针对laravel安装intervention/image图像处理扩展报错intervention/image2.3.7requiresext-fileinfo这个问题,本篇文章进行了详细的解答,同时
针对laravel 安装 intervention/image 图像处理扩展 报错 intervention/image 2.3.7 requires ext-fileinfo这个问题,本篇文章进行了详细的解答,同时本文还将给你拓展2018_CVPR_Interactive Image Segmentation with Latent Diversity、AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks 笔记、CVPR2018: Generative Image Inpainting with Contextual Attention 论文翻译、解读、ims.emergency.vo.domain.TreatmentInterventionForAdviceLeafletVoAssembler的实例源码等相关知识,希望可以帮助到你。
本文目录一览:- laravel 安装 intervention/image 图像处理扩展 报错 intervention/image 2.3.7 requires ext-fileinfo
- 2018_CVPR_Interactive Image Segmentation with Latent Diversity
- AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks 笔记
- CVPR2018: Generative Image Inpainting with Contextual Attention 论文翻译、解读
- ims.emergency.vo.domain.TreatmentInterventionForAdviceLeafletVoAssembler的实例源码

laravel 安装 intervention/image 图像处理扩展 报错 intervention/image 2.3.7 requires ext-fileinfo
在安装 intervention/image 图像处理扩展 报错 fileinfo is missing
报错信息如下:
\blog>composer require intervention/image
Using version ^2.3 for intervention/image
./composer.json has been updated
Loading composer repositories with package information
Updating dependencies (including require-dev)
Your requirements could not be resolved to an installable set of packages.
Problem 1
- intervention/image 2.3.7 requires ext-fileinfo * -> the requested PHP extension fileinfo is missing from your system.
- intervention/image 2.3.6 requires ext-fileinfo * -> the requested PHP extension fileinfo is missing from your system.
- intervention/image 2.3.5 requires ext-fileinfo * -> the requested PHP extension fileinfo is missing from your system.
- intervention/image 2.3.4 requires ext-fileinfo * -> the requested PHP extension fileinfo is missing from your system.
- intervention/image 2.3.3 requires ext-fileinfo * -> the requested PHP extension fileinfo is missing from your system.
- intervention/image 2.3.2 requires ext-fileinfo * -> the requested PHP extension fileinfo is missing from your system.
- intervention/image 2.3.1 requires ext-fileinfo * -> the requested PHP extension fileinfo is missing from your system.
- intervention/image 2.3.0 requires ext-fileinfo * -> the requested PHP extension fileinfo is missing from your system.
出现此错误的原因是 php.ini 中的 fileinfo 扩展没有开启
开启 extension=php_fileinfo.dll
再重新安装就可以了’

