如果您想了解Pythonnumpy模块-get_printoptions()实例源码的相关知识,那么本文是一篇不可错过的文章,我们将对python的numpy模块进行全面详尽的解释,并且为您提供关于J
如果您想了解Python numpy 模块-get_printoptions() 实例源码的相关知识,那么本文是一篇不可错过的文章,我们将对python的numpy模块进行全面详尽的解释,并且为您提供关于Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: 'numpy.ndarray' object is not callable、numpy.random.random & numpy.ndarray.astype & numpy.arange、numpy.ravel()/numpy.flatten()/numpy.squeeze()、Numpy:数组创建 numpy.arrray() , numpy.arange()、np.linspace ()、数组基本属性的有价值的信息。
本文目录一览:- Python numpy 模块-get_printoptions() 实例源码(python的numpy模块)
- Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: 'numpy.ndarray' object is not callable
- numpy.random.random & numpy.ndarray.astype & numpy.arange
- numpy.ravel()/numpy.flatten()/numpy.squeeze()
- Numpy:数组创建 numpy.arrray() , numpy.arange()、np.linspace ()、数组基本属性
 实例源码(python的numpy模块)")
Python numpy 模块-get_printoptions() 实例源码(python的numpy模块)
Python numpy 模块,get_printoptions() 实例源码
我们从Python开源项目中,提取了以下50个代码示例,用于说明如何使用numpy.get_printoptions()。
- def compute_mean(self, file_list):
- logger = logging.getLogger("acoustic_norm")
- mean_vector = numpy.zeros((1, self.feature_dimension))
- all_frame_number = 0
- io_funcs = BinaryIOCollection()
- for file_name in file_list:
- features = io_funcs.load_binary_file(file_name, self.feature_dimension)
- current_frame_number = features.size // self.feature_dimension
- mean_vector += numpy.reshape(numpy.sum(features, axis=0), (1, self.feature_dimension))
- all_frame_number += current_frame_number
- mean_vector /= float(all_frame_number)
- # po=numpy.get_printoptions()
- # numpy.set_printoptions(precision=2,threshold=20,linewidth=1000,edgeitems=4)
- logger.info(''computed mean vector of length %d :'' % mean_vector.shape[1] )
- logger.info('' mean: %s'' % mean_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- return mean_vector
- def compute_mean(self, file_list, start_index, end_index):
- local_feature_dimension = end_index - start_index
- mean_vector = numpy.zeros((1, local_feature_dimension))
- all_frame_number = 0
- io_funcs = BinaryIOCollection()
- for file_name in file_list:
- features, current_frame_number = io_funcs.load_binary_file_frame(file_name, self.feature_dimension)
- mean_vector += numpy.reshape(numpy.sum(features[:, start_index:end_index], local_feature_dimension))
- all_frame_number += current_frame_number
- mean_vector /= float(all_frame_number)
- # po=numpy.get_printoptions()
- # numpy.set_printoptions(precision=2,edgeitems=4)
- self.logger.info(''computed mean vector of length %d :'' % mean_vector.shape[1] )
- self.logger.info('' mean: %s'' % mean_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- return mean_vector
- def compute_mean(self, self.feature_dimension)
- current_frame_number = features.size / self.feature_dimension
- mean_vector += numpy.reshape(numpy.sum(features,edgeitems=4)
- logger.info(''computed mean vector of length %d :'' % mean_vector.shape[1] )
- logger.info('' mean: %s'' % mean_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- return mean_vector
- def compute_mean(self,edgeitems=4)
- self.logger.info(''computed mean vector of length %d :'' % mean_vector.shape[1] )
- self.logger.info('' mean: %s'' % mean_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- return mean_vector
- def pformat(obj, indent=0, depth=3):
- if ''numpy'' in sys.modules:
- import numpy as np
- print_options = np.get_printoptions()
- np.set_printoptions(precision=6, threshold=64, edgeitems=1)
- else:
- print_options = None
- out = pprint.pformat(obj, depth=depth, indent=indent)
- if print_options:
- np.set_printoptions(**print_options)
- return out
- ###############################################################################
- # class `Logger`
- ###############################################################################
- def compute_mean(self,edgeitems=4)
- logger.info(''computed mean vector of length %d :'' % mean_vector.shape[1] )
