在本文中,我们将给您介绍关于Intermediatelinearregression的详细内容,此外,我们还将为您提供关于.net–找不到字段:System.Text.RegularExpressio
在本文中,我们将给您介绍关于Intermediate linear regression的详细内容,此外,我们还将为您提供关于.net – 找不到字段:System.Text.RegularExpressions.Regex.internalMatchTimeout、17.贝叶斯线性回归(Bayesian Linear Regression)、c# regular expression validate currency, float or integer、Expression parameters.parseContent is undefined on line 45, column 28 in template/ajax/head.ftl. - C的知识。
本文目录一览:- Intermediate linear regression
- .net – 找不到字段:System.Text.RegularExpressions.Regex.internalMatchTimeout
- 17.贝叶斯线性回归(Bayesian Linear Regression)
- c# regular expression validate currency, float or integer
- Expression parameters.parseContent is undefined on line 45, column 28 in template/ajax/head.ftl. - C

Intermediate linear regression
1: Introduction To The Data
The Leaning Tower of Pisa is one of the largest tourist attractions in Italy. For hundreds of years this tower slowly leaned to one side, eventually reaching 5.5 degrees off axis, nearly 3 meters horizontal at it''s peak. Yearly data was recorded from 1975 to 1987 measuing the tower''s lean. In 1988 restoration began on the tower to stop more leaning in the future. The data is provided in the dataframe pisa. The column lean represents the number of meters the tower is off axis at the respective year. In this mission we will try to estimate the leaning rate using a linear regression and interpret its coefficient and statistics.

Instructions
- Create a scatter plot with
yearon the x-axis andleanon the y-axis.
import pandas
import matplotlib.pyplot as plt
%matplotlib inline
pisa = pandas.DataFrame({"year": range(1975, 1988),
"lean": [2.9642, 2.9644, 2.9656, 2.9667, 2.9673, 2.9688, 2.9696,
2.9698, 2.9713, 2.9717, 2.9725, 2.9742, 2.9757]})
print(pisa)
plt.scatter(pisa["year"],pisa["lean"])
plt.show()
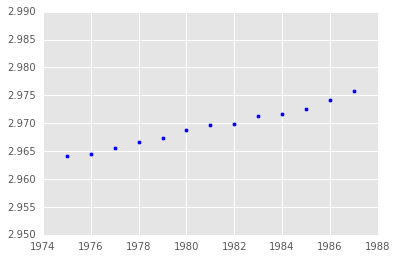
2: Fit The Linear Model
From the scatter plot you just made, we visually see that a linear regression looks to be a good fit for the data. We''ve used linear regression to predict wine quality and to analyze the stock market in previous missions, but in this mission we will learn how to understand key statistcal concepts of the model.
Statsmodels is a library which allows for rigorous statistical analysis in python. For linear models, statsmodels provides ample statistical measures for proper evaluation. The class sm.OLS is used to fit linear models, standing for oridinary least squares(最小二乘). After the initialization of our model we fit data to it using the .fit() method that estimates the coefficients of the linear model. OLS() does not automatically add an intercept to our model. We can add a column of 1''s to add another coefficient to our model and since the coefficient is multiplied by 1 we are given an intercept.
Instructions
linearfitcontains the fitted linear model to our data. Print the summary of the model by using the method.summary().- Don''t worry about understanding all of the summary, we will cover many of the statistics in the following screens.
import statsmodels.api as sm
y = pisa.lean # target
X = pisa.year # features
X = sm.add_constant(X) # add a column of 1''s as the constant term
# OLS -- Ordinary Least Squares Fit
linear = sm.OLS(y, X)
# fit model
linearfit = linear.fit()
linearfit.summary()
3: Define A Basic Linear Model
We see that the printed summary contains a lot of information about our model. To understand these statistical measures we must start with a formal definition of a basic linear regression model. Mathematically, a basic linear regression model is defined as ![]() is the error term for each observation ii where
is the error term for each observation ii where ![]() is the intercept and
is the intercept and ![]() is the slope. The residual for the prediction of observation ii is
is the slope. The residual for the prediction of observation ii is ![]() where
where ![]() is the prediction. As introduced previously,
is the prediction. As introduced previously, ![]() is a normal distribution with mean 0 and a variance
is a normal distribution with mean 0 and a variance ![]() . This means that the model assumes that the errors, known as residuals, between our prediction and observed values are normally distributed and that the average error is 0. Estimated coefficients, those which are modeled, will be refered to as
. This means that the model assumes that the errors, known as residuals, between our prediction and observed values are normally distributed and that the average error is 0. Estimated coefficients, those which are modeled, will be refered to as ![]() while
while ![]() is the true coefficient which we cannot calculated. In the end,
is the true coefficient which we cannot calculated. In the end, ![]() is the model we will estimate.
is the model we will estimate.
