对于想了解Java基础知识_TreeMap的读者,本文将是一篇不可错过的文章,我们将详细介绍java基础知识笔记,并且为您提供关于Java基础知识_ConcurrentHashMap、Java基础知识
对于想了解Java基础知识_TreeMap的读者,本文将是一篇不可错过的文章,我们将详细介绍java基础知识笔记,并且为您提供关于Java 基础知识_ConcurrentHashMap、Java 基础知识_Map 集合、散列表、红黑树、Java 基础知识_多线程入门、JavaScipt对象的基本知识_基础知识的有价值信息。
本文目录一览:- Java基础知识_TreeMap(java基础知识笔记)
- Java 基础知识_ConcurrentHashMap
- Java 基础知识_Map 集合、散列表、红黑树
- Java 基础知识_多线程入门
- JavaScipt对象的基本知识_基础知识
")
Java基础知识_TreeMap(java基础知识笔记)
一、TreeMap剖析
国际惯例,先看一下顶部注释
/**
* A Red-Black tree based {@link NavigableMap} implementation.
* The map is sorted according to the {@linkplain Comparable natural
* ordering} of its keys, or by a {@link Comparator} provided at map
* creation time, depending on which constructor is used.
*
* <p>This implementation provides guaranteed log(n) time cost for the
* {@code containsKey}, {@code get}, {@code put} and {@code remove}
* operations. Algorithms are adaptations of those in Cormen, Leiserson, and
* Rivest''s <em>Introduction to Algorithms</em>.
*
* <p>Note that the ordering maintained by a tree map, like any sorted map, and
* whether or not an explicit comparator is provided, must be <em>consistent
* with {@code equals}</em> if this sorted map is to correctly implement the
* {@code Map} interface. (See {@code Comparable} or {@code Comparator} for a
* precise definition of <em>consistent with equals</em>.) This is so because
* the {@code Map} interface is defined in terms of the {@code equals}
* operation, but a sorted map performs all key comparisons using its {@code
* compareTo} (or {@code compare}) method, so two keys that are deemed equal by
* this method are, from the standpoint of the sorted map, equal. The behavior
* of a sorted map <em>is</em> well-defined even if its ordering is
* inconsistent with {@code equals}; it just fails to obey the general contract
* of the {@code Map} interface.
*
* <p><strong>Note that this implementation is not synchronized.</strong>
* If multiple threads access a map concurrently, and at least one of the
* threads modifies the map structurally, it <em>must</em> be synchronized
* externally. (A structural modification is any operation that adds or
* deletes one or more mappings; merely changing the value associated
* with an existing key is not a structural modification.) This is
* typically accomplished by synchronizing on some object that naturally
* encapsulates the map.
* If no such object exists, the map should be "wrapped" using the
* {@link Collections#synchronizedSortedMap Collections.synchronizedSortedMap}
* method. This is best done at creation time, to prevent accidental
* unsynchronized access to the map: <pre>
* SortedMap m = Collections.synchronizedSortedMap(new TreeMap(...));</pre>
*
* <p>The iterators returned by the {@code iterator} method of the collections
* returned by all of this class''s "collection view methods" are
* <em>fail-fast</em>: if the map is structurally modified at any time after
* the iterator is created, in any way except through the iterator''s own
* {@code remove} method, the iterator will throw a {@link
* ConcurrentModificationException}. Thus, in the face of concurrent
* modification, the iterator fails quickly and cleanly, rather than risking
* arbitrary, non-deterministic behavior at an undetermined time in the future.
*
* <p>Note that the fail-fast behavior of an iterator cannot be guaranteed
* as it is, generally speaking, impossible to make any hard guarantees in the
* presence of unsynchronized concurrent modification. Fail-fast iterators
* throw {@code ConcurrentModificationException} on a best-effort basis.
* Therefore, it would be wrong to write a program that depended on this
* exception for its correctness: <em>the fail-fast behavior of iterators
* should be used only to detect bugs.</em>
*
* <p>All {@code Map.Entry} pairs returned by methods in this class
* and its views represent snapshots of mappings at the time they were
* produced. They do <strong>not</strong> support the {@code Entry.setValue}
* method. (Note however that it is possible to change mappings in the
* associated map using {@code put}.)
*
* <p>This class is a member of the
* <a href="{@docRoot}/../technotes/guides/collections/index.html">
* Java Collections Framework</a>.
*
* @param <K> the type of keys maintained by this map
* @param <V> the type of mapped values
*
* @author Josh Bloch and Doug Lea
* @see Map
* @see HashMap
* @see Hashtable
* @see Comparable
* @see Comparator
* @see Collection
* @since 1.2
*/底层是红黑树,实现NavigableMap这个接口,可以根据key自然排序,也可以在构造方法上传递Comparator实现Map的排序。
有序的map一般是使用compareTo或者compare方法来比较key,只要该两个方法认为相等,在map的角度就认为这两个元素相等
非同步的,时间复杂度都不会太高:logn
1.2 TreeMap构造方法
TreeMap的构造方法有4个
可以发现,TreeMap的构造方法大多数与comparator有关
也就是顶部注释说的:TreeMap有序是通过Comparator来进行比较的,如果comparator为null,那么就使用自然顺序~
打个比方
如果value是整数,自然顺序指的是我们平时的顺序(1,2,3,4,5)~
1 import java.util.*;
2 import java.util.Map.Entry;
3 public class Solution {
4 public static void main(String[] args) {
5 TreeMap<Integer, Integer> map = new TreeMap<>();
6 map.put(1, 5);
7 map.put(2, 4);
8 map.put(3, 3);
9 map.put(4, 2);
10 map.put(5, 1);
11
12 for (Entry<Integer, Integer> entry : map.entrySet()) {
13 String s = entry.getKey()+"--"+entry.getValue();
14 System.out.println(s);
15 }
16 }
17 }
1.3 put方法
我们来看看TreeMap的核心put方法,阅读它就可以获取了不少关于TreeMap特性的东西了
1 public V put(K key, V value) {
2 Entry<K,V> t = root;
3 if (t == null) {
4 compare(key, key); // type (and possibly null) check
5
6 root = new Entry<>(key, value, null);
7 size = 1;
8 modCount++;
9 return null;
10 }
11 int cmp;
12 Entry<K,V> parent;
13 // split comparator and comparable paths
14 Comparator<? super K> cpr = comparator;
15 if (cpr != null) {
16 do {
17 parent = t;
18 cmp = cpr.compare(key, t.key);
19 if (cmp < 0)
20 t = t.left;
21 else if (cmp > 0)
22 t = t.right;
23 else
24 return t.setValue(value);
25 } while (t != null);
26 }
27 else {
28 if (key == null)
29 throw new NullPointerException();
30 @SuppressWarnings("unchecked")
31 Comparable<? super K> k = (Comparable<? super K>) key;
32 do {
33 parent = t;
34 cmp = k.compareTo(t.key);
35 if (cmp < 0)
36 t = t.left;
37 else if (cmp > 0)
38 t = t.right;
39 else
40 return t.setValue(value);
41 } while (t != null);
42 }
43 Entry<K,V> e = new Entry<>(key, value, parent);
44 if (cmp < 0)
45 parent.left = e;
46 else
47 parent.right = e;
48 fixAfterInsertion(e);
49 size++;
50 modCount++;
51 return null;
52 }如果红黑树为null,则新建红黑树,要判断key是否为空类型
comparator比较找到合适的位置插入到红黑树中
如果Comparator为null,则利用key作为比较器进行比较,并且key必须实现Comparable接口
key不能为null,找到合适的位置插入到红黑树中
下面是compare(Object k1, Object k2)方法
1 /**
2 * Compares two keys using the correct comparison method for this TreeMap.
