafka(八)- Kafka Delivery Semantics for Consumers
Kafka Delivery Semantics
在Kafka Consumer中,有3种delivery semantics,分别为:至多一次(at most once)、至少一次(at least once)、以及准确一次(exactly once),下面我们分别介绍这3种Delivery 语义。
1. At Most Once
在message batch在被consumer接收后,立即commit offsets。此时若是在消息处理逻辑中出现异常,则未被处理的消息会丢失(不会再次被读取)。
此场景一个例子如下图:
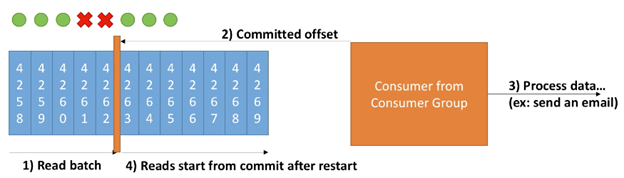
此例流程如下:
- Consumer读一个batch的消息
- 在接收到消息后,Consumer commits offsets
- Consumer 处理数据,例如发送邮件,但是此时一个batch中的最后两条消息由于consumer异常宕机而未被正常处理
- Consumer 重启并重新开始读数据。但是此时由于已经committed offset,所以consumer会在最新的offset处读一个batch的消息,之前上一个batch中由于异常而未被处理的消息会丢失
所以at most once 会有丢失数据的风险,但若是应用可以承受丢失数据的风险,则可以使用此方式。
2. At Least Once
在消息被consumer接收并处理后,offsets才被 commit。若是在消息处理时发生异常,则消息会被重新消费。也就是说,会导致消息被重复处理。
At Least Once 是默认使用的语义,在这种情况下,需要保证应用是idempotent 类型(处理重复的消息不会对应用产生影响)。
此场景一个例子如下:
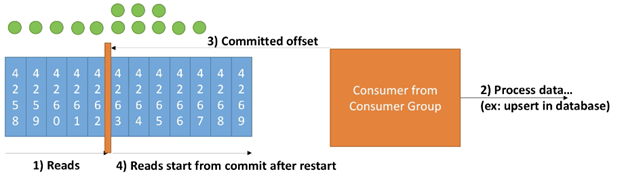
此示例流程如下:
- Consumer 读一个batch的消息
- 在接收到消息并正常处理
- 在consumer 正常处理消息完毕后,commits offset
- 继续读并处理下一个batch 的消息。若是在此过程中发生异常(例如consumer 重启),则consumer会从最近的 offset 开始读一个batch的消息并处理。所以此时会导致有重复消息被处理(此例中为4263、4264、4265)
3. Exactly once
此语义较难实现,在kafka中仅能在Kafka => Kafka的工作流中,通过使用Kafka Stream API 实现。对于Kafka => Sink 的工作流,请使用 idempotent consumer。
对于大部分应用程序,我们应使用at least once processing,并确保consumer端的transformation/processing 是idempotent类型。
4. 构建 idempotent consumer
一个idempotent consumer可以在处理重复消息时,不影响整个应用的逻辑。在ElasticSearch 中,通过一个_id 字段唯一识别一条消息。所以在这个场景下,为了实现idempotent consumer,我们需要对同样_id字段的消息做同样的处理。
之前给出的Elastic Search Consumer的例子中,每条消息的 _id 都是默认随机生成的,也就是说:若是处理之前重复的消息,生成的id也是一条新的随机_id,此行为不符合一个idempotent consumer。对此,我们可以自定义一个_id 模式,修改代码如下:
// poll for new data
while(true){
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMinutes(100));
for(ConsumerRecord record : records) {
// construct a kafka generic ID
String kafka_generic_id = record.topic() + "_" + record.partition() + "_" + record.offset();
// where we insert data into ElasticSearch
IndexRequest indexRequest = new IndexRequest(
"kafkademo"
).id(kafka_generic_id).source(record.value(), XContentType.JSON);
IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
String id = indexResponse.getId();
logger.info(id);
try {
Thread.sleep(1000); // introduce a small delay
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
打印出id结果为:

可以看到新的 id 由 kafka topic + partition + offset 这3 部分组成,可以唯一定位一个 record。所以即使重复处理一条record,它发往 ElasticSearch 的 id 也是一样的(即处理逻辑一样)。在这个场景下,即为一个imdepotent consumer。
Partitions与Replication Factor 调整准则")
Apache Kafka(十)Partitions与Replication Factor 调整准则
Partitions与Replication Factor调整准则
Partition 数目与Replication Factor是在创建一个topic时非常重要的两个参数,这两个参数的取值会直接影响到系统的性能与稳定性。
尽量在第一次创建一个topic时就指定这两个参数,因为
- 如果Partition 数目在之后再次做调整,则会打乱key的顺序保证(同样的key会分布到不同的partition上)
- 如果Replication Factor在之后再次增加,则会给集群带来更大的压力,可能会导致性能下降
1. Partition 数目
一般来说,每个partition 能处理的吞吐为几MB/s(仍需要基于根据本地环境测试后获取准确指标),增加更多的partitions意味着:
- 更高的并行度与吞吐
- 可以扩展更多的(同一个consumer group中的)consumers
- 若是集群中有较多的brokers,则可更大程度上利用闲置的brokers
- 但是会造成Zookeeper的更多选举
- 也会在Kafka中打开更多的文件
调整准则:
- 一般来说,若是集群较小(小于6个brokers),则配置2 x broker数的partition数。在这里主要考虑的是之后的扩展。若是集群扩展了一倍(例如12个),则不用担心会有partition不足的现象发生
- 一般来说,若是集群较大(大于12个),则配置1 x broker 数的partition数。因为这里不需要再考虑集群的扩展情况,与broker数相同的partition数已经足够应付常规场景。若有必要,则再手动调整
- 考虑最高峰吞吐需要的并行consumer数,调整partition的数目。若是应用场景需要有20个(同一个consumer group中的)consumer并行消费,则据此设置为20个partition
- 考虑producer所需的吞吐,调整partition数目(如果producer的吞吐非常高,或是在接下来两年内都比较高,则增加partition的数目)