- logger.info('' mean: %s'' % mean_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- return mean_vector
- def compute_mean(self,edgeitems=4)
- self.logger.info(''computed mean vector of length %d :'' % mean_vector.shape[1] )
- self.logger.info('' mean: %s'' % mean_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- return mean_vector
- def pformat(obj, indent=indent)
- if print_options:
- np.set_printoptions(**print_options)
- return out
- ###############################################################################
- # class `Logger`
- ###############################################################################
- def after_run(self, run_context, run_values):
- global_episode = run_values.results[''global_episode'']
- if can_run_hook(run_context):
- if self._timer.should_trigger_for_episode(global_episode):
- original = np.get_printoptions()
- np.set_printoptions(suppress=True)
- elapsed_secs, _ = self._timer.update_last_triggered_episode(global_episode)
- if self._formatter:
- logging.info(self._formatter(run_values.results))
- else:
- stats = []
- for tag in self._tag_order:
- stats.append("%s = %s" % (tag, run_values.results[tag]))
- if elapsed_secs is not None:
- logging.info("%s (%.3f sec)", ",".join(stats), elapsed_secs)
- else:
- logging.info("%s",".join(stats))
- np.set_printoptions(**original)
- def pformat(obj, indent=indent)
- if print_options:
- np.set_printoptions(**print_options)
- return out
- ###############################################################################
- # class `Logger`
- ###############################################################################
- def np_printoptions(**kwargs):
- """Context manager to temporarily set numpy print options."""
- old = np.get_printoptions()
- np.set_printoptions(**kwargs)
- yield
- np.set_printoptions(**old)
- def setUp(self):
- self.oldopts = np.get_printoptions()
- def printoptions(*args, **kwargs):
- original = np.get_printoptions()
- np.set_printoptions(*args, **kwargs)
- try:
- yield
- finally:
- np.set_printoptions(**original)
- def compute_mean(self, end_index):
- logger = logging.getLogger(''feature_normalisation'')
- local_feature_dimension = end_index - start_index
- mean_vector = numpy.zeros((1, local_feature_dimension))
- all_frame_number = 0
- io_funcs = HTKFeat_read()
- for file_name in file_list:
- features, current_frame_number = io_funcs.getall(file_name)
- # io_funcs = HTK_Parm_IO()
- # io_funcs.read_htk(file_name)
- # features = io_funcs.data
- # current_frame_number = io_funcs.n_samples
- mean_vector += numpy.reshape(numpy.sum(features[:, local_feature_dimension))
- all_frame_number += current_frame_number
- mean_vector /= float(all_frame_number)
- # setting the print options in this way seems to break subsequent printing of numpy float32 types
- # no idea what is going on - removed until this can be solved
- # po=numpy.get_printoptions()
- # numpy.set_printoptions(precision=2,edgeitems=4)
- logger.info(''computed mean vector of length %d :'' % mean_vector.shape[1] )
- logger.info('' mean: %s'' % mean_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- self.mean_vector = mean_vector
- return mean_vector
- def compute_std(self, mean_vector, end_index):
- logger = logging.getLogger(''feature_normalisation'')
- local_feature_dimension = end_index - start_index
- std_vector = numpy.zeros((1, self.feature_dimension))
- all_frame_number = 0
- io_funcs = HTKFeat_read()
- for file_name in file_list:
- features, current_frame_number = io_funcs.getall(file_name)
- mean_matrix = numpy.tile(mean_vector, (current_frame_number, 1))
- std_vector += numpy.reshape(numpy.sum((features[:, start_index:end_index] - mean_matrix) ** 2, local_feature_dimension))
- all_frame_number += current_frame_number
- std_vector /= float(all_frame_number)
- std_vector = std_vector ** 0.5
- # setting the print options in this way seems to break subsequent printing of numpy float32 types