3 */
4 @SuppressWarnings("unchecked")
5 final int compare(Object k1, Object k2) {
6 return comparator==null ? ((Comparable<? super K>)k1).compareTo((K)k2)
7 : comparator.compare((K)k1, (K)k2);
8 }
1.4 get方法
接下来我们看看get方法的实现
找到返回value,找不到返回null
1 public V get(Object key) {
2 Entry<K,V> p = getEntry(key);
3 return (p==null ? null : p.value);
4 }点进去看看getEntry看看实现
1 final Entry<K,V> getEntry(Object key) {
2 // Offload comparator-based version for sake of performance
3 if (comparator != null)
4 return getEntryUsingComparator(key);
5 if (key == null)
6 throw new NullPointerException();
7 @SuppressWarnings("unchecked")
8 Comparable<? super K> k = (Comparable<? super K>) key;
9 Entry<K,V> p = root;
10 while (p != null) {
11 int cmp = k.compareTo(p.key);
12 if (cmp < 0)
13 p = p.left;
14 else if (cmp > 0)
15 p = p.right;
16 else
17 return p;
18 }
19 return null;
20 }如果comparator不为null,调的是
getEntryUsingComparator(key)不然就是使用compareTo()方法,从红黑树中找到对应的值,返回出去。
如果Comparator不为null,接下来我们进去看看getEntryUsingComparator(Object key),是怎么实现的
1 final Entry<K,V> getEntryUsingComparator(Object key) {
2 @SuppressWarnings("unchecked")
3 K k = (K) key;
4 Comparator<? super K> cpr = comparator;
5 if (cpr != null) {
6 Entry<K,V> p = root;
7 while (p != null) {
8 int cmp = cpr.compare(k, p.key);
9 if (cmp < 0)
10 p = p.left;
11 else if (cmp > 0)
12 p = p.right;
13 else
14 return p;
15 }
16 }
17 return null;
18 }只不过是调用Comparator自己实现的方法来获取相应的位置,总体逻辑和外面的没啥区别
1.5 remove方法
1 public V remove(Object key) {
2 Entry<K,V> p = getEntry(key);
3 if (p == null)
4 return null;
5
6 V oldValue = p.value;
7 deleteEntry(p);
8 return oldValue;
9 }先找到这个节点的位置,记录这个想要删除的值(返回),删除这个节点
删除节点的时候调用的是deleteEntry(Entry<K,V> p)方法,这个方法主要是删除节点并且平衡红黑树。
平衡红黑树的代码是比较复杂的。emm,以后有空再整理
1.6遍历方法
TreeMap遍历是使用EntryIterator这个内部类的
可以发现,EntryIterator大多的实现都是在父类中:
1 final class EntryIterator extends PrivateEntryIterator<Map.Entry<K,V>> {
2 EntryIterator(Entry<K,V> first) {
3 super(first);
4 }
5 public Map.Entry<K,V> next() {
6 return nextEntry();
7 }
8 }那接下来我们去看看PrivateEntryIterator比较重要的方法:
1 abstract class PrivateEntryIterator<T> implements Iterator<T> {
2 Entry<K,V> next;
3 Entry<K,V> lastReturned;
4 int expectedModCount;
5
6 PrivateEntryIterator(Entry<K,V> first) {
7 expectedModCount = modCount;
8 lastReturned = null;
9 next = first;
10 }
11
12 public final boolean hasNext() {
13 return next != null;
14 }
15
16 final Entry<K,V> nextEntry() {
17 Entry<K,V> e = next;
18 if (e == null)
19 throw new NoSuchElementException();
20 if (modCount != expectedModCount)
21 throw new ConcurrentModificationException();
22 next = successor(e);
23 lastReturned = e;
24 return e;
25 }lastReturned是返回的节点successor是获取下一个节点我们进去方法
successor看看实现
successor其实就是一个节点的下一个节点,所谓的下一个,是按次序排序后的下一个节点,从代码中可以看出,如果右子树不为空,就返回右子树中最小结点。如果右子树为空,就要向上回溯了。在这种情况下,t是以其为根的树的最后一个节点。如果它是其父节点的左孩子,那么父节点就是它的下一个节点,否则,t就是以其父节点为根的树的最后一个节点,需要再次向上回溯,一直到ch是p的右孩子为止。
1 static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) {
2 if (t == null)
3 return null;
4 else if (t.right != null) {
5 Entry<K,V> p = t.right;
6 while (p.left != null)
7 p = p.left;
8 return p;
9 } else {
10 Entry<K,V> p = t.parent;
11 Entry<K,V> ch = t;
12 while (p != null && ch == p.right) {
13 ch = p;
14 p = p.parent;
15 }
16 return p;
17 }
18 }
二、总结
TreeMap底层是红黑树,能够实现该Map集合有序
如果在构造方法传递了Comparator对象,那么就会以Comparator对象的方法进行比较。否则则使用Comparable的compareTo(T o)方法来比较。
值得说明的是:如果使用的是compareTo(T o)方法来进行比较,key一定不能是null,并且实现了Comparable接口的。
即使是传入了Comparator对象,不用compareTo方法进行比较,key也不能为null的
我们从源码中的很多地方中发现:Comparator和Comparable出现的频率是很高的,因为TreeMap实现有序要么就是外界传递进来Comparator对象,要么就使用默认key的Comparable接口(实现自然排序)
最后我就来总结一下TreeMap要点吧:
-
由于底层是红黑树,那么时间复杂度可以保证为log(n)
-
key不能为null,为null为抛出NullPointException的
-
想要自定义比较,在构造方法中传入Comparator对象,否则使用key的自然排序来进行比较
-
TreeMap非同步的,想要同步可以使用Collections来进行封装

Java 基础知识_ConcurrentHashMap
一、ConCurrentHashMap 剖析
1.1 初识 ConCurrentHashMap
ConCurrentHashMap 的底层是散列表 + 红黑树,与 HashMap 是一样的。

从前面的章节可以发现,最快了解一个类是干嘛的,我们看源码的顶部注释就可以了。
1 /**
2 * A hash table supporting full concurrency of retrievals and
3 * high expected concurrency for updates. This class obeys the
4 * same functional specification as {@link java.util.Hashtable}, and
5 * includes versions of methods corresponding to each method of
6 * {@code Hashtable}. However, even though all operations are
7 * thread-safe, retrieval operations do <em>not</em> entail locking,
8 * and there is <em>not</em> any support for locking the entire table
9 * in a way that prevents all access. This class is fully
10 * interoperable with {@code Hashtable} in programs that rely on its
11 * thread safety but not on its synchronization details.
12 *
13 * <p>Retrieval operations (including {@code get}) generally do not
14 * block, so may overlap with update operations (including {@code put}
15 * and {@code remove}). Retrievals reflect the results of the most
16 * recently <em>completed</em> update operations holding upon their
17 * onset. (More formally, an update operation for a given key bears a
18 * <em>happens-before</em> relation with any (non-null) retrieval for
19 * that key reporting the updated value.) For aggregate operations
20 * such as {@code putAll} and {@code clear}, concurrent retrievals may
21 * reflect insertion or removal of only some entries. Similarly,
22 * Iterators, Spliterators and Enumerations return elements reflecting the
23 * state of the hash table at some point at or since the creation of the
24 * iterator/enumeration. They do <em>not</em> throw {@link
25 * java.util.ConcurrentModificationException ConcurrentModificationException}.
26 * However, iterators are designed to be used by only one thread at a time.
27 * Bear in mind that the results of aggregate status methods including
28 * {@code size}, {@code isEmpty}, and {@code containsValue} are typically
29 * useful only when a map is not undergoing concurrent updates in other threads.
30 * Otherwise the results of these methods reflect transient states
31 * that may be adequate for monitoring or estimation purposes, but not
32 * for program control.
33 *
34 * <p>The table is dynamically expanded when there are too many
35 * collisions (i.e., keys that have distinct hash codes but fall into
36 * the same slot modulo the table size), with the expected average
37 * effect of maintaining roughly two bins per mapping (corresponding
38 * to a 0.75 load factor threshold for resizing). There may be much
39 * variance around this average as mappings are added and removed, but
40 * overall, this maintains a commonly accepted time/space tradeoff for
41 * hash tables. However, resizing this or any other kind of hash
42 * table may be a relatively slow operation. When possible, it is a
43 * good idea to provide a size estimate as an optional {@code
44 * initialCapacity} constructor argument. An additional optional
45 * {@code loadFactor} constructor argument provides a further means of
46 * customizing initial table capacity by specifying the table density
47 * to be used in calculating the amount of space to allocate for the
48 * given number of elements. Also, for compatibility with previous
49 * versions of this class, constructors may optionally specify an
50 * expected {@code concurrencyLevel} as an additional hint for
51 * internal sizing. Note that using many keys with exactly the same
52 * {@code hashCode()} is a sure way to slow down performance of any
53 * hash table. To ameliorate impact, when keys are {@link Comparable},
54 * this class may use comparison order among keys to help break ties.
55 *
56 * <p>A {@link Set} projection of a ConcurrentHashMap may be created
57 * (using {@link #newKeySet()} or {@link #newKeySet(int)}), or viewed
58 * (using {@link #keySet(Object)} when only keys are of interest, and the
59 * mapped values are (perhaps transiently) not used or all take the
60 * same mapping value.
61 *
62 * <p>A ConcurrentHashMap can be used as scalable frequency map (a
63 * form of histogram or multiset) by using {@link
64 * java.util.concurrent.atomic.LongAdder} values and initializing via
65 * {@link #computeIfAbsent computeIfAbsent}. For example, to add a count
66 * to a {@code ConcurrentHashMap<String,LongAdder> freqs}, you can use
67 * {@code freqs.computeIfAbsent(k -> new LongAdder()).increment();}
68 *
69 * <p>This class and its views and iterators implement all of the
70 * <em>optional</em> methods of the {@link Map} and {@link Iterator}
71 * interfaces.
72 *
73 * <p>Like {@link Hashtable} but unlike {@link HashMap}, this class
74 * does <em>not</em> allow {@code null} to be used as a key or value.
75 *
76 * <p>ConcurrentHashMaps support a set of sequential and parallel bulk
77 * operations that, unlike most {@link Stream} methods, are designed
78 * to be safely, and often sensibly, applied even with maps that are
79 * being concurrently updated by other threads; for example, when
80 * computing a snapshot summary of the values in a shared registry.
81 * There are three kinds of operation, each with four forms, accepting
82 * functions with Keys, Values, Entries, and (Key, Value) arguments
83 * and/or return values. Because the elements of a ConcurrentHashMap
84 * are not ordered in any particular way, and may be processed in
85 * different orders in different parallel executions, the correctness
86 * of supplied functions should not depend on any ordering, or on any
87 * other objects or values that may transiently change while
88 * computation is in progress; and except for forEach actions, should
89 * ideally be side-effect-free. Bulk operations on {@link java.util.Map.Entry}
90 * objects do not support method {@code setValue}.
