对于php–将latin1编码的文本插入utf8表(忘记使用mysql_set_charset)感兴趣的读者,本文将提供您所需要的所有信息,并且为您提供关于Can''tinitializecharac
对于php – 将latin1编码的文本插入utf8表(忘记使用mysql_set_charset)感兴趣的读者,本文将提供您所需要的所有信息,并且为您提供关于Can''t initialize character set utf8 (path: /usr/share/mysql/charsets/)、Can''t initialize character set utf8mb4 (path: /usr/share/mysql/charsets/)、MySQL Charset--UTF8和UTF8MB4对比测试、mysql charset=utf8你真的弄明白意思了吗的宝贵知识。
本文目录一览:- php – 将latin1编码的文本插入utf8表(忘记使用mysql_set_charset)
- Can''t initialize character set utf8 (path: /usr/share/mysql/charsets/)
- Can''t initialize character set utf8mb4 (path: /usr/share/mysql/charsets/)
- MySQL Charset--UTF8和UTF8MB4对比测试
- mysql charset=utf8你真的弄明白意思了吗
")
php – 将latin1编码的文本插入utf8表(忘记使用mysql_set_charset)
我有一个PHP网络应用程序,MysqL表格采用utf8文本.我最近将数据从latin1转换为utf8以及相应的表和列.但是,我确实忘了使用MysqL_set_charset和我认为最新的传入数据通过MysqL连接作为latin1.我不知道当latin1进入utf8列时会发生什么,但它会导致一些奇怪的显示问题,例如逗号,引号,&符号等.
现在MysqL_set_charset就位,它正在用时髦的字符拉出数据.现在我有使用正确的字符集的数据库连接资源的任何方式将latin1-utf8汤转换为直接的utf8?
UPDATE table SET col = CONVERT(CONVERT(CONVERT(col USING latin1) USING binary) using utf8);
即使该列是UTF8,它也会强制它将数据拉出为latin1,转换为二进制,转换为utf8并重新插入.
")
Can''t initialize character set utf8 (path: /usr/share/mysql/charsets/)
【1】Can''t initialize character set utf8] (path: /usr/share/mysql/charsets/)

mysql: Character set ''utf8]'' is not a compiled character set and is not specified in the ''/usr/share/mysql/charsets/Index.xml'' file
ERROR 2019 (HY000): Can''t initialize character set utf8] (path: /usr/share/mysql/charsets/)

【1.3】usr/share/mysql/charsets/Index.xml

一看就知道,无法识别解析字符,看看配置文件
【1.4】my.cnf

果然,客户端字符集设置有问题,修改好后,解决问题。
这里因为是 [client]的问题,所以不需要重启mysql,大家可以试试,实在不行再重启 Mysql。
【2】Character set ''utf-8'' is not a compiled character set and is not specified
【3】Mysql:Character set ''utf8mb4'' is not a compiled character set ... 解决方案
连接Mysql时出现如下错误
Mysql:Character set ''utf8mb4'' is not a compiled character set and is not specified in the ''/usr/share/mysql/charsets/Index.xml'' file
解决方法如下:
打开文件/usr/share/mysql/charsets/Index.xml
直接复制文件中utf8的配置,改为utf8mb4后,添加到文件中故障解决,更改方式如下
<charset name="utf8mb4">
<family>Unicode</family>
<description>UTF-8 Unicode</description>
<alias>utf-8</alias>
<collation name="utf8_general_ci" id="33">
<flag>primary</flag>
<flag>compiled</flag>
</collation>
<collation name="utf8_bin" id="83">
<flag>binary</flag>
<flag>compiled</flag>
</collation>
</charset>
参考文件
字符集问题: https://blog.csdn.net/ACMAIN_CHM/article/details/4174186Character set ''utf8mb4'' is not a compiled:https://blog.51cto.com/yangjingangel/1754413
")
Can''t initialize character set utf8mb4 (path: /usr/share/mysql/charsets/)
为了支持 emoj 存储,数据集从 utf8 改成 utf8mb4
环境变量配置如下

Can''t initialize character set utf8mb4 (path: /usr/share/mysql/charsets/)此问题解决办法如下
yum erase php56w-mysql
yum install php56w-mysqlnd意思就是需要使用 php-mysqlnd