- # no idea what is going on - removed until this can be solved
- # po=numpy.get_printoptions()
- # numpy.set_printoptions(precision=2,edgeitems=4)
- logger.info(''computed std vector of length %d'' % std_vector.shape[1] )
- logger.info('' std: %s'' % std_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- self.std_vector = std_vector
- return std_vector
- def printoptions(*args, **kwargs):
- original = numpy.get_printoptions()
- numpy.set_printoptions(*args, **kwargs)
- yield
- numpy.set_printoptions(**original)
- def find_min_max_values(self, in_file_list):
- logger = logging.getLogger("acoustic_norm")
- file_number = len(in_file_list)
- min_value_matrix = numpy.zeros((file_number, self.feature_dimension))
- max_value_matrix = numpy.zeros((file_number, self.feature_dimension))
- io_funcs = BinaryIOCollection()
- for i in range(file_number):
- features = io_funcs.load_binary_file(in_file_list[i], self.feature_dimension)
- temp_min = numpy.amin(features, axis = 0)
- temp_max = numpy.amax(features, axis = 0)
- min_value_matrix[i, ] = temp_min;
- max_value_matrix[i, ] = temp_max;
- self.min_vector = numpy.amin(min_value_matrix, axis = 0)
- self.max_vector = numpy.amax(max_value_matrix, axis = 0)
- self.min_vector = numpy.reshape(self.min_vector, self.feature_dimension))
- self.max_vector = numpy.reshape(self.max_vector, self.feature_dimension))
- # po=numpy.get_printoptions()
- # numpy.set_printoptions(precision=2,edgeitems=4)
- logger.info(''across %d files found min/max values of length %d:'' % (file_number,self.feature_dimension) )
- logger.info('' min: %s'' % self.min_vector)
- logger.info('' max: %s'' % self.max_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- def find_min_max_values(self, in_file_list, end_index):
- local_feature_dimension = end_index - start_index
- file_number = len(in_file_list)
- min_value_matrix = numpy.zeros((file_number, local_feature_dimension))
- max_value_matrix = numpy.zeros((file_number, local_feature_dimension))
- io_funcs = BinaryIOCollection()
- for i in range(file_number):
- features = io_funcs.load_binary_file(in_file_list[i], self.feature_dimension)
- temp_min = numpy.amin(features[:, axis = 0)
- temp_max = numpy.amax(features[:, local_feature_dimension))
- self.max_vector = numpy.reshape(self.max_vector, local_feature_dimension))
- # po=numpy.get_printoptions()
- # numpy.set_printoptions(precision=2,edgeitems=4)
- self.logger.info(''found min/max values of length %d:'' % local_feature_dimension)
- self.logger.info('' min: %s'' % self.min_vector)
- self.logger.info('' max: %s'' % self.max_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- def compute_std(self, end_index):
- local_feature_dimension = end_index - start_index
- std_vector = numpy.zeros((1, self.feature_dimension))
- all_frame_number = 0
- io_funcs = BinaryIOCollection()
- for file_name in file_list:
- features, self.feature_dimension)
- mean_matrix = numpy.tile(mean_vector, local_feature_dimension))
- all_frame_number += current_frame_number
- std_vector /= float(all_frame_number)
- std_vector = std_vector ** 0.5
- # po=numpy.get_printoptions()
- # numpy.set_printoptions(precision=2,edgeitems=4)
- self.logger.info(''computed std vector of length %d'' % std_vector.shape[1] )
- self.logger.info('' std: %s'' % std_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- return std_vector
- def compute_mean(self,edgeitems=4)
- logger.info(''computed mean vector of length %d :'' % mean_vector.shape[1] )
- logger.info('' mean: %s'' % mean_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- self.mean_vector = mean_vector
- return mean_vector
- def compute_std(self,edgeitems=4)
- logger.info(''computed std vector of length %d'' % std_vector.shape[1] )
- logger.info('' std: %s'' % std_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- self.std_vector = std_vector
- return std_vector
- def test_precision():
- """test varIoUs values for float_precision."""