91 *
92 * <ul>
93 * <li> forEach: Perform a given action on each element.
94 * A variant form applies a given transformation on each element
95 * before performing the action.</li>
96 *
97 * <li> search: Return the first available non-null result of
98 * applying a given function on each element; skipping further
99 * search when a result is found.</li>
100 *
101 * <li> reduce: Accumulate each element. The supplied reduction
102 * function cannot rely on ordering (more formally, it should be
103 * both associative and commutative). There are five variants:
104 *
105 * <ul>
106 *
107 * <li> Plain reductions. (There is not a form of this method for
108 * (key, value) function arguments since there is no corresponding
109 * return type.)</li>
110 *
111 * <li> Mapped reductions that accumulate the results of a given
112 * function applied to each element.</li>
113 *
114 * <li> Reductions to scalar doubles, longs, and ints, using a
115 * given basis value.</li>
116 *
117 * </ul>
118 * </li>
119 * </ul>
120 *
121 * <p>These bulk operations accept a {@code parallelismThreshold}
122 * argument. Methods proceed sequentially if the current map size is
123 * estimated to be less than the given threshold. Using a value of
124 * {@code Long.MAX_VALUE} suppresses all parallelism. Using a value
125 * of {@code 1} results in maximal parallelism by partitioning into
126 * enough subtasks to fully utilize the {@link
127 * ForkJoinPool#commonPool()} that is used for all parallel
128 * computations. Normally, you would initially choose one of these
129 * extreme values, and then measure performance of using in-between
130 * values that trade off overhead versus throughput.
131 *
132 * <p>The concurrency properties of bulk operations follow
133 * from those of ConcurrentHashMap: Any non-null result returned
134 * from {@code get(key)} and related access methods bears a
135 * happens-before relation with the associated insertion or
136 * update. The result of any bulk operation reflects the
137 * composition of these per-element relations (but is not
138 * necessarily atomic with respect to the map as a whole unless it
139 * is somehow known to be quiescent). Conversely, because keys
140 * and values in the map are never null, null serves as a reliable
141 * atomic indicator of the current lack of any result. To
142 * maintain this property, null serves as an implicit basis for
143 * all non-scalar reduction operations. For the double, long, and
144 * int versions, the basis should be one that, when combined with
145 * any other value, returns that other value (more formally, it
146 * should be the identity element for the reduction). Most common
147 * reductions have these properties; for example, computing a sum
148 * with basis 0 or a minimum with basis MAX_VALUE.
149 *
150 * <p>Search and transformation functions provided as arguments
151 * should similarly return null to indicate the lack of any result
152 * (in which case it is not used). In the case of mapped
153 * reductions, this also enables transformations to serve as
154 * filters, returning null (or, in the case of primitive
155 * specializations, the identity basis) if the element should not
156 * be combined. You can create compound transformations and
157 * filterings by composing them yourself under this "null means
158 * there is nothing there now" rule before using them in search or
159 * reduce operations.
160 *
161 * <p>Methods accepting and/or returning Entry arguments maintain
162 * key-value associations. They may be useful for example when
163 * finding the key for the greatest value. Note that "plain" Entry
164 * arguments can be supplied using {@code new
165 * AbstractMap.SimpleEntry(k,v)}.
166 *
167 * <p>Bulk operations may complete abruptly, throwing an
168 * exception encountered in the application of a supplied
169 * function. Bear in mind when handling such exceptions that other
170 * concurrently executing functions could also have thrown
171 * exceptions, or would have done so if the first exception had
172 * not occurred.
173 *
174 * <p>Speedups for parallel compared to sequential forms are common
175 * but not guaranteed. Parallel operations involving brief functions
176 * on small maps may execute more slowly than sequential forms if the
177 * underlying work to parallelize the computation is more expensive
178 * than the computation itself. Similarly, parallelization may not
179 * lead to much actual parallelism if all processors are busy
180 * performing unrelated tasks.
181 *
182 * <p>All arguments to all task methods must be non-null.
183 *
184 * <p>This class is a member of the
185 * <a href="{@docRoot}/../technotes/guides/collections/index.html">
186 * Java Collections Framework</a>.
187 *
188 * @since 1.5
189 * @author Doug Lea
190 * @param <K> the type of keys maintained by this map
191 * @param <V> the type of mapped values
192 */支持高并发的检索和更新,线程是安全的,并且检索操作是不再加锁的。get 方法非阻塞,检索出来结果是最新设置的值,一些关于统计的方法,最好在单线程的环境下使用,不然它只满足监控或估算的目的,在项目中使用它是无法准确返回的,当有太多散列碰撞的时候,这表会动态增加,再散列(扩容)是一件非常消耗资源的事情,最好是提取计算放入容器中有多少元素来手动初始化装载因子和初始容量,这样会好很多。
能够用来频繁改变的 Map,通过 LongAdder,实现了 Map 和 Iterator 的所有方法,ConCurrentHashMap 不允许 key 或 value 为 null,ConCurrentHashMap 提供方法支持批量操作
简单总结
jdk1.8 的底层是散列表 + 红黑树
ConCurrentHashMap 支持高并发的访问和更新,它是线程安全的
检索操作不用加锁,get 方法是非阻塞的
key 和 value 都不允许为 null
1.2 JDK1.7 底层实现
上面指明的是 jdk1.8 底层是:散列表 + 红黑树,也就意味着 jdk1.7 的底层根 jdk1.8 是不同的~
jdk1.7 的底层是:segments+HashEntry 数组:
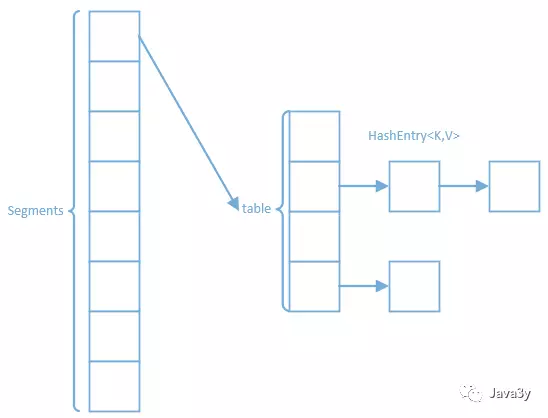
Segment 继承了 ReentrantLock,每个片段都有了一个锁,叫做锁分段
1.3 有了 Hashtable 为啥需要 ConCurrentHashMap
Hashtable 是在每个方法上都加上了 Synchronized 完成同步,效率低下
ConCurrentHashMap 通过部分加锁和利用 CAS 算法来实现同步
1.4CAS 算法和 volatile 简单介绍
在看 ConCurrentHashMap 源码之前,我们来简单讲讲 CAS 算法和 volatile 关键字
CAS(比较与交换,Compare and swap)是一种有名的无锁算法
CAS 有 3 个操作数
内存值 V
旧的预期值 A
要修改的新值 B
当前仅当预期值 A 和内存值 V 相同的时候,将内存值 V 修改成 B,否则什么都不做
当多个线程尝试使用 CAS 同时更新同一个变量的时候,只有一个线程能更新变量的值(A 和内存值 V 相同时,将内存值 V 修改为 B),而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并且可以再次尝试(否则什么都不做)
看了上面的描述应该很容易理解了,先比较是否相等,如果相等则替换(CAS 算法)
接下来我们来看看 volatile 关键字
volatile 经典总结:volatile 仅仅用来保证该变量对所有的线程的可见性,但不保证原子性。
我们将其拆开来解释一下:
保证该变量对所有线程的可见性
在多线程的环境下:当这个变量修改时,所有线程都会知道该变量被修改了,也就是所谓的可见性
不保证原子性
修改变量实质上在 JVM 分为好几步,它是不安全的。
1.5 ConCurrentHashMap
域对象有这么几个:
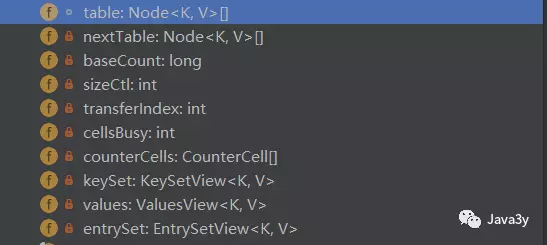
我们来简单看看他们是啥玩意
1 /* ---------------- Fields -------------- */
2
3 /**
4 * The array of bins. Lazily initialized upon first insertion.
5 * Size is always a power of two. Accessed directly by iterators.
6 */
7 transient volatile Node<K,V>[] table;
8
9 /**
10 * The next table to use; non-null only while resizing.
11 */
12 private transient volatile Node<K,V>[] nextTable;
13
14 /**
15 * Base counter value, used mainly when there is no contention,
16 * but also as a fallback during table initialization
17 * races. Updated via CAS.
18 */
19 private transient volatile long baseCount;
20
21 /**
22 * Table initialization and resizing control. When negative, the
23 * table is being initialized or resized: -1 for initialization,
24 * else -(1 + the number of active resizing threads). Otherwise,
25 * when table is null, holds the initial table size to use upon
26 * creation, or 0 for default. After initialization, holds the
27 * next element count value upon which to resize the table.