Instructions
- Using
linearfitwith dataXandypredict the residuals.- Residuals are computed by subtracting the observed values from the predicted values.
- Assign the residuals to variable
residuals.
# Our predicted values of y
yhat = linearfit.predict(X)
print(yhat)
residuals=yhat-y
4: Histogram Of Residuals
We''ve used histograms in the past to visualize the distribution of our data. By creating a histogram of our residuals we can visually accept or reject the assumption of normality of the errors. If the histogram of residuals look similar to a bell curve then we will accept the assumption of normality. There are more rigorous statistical tests to test for normality which we will cover in future lessons.
Instructions
- Create a histogram with 5 bins of the residuals using matplotlib''s
hist()function.- The
binsparameter allows us to specify the number of bins.
- The
# The variable residuals is in memory
import matplotlib.pyplot as plt
%matplotlib inline
plt.hist(residuals,bins=5)
plt.show()
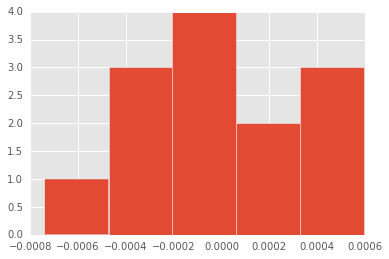
5: Interpretation Of Histogram
Our dataset only has 13 observations in it making it difficult to interpret such a plot. Though the plot looks somewhat normal the largest bin only has 4 observations. In this case we cannot reject the assumption that the residuals are normal. Lets move forward with this linear model and look at measures of statistical fit.
6: Sum Of Squares
Many of the statistical measures used to evaluate linear regression models rely on three sum of squares measures. The three measures include Sum of Square Error (SSE), Regression Sum of Squares (RSS), and Total Sum of Squares (TSS). In aggregate each of these measures explain the variance of the entire model. We define the measures as the following:
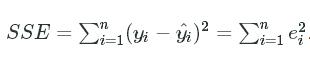 We see that SSE is the sum of all residuals giving us a measure between the model''s prediction and the observed values.
We see that SSE is the sum of all residuals giving us a measure between the model''s prediction and the observed values.
![]() . RSS measures the amount of explained variance which our model accounts for. For instance, if we were to predict every observation as the mean of the observed values then our model would be useless and RSS would be very low. A large RSS and small SSE can be an indicator of a strong model.
. RSS measures the amount of explained variance which our model accounts for. For instance, if we were to predict every observation as the mean of the observed values then our model would be useless and RSS would be very low. A large RSS and small SSE can be an indicator of a strong model.
![]() TSS measures the total amount of variation within the data.
TSS measures the total amount of variation within the data.
With some algebra we can show that ![]() . Intuitively this makes sense, the total amount of variance in the data is captured by the variance explained by the model plus the variance missed by the model.
. Intuitively this makes sense, the total amount of variance in the data is captured by the variance explained by the model plus the variance missed by the model.
Instructions
- Compute the RSS and TSS for our model,
linearfit, using the formulas above.- Assign the RSS to variable
RSSand the TSS to variableTSS.
- Assign the RSS to variable
import numpy as np
# sum the (predicted - observed) squared
SSE = np.sum((yhat-y.values)**2)
# Average y
ybar = np.mean(y.values)
# sum the (mean - predicted) squared
RSS = np.sum((ybar-yhat)**2)
# sum the (mean - observed) squared
TSS = np.sum((ybar-y.values)**2)
7: R-Squared
The coefficient of determination, also known as R-Squared, is a great measure of linear dependence. It is a single number which tells us what the percentage of variation in the target variable is explained by our model.