- f = Plaintextformatter()
- nt.assert_equal(f(pi), repr(pi))
- f.float_precision = 0
- if numpy:
- po = numpy.get_printoptions()
- nt.assert_equal(po[''precision''], 0)
- nt.assert_equal(f(pi), ''3'')
- f.float_precision = 2
- if numpy:
- po = numpy.get_printoptions()
- nt.assert_equal(po[''precision''], 2)
- nt.assert_equal(f(pi), ''3.14'')
- f.float_precision = ''%g''
- if numpy:
- po = numpy.get_printoptions()
- nt.assert_equal(po[''precision''], ''3.14159'')
- f.float_precision = ''%e''
- nt.assert_equal(f(pi), ''3.141593e+00'')
- f.float_precision = ''''
- if numpy:
- po = numpy.get_printoptions()
- nt.assert_equal(po[''precision''], 8)
- nt.assert_equal(f(pi), repr(pi))
- def __repr__(self):
- """
- FloatArrayParameter needs to "truncate" the array by temporarily
- overriding np.set_printoptions
- """
- opt = np.get_printoptions()
- # <Parameter:_qualifier= takes 13+len(qualifier) characters
- np.set_printoptions(threshold=8, edgeitems=3, linewidth=opt[''linewidth'']-(13+len(self.qualifier)))
- repr_ = super(FloatArrayParameter, self).__repr__()
- np.set_printoptions(**opt)
- return repr_
- def __str__(self):
- """
- FloatArrayParameter needs to "truncate" the array by temporarily
- overriding np.set_printoptions
- """
- opt = np.get_printoptions()
- # Value:_ takes 7 characters
- np.set_printoptions(threshold=8, linewidth=opt[''linewidth'']-7)
- str_ = super(FloatArrayParameter, self).__str__()
- np.set_printoptions(**opt)
- return str_
- def to_string_short(self):
- """
- see also :meth:`to_string`
- :return: a shorter abreviated string reprentation of the parameter
- """
- opt = np.get_printoptions()
- np.set_printoptions(threshold=8, linewidth=opt[''linewidth'']-len(self.uniquetwig)-2)
- str_ = super(FloatArrayParameter, self).to_string_short()
- np.set_printoptions(**opt)
- return str_
- def __repr__(self):
- """
- IntArrayParameter needs to "truncate" the array by temporarily
- overriding np.set_printoptions
- """
- opt = np.get_printoptions()
- # <Parameter:_qualifier= takes 13+len(qualifier) characters
- np.set_printoptions(threshold=8, linewidth=opt[''linewidth'']-(13+len(self.qualifier)))
- repr_ = super(IntArrayParameter, self).__repr__()
- np.set_printoptions(**opt)
- return repr_
- def __str__(self):
- """
- IntArrayParameter needs to "truncate" the array by temporarily
- overriding np.set_printoptions
- """
- opt = np.get_printoptions()
- # Value:_ takes 7 characters
- np.set_printoptions(threshold=8, linewidth=opt[''linewidth'']-7)
- str_ = super(IntArrayParameter, self).__str__()
- np.set_printoptions(**opt)
- return str_
- def setUp(self):
- self.oldopts = np.get_printoptions()
- def printoptions(*args, **kwargs)
- yield
- numpy.set_printoptions(**original)
- def find_min_max_values(self, self.feature_dimension))
- io_funcs = BinaryIOCollection()
- for i in xrange(file_number):
- features = io_funcs.load_binary_file(in_file_list[i],self.feature_dimension) )
- logger.info('' min: %s'' % self.min_vector)
- logger.info('' max: %s'' % self.max_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- def compute_std(self, mean_vector):
- logger = logging.getLogger("acoustic_norm")
- std_vector = numpy.zeros((1, self.feature_dimension)
- current_frame_number = features.size / self.feature_dimension
- mean_matrix = numpy.tile(mean_vector, 1))
- std_vector += numpy.reshape(numpy.sum((features - mean_matrix) ** 2, self.feature_dimension))
- all_frame_number += current_frame_number
- std_vector /= float(all_frame_number)
- std_vector = std_vector ** 0.5
- # po=numpy.get_printoptions()
- # numpy.set_printoptions(precision=2,edgeitems=4)
- logger.info(''computed std vector of length %d'' % std_vector.shape[1] )
- logger.info('' std: %s'' % std_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- return std_vector
- def find_min_max_values(self, local_feature_dimension))
- io_funcs = BinaryIOCollection()
- for i in xrange(file_number):
- features = io_funcs.load_binary_file(in_file_list[i],edgeitems=4)
- self.logger.info(''found min/max values of length %d:'' % local_feature_dimension)
- self.logger.info('' min: %s'' % self.min_vector)
