关于PHP实现机器学习之朴素贝叶斯算法详解和朴素贝叶斯算法实例代码的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于#机器学习算法总结-第二天(朴素贝叶斯、逻辑回归)、PHP如何实现机器学习
关于PHP实现机器学习之朴素贝叶斯算法详解和朴素贝叶斯算法实例代码的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于# 机器学习算法总结-第二天(朴素贝叶斯、逻辑回归)、PHP如何实现机器学习之朴素贝叶斯算法、Python实现机器学习算法:朴素贝叶斯算法、R语言实现 朴素贝叶斯算法等相关知识的信息别忘了在本站进行查找喔。
本文目录一览:- PHP实现机器学习之朴素贝叶斯算法详解(朴素贝叶斯算法实例代码)
- # 机器学习算法总结-第二天(朴素贝叶斯、逻辑回归)
- PHP如何实现机器学习之朴素贝叶斯算法
- Python实现机器学习算法:朴素贝叶斯算法
- R语言实现 朴素贝叶斯算法
")
PHP实现机器学习之朴素贝叶斯算法详解(朴素贝叶斯算法实例代码)
本文实例讲述了PHP实现机器学习之朴素贝叶斯算法。分享给大家供大家参考,具体如下:
机器学习已经在我们的生活中变得随处可见了。比如从你在家的时候温控器开始工作到智能汽车以及我们口袋中的智能手机。机器学习看上去已经无处不在并且是一个非常值得探索的领域。但是什么是机器学习呢?通常来说,机器学习就是让系统不断的学习并且对新的问题进行预测。从简单的预测购物商品到复杂的数字助理预测。
在这篇文章我将会使用朴素贝叶斯算法Clasifier作为一个类来介绍。这是一个简单易于实施的算法,并且可给出满意的结果。但是这个算法是需要一点统计学的知识去理解的。在文章的最后部分你可以看到一些实例代码,甚至自己去尝试着自己做一下你的机器学习。
起步
那么,这个Classifier是要用来实现什么功能呢?其实它主要是用来判断给定的语句是积极地还是消极的。比如,“Symfony is the best”是一个积极的语句,“No Symfony is bad”是一个消极的语句。所以在给定了一个语句之后,我想让这个Classifier在我不给定一个新的规则的情况就返回一个语句类型。
我给Classifier命名了一个相同名称的类,并且包含一个guess方法。这个方法接受一个语句的输入,并且会返回这个语句是积极的还是消极的。这个类就像下面这样:
class Classifier
{
public function guess($statement)
{}
}
我更喜欢使用枚举类型的类而不是字符串作为我的返回值。我将这个枚举类型的类命名为Type,并且包含两个常量:一个POSITIVE,一个NEGATIVE。这两个常量将会当做guess方法的返回值。
class Type
{
const POSITIVE = ''positive'';
const NEGATIVE = ''negative'';
}
初始化工作已经完成,接下来就是要编写我们的算法进行预测了。
朴素贝叶斯
朴素贝叶斯算法是基于一个训练集合工作的,根据这个训练集从而做出相应的预测。这个算法运用了简单的统计学以及一点数学去进行结果的计算。比如像下面四个文本组成的训练集合:
| 语句 | 类型 |
| Symfony is the best | Positive |
| PhpStorm is great | Positive |
| Iltar complains a lot | Negative |
| No Symfony is bad | Negative |
如果给定语句是“Symfony is the best”,那么你可以说这个语句是积极地。你平常也会根据之前学习到的相应知识做出对应的决定,朴素贝叶斯算法也是同样的道理:它根据之前的训练集来决定哪一个类型更加相近。
学习
在这个算法正式工作之前,它需要大量的历史信息作为训练集。它需要知道两件事:每一个类型对应的词产生了多少次和每一个语句对应的类型是什么。我们在实施的时候会将这两种信息存储在两个数组当中。一个数组包含每一类型的词语统计,另一个数组包含每一个类型的语句统计。所有的其他信息都可以从这两个数组中聚合。代码就像下面的一样:
function learn($statement, $type)
{
$words = $this->getWords($statement);
foreach ($words as $word) {
if (!isset($this->words[$type][$word])) {
$this->words[$type][$word] = 0;
}
$this->words[$type][$word]++; // 增加类型的词语统计
}
$this->documents[$type]++; // 增加类型的语句统计
}
有了这个集合以后,现在这个算法就可以根据历史数据接受预测训练了。
定义
为了解释这个算法是如何工作的,几个定义是必要的。首先,让我们定义一下输入的语句是给定类型中的一个的概率。这个将会表示为P(Type)。它是以已知类型的数据的类型作为分子,还有整个训练集的数据数量作为分母来得出的。一个数据就是整个训练集中的一个。到现在为止,这个方法可以将会命名为totalP,像下面这样:
function totalP($type)
{
return ($this->documents[$type] + 1) / (array_sum($this->documents) + 1);
}
请注意,在这里分子和分母都加了1。这是为了避免分子和分母都为0的情况。
根据上面的训练集的例子,积极和消极的类型都会得出0.6的概率。每中类型的数据都是2个,一共是4个数据所以就是(2+1)/(4+1)。
第二个要定义的是对于给定的一个词是属于哪个确定类型的概率。这个我们定义成P(word,Type)。首先我们要得到一个词在训练集中给出确定类型出现的次数,然后用这个结果来除以整个给定类型数据的词数。这个方法我们定义为p:
function p($word, $type)
{
$count = isset($this->words[$type][$word]) ? $this->words[$type][$word] : 0;
return ($count + 1) / (array_sum($this->words[$type]) + 1);
}
在本次的训练集中,“is”的是积极类型的概率为0.375。这个词在整个积极的数据中的7个词中占了两次,所以结果就是(2+1)/(7+1)。
最后,这个算法应该只关心关键词而忽略其他的因素。一个简单的方法就是将给定的字符串中的单词分离出来:
function getWords($string)
{
return preg_split(''/\s+/'', preg_replace(''/[^A-Za-z0-9\s]/'', '''', strtolower($string)));
}
准备工作都做好了,开始真正实施我们的计划吧!