2018_CVPR_Interactive Image Segmentation with Latent Diversity
基本信息
CVPR 2018
Interactive Image Segmentation with Latent Diversity
笔记
-
主要研究内容是交互式图像分割。偏重于图像编辑应用领域。大概的理解,就是 PS 里面的魔棒什么的吧。
-
问题描述,用户在一张图片上点击(选取正负样本点),生成感兴趣的分割目标。问题的特点是多模态的(multimodality),用户的点击,你不能确定他是想选中 jacket,还是整个人?
-
本文的目标是,尽可能减少用户的点击,就能获得一定满意程度的目标分割实例。
-
整体的思路是:
our approach trains a single feed-forward stream that generates diverse solutions and then selects among them.
生成一系列的候选分割目标,然后从中间选择一张的目标分割图片。
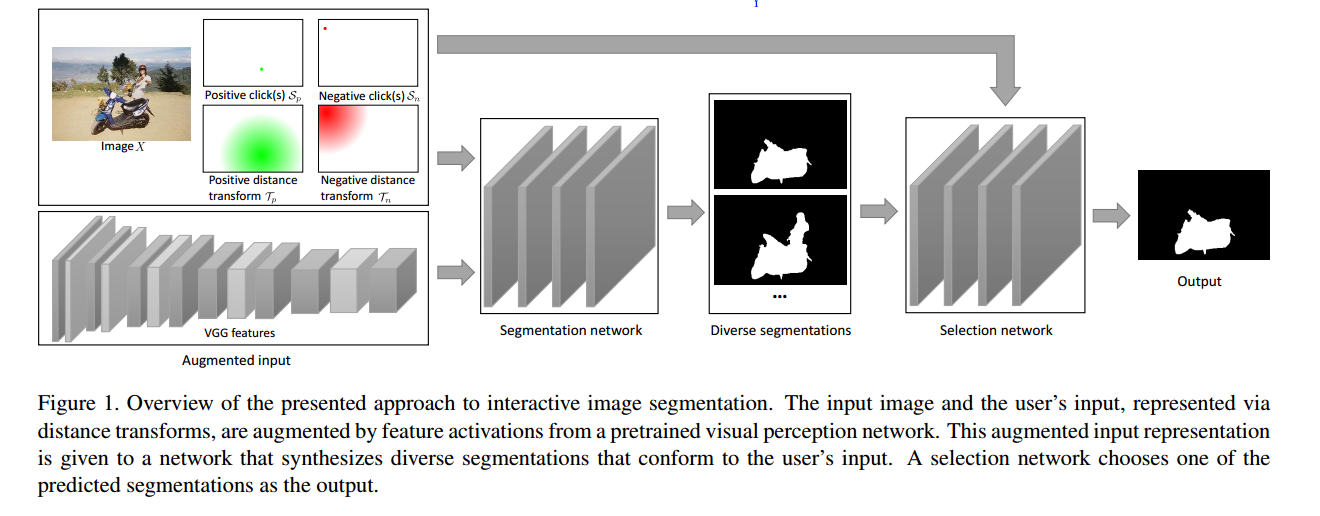
整体分成两个步骤:
- segmentation network (函数 $f$)
- 输入:原始图片 $X$, 正负点击点 $S_p$ 和 $S_n$, 正负点击距离转换 $T_p$ 和 $T_n$,VGG 提取后的特征。
- 输出:M 个 Segmentation Mask,像素值区间是 [0,1] 实数,连续的。
- selection network (函数 $g$)
- 输入:原始图片 $X$, 正负点击点 $S_p$ 和 $S_n$, 正负点击距离转换 $T_p$ 和 $T_n$, 以及 M 个 Segmentation Masks。
- 输出:从 M 个中选择一个作为输出。
- segmentation network (函数 $f$)
-
关于 Loss 函数 Segmentation network 使用的 loss 是作者自己构造的:
其中,这是一个简化版本(放宽限制)的 Jaccard IoU 距离。其中 $\odot$ 表示阿达马元素乘积。其实就是统计预测正确的点有多少个,当然实际上不是这样。 值得注意的是 也就是说 A 中值是离散的,而 B 中是连续的。 selection network 的 loss 函数是: 其中,$\phi_i $ 是 mask 的索引,用于最小化其和 $Y_i$ 之间的 Jaccard 距离。
也就是说 A 中值是离散的,而 B 中是连续的。 selection network 的 loss 函数是: 其中,$\phi_i $ 是 mask 的索引,用于最小化其和 $Y_i$ 之间的 Jaccard 距离。 -
Segmentation network 的设计主要参考 Multi-Scale Context Aggregation by Dilated Convolutions, 主要特点是空洞卷积获得多尺度特征。主要结构如下:
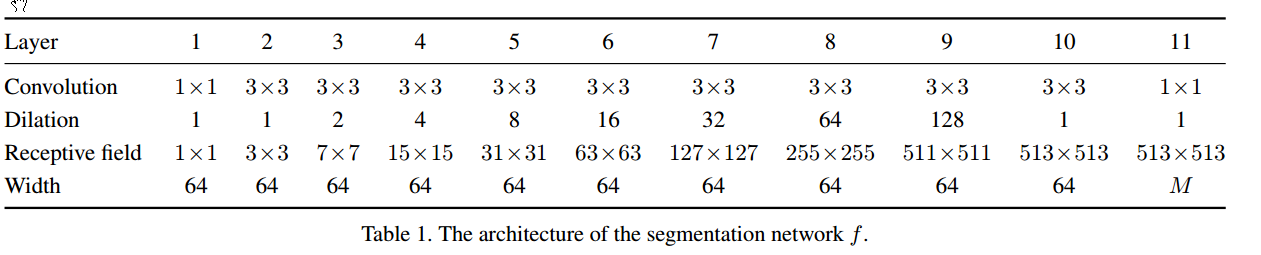 Selection network 本质上是一个分类网络,本文沿用上面的网络结构,做了一些改变,第一层换成一个全局平均池化层,最后的全分辨率预测层,也增加一个全局平均池化层。
Selection network 本质上是一个分类网络,本文沿用上面的网络结构,做了一些改变,第一层换成一个全局平均池化层,最后的全分辨率预测层,也增加一个全局平均池化层。 -
关于数据集。 作者使用了
+ Semantic BoundariesDataset (SBD) + GrabCut + DAVIS + Microsoft COCONote that we do not train on GrabCut, DAVIS, or COCO. Our model is trained only once, on the SBD training set.
-
关于结果
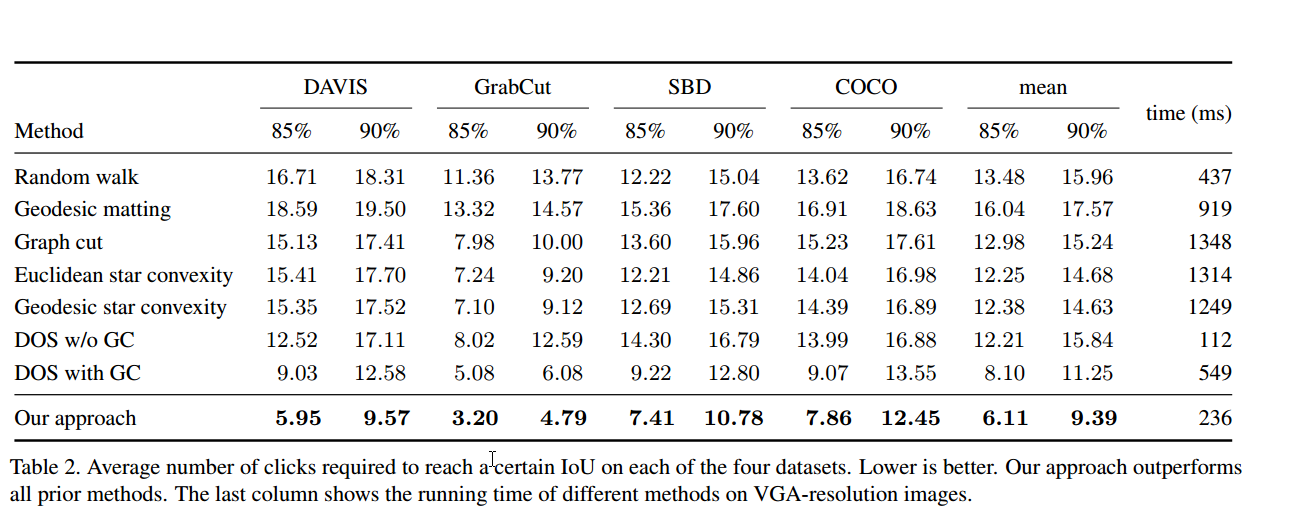
 因为作者的目的是减少点击次数,这个 U-Net 上面的数据貌似不是很好,添加这个 Unet 和 CAN 的纵向对比试验,也就是说 SBD 和 COCO 上的数据集数据是怎么样呢?都做了怎么多了,应该不差这俩个吧・・・・
因为作者的目的是减少点击次数,这个 U-Net 上面的数据貌似不是很好,添加这个 Unet 和 CAN 的纵向对比试验,也就是说 SBD 和 COCO 上的数据集数据是怎么样呢?都做了怎么多了,应该不差这俩个吧・・・・
总结
这个整体方案还是第一次见到,用的网络还是在其他网路的基础上,做了小修改。
第一次接触交互式任务。主要特点就在这仿真生成模拟点击,在实际使用的过程中相当于增加了两个通道,本文的相较于普通的图像增加了四个通道。
关于交互式点击模拟:  对于图像大致方法就是采样 20 次,之间关于分布概率的计算采用测地距离。第一次是根据 mask 进行正例的采样,以后每次采样都是从当前分类错误的集合 $\mathcal {O}''$ 中采样。每次采样,都会刷新预测结果,影响下一次采样。根据这个分布进行采样,应该是尽量采样那些较大块未分类正确的区域,我的理解。(这块不是很了解,欢迎讨论。)
对于图像大致方法就是采样 20 次,之间关于分布概率的计算采用测地距离。第一次是根据 mask 进行正例的采样,以后每次采样都是从当前分类错误的集合 $\mathcal {O}''$ 中采样。每次采样,都会刷新预测结果,影响下一次采样。根据这个分布进行采样,应该是尽量采样那些较大块未分类正确的区域,我的理解。(这块不是很了解,欢迎讨论。)

AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks 笔记
AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks 笔记
这篇文章的任务是 “根据文本描述” 生成图像。以往的常规做法是将整个句子编码为condition向量,与随机采样的高斯噪音$z$进行拼接,经过卷积神经网络(GAN,变分自编码等)来上采样生成图像。这篇文章发现的问题是:仅通过编码整个句子去生成图像会忽略掉一些细粒度的信息,而这些细粒度的信息是由单词层面来决定的(例如颜色、形状等)。
解决的方法是在生成过程中引入对单词的注意力机制,这种注意力机制需要把相关的单词与对应的图像区域匹配起来, 如果让我自己去设计这种匹配关系,我的第一反应是要先进行大量的人工标注(根据单词先人工框出来图像中对应的区域),这样搞的话光标注就需要巨大的人力与时间(特别是在COCO这么大的数据集上。。。)。
AttnGAN没有对数据集进行额外的标注, 利用生成过程中的 $C \times N \times N$ feature map ,有 $N^{2}$ 个位置。每一位置的向量维度是 $C$,为了表示某一位置与句子中某一单词的相关性,可以根据 某一位置向量与单词向量的内积 / 某一位置向量与句子中所有单词向量内积之和 来得到与某一单词的权重(相关)系数,那么在某一位置上的单词表征可以表示为所有单词向量的加权和。

方法

模型包含两个部分,
- 注意力生成网络
- 多模态注意力相似模型(DAMSM,是个匹配网络)
注意力生成网络包含多个阶段的生成(这里是三次生成,只要计算资源足,还可以加), coarse-to-fine的图像生成模式。 DAMSM需要在真实的数据对上预训练,相当于给生成网络加了一个监督信息,使生成的图像能像真实图像那样与相应的文本匹配。
Attentional Generative Network(注意力生成网络)
输入文本,经过Text Encoder(用的是双向LSTM)编码输出“整句特征”(global sentence vector)$\bar{e}$ 和拼接起来的“单词特征” $e \in \mathbb{R}^{D \times T}$。 $\bar{e}$ 经过 Conditioning Augmentation(具体可以看stackgan和vae的文章,目的是为了降维以及增加多样性) 进行降维转换来作为条件向量,用 $F^{ca}$ 来表示Conditioning Augmentation操作。
第一次的image features的生成过程为: $$ h_{0} = F_{0}(z, F^{ca}(\bar{e})) $$ 从图中可以看出$F_{0}$代表着一系列的上采样操作,但还没有生成最后的图像,输出了一个隐含特征$h_{0}$。这个隐含特征已经初具图像的位置和物体信息。后面的生成过程为: $$ h_{i} = F_{i}(h_{i-1}, F^{attn}{i}(e,h{i-1})) $$ 这里面最重要的就是$F_{i}^{attn}$的操作,也是作者所提出的创新点,即如何将单词信息融入到生成的过程中去,而且不同单词对于图像中不同区域的attention作用也是不同的。先来看看$F^{attn}{i}$的操作,输入是单词向量矩阵 $e$ 以及前一阶段所得到的image features $h{i-1}$($h \in \mathbb{R}^{\hat{D} \times N}$)。单词向量要经过一次乘积转换(可以加个全连接层)来改变维度到$\hat{D}$维,$e^{''}=Ue$ where $U\in\mathbb{R}^{\hat{D}\times D}$,与image features的维度保持一致, 有助于后面进行内积操作计算相似性。 $h$ 中的每一列其实都代表着图像的一个sub-region,其中$N=\sqrt{N}\times \sqrt{N}$。对于第 $j$ 个sub-region,用句子中所有的单词向量来进行表示,那么相关的单词向量应具有更大的权重,不相关的单词向量与其的相关权重应很小,每个sub-region进行单词向量加权和的结果称为“word-context”(相当于加入了具有侧重点的文本condition)。每一个sub-region与所有的单词向量权重计算以及最后的word-context计算过程为 $$ c_{j} = \sum\limits_{i=0}\limits^{T-1}\beta_{j,i}e^{''}{i}, where \beta{j,i}=\frac{exp(s^{''}{j,i})}{\sum{k=0}^{T-1}exp(s^{''}{j,k})} $$ $s^{''}{j,i}=h^{T}{j}e^{''}{i}$, $\beta_{j,i}$表示当生成图像第$j$个子区域时,第$i$个单词所获得的关注程度。$c_{j}$代表着第$j$个子区域的word-context向量,$F^{attn}$就是为了生成所有子区域的word-context向量:$F^{attn}(e,h)=(c_{0},c_{1},\ldots,c_{N-1})\in \mathbb{R}^{\hat{D}\times N}$。