- self.logger.info('' max: %s'' % self.max_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- def compute_std(self,edgeitems=4)
- self.logger.info(''computed std vector of length %d'' % std_vector.shape[1] )
- self.logger.info('' std: %s'' % std_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- return std_vector
- def compute_mean(self,edgeitems=4)
- logger.info(''computed mean vector of length %d :'' % mean_vector.shape[1] )
- logger.info('' mean: %s'' % mean_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- self.mean_vector = mean_vector
- return mean_vector
- def compute_std(self,edgeitems=4)
- logger.info(''computed std vector of length %d'' % std_vector.shape[1] )
- logger.info('' std: %s'' % std_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- self.std_vector = std_vector
- return std_vector
- def find_min_max_values(self,edgeitems=4)
- self.logger.info(''found min/max values of length %d:'' % local_feature_dimension)
- self.logger.info('' min: %s'' % self.min_vector)
- self.logger.info('' max: %s'' % self.max_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- def compute_mean(self,edgeitems=4)
- logger.info(''computed mean vector of length %d :'' % mean_vector.shape[1] )
- logger.info('' mean: %s'' % mean_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- self.mean_vector = mean_vector
- return mean_vector
- def compute_std(self,edgeitems=4)
- logger.info(''computed std vector of length %d'' % std_vector.shape[1] )
- logger.info('' std: %s'' % std_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- self.std_vector = std_vector
- return std_vector
- def setUp(self):
- self.oldopts = np.get_printoptions()
- def compute_mean(self,edgeitems=4)
- logger.info(''computed mean vector of length %d :'' % mean_vector.shape[1] )
- logger.info('' mean: %s'' % mean_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- self.mean_vector = mean_vector
- return mean_vector
- def compute_std(self,edgeitems=4)
- logger.info(''computed std vector of length %d'' % std_vector.shape[1] )
- logger.info('' std: %s'' % std_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- self.std_vector = std_vector
- return std_vector
- def printoptions(*args, **kwargs)
- yield
- numpy.set_printoptions(**original)
- def find_min_max_values(self,self.feature_dimension) )
- logger.info('' min: %s'' % self.min_vector)
- logger.info('' max: %s'' % self.max_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- def find_min_max_values(self,edgeitems=4)
- self.logger.info(''found min/max values of length %d:'' % local_feature_dimension)
- self.logger.info('' min: %s'' % self.min_vector)
- self.logger.info('' max: %s'' % self.max_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- def compute_std(self,edgeitems=4)
- self.logger.info(''computed std vector of length %d'' % std_vector.shape[1] )
- self.logger.info('' std: %s'' % std_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- return std_vector
- def compute_mean(self,edgeitems=4)
- logger.info(''computed mean vector of length %d :'' % mean_vector.shape[1] )
- logger.info('' mean: %s'' % mean_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- self.mean_vector = mean_vector
- return mean_vector
- def compute_std(self,edgeitems=4)
- logger.info(''computed std vector of length %d'' % std_vector.shape[1] )
- logger.info('' std: %s'' % std_vector)
- # restore the print options
- # numpy.set_printoptions(po)
- self.std_vector = std_vector
- return std_vector
- def _printoptions(*args, **kwargs)
- yield
- np.set_printoptions(**original)
- # http://code.activestate.com/recipes/577586-converts-from-decimal-to-any-base-between-2-and-26/
- def setUp(self):
- self.oldopts = np.get_printoptions()
- def parse_numpy_printoption(kv_str):
- """Sets a single numpy printoption from a string of the form ''x=y''.
- See documentation on numpy.set_printoptions() for details about what values
- x and y can take. x can be any option listed there other than ''formatter''.
- Args:
- kv_str: A string of the form ''x=y'',such as ''threshold=100000''
- Raises:
- argparse.ArgumentTypeError: If the string Couldn''t be used to set any
- nump printoption.
