在本文中,我们将给您介绍关于NO_RESPONSE_FROM_FUNCTIONNextJS部署与getServerSideProps的详细内容,并且为您解答node.jsresponse的相关问题,此
在本文中,我们将给您介绍关于NO_RESPONSE_FROM_FUNCTION NextJS 部署与 getServerSideProps的详细内容,并且为您解答node.js response的相关问题,此外,我们还将为您提供关于appium 报错:selenium.common.exceptions.WebDriverException: Message: An unknown server-side error occu、Automated Refactoring from Mainframe to Serverless Functions and Containers with Blu Age、BERT(Bidirectional Encoder Representations from Transformers)理解、Cannot open connection] with root cause com.microsoft.sqlserver.jdbc.SQLServerException: Connection reset的知识。
本文目录一览:- NO_RESPONSE_FROM_FUNCTION NextJS 部署与 getServerSideProps(node.js response)
- appium 报错:selenium.common.exceptions.WebDriverException: Message: An unknown server-side error occu
- Automated Refactoring from Mainframe to Serverless Functions and Containers with Blu Age
- BERT(Bidirectional Encoder Representations from Transformers)理解
- Cannot open connection] with root cause com.microsoft.sqlserver.jdbc.SQLServerException: Connection reset
")
NO_RESPONSE_FROM_FUNCTION NextJS 部署与 getServerSideProps(node.js response)
如何解决NO_RESPONSE_FROM_FUNCTION NextJS 部署与 getServerSideProps?
我正在 vercel 上部署我的网站,但在加载详细信息页面时遇到了 502: BAD_GATEWAY NO RESPONSE FROM FUNCTION 错误。为此,我正在使用 getServerSideProps。在我的本地主机上,它运行良好。您可以在此处查看代码:
export async function getServerSideProps(context) {
const apollo = require(''../../lib/apolloClient''); // import client
var XMLHttpRequest = require(''xmlhttprequest'').XMLHttpRequest;
var xhr = new XMLHttpRequest();
const GET_PROJECT_BY_ID = gql`
query getProjectById($id: Int!) {
projects(where: { id: { _eq: $id } }) {
id
title
}
}
`;
const client = apollo.default();
const { data,error } = await client.query({
query: GET_PROJECT_BY_ID,variables: { id: context.params.id },});
if (!data || error) {
return {
notFound: true,};
}
return { props: { props: data.projects[0] } };
}
我有另一个页面,项目概述,我在其中加载了所有项目。我使用 getServerSideProps 的方式和我在这里一样,在那里也能用。
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

appium 报错:selenium.common.exceptions.WebDriverException: Message: An unknown server-side error occu
appium进行手机浏览器的自动化测试启动代码如下
#使用手机浏览器进行自动化测试
import time
from appium import webdriver
#自动化配置信息
des={
'platformName': 'Android',
'platformVersion': '8.0', #填写android虚拟机的系统版本
'deviceName': 'SamSung galaxy S9', #填写安卓虚拟机的设备名称---值可以随便写
'browserName': 'chrome', # 直接指定浏览器名称参数为chrome【重点添加了这一步】
'udid': '192.168.235.103:5555', # 填写通过命令行 adb devices 查看到的 uuid
'noreset': True, # 确保自动化之后不重置app
'unicodeKeyboard': True,
'resetKeyboard': True,
'chromedriverExecutable': r"C:\Program Files\Appium\resources\app\node_modules\appium\node_modules\appium-chromedriver\chromedriver\win\chromedriver.exe" #使用指定的浏览器驱动-匹配手机上的谷歌浏览器
}
driver = webdriver.Remote('http://127.0.0.1:4723/wd/hub', des)
driver.implicitly_wait(5)
driver.get('http://hao.uc.cn/') #打开UC网页
报错如下:
selenium.common.exceptions.WebDriverException:
Message: An unkNown server-side error occurred while processing the command. Original error: Can't stop process;
it's not currently running (cmd: ''C:/Program Files/Appium/resources/app/node_modules/appium/node_modules/appium-chromedriver/chromedriver/win/chromedriver.exe' --url-base\=wd/hub --port\=8001 --adb-port\=5037 --verbose')
原因
折腾了相当久 ,两个晚上 才找到原因,代码没有问题,问题出在浏览器版本与chromedriver版本不一致导致的
解决办法
下载与浏览器版本一致的驱动后,再次启动就成功了。
对应浏览器版本的Chromedriver下载地址:https://npm.taobao.org/mirrors/chromedriver
chromedriver版本匹配地址:https://github.com/appium/appium/blob/master/docs/en/writing-running-appium/web/chromedriver.md

Automated Refactoring from Mainframe to Serverless Functions and Containers with Blu Age
https://amazonaws-china.com/blogs/apn/automated-refactoring-from-mainframe-to-serverless-functions-and-containers-with-blu-age/
By Alexis Henry, Chief Technology Officer at Blu Age
By Phil de Valence, Principal Solutions Architect for Mainframe Modernization at AWS
 |
 |
Mainframe workloads are often tightly-coupled legacy monoliths with millions of lines of code, and customers want to modernize them for business agility.
Manually rewriting a legacy application for a cloud-native architecture requires re-engineering use cases, functions, data models, test cases, and integrations. For a typical mainframe workload with millions of lines of code, this involves large teams over long periods of time, which can be risky and cost-prohibitive.
Fortunately, Blu Age Velocity accelerates the mainframe transformation to agile serverless functions or containers. It relies on automated refactoring and preserves the investment in business functions while expediting the reliable transition to newer languages, data stores, test practices, and cloud services.
Blu Age is an AWS Partner Network (APN) Select Technology Partner that helps organizations enter the digital era by modernizing legacy systems while substantially reducing modernization costs, shortening project duration, and mitigating the risk of failure.
In this post, we’ll describe how to transform a typical mainframe CICS application to Amazon Web Services (AWS) containers and AWS Lambda functions. We’ll show you how to increase mainframe workload agility with refactoring to serverless and containers.
Customer Drivers
There are two main drivers for mainframe modernization with AWS: cost reduction and agility. Agility has many facets related to the application, underlying infrastructure, and modernization itself.
On the infrastructure agility side, customers want to go away from rigid mainframe environments in order to benefit from the AWS Cloud’s elastic compute, managed containers, managed databases, and serverless functions on a pay-as-you-go model.
They want to leave the complexity of these tightly-coupled systems in order to increase speed and adopt cloud-native architectures, DevOps best practices, automation, continuous integration and continuous deployment (CI/CD), and infrastructure as code.
On the application agility side, customers want to stay competitive by breaking down slow mainframe monoliths into leaner services and microservices, while at the same time unleashing the mainframe data.
Customers also need to facilitate polyglot architectures where development teams decide on the most suitable programming language and stack for each service.
Some customers employ large teams of COBOL developers with functional knowledge that should be preserved. Others suffer from the mainframe retirement skills gap and have to switch to more popular programming languages quickly.
Customers also require agility in the transitions. They want to choose when and how fast they execute the various transformations, and whether they’re done simultaneously or independently.
For example, a transition from COBOL to Java is not only a technical project but also requires transitioning code development personnel to the newer language and tools. It can involve retraining and new hiring.
A transition from mainframe to AWS should go at a speed which reduces complexity and minimizes risks. A transition to containers or serverless functions should be up to each service owner to decide. A transition to microservices needs business domain analysis, and consequently peeling a monolith is done gradually over time.
This post shows how Blu Age automated refactoring accelerates the customer journey to reach a company’s desired agility with cloud-native architectures and microservices. Blu Age does this by going through incremental transitions at a customer’s own pace.
Sample Mainframe COBOL Application
Let’s look at a sample application of a typical mainframe workload that we will then transform onto AWS.
This application is a COBOL application that’s accessed by users via 3270 screens defined by CICS BMS maps. It stores data in a DB2 z/OS relational database and in VSAM indexed files, using CICS Temporary Storage (TS) queues.