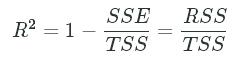
Intuitively we know that a low SSE and high RSS indicates a good fit. This single measure tells us what percentage of the total variation of the data our model is accounting for. Correspondingly, the ![]() exists between 0 and 1.
exists between 0 and 1.
Instructions
- Compute the R-Squared for our model,
linearfit. Assign the R-squared to variableR2.
SSE = np.sum((yhat-y.values)**2)
ybar = np.mean(y.values)
RSS = np.sum((ybar-yhat)**2)
TSS = np.sum((ybar-y.values)**2)
R2=1-SSE/TSS
8: Interpretation Of R-Squared
We see that the R-Squared value is very high for our linear model, 0.988, accounting for 98.8% of the variation within the data.
9: Coefficients Of The Linear Model
The ability to understand and interpret coefficients is a huge advantage of linear models over some more complex ones. Each ![]() in a linear model
in a linear model ![]() is a coefficient. Fortunately there are methods to find the confidence of the estimated coefficients.
is a coefficient. Fortunately there are methods to find the confidence of the estimated coefficients.
Below we see the summary of our model. There are many statistics here including R-squared, the number of observations, and others. In the second section there are coefficients with corresponding statistics. The row year corresponds to the independent variable x whilelean is the target variable. The variable const represents the model''s intercept.
First we look at the coefficient itself. The coefficient measures how much the dependent variable will change with a unit increase in the independent variable. For instance, we see that the coefficient for year is 0.0009. This means that on average the tower of pisa will lean 0.0009 meters per year.
Instructions
- Assuming no external forces on the tower, how many meters will the tower of pisa lean in
15years?- Assign the number of meters moved to variable
delta.
- Assign the number of meters moved to variable
# Print the models summary
#print(linearfit.summary())
#The models parameters
print("\n",linearfit.params)
delta = linearfit.params["year"] * 15
print(delta)
10: Variance Of Coefficients
The variance of each of the coefficients is an important and powerful measure. In our example the coefficient of year represents the number of meters the tower will lean each year. The variance of this coefficient would then give us an interval of the expected movement for each year.
In the summary output, next to each coefficient, you see a column with standard errors. The standard error is the square root of the estimated variance. The estimated variance for a single variable linear model is defined as: .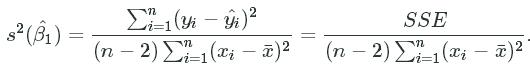
This formulation can be shown by taking the variance of our estimated ![]() but we will not cover that here. Analyzing the formula term by term we see that the numerator, SSE, represents the error within the model. A small error in the model will then decrease the coefficient''s variance. The denominator term,
but we will not cover that here. Analyzing the formula term by term we see that the numerator, SSE, represents the error within the model. A small error in the model will then decrease the coefficient''s variance. The denominator term, ![]() , measures the amount of variance within x. A large variance within the independent variable decreases the coefficient''s variance. The entire value is divided by (n-2) to normalize over the SSE terms while accounting for 2 degrees of freedom in the model.
, measures the amount of variance within x. A large variance within the independent variable decreases the coefficient''s variance. The entire value is divided by (n-2) to normalize over the SSE terms while accounting for 2 degrees of freedom in the model.
Using this variance we will be able to compute t-statistics and confidence intervals regarding this ![]() . We will get to these in the following screens.
. We will get to these in the following screens.
Instructions
- Compute
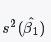 for
for linearfit.- Assign this variance to variable
s2b1.
- Assign this variance to variable
# Enter your code here.
s2b1=SSE/((len(y.values)-2)*sum((pisa.year-np.mean(pisa.year))**2))
11: T-Distribution
Statistical tests can be done to show that the lean of the tower is dependent on the year. A common test of statistical signficance is the student t-test. The student t-test relies on the t-distribution, which is very similar to the normal distribution, following the bell curve but with a lower peak.
The t-distribution accounts for the number of observations in our sample set while the normal distribution assumes we have the entire population. In general, the smaller the sample we have the less confidence we have in our estimates. The t-distribution takes this into account by increasing the variance relative to the number of observations. You will see that as the number of observations increases the t-distribution approaches the normal distributions.