预测
为了预测语句的类型,这个算法应该计算所给定语句的两个类型的概率。像上面一样,我们定义一个P(Type,sentence)。得出概率高的类型将会是Classifier类中算法返回的结果。
为了计算P(Type,sentence),算法当中将用到贝叶斯定理。算法像这样被定义:P(Type,sentence)= P(Type)* P(sentence,Type)/ P(sentence)。这意味着给定语句的类型概率和给定类型语句概率除以语句的概率的结果是相同的。
那么算法在计算每一个相同语句的P(Tyoe,sentence),P(sentence)是保持一样的。这意味着算法就可以省略其他因素,我们只需要关心最高的概率而不是实际的值。计算就像这样:P(Type,sentence) = P(Type)* P(sentence,Type)。
最后,为了计算P(sentence,Type),我们可以为语句中的每个词添加一条链式规则。所以在一条语句中如果有n个词的话,它将会和P(word_1,Type)* P(word_2,Type)* P(word_3,Type)* .....*P(word_n,Type)是一样的。每一个词计算结果的概率使用了我们前面看到的定义。
好了,所有的都说完了,是时候在php中实际操作一下了:
function guess($statement)
{
$words = $this->getWords($statement); // 得到单词
$best_likelihood = 0;
$best_type = null;
foreach ($this->types as $type) {
$likelihood = $this->pTotal($type); //计算 P(Type)
foreach ($words as $word) {
$likelihood *= $this->p($word, $type); // 计算 P(word, Type)
}
if ($likelihood > $best_likelihood) {
$best_likelihood = $likelihood;
$best_type = $type;
}
}
return $best_type;
}
这就是所有的工作,现在算法可以预测语句的类型了。你要做的就是让你的算法开始学习:
$classifier = new Classifier();
$classifier->learn(''Symfony is the best'', Type::POSITIVE);
$classifier->learn(''PhpStorm is great'', Type::POSITIVE);
$classifier->learn(''Iltar complains a lot'', Type::NEGATIVE);
$classifier->learn(''No Symfony is bad'', Type::NEGATIVE);
var_dump($classifier->guess(''Symfony is great'')); // string(8) "positive"
var_dump($classifier->guess(''I complain a lot'')); // string(8) "negative"
所有的代码我已经上传到了GIT上,https://github.com/yannickl88/blog-articles/blob/master/src/machine-learning-naive-bayes/Classifier.php
github上完整php代码如下:
<?php
class Type
{
const POSITIVE = ''positive'';
const NEGATIVE = ''negative'';
}
class Classifier
{
private $types = [Type::POSITIVE, Type::NEGATIVE];
private $words = [Type::POSITIVE => [], Type::NEGATIVE => []];
private $documents = [Type::POSITIVE => 0, Type::NEGATIVE => 0];
public function guess($statement)
{
$words = $this->getWords($statement); // get the words
$best_likelihood = 0;
$best_type = null;
foreach ($this->types as $type) {
$likelihood = $this->pTotal($type); // calculate P(Type)
foreach ($words as $word) {
$likelihood *= $this->p($word, $type); // calculate P(word, Type)
}
if ($likelihood > $best_likelihood) {
$best_likelihood = $likelihood;
$best_type = $type;
}
}
return $best_type;
}
public function learn($statement, $type)
{
$words = $this->getWords($statement);
foreach ($words as $word) {
if (!isset($this->words[$type][$word])) {
$this->words[$type][$word] = 0;
}
$this->words[$type][$word]++; // increment the word count for the type
}
$this->documents[$type]++; // increment the document count for the type
}
public function p($word, $type)
{
$count = 0;
if (isset($this->words[$type][$word])) {
$count = $this->words[$type][$word];
}
return ($count + 1) / (array_sum($this->words[$type]) + 1);
}
public function pTotal($type)
{
return ($this->documents[$type] + 1) / (array_sum($this->documents) + 1);
}
public function getWords($string)
{
return preg_split(''/\s+/'', preg_replace(''/[^A-Za-z0-9\s]/'', '''', strtolower($string)));
}
}
$classifier = new Classifier();
$classifier->learn(''Symfony is the best'', Type::POSITIVE);
$classifier->learn(''PhpStorm is great'', Type::POSITIVE);
$classifier->learn(''Iltar complains a lot'', Type::NEGATIVE);
$classifier->learn(''No Symfony is bad'', Type::NEGATIVE);
var_dump($classifier->guess(''Symfony is great'')); // string(8) "positive"
var_dump($classifier->guess(''I complain a lot'')); // string(8) "negative"
结束语
尽管我们只进行了很少的训练,但是算法还是应该能给出相对精确的结果。在真实环境,你可以让机器学习成百上千的记录,这样就可以给出更精准的结果。你可以下载查看这篇文章(英文):朴素贝叶斯已经被证明可以给出情绪统计的结果。
而且,朴素贝叶斯不仅仅可以运用到文本类的应用。希望通过这篇文章可以拉近你和机器学习的一点点距离。
原文地址:https://stovepipe.systems/post/machine-learning-naive-bayes
更多关于PHP相关内容感兴趣的读者可查看本站专题:《PHP数据结构与算法教程》、《php程序设计算法总结》、《php字符串(string)用法总结》、《PHP数组(Array)操作技巧大全》、《PHP常用遍历算法与技巧总结》及《PHP数学运算技巧总结》
希望本文所述对大家PHP程序设计有所帮助。
- python中文分词教程之前向最大正向匹配算法详解
- PHP实现的字符串匹配算法示例【sunday算法】
- 基于PHP实现栈数据结构和括号匹配算法示例
- php中最简单的字符串匹配算法
- PHP基于二分法实现数组查找功能示例【循环与递归算法】
- PHP基于回溯算法解决n皇后问题的方法示例
- PHP实现找出数组中出现次数超过数组长度一半的数字算法示例
- php 二维数组快速排序算法的实现代码
- PHP实现的贪婪算法实例
- PHP实现的折半查询算法示例
- PHP实现的最大正向匹配算法示例
")
# 机器学习算法总结-第二天(朴素贝叶斯、逻辑回归)
朴素贝叶斯
 全概率公式:
全概率公式:  例子参考这里:https://www.cnblogs.com/panlangen/p/7801054.html
例子参考这里:https://www.cnblogs.com/panlangen/p/7801054.html
优缺点
优点: (1) 算法逻辑简单,易于实现(算法思路很简单,只要使用贝叶斯公式转化即可!) (2)分类过程中时空开销小(假设特征相互独立,只会涉及到二维存储) 缺点: 朴素贝叶斯假设属性之间相互独立,这种假设在实际过程中往往是不成立的。在属性之间相关性越大,分类误差也就越大。
类型
- 高斯分布型:先验为高斯分布(正态分布)的朴素贝叶斯,假设每个标签的数据都服从简单的正态分布
- 多项式型:用于离散值模型里。先验为多项式分布的朴素贝叶斯(非常适合用于描述出现次数,常用于文本分类)
- 伯努利型:最后得到的特征只有0(没出现)和1(出现过)。
总结

词集模型:Set Of Words,单词构成的集合,集合自然每个元素都只有一个,也即词集中的每个单词都只有一个. 词袋模型:Bag Of Words,如果一个单词在文档中出现不止一次,并统计其出现的次数(频数)
面试常问的
1、 朴素贝叶斯与LR的区别?