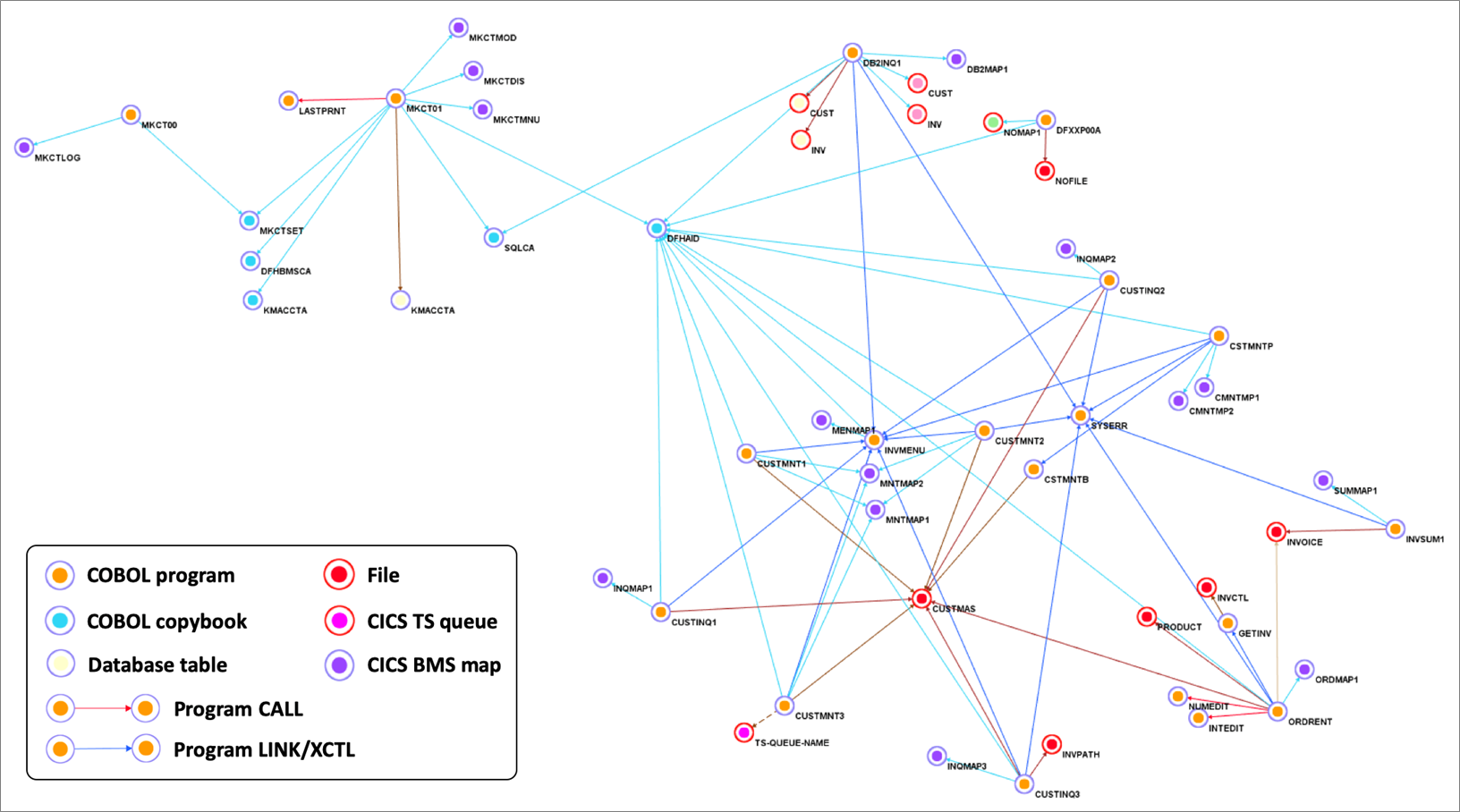
Figure 1 – Sample COBOL CICS application showing file dependencies.
We use Blu Age Analyzer to visualize the application components such as programs, copybooks, queues, and data elements.
Figure 1 above shows the Analyzer display. Each arrow represents a program call or dependency. You can see the COBOL programs using BMS maps for data entry and accessing data in DB2 database tables or VSAM files.
You can also identify the programs which are data-independent and those which access the same data file. This information helps define independent groupings that facilitate the migration into smaller services or even microservices.
This Analyzer view allows customers to identify the approach, groupings, work packages, and transitions for the automated refactoring.
In the next sections, we describe how to do the groupings and the transformation for three different target architectures: compute with Amazon Elastic Compute Cloud (Amazon EC2), containers with Amazon Elastic Kubernetes Service (Amazon EKS), and serverless functions with AWS Lambda.
Automated Refactoring to Elastic Compute
First, we transform the mainframe application to be deployed on Amazon EC2. This provides infrastructure agility with a large choice of instance types, horizontal scalability, auto scaling, some managed services, infrastructure automation, and cloud speed.
Amazon EC2 also provides some application agility with DevOps best practices, CI/CD pipeline, modern accessible data stores, and service-enabled programs.
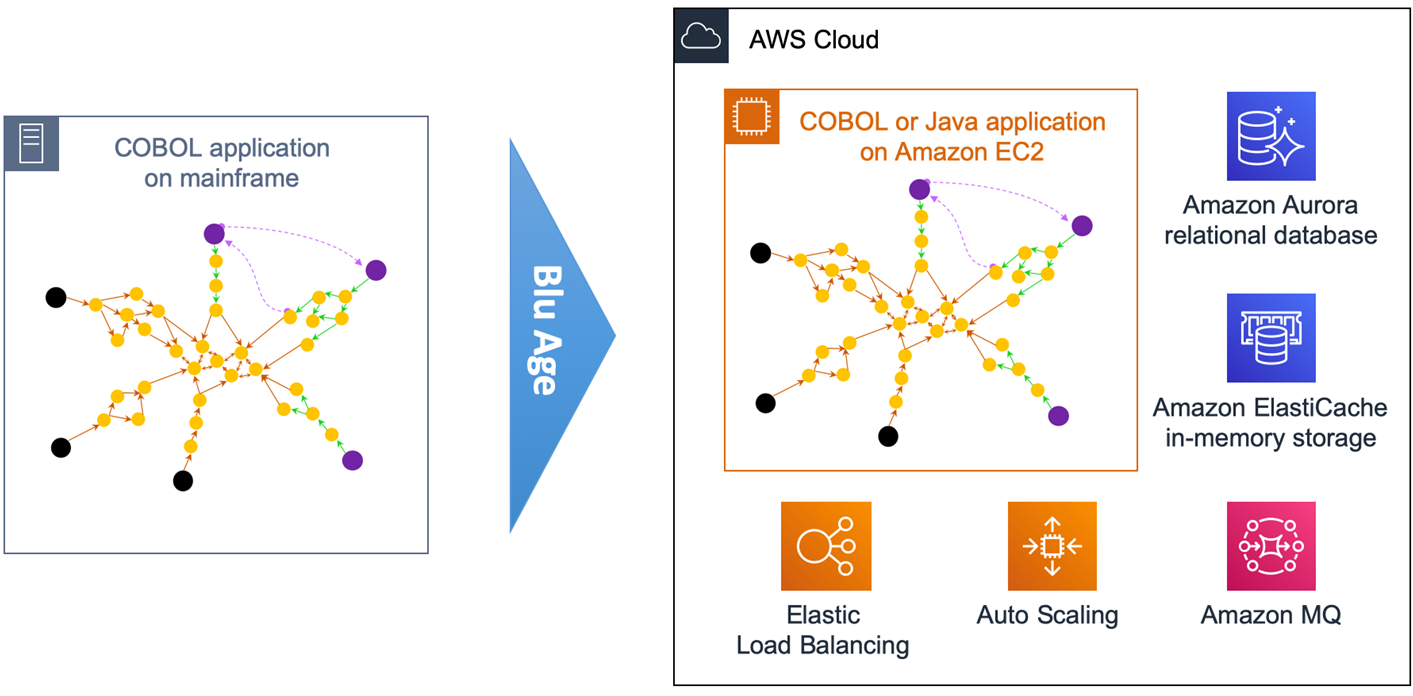
Figure 2 – Overview of automated refactoring from mainframe to Amazon EC2.
Figure 2 above shows the automated refactoring of the mainframe application to Amazon EC2.
The DB2 tables and VSAM files are refactored to Amazon Aurora relational database. Amazon ElastiCache is used for in-memory temporary storage or for performance acceleration, and Amazon MQ takes care of the messaging communications.
Once refactored, the application becomes stateless and elastic across many duplicate Amazon EC2 instances that benefit from Auto Scaling Groups and Elastic Load Balancing (ELB). The application code stays monolithic in this first transformation.
With such monolithic transformation, all programs and dependencies are kept together. That means we create only one grouping.
Figure 3 below shows the yellow grouping that includes all application elements. Using Blu Age Analyzer, we define groupings by assigning a common tag to multiple application elements.