- """
- k_v_str = kv_str.split("=", 1)
- if len(k_v_str) != 2 or not k_v_str[0]:
- raise argparse.ArgumentTypeError("''%s'' is not in the form k=v." % kv_str)
- k, v_str = k_v_str
- printoptions = np.get_printoptions()
- if k not in printoptions:
- raise argparse.ArgumentTypeError("''%s'' is not a valid printoption." % k)
- v_type = type(printoptions[k])
- if v_type is type(None):
- raise argparse.ArgumentTypeError(
- "Setting ''%s'' from the command line is not supported." % k)
- try:
- v = (v_type(v_str) if v_type is not bool
- else flags.BooleanParser().Parse(v_str))
- except ValueError as e:
- raise argparse.ArgumentTypeError(e.message)
- np.set_printoptions(**{k: v})
:TypeError: 'numpy.ndarray' object is not callable")
Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: 'numpy.ndarray' object is not callable
如何解决Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: ''numpy.ndarray'' object is not callable?
晚安, 尝试打印以下内容时,我在 jupyter 中遇到了 numpy 问题,并且得到了一个 错误: 需要注意的是python版本是3.8.8。 我先用 spyder 测试它,它运行正确,它给了我预期的结果
使用 Spyder:
import numpy as np
for i in range (5):
n = np.random.rand ()
print (n)
Results
0.6604903457995978
0.8236300859753154
0.16067650689842816
0.6967868357083673
0.4231597934445466
现在有了 jupyter
import numpy as np
for i in range (5):
n = np.random.rand ()
print (n)
-------------------------------------------------- ------
TypeError Traceback (most recent call last)
<ipython-input-78-0c6a801b3ea9> in <module>
2 for i in range (5):
3 n = np.random.rand ()
----> 4 print (n)
TypeError: ''numpy.ndarray'' object is not callable
感谢您对我如何在 Jupyter 中解决此问题的帮助。
非常感谢您抽出宝贵时间。
阿特,约翰”
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

numpy.random.random & numpy.ndarray.astype & numpy.arange
今天看到这样一句代码:
xb = np.random.random((nb, d)).astype(''float32'') #创建一个二维随机数矩阵(nb行d列)
xb[:, 0] += np.arange(nb) / 1000. #将矩阵第一列的每个数加上一个值要理解这两句代码需要理解三个函数
1、生成随机数
numpy.random.random(size=None)
size为None时,返回float。
size不为None时,返回numpy.ndarray。例如numpy.random.random((1,2)),返回1行2列的numpy数组
2、对numpy数组中每一个元素进行类型转换
numpy.ndarray.astype(dtype)
返回numpy.ndarray。例如 numpy.array([1, 2, 2.5]).astype(int),返回numpy数组 [1, 2, 2]
3、获取等差数列
numpy.arange([start,]stop,[step,]dtype=None)
功能类似python中自带的range()和numpy中的numpy.linspace
返回numpy数组。例如numpy.arange(3),返回numpy数组[0, 1, 2]
/numpy.flatten()/numpy.squeeze()")
numpy.ravel()/numpy.flatten()/numpy.squeeze()
numpy.ravel(a, order=''C'')
Return a flattened array
numpy.chararray.flatten(order=''C'')
Return a copy of the array collapsed into one dimension
numpy.squeeze(a, axis=None)
Remove single-dimensional entries from the shape of an array.