朴素贝叶斯是生成模型,根据已有样本进行贝叶斯估计学习出先验概率P(Y)和条件概率P(X|Y),进而求出联合分布概率P(XY),最后利用贝叶斯定理求解P(Y|X), 而LR是判别模型,根据极大化对数似然函数直接求出条件概率P(Y|X);朴素贝叶斯是基于很强的条件独立假设(在已知分类Y的条件下,各个特征变量取值是相互独立的),而LR则对此没有要求;朴素贝叶斯适用于数据集少的情景,而LR适用于大规模数据集。
2、 在估计条件概率P(X|Y)时出现概率为0的情况怎么办?
引入λ,当λ=1时称为拉普拉斯平滑。
3、太多小的数相乘,最后会四舍五入得到0.出现下溢出怎么办?
乘积取自然对数
生成模式和判别模式的区别: 生成模式:由数据学得联合概率分布,求出条件概率分布P(Y|X)的预测模型; 常见的生成模型有:朴素贝叶斯、隐马尔可夫模型、高斯混合模型、文档主题生成模型(LDA)、限制玻尔兹曼机 判别模式:由数据学得决策函数或条件概率分布作为预测模型 常见的判别模型有:K近邻、SVM、决策树、感知机、线性判别分析(LDA)、线性回归、传统的神经网络、逻辑斯蒂回归、boosting、条件随机场
逻辑回归
pdf下载在这里:http://www.peixun.net/view/1278.html 
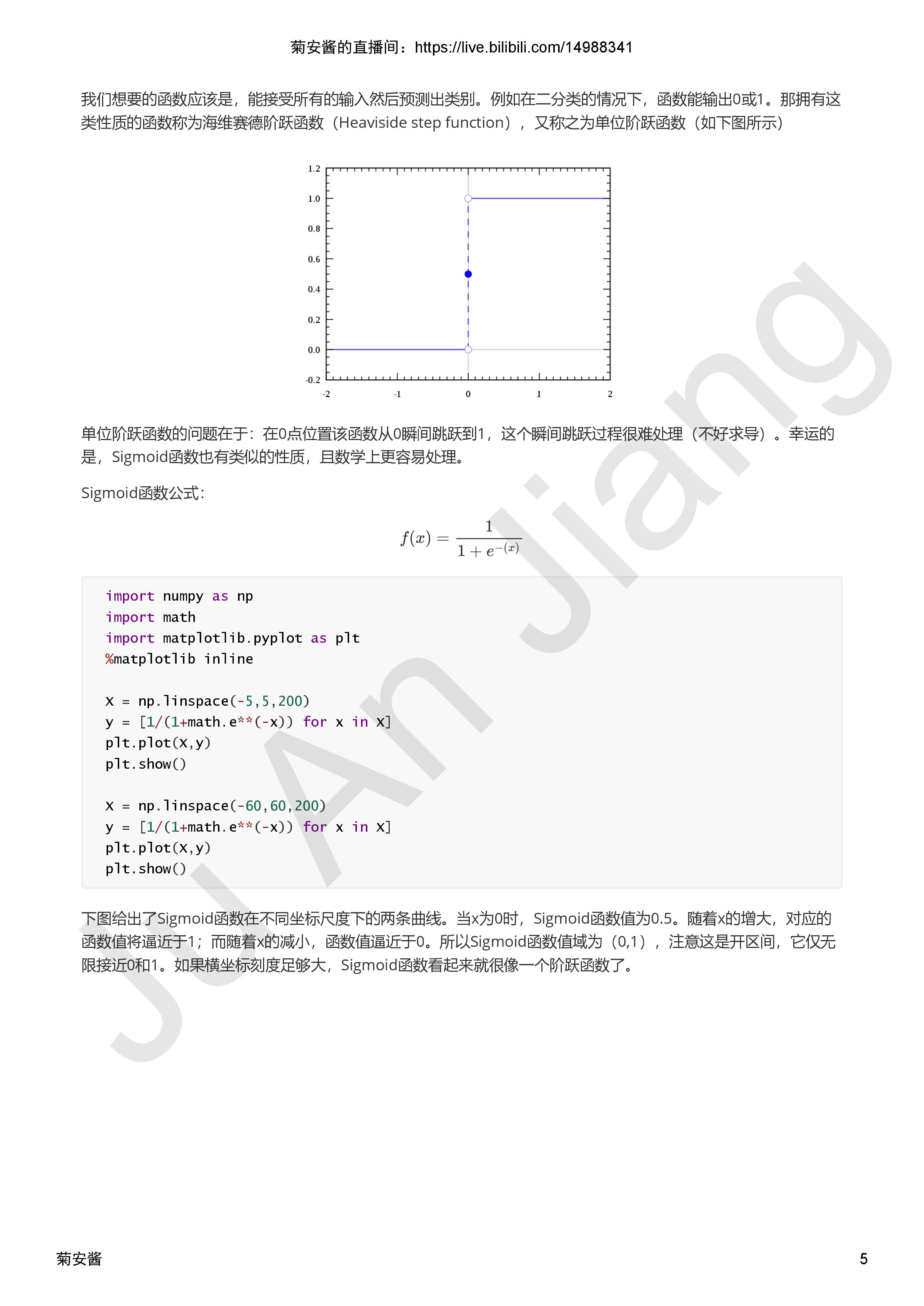
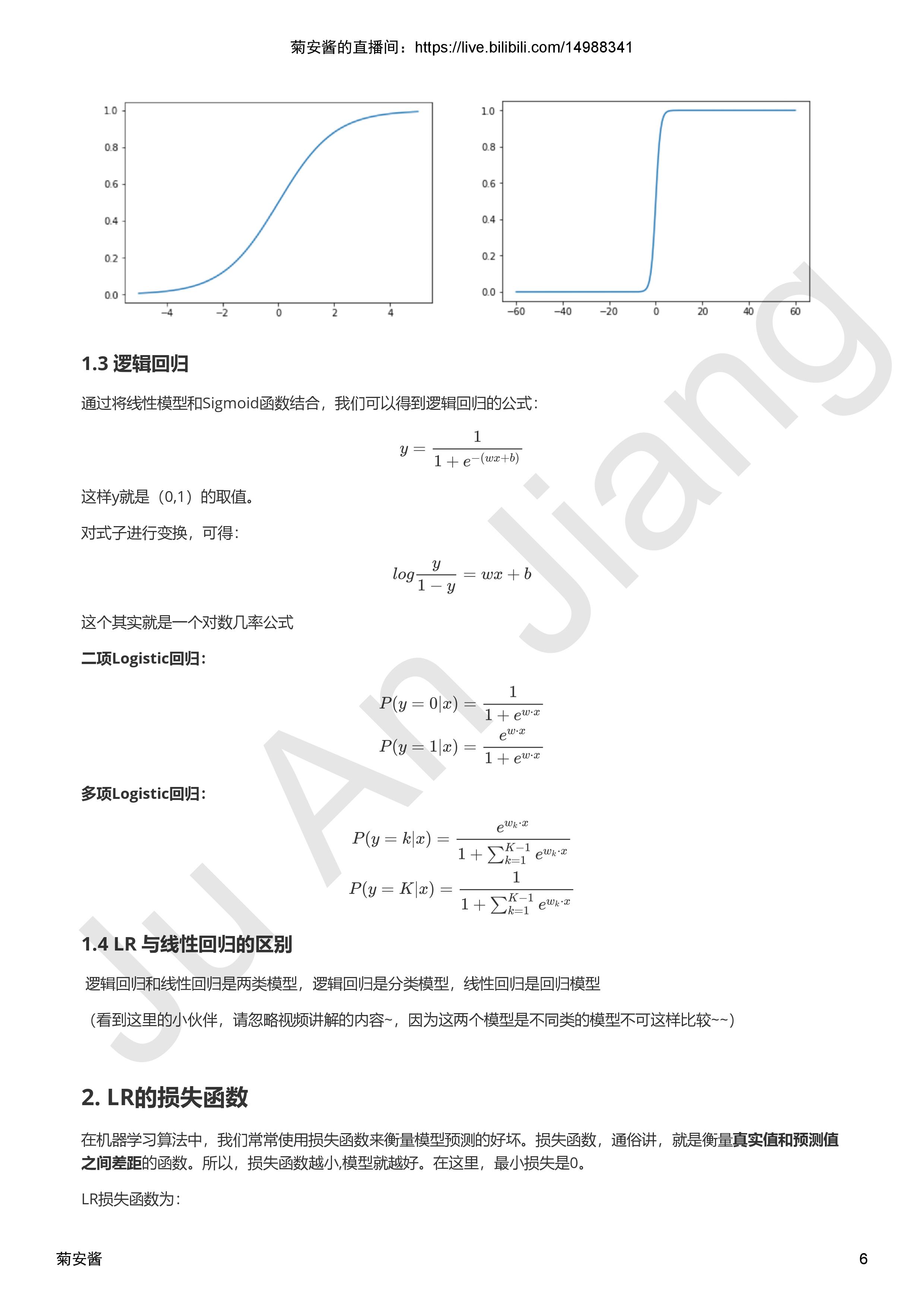













 视频参考链接:https://www.bilibili.com/video/av36837923/?spm_id_from=333.788.videocard.2
视频参考链接:https://www.bilibili.com/video/av36837923/?spm_id_from=333.788.videocard.2

PHP如何实现机器学习之朴素贝叶斯算法
本文主要介绍了php实现机器学习之朴素贝叶斯算法,结合实例形式详细分析了朴素贝叶斯算法的概念、原理及php实现技巧,需要的朋友可以参考下,希望能帮助到大家。
本文实例讲述了PHP实现机器学习之朴素贝叶斯算法。分享给大家供大家参考,具体如下:
机器学习已经在我们的生活中变得随处可见了。比如从你在家的时候温控器开始工作到智能汽车以及我们口袋中的智能手机。机器学习看上去已经无处不在并且是一个非常值得探索的领域。但是什么是机器学习呢?通常来说,机器学习就是让系统不断的学习并且对新的问题进行预测。从简单的预测购物商品到复杂的数字助理预测。
在这篇文章我将会使用朴素贝叶斯算法Clasifier作为一个类来介绍。这是一个简单易于实施的算法,并且可给出满意的结果。但是这个算法是需要一点统计学的知识去理解的。在文章的最后部分你可以看到一些实例代码,甚至自己去尝试着自己做一下你的机器学习。
起步
立即学习“PHP免费学习笔记(深入)”;
那么,这个Classifier是要用来实现什么功能呢?其实它主要是用来判断给定的语句是积极地还是消极的。比如,“Symfony is the best”是一个积极的语句,“No Symfony is bad”是一个消极的语句。所以在给定了一个语句之后,我想让这个Classifier在我不给定一个新的规则的情况就返回一个语句类型。
我给Classifier命名了一个相同名称的类,并且包含一个guess方法。这个方法接受一个语句的输入,并且会返回这个语句是积极的还是消极的。这个类就像下面这样:
class Classifier
{
public function guess($statement)
{}
}我更喜欢使用枚举类型的类而不是字符串作为我的返回值。我将这个枚举类型的类命名为Type,并且包含两个常量:一个POSITIVE,一个NEGATIVE。这两个常量将会当做guess方法的返回值。
class Type
{
const POSITIVE = 'positive';
const NEGATIVE = 'negative';
}初始化工作已经完成,接下来就是要编写我们的算法进行预测了。
朴素贝叶斯
朴素贝叶斯算法是基于一个训练集合工作的,根据这个训练集从而做出相应的预测。这个算法运用了简单的统计学以及一点数学去进行结果的计算。比如像下面四个文本组成的训练集合:
如果给定语句是“Symfony is the best”,那么你可以说这个语句是积极地。你平常也会根据之前学习到的相应知识做出对应的决定,朴素贝叶斯算法也是同样的道理:它根据之前的训练集来决定哪一个类型更加相近。
学习
在这个算法正式工作之前,它需要大量的历史信息作为训练集。它需要知道两件事:每一个类型对应的词产生了多少次和每一个语句对应的类型是什么。我们在实施的时候会将这两种信息存储在两个数组当中。一个数组包含每一类型的词语统计,另一个数组包含每一个类型的语句统计。所有的其他信息都可以从这两个数组中聚合。代码就像下面的一样:
function learn($statement, $type)
{
$words = $this->getWords($statement);
foreach ($words as $word) {