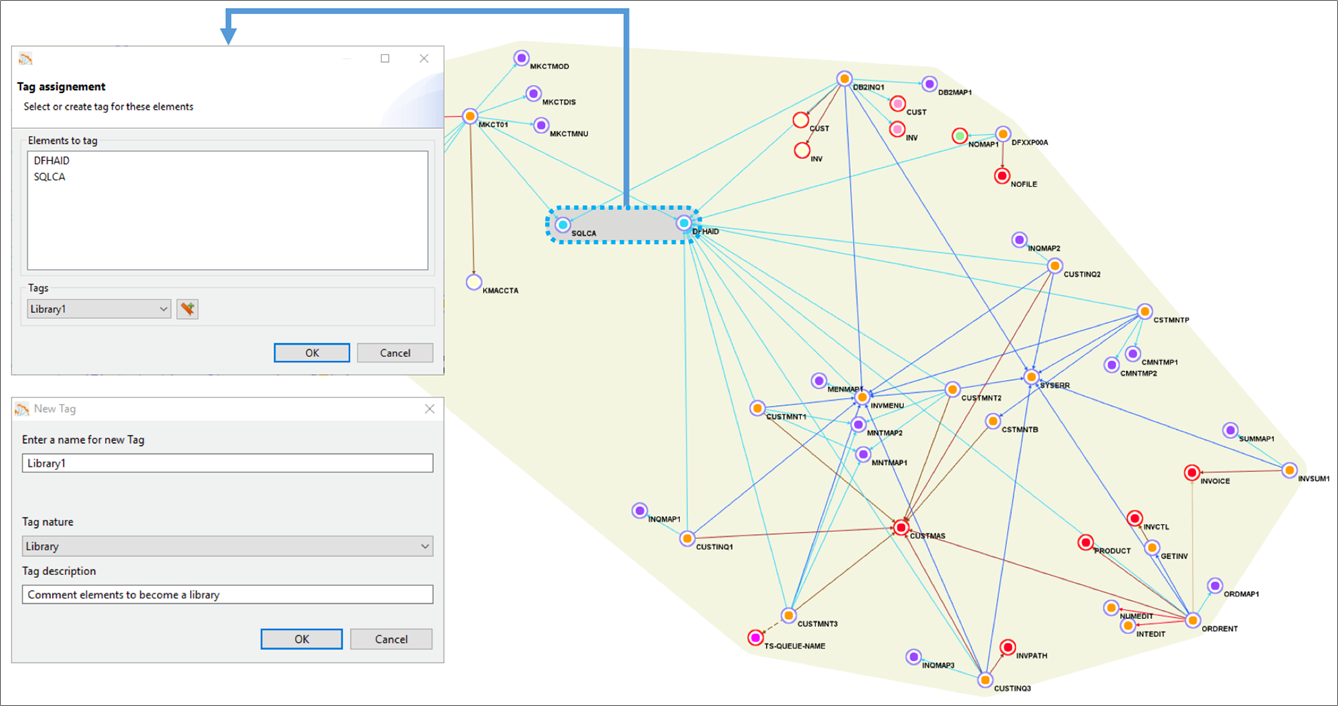
Figure 3 – Blu Age Analyzer with optional groupings for work packages and libraries.
With larger applications, it’s very likely we’d break down the larger effort by defining incremental work packages. Each work package is associated with one grouping and one tag.
Similarly, some shared programs or copybooks can be externalized and shared using a library. Each library is associated with one grouping and one tag. For example, in Figure 3 one library is created based on two programs, as shown by the grey grouping.
Ultimately, once the project is complete, all programs and work packages are deployed together within the same Amazon EC2 instances.
For each tag, we then export the corresponding application elements to Git.
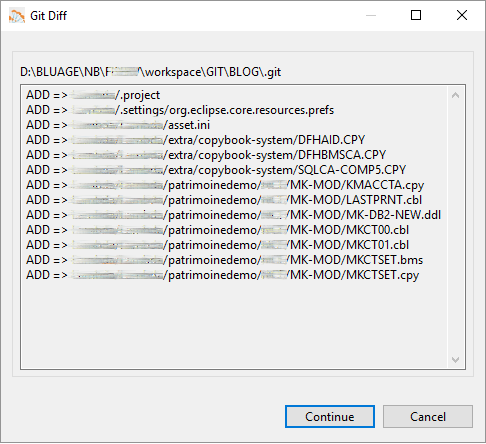
Figure 4 – Blu Age Analyzer export to Git.
Figure 4 shows the COBOL programs, copybooks, DB2 Data Definition Language (DDL), and BMS map being exported to Git.
As you can see in Figure 5 below, the COBOL application elements are available in the Integrated Development Environment (IDE) for maintenance, or for new development and compilation.
Blu Age toolset allows maintaining the migrated code in either in COBOL or in Java.
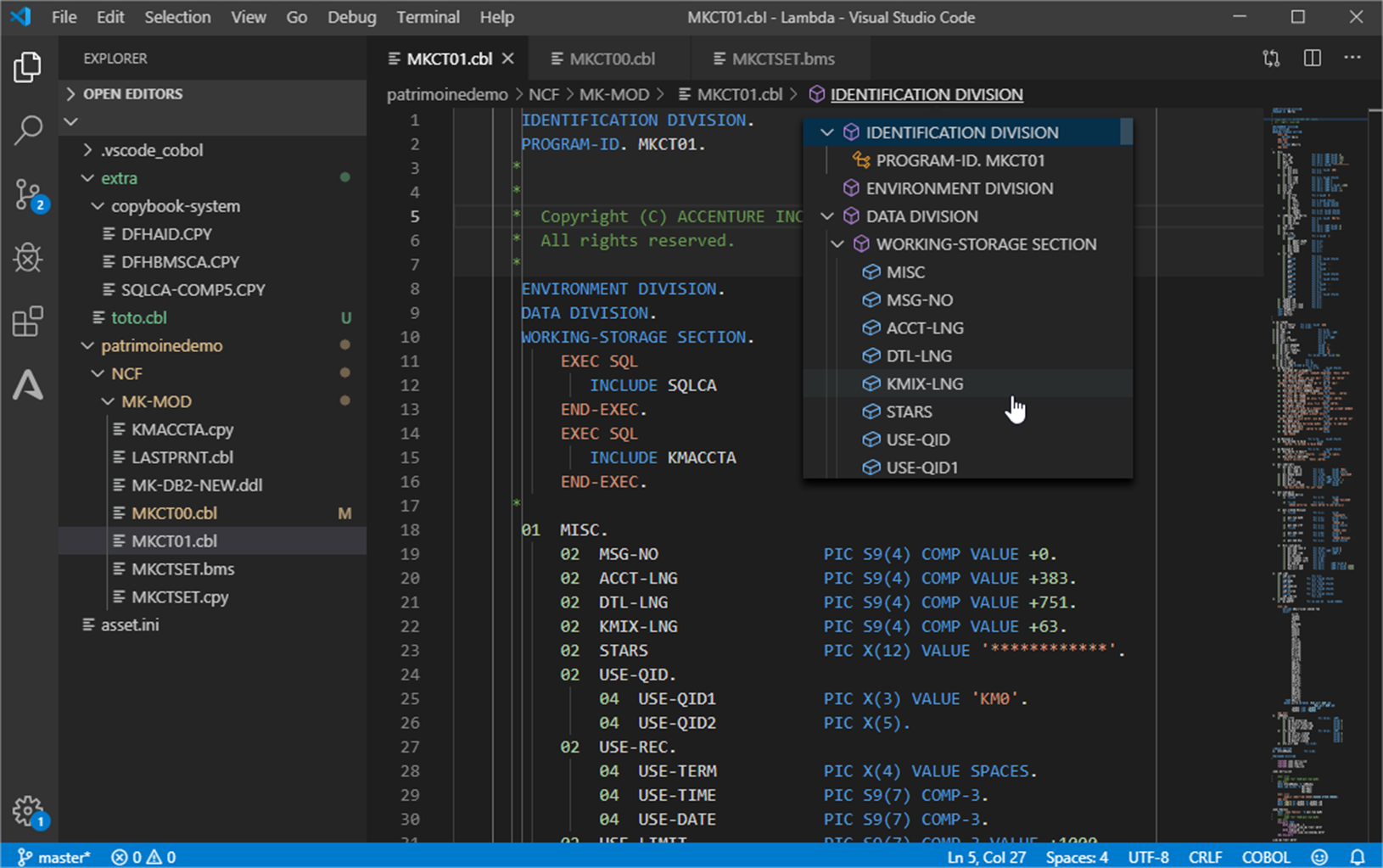
Figure 5 – Integrated Development Environment with COBOL application.
The code is recompiled and automatically packaged for the chosen target Amazon EC2 deployment.
During this packaging, the compute code is made stateless with any shared or persistent data externalized to data stores. This follows many of The Twelve-Factor App best practices that enable higher availability, scalability, and elasticity on the AWS Cloud.
In parallel, based on the code refactoring, the data from VSAM and DB2 z/OS is converted to the PostgreSQL-compatible edition of Amazon Aurora with corresponding data access queries conversions. Blu Age Velocity also generates the scripts for data conversion and migration.
Once deployed, the code and data go through unit, integration, and regression testing in order to validate functional equivalence. This is part of an automated CI/CD pipeline which also includes quality and security gates. The application is now ready for production on elastic compute.
Automated Refactoring to Containers
In this section, we increase agility by transforming the mainframe application to be deployed as different services in separate containers managed by Amazon EKS.
The application agility increases because the monolith is broken down into different services that can evolve and scale independently. Some services execute online transactions for users’ direct interactions. Some services execute batch processing. All services run in separate containers in Amazon EKS.
With such an approach, we can create microservices with both independent data stores and independent business functionalities. Read more about How to Peel Mainframe Monoliths for AWS Microservices with Blu Age.