The density functions of the t-distributions are used in signficance testing. The probability density function (pdf) models the relative likelihood of a continous random variable. The cumulative density function (cdf) models the probability of a random variable being less than or equal to a point. The degrees of freedom (df) accounts for the number of observations in the sample. In general the degrees of freedom will be equal to the number of observations minus 2. Say we had a sample size with just 2 observations, we could fit a line through them perfectly and no error in the model. To account for this we subtract 2 from the number of observations to compute the degrees of freedom.
Scipy has a functions in the library scipy.stats.t which can be used to compute the pdf and cdf of the t-distribution for any number of degrees of freedom. scipy.stats.t.pdf(x,df) is used to estimate the pdf at variable x with df degrees of freedom.
Instructions
This step is a demo. Play around with code or advance to the next step.
from scipy.stats import t
# 100 values between -3 and 3
x = np.linspace(-3,3,100)
# Compute the pdf with 3 degrees of freedom
print(t.pdf(x=x, df=3))
12: Statistical Significance Of Coefficients
Now that we know what the t-distribution is we can use it for significance testing. To do significance testing we must first start by stating our hypothesis. We want to test whether the lean of the tower depends on the year, ie. every year the tower leans a certain amount. This is done by setting null and alternative hypotheses. In our case we will say the null hypothesis is that the lean of the tower of pisa does not depend on the year, meaning the coefficient will be equal to zero. The alternative hypothesis would then follow as the lean of the tower depend on the year, the coefficient is not equal to zero. These are written mathematically as,
![]()
Testing the null hypothesis is done by using the t-distribution. The t-statistic is defined as,
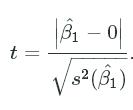
This statistic measures how many standard deviations the expected coefficient is from 0. If β1β1 is far from zero with a low variance then t will be very high. We see from the pdf, a t-statistic far from zero will have a very low probability.
Instructions
- Using the formula above, compute the t-statistic of
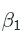 .
.
- Assign the t-statistic to variable
tstat.
- Assign the t-statistic to variable
tstat=linearfit.params["year"]/np.sqrt(s2b1)
13: The P-Value
Finally, now that we''ve computed the t-statistic we can test our coefficient. Testing the coefficient is easy, we need to find the probability of ![]() being different than 0 at some significance level. Lets use the 95% significance level, meaning that we are 95% certian that
being different than 0 at some significance level. Lets use the 95% significance level, meaning that we are 95% certian that ![]() differs from zero. This is done by using the t-distribution. By computing the cumulative density at the given p-value and degrees of freedom we can retrieve a corresponding probability.
differs from zero. This is done by using the t-distribution. By computing the cumulative density at the given p-value and degrees of freedom we can retrieve a corresponding probability.
A two-sided test, one which test whether a coefficient is either less than 0 and greater than 0, should be used for linear regression coefficients. For example, the number of meters per year which the tower leans could be either positive or negative and we must check both. To test whether ![]() is either positive or negative at the 95% confidence interval we look at the 2.5 and 97.5 percentiles in the distribution, leaving a 95% confidence between the two. Since the t-distribution is symmetrical around zero we can take the absolute value and test only at the 97.5 percentile (the positive side).
is either positive or negative at the 95% confidence interval we look at the 2.5 and 97.5 percentiles in the distribution, leaving a 95% confidence between the two. Since the t-distribution is symmetrical around zero we can take the absolute value and test only at the 97.5 percentile (the positive side).
If probability is greater than 0.975 than we can reject the null hypothesis (H0H0) and say that the year significantly affects the lean of the tower.
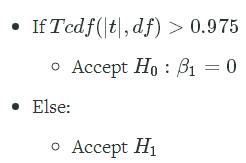
Instructions
- Do we accept
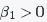 ?
?
- Assign the boolean value, True or False, to variable
beta1_test.
- Assign the boolean value, True or False, to variable
# At the 95% confidence interval for a two-sided t-test we must use a p-value of 0.975
pval = 0.975
# Thae degrees of freedom
df = pisa.shape[0] - 2
# The probability to test against
p = t.cdf(tstat, df=df)
beta1_test=p>pval
14: Conclusion
Here we learned how to compute and interpret statistics often used to measure linear models. We introduce t-statistics which are used in many field and applications. The assumption of normality is very important in rigorous statistical analysis. This assumption allows each of these statistical tests to be valid. If the assumption is rejected than a different model may be in order.