if (!isset($this->words[$type][$word])) {
$this->words[$type][$word] = 0;
}
$this->words[$type][$word]++; // 增加类型的词语统计
}
$this->documents[$type]++; // 增加类型的语句统计
}有了这个集合以后,现在这个算法就可以根据历史数据接受预测训练了。
定义
为了解释这个算法是如何工作的,几个定义是必要的。首先,让我们定义一下输入的语句是给定类型中的一个的概率。这个将会表示为P(Type)。它是以已知类型的数据的类型作为分子,还有整个训练集的数据数量作为分母来得出的。一个数据就是整个训练集中的一个。到现在为止,这个方法可以将会命名为totalP,像下面这样:
function totalP($type)
{
return ($this->documents[$type] + 1) / (array_sum($this->documents) + 1);
}请注意,在这里分子和分母都加了1。这是为了避免分子和分母都为0的情况。
根据上面的训练集的例子,积极和消极的类型都会得出0.6的概率。每中类型的数据都是2个,一共是4个数据所以就是(2+1)/(4+1)。
第二个要定义的是对于给定的一个词是属于哪个确定类型的概率。这个我们定义成P(word,Type)。首先我们要得到一个词在训练集中给出确定类型出现的次数,然后用这个结果来除以整个给定类型数据的词数。这个方法我们定义为p:
function p($word, $type)
{
$count = isset($this->words[$type][$word]) ? $this->words[$type][$word] : 0;
return ($count + 1) / (array_sum($this->words[$type]) + 1);
}在本次的训练集中,“is”的是积极类型的概率为0.375。这个词在整个积极的数据中的7个词中占了两次,所以结果就是(2+1)/(7+1)。
最后,这个算法应该只关心关键词而忽略其他的因素。一个简单的方法就是将给定的字符串中的单词分离出来:
function getWords($string)
{
return preg_split('/\s+/', preg_replace('/[^A-Za-z0-9\s]/', '', strtolower($string)));
}准备工作都做好了,开始真正实施我们的计划吧!
预测
为了预测语句的类型,这个算法应该计算所给定语句的两个类型的概率。像上面一样,我们定义一个P(Type,sentence)。得出概率高的类型将会是Classifier类中算法返回的结果。
为了计算P(Type,sentence),算法当中将用到贝叶斯定理。算法像这样被定义:P(Type,sentence)= P(Type)* P(sentence,Type)/ P(sentence)。这意味着给定语句的类型概率和给定类型语句概率除以语句的概率的结果是相同的。
那么算法在计算每一个相同语句的P(Tyoe,sentence),P(sentence)是保持一样的。这意味着算法就可以省略其他因素,我们只需要关心最高的概率而不是实际的值。计算就像这样:P(Type,sentence) = P(Type)* P(sentence,Type)。
最后,为了计算P(sentence,Type),我们可以为语句中的每个词添加一条链式规则。所以在一条语句中如果有n个词的话,它将会和P(word_1,Type)* P(word_2,Type)* P(word_3,Type)* .....*P(word_n,Type)是一样的。每一个词计算结果的概率使用了我们前面看到的定义。
好了,所有的都说完了,是时候在php中实际操作一下了:
function guess($statement)
{
$words = $this->getWords($statement); // 得到单词
$best_likelihood = 0;
$best_type = null;
foreach ($this->types as $type) {
$likelihood = $this->pTotal($type); //计算 P(Type)
foreach ($words as $word) {
$likelihood *= $this->p($word, $type); // 计算 P(word, Type)
}
if ($likelihood > $best_likelihood) {
$best_likelihood = $likelihood;
$best_type = $type;
}
}
return $best_type;
}这就是所有的工作,现在算法可以预测语句的类型了。你要做的就是让你的算法开始学习:
$classifier = new Classifier(); $classifier->learn('Symfony is the best', Type::POSITIVE); $classifier->learn('PhpStorm is great', Type::POSITIVE); $classifier->learn('Iltar complains a lot', Type::NEGATIVE); $classifier->learn('No Symfony is bad', Type::NEGATIVE); var_dump($classifier->guess('Symfony is great')); // string(8) "positive" var_dump($classifier->guess('I complain a lot')); // string(8) "negative"
所有的代码我已经上传到了GIT上,https://github.com/yannickl88/blog-articles/blob/master/src/machine-learning-naive-bayes/Classifier.php
github上完整php代码如下:
[], Type::NEGATIVE => []];
private $documents = [Type::POSITIVE => 0, Type::NEGATIVE => 0];
public function guess($statement)
{
$words = $this->getWords($statement); // get the words
$best_likelihood = 0;
$best_type = null;
foreach ($this->types as $type) {
$likelihood = $this->pTotal($type); // calculate P(Type)
foreach ($words as $word) {
$likelihood *= $this->p($word, $type); // calculate P(word, Type)
}
if ($likelihood > $best_likelihood) {
$best_likelihood = $likelihood;
$best_type = $type;
}
}
return $best_type;
}
public function learn($statement, $type)
{
$words = $this->getWords($statement);
foreach ($words as $word) {
if (!isset($this->words[$type][$word])) {
$this->words[$type][$word] = 0;
}
$this->words[$type][$word]++; // increment the word count for the type
}
$this->documents[$type]++; // increment the document count for the type
}
public function p($word, $type)
{
$count = 0;
if (isset($this->words[$type][$word])) {
$count = $this->words[$type][$word];
}
return ($count + 1) / (array_sum($this->words[$type]) + 1);
}
public function pTotal($type)
{
return ($this->documents[$type] + 1) / (array_sum($this->documents) + 1);
}
public function getWords($string)
{
return preg_split(''/\s+/'', preg_replace(''/[^A-Za-z0-9\s]/'', '''', strtolower($string)));
}
}
$classifier = new Classifier();
$classifier->learn('Symfony is the best', Type::POSITIVE);
$classifier->learn('PhpStorm is great', Type::POSITIVE);
$classifier->learn('Iltar complains a lot', Type::NEGATIVE);
$classifier->learn('No Symfony is bad', Type::NEGATIVE);
var_dump($classifier->guess('Symfony is great')); // string(8) "positive"
var_dump($classifier->guess('I complain a lot')); // string(8) "negative"相关推荐:
总结Python常用的机器学习库
机器学习算法的随机数据生成方法介绍
用Python从零实现贝叶斯分类器的机器学习的教程