图像的生成是根据Image features $h_{i}$ $$ \hat{x_{i}}=G_{i}(h_{i}) $$ 在注意力生成网络里的损失也就是常规的conditionGAN损失的变种(包含带有文本条件与不带有条件):
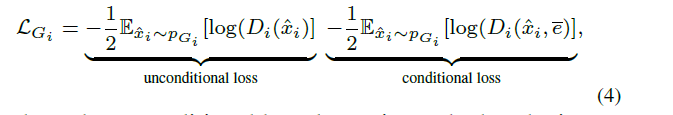

Deep Attentional Multimodal Similarity Model(匹配模型)
这一部分的提出相当于额外加了一个文本-图像匹配的监督信息,由于DAMSM是在真实数据集上预训练好的(即真实图像与相关的文本匹配损失会比较小),在输入生成的图像与相关的文本信息时,它会倒逼着注意力生成网络生成更加真实且与文本相关的图像。在这一模型中,从两个部分来计算匹配损失,分别是基于整个句子的和基于逐个单词的。
图像编码器(image encode)将图像下采样到feature matrix $f\in \mathbb{R}^{768\times 289}$(这是从$768\times 17\times 17$ reshape 过来的),为了度量图像与文本的相似性,文本与图像的特征维度应保持一致,在这里,是将图像的特征进行转换与单词向量的维度保持一致: $$ v=Wf, \bar{v}=\bar{W}\bar{f} $$ $v$是图像特征转换过之后的特征$v\in \mathbb{R}^{D\times 289}$,$\bar{v}\in \mathbb{R}^{D}$表示图像的全局向量,$\bar{f}$是从Inception-v3网络的最后一层(全连接分类层)提取出来的,作为全局特征。
经过维度统一之后,下面的单词层面的匹配操作类似于attention生成过程中的word-context计算过程,只不过这里是针对每个单词计算出相应的sub-region的加权和,也就是说每个单词都有个视觉信息的加权表征。计算过程如下: $$ s=e^{T}v $$ $s\in \mathbb{R}^{T\times 289}$,表示单词与sub-region的内积来度量相似性。这里搞了一个归一化,说是能提升效果 $$ \bar{s}{i,j} = \frac{exp(s{i,j})}{\sum_{k=0}^{T-1}exp(s_{k,j})} $$ 也就是针对同一个sub-region,所有单词相似性的归一化。
针对每一个单词所有的sub-region视觉信息加权和称为“region-context”向量,记作$c_{i}$,计算过程为 $$ c_{i}=\sum_\limits{j=0}^\limits{288}\alpha_{j}v_{j}, where \alpha_{j}=\frac{exp(\gamma_{1}\bar{s}{i,j})}{\sum{k=0}^{288}exp(\gamma_{1}\bar{s}{i,k})} $$ $\gamma{1}$表示对于相关的sub-regions扩大它的影响(相似性值越大的占的比重更大)。这样每一个单词都有一个对应的region-context视觉信息,可以进行单词-视觉信息相关的匹配度量,这里用余弦距离来衡量差异 $$ R(c_{i},e_{i})=(c_{i}^{T}e_{i})/(||c_{i}||||e_{i}||) $$ 基于单词层面来衡量整个图像与文本的相似性 $$ R(Q,D)=log\left(\sum_\limits{i=1}^\limits{T-1}exp(\gamma_{2}R(c_{i},e_{i}))\right)^{\frac{1}{\gamma_{2}}} $$ 之所以用这个形式,是为了突出最相关的word-to-region-context pair,用$\gamma_{2}$来调节突出程度,当$\gamma_{2} \rightarrow \infty$ 时,上式结果
趋近于$\max_{i=1}^{T-1}R(c_{i},e_{i})$。
DAMSM的监督标签是"图片与整个句子是否匹配"。用图片去匹配句子,目标函数的后验概率形式为
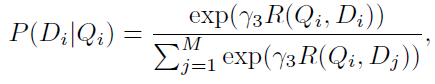
$Q$表示图像,$D$表示句子
基于单词水平的匹配损失函数为:

对应的,在以句子匹配图像的情况下,损失函数为

另外,基于整个句子的匹配损失设计与上面的类似,不同点是直接用全局向量计算相似距离。 $$ R(Q,D)=(\bar{v}^{T}\bar{e}/\left(||\bar{v}||||\bar{e}||\right)) $$ 

CVPR2018: Generative Image Inpainting with Contextual Attention 论文翻译、解读
CVPR2018: Generative Image Inpainting with Contextual Attention 论文翻译、解读
注:博主是大四学生,翻译水平可能比不上研究人员的水平,博主会尽自己的力量为大家翻译这篇论文。翻译结果仅供参考,提供思路,翻译不足的地方博主会标注出来,请大家参照原文,请大家多多关照。
未经允许,严禁转载。
0. 译者序
题目翻译:基于内容感知生成模型的图像修复
介绍:这篇文章也被称作deepfill v1,作者的后续工作 "Free-Form Image Inpainting with Gated Convolution" 也被称为deepfill v2。两者最主要的区别是,v2支持任意形状的mask(标记图像待修复区域的罩子),且支持标记黑线来指定修复的大致形状。
相关资料:
deepfill v1官方介绍