28 */
29 private transient volatile int sizeCtl;
30
31 /**
32 * The next table index (plus one) to split while resizing.
33 */
34 private transient volatile int transferIndex;
35
36 /**
37 * Spinlock (locked via CAS) used when resizing and/or creating CounterCells.
38 */
39 private transient volatile int cellsBusy;
40
41 /**
42 * Table of counter cells. When non-null, size is a power of 2.
43 */
44 private transient volatile CounterCell[] counterCells;
45
46 // views
47 private transient KeySetView<K,V> keySet;
48 private transient ValuesView<K,V> values;
49 private transient EntrySetView<K,V> entrySet;table 是散列表,迭代器迭代的就是它了。
1.6 ConCurrentHashMap 构造方法
ConcurrentHashMap 的构造方法有五个
默认初始容量是 16,可以直接指定初始容量,这样可以不用过度依赖动态扩容了,也可以指定估计的并发线程数量。
1 public ConcurrentHashMap() {
2 }
3
4 /**
5 * Creates a new, empty map with an initial table size
6 * accommodating the specified number of elements without the need
7 * to dynamically resize.
8 *
9 * @param initialCapacity The implementation performs internal
10 * sizing to accommodate this many elements.
11 * @throws IllegalArgumentException if the initial capacity of
12 * elements is negative
13 */
14 public ConcurrentHashMap(int initialCapacity) {
15 if (initialCapacity < 0)
16 throw new IllegalArgumentException();
17 int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
18 MAXIMUM_CAPACITY :
19 tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
20 this.sizeCtl = cap;
21 }
22
23 /**
24 * Creates a new map with the same mappings as the given map.
25 *
26 * @param m the map
27 */
28 public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
29 this.sizeCtl = DEFAULT_CAPACITY;
30 putAll(m);
31 }
32
33 /**
34 * Creates a new, empty map with an initial table size based on
35 * the given number of elements ({@code initialCapacity}) and
36 * initial table density ({@code loadFactor}).
37 *
38 * @param initialCapacity the initial capacity. The implementation
39 * performs internal sizing to accommodate this many elements,
40 * given the specified load factor.
41 * @param loadFactor the load factor (table density) for
42 * establishing the initial table size
43 * @throws IllegalArgumentException if the initial capacity of
44 * elements is negative or the load factor is nonpositive
45 *
46 * @since 1.6
47 */
48 public ConcurrentHashMap(int initialCapacity, float loadFactor) {
49 this(initialCapacity, loadFactor, 1);
50 }
51
52 /**
53 * Creates a new, empty map with an initial table size based on
54 * the given number of elements ({@code initialCapacity}), table
55 * density ({@code loadFactor}), and number of concurrently
56 * updating threads ({@code concurrencyLevel}).
57 *
58 * @param initialCapacity the initial capacity. The implementation
59 * performs internal sizing to accommodate this many elements,
60 * given the specified load factor.
61 * @param loadFactor the load factor (table density) for
62 * establishing the initial table size
63 * @param concurrencyLevel the estimated number of concurrently
64 * updating threads. The implementation may use this value as
65 * a sizing hint.
66 * @throws IllegalArgumentException if the initial capacity is
67 * negative or the load factor or concurrencyLevel are
68 * nonpositive
69 */
70 public ConcurrentHashMap(int initialCapacity,
71 float loadFactor, int concurrencyLevel) {
72 if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
73 throw new IllegalArgumentException();
74 if (initialCapacity < concurrencyLevel) // Use at least as many bins
75 initialCapacity = concurrencyLevel; // as estimated threads
76 long size = (long)(1.0 + (long)initialCapacity / loadFactor);
77 int cap = (size >= (long)MAXIMUM_CAPACITY) ?
78 MAXIMUM_CAPACITY : tableSizeFor((int)size);
79 this.sizeCtl = cap;
80 }可以发现在构造方法中有几处都调用了 tableSizeFor (),我们来看一下他是干什么的;
点进去之后,啊,原来我看过这个方法,在 HashMap 的时候。
1 private static final int tableSizeFor(int c) {
2 int n = c - 1;
3 n |= n >>> 1;
4 n |= n >>> 2;
5 n |= n >>> 4;
6 n |= n >>> 8;
7 n |= n >>> 16;
8 return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
9 }它就是用来获取大于参数且最接近 2 的整次幂的数...
赋值给 sizeCtl 属性也就说明了:这是下次扩容的大小
1.7 put 方法
终于来到了最核心的方法之一了:put 方法啦~~~~
我们先来整体看一下 put 方法干了什么事;
1 final V putVal(K key, V value, boolean onlyIfAbsent) {
2 if (key == null || value == null) throw new NullPointerException();
3 int hash = spread(key.hashCode());
4 int binCount = 0;
5 for (Node<K,V>[] tab = table;;) {
6 Node<K,V> f; int n, i, fh;
7 if (tab == null || (n = tab.length) == 0)
8 tab = initTable();
9 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
10 if (casTabAt(tab, i, null,
11 new Node<K,V>(hash, key, value, null)))
12 break; // no lock when adding to empty bin
13 }
14 else if ((fh = f.hash) == MOVED)
15 tab = helpTransfer(tab, f);
16 else {
17 V oldVal = null;
18 synchronized (f) {
19 if (tabAt(tab, i) == f) {
20 if (fh >= 0) {
21 binCount = 1;
22 for (Node<K,V> e = f;; ++binCount) {
23 K ek;
24 if (e.hash == hash &&
25 ((ek = e.key) == key ||
26 (ek != null && key.equals(ek)))) {
27 oldVal = e.val;
28 if (!onlyIfAbsent)
29 e.val = value;
30 break;
31 }
32 Node<K,V> pred = e;
33 if ((e = e.next) == null) {
34 pred.next = new Node<K,V>(hash, key,
35 value, null);
36 break;
37 }
38 }
39 }
40 else if (f instanceof TreeBin) {
41 Node<K,V> p;
42 binCount = 2;
43 if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
44 value)) != null) {
45 oldVal = p.val;
46 if (!onlyIfAbsent)
47 p.val = value;
48 }
49 }
50 }
51 }
52 if (binCount != 0) {
53 if (binCount >= TREEIFY_THRESHOLD)
54 treeifyBin(tab, i);
55 if (oldVal != null)
56 return oldVal;
57 break;
58 }
59 }
60 }
61 addCount(1L, binCount);
62 return null;
63 }对 key 进行散列,获取哈希值,当表为 null 时,进行初始化。如果这个哈希值直接可以存到数组,就直接插入进去,插入的位置是表的连接点时,那就表明在扩容,帮助当前线程扩容,链表长度大于 8,链表结构转化成树形结构。
接下来我们看看初始化散列表的时候干了什么事:initTable ()
1 private final Node<K,V>[] initTable() {
2 Node<K,V>[] tab; int sc;
3 while ((tab = table) == null || tab.length == 0) {
4 if ((sc = sizeCtl) < 0)
5 Thread.yield(); // lost initialization race; just spin
6 else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
7 try {
8 if ((tab = table) == null || tab.length == 0) {
9 int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
10 @SuppressWarnings("unchecked")
11 Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
12 table = tab = nt;
13 sc = n - (n >>> 2);
14 }
15 } finally {
16 sizeCtl = sc;
17 }
18 break;
19 }
20 }
21 return tab;
22 }有线程正在初始化,告诉其他线程不要进来了。设置为 - 1,说明本线程正在初始化。相当于设置一个 0.75*n 设置一个扩容的阈值
只让一个线程对散列表进行初始化!