以上就是PHP如何实现机器学习之朴素贝叶斯算法的详细内容,更多请关注php中文网其它相关文章!

Python实现机器学习算法:朴素贝叶斯算法
''''''
数据集:Mnist
训练集数量:60000
测试集数量:10000
''''''
import numpy as np
import time
def loadData(fileName):
''''''
加载文件
:param fileName:要加载的文件路径
:return: 数据集和标签集
''''''
# 存放数据及标记
dataArr = [];
labelArr = []
# 读取文件
fr = open(fileName)
# 遍历文件中的每一行
for line in fr.readlines():
# 获取当前行,并按“,”切割成字段放入列表中
# strip:去掉每行字符串首尾指定的字符(默认空格或换行符)
# split:按照指定的字符将字符串切割成每个字段,返回列表形式
curLine = line.strip().split('','')
# 将每行中除标记外的数据放入数据集中(curLine[0]为标记信息)
# 在放入的同时将原先字符串形式的数据转换为整型
# 此外将数据进行了二值化处理,大于128的转换成1,小于的转换成0,方便后续计算
dataArr.append([int(int(num) > 128) for num in curLine[1:]])
# 将标记信息放入标记集中
# 放入的同时将标记转换为整型
labelArr.append(int(curLine[0]))
# 返回数据集和标记
return dataArr, labelArr
def NaiveBayes(Py, Px_y, x):
''''''
通过朴素贝叶斯进行概率估计
:param Py: 先验概率分布
:param Px_y: 条件概率分布
:param x: 要估计的样本x
:return: 返回所有label的估计概率
''''''
# 设置特征数目
featrueNum = 784
# 设置类别数目
classNum = 10
# 建立存放所有标记的估计概率数组
P = [0] * classNum
# 对于每一个类别,单独估计其概率
for i in range(classNum):
# 初始化sum为0,sum为求和项。
# 在训练过程中对概率进行了log处理,所以这里原先应当是连乘所有概率,最后比较哪个概率最大
# 但是当使用log处理时,连乘变成了累加,所以使用sum
sum = 0
# 获取每一个条件概率值,进行累加
for j in range(featrueNum):
sum += Px_y[i][j][x[j]]
# 最后再和先验概率相加(也就是式4.7中的先验概率乘以后头那些东西,乘法因为log全变成了加法)
P[i] = sum + Py[i]
# max(P):找到概率最大值
# P.index(max(P)):找到该概率最大值对应的所有(索引值和标签值相等)
return P.index(max(P))
def accuracy(Py, Px_y, testDataArr, testLabelArr):
''''''
对测试集进行测试
:param Py: 先验概率分布
:param Px_y: 条件概率分布
:param testDataArr: 测试集数据
:param testLabelArr: 测试集标记
:return: 准确率
''''''
# 错误值计数
errorCnt = 0
# 循环遍历测试集中的每一个样本
for i in range(len(testDataArr)):
# 获取预测值
presict = NaiveBayes(Py, Px_y, testDataArr[i])
# 与答案进行比较
if presict != testLabelArr[i]:
# 若错误 错误值计数加1
errorCnt += 1
# 返回准确率
return 1 - (errorCnt / len(testDataArr))
def getAllProbability(trainDataArr, trainLabelArr):
''''''
通过训练集计算先验概率分布和条件概率分布
:param trainDataArr: 训练数据集
:param trainLabelArr: 训练标记集
:return: 先验概率分布和条件概率分布
''''''
# 设置样本特诊数目,数据集中手写图片为28*28,转换为向量是784维。
# (我们的数据集已经从图像转换成784维的形式了,CSV格式内就是)
featureNum = 784
# 设置类别数目,0-9共十个类别
classNum = 10
# 初始化先验概率分布存放数组,后续计算得到的P(Y = 0)放在Py[0]中,以此类推
# 数据长度为10行1列
# 各个类别的先验概率分布
Py = np.zeros((classNum, 1))
# 对每个类别进行一次循环,分别计算它们的先验概率分布
# 计算公式为书中"4.2节 朴素贝叶斯法的参数估计 公式4.8"
for i in range(classNum):