相同点: 将多维数组 降为 一维数组
不同点:
ravel() 返回的是视图(view),意味着改变元素的值会影响原始数组元素的值;
flatten() 返回的是拷贝,意味着改变元素的值不会影响原始数组;
squeeze()返回的是视图(view),仅仅是将shape中dimension为1的维度去掉;
ravel()示例:
1 import matplotlib.pyplot as plt
2 import numpy as np
3
4 def log_type(name,arr):
5 print("数组{}的大小:{}".format(name,arr.size))
6 print("数组{}的维度:{}".format(name,arr.shape))
7 print("数组{}的维度:{}".format(name,arr.ndim))
8 print("数组{}元素的数据类型:{}".format(name,arr.dtype))
9 #print("数组:{}".format(arr.data))
10
11 a = np.floor(10*np.random.random((3,4)))
12 print(a)
13 log_type(''a'',a)
14
15 a1 = a.ravel()
16 print("a1:{}".format(a1))
17 log_type(''a1'',a1)
18 a1[2] = 100
19
20 print(a)
21 log_type(''a'',a)
flatten()示例
1 import matplotlib.pyplot as plt
2 import numpy as np
3
4 def log_type(name,arr):
5 print("数组{}的大小:{}".format(name,arr.size))
6 print("数组{}的维度:{}".format(name,arr.shape))
7 print("数组{}的维度:{}".format(name,arr.ndim))
8 print("数组{}元素的数据类型:{}".format(name,arr.dtype))
9 #print("数组:{}".format(arr.data))
10
11 a = np.floor(10*np.random.random((3,4)))
12 print(a)
13 log_type(''a'',a)
14
15 a1 = a.flatten()
16 print("修改前a1:{}".format(a1))
17 log_type(''a1'',a1)
18 a1[2] = 100
19 print("修改后a1:{}".format(a1))
20
21 print("a:{}".format(a))
22 log_type(''a'',a)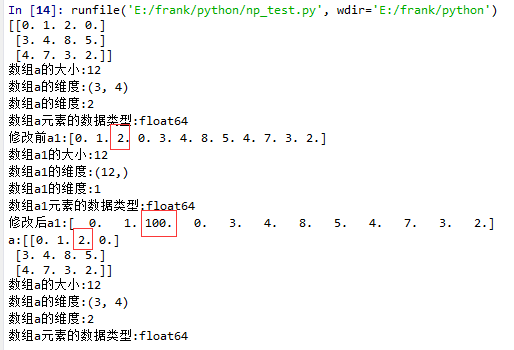
squeeze()示例:
1. 没有single-dimensional entries的情况
1 import matplotlib.pyplot as plt
2 import numpy as np
3
4 def log_type(name,arr):
5 print("数组{}的大小:{}".format(name,arr.size))
6 print("数组{}的维度:{}".format(name,arr.shape))
7 print("数组{}的维度:{}".format(name,arr.ndim))
8 print("数组{}元素的数据类型:{}".format(name,arr.dtype))
9 #print("数组:{}".format(arr.data))
10
11 a = np.floor(10*np.random.random((3,4)))
12 print(a)
13 log_type(''a'',a)
14
15 a1 = a.squeeze()
16 print("修改前a1:{}".format(a1))
17 log_type(''a1'',a1)
18 a1[2] = 100
19 print("修改后a1:{}".format(a1))
20
21 print("a:{}".format(a))
22 log_type(''a'',a)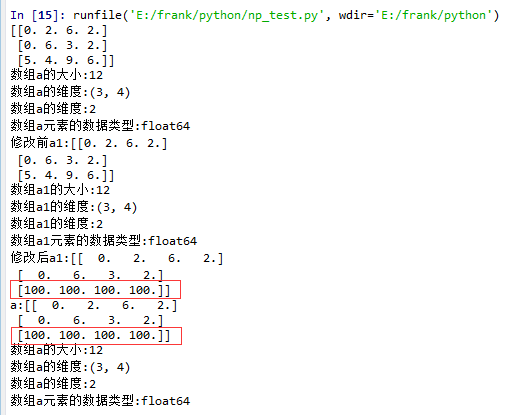
从结果中可以看到,当没有single-dimensional entries时,squeeze()返回额数组对象是一个view,而不是copy。
2. 有single-dimentional entries 的情况
1 import matplotlib.pyplot as plt
2 import numpy as np
3
4 def log_type(name,arr):
5 print("数组{}的大小:{}".format(name,arr.size))
6 print("数组{}的维度:{}".format(name,arr.shape))
7 print("数组{}的维度:{}".format(name,arr.ndim))
8 print("数组{}元素的数据类型:{}".format(name,arr.dtype))
9 #print("数组:{}".format(arr.data))
10
11 a = np.floor(10*np.random.random((1,3,4)))
12 print(a)
13 log_type(''a'',a)
14
15 a1 = a.squeeze()
16 print("修改前a1:{}".format(a1))
17 log_type(''a1'',a1)
18 a1[2] = 100
19 print("修改后a1:{}".format(a1))
20
21 print("a:{}".format(a))
22 log_type(''a'',a)
 , numpy.arange()、np.linspace ()、数组基本属性")
Numpy:数组创建 numpy.arrray() , numpy.arange()、np.linspace ()、数组基本属性
一、Numpy数组创建
part 1:np.linspace(起始值,终止值,元素总个数
import numpy as np
''''''
numpy中的ndarray数组
''''''
ary = np.array([1, 2, 3, 4, 5])
print(ary)
ary = ary * 10
print(ary)
''''''
ndarray对象的创建
''''''