deepfill v2官方介绍
deepfill v1官方Tensorflow代码
deepfill v2非官方Tensorflow代码
量子位对deepfill v2的介绍(知乎)
多种感知模型(Attention Model)的介绍
卷积核的膨胀(dilation)
近期在做有关图像修复的工作,正好看到CVPR2018上这篇Jiahui Yu(余家辉)大牛的著作deepfill v1,在此基础上作者与其导师Thomas S.Huang(黄煦涛,计算机视觉之父)等人发布了deepfill v2 。本博文只关注deepfill v1,今后会更新deepfill v2的翻译解读。
引言 Abstract
近期的基于深度学习的图像修复方法展现了很大的潜力,这些方法都能生成看似合理的图像结构及纹理,但在修复区域的边界,经常会生成扭曲的结构和模糊的图像,这是因为卷积神经网络无法从图像较远的区域提取信息导致的。不过,传统的纹理和斑块(patch)的修复能取得比较好的效果(因为他们只需要从周围区域借鉴图像)。
作者基于上述这些现象,提出了一种新的基于深度生成模型的方法,不仅可以生成新的图像结构,还能够很好地利用周围的图像特征作为参考,从而做出更好的预测。
该模型是一个前馈全卷积神经网络,可以处理包含多个缺失区域的图像,且在修复图像的时候,输入的图像大小没有限制。作者在人脸图像、自然图像、纹理图像等测试集上,都产生了比现在已有的方法更好的效果。
1. 介绍 Introduction
图像修复(填补缺失像素值)在计算机视觉领域是一项很重要的研究工作。其核心挑战就是能够综合现实情况(realistic)和图像的语义(semantic),来修补缺失的图像。
早期的图像修复原理,都类似于纹理的合成,通过匹配(match)和复制(copy)背景的斑块来填补缺失的图像。这些方法在背景修复(background inpainting)任务上都有着比较好的结果,但他们无法修复一些比较复杂的,不可重复的图像结构(类似于人脸、物体)。更多地,这些方法不能捕捉到图像的高维特征(high-level semantics)。
近期基于深度卷积网络和GAN(生成对抗网络)的图像修复方法,其原理都是通过自编码器,结合对抗网络训练的方式,来让生成的图像和存在的图像保持一致性。
可惜的是,这些基于CNN的方法,通常都会在边界生成扭曲的结构和模糊的纹理。作者发现是因为卷积神经网络无法很好地提取远距离的图像内容(distant contextual information)和不规则区域的图像内容(hole regions)。
举例来说,一个像素点的内容被64个像素点以外的内容影响,那么他至少要使用6层3x3的卷积核才能够有这么大的感受野(receptive filed)。而且由于这个感受野的形状是非常标准且对称的矩形(regular and symmetric grid),所以在不规则的一些图像内容上,无法很好地给对应特征分配正确的权值。
近期的一项研究基于生成斑块和匹配斑块的相似性优化问题(optimize problem),能够提高效果,但由于是基于优化问题,需要非常多次的梯度下降迭代,以及处理一张512x512的图像需要很长的时间。
作者提出了一个带有内容感知层(contextual attention layer)的前馈生成网络,这个网络的训练分为两个阶段。第一阶段是一个简单的卷积网络,通过不断修复缺失区域来产生损失值reconstruction loss,修复出的是一个比较模糊的结果。第二阶段是内容感知层的训练,其核心思想是:使用已知图像斑块的特征作为卷积核来加工生成出来的斑块,来精细化这个模糊的修复结果。它是这样来设计和实现的:用卷积的方法,来从已知的图像内容中匹配相似的斑块,通过在全通道上做softmax来找出最像待修补区域的斑块,然后使用这个区域的信息做反卷积(deconvolution)从而来重建该修补区域。
(译者注:这里的思想应该是,假设我有一个待修补区域x,我要通过卷积的方法,从整个图像出匹配出几个像x的区域a, b, c, d,然后从a, b, c, d中使用softmax的方法挑选出最像x的那个区域,然后通过反卷积的方式,来生成x区域的图像。)
这个内容感知模块,还有着空间传播层(spatial propagation layer)来提高感知的空间一致性。
为了让网络能“想象”(hallucinate)出新的图像内容,有着另一条卷积通路(convolutional pathway),这条通路和内容感知卷积通路是平行的。这两个通路最终聚合并送入一个大哥哥来产生最后的输出。第二阶段的网络通过两个损失值来训练(重建损失值 reconstruction losses 和两个WGAN-GP损失(Wasserstein GAN losses),其中一个WGAN来观察全局图像,另一个WGAN来观察局部生成出的图像。
网络架构如下图:
图1
作者的主要贡献总结如下:
作者提出了一种全新的内容感知层(contextual attention layer)来从距离遥远的区域提取近似待修复区域的特征。
介绍了几种技术(图像修复网络增强、全局和局部的WGANs、空间衰减的重建损失(spatially discounted reconstruction loss, 会在下文中讲到)来提高训练的稳定性和速度,上述这些方法都基于最近的图像修复生成网络。最终,作者能够在一周内训练出该网络而不是两个月。(据译者在github issue里看到,作者使用的是一个GTX1080Ti进行训练)