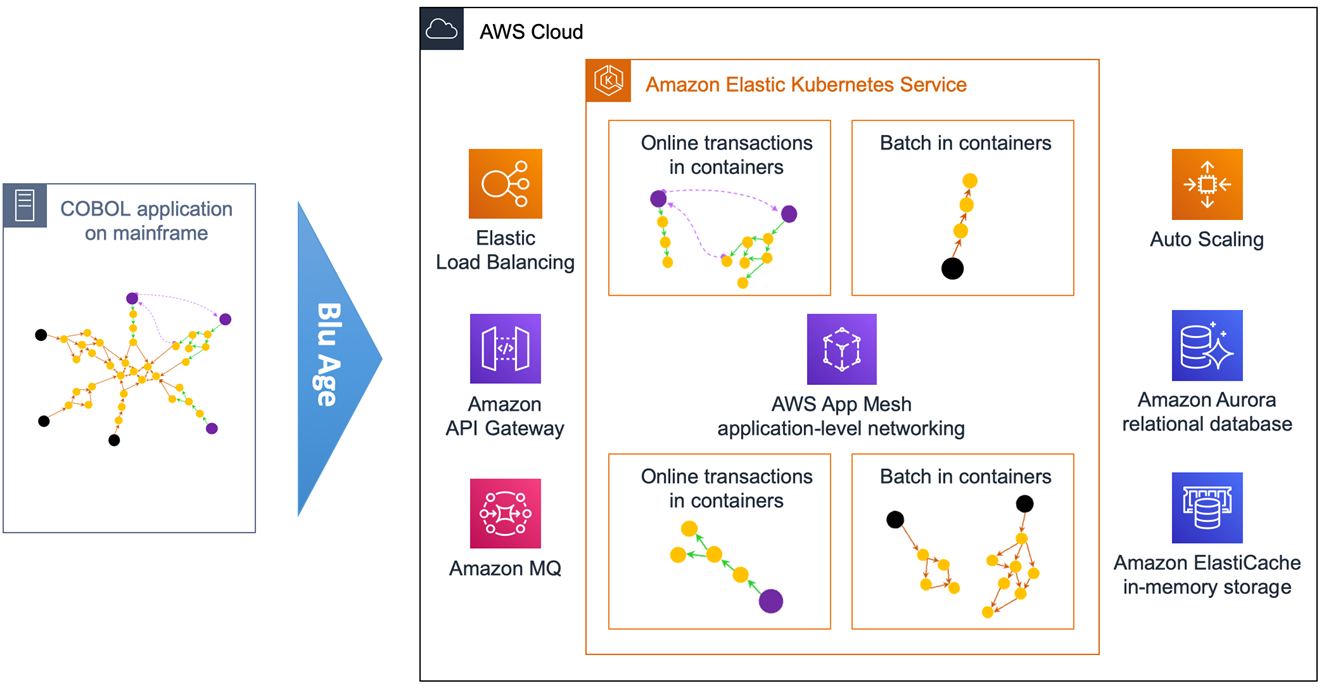
Figure 6 – Overview of automated refactoring from mainframe to Amazon EKS.
Figure 6 shows the automated refactoring of the mainframe application to Amazon EKS. You could also use Amazon Elastic Container Service (Amazon ECS) and AWS Fargate.
The mainframe application monolith is broken down targeting different containers for various online transactions, and different containers for various batch jobs. Each service DB2 tables and VSAM files are refactored to their own independent Amazon Aurora relational database.
AWS App Mesh facilitates internal application-level communication, while Amazon API Gateway and Amazon MQ focus more on the external integration.
With the Blu Age toolset, some services can still be maintained and developed in COBOL while others can be maintained in Java, which simultaneously allows a polyglot architecture.
For the application code maintained in COBOL on AWS, Blu Age Serverless COBOL provides native integration COBOL APIs for AWS services such as Amazon Aurora, Amazon Relational Database Service (Amazon RDS), Amazon DynamoDB, Amazon ElastiCache, and Amazon Kinesis, among others.
With such refactoring, programs and dependencies are grouped into separate services. This is called service decomposition and means we create multiple groupings in Blu Age Analyzer.
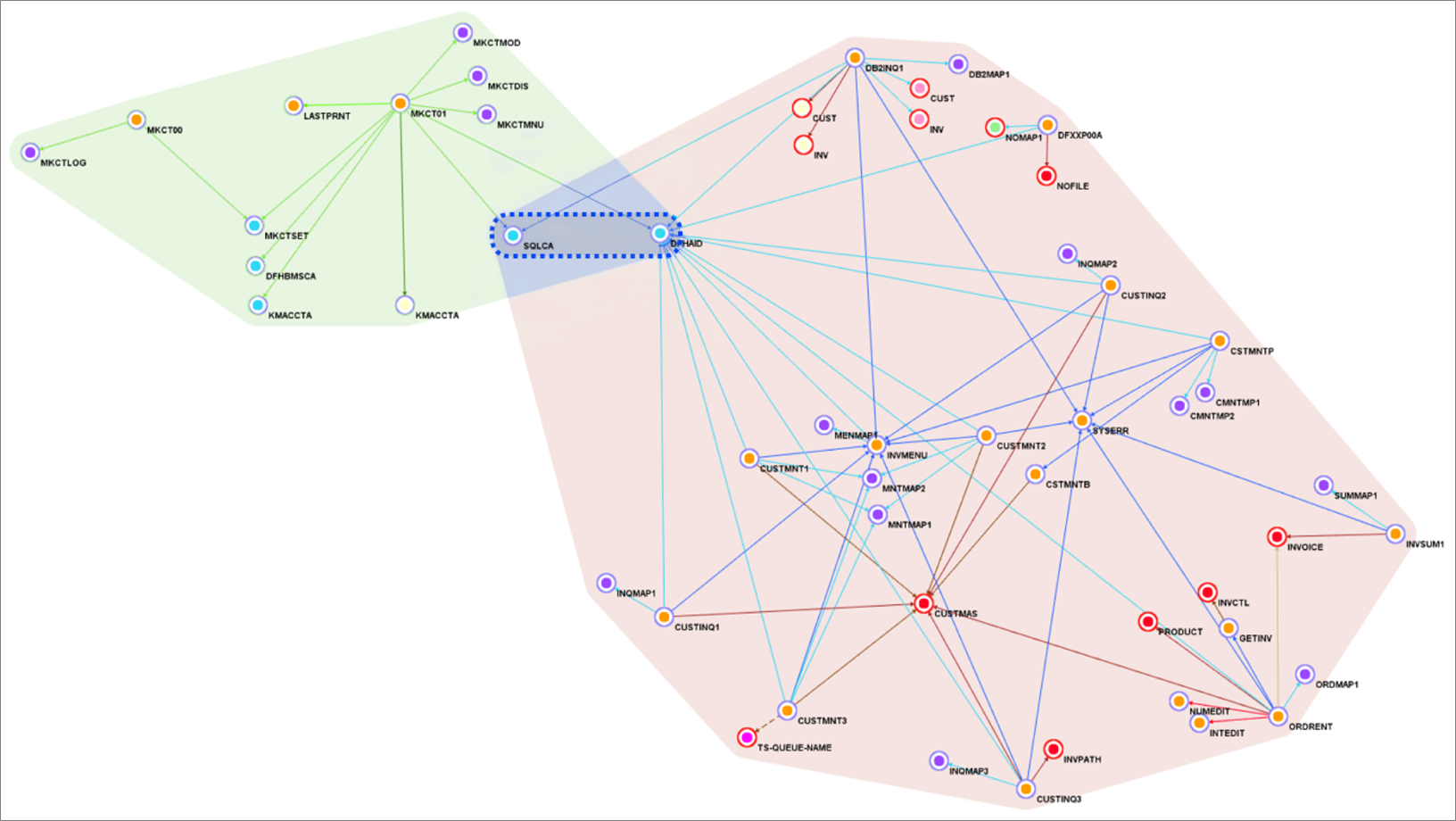
Figure 7 – Blu Age Analyzer with two services groupings and one library grouping.
Figure 7 shows one service grouping in green, another service grouping in rose, and a library grouping in blue. Groupings are formalized with one tag each.
For each tag, we export the corresponding application elements to Git and open them in the IDE for compilation. We can create one Git project per tag providing independence and agility to individual service owner.