# 创建二维数组
# np.array([[],[],...])
a = np.array([[1, 2, 3, 4], [5, 6, 7, 8]])
print(a)
# np.arange(起始值, 结束值, 步长(默认1))
b = np.arange(1, 10, 1)
print(b)
print("-------------np.zeros(数组元素个数, dtype=''数组元素类型'')-----")
# 创建一维数组:
c = np.zeros(10)
print(c, ''; c.dtype:'', c.dtype)
# 创建二维数组:
print(np.zeros ((3,4)))
print("----------np.ones(数组元素个数, dtype=''数组元素类型'')--------")
# 创建一维数组:
d = np.ones(10, dtype=''int64'')
print(d, ''; d.dtype:'', d.dtype)
# 创建三维数组:
print(np.ones( (2,3,4), dtype=np.int32 ))
# 打印维度
print(np.ones( (2,3,4), dtype=np.int32 ).ndim) # 返回:3(维)
结果图:

part 2 :np.linspace ( 起始值,终止值,元素总个数)
import numpy as np
a = np.arange( 10, 30, 5 )
b = np.arange( 0, 2, 0.3 )
c = np.arange(12).reshape(4,3)
d = np.random.random((2,3)) # 取-1到1之间的随机数,要求设置为诶2行3列的结构
print(a)
print(b)
print(c)
print(d)
print("-----------------")
from numpy import pi
print(np.linspace( 0, 2*pi, 100 ))
print("-------------np.linspace(起始值,终止值,元素总个数)------------------")
print(np.sin(np.linspace( 0, 2*pi, 100 )))
结果图:

二、Numpy的ndarray对象属性:
数组的结构:array.shape
数组的维度:array.ndim
元素的类型:array.dtype
数组元素的个数:array.size
数组的索引(下标):array[0]
''''''
数组的基本属性
''''''
import numpy as np
print("--------------------案例1:------------------------------")
a = np.arange(15).reshape(3, 5)
print(a)
print(a.shape) # 打印数组结构
print(len(a)) # 打印有多少行
print(a.ndim) # 打印维度
print(a.dtype) # 打印a数组内的元素的数据类型
# print(a.dtype.name)
print(a.size) # 打印数组的总元素个数
print("-------------------案例2:---------------------------")
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a)
# 测试数组的基本属性
print(''a.shape:'', a.shape)
print(''a.size:'', a.size)
print(''len(a):'', len(a))
# a.shape = (6, ) # 此格式可将原数组结构变成1行6列的数据结构
# print(a, ''a.shape:'', a.shape)
# 数组元素的索引
ary = np.arange(1, 28)
ary.shape = (3, 3, 3) # 创建三维数组
print("ary.shape:",ary.shape,"\n",ary )
print("-----------------")
print(''ary[0]:'', ary[0])
print(''ary[0][0]:'', ary[0][0])
print(''ary[0][0][0]:'', ary[0][0][0])
print(''ary[0,0,0]:'', ary[0, 0, 0])
print("-----------------")
# 遍历三维数组:遍历出数组里的每个元素
for i in range(ary.shape[0]):
for j in range(ary.shape[1]):
for k in range(ary.shape[2]):
print(ary[i, j, k], end='' '')
结果图:

今天关于Python numpy 模块-get_printoptions() 实例源码和python的numpy模块的讲解已经结束,谢谢您的阅读,如果想了解更多关于Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: 'numpy.ndarray' object is not callable、numpy.random.random & numpy.ndarray.astype & numpy.arange、numpy.ravel()/numpy.flatten()/numpy.squeeze()、Numpy:数组创建 numpy.arrray() , numpy.arange()、np.linspace ()、数组基本属性的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