R-squared is a very powerful measure but it is often over used. A low R-squared value does not necessarily mean that there is no dependency between the variables. For instance, if the r-square would equal 0 but there is certianly a relationship. A high r-squared value does not necessarily mean that the model is good a predicting future events because it does not account for the number of observations seen.
Student t-tests are great for multivariable regressions where we have many features. The test can allow us to remove certian variables which do not help the model signficantly and keep those which do.
In practice be sure to use the statistics that are most important to your given application and not use ones that could give unreliable results. Following lessons will include statistics such as AIC, BIC, and F-statistic on multivariate linear models.

.net – 找不到字段:System.Text.RegularExpressions.Regex.internalMatchTimeout
简而言之:我尝试在已更新为.Net 4.5的计算机上构建.Net 4.0程序集.所以我的目标是.Net 4.0.当试图在只安装了.Net 4.0的机器上运行此程序集时,我得到以下异常:找不到字段:’System.Text.RegularExpressions.Regex.internalMatchTimeout’.
如果我在尚未更新到.Net 4.5的机器上构建相同的程序集,我可以在.Net 4.0机器上运行生成的程序集而不会出现任何问题.换句话说:.Net 4.5计算机上生成的.Net 4.0程序集与.Net 4.0计算机上生成的程序集不同.
程序集提供预编译的正则表达式.
我可以通过以下两种方式解决
>在.Net 4.0系统上构建装配.
>将目标计算机升级到.Net 4.5.
但是,这两种解决方案都存在问题:
>我们为各种目标构建程序集,包括WinRT.我们现在面临的问题是,我们不能使用单个机器来构建所有这些,这使我们的构建/测试过程变得复杂.
>生产的组件被运送给客户.如果我们告诉他们升级到.Net 4.5,为了使用4.0程序集,他们不会都很高兴.
除了摆脱预编译的正则表达式之外,你们中的任何人都知道一个更好的解决方案吗?
解决方法
")
17.贝叶斯线性回归(Bayesian Linear Regression)
本文顺序
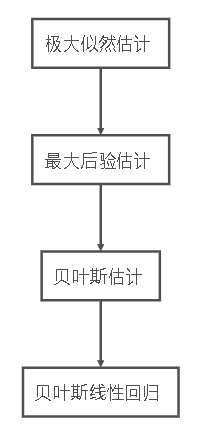
一、回忆线性回归
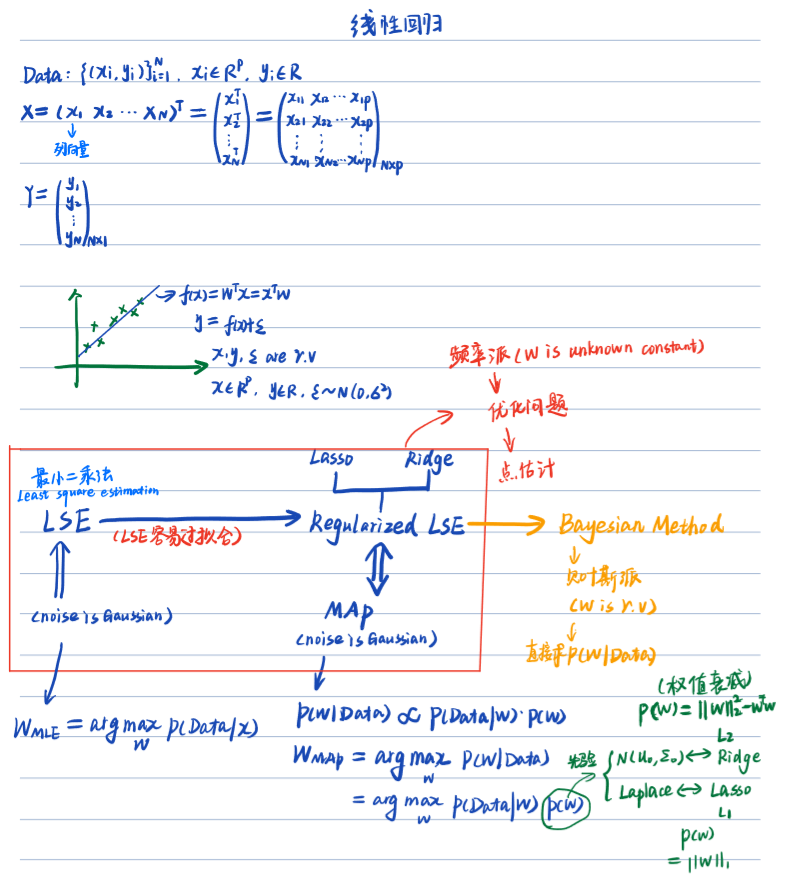
线性回归用最小二乘法,转换为极大似然估计求解参数W,但这很容易导致过拟合,由此引入了带正则化的最小二乘法(可证明等价于最大后验概率)
二、什么是贝叶斯回归?