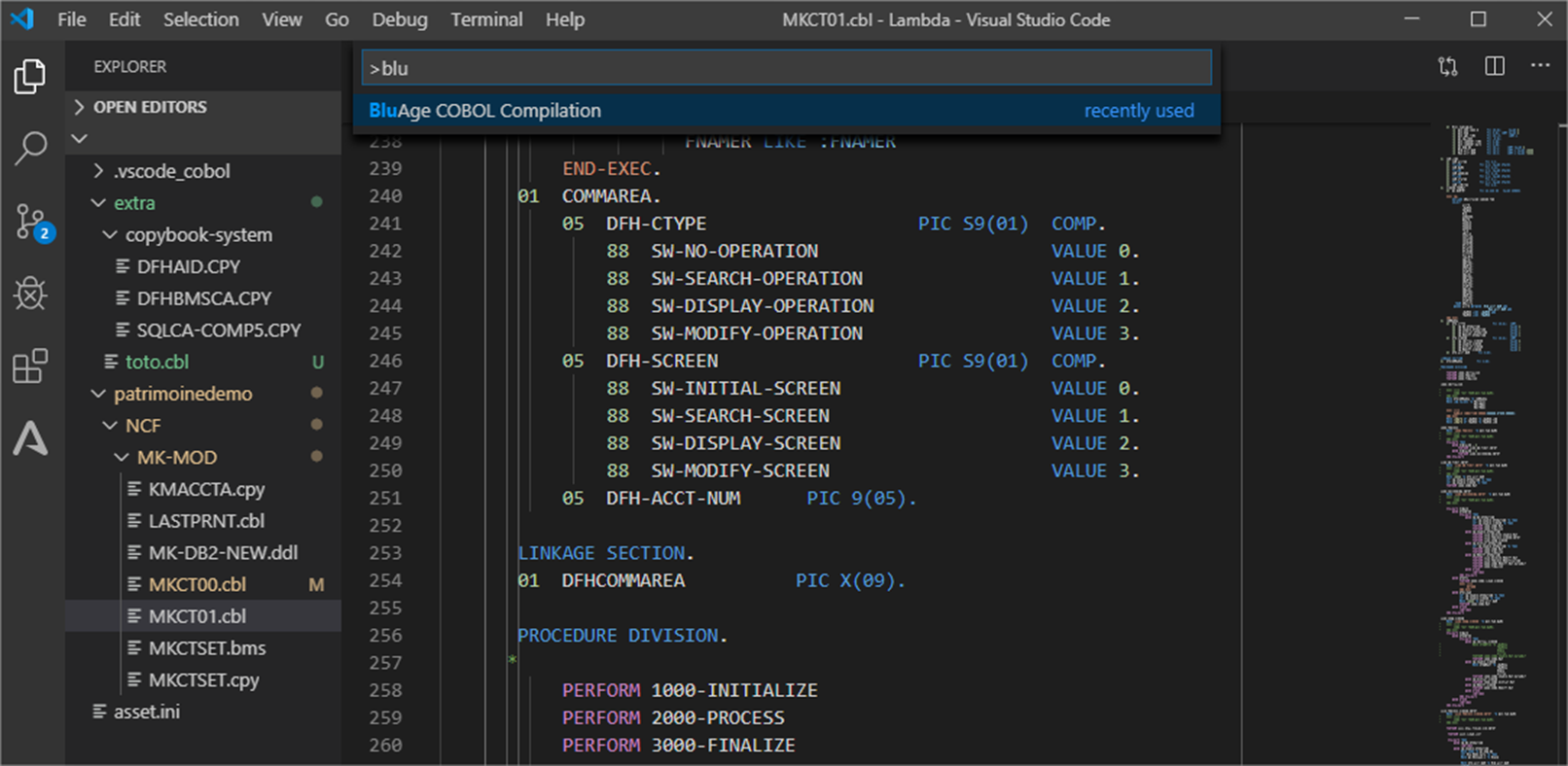
Figure 8 – COBOL program in IDE ready for compilation.
The Blu Age compiler for containers compiles the code and packages it into a Docker container image with all the necessary language runtime configuration for deployment and services communication.
The REST APIs for communication are automatically generated. The container images are automatically produced, versioned and stored into Amazon Elastic Container Registry (Amazon ECR), and the two container images are deployed onto Amazon EKS.
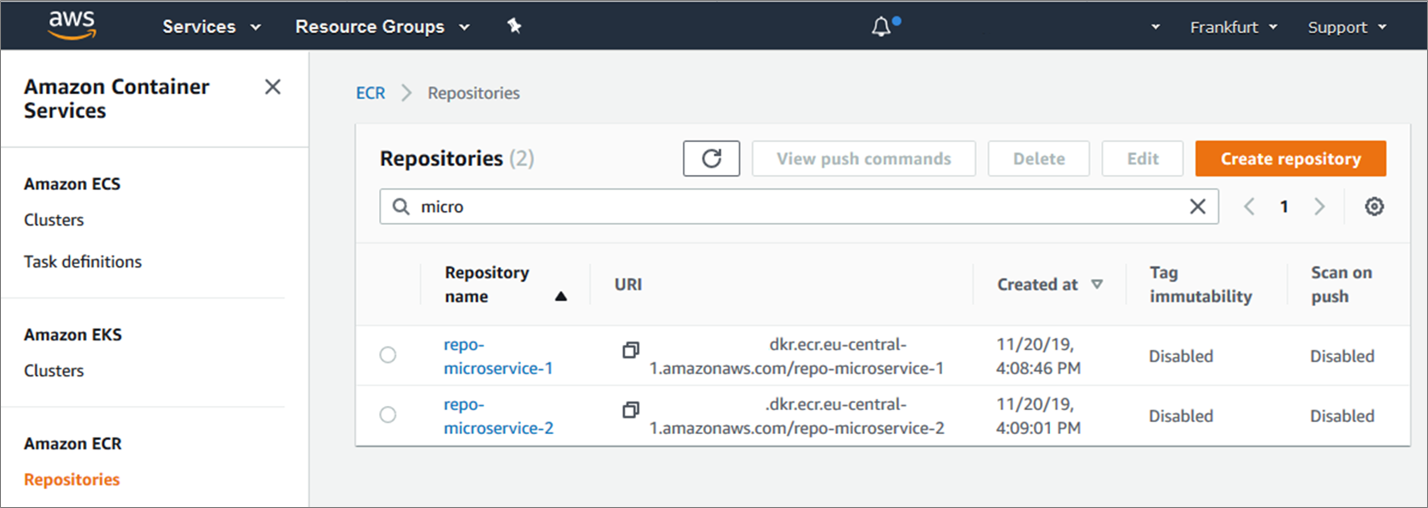
Figure 9 – AWS console showing the two container images created in Amazon ECR.
Figure 9 above shows the two new Docker container images referenced in Amazon ECR.
After going through data conversion and extensive testing similar to the previous section, the application is now ready for production on containers managed by Amazon EKS.
Automated Refactoring to Serverless Functions
Now, we can increase agility and cost efficiency further by targeting serverless functions in AWS Lambda.
Not only is the monolith broken down into separate services, but the services become smaller functions with no need to manage servers or containers. With Lambda, there’s no charge when the code is not running.
Not all programs are good use-cases for Lambda. Technical characteristics make Lambda better suited for short-lived lightweight stateless functions. For this reason, some services are deployed in Lambda while others are still deployed in containers or elastic compute.
For example, long-running batch processing cannot run in Lambda but they can run in containers. Online transactions or batch-specific short functions, on the other hand, can run in Lambda.
With this approach, we can create granular microservices with independent data stores and business functions.
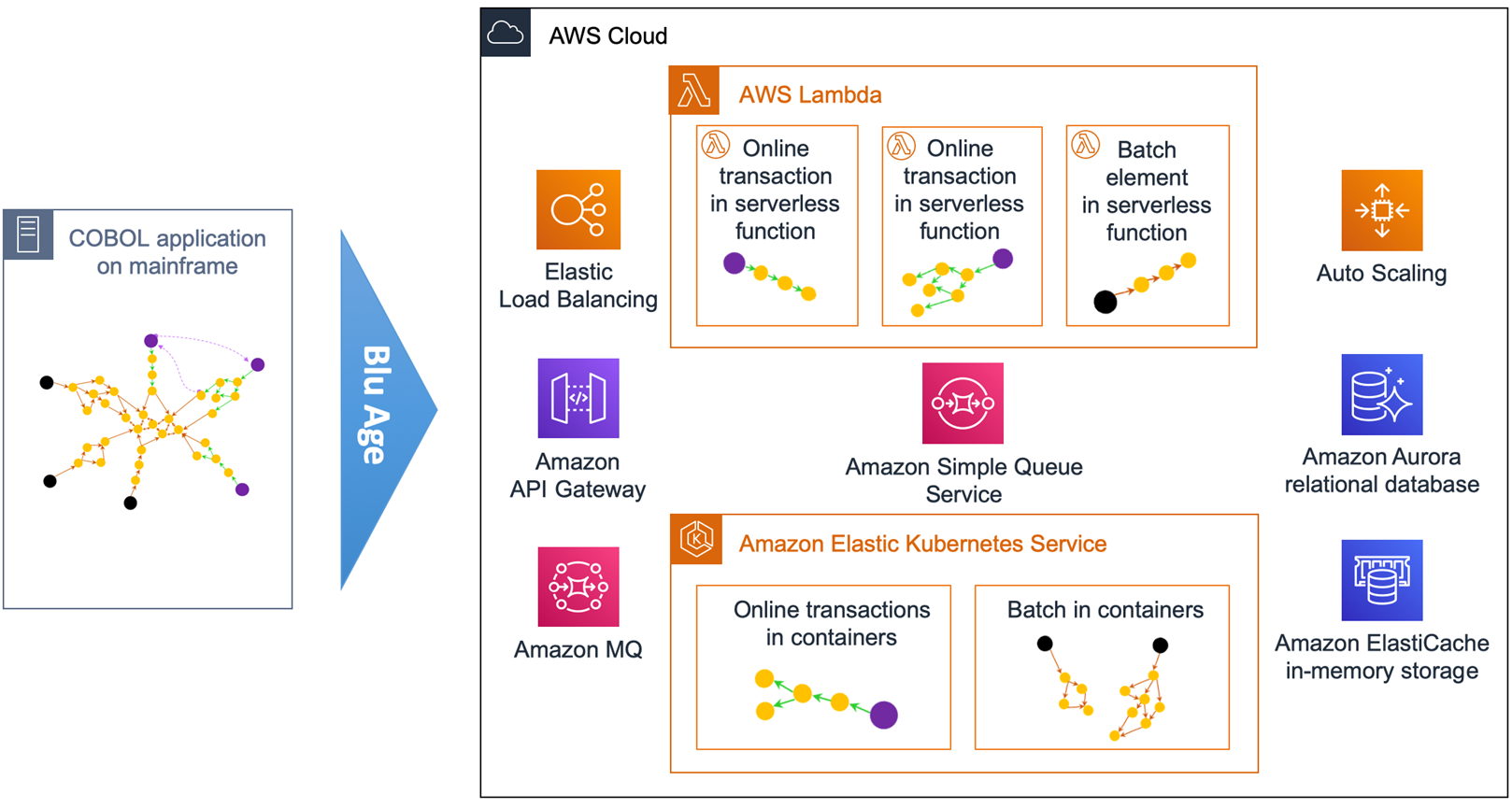
Figure 10 – Overview of automated refactoring from mainframe to AWS Lambda.