以上仅是几个基本准则,最重要的是:在本地集群做测试,以获取一个更合适的partition数目,不同的集群会有不同的性能。
2. Replication factor
此参数决定的是records复制的数目,建议至少 设置为2,一般是3,最高设置为4。更高的replication factor(假设数目为N)意味着:
- 系统更稳定(允许N-1个broker宕机)
- 更多的副本(如果acks=all,则会造成较高的延时)
- 系统磁盘的使用率会更高(一般若是RF为3,则相对于RF为2时,会占据更多50% 的磁盘空间)
调整准则:
- 以3为起始(当然至少需要有3个brokers,同时也不建议一个Kafka 集群中节点数少于3个节点)
- 如果replication 性能成为了瓶颈或是一个issue,则建议使用一个性能更好的broker,而不是降低RF的数目
- 永远不要在生产环境中设置RF为1
3. 集群调整建议
一个已被业界接受的准则是:
- 一个broker不应该承载超过2000 到 4000 个partitions(考虑此broker上所有来自不同topics的partitions)。同时,一个Kafka集群上brokers中所有的partitions总数最多不应超过20,000个。
此准则基于的原理是:在有broker宕机后,zookeeper需要重新做选举。若是partitions数目过多,则需要执行大量的leader elections。
另外几个常规原则有:
- 如果集群中需要更多的partitions,则优先考虑增加brokers
- 如果集群中需要20,000 个以上的partitions,则可以参考Netflix的模型,创建更多的Kafka 集群
最后需要注意的是:不要为一个topic创建超过1000个的partitions。我们也并不需要1000个partitions才能达到很高的吞吐。在开始的时候,选择一个更合理的partition数目,然后测试性能,根据测试结果再调整partitions 数目。

Caused by: java.lang.ClassNotFoundException: org.apache.spark.streaming.kafka.KafkaUtils
Successfully started service ''org.apache.spark.network.netty.NettyBlockTransferService'' on port 37493.
17/06/29 18:10:40 INFO netty.NettyBlockTransferService: Server created on 192.168.8.29:37493
17/06/29 18:10:40 INFO storage.BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
17/06/29 18:10:40 INFO storage.BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.8.29, 37493, None)
17/06/29 18:10:40 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.8.29:37493 with 912.3 MB RAM, BlockManagerId(driver, 192.168.8.29, 37493, None)
17/06/29 18:10:40 INFO storage.BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.8.29, 37493, None)
17/06/29 18:10:40 INFO storage.BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.8.29, 37493, None)
17/06/29 18:10:40 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4aeaadc1{/metrics/json,null,AVAILABLE}
17/06/29 18:10:40 WARN streaming.StreamingContext: spark.master should be set as local[n], n > 1 in local mode if you have receivers to get data, otherwise Spark jobs will not get resources to process the received data.
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/streaming/kafka/KafkaUtils
at org.apache.spark.examples.streaming.JavaKafkaWordCount.main(JavaKafkaWordCount.java:95)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:738)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:187)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:212)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:126)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.streaming.kafka.KafkaUtils
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 10 more
17/06/29 18:10:40 INFO spark.SparkContext: Invoking stop() from shutdown hook
17/06/29 18:10:40 INFO server.ServerConnector: Stopped ServerConnector@2a76b80a{HTTP/1.1}{0.0.0.0:4040}
17/06/29 18:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@1601e47{/stages/stage/kill,null,UNAVAILABLE}
关于Kafka Replication: The case for MirrorMaker 2.0的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于 java.lang.NoClassDefFoundError: org/apache/spark/streaming/kafka/KafkaUtils、Apache Kafka(八)- Kafka Delivery Semantics for Consumers、Apache Kafka(十)Partitions与Replication Factor 调整准则、Caused by: java.lang.ClassNotFoundException: org.apache.spark.streaming.kafka.KafkaUtils的相关信息,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