基于上面的讨论,这里就可以引出本文的核心内容:贝叶斯线性回归。
贝叶斯线性回归不仅可以解决极大似然估计中存在的过拟合的问题。
- 它对数据样本的利用率是100%,仅仅使用训练样本就可以有效而准确的确定模型的复杂度。
- 在极大似然估计线性回归中我们把参数看成是一个未知的固定值,而贝叶斯学派则把看成是一个随机变量。
贝叶斯回归主要研究两个问题:inference(求后验)和prediction

下面结合图来说明贝叶斯线性回归的过程.


三、贝叶斯回归的inference问题


四、贝叶斯回归的prediction问题
根据inference求得的后验求prediction

五、总结

贝叶斯回归的优缺点
优点:
1. 贝叶斯回归对数据有自适应能力,可以重复的利用实验数据,并防止过拟合
2. 贝叶斯回归可以在估计过程中引入正则项
缺点:
1. 贝叶斯回归的学习过程开销太大
参考文献:
【1】【机器学习】贝叶斯线性回归(最大后验估计+高斯先验)

c# regular expression validate currency, float or integer
美元金额正则表达式
Currency:
^\$?([1-9]{1}[0-9]{0,2}(\,[0-9]{3})*(\.[0-9]{0,2})?|[1-9]{1}[0-9]{0,}(\.[0-9]{0,2})?|0(\.[0-9]{0,2})?|(\.[0-9]{1,2})?)$
C# codes:
float num;
bool isValid = float.TryParse(str,NumberStyles.Currency, CultureInfo.GetCultureInfo("en-US"),out num);
http://www.regexlib.com/DisplayPatterns.aspx?cattabindex=2&categoryId=3
Expression parameters.parseContent is undefined on line 45, column 28 in template/ajax/head.ftl. - C
在struts-2.2.3.1中加入<s:head theme="ajax"/>这个标签,报错Expression parameters.parseContent is undefined on line 45,column 28 in template/ajax/head.ftl. - Class: freemarker.core.TemplateObject File: TemplateObject.java出错,后网上一查原因为出现此问题的原因:在jsp页面用到了struts提供的ajax主题,但是声明主题时出现问题,struts2.0到struts2.1有一个重要的改变就是对ajax支持的改变,struts2.0的ajax支持主要以DWR和dojo为主,并专门提供ajax主题,如:<s:head theme="ajax"/>,但是在struts2.1不在提供ajax主题,而将原来的ajax主题放入了dojo插件中,我们需要将dojo标签引入到jsp页面, 在改为<%@ taglib uri="/struts-tags" prefix="s" %><%@ taglib uri="/struts-dojo-tags" prefix="sd" %>后又出现异常Attribute theme invalid for tag head according to TLD
经过一下午的网上查询,终于找到答案了,至于异常原因也没明说,又将上面
页面上<sd:head theme="ajax" />改成下面这两行,其他的不用改:
<s:head theme="xhtml"/>
<sd:head parseContent="true"/>问题解决了。希望遇到同样问题的朋友对你有所帮助
我们今天的关于Intermediate linear regression的分享已经告一段落,感谢您的关注,如果您想了解更多关于.net – 找不到字段:System.Text.RegularExpressions.Regex.internalMatchTimeout、17.贝叶斯线性回归(Bayesian Linear Regression)、c# regular expression validate currency, float or integer、Expression parameters.parseContent is undefined on line 45, column 28 in template/ajax/head.ftl. - C的相关信息,请在本站查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