作者的前馈生成网络在众多具有挑战的数据集(例如CelebA、CelebA-HQ、DTD textures、ImageNet、Places2)实现了高质量的图像修复结果
2. 相关研究 Related Work
2.1 图像修复 Image Inpainting
现有的图像修复技术分为两个流派,一个是传统算法,其基于扩散(diffusion)或斑块(patch-based),只能提取出低维特征(low-level features)。另一个是基于学习的算法,比如训练深度卷积神经网络来预测像素值。
传统的扩散或斑块算法,通常使用变分算法(variational algorithms)或斑块相似性来将图像信息从背景区域传播到缺失区域内,这些算法在静态纹理(stationary textures)比较适用,但在处理一些非静态纹理(non-stationary textures)比如自然景观就不行了。
Simakov等人提出的基于双向斑块相似性的方法(bidirectional patch similarity-based scheme)可以更好地模拟非静态纹理,但计算量十分巨大,无法投入使用。
最近,深度学习和基于GAN的方法在图像修复领域很有前途,初始的研究是将卷积网络用于图像去噪、小区域的图像修复。内容编码器(Context Encoder)首先被用于训练大面积图像修复的深度神经网络。它使用GAN的损失值加上2-范数(MSE)作为重建损失值(reconstruction loss)来作为目标函数。
更进一步的研究,比如Iizuka等人提出了利用全局和局部的判别器(Discriminator)来作为GAN的对抗损失,全局判别器用于判定整幅图像的语义一致性,局部判别器专注于小块生成区域的语义,以此来保证修复出的图像的高度一致性。
此外,Iizuka等人还使用了扩展卷积(dialated convolutions)的方式来替代内容编码器的全连接层,这两种方法的目标都是为了提高输出神经元(output neurons)的感受野的大小。
与此同时,还有多项研究专注于人脸的图像生成修复。例如Yeh等人通过在缺失区域的周围寻找一种编码,来尝试解码来获得完整的图像。Li等人引入了额外的人脸完整度作为损失值来训练网络。然而这些方法通常都需要图像的后续处理,来修复缺失区域边界上的色彩一致性(color coherency)。
2.2 感知模型 Attention Modeling
(译者注:感知模型在参考资料里有)
关于深度卷积网络中的空间感知问题有着很多的研究。在这里,作者回顾了几个具有代表性的内容感知模型。
首先是Jaderberg等人提出的STN(spatial transformer network),用来进行目标分类任务。由于整个网络专注于全局迁移问题(global transformation),所以在斑块大小的问题上不合适,不能用于图像修复。
第二个是Zhou等人的表征扩散(appearance flow),就是从输入的图像中查找哪些像素点应该被移动到待修复区域,这种方法适合在多个同样的物体之间进行图像修复。但从背景区域还原前景效果不是很好(译者注:可能是因为找不到哪些像素点可以flow到前景)。
第三个是Dai等人提出的空间感知卷积核的学习和激活。
这些方法都不能很好地从背景中提取有效的特征。
3. 改进图像修复的生成网络 Improved Generative Inpainting Network
(译者注:为了不让读者读懵了,译者在这里说明一下接下来的论文结构。作者在第三部分改进了Iizuka等人提出的图像修复网络,在第四部分将内容感知层加入这个修复网络,从而构建出完整的图像修复网络)
作者通过复现近期的图像修复模型(其实就是上文中提到的用全局和局部Discriminator的Iizuka的方案),以及做出多种提升方法来构建生成模型。Iizuka的模型在人脸图像、建筑图像、自然图像都能有较好的结果。
1) 粗细网络 Coarse-to-fine network architecture
网络结构如下图(其实就是上文中网络结构的简化版):
图2
整个网络的输入和输出和Iizuka的网络设定是一样的,也就是说,生成网络的输入是一张带有白色mask的图像,以及一个用于表示mask区域的二进制串,输出是一张完整的图像。作者配对(pair)了输入的图像和对应的二进制mask,这样就可以处理任意大小、任意位置、任意形状的mask了。
网络的输入是带有随机矩形缺失区域的256x256图像,训练后的模型可以接受包含多个孔洞的任意大小的图像。
在图像修复任务中,感受野的大小决定了修复的质量,Iizuka等人通过使用扩张卷积(dilated convolution)来增大感受野,为了进一步增大感受野,作者提出了粗细网络的概念。
(译者注:这里扩张卷积的意思就是,将卷积核填充扩大,见参考资料,以此来提高感受野的大小,在下文中会反复提到。)
粗网络(Coarse network)仅仅使用使用重构损失进行训练,而细网络(Refinement network)使用重构损失+两个GAN损失进行训练。
直观上,细网络比带有缺失区域的图像看到的场景更完整(译者注:因为粗网络已经修复了一部分),因此编码器比粗网络能更好地学习特征表示。这种二阶段(two-stage)的网络架构类似于残差学习(residual learning)或是深度监督机制(deep supervision)。