1.8 get 方法
从顶部注释我们可以读到,get 方法是不用加锁的,是非阻塞的。
我们可以发现,Node 节点是重写的设置了 volatile 关键字,致使它每次获取的都是最新的值
1 static class Node<K,V> implements Map.Entry<K,V> {
2 final int hash;
3 final K key;
4 volatile V val;
5 volatile Node<K,V> next;
6
7 Node(int hash, K key, V val, Node<K,V> next) {
8 this.hash = hash;
9 this.key = key;
10 this.val = val;
11 this.next = next;
12 }
13
14 public final K getKey() { return key; }
15 public final V getValue() { return val; }
16 public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
17 public final String toString(){ return key + "=" + val; }
18 public final V setValue(V value) {
19 throw new UnsupportedOperationException();
20 }
21
22 public final boolean equals(Object o) {
23 Object k, v, u; Map.Entry<?,?> e;
24 return ((o instanceof Map.Entry) &&
25 (k = (e = (Map.Entry<?,?>)o).getKey()) != null &&
26 (v = e.getValue()) != null &&
27 (k == key || k.equals(key)) &&
28 (v == (u = val) || v.equals(u)));
29 }在桶子上就直接获取,和在树形结构上以及在链表上
1 public V get(Object key) {
2 Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
3 int h = spread(key.hashCode());
4 if ((tab = table) != null && (n = tab.length) > 0 &&
5 (e = tabAt(tab, (n - 1) & h)) != null) {
6 if ((eh = e.hash) == h) {
7 if ((ek = e.key) == key || (ek != null && key.equals(ek)))
8 return e.val;
9 }
10 else if (eh < 0)
11 return (p = e.find(h, key)) != null ? p.val : null;
12 while ((e = e.next) != null) {
13 if (e.hash == h &&
14 ((ek = e.key) == key || (ek != null && key.equals(ek))))
15 return e.val;
16 }
17 }
18 return null;
19 }二、总结
上面简单介绍了 ConcurrentHashMap 的核心知识,还有很多知识点都没提到
下面简单总结一下
1、底层结构是散列表(数组 + 链表)+ 红黑树,这一点是和 HashMap 是一样的
2、Hashtable 是将所有方法实现同步,效率低下。而 ConcurrentHashMap 作为一个高并发容器,它是通过部分锁定 + CAS 算法来实现线程安全的。CAS 算法也可以认为是乐观锁的一种。
3、在高并发的环境下,统计数据(计算 size)其实是无意义的,因为下一时刻 size 值就变化了。
4、get 方法是非阻塞,无锁的。重写 Node 类,通过 volatile 修饰 next 来实现每次获取的都是最新设置的值
5、ConcurrentHashMap 的 key 和 value 都不能为 null

Java 基础知识_Map 集合、散列表、红黑树
一、Map 介绍
1.1 为什么需要 Map
前面我们学习的 Collection 叫做集合,它可以快速查找现有的元素
而 Map 在《Core Java》中称之为映射
映射的模型图是这样的:
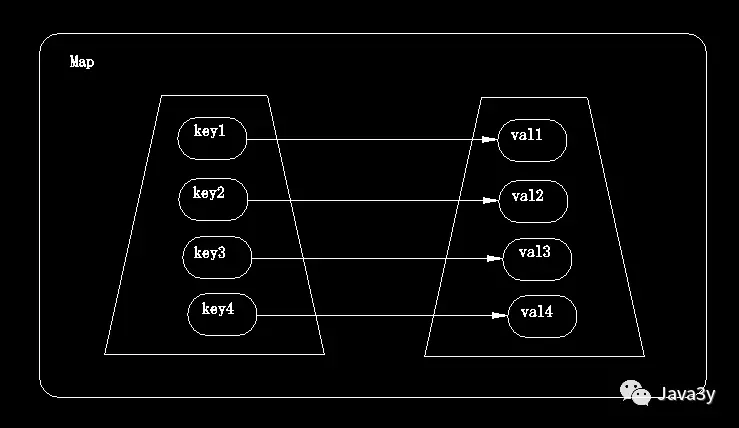
那为什么我们需要这种数据存储结构呢??举个例子
作为学生来说,我们根据学号来区分不同的学生。只要我们知道学号,就可以获取对应的学生信息,这就是 Map 映射的作用。
生活中还有很多这样的例子:只要你掏出身份证(Key),那就可以证明是你自己(value)
1.2 Map 与 Collection 的区别
Map 集合的特点:
将键映射到值得对象,一个映射不能包含重复,每个键最多只能映射到一个值
Map 和 Collection 集合得区别
1、Map 集合存储元素是成对出现得,Map 键是唯一得,值是可以重复的。
2、Collection 集合存储元素是单独出现的,Collection 的儿子 Set 是唯一的,list 是可重复的
要点:
1、Map 集合的数据结构针对键有效,跟值无关
2、Collection 集合的数据结构针对元素有效
1.3 Map 的功能
简单的常用 Map 功能概述
1:添加功能
V put (K key , V value) 添加元素
如果键的第一次存储,就直接存储元素,返回 null
如果键不是第一次存在,就用值把以前的值替换掉,返回以前的值
2:删除功能
void clear (); 移除所有的键值对元素
V remove (Object key); 根据键删除值,并把值返回
3、判断功能
boolean containsKey (Object key); 判断集合是否包含指定的键
boolean containsValue (Object value); 判断集合是否包含指定的值
boolean isEmpty (); 判断集合是否为空
4、获取功能
Set<Map.Entry<K key , V value>> entrySet (); 返回的是键值对对象的集合
V get (Object key); 根据键获取值
Set<K> keySet (); 获取集合中所有的键的集合
Collection<V> values; 获取集合中所有值的集合
5、长度功能
int size () 返回集合中键值对的对数
二、散列表介绍
无论是 Set 还是 Map,我们会发现有对应的 HashSet 和 HashMap
首先我们也得回顾一下数组和链表
链表和数组都可以按照人们的意愿来排序
链表和数组都可以按照人们的意愿来排列元素的次序,他们可以说是有序的(存储顺序和取出的顺序是一致的)
但同时,这会带来缺点:想要获取某个元素,就要访问所有的元素,直到找到为止
这会让我们消耗很多的时间在里面,遍历访问元素。
而还有另外的一些存储结构:不在意元素的顺序,能够快速的查找元素的数据
其中就有一种常见的:散列表
2.1 散列表工作原理
散列表为每个对象计算出一个整数,称为散列码。根据这些计算出来的整数(散列码)保存在相对应的位置上。
在 Java 中,散列表用的是链表数组实现的,每个列表称之为桶。一个桶上可能遇到被占用的情况(hashCode 散列码相同,就存储在同一个位置上),这种情况是无法避免的,这种现象称之为:散列冲突。
此时,需要用该对象与桶上的对象进行比较,看看该对象是否存在桶子上了,如果存在就不添加了,如果不存在则添加到桶子上
当然了,如果 hashcode 函数设计得足够好,桶的数目也足够,这种比较少的
在 jdk1.8 中,当同一个 hash 值的节点数不小于 8 时,将不再以单链表的形式存储了,会被调整成一颗红黑树。
如果散列表太满,时需要对散列表再散列,创建一个桶数更多的散列表,并将原有的元素插入到新表中,丢弃原来的表。
装填因子决定了何时对散列表再散列
装填因子默认是 0.75,如何表中超过了 75% 的位置已经填入了元素,那么这个表就会用双倍的桶数自动进行再散列。
三、红黑树的介绍
各种常见的树的用途
AVL 树:最早的平衡二叉树之一。应用相对其他数据结构比较少,windows 对进程地址空间的管理用到了 AVL 树。
红黑树:平衡二叉树,广泛用在 C++ 的 STL 中。如 map 和 set 都是用红黑树实现的。
B/B + 树:用在磁盘文件组织,数据索引和数据库索引
Trie 树(字典树):用于统计和排序大量字符串,如自动机
3.1 回顾二叉树
利用二叉树的特性,我们一般可以很快的查找到对应的元素,可是二叉树也有个例(最坏)的情况,线性
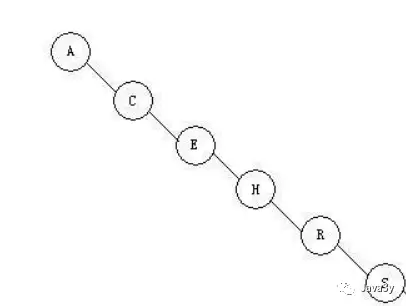
上述符合二叉树的特性,但是它是线性的,完全没有树的用处
树是要均衡才能将它的优点展示出来的,比如下面这种
因此,就有了平衡树这个概念,红黑树就是一种平衡树,它可以保证二叉树基本上都符合矮矮胖胖的结构,也就是均衡
3.2 2-3 树
讲到了平衡树就不得不说了最基础的 2-3 树,2-3 树长得是这个样子
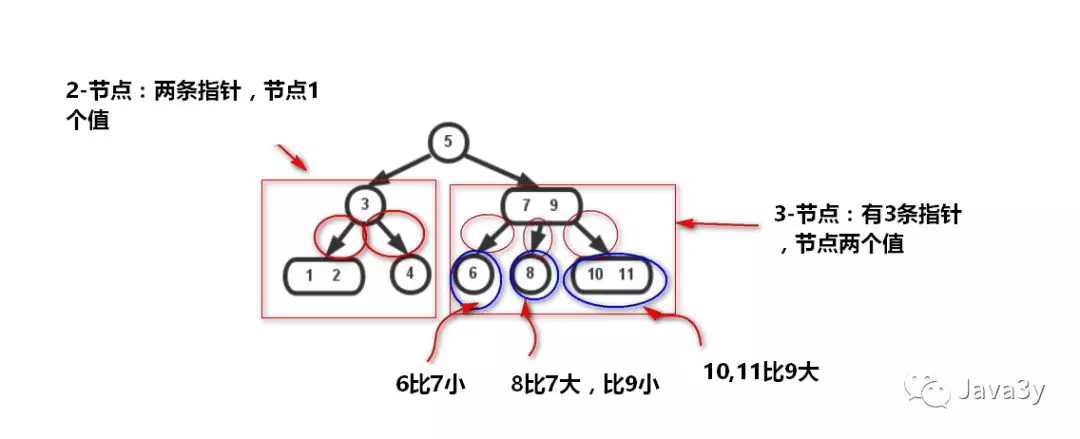
在二叉查找树,我们插入节点的过程是这样的:小于节点的值往右继续与左子节点比,大于则继续与右子节点比,直到某节点左或右子节点为空,把值插入进去,这样无法避免偏向问题。
而 2-3 树不一样:它插入的时候可以保持树的平衡
在 2-3 树插入的时候,可以简单总结为两个操作
合并 2 - 节点为 3 - 节点,扩充将 3 - 节点扩充为一个 4 - 节点
分解 4 - 节点为 3 - 节点,节点 3 - 节点为 2 - 节点
使得树平衡
合并分解的操作还是比较复杂的,以后详细说
3.3 从 2-3 树到红黑树
由于 2-3 树为了保持平衡性,在维护的时候是需要大量节点交换的!这些变化实际代码中是很复杂的,大佬们在 2-3 的理论上发明了红黑树
红黑树是对 2-3 查找树的改进,它能用一种统一的方式完成所有变换
红黑树是一种平衡二叉树,因此它没有 3 - 节点。那么红黑树是怎么将 3 - 节点来改进成全都是二叉树的呢?