# 下方式子拆开分析
# np.mat(trainLabelArr) == i:将标签转换为矩阵形式,里面的每一位与i比较,若相等,该位变为Ture,反之False
# np.sum(np.mat(trainLabelArr) == i):计算上一步得到的矩阵中Ture的个数,进行求和(直观上就是找所有label中有多少个
# 为i的标记,求得4.8式P(Y = Ck)中的分子)
# np.sum(np.mat(trainLabelArr) == i)) + 1:参考“4.2.3节 贝叶斯估计”,例如若数据集总不存在y=1的标记,也就是说
# 手写数据集中没有1这张图,那么如果不加1,由于没有y=1,所以分子就会变成0,那么在最后求后验概率时这一项就变成了0,再
# 和条件概率乘,结果同样为0,不允许存在这种情况,所以分子加1,分母加上K(K为标签可取的值数量,这里有10个数,取值为10)
# 参考公式4.11
# (len(trainLabelArr) + 10):标签集的总长度+10.
# ((np.sum(np.mat(trainLabelArr) == i)) + 1) / (len(trainLabelArr) + 10):最后求得的先验概率
Py[i] = ((np.sum(np.mat(trainLabelArr) == i)) + 1) / (len(trainLabelArr) + 10)
# 转换为log对数形式
# log书中没有写到,但是实际中需要考虑到,原因是这样:
# 最后求后验概率估计的时候,形式是各项的相乘(“4.1 朴素贝叶斯法的学习” 式4.7),这里存在两个问题:1.某一项为0时,结果为0.
# 这个问题通过分子和分母加上一个相应的数可以排除,前面已经做好了处理。2.如果特征特别多(例如在这里,需要连乘的项目有784个特征
# 加一个先验概率分布一共795项相乘,所有数都是0-1之间,结果一定是一个很小的接近0的数。)理论上可以通过结果的大小值判断, 但在
# 程序运行中很可能会向下溢出无法比较,因为值太小了。所以人为把值进行log处理。log在定义域内是一个递增函数,也就是说log(x)中,
# x越大,log也就越大,单调性和原数据保持一致。所以加上log对结果没有影响。此外连乘项通过log以后,可以变成各项累加,简化了计算。
# 在似然函数中通常会使用log的方式进行处理(至于此书中为什么没涉及,我也不知道)
Py = np.log(Py)
# 计算条件概率 Px_y=P(X=x|Y = y)
# 计算条件概率分成了两个步骤,下方第一个大for循环用于累加,参考书中“4.2.3 贝叶斯估计 式4.10”,下方第一个大for循环内部是
# 用于计算式4.10的分子,至于分子的+1以及分母的计算在下方第二个大For内
# 初始化为全0矩阵,用于存放所有情况下的条件概率
Px_y = np.zeros((classNum, featureNum, 2))
# 对标记集进行遍历
for i in range(len(trainLabelArr)):
# 获取当前循环所使用的标记
label = trainLabelArr[i]
# 获取当前要处理的样本
x = trainDataArr[i]
# 对该样本的每一维特诊进行遍历
for j in range(featureNum):
# 在矩阵中对应位置加1
# 这里还没有计算条件概率,先把所有数累加,全加完以后,在后续步骤中再求对应的条件概率
Px_y[label][j][x[j]] += 1
# 第二个大for,计算式4.10的分母,以及分子和分母之间的除法
# 循环每一个标记(共10个)
for label in range(classNum):
# 循环每一个标记对应的每一个特征
for j in range(featureNum):
# 获取y=label,第j个特诊为0的个数
Px_y0 = Px_y[label][j][0]
# 获取y=label,第j个特诊为1的个数
Px_y1 = Px_y[label][j][1]
# 对式4.10的分子和分母进行相除,再除之前依据贝叶斯估计,分母需要加上2(为每个特征可取值个数)
# 分别计算对于y= label,x第j个特征为0和1的条件概率分布
Px_y[label][j][0] = np.log((Px_y0 + 1) / (Px_y0 + Px_y1 + 2))
Px_y[label][j][1] = np.log((Px_y1 + 1) / (Px_y0 + Px_y1 + 2))
# 返回先验概率分布和条件概率分布
return Py, Px_y
if __name__ == "__main__":
start = time.time()
# 获取训练集
print(''start read transSet'')
trainDataArr, trainLabelArr = loadData(''../Mnist/mnist_train.csv'')
# 获取测试集
print(''start read testSet'')
testDataArr, testLabelArr = loadData(''../Mnist/mnist_test.csv'')
# 开始训练,学习先验概率分布和条件概率分布
print(''start to train'')
Py, Px_y = getAllProbability(trainDataArr, trainLabelArr)
# 使用习得的先验概率分布和条件概率分布对测试集进行测试
print(''start to test'')
accuracy = accuracy(Py, Px_y, testDataArr, testLabelArr)
# 打印准确率
print(''the accuracy is:'', accuracy)
# 打印时间
print(''time span:'', time.time() - start)
start read transSet
start read testSet
start to train
start to test
the accuracy is: 0.8432999999999999
time span: 90.73810172080994

R语言实现 朴素贝叶斯算法
library(NLP)
library(tm)
library(wordcloud)
library(RColorBrewer)
library(e1071)
library(gmodels)
setwd(''C:/Users/E0399448/Desktop/机器学习'')
###spam 垃圾短信 ham非垃圾短信
###数据地址:https://github.com/stedy/Machine-Learning-with-R-datasets/commit/72e6b6cc91bc2bb08eb6f99f52c033677cb70c1a
###选择 sms_spam.csv 这个表格
sms_raw <- read.csv("sms_spam.csv",header=TRUE,stringsAsFactors=FALSE)
#str(sms_raw)查看数据结构
sms_raw$type <- factor(sms_raw$type) ####将type设为因子变量
table(sms_raw$type)#产看每个类型的数量
prop.table(table(sms_raw$type))#查看每个类型的占的百分比
######################数据清洗
#1. 创建语料库corpus 只收集test短信内容 为list格式 sms_corpus[[1]]$content
sms_corpus <- Corpus(VectorSource(sms_raw$text))
#2.清理语料库
#2.1 # 所有字母转换成小写
corpus_clean <- tm_map(sms_corpus, tolower)
# 2.2去除text中的数字
corpus_clean <- tm_map(corpus_clean, removeNumbers)