为了提高网络的训练效率以及减少参数的数量,作者使用了窄而深(thin and deep)的网络,在layer的实现方面,作者对所有layer的边界使用了镜像填充(mirror padding),移除了批归一化(batch normalization),原因是作者发现批归一化会降低修复的图像色彩的一致性。此外,作者使用了ELUs来替代ReLU,通过对输出卷积核的值的裁剪(clip the output filter values)来替代激活函数tanh或是sigmoid。另外,作者发现将全局和局部的特征表示分开,而不是合并到一起(Iizuka的网络合并到一起了),能够更好地对GAN进行训练。
2) 全局和局部的WGAN Global and local Wasserstein GANs
不同于先前的使用DCGAN进行图像修复,作者提出了WGAN-GP的修改版本。通过在第二阶段结合全局和局部的WGAN-GP损失来增强全局和局部的一致性(这一点是受Iizuka网络的启发)。WGAN-GP损失是目前已有的用于图像生成的GAN中表现最好的损失值(使用1-范数重建损失,表现的会更好)。
(译者注:以下是公式证明推导来说明WGAN损失的有效性,译者的数学水平不够,请大家见谅,详细推导请参照原文)
更精确的说,WGAN使用了Earth-Mover距离来比较生成图像和真实图像的分布。它的目标函数应用了Kantorovich-Rubinstein duality……
3) 空间衰减重构损失 Spatially discounted reconstruction loss
对于图像修复问题,一个缺失区域可能会有多种可行的修复结果。一个可行的修复结果可能会和原始图像差距很大,如果使用原始图像作为唯一的参照标准(ground truth),计算重构损失(reconstruction loss)时就会误导卷积网络的训练过程。
直观上来说,在缺失区域的边界上修复的结果的歧义性(ambiguity),要远小于中心区域(译者注:这里的意思是边界区域的取值范围要比中心区域小)。这与强化学习中的问题类似。当长期奖励(long-term rewards)有着很大的取值范围时,人们在采样轨迹(sampled trajectories)上使用随着时间衰减的奖励(译者注:随着时间的流逝,网络得到的奖励会越来越小)。
受这一点的启发,作者提出了空间衰减重构损失。
(译者注:随着像素点越靠近中心位置,权重越来越小,以此来减小中心区域的权值,使计算损失值时,不会因为中心结果和原始图像差距过大,从而误导训练过程)
具体的做法是使用一个带有权值的mask M,在M上,每一点的权值由γl来计算,其中γ被设定为0.99,l是该点到最近的已知像素点的距离(1-范数,即城市街区距离)。
近似的权重衰减方法在其他人的研究中也被提到了(例如Pathak等人的研究),在修复大面积缺失区域的时候,这种带衰减的损失值在提高修复质量上将更有效。
通过上述提升的方法,作者的生成修复网络有着比Iizuka的网络更快的收敛速度,结果也更精确。此外也不需要图像的后续处理了。
4. 使用内容感知进行图像修复 Image Inpainting with Contextual Attention
卷积神经网络通过一层层的卷积核,很难从远处区域提取图像特征,为了克服这一限制。作者考虑了感知机制(attention mechanism)以及提出了内容感知层(contextual attention layer)。在这一部分,作者首先讨论内容感知层的细节,然后说明如何将它融入生成修复网络中。
4.1 内容感知 Contextual Attention
内容感知层学习的内容是,从已知图像的何处借鉴特征信息,以此来生成缺失的斑块。
(译者注:这一部分译者在第一部分Introduction里就有简单的说明,如果没有概念的读者可以倒回去看一看)
由于这个layer是可微的(differentiable),所以可以在深度模型和全卷积网络中进行训练,允许在任意分辨率的图像上进行测试。
图3
1) 匹配及选取 Match and attend
作者想解决的问题是:在背景区域中匹配缺失区域的特征。
作者首先在背景区域提取3x3的斑块,并作为卷积核。为了匹配前景(即待修复区域)斑块,使用标准化内积(余弦相似度)来测量,然后用softmax来为每个背景斑块计算权值,最后选取出一个最好的斑块,并反卷积出前景区域。对于反卷积过程中的重叠区域(overlapped pixels)取平均值。
对于这个匹配出的背景斑块可视化:
图4
2) 感知传播 Attention propagation
(译者注:这一部分译者不是很明白其原理,各位读者可参照原文)
为了进一步保持图像的一致性,作者使用了感知传播。思想是对前景区域做偏移,可能对应和背景区域做相同的偏移,实现方式是使用单位矩阵作为卷积核,从而做到对图像的偏移。作者先做了左右传播,然后再做上下传播。从而得到新的感知分数(attention score)
该方法有效的提高了修复的结果,以及在训练过程中提供了更丰富的梯度。
3) 显存效率 Memory efficiency
假设在128x128的图像中有个64x64的缺失区域作为输入,那么从背景区域提取出的卷积核个数是12288个(3x3大小)。这可能会超过GPU的显存限制。
为了克服这一问题,作者介绍两种方法:1)在提取背景斑块时添加步长参数来减少提取的卷积核个数;2)在卷积前降低前景区域(缺失区域)的分辨率,然后在感知传播后提高感知图(attention map)的大小。
4.2 合并修复网络 Unified Inpainting Network
为了将感知模块集成到修复模型中,作者提出了两个平行的编码器(见图4).