Figure 10 shows the automated refactoring of the mainframe application to Lambda and Amazon EKS. Short-lived stateless transactions and programs are deployed in Lambda, while long-running or unsuitable programs run in Docker containers within Amazon EKS.
Amazon Simple Queue Service (SQS) is used for service calls within or across Lambda and Amazon EKS. Such architecture is similar to a cloud-native application architecture that’s much better positioned in the Cloud-Native Maturity Model.
With this refactoring, programs and dependencies are grouped into more separate services in Blu Age Analyzer.
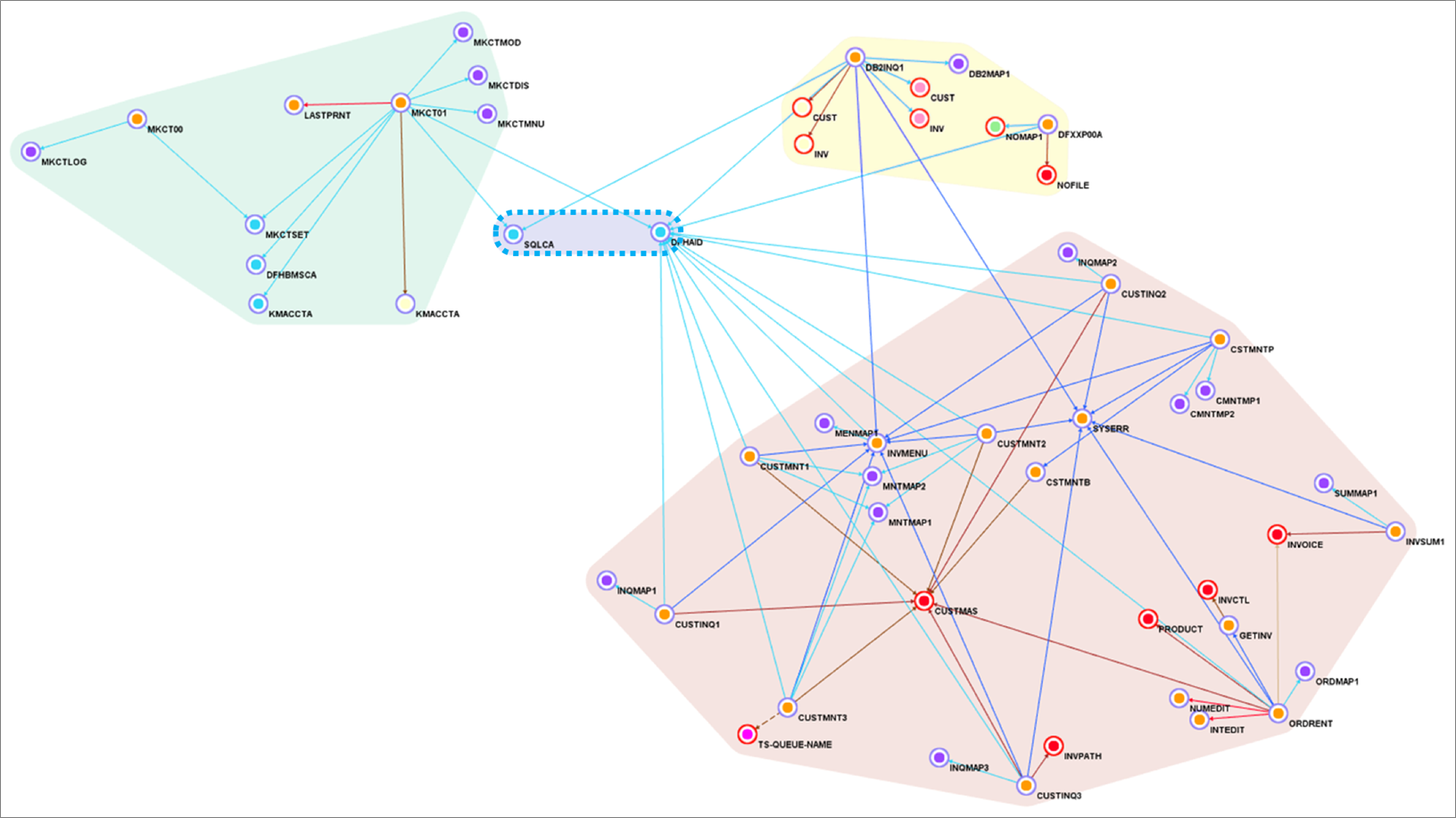
Figure 11 – Blu Age Analyzer with two AWS Lambda groupings, on container grouping and one library grouping.
In Figure 11 above, the green grouping and yellow grouping are tagged for Lambda deployment. The rose grouping stays tagged for container deployment, while the blue grouping stays a library. Same as before, the code is exported tag after tag into Git, then opened within the IDE for compilation.
The compilation and deployment for Lambda does not create a container image, but it creates compiled code ready to be deployed on Blu Age Serverless COBOL layer for Lambda.
Here’s the Serverless COBOL layer added to the deployed functions.
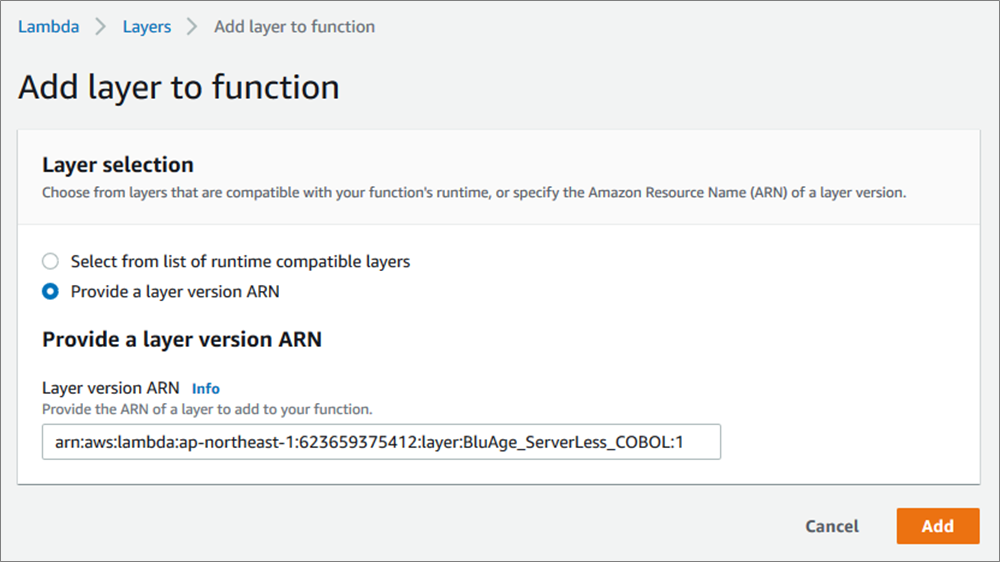
Figure 12 – Blu Age Serverless COBOL layer added to AWS Lambda function.
Now, here’s the two new Lambda functions created once the compiled code is deployed.

Figure 13 – AWS console showing the two AWS Lambda functions created.
After data conversion and thorough testing similar to the previous sections, the application is now ready for production on serverless functions and containers.
With business logic in Lambda functions, this logic can be invoked from many sources (REST APIs, messaging, object store, streams, databases) for innovations.
Incremental Transitions
Automated refactoring allows customers to accelerate modernization and minimize project risks on many dimensions.
On one side, the extensive automation for the full software stack conversion including code, data formats, dependencies provides functional equivalence preserving core business logic.
On the other side, the solution provides incremental transitions and accelerators tailored to the customer constraints and objectives:
- Incremental transition from mainframe to AWS: As shown with Blu Age Analyzer, a large application migration is piece-mealed into small work packages with coherent programs and data elements. The migration does not have to be a big bang, and it can be executed incrementally over time.
. - Incremental transition from COBOL to Java: Blu Age compilers and toolset supports maintaining the application code either in the original COBOL or Java.
.
All the deployment options described previously can be maintained similarly in COBOL or in Java and co-exist. That means you can choose to keep developing in COBOL if appropriate, and decide to start developing in Java when convenient facilitating knowledge transfer between developers.
. - Incremental transition from elastic compute, to containers, to functions: Some customers prefer starting with elastic compute, while others prefer jumping straight to containers or serverless functions. Blu Age toolset has the flexibility to switch from one target to the other following the customer specific needs.