红黑树就是字面上的意思,有红色的节点,有黑色的节点;
一颗典型的二叉树:
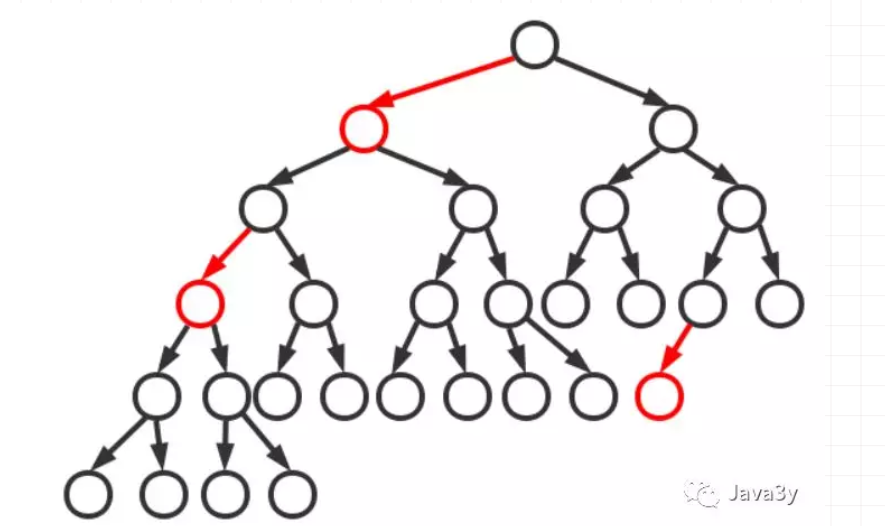
将红色节点的左链接画平之后:得到 2-3 平衡树:
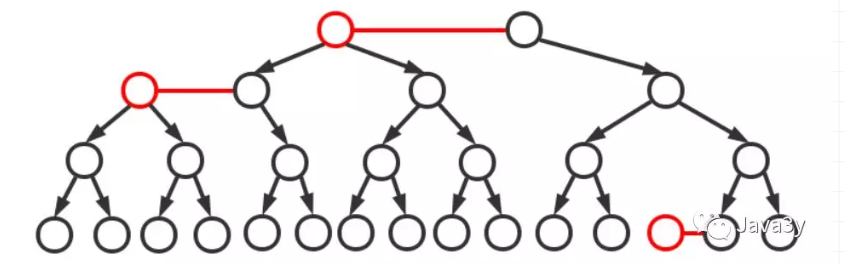
3.4 红黑树的基础知识
前面已经说了,红黑树是在 2-3 的基础上实现的一种树,它能够用统一的方式完成所有变换。
红黑树用的是两种方式来代替 2-3 树不断的节点交换操作
旋转:顺时针旋转和逆时针旋转
反色:交换红黑的颜色
这个两个实现比 2-3 树交换的节点(合并分解要方便一点)
红黑树为了保持平衡还是有制定一些约束的,遵守这些约束的才能叫做红黑树
1、红黑树是二叉搜索树
2、根节点是黑色
3、每个叶子节点都是黑色的空节点(NIL 节点)
4、每个红色节点的两个子节点都是黑色(从每个叶子到根的所有路径上不能有两个连续的红色节点)
5、从任一节点到其每个叶子节点的所有路径都包含相同的数目的黑色节点(每一条树链上的黑色节点数量(称之为 “黑高”)必须相等)。
3.5 红黑树总结
之后复习数据结构再好好总结细节,今天就稍微过一遍

Java 基础知识_多线程入门
一、初识多线程
1.1 介绍进程
讲到线程,又不得不提进程了。wwww
进程大家是了解滴,在 windows 下打开任务管理器,可以发现我们操作系统上运行的程序都是进程。
进程的定义:
进程是程序的一次执行,进程是一个程序及其数据在处理机上顺序执行时所发生的活动,进程是具有独立功能的程序在一个数据集合上运行的过程,它是系统进行资源调度分配的一个独立单位
进程是系统进行资源分配和调度的独立单位,每一个进程都有它自己的内存空间和系统资源。
1.2 回到线程
那系统已经有了进程这么个概念了,进程已经是可以进行资源调度和分配了,为什么还要哦线程呢?
为使程序能够并发执行,系统必须进行以下一系列的操作
1、创建进程:系统在创建一个进程的时候,必须为它分配其必须的、除处理机以外的资源,如内存空间、IO 设备、以及相应的 PCB
2、撤销进程:系统在撤销进程的时候,又必须先对其所占有的资源执行回收操作,然后再撤销 PCB
3、进程切换:对进程进行上下文切换时,需要保留当前进程的 CPU 环境,设置新选中的进程的 CPU 环境,因而须花费不少的处理机时间。

可以看到进程实现多处理机环境下的进程调度分派和切换,都需要花费较大的时间和空间开销。
引入线程主要是为了提高系统的执行效率,减少处理机的空转时间和调度切换的时间,以及便于系统管理。使 OS 具有更好的并发性
简单来说:进程实现多处理非常耗费 CPU 的资源,而我们引入线程使作为调度和分派的基本单位(取代进程的部分基本功能【调度】)
那么,线程在哪呢?????
比如听着网易云音乐,点击菜单时还可以响应。
也就是说:在同一个进程内又可以执行多个任务,而这每一个任务我们就可以看作是一个线程。
所以说:一个进程会有 1 个或多个线程!
1.3 进程与线程
我们可以总结:
进程作为资源分配的基本单位
线程作为资源调度的基本单位,最程序的执行单位,执行路径。是程序使用 CPU 的最基本的单位
线程有 3 个基本状态
执行、就绪、阻塞
线程有 5 个基本操作
派生、阻塞、激活、调度、结束
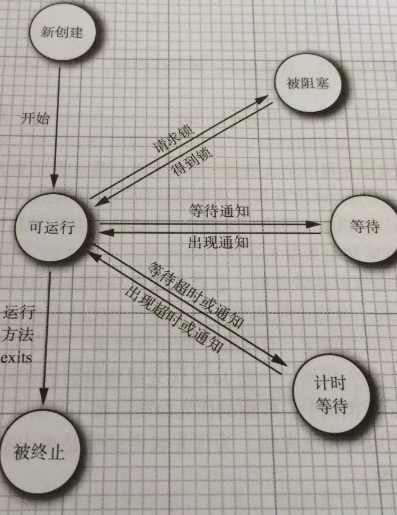
线程的属性:
1、轻型实体
2、独立调度和分派的基本单位
3、可并发执行
4、共享进程资源
线程有两个基本类型
1、用户级线程:管理过程全部由用户程序完成,操作系统内核心只对进程进行管理。
2、系统级线程(核心级线程)由操作系统内核进行管理,操作系统内核给应用程序提供相应的系统调用和应用程序接口 API,以使用户程序可以创建、执行以及撤销线程。
值得注意的是:多线程的存在不是为了提高程序的执行速度。其实是为了提高程序的执行速度,其实是为了提高应用程序的使用率,程序的执行其实都是在抢 CPU 的资源,CPU 的执行权。多个进程在抢这个资源,而其中某个进程如果执行路径比较多,就会有更高的几率抢到 CPU 的执行权
1.4 并行与并发
并行
并行指的是同一时刻发生两个或多个事件
并行是在不同实体上的多个事件
并发
并发性是指同一个时间间隔内发生两个或多个事件
并发是指在同一个实体上的多个事件
1.5 Java 实现多线程
我们回到 Java 中,看看 Java 是如何实现多线程的
Java 实现多线程使用的是 Thread 这个类,我们来看看 Thread 类的顶部注释
1 /**
2 * A <i>thread</i> is a thread of execution in a program. The Java
3 * Virtual Machine allows an application to have multiple threads of
4 * execution running concurrently.
5 * <p>
6 * Every thread has a priority. Threads with higher priority are
7 * executed in preference to threads with lower priority. Each thread
8 * may or may not also be marked as a daemon. When code running in
9 * some thread creates a new <code>Thread</code> object, the new
10 * thread has its priority initially set equal to the priority of the
11 * creating thread, and is a daemon thread if and only if the
12 * creating thread is a daemon.
13 * <p>
14 * When a Java Virtual Machine starts up, there is usually a single
15 * non-daemon thread (which typically calls the method named
16 * <code>main</code> of some designated class). The Java Virtual
17 * Machine continues to execute threads until either of the following
18 * occurs:
19 * <ul>
20 * <li>The <code>exit</code> method of class <code>Runtime</code> has been
21 * called and the security manager has permitted the exit operation
22 * to take place.