MySQL Charset--UTF8和UTF8MB4对比测试
UTF8和UTF8MB4
在早期MySQL版本中,使用只支持最长三字节的UTF8字符集便可以存放所有Unicode字符。随着Unicode的完善,Unicode字符集收录的字符数量越来越多,最新版本的UTF8需要使用1到4个字节来存放Unicode字符,而MySQL为保持版本兼容,依旧使用最多3字节的UTF8字符集,并在MySQL 5.5.3版本引入UTF8MB4字符集来支持4字节的Unicode字符。
汉字 '''' 和 '' '' 是异体字,读音均为xi,但两个字的unicode不同:
对应的UNICODE是 \ud850\udeee;
对应的UTF8是 ��
对应的HEX编码是 %f0%a4%8b%ae熙 对应的UNICODE是 \u7199
熙 对应的UTF8是 熙
熙 对应的HEX编码是 %e7%86%99
在UTF8字符集模式下测试
创建测试表:
CREATE TABLE `tb5001` (
`ID` INT(11) NOT NULL AUTO_INCREMENT,
`C1` VARBINARY(100) DEFAULT NULL,
`C2` VARCHAR(100) DEFAULT NULL,
PRIMARY KEY (`ID`)
) ENGINE=INNODB AUTO_INCREMENT=33 DEFAULT CHARSET=utf8mb4在UTF8字符集下测试
SET NAMES utf8;
INSERT INTO TB5001(C1,C2)
SELECT '''','''';INSERT INTO TB5001(C1,C2)
SELECT ''熙'',''熙'';
SELECT * FROM TB5001;执行第一条INSERT有警告,警告信息为:
Warning Code : 1300
Invalid utf8 character string: ''F0A48B''
Warning Code : 1366
Incorrect string value: ''\xF0\xA4\x8B\xAE'' for column ''C2'' at row 1查询结果为:
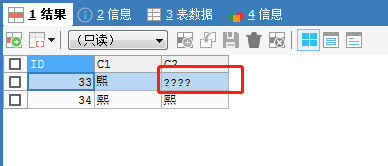
在UTF8字符集下,VARCHAR类型"无法支持“四字节的"",但VARBINARY不受字符集影响。
在UTF8MB4字符集模式下测试
测试脚本
SET NAMES utf8mb4;
INSERT INTO TB5001(C1,C2)
SELECT '''','''';
INSERT INTO TB5001(C1,C2)
SELECT ''熙'',''熙'';
SELECT * FROM TB5001;测试中无任何警告,查询结果:
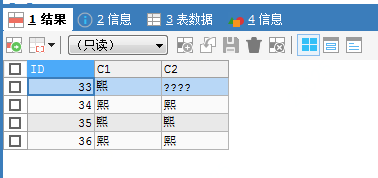
在UTF8MB4字符集下,VARCHAR类型"完美支持“四字节的"",但VARBINARY不受字符集影响。
乱码问题
表TB5001字符集已定义为UTF8MB4,表上C1列的字符集也是UTF8MB4,为啥还出现乱码呢?
测试脚本:
SET NAMES utf8;
SELECT * FROM TB5001;
SET NAMES utf8mb4;
SELECT * FROM TB5001;测试对比图:
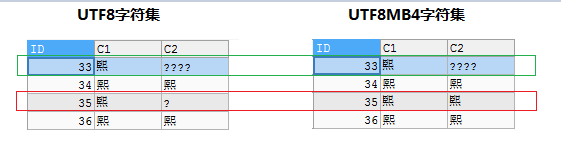
虽然表上C1列的字符集是UTF8MB4,能存放4字节的字符,但:
1、对于ID=33的记录,由于在插入时使用UTF8字符集,在插入到C1列前''''字已经发生乱码,存储到C1列中数据也是乱码,因此无论读取时使用UTF8还是UTF8MB4都是乱码。
2、对于ID-35的记录,由于在插入时使用UTF8MB4字符集,插入C1列前和存储到C1中都正常,在读取时使用UTF8MB4能正常读取,但在读取使用UTF8是乱码。
SET NAMES x相当于执行下面三条语句:
SET character_set_client = x;
SET character_set_results = x;
SET character_set_connection = x;要保证数据库正常存储4字节的表情符合生僻字,除将数据库相关表和列设置为UTF8MB4外,还需要确保操作数据库时使用UTF8MB4,需重点关注以下几个方面:
1、数据库启动配置参数
2、应用与数据库连接配置
3、DBA日常运维操作
如DBA操作过程中,使用mysql客户端连接到数据库执行操作,而mysql客户端可能使用默认UTF8字符集(default-character-set),导出乱码问题。
在xshell工具下粘贴下面代码:
SELECT '''','''';
SELECT ''熙'',''熙'';将代码粘贴到vim工具中自动变为:
SELECT ''<d850><deee>'',''<d850><deee>'';
SELECT ''熙'',''熙'';将代码粘贴到mysql命令总变为:
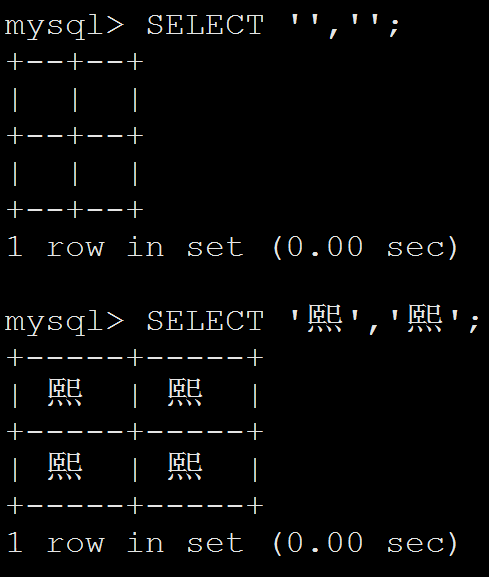
因此建议DBA在日常运维中关注生僻字和表情符,避免异常。
参考:http://seanlook.com/2016/10/23/mysql-utf8mb4/