. - Incremental transition from monolith to services and microservices: Peeling a large monolith is a long process, and the monolith can be kept and deployed on the various compute targets. When time comes, services or microservices are identified in Blu Age Analyzer, and then extracted and deployed on elastic compute, containers, or serverless functions.
From a timeline perspective, the incremental transition from mainframe to AWS is a short-term project with achievable return on investment, as shown on Figure 14.
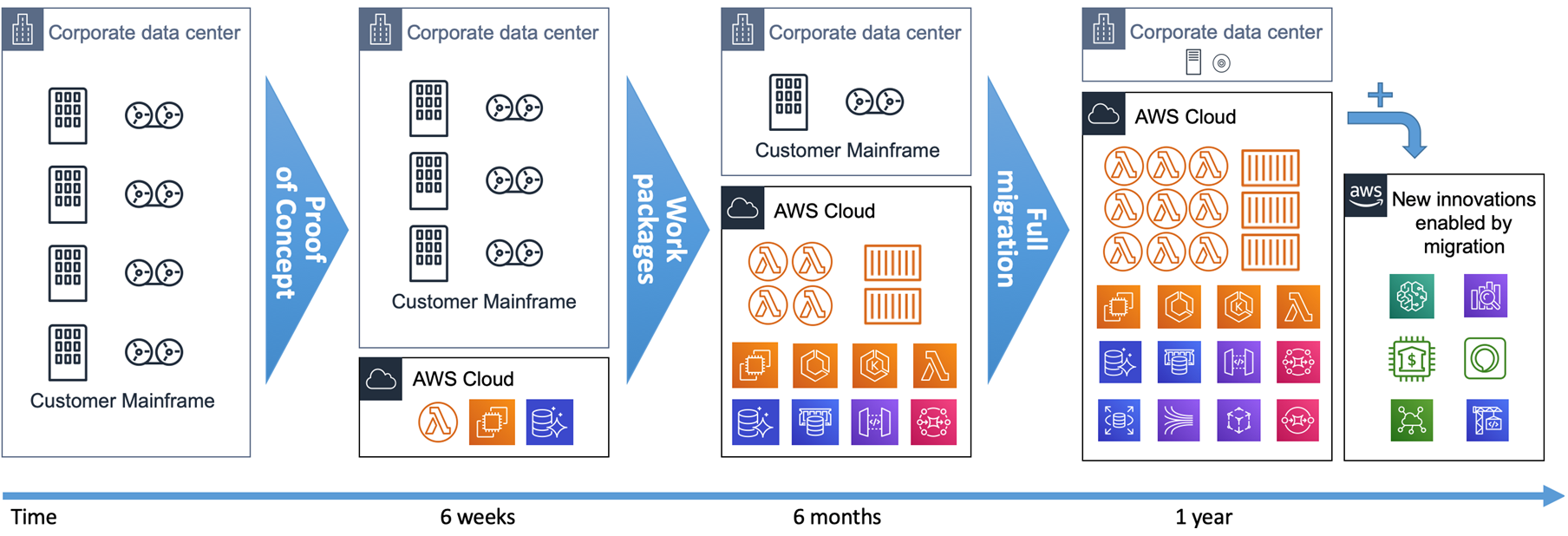
Figure 14 – Mainframe to AWS transition timeline.
We recommend starting with a hands-on Proof-of-Concept (PoC) with customers’ real code. It’s the only way to prove the technical viability and show the outcome quality within 6 weeks.
Then, you can define work packages and incrementally refactor the mainframe application to AWS targeting elastic compute, containers, or serverless functions.
The full refactoring of a mainframe workload onto AWS can be completed in a year. As soon as services are refactored and in production on AWS, new integrations and innovations become possible for analytics, mobile, voice, machine learning (ML), or Internet of Things (IoT) use cases.
Summary
Blu Age mainframe automated refactoring provides the speed and flexibility to meet the agility needs of customers. It leverages the AWS quality of service for high security, high availability, elasticity, and rich system management to meet or exceed the mainframe workloads requirements.
While accelerating modernization, Blu Age toolset allows incremental transitions adapting to customers priorities. It accelerates mainframe modernization to containers or serverless functions
Blu Age also gives the option to keep developing in COBOL or transition smoothly to Java. It facilitates the identification and extraction of microservices.
For more details, visit the Serverless COBOL page and contact Blu Age to learn more.
.

.
Blu Age – APN Partner Spotlight
Blu Age is an APN Select Technology Partner that helps organizations enter the digital era by modernizing legacy systems while substantially reducing modernization costs, shortening project duration, and mitigating the risk of failure.
Contact Blu Age | Solution Overview | AWS Marketplace
*Already worked with Blu Age? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.
理解")
BERT(Bidirectional Encoder Representations from Transformers)理解
BERT的新语言表示模型,它代表Transformer的双向编码器表示。与最近的其他语言表示模型不同,BERT旨在通过联合调节所有层中的上下文来预先训练深度双向表示。因此,预训练的BERT表示可以通过一个额外的输出层进行微调(fine-tuning),适用于广泛任务的最先进模型的构建,比如问答任务和语言推理,无需针对具体任务做大幅架构修改。
一、BERT是如何进行预训练 pre-training的?
BERT 用了两个步骤,试图去正确地训练模型的参数。
1)第一个步骤是把一篇文章中,15% 的词汇遮盖,让模型根据上下文全向地预测被遮盖的词。假如有 1 万篇文章,每篇文章平均有 100 个词汇,随机遮盖 15% 的词汇,模型的任务是正确地预测这 15 万个被遮盖的词汇。通过全向预测被遮盖住的词汇,来初步训练 Transformer 模型的参数。
2)然后,用第二个步骤继续训练模型的参数。譬如从上述 1 万篇文章中,挑选 20 万对语句,总共 40 万条语句。挑选语句对的时候,其中 2*10 万对语句,是连续的两条上下文语句,另外 2*10 万对语句,不是连续的语句。然后让 Transformer 模型来识别这 20 万对语句,哪些是连续的,哪些不连续。
这两步训练合在一起,称为预训练 pre-training,训练结束后的Transformer模型,包括它的参数,就是论文期待的通用的语言表征模型。
二、BERT的bidirectional如何体现的?
论文研究团队有理由相信,深度双向模型比left-to-right 模型或left-to-right and right-to-left模型的浅层连接更强大。从中可以看出BERT的双向叫深度双向,不同于以往的双向理解,以往的双向是从左到右和从右到左结合,这种虽然看着是双向的,但是两个方向的loss计算相互独立,所以其实还是单向的,只不过简单融合了一下,而bert的双向是要同时看上下文语境的,所有不同。
为了训练一个深度双向表示(deep bidirectional representation),研究团队采用了一种简单的方法,即随机屏蔽(masking)部分输入token,然后只预测那些被屏蔽的token,(我理解这种情况下,模型如果想预测出这个masked的词,就必须结合上下文来预测,所以就达到了双向目的,有点类似于我们小学时候做的完形填空题目,你要填写对这个词,就必须结合上下文,BERT就是这个思路训练机器的,看来利用小学生的教学方式,有助于训练机器)。论文将这个过程称为“Masked Language Model”(MLM)。
Masked双向语言模型这么做:随机选择语料中15%的单词,把它抠掉,也就是用[Mask]掩码代替原始单词,然后要求模型去正确预测被抠掉的单词。但是这里有个问题:训练过程大量看到[mask]标记,但是真正后面用的时候是不会有这个标记的,这会引导模型认为输出是针对[mask]这个标记的,但是实际使用又见不到这个标记,这自然会有问题。为了避免这个问题,Bert改造了一下,15%的被上天选中要执行[mask]替身这项光荣任务的单词中,只有80%真正被替换成[mask]标记,10%被狸猫换太子随机替换成另外一个单词,10%情况这个单词还待在原地不做改动。这就是Masked双向语音模型的具体做法。
例如在这个句子“my dog is hairy”中,它选择的token是“hairy”。然后,执行以下过程:
数据生成器将执行以下操作,而不是始终用[MASK]替换所选单词:
80%的时间:用[MASK]标记替换单词,例如,my dog is hairy → my dog is [MASK]
10%的时间:用一个随机的单词替换该单词,例如,my dog is hairy → my dog is apple
10%的时间:保持单词不变,例如,my dog is hairy → my dog is hairy. 这样做的目的是将表示偏向于实际观察到的单词。
Transformer encoder不知道它将被要求预测哪些单词或哪些单词已被随机单词替换,因此它被迫保持每个输入token的分布式上下文表示。此外,因为随机替换只发生在所有token的1.5%(即15%的10%),这似乎不会损害模型的语言理解能力。
使用MLM的第二个缺点是每个batch只预测了15%的token,这表明模型可能需要更多的预训练步骤才能收敛。团队证明MLM的收敛速度略慢于 left-to-right的模型(预测每个token),但MLM模型在实验上获得的提升远远超过增加的训练成本。
三、语句对预测
至于说“Next Sentence Prediction”,指的是做语言模型预训练的时候,分两种情况选择两个句子,一种是选择语料中真正顺序相连的两个句子;另外一种是第二个句子从语料库中抛色子,随机选择一个拼到第一个句子后面。我们要求模型除了做上述的Masked语言模型任务外,附带再做个句子关系预测,判断第二个句子是不是真的是第一个句子的后续句子。之所以这么做,是考虑到很多NLP任务是句子关系判断任务,单词预测粒度的训练到不了句子关系这个层级,增加这个任务有助于下游句子关系判断任务。所以可以看到,它的预训练是个多任务过程。这也是Bert的一个创新。其实这个下一句的预测就变成了二分类问题了,如下:
四、BERT模型的影响
BERT是一个语言表征模型(language representation model),通过超大数据、巨大模型、和极大的计算开销训练而成,在11个自然语言处理的任务中取得了最优(state-of-the-art, SOTA)结果。或许你已经猜到了此模型出自何方,没错,它产自谷歌。估计不少人会调侃这种规模的实验已经基本让一般的实验室和研究员望尘莫及了,但它确实给我们提供了很多宝贵的经验:
深度学习就是表征学习 (Deep learning is representation learning):"We show that pre-trained representations eliminate the needs of many heavily engineered task-specific architectures". 在11项BERT刷出新境界的任务中,大多只在预训练表征(pre-trained representation)微调(fine-tuning)的基础上加一个线性层作为输出(linear output layer)。在序列标注的任务里(e.g. NER),甚至连序列输出的依赖关系都先不管(i.e. non-autoregressive and no CRF),照样秒杀之前的SOTA,可见其表征学习能力之强大。
规模很重要(Scale matters):"One of our core claims is that the deep bidirectionality of BERT, which is enabled by masked LM pre-training, is the single most important improvement of BERT compared to previous work". 这种遮挡(mask)在语言模型上的应用对很多人来说已经不新鲜了,但确是BERT的作者在如此超大规模的数据+模型+算力的基础上验证了其强大的表征学习能力。这样的模型,甚至可以延伸到很多其他的模型,可能之前都被不同的实验室提出和试验过,只是由于规模的局限没能充分挖掘这些模型的潜力,而遗憾地让它们被淹没在了滚滚的paper洪流之中。
预训练价值很大(Pre-training is important):"We believe that this is the first work to demonstrate that scaling to extreme model sizes also leads to large improvements on very small-scale tasks, provided that the model has been sufficiently pre-trained". 预训练已经被广泛应用在各个领域了(e.g. ImageNet for CV, Word2Vec in NLP),多是通过大模型大数据,这样的大模型给小规模任务能带来的提升有几何,作者也给出了自己的答案。BERT模型的预训练是用Transformer做的,但我想换做LSTM或者GRU的话应该不会有太大性能上的差别,当然训练计算时的并行能力就另当别论了。
五、BERT如何解决NLP的经典问题且使之通用呢?