# 2.3去除停用词,例如and,or,until...
corpus_clean <- tm_map(corpus_clean, removeWords, stopwords())
# 2.4去除标点符号
corpus_clean <- tm_map(corpus_clean, removePunctuation)
# 2.5去除多余的空格,使单词之间只保留一个空格
corpus_clean <- tm_map(corpus_clean, stripWhitespace)
###see effect
#inspect(corpus_clean[1:3])
##在矩阵中,若数值为0的元素数目远远多于非0元素的数目,并且非0元素分布没有规律时,则称该矩阵为稀疏矩阵;与之相反,若非0元素数目占大多数时,则称该矩阵为稠密矩阵。定义非零元素的总数比上矩阵所有元素的总数为矩阵的稠密度。
#2.6 将文本信息转化成DocumentTermMatrix类型的稀疏矩阵 把所有单词转化成0/1/2/34zhiou ,每一条短信百变成单独的文件,terms为所有单词的总数,ncols, nrows为文件总数也就是相当于短信的数量
sms_dtm <- DocumentTermMatrix(corpus_clean)
#
#corpus_clean <- tm_map(corpus_clean, PlainTextDocument) ###下一句出错了用的转格式先
############################数据清理完毕####################
#1. 数据准备——建立train set & test set
#1.1 # split sms_raw
sms_raw_train <- sms_raw[1:4169,]
sms_raw_test <- sms_raw[4170:5574,]
#1.2 #split sms_dtm
sms_dtm_train <- sms_dtm[1:4169,]
sms_dtm_test <- sms_dtm[4170:5574,]
#split corpus_clean
sms_corpus_train <- corpus_clean[1:4169]
sms_corpus_test <- corpus_clean[4170:5574]
####################
#####分别取取垃圾spam短信种类和ham-非垃圾种类短信
spam <- subset(sms_raw_train, type == "spam")
ham <- subset(sms_raw_train, type == "ham")
####查看垃圾短信的最多出现的词语,可视化!!!!!!!!!!!!!!!!
wordcloud(spam$text, max.words=40, scale=c(3,0.5)) ####
####查看非垃圾短信的最多出现的词语,可视化!!!!!!!!!!!!!!!!
wordcloud(ham$text,max.words=40,scale=c(3,0.5))
#########################减少词儿特征#############################
##1.找出出现过5次以上的词语
findFreqTerms(sms_dtm_train,5)
#2.将这些词设置成指示标识,下面建模时用这个指示标识提示模型只对这些词进行计算
#sms_dict <- Dictionary(findFreqTerms(sms_dtm_train,5))
####2.1· 先改文本格式
myfindFreqTerms <- function(x,lowfreq=0,highfreq=Inf){
stopifnot(inherits(x,c("DocumentTermMatrix","TermDocumentMatrix")),
is.numeric(lowfreq),is.numeric(highfreq))
if(inherits(x,"DocumentTermMatrix"))
x<-t(x)
rs <- slam::row_sums(x)
y <- which(rs >= lowfreq & rs<= highfreq)
return(x[y,])
}
###2.2 dictionary 化 把出现过5次以上的词单独组成一个元素
sms_dict <- Terms(myfindFreqTerms(sms_dtm_train,5))
#继续稀疏矩阵 nols
sms_train <- DocumentTermMatrix(sms_corpus_train,list(dictionary=sms_dict))
sms_test <- DocumentTermMatrix(sms_corpus_test, list(dictionary=sms_dict))
#####有的单词在同一条会出现多次,转化为某单词是否出现
convert_counts <- function(x){
x <- ifelse(x>0,1,0)
x <- factor(x, levels=c(0,1),labels=c("No","Yes"))
return(x)
}
###change to table of one document has the words or not format 转为每条信息是否出现某单词的表格i形式
sms_train <- apply(sms_train, MARGIN=2, convert_counts)
sms_test <- apply(sms_test, MARGIN=2, convert_counts)
##################################开始训练模型###############################
#1.建立NaiveBayesClassifier 建立模型
sms_classifier <- naiveBayes(sms_train,sms_raw_train$type)
#2.测试Classifier 预测test信息的判断是否是垃圾短信
sms_prediction <- predict(sms_classifier, sms_test)
##################################开始评估模型是否标准 看对比情况###############################
CrossTable(sms_prediction,sms_raw_test$type,prop.chisq=TRUE,prop.t=FALSE,
dnn=c("predicted","actual"))
##################################优化模型laplace添加 改lapplace的值进行优化,1或者0.5或者其他的###############################
sms_classifier2 <- naiveBayes(sms_train,sms_raw_train$type,laplace=0.5)
sms_predictions2<- predict(sms_classifier2,sms_test)
CrossTable(sms_predictions2,sms_raw_test$type,prop.chisq = FALSE,prop.r = FALSE,dnn=c(''predicted'',''actual''))
原文出处:https://www.cnblogs.com/bellagao/p/10531284.html
今天关于PHP实现机器学习之朴素贝叶斯算法详解和朴素贝叶斯算法实例代码的讲解已经结束,谢谢您的阅读,如果想了解更多关于# 机器学习算法总结-第二天(朴素贝叶斯、逻辑回归)、PHP如何实现机器学习之朴素贝叶斯算法、Python实现机器学习算法:朴素贝叶斯算法、R语言实现 朴素贝叶斯算法的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