mysql charset=utf8你真的弄明白意思了吗
1、先来查看一个建表语句
create table student( sid int primary key aotu_increment, sname varchar(20) not null, age int )charset=utf8;
思考一个问题:
- 当我们建表时,不指定charset=utf8的时候,此时插入中文,为什么会报错呢?
- 当指定charset=utf8后,再次插入中文,为什么又可以插入中文,并且不乱码呢?
2、查看CMD黑窗口的字符集
打开CMD黑窗口–>鼠标放在窗口最上方–>点击鼠标右键–>属性–>点击选项

通过上图可以知道:CMD中输入文字使用的字符编码是GBK。同时你在保存文件的时候,经常会看到ANSI字符集,这个代表的是本地字符集,我们在中国,本地字符集使用的就都是GBK编码。
3、你注意这个问题了吗?

客户端client输入的字符,都是采用GBK编码的。mysql服务器存储的字符又是UTF8编码的。那么,我们对数据库、表进行增删改查,最后返回到客户端界面中,要想保证字符不乱码,肯定是经过了"编码转换过程的"。我要问的是,究竟是什么东西完成了这个编码的转换过程的?
4、你不熟悉的几个mysql操作命令
-- 查看数据库支持的所有的字符集(这句命令自己下去操作)。 mysql> show character set; -- 查看系统当前状态,里面可以看到部分字符集设置。 mysql> status; -- 查看系统字符集设置,包括所有的字符集设置 mysql> show variables like ''%char%'';
操作结果如下:

通过上图我们可以看到有一个叫做"connection"的东西,中文名叫做"连接器"。"连接器"就是用来进行"编码转换过程"的。
1)连接器的特性
① “连接器的作用”:
连接客户端与服务端,进行字符集的转换。连接器有这种自动转换的功能。
② “连接器的工作流程”:
Ⅰ首先,客户端的字符先发给连接器,连接器选择一种编码将其转换(转换之后的编码, 与连接器的编码格式一致),进行临时存储。
Ⅱ 接着,连接器再次转换成与服务器一致的编码,并最终存储在服务器中。
Ⅲ 然后,服务器返回的结果,再次先通过连接器,连接器仍然是选择一种编码将其转换(转换之后的编码, 与连接器的编码格式一致),进行临时存储。
Ⅳ 最后,连接器再将结果转化为与客户端一致的字符集,就可以在客户端正常显示了。
2)图示说明连接器connection的作用
图一:

图一说明如下:

图二:

图二说明如下:

5、对上述两个图的实战演示
1)首先,了解如下几个代码。
-- 1)设置客户端的字符集。 set character_set_client=gbk; -- 2)设置连接器的字符集。 set character_set_connection=utf8; -- 3)设置返回结果的字符集。 set character_set_results=gbk;
2)代码演示过程,详细地写在如下链接中的sql文件中,可以自行下载,查看。
http://note.youdao.com/noteshare?id=3fe60a490637d1a51ac78bf4a9e7e4d0&sub=511D73BDDEA34D9BAC565249035D74A8
6、产生乱码的两个原因
解码与实际编码,不一致导致的乱码,可修复。
在传输过程中,由于编码不一致,导致部分字节丢失,造成的乱码,不可修复。
1)编码和解码不一致导致的乱码

2)传输过程中,丢失字节导致的乱码。

7、对实际情况的分析(什么都不设置,系统默认是如何呢?)
1)仔细查看如下图片

根据上图可以知道(好好理解下面的文字说明):

图二:

2)set names gbk的含义
-- 当客户端、连接器、返回值的字符集相同,并且都是gbk的时候,我们可以采取如下的简写方式: set names gbk; -- 上述sql语句其实包含了如下三层意思: set character_set_client=gbk; set character_set_connection=gbk; set character_set_results=gbk;
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持
- Linux系统下修改mysql字符集为UTF8步骤
- MySQL中utf8mb4排序规则示例
- MySQL 编码utf8 与 utf8mb4 utf8mb4_unicode_ci 与 utf8mb4_general_ci
- 如何更改MySQL数据库的编码为utf8mb4
- MySQL字符集utf8修改为utf8mb4的方法步骤
- mysql 乱码字符 latin1 characters 转换为 UTF8详情
我们今天的关于php – 将latin1编码的文本插入utf8表(忘记使用mysql_set_charset)的分享就到这里,谢谢您的阅读,如果想了解更多关于Can''t initialize character set utf8 (path: /usr/share/mysql/charsets/)、Can''t initialize character set utf8mb4 (path: /usr/share/mysql/charsets/)、MySQL Charset--UTF8和UTF8MB4对比测试、mysql charset=utf8你真的弄明白意思了吗的相关信息,可以在本站进行搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