NLP的四大任务,绝大部分NLP问题可以归入下面的四类任务中:
1)序列标注。这是最典型的NLP任务,比如中文分词,词性标注,命名实体识别,语义角色标注等都可以归入这一类问题,它的特点是句子中每个单词要求模型根据上下文都要给出一个分类类别。
2)分类任务。比如我们常见的文本分类,情感计算等都可以归入这一类。它的特点是不管文章有多长,总体给出一个分类类别即可。
3)任务是句子关系判断。比如Entailment,QA,语义改写,自然语言推理等任务都是这个模式,它的特点是给定两个句子,模型判断出两个句子是否具备某种语义关系;
4)生成式任务。比如机器翻译,文本摘要,写诗造句,看图说话等都属于这一类。它的特点是输入文本内容后,需要自主生成另外一段文字。
对于种类如此繁多而且各具特点的下游NLP任务,Bert如何改造输入输出部分使得大部分NLP任务都可以使用Bert预训练好的模型参数呢?
对于句子关系类任务,很简单,和GPT类似,加上一个起始和终结符号,句子之间加个分隔符即可。对于输出来说,把第一个起始符号对应的Transformer最后一层位置上面串接一个softmax分类层即可。
对于分类问题,与GPT一样,只需要增加起始和终结符号,输出部分和句子关系判断任务类似改造;
对于序列标注问题,输入部分和单句分类是一样的,只需要输出部分Transformer最后一层每个单词对应位置都进行分类即可。
从这里可以看出,上面列出的NLP四大任务里面,除了生成类任务外,Bert其它都覆盖到了,而且改造起来很简单直观。尽管Bert论文没有提,但是稍微动动脑子就可以想到,其实对于机器翻译或者文本摘要,聊天机器人这种生成式任务,同样可以稍作改造即可引入Bert的预训练成果。只需要附着在S2S结构上,encoder部分是个深度Transformer结构,decoder部分也是个深度Transformer结构。根据任务选择不同的预训练数据初始化encoder和decoder即可。这是相当直观的一种改造方法。当然,也可以更简单一点,比如直接在单个Transformer结构上加装隐层产生输出也是可以的。不论如何,从这里可以看出,NLP四大类任务都可以比较方便地改造成Bert能够接受的方式。这其实是Bert的非常大的优点,这意味着它几乎可以做任何NLP的下游任务,具备普适性,这是很强的。
六、预训练的本质。
我们应该弄清楚预训练这个过程本质上是在做什么事情,本质上预训练是通过设计好一个网络结构来做语言模型任务,然后把大量甚至是无穷尽的无标注的自然语言文本利用起来,预训练任务把大量语言学知识抽取出来编码到网络结构中,当手头任务带有标注信息的数据有限时,这些先验的语言学特征当然会对手头任务有极大的特征补充作用,因为当数据有限的时候,很多语言学现象是覆盖不到的,泛化能力就弱,集成尽量通用的语言学知识自然会加强模型的泛化能力。如何引入先验的语言学知识其实一直是NLP尤其是深度学习场景下的NLP的主要目标之一,不过一直没有太好的解决办法,而ELMO/GPT/Bert的这种两阶段模式看起来无疑是解决这个问题自然又简洁的方法,这也是这些方法的主要价值所在。
![Cannot open connection] with root cause com.microsoft.sqlserver.jdbc.SQLServerException: Connection reset](http://www.gvkun.com/zb_users/upload/2025/03/c9e32be7-6849-42e8-a4dd-01ef52bec8081741166351182.jpg "Cannot open connection] with root cause com.microsoft.sqlserver.jdbc.SQLServerException: Connection reset")
Cannot open connection] with root cause com.microsoft.sqlserver.jdbc.SQLServerException: Connection reset
<hibernate-configuration>
<session-factory>
<property name="dialect">
org.hibernate.dialect.SQLServerDialect
</property>
<property name="connection.url">
jdbc:sqlserver://localhost:1433;databaseName=test
</property>
<!-- C3P0连接池设定 -->
<property name="hibernate.connection.provider_class">
org.hibernate.connection.C3P0ConnectionProvider
</property>
<property name="hibernate.c3p0.max_size">100</property>
<property name="hibernate.c3p0.min_size">10</property>
<property name="hibernate.c3p0.timeout">120</property>
<property name="hibernate.c3p0.max_statements">100</property>
<property name="hibernate.c3p0.idle_test_period">120</property>
<property name="hibernate.c3p0.acquire_increment">2</property>
<!-- 每次都验证连接 是否可用 -->
<property name="hibernate.c3p0.validate">true</property>
<!--最大空闲时间 ,60秒内未使用则连接被丢弃。若为0则永不丢弃。Default: 0 -->
<property name="hibernate.c3p0.maxIdleTime">0</property>
<!--c3p0是异步操作的,缓慢的JDBC操作通过帮助进程 完成。扩展这些操作可以有效的提升性能通过多线程实现多个操作同时被执行。Default: 3-->
<property name="hibernate.c3p0.numHelperThreads">10</property>
<!--每60秒 检查所有连接池中的空闲连接 。Default: 0 -->
<property name="hibernate.c3p0.idleConnectionTestPeriod">
60
</property>
<!--如果设为true那么在取得连接的同时将校验连接的有效性 。Default: false -->
<property name="hibernate.c3p0.testConnectionOnCheckin">
true
</property>
<!--因性能消耗大请只在需要的时候使用它。如果设为true那么在每个connection提交的时候 都将校验其有效性 。建议使用idleConnectionTestPeriod或automaticTestTable等方法来提升连接测试的性能。Default: false -->
<property name="hibernate.c3p0.testConnectionOnCheckout">
false
</property>
<!-- C3P0连接池设定 -->
<property name="connection.username">sa</property>
<property name="connection.password">sa</property>
<property name="connection.driver_class">
com.microsoft.sqlserver.jdbc.SQLServerDriver
</property>
<property name="connection.autocommit">true</property>
<property name="show_sql">true</property>
</ssion-factory>
</hibernate-configuration>
我们今天的关于NO_RESPONSE_FROM_FUNCTION NextJS 部署与 getServerSideProps和node.js response的分享已经告一段落,感谢您的关注,如果您想了解更多关于appium 报错:selenium.common.exceptions.WebDriverException: Message: An unknown server-side error occu、Automated Refactoring from Mainframe to Serverless Functions and Containers with Blu Age、BERT(Bidirectional Encoder Representations from Transformers)理解、Cannot open connection] with root cause com.microsoft.sqlserver.jdbc.SQLServerException: Connection reset的相关信息,请在本站查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