23 * <li>All threads that are not daemon threads have died, either by
24 * returning from the call to the <code>run</code> method or by
25 * throwing an exception that propagates beyond the <code>run</code>
26 * method.
27 * </ul>
28 * <p>
29 * There are two ways to create a new thread of execution. One is to
30 * declare a class to be a subclass of <code>Thread</code>. This
31 * subclass should override the <code>run</code> method of class
32 * <code>Thread</code>. An instance of the subclass can then be
33 * allocated and started. For example, a thread that computes primes
34 * larger than a stated value could be written as follows:
35 * <hr><blockquote><pre>
36 * class PrimeThread extends Thread {
37 * long minPrime;
38 * PrimeThread(long minPrime) {
39 * this.minPrime = minPrime;
40 * }
41 *
42 * public void run() {
43 * // compute primes larger than minPrime
44 * . . .
45 * }
46 * }
47 * </pre></blockquote><hr>
48 * <p>
49 * The following code would then create a thread and start it running:
50 * <blockquote><pre>
51 * PrimeThread p = new PrimeThread(143);
52 * p.start();
53 * </pre></blockquote>
54 * <p>
55 * The other way to create a thread is to declare a class that
56 * implements the <code>Runnable</code> interface. That class then
57 * implements the <code>run</code> method. An instance of the class can
58 * then be allocated, passed as an argument when creating
59 * <code>Thread</code>, and started. The same example in this other
60 * style looks like the following:
61 * <hr><blockquote><pre>
62 * class PrimeRun implements Runnable {
63 * long minPrime;
64 * PrimeRun(long minPrime) {
65 * this.minPrime = minPrime;
66 * }
67 *
68 * public void run() {
69 * // compute primes larger than minPrime
70 * . . .
71 * }
72 * }
73 * </pre></blockquote><hr>
74 * <p>
75 * The following code would then create a thread and start it running:
76 * <blockquote><pre>
77 * PrimeRun p = new PrimeRun(143);
78 * new Thread(p).start();
79 * </pre></blockquote>
80 * <p>
81 * Every thread has a name for identification purposes. More than
82 * one thread may have the same name. If a name is not specified when
83 * a thread is created, a new name is generated for it.
84 * <p>
85 * Unless otherwise noted, passing a {@code null} argument to a constructor
86 * or method in this class will cause a {@link NullPointerException} to be
87 * thrown.
88 *
89 * @author unascribed
90 * @see Runnable
91 * @see Runtime#exit(int)
92 * @see #run()
93 * @see #stop()
94 * @since JDK1.0
95 */通过顶部注释我们就可以发现,创建多线程有两种方法:
继承 Thread,重写 run 方法
实现 Runnable 接口,重写 run 方法
1.6 Java 实现多线程需要注意的细节
不要将 run 和 start 搞混了
run 和 start 的区别
run 仅仅是封装了被线程执行的代码,直接调用是普通方法
start 首先启动了线程,然后再由 Java 虚拟机去调用线程的 run 方法
jvm 虚拟机启动的是单线程还是多线程的
是多线程的。不仅仅是启动 main 线程,还至少会启动垃圾回收线程的,不然谁帮你回收不用的内存
那么,既然有两种方式实现多线程,我们一般使用哪一种
一般我们使用实现 Runnable 接口
可以避免 Java 中的单继承的限制
应该将并发运行任务和运行机制解耦,因此我们选择 Runnable 接口这种方式
二、总结
简单入门。

JavaScipt对象的基本知识_基础知识
javascript 是使用“对象化编程”的,或者叫“面向对象编程”的。所谓“对象化编程”,意思是把 javascript 能涉及的范围划分成大大小小的对象,对象下面还继续划分对象直至非常详细为止,所有的编程都以对象为出发点,基于对象。小到一个变量,大到网页文档、窗口甚至屏幕,都是对象。这一章将“面向对象”讲述 javascript 的运行情况。
对象的基本知识
对象是可以从 javascript“势力范围”中划分出来的一小块,可以是一段文字、一幅图片、一个表单(form)等等。每个对象有它自己的属性、方法和事件。对象的属性是反映该对象某些特定的性质的,例如:字符串的长度、图像的长宽、文字框(textbox)里的文字等等;对象的方法能对该对象做一些事情,例如,表单的“提交”(submit),窗口的“滚动”(scrolling)等等;而对象的事件就能响应发生在对象上的事情,例如提交表单产生表单的“提交事件”,点击连接产生的“点击事件”。不是所有的对象都有以上三个性质,有些没有事件,有些只有属性。引用对象的任一“性质”用“.”这种方法。
基本对象
现在我们要复习以上学过的内容了——把一些数据类型用对象的角度重新学习一下。
number “数字”对象。这个对象用得很少,作者就一次也没有见过。不过属于“number”的对象,也就是“变量”就多了。
属性
max_value 用法:number.max_value;返回“最大值”。
min_value 用法:number.min_value;返回“最小值”。
nan 用法:number.nan 或 nan;返回“nan”。“nan”(不是数值)在很早就介绍过了。
negative_infinity 用法:number.negative_infinity;返回:负无穷大,比“最小值”还小的值。
positive_infinity 用法:number.positive_infinity;返回:正无穷大,比“最大值”还大的值。
方法
tostring() 用法:.tostring();返回:字符串形式的数值。如:若 a == 123;则 a.tostring() == ''123''。
string 字符串对象。声明一个字符串对象最简单、快捷、有效、常用的方法就是直接赋值。
属性
length 用法:.length;返回该字符串的长度。
方法
charat() 用法:.charat();返回该字符串位于第位的单个字符。注意:字符串中的一个字符是第 0 位的,第二个才是第 1 位的,最后一个字符是第 length - 1 位的。
charcodeat() 用法:.charcodeat();返回该字符串位于第位的单个字符的 ascii 码。
fromcharcode() 用法:string.fromcharcode(a, b, c...);返回一个字符串,该字符串每个字符的 ascii 码由 a, b, c... 等来确定。
indexof() 用法:.indexof([, ]);该方法从中查找(如果给出就忽略之前的位置),如果找到了,就返回它的位置,没有找到就返回“-1”。所有的“位置”都是从零开始的。
lastindexof() 用法:.lastindexof([, ]);跟 indexof() 相似,不过是从后边开始找。
split() 用法:.split();返回一个数组,该数组是从中分离开来的,决定了分离的地方,它本身不会包含在所返回的数组中。例如:''1&2&345&678''.split(''&'')返回数组:1,2,345,678。关于数组,我们等一下就讨论。
substring() 用法:.substring([, ]);返回原字符串的子字符串,该字符串是原字符串从位置到位置的前一位置的一段。 - = 返回字符串的长度(length)。如果没有指定或指定得超过字符串长度,则子字符串从位置一直取到原字符串尾。如果所指定的位置不能返回字符串,则返回空字符串。
substr() 用法:.substr([, ]);返回原字符串的子字符串,该字符串是原字符串从位置开始,长度为的一段。如果没有指定或指定得超过字符串长度,则子字符串从位置一直取到原字符串尾。如果所指定的位置不能返回字符串,则返回空字符串。
tolowercase() 用法:.tolowercase();返回把原字符串所有大写字母都变成小写的字符串。
touppercase() 用法:.touppercase();返回把原字符串所有小写字母都变成大写的字符串。
array 数组对象。数组对象是一个对象的集合,里边的对象可以是不同类型的。数组的每一个成员对象都有一个“下标”,用来表示它在数组中的位置(既然是“位置”,就也是从零开始的啦)。
数组的定义方法:
var = new array();
这样就定义了一个空数组。以后要添加数组元素,就用:
[] = ...;
注意这里的方括号不是“可以省略”的意思,数组的下标表示方法就是用方括号括起来。
如果想在定义数组的时候直接初始化数据,请用:
var = new array(, , ...);