下面的那个编码器通过扩张卷积(dilated convolution)来“想象”缺失区域的内容。
上面的那个编码器则专注于提取感兴趣的背景区域。
两个编码器的输出被聚合输入到一个大哥哥中,反卷积生成出最后的图像。
在图4中,作者使用了颜色来指出最感兴趣的背景区域的相关位置。比如说,白色区域(彩色图的中心)意味着该区域的像素依赖于自己、左下角的粉色、右上角的绿色。对于不同的图像,偏移值也会跟着缩放,以此来更好地标记出感兴趣的区域(interested background patch)。
(译者注:这里用颜色图(color map)来可视化感知图(attention map)的概念译者不是很明白,读者可以参考原文)
对于训练过程,可以用以下算法来表示:
当G还没有收敛时:
以下步骤循环5次:
从训练集中提取图像x
生成随机的mask m
使用x和m生成带有缺失区域的图像z
将z和m输入生成网络G中,获取修复后的缺失区域图像~x
通过空间衰减重构损失的maskM,对~x做一个权值处理,然后覆盖原图像的这个区域,得到图像^x(这一步译者不确定)
使用x、~x、^x计算全局、局部损失值(这一步译者不确定)
循环结束
从训练集中提取图像x
生成随机的mask m
计算空间衰减重构损失、全局和局部的WGAN-GP损失,来更新生成网络G的权值。
结束循环。
5. 实验 Experiments
(译者注:这里实验可以直接参照参考资料中的余家辉官方的demo,译者后续会给出翻译)
6. 总结 Conclusion
作者提出了粗细网络图像生成修复的框架(coarse-to-fine generative image inpainting framework),并介绍了带有内容感知的模型。作者展示了内容感知模型在提高图像修复结果上,有着很大的意义(通过对背景特征的匹配、提取这一过程的学习)。在今后的研究中,作者基于GAN的不断发展,计划将该方法扩展到更高分辨率的图像修复应用中。图像修复框架和内容感知模块也可以用于带有条件的图像生成、图像编辑、计算摄影任务中(例如图像渲染、超高分辨率图像、指导编辑(guided editing),以及其他种种应用。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.www.huarenyl.cn support import expected_conditions as EC
driver = webdriver.Firefox(www.gcyl152.com/ )
driver.get("http://www.gcyl159.com somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver,www.furong157.com 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
# 注意:是传的一个元组!!!!
)
finally:
driver.quit(www.michenggw.com)
一些其他的等待条件:
presence_of_element_located:某个元素已经加载完毕了。
presence_of_all_emement_located:网页中所有满足条件的元素都加载完毕了。
element_to_be_cliable:某个元素是可以点击了。
更多条件请参考:http:// www.mhylpt.com selenium-python.readthedocs.io/waits.html
切换页面:
有时候窗口中有很多子tab页面。这时候肯定是需要进行切换的。selenium提供了一个叫做switch_to_window来进行切换,具体切换到哪个页面,可以从driver.window_handles中找到。
# 打开一个新的页面
self.driver.execute_script("window.open(''"+url+"'')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时候频繁爬取一些网页。服务器发现你是爬虫后会封掉你的ip地址。这时候我们可以更改代理ip。更改代理ip,不同的浏览器有不同的实现方式。这里以Chrome浏览器为例来讲解:
from selenium import webdriver
options = webdriver.ChromeOptions(www.mcyllpt.com)
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(''http://httpbin.org/ip'')
其他
D. 网络架构 Network Architectures
这里是论文第三部分的附录,提供了网络的更多细节。
以下的表示方法:K(卷积核大小,kernel size)、D(卷积核扩张量,dilation)、S(卷积步长,stride size)、C(通道数,channel number)。

ims.emergency.vo.domain.TreatmentInterventionForAdviceLeafletVoAssembler的实例源码
public TreatmentInterventionForAdviceLeafletVo getTreatmentIntervention(TaxonomyType taxonomyType,String taxonomyCode)
{
if( taxonomyType == null && taxonomyCode == null)
throw new CodingRuntimeException("TaxonomyType and taxonomyCode are null.");
DomainFactory factory = getDomainFactory();
StringBuffer hql = new StringBuffer();
hql.append("select t1_1 from TreatmentIntervention as t1_1 left join t1_1.taxonomyMap as t2_1 left join t2_1.taxonomyName as l1_1 where (t2_1.taxonomyCode = :taxonomyCode and l1_1.id = :taxonomyType and t1_1.isActive = 1)");
List<?> list = factory.find(hql.toString(),new String[] {"taxonomyCode","taxonomyType"},new Object[] {taxonomyCode,taxonomyType.getID()});
if( list != null && list.size() > 0 )
return TreatmentInterventionForAdviceLeafletVoAssembler.createTreatmentInterventionForAdviceLeafletVoCollectionFromTreatmentIntervention(list).get(0);
return null;
}
public TreatmentInterventionForAdviceLeafletVo getTreatmentIntervention(TaxonomyType taxonomyType,taxonomyType.getID()});
if( list != null && list.size() > 0 )
return TreatmentInterventionForAdviceLeafletVoAssembler.createTreatmentInterventionForAdviceLeafletVoCollectionFromTreatmentIntervention(list).get(0);
return null;
}
public TreatmentInterventionForAdviceLeafletVo getTreatmentIntervention(TaxonomyType taxonomyType,taxonomyType.getID()});
if( list != null && list.size() > 0 )
return TreatmentInterventionForAdviceLeafletVoAssembler.createTreatmentInterventionForAdviceLeafletVoCollectionFromTreatmentIntervention(list).get(0);
return null;
}
关于laravel 安装 intervention/image 图像处理扩展 报错 intervention/image 2.3.7 requires ext-fileinfo的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于2018_CVPR_Interactive Image Segmentation with Latent Diversity、AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks 笔记、CVPR2018: Generative Image Inpainting with Contextual Attention 论文翻译、解读、ims.emergency.vo.domain.TreatmentInterventionForAdviceLeafletVoAssembler的实例源码的相关信息,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