例如,var myarray = new array(1, 4.5, ''hi''); 定义了一个数组 myarray,里边的元素是:myarray[0] == 1; myarray[1] == 4.5; myarray[2] == ''hi''。
但是,如果元素列表中只有一个元素,而这个元素又是一个正整数的话,这将定义一个包含个空元素的数组。
注意:javascript只有一维数组!千万不要用“array(3,4)”这种愚蠢的方法来定义 4 x 5 的二维数组,或者用“myarray[2,3]”这种方法来返回“二维数组”中的元素。任意“myarray[...,3]”这种形式的调用其实只返回了“myarray[3]”。要使用多维数组,请用这种虚拟法:
var myarray = new array(new array(), new array(), new array(), ...);
其实这是一个一维数组,里边的每一个元素又是一个数组。调用这个“二维数组”的元素时:myarray[2][3] = ...;
属性
length 用法:.length;返回:数组的长度,即数组里有多少个元素。它等于数组里最后一个元素的下标加一。所以,想添加一个元素,只需要:myarray[myarray.length] = ...。
方法
join() 用法:.join();返回一个字符串,该字符串把数组中的各个元素串起来,用置于元素与元素之间。这个方法不影响数组原本的内容。
reverse() 用法:.reverse();使数组中的元素顺序反过来。如果对数组[1, 2, 3]使用这个方法,它将使数组变成:[3, 2, 1]。
slice() 用法:.slice([, ]);返回一个数组,该数组是原数组的子集,始于,终于。如果不给出,则子集一直取到原数组的结尾。
sort() 用法:.sort([]);使数组中的元素按照一定的顺序排列。如果不指定,则按字母顺序排列。在这种情况下,80 是比 9 排得前的。如果指定,则按所指定的排序方法排序。比较难讲述,这里只将一些有用的介绍给大家。
按升序排列数字:
function sortmethod(a, b) {
return a - b;
}
myarray.sort(sortmethod);
按降序排列数字:把上面的“a - b”该成“b - a”。
有关函数,请看下面。
math “数学”对象,提供对数据的数学计算。下面所提到的属性和方法,不再详细说明“用法”,大家在使用的时候记住用“math.”这种格式。
属性
e 返回常数 e (2.718281828...)。
ln2 返回 2 的自然对数 (ln 2)。
ln10 返回 10 的自然对数 (ln 10)。
log2e 返回以 2 为低的 e 的对数 (log2e)。
log10e 返回以 10 为低的 e 的对数 (log10e)。
pi 返回π(3.1415926535...)。
sqrt1_2 返回 1/2 的平方根。
sqrt2 返回 2 的平方根。
方法
abs(x) 返回 x 的绝对值。
acos(x) 返回 x 的反余弦值(余弦值等于 x 的角度),用弧度表示。
asin(x) 返回 x 的反正弦值。
atan(x) 返回 x 的反正切值。
atan2(x, y) 返回复平面内点(x, y)对应的复数的幅角,用弧度表示,其值在 -π 到 π 之间。
ceil(x) 返回大于等于 x 的最小整数。
cos(x) 返回 x 的余弦。
exp(x) 返回 e 的 x 次幂 (ex)。
floor(x) 返回小于等于 x 的最大整数。
log(x) 返回 x 的自然对数 (ln x)。
max(a, b) 返回 a, b 中较大的数。
min(a, b) 返回 a, b 中较小的数。
pow(n, m) 返回 n 的 m 次幂 (nm)。
random() 返回大于 0 小于 1 的一个随机数。
round(x) 返回 x 四舍五入后的值。
sin(x) 返回 x 的正弦。
sqrt(x) 返回 x 的平方根。
tan(x) 返回 x 的正切。
date 日期对象。这个对象可以储存任意一个日期,从 0001 年到 9999 年,并且可以精确到毫秒数(1/1000 秒)。在内部,日期对象是一个整数,它是从 1970 年 1 月 1 日零时正开始计算到日期对象所指的日期的毫秒数。如果所指日期比 1970 年早,则它是一个负数。所有日期时间,如果不指定时区,都采用“utc”(世界时)时区,它与“gmt”(格林威治时间)在数值上是一样的。
定义一个日期对象:
var d = new date;
这个方法使 d 成为日期对象,并且已有初始值:当前时间。如果要自定初始值,可以用:
var d = new date(99, 10, 1); //99 年 10 月 1 日
var d = new date(''oct 1, 1999''); //99 年 10 月 1 日
等等方法。最好的方法就是用下面介绍的“方法”来严格的定义时间。
方法
以下有很多“g/set[utc]xxx”这样的方法,它表示既有“getxxx”方法,又有“setxxx”方法。“get”是获得某个数值,而“set”是设定某个数值。如果带有“utc”字母,则表示获得/设定的数值是基于 utc 时间的,没有则表示基于本地时间或浏览期默认时间的。
如无说明,方法的使用格式为:“.”,下同。
g/set[utc]fullyear() 返回/设置年份,用四位数表示。如果使用“x.set[utc]fullyear(99)”,则年份被设定为 0099 年。
g/set[utc]year()返回/设置年份,用两位数表示。设定的时候浏览器自动加上“19”开头,故使用“x.set[utc]year(00)”把年份设定为 1900 年。
g/set[utc]month()返回/设置月份。
g/set[utc]date()返回/设置日期。
g/set[utc]day()返回/设置星期,0 表示星期天。
g/set[utc]hours()返回/设置小时数,24小时制。
g/set[utc]minutes()返回/设置分钟数。
g/set[utc]seconds()返回/设置秒钟数。
g/set[utc]milliseconds()返回/设置毫秒数。
g/settime() 返回/设置时间,该时间就是日期对象的内部处理方法:从 1970 年 1 月 1 日零时正开始计算到日期对象所指的日期的毫秒数。如果要使某日期对象所指的时间推迟 1 小时,就用:“x.settime(x.gettime() + 60 * 60 * 1000);”(一小时 60 分,一分 60 秒,一秒 1000 毫秒)。
gettimezoneoffset() 返回日期对象采用的时区与格林威治时间所差的分钟数。在格林威治东方的市区,该值为负,例如:中国时区(gmt+0800)返回“-480”。
tostring() 返回一个字符串,描述日期对象所指的日期。这个字符串的格式类似于:“fri jul 21 15:43:46 utc+0800 2000”。
tolocalestring() 返回一个字符串,描述日期对象所指的日期,用本地时间表示格式。如:“2000-07-21 15:43:46”。
togmtstring() 返回一个字符串,描述日期对象所指的日期,用 gmt 格式。
toutcstring() 返回一个字符串,描述日期对象所指的日期,用 utc 格式。
parse() 用法:date.parse();返回该日期对象的内部表达方式。
全局对象
全局对象从不现形,它可以说是虚拟出来的,目的在于把全局函数“对象化”。在 microsoft jscript 语言参考中,它叫做“global 对象”,但是引用它的方法和属性从来不用“global.xxx”(况且这样做会出错),而直接用“xxx”。
属性
nan 一早就说过了。
方法
eval() 把括号内的字符串当作标准语句或表达式来运行。
isfinite() 如果括号内的数字是“有限”的(介于 number.min_value 和 number.max_value 之间)就返回 true;否则返回 false。
isnan() 如果括号内的值是“nan”则返回 true 否则返回 false。
parseint() 返回把括号内的内容转换成整数之后的值。如果括号内是字符串,则字符串开头的数字部分被转换成整数,如果以字母开头,则返回“nan”。
parsefloat() 返回把括号内的字符串转换成浮点数之后的值,字符串开头的数字部分被转换成浮点数,如果以字母开头,则返回“nan”。
tostring() 用法:.tostring();把对象转换成字符串。如果在括号中指定一个数值,则转换过程中所有数值转换成特定进制。
escape() 返回括号中的字符串经过编码后的新字符串。该编码应用于 url,也就是把空格写成“%20”这种格式。“+”不被编码,如果要“+”也被编码,请用:escape(''...'', 1)。
unescape() 是 escape() 的反过程。解编括号中字符串成为一般字符串。
函数函数的定义
所谓“函数”,是有返回值的对象或对象的方法。
函数的种类
常见的函数有:构造函数,如 array(),能构造一个数组;全局函数,即全局对象里的方法;自定义函数;等等。
自定义函数
定义函数用以下语句:
function 函数名([参数集]) {
...
[return[ ];]
...
}
其中,用在 function 之后和函数结尾的大括号是不能省去的,就算整个函数只有一句。
函数名与变量名有一样的起名规定,也就是只包含字母数字下划线、字母排头、不能与保留字重复等。
参数集可有可无,但括号就一定要有。
参数 是函数外部向函数内部传递信息的桥梁,例如,想叫一个函数返回 3 的立方,你就要让函数知道“3”这个数值,这时候就要有一个变量来接收数值,这种变量叫做参数。
参数集是一个或多个用逗号分隔开来的参数的集合,如:a, b, c。
函数的内部有一至多行语句,这些语句并不会立即执行,而只当有其它程序调用它时才执行。这些语句中可能包含“return”语句。在执行一个函数的时候,碰到 return 语句,函数立刻停止执行,并返回到调用它的程序中。如果“return”后带有,则退出函数的同时返回该值。
在函数的内部,参数可以直接当作变量来使用,并可以用 var 语句来新建一些变量,但是这些变量都不能被函数外部的过程调用。要使函数内部的信息能被外部调用,要么使用“return”返回值,要么使用全局变量。
全局变量 在 script 的“根部”(非函数内部)的“var”语句所定义的变量就是全局变量,它能在整个过程的任意地方被调用、更改。
例
function addall(a, b, c) {
return a + b + c;
}
var total = addall(3, 4, 5);
这个例子建立了一个叫“addall”的函数,它有 3 个参数:a, b, c,作用是返回三个数相加的结果。在函数外部,利用“var total = addall(3, 4, 5);”接收函数的返回值。
更多的时候,函数是没有返回值的,这种函数在一些比较强调严格的语言中是叫做“过程”的,例如 basic 类语言的“sub”、pascal 语言的“procedure”。
属性
arguments 一个数组,反映外部程序调用函数时指定的参数。用法:直接在函数内部调用“arguments”。
关于Java基础知识_TreeMap和java基础知识笔记的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于Java 基础知识_ConcurrentHashMap、Java 基础知识_Map 集合、散列表、红黑树、Java 基础知识_多线程入门、JavaScipt对象的基本知识_基础知识等相关内容,可以在本站寻找。
本文标签:




