本篇文章给大家谈谈kafka生产者性能监控:MonitorKafkaProducerforPerformance,以及kafkaexporter能监控哪些指标的知识点,同时本文还将给你拓展apache
本篇文章给大家谈谈kafka 生产者性能监控:Monitor Kafka Producer for Performance,以及kafka exporter能监控哪些指标的知识点,同时本文还将给你拓展apache kafka监控系列-KafkaOffsetMonitor、Apache Kafka(五)- Safe Kafka Producer、Kafka 0.11.0 Java API 中文翻译—— KafkaProducer、Kafka Manager| KafkaMonitor等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- kafka 生产者性能监控:Monitor Kafka Producer for Performance(kafka exporter能监控哪些指标)
- apache kafka监控系列-KafkaOffsetMonitor
- Apache Kafka(五)- Safe Kafka Producer
- Kafka 0.11.0 Java API 中文翻译—— KafkaProducer
- Kafka Manager| KafkaMonitor
")
kafka 生产者性能监控:Monitor Kafka Producer for Performance(kafka exporter能监控哪些指标)
Introduction
The producer sends data directly to the broker that is the leader for the partition without any intervening routing tier.
Optimization Approach
Batching is one of the big drivers of efficiency, and to enable batching the Kafka producer will attempt to accumulate data in memory and to send out larger batches in a single request. The batching can be configured to accumulate no more than a fixed number of messages and to wait no longer than some fixed latency bound (say 64k or 10 ms). This allows the accumulation of more bytes to send, and few larger I/O operations on the servers. This buffering is configurable and gives a mechanism to trade off a small amount of additional latency for better throughput.
In order to find the optimal batch size and latency, iterative test supported by producer statistics monitoring is needed.
Enable Monitoring
Start the producer with the JMX parameters enabled:
JMX_PORT=10102 bin/kafka-console-producer.sh --broker-list localhost:9092--topic testtopic
Producer Metrics
Use jconsole application via JMX at port number 10102.
Tip: run jconsole application remotely to avoid impact on broker machine.
See metrics in MBeans tab.

The<strong>clientId</strong>parameter is the producer client ID for which you want the statistics.
<strong>kafka.producer:type=ProducerRequestMetrics,name=ProducerRequestRateAndTimeMs,clientId=console-producer</strong>
This MBean give values for the rate of producer requests taking place as well as latencies involved in that process. It gives latencies as a mean, the 50th, 75th, 95th, 98th, 99th, and 99.9thlatency percentiles. It also gives the time taken to produce the data as a mean, one minute average, five minute average, and fifteen minute average. It gives the count as well.
<strong>kafka.producer:type=ProducerRequestMetrics,name=ProducerRequestSize,clientId=console-producer</strong>
This MBean gives the request size for the producer. It gives the count, mean, max, min, standard deviation, and the 50th, 75th, 95th, 98th, 99th, and 99.9thpercentile of request sizes.
<strong>kafka.producer:type=ProducerStats,name=FailedSendsPerSec,clientId=console-producer</strong>
This gives the number of failed sends per second. It gives this value of counts, the mean rate, one minute average, five minute average, and fifteen minute average value for the failed requests per second.
<strong>kafka.producer:type=ProducerStats,name=SerializationErrorsPerSec,clientId=console-producer</strong>
This gives the number of serialization errors per second. It gives this value of counts, mean rate, one minute average, five minute average, and fifteen minute average value for the serialization errors per second.
<strong>kafka.producer:type=ProducerTopicMetrics,name=MessagesPerSec,clientId=console-producer</strong>
This gives the number of messages produced per second. It gives this value of counts, mean rate, one-minute average, five-minute average, and fifteen-minute average for the messages produced per second.
References
- https://kafka.apache.org/documentation.html#monitoring

apache kafka监控系列-KafkaOffsetMonitor
概览
最近kafka server消息服务上线了,基于jmx指标参数也写到zabbix中了,但总觉得缺少点什么东西,可视化可操作的界面。zabbix中数据比较分散,不能集中看整个集群情况。或者一个cluster中broker列表,自己写web-console比较耗时耗力,用原型工具画了一些管理界面东西,关键自己也不前端方面技术,这方面比较薄弱。这不开源社区提供了kafka的web管理平台KafkaOffsetMonitor.就迅速拿过来运行。大家不要着急,马上娓娓道来。
说明:
这个应用程序来实时监控你kafka服务的consumer以及他们在partition中的offset(偏移)。
你可以浏览当前的消费者组,每个topic的所有partition的消费情况都可以一览无余。这其实是很有用得,从这里你很快知道每个partition的message是否很快被消费(没有阻塞)。他能指导你(kafka producer和consumer)优化代码。
这个web管理平台保留的partition offset和consumer滞后的历史数据,所以你可以很轻易了解这几天consumer消费情况。
KafkaOffsetMonitor功能:
1.从标题都可以看出来,Kafka Offset Monitor,是对consumer消费情况进行监控,并能列出每个consumer offset,滞后数据。
2.消费者组列表
3.每个topic的所有parition列表(topic,pid,offset,logSize,lag,owner)
4.查看topic的历史消费信息.
虽然功能覆盖面不全,但是很实用。
1.下载
github官网下载
KafkaOffsetMonitor
百度云下载(网速快)
百度云KafkaOffsetMonitor下载
说明:百度云下载为修改版本,因为KafkaOffsetMonitor中有些资源文件(css,js)是访问外网的,特别是有访问google资源,大家都懂的,经常不能访问。建议下载修改版
2.安装
KafkaOffsetMonitor运行比较简单,因为所有运行文件,资源文件,jar文件都打包到KafkaOffsetMonitor-assembly-0.2.0.jar了,直接运行就可以,这种方式太棒了。既不用编译也不用配置,呵呵,也不是绝对不配置。
a.新建一个目录kafka-offset-console,然后把jar拷贝到该目录下.
b.新建脚本,因为您可能不是一个kafka集群。用脚本可以启动多个
lizhitao@users-MacBook-Pro: vim mobile_start_en.sh
#!/bin/bash
java -Xms512M -Xmx512M -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -cp KafkaOffsetMonitor-assembly-0.2.0.jar \
com.quantifind.kafka.offsetapp.OffsetGetterWeb \
--zk 192.168.2.101:2181,192.168.2.102:2182,192.168.2.103:2181/config/mobile/xxx \
--port 8086 \
--refresh 10.seconds \
--retain 7.days 1>mobile-logs/stdout.log 2>mobile-logs/stderr.log &
注意:/config/mobile/xxx 表示zk的根目录,需要手工创建,也可以不设置
3.运行
lizhitao@users-MacBook-Pro: chmod +x mobile_start_en.sh
lizhitao@users-MacBook-Pro: ./mobile_start_en.sh
serving resources from: jar:file:/opt/xxx/kafka-offset-console/KafkaOffsetMonitor-assembly-0.2.0.jar!/offsetapp
6 演示截图:
消费者组列表

topic的所有partiton消费情况列表

以上图中参数含义解释如下:
topic:创建时topic名称
partition:分区编号
offset:表示该parition已经消费了多少条message
logSize:表示该partition已经写了多少条message
Lag:表示有多少条message没有被消费。
Owner:表示消费者
Created:该partition创建时间
Last Seen:消费状态刷新最新时间。
kafka正在运行的topic
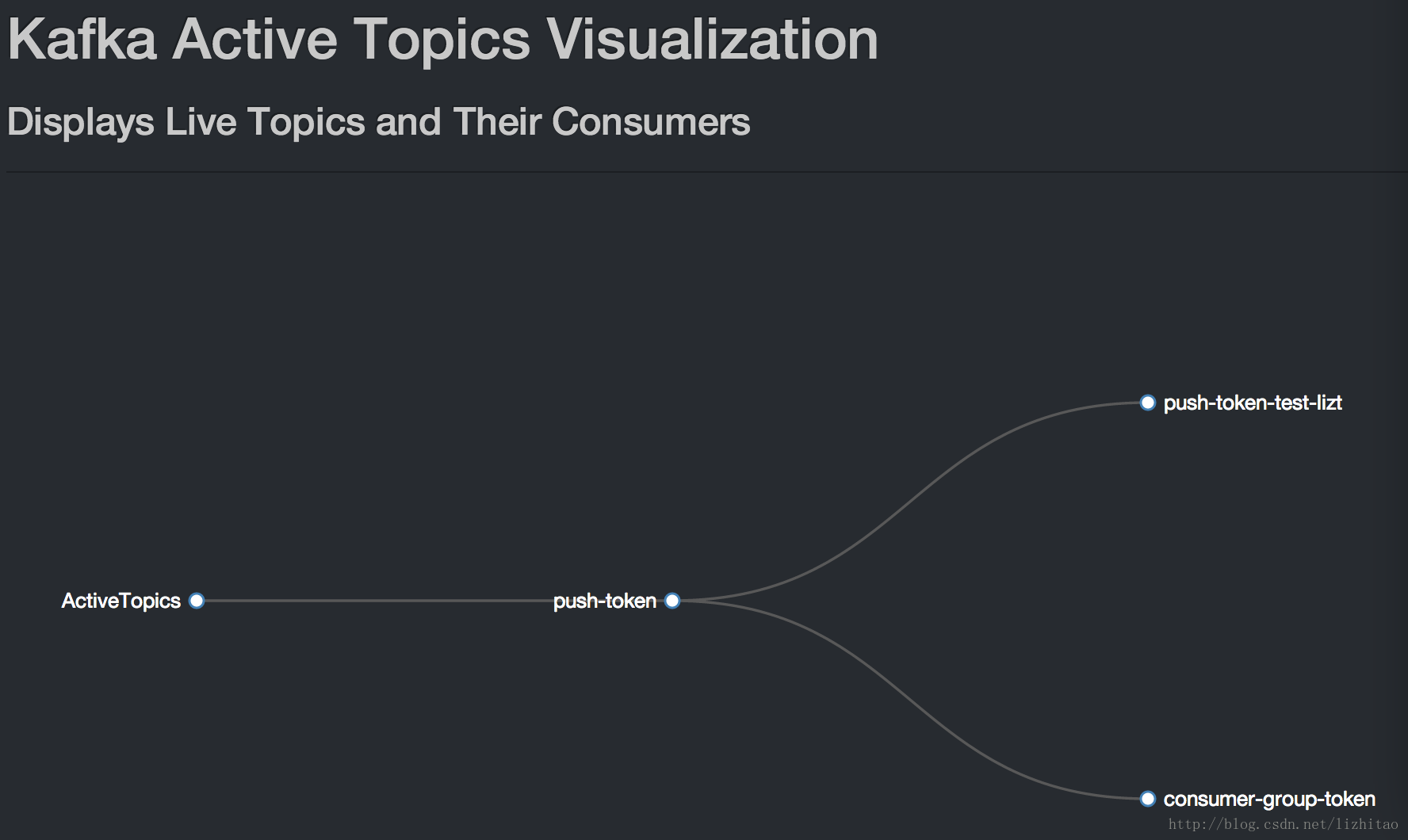
kafka集群中topic列表
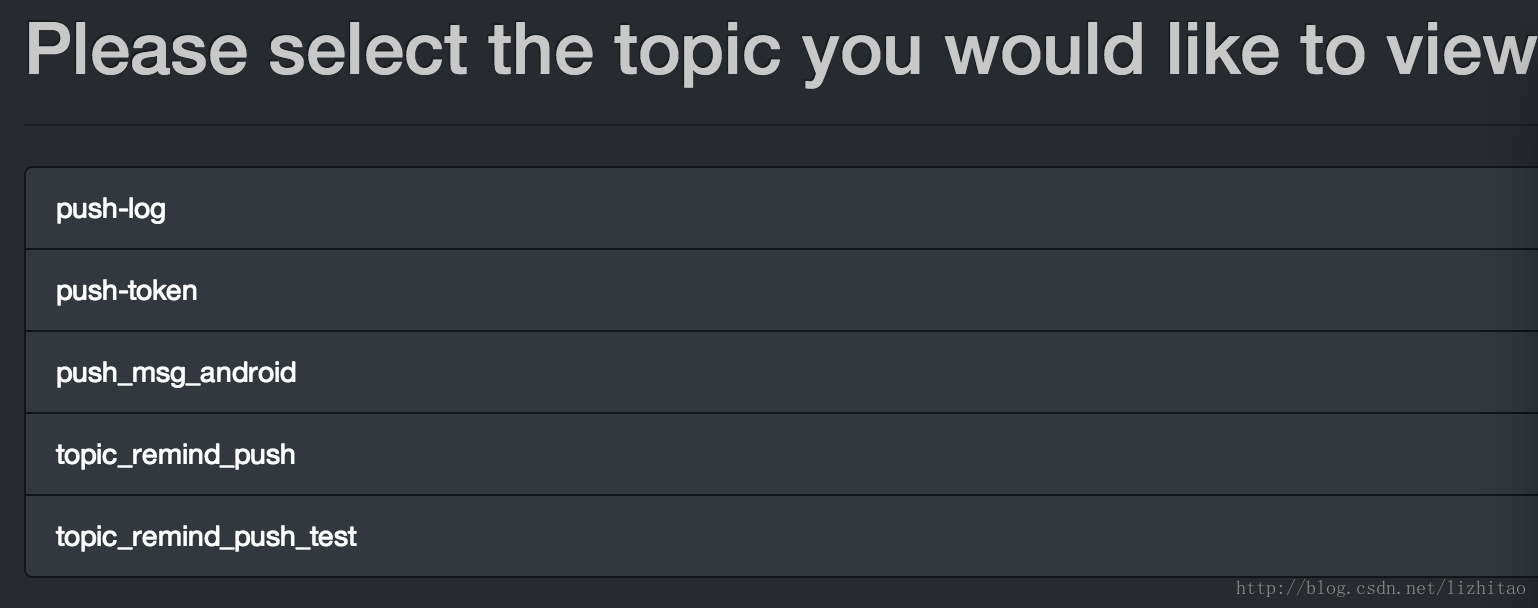
kafka集群中broker列表

请注明转载自:http://blog.csdn.net/lizhitao/article/details/27199863
- Safe Kafka Producer")
Apache Kafka(五)- Safe Kafka Producer
Kafka Safe Producer
在应用Kafka的场景中,需要考虑到在异常发生时(如网络异常),被发送的消息有可能会出现丢失、乱序、以及重复消息。
对于这些情况,我们可以创建一个“safe producer”,用于规避这些问题。下面我们会先介绍对于这几种情况的说明以及配置,最后给出一个配置示例。
1. acks 详述
之前我们介绍过 Kafka Producer 的 acks 有三种模式,下面我们进一步介绍一下这三种模式:
1.1. acks = 0(no acks)
使用acks=0 时,也就意味着:
- 在发送一条message 后,不需要response
- 如果broker 下线或是发生了故障,则我们不会知道,并且会丢失数据,因为broker不会返回任何response 给producers
acks=0 的工作方式如下图,不需要收到任何 ack:

一般使用 acks=0 的场景为:可以接受可能丢失数据。例如:
- 指标信息收集
- 日志收集(可接受偶尔丢失几条log数据)
1.2. acks=1(leader acks)
使用acks=1 时:
- producer需要获取leader 的response,才能确认消息已被收到。但是replication是否收到则不会保证(会在后台执行replication)
- 如果producer 没有收到ack,则可能会retry
acks=1 的工作方式如下图,Producer需要收到每条消息的ack:

- 如果leader broker下线或是发生故障,但是replicas还没有复制发送的数据,则我们也会有数据丢失
- 默认是这个模式
1.3. acks=all(replicas acks)
使用acks=all 时:
- 需要Leader与Replicas的ack
- 增加了latency与更高的“数据不丢失”安全性
- 如果有足够的replicas,则不会有数据丢失
acks=all的一个工作方式如下,每个replica都需要回复ack,才能保证一个write的写入:
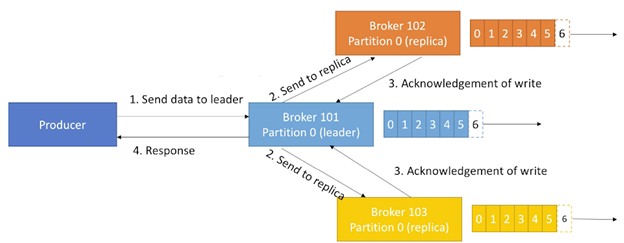
如果是需要完全不丢失数据,则这个设置是有必要考虑的。
在设置 acks=all(也就是replica acks)时,必须与另一个参数一起用,也就是:min.insync.replicas:
- min.insync.replicas参数可以在broker level设置或是topic level设置(override)
- min.insync.replicas=2表示的是:至少2个brokers是ISR(in-sync replicas)(包括leader),且必须响应表示它们有数据,否则就会返回报错。设置此参数为2也是最常见的配置。
假设设置参数replication.factor=3, min.insync=2, acks=all,则最多只能容许1一个broker异常,否则producer在发送数据时会收到报错。
假设有3个brokers,min.insync.replicas=2,若其中有两个broker异常,则Producer会收到“NOT_ENOUGH_REPLICAS”的异常。
2. Producer Retry
为了防止一些瞬时的错误(例如NotEnoughReplicasException)影响整个应用,一般我们需要处理一些异常,以避免数据丢失。在Producer中也有重试的配置,默认为0,可以手动调整它的值,最高可以到Integer.MAX_VALUE。
在重试时,默认情况下,会有可能造成消息发送时乱序。因为一般发送失败的消息会被re-queue,然后再次发送,所以会造成部分消息乱序。
此情况在key-based 序列消息中,尤为严重。因为所有具有相同key的messages会被送往同一个partition,而若是有消息被requeue,然后重传,则会打乱这个partition中的部分key顺序。
对于这种情况,我们可以设置参数max.in.flight.requests.per.connection控制:同一时刻,有多少个produce请求可以被并行发起:
- 默认为5
- 如果为了完全确保重试后的消息也能保持严格有序,则可以设置此参数为1(但是可能会影响throughput)
不过在 Kafka >= 1.0.0中,对于此场景会有更好的解决方案,本文之后的部分会提及。
3. Idempotent Producer
在重传场景中,会遇到一个常见的问题是:由于网络的原因,Producer会在Kafka中引入重复的messages。
如下图所示:

一个正常的request请求为:
- Producer 发送消息到Kafka
- Kafka commit 这条消息
- Kafka发送ack回Producer
但是一个产生重复消息的请求过程为:
- Producer发送消息到Kafka
- Kafka commit 这条消息
- Kafka发送ack回Producer时,由于网络原因,ack未到达Producer端
- Producer过一段时间后开始重传消息
- Kafka commit这条重复的消息并返回ack给Producer
从Producer的角度看,它仅正常发送了一次消息,因为它只收到了一次 ack。从Kafka的角度看,它收到了两次消息,所以commit了两次。
在Kafka >= 0.11之后,可以定义一个“idempotent producer”,可以解决由网络问题造成的重复消息。如下图所示:
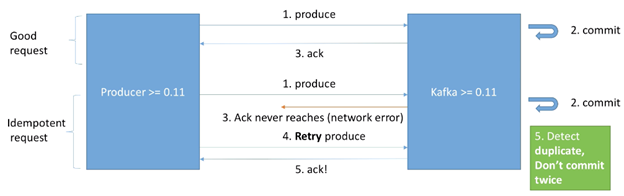
对于一个idempotent producer 来说,处理重复消息的请求过程为:
- Producer 发送一条消息
- Kafka收到消息并commit
- Kafka发送回Producer的ack由于网络问题未到达Producer
- Producer重试发送消息,在Producer>=0.11 的版本中,消息里会带上一个produce request id
- Kafka收到消息后,通过对比produce request id,可以辨别出这条消息是一条重复的消息,所以不会再次commit,并会再次发送一个ack
Idempotent producers可以很好的保证一个稳定,以及无重复数据的pipeline。
伴随Idempotent producers一起被设置的参数有:
- retries = Integer.MAX_VALUE (2^31-1 = 2147483647),也就是说基本会在出错时无限重传
- max.in.flight.requests=1 (Kafka >= 0.11 & < 1.1) ,也就是说在这些版本中,若是设置max.in.flight.requests > 1时仍会有可能产生乱序数据
- 或者 max.in.flight.requests=5 (Kafka >= 1.1 –> High Performance),也就是说在高于1.1版本的Kafka中,设置max.in.flight.requests=5也可以在保证不乱序的同时,保证并行的高性能
对于Idempotent Producer的配置,仅需配置类似以下参数即可:
properties.setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
4. Safe Producer 配置总结
上面介绍了创建一个safe producer 所需的配置,下面我们总结一下在不同版本的Kafka中所需要做的配置:
Kafka < 0.11
- ack=all (procuder level):确保在发送ack前,数据已经正常备份
- min.insync.replicas=2 (broker/topic level):确保至少有两个in ISR 的brokers 有数据后再回送ack
- retires=MAX_INT (producer level):确保在发生瞬时问题时,可以无限次重试
- max.in.flight.requests.per.connection=1 (producer level):确保每次仅有一个请求发送,防止在重试时产生乱序数据
Kafka >= 0.11
- enable.idempotence=true (producer level) + min.insync.replicas=2 (broker/topic level)
- 隐含的配置为 acks=all, retries=MAX_INT, max.in.flight.requests.per.connection=5 (default)
- 可以在保证消息顺序的同时,提高performance
这里必须要提到的是:运行一个“safe producer”可能会影响系统的throughput与latency,所以在应用到生产系统前,必须先做测试以判断影响。
5. safe producer 示例
我们按照之前的步骤启动一个由Java编写的Kafka Producer,并查看输出的配置,可以看到默认的部分参数为:
acks = 1
enable.idempotence = false
max.in.flight.requests.per.connection = 5
retries = 2147483647
现在我们显式地加上以下参数:
// create a safe Producer
properties.setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
properties.setProperty(ProducerConfig.ACKS_CONFIG, "all");
properties.setProperty(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, "5");
properties.setProperty(ProducerConfig.RETRIES_CONFIG, Integer.toString(Integer.MAX_VALUE));
然后查看producer配置的部分输出为:
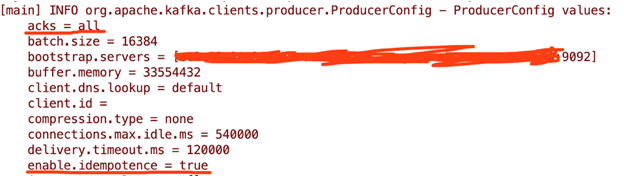

以上为创建一个safe producer所需的配置介绍以及示例,在实际生产环境中,务必要先测试safe producer 对应用吞吐以及延时的影响后,再斟酌是否有必要对参数做部分调整。

Kafka 0.11.0 Java API 中文翻译—— KafkaProducer
首先推荐一个关于Kafka的中文网站:http://orchome.com/kafka/index
部分翻译直接参考此网站内容,但是网站目前的API版本为0.10.0.1,所以在学习过程中,自行翻译了一下0.11.0的API文档。在翻译过程中有些地方也不是太理解,感觉翻译的不太准确,有问题的地方望读者指出。
原文地址:http://kafka.apache.org/0110/javadoc/index.html? org/apache/kafka/clients/producer/KafkaProducer.html
public class KafkaProducer<K,V>
extends Object
implements Producer<K,V>Kafka客户端发布消息至kafka集群。
生产者是线程安全的,在线程之间共享单个生产者实例通常比持有多个实例更快。
下面是一个简单的例子,它使用生产者将包含有序数字的字符串消息作为键/值对发送。
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i),
Integer.toString(i)));
producer.close(); 生产者的缓冲空间池保留尚未发送到服务器的消息,后台I/O线程负责将这些消息转换成请求发送到集群。如果使用后不关闭生产者,则会泄露这些资源。
send()方法是异步的,添加消息到缓冲区等待发送,并立即返回。这允许生产者将单个的消息批量在一起发送来提高效率。
ack是判别请求是否为完整的条件。我们指定了“all”将会阻塞消息,这种设置使性能最低,但是是最可靠的。
retries,如果请求失败,生产者会自动重试,我们指定是0次即不启动重试,如果启用重试,则会有重复消息的可能性。
batch.size ,producer为每个分区未发送的消息保持一个缓冲区。缓存的大小是通过 batch.size 配置指定的。值较大的话将会产生更大的批处理。并需要更多的内存(因为通常我们会为每个“活跃”的分区都设置1个缓冲区)。
linger.ms默认情况,即便缓冲空间还没有满,缓冲也可立即发送,但是,如果想减少请求的数量,可以设置linger.ms大于0。这将指示生产者发送请求之前等待一段时间,希望更多的消息填补到未满的批中。这类似于TCP的算法,例如上面的代码段,可能100条消息在一个请求发送,因为我们设置了linger(逗留)时间为1毫秒,然后,如果我们没有填满缓冲区,这个设置将增加1毫秒的延迟请求以等待更多的消息。需要注意的是,在高负载下,即使是 linger.ms=0,相近的时间一般也会组成批。在不处于高负载的情况下,如果设置比0大,将以少量的延迟代价换取更少的,更有效的请求。
buffer.memory 控制生产者可用的缓存总量,如果消息发送速度比它们能够传输到服务器的速度快,将会耗尽这个缓存空间。当缓存空间耗尽,其他发送调用将被阻塞,阻塞时间的阈值通过max.block.ms设定,之后它将抛出一个TimeoutException。
key.serializer和value.serializer示例,将用户提供的key和value对象ProducerRecord转换成字节,你可以使用附带的ByteArraySerializaer或StringSerializer处理简单的string或byte类型。
从kafka 0.11开始,KafkaProducer 支持两种额外的模式:idempotent producer和transactional producer。
idempotent producer(幂等性生产者)增强Kafka的投递语义,从至少一次投递变为完全的一次投递,特别是消息重试将不再重复提出。
transactional producer(事务性生产者)允许应用程序将消息发送给多个原子分区(和topics)。
使用idempotent,enable.idempotence配置项必须设置为true,如果设置为true,重试配置项(retries )将默认设置为 Integer.MAX_VALUE,max.inflight.requests.per.connection 将默认设置为 1,asks config(确认配置)将默认设置为all 。idempotent producer的API并没有改变,所以现有的应用程序应用此特性时不需要做修改。
为了充分利用idempotent producer,必须避免应用级别的重试发送,因为这样不能de-duplicated(去耦合/去重复:此处不是太理解,不知道如何翻译)。因此,如果应用程序启用了idempotence,建议取消retries (重试)配置,因为它将被默认为Integer.MAX_VALUE。此外,如果send(ProducerRecord)即使有无限重试还是返回了一个错误(例如,如果消息在发送之前在缓冲区中过期),则建议关闭producer 并检查最后生成的消息的内容,以确保它不是重复的。最后,producer 只能保证在单个会话中发送消息的idempotent 特性。
使用transactional producer和与它相关的API,则必须设置transactional.id配置属性,如果transactional.id被设置,idempotence 会随着其所依赖的producer的配置被自动启用,此外,transactions 中包含的topics应该配置为持久性的。特别是,replication.factor(复制因子)至少应该为3,这些topics的 min.insync.replicas应该设为2。最后,为了保证transactional 端到端的实现,consumers必须配置为只读取提交的信息。
transactional.id的目的是在单个生产者实例的多个会话中启用事务恢复(transaction recovery )。它通常由分区、状态和应用程序中的shard标识符派生而来。因此,对于在分区应用程序中运行的每个生产者实例来说,它应该是惟一的。
所有新的transactional api都是阻塞的,并且在故障时抛出异常。下面的示例演示了如何使用新的api。它与上面的示例类似,只是所有100个消息都是单个事务的一部分。
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("transactional.id", "my-transactional-id");
Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new
StringSerializer());
producer.initTransactions();
try {
producer.beginTransaction();
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<>("my-topic", Integer.toString(i),
Integer.toString(i)));
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// We can''t recover from these exceptions, so our only option is to close the producer and
exit.
producer.close();
} catch (KafkaException e) {
// For all other exceptions, just abort the transaction and try again.
producer.abortTransaction();
}
producer.close();正如在示例中所暗示的那样,每个生产者只能有一个打开的事务。beginTransaction()和commitTransaction()之间发送的所有消息都将是单个事务的一部分。当transactional.id被指定,producer发送的所有消息必须是事务的一部分。
transactional producer使用异常来传达错误状态。具体地说,不需要为producer . send()或调用. get()指定回调函数:如果任何一个producer.send()或事务性调用在事务中遇到不可恢复的错误,则将抛出KafkaException。查看send(ProducerRecord)文档,了解从事务发送中探知错误的更多细节。
在接收一个KafkaException时,通过调用producer.abortTransaction()我们可以确保任何成功的写操作标记为失败(中止),因此保持事务保证。
这个客户端可以与0.10.0版本或更新的brokers进行通信。旧的或新的brokers可能不支持某些客户端特性。例如,事务api需要broker 0.11.0版本或更高。当调用的API在运行broker版本中不可用,你将收到一个UnsupportedVersionException。
构造函数总结:
public KafkaProducer(Map<String,Object> configs)producer通过提供一组键值对作为配置来实例化。有效配置字符串都记录在这里。值可以是字符串或适当类型的对象(例如,数字配置可以接受字符串“42”或整数42)。
public KafkaProducer(Map<String,Object> configs,Serializer<K> keySerializer,Serializer<V> valueSerializer)producer通过提供一组键值对作为配置、一个键和一个值序列化器来实例化。有效配置字符串都记录在这里。值可以是字符串或适当类型的对象(例如,数字配置可以接受字符串“42”或整数42)。
public KafkaProducer(Properties properties)
public KafkaProducer(Properties properties,Serializer<K> keySerializer,Serializer<V> valueSerializer)同上。
方法总结:
public void initTransactions()
当在配置中设置了transactional.id,该方法需要在任何其他方法之前被调用,该方法执行以下步骤:1、确保由producer先前实例发起的任何事物都已经完成。如果前一个实例的事务在进程中失败,它将被终止。如果最后一个事务已经开始完成,但还没有完成,该方法将等待它完成。2、获取producer的内部ID和epoch(纪元?此处不清楚准确的翻译),用于 producer.发布的所有未来的事务消息。
Specified by:
initTransactions in interface Producer<K,V>
Throws:
IllegalStateException - 如果配置中没有设置producer的transactional.id则抛出此异常。
public void beginTransaction()
需要在每个新事务开始之前调用。
Specified by:
beginTransaction in interface Producer<K,V>
Throws:
ProducerFencedException - 如果另一个活跃的producer有相同的transactional.id则抛出此异常。
public void sendOffsetsToTransaction(Map<TopicPartition,OffsetAndMetadata> offsets,String consumerGroupId)
向consumer组协调器发送被消耗的偏移量列表,并将这些偏移量标记为当前事务的一部分。只有当事务成功提交时,这些偏移量才会被视为消费掉的。当您需要将消费和生成的消息一起批量处理时,应该使用此方法,通常在consume-transform-produce 模式中使用。
Specified by:
sendOffsetsToTransaction in interface Producer<K,V>
Throws:
ProducerFencedException - 如果另一个活跃的producer有相同的transactional.id则抛出此异常。
public void commitTransaction()
提交正在进行中的事务。此方法将在实际提交事务之前flush任何未发送的消息。此外,如何事务包含部分的任何send(ProducerRecord) 调用触发不可恢复的错误,那么该方法将立即抛出最后一个接收到的异常,而事务将不会被提交。因此,在事务中对send(ProducerRecord)的调用必须成功,以便此方法成功。
Specified by:
commitTransaction in interface Producer<K,V>
Throws:
ProducerFencedException - 如果另一个活跃的producer有相同的transactional.id则抛出此异常。
public void abortTransaction()
中止正在进行中的事务。当此调用完成时,任何未flush的生成消息将中止。如果任何先前的send(ProducerRecord)调用有ProducerFencedException或ProducerFencedException 导致的调用失败,此调用将立即抛出异常。
Specified by:
abortTransaction in interface Producer<K,V>
Throws:
ProducerFencedException - 如果另一个活跃的producer有相同的transactional.id则抛出此异常。
public Future<RecordMetadata> send(ProducerRecord<K,V> record,Callback callback)
异步发送消息到topic,并在发送的消息被确认的时候调用所提供的回调。
send是异步的,并且一旦消息被保存在等待发送的消息缓冲区中,此方法就立即返回。这样并行发送多条消息而不阻塞去等待每一条消息的响应。
发送的结果是一个RecordMetadata,它指定了消息发送的分区,分配的offset和消息的时间戳。如果topic使用的是CreateTime,则使用用户提供的时间戳或发送的时间(如果用户没有指定消息的时间戳时使用发送的时间)如果topic使用的是LogAppendTime,则追加消息时,时间戳是broker的本地时间。
因为send 调用是异步的,它将为分配给消息的RecordMetadata返回一个Future。如果future调用get(),则将阻塞,直到相关请求完成并返回该消息的metadata,或抛出发送异常。
如果你想模拟一个简单的阻塞调用,您可以立即调用get()方法:
byte[] key = "key".getBytes();
byte[] value = "value".getBytes();
ProducerRecord<byte[],byte[]> record = new ProducerRecord<byte[],byte[]>("my-topic", key, value);
producer.send(record).get();完全非阻塞的使用可以利用回调参数提供一个回调,当请求完成时将被调用。
producer.send(myRecord,
new Callback() {
public void onCompletion(RecordMetadata metadata, Exception e) {
if(e != null)
e.printStackTrace();
System.out.println("The offset of the record we just sent is: " +
metadata.offset());
}
});发送到同一个分区的消息回调保证按一定的顺序执行,也就是说,在下面的例子中 callback1 保证执行 callback2 之前:
producer.send(new ProducerRecord<byte[],byte[]>(topic, partition, key1, value1), callback1);
producer.send(new ProducerRecord<byte[],byte[]>(topic, partition, key2, value2), callback2);当send作为事务的一部分使用时,不需要定义回调或者检查future的结果来检查send的错误。如果任何send因为一个不可恢复的错误而调用失败,则最终的commitTransaction() 调用将失败,并且在最后的发送失败时抛出异常。当发生这种情况的时候,应用程序应该调用abortTransaction()来重置状态并继续发送数据。
有些事务发送错误无法通过调用abortTransaction()来解决。特别是,如果一个事务发送完成时伴随着一个ProducerFencedException,OutOfOrderSequenceException,
UnsupportedVersionException,或一个AuthorizationException等异常,那么唯一的选择就是调用close()。重大的错误导致生产者进入无效状态,在这种状态下,future的API调用将同样的底层错误包装在新的KafkaException中抛出。
当启用idempotence(幂等性),但没有配置transactional.id 的时候,是一个类似的场景。在这种情况下,UnsupportedVersionException和AuthorizationException被视为重大错误。但是,ProducerFencedException不需要被处理。此外,它有可能在收到一个OutOfOrderSequenceException之后继续发送信息,但是这样做可能导致等待中的消息的无序投递,为了确保正确的顺序,你应该关闭生产者并创建一个新的实例。
如果目标topic的消息格式不升级到0.11.0.0,idempotent(幂等性)和transactional(事务性)的生产请求将失败并伴随一个UnsupportedForMessageFormatException的错误。如果在事务中遇到这种情况,则可以中止并继续执行。但是需要注意的是,之后发送到同一topic将会继续收到相同的异常,直到topic被更新。
注意:callback一般在生产者的I/O线程中执行,所以是相当的快的,否则将延迟其他的线程的消息发送。如果你想要执行阻塞或计算代价高昂的回调,建议在callback主体中使用自己的Executor来并行处理。
Specified by:
send in interface Producer<K,V>
Parameters:
record - 发送的消息
callback - 当消息被服务器确认的时候执行用户提供的回调 (null 表示没有回调)
Throws:
IllegalStateException -如果配置了transactional.id 但没有事务启动。
InterruptException - 如果线程在阻塞时被中断
SerializationException - 如果序列化配置了无效的键值对象
TimeoutException - 如果获取metadata或为消息分配内存所消耗的时间超过了 max.block.ms设定的值。
KafkaException -如果出现了不属于公共API异常的Kafka相关的错误。
public void flush()
调用此方法可以使所有的缓冲消息立即可以发送(即使linger.ms配置的值大于0)并且阻塞与这些信息相关联的请求的完成。flush()后置条件是任何先前发送的记录已经完成(举例来说就是,Future.isDone() == true)。一个请求根据你指定的确认配置被成功确认之后则被认为是完成的,否则会导致错误。
当一个线程被阻塞等待一个flush()调用完成时,其它线程可以继续发送消息,但是不能保证关于flush调用开始之后发送的消息的完成。
这个方法可以用于从一些输入系统消费消息并生产至kafka中。flush()调用提供了一种方便的方法来确保所有以前发送的消息实际上已经完成。
这个示例展示了如何从一个Kafka topic中消费,并生成至另一个Kafka topic:
for(ConsumerRecord<String, String> record: consumer.poll(100))
producer.send(new ProducerRecord("my-topic", record.key(), record.value());
producer.flush();
consumer.commit();需要注意的是,上述示例可能在生产(produce)请求失败的时候删除消息。如果要确保这种情况不会发生,需要在配置中设置retries=<large_number>。
应用程序不需要为事务性生产者调用此方法,因为commitTransaction()将在执行提交之前flush所有缓冲消息。这将确保在提交之前先前的beginTransaction()之后的所有send(ProducerRecord)调用都已经完成。
Specified by:
flush in interface Producer<K,V>
Throws:
InterruptException - 如果线程在阻塞时被中断
public List<PartitionInfo> partitionsFor(String topic)
获取给定topic的分区metadata ,这可以用于自定义分区。
Specified by:
partitionsFor in interface Producer<K,V>
Throws:
InterruptException - 如果线程在阻塞时被中断
public Map<MetricName,? extends Metric> metrics()
获得生产者维护的完整的内部度量集。
Specified by:
metrics in interface Producer<K,V>
public void close()
关闭这个生产者,此方法阻塞直到所有以前的发送请求完成。该方法等效于close(Long.MAX_VALUE, TimeUnit.MILLISECONDS)。
如果从回调中调用close(),日志将记录一条警告消息并以close(0, TimeUnit.MILLISECONDS)调用替代。我们这样做是因为发送方线程将尝试连接自己并永远阻塞。
Specified by:
close in interface Closeable
Specified by:
close in interface AutoCloseable
Specified by:
close in interface Producer<K,V>
Throws:
InterruptException - 如果线程在阻塞时被中断
public void close(long timeout,TimeUnit timeUnit)
此方法等待生产者完成所有未完成请求的发送直到超时。如果超时之前生产者不能完成所有请求,此方法将立刻丢弃任何的未发送和未确认的消息。
如果从一个Callback中调用此方法,此方法将不会阻塞,等同于close(0, TimeUnit.MILLISECONDS).这样做是因为在阻塞生产者的I/O线程时不会发生进一步的发送。
Specified by:
close in interface Producer<K,V>
Parameters:
timeout - 等待生产者完成任何正要发生的请求的最大时间。这个值应该是非负的。指定超时为0意味着不等待正要发生的请求的完成。
timeUnit - 超时时间的单位
Throws:
InterruptException - 如果线程在阻塞时被中断
IllegalArgumentException - 如果超时时间的值是负的

Kafka Manager| KafkaMonitor
1.kafka Manager
1.上传压缩包kafka-manager-1.3.3.15.zip到集群
2.解压到/opt/module
3.修改配置文件conf/application.conf
kafka-manager.zkhosts="kafka-manager-zookeeper:2181"
修改为:
kafka-manager.zkhosts="hadoop101:2181,hadoop102:2181,hadoop103:2181"
4.启动kafka-manager
bin/kafka-manager
5.登录hadoop102:9000页面查看详细信息
[kris@hadoop101 software]$ unzip kafka-manager-1.3.3.15.zip -d /opt/module/
[kris@hadoop101 bin]$ chmod +x kafka-manager
[kris@hadoop101 bin]$ ./kafka-manager ##启动9000端口号可能会冲突,也可以修改端口号
启动KafkaManager
[kris@hadoop101 kafka-manager]$
nohup bin/kafka-manager -Dhttp.port=7456 >/opt/module/kafka-manager-1.3.3.22/start.log 2>&1 &
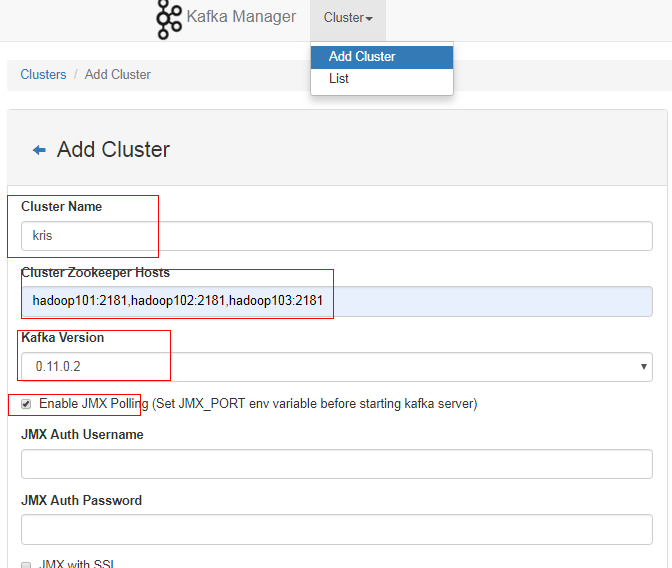
添加集群:
集群信息: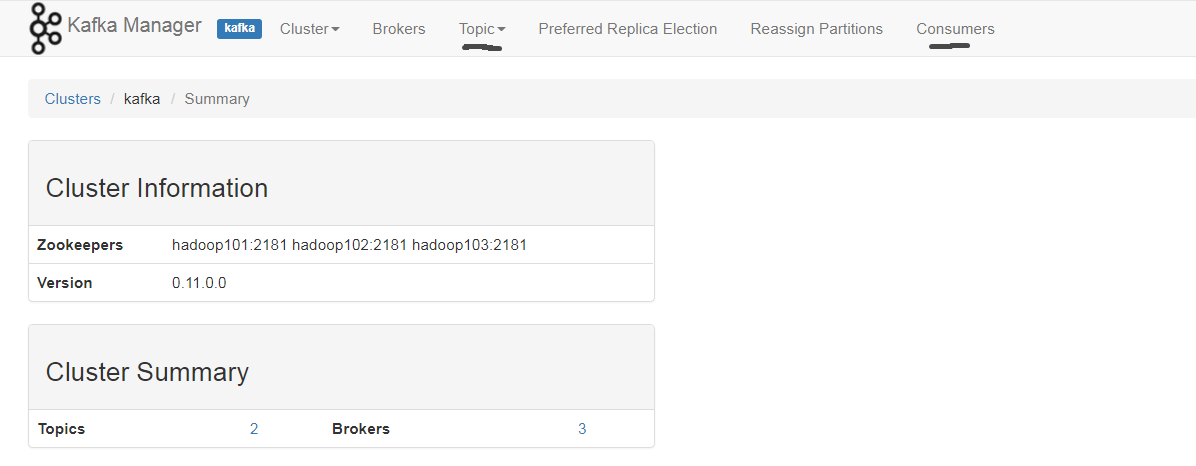
添加主题;
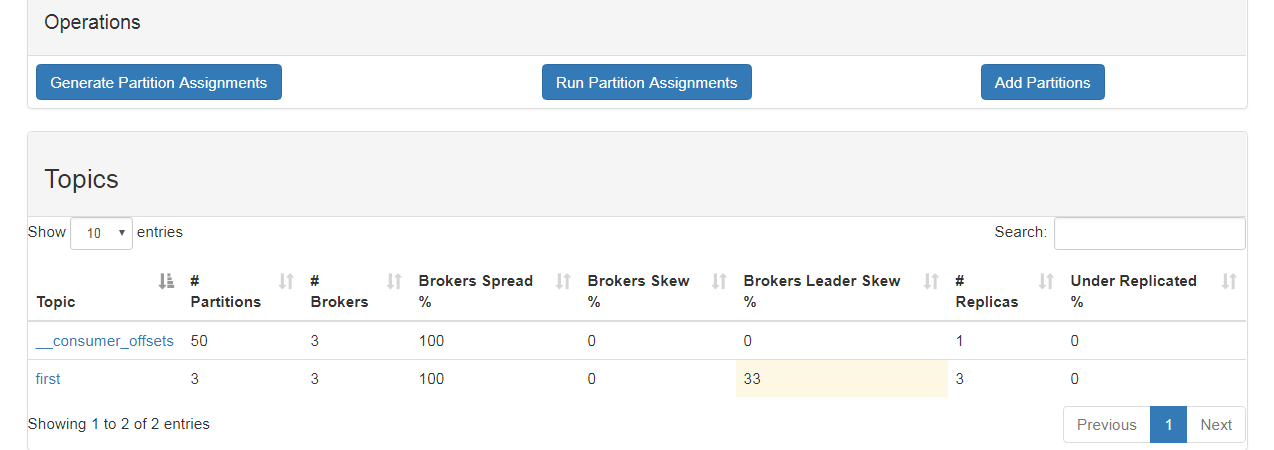
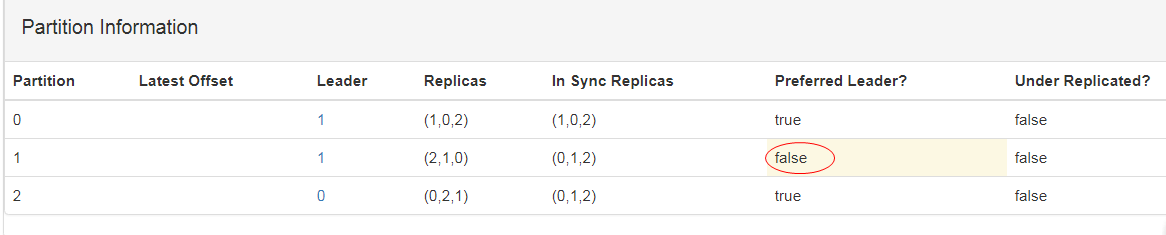
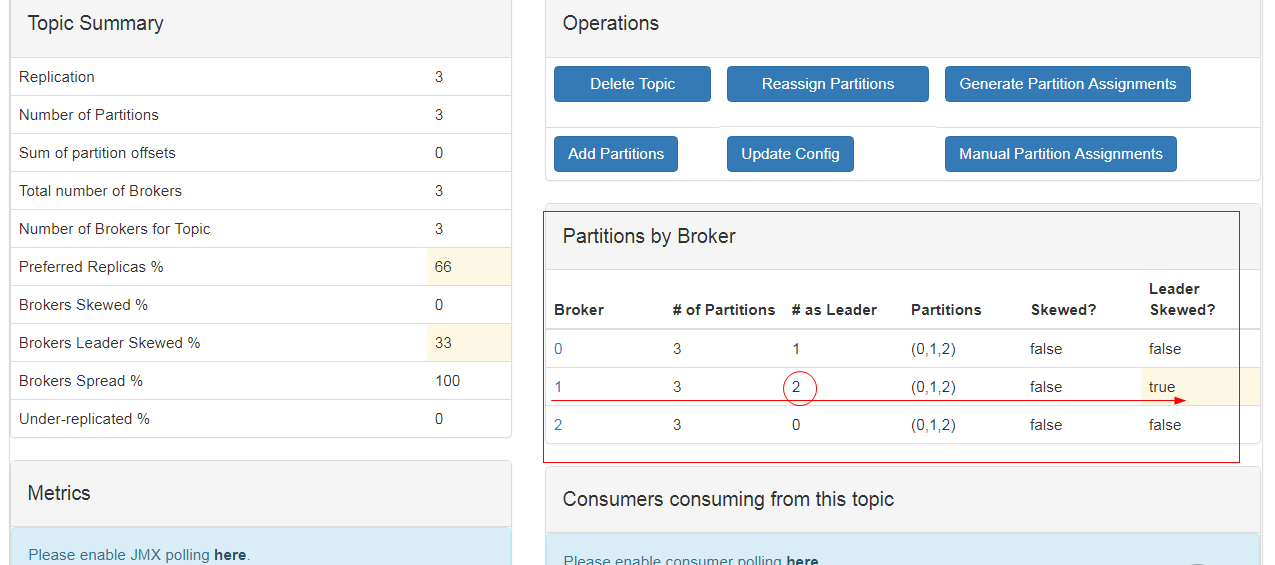
重新获取平衡
分区数、节点数、Brokers Spread节点分布比例(如一共3个节点,主题占了3个节点所以分布比例是100%,如果有3个节点主题只占1个,则33% )
Brokers Skew节点倾斜度、(1个Topic--3个分区--每个分区3个副本;如果某个节点上分区数>3个, 有节点超负荷了(有1个节点超负荷了即1/3=33%,两个节点超负荷了则2/3)
Brokers Leader Skew Leader的倾斜度,leader都在一个节点上,leader倾斜度)
起一个消费者
[kris@hadoop101 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop101:9092 --topic first
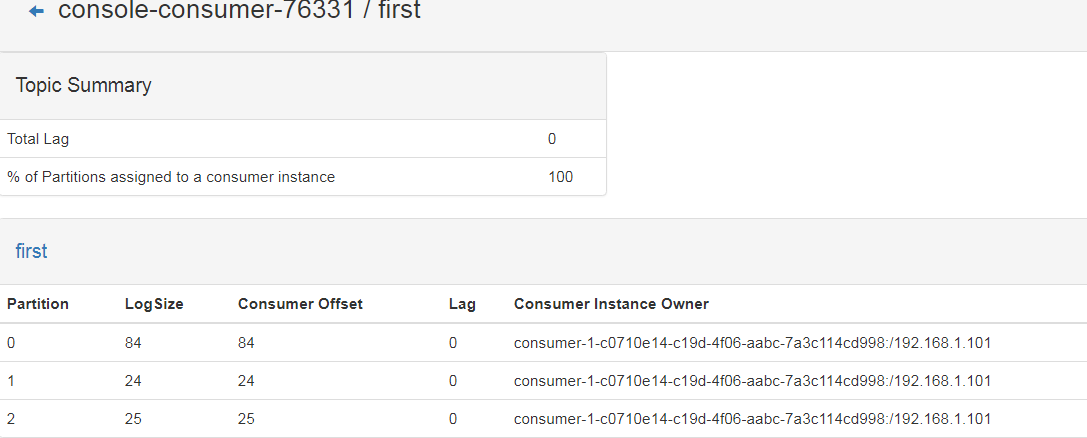
2. KafkaMonitor
局限性,offset在zk上可以使用
1.上传jar包KafkaOffsetMonitor-assembly-0.2.0.jar到集群
2.在/opt/module/下创建kafka-offset-console文件夹
3.将上传的jar包放入刚创建的目录下
4.在/opt/module/kafka-offset-console目录下创建启动脚本start_en.sh,内容如下:
java -cp就是执行下那个jar包;主方法所在的类的类名;zk地址;每隔10s刷新下库;
[kris@hadoop101 kafka-offset-console]$ vim start_en.sh
#!/bin/bash
java -Xms512M -Xmx512M -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -cp KafkaOffsetMonitor-assembly-0.2.0.jar \
com.quantifind.kafka.offsetapp.OffsetGetterWeb \
--zk 192.168.1.101:2181,192.168.1.102:2182,192.168.1.103:2181 \
--port 8086 \
--refresh 10.seconds \
--retain 7.days 1>mobile-logs/stdout.log 2>mobile-logs/stderr.log &
[kris@hadoop101 kafka-offset-console]$ ll
总用量 56560
-rw-rw-r--. 1 kris kris 57910726 3月 1 21:23 KafkaOffsetMonitor-assembly-0.2.0.jar
-rw-rw-r--. 1 kris kris 375 3月 1 21:25 start_en.sh
5.在/opt/module/kafka-offset-console目录下创建mobile-logs文件夹
[kris@hadoop101 kafka-offset-console]$ mkdir /opt/module/kafka-offset-console/mobile-logs
[kris@hadoop101 kafka-offset-console]$ ll
总用量 56564
-rw-rw-r--. 1 kris kris 57910726 3月 1 21:23 KafkaOffsetMonitor-assembly-0.2.0.jar
drwxrwxr-x. 2 kris kris 4096 3月 1 21:26 mobile-logs
-rw-rw-r--. 1 kris kris 375 3月 1 21:25 start_en.sh
[kris@hadoop101 kafka-offset-console]$ ./start_en.sh
-bash: ./start_en.sh: 权限不够
[kris@hadoop101 kafka-offset-console]$ chmod +x start_en.sh
6.启动KafkaMonitor
[kris@hadoop101 kafka-offset-console]$ ./start_en.sh
http://hadoop101:8086/#/
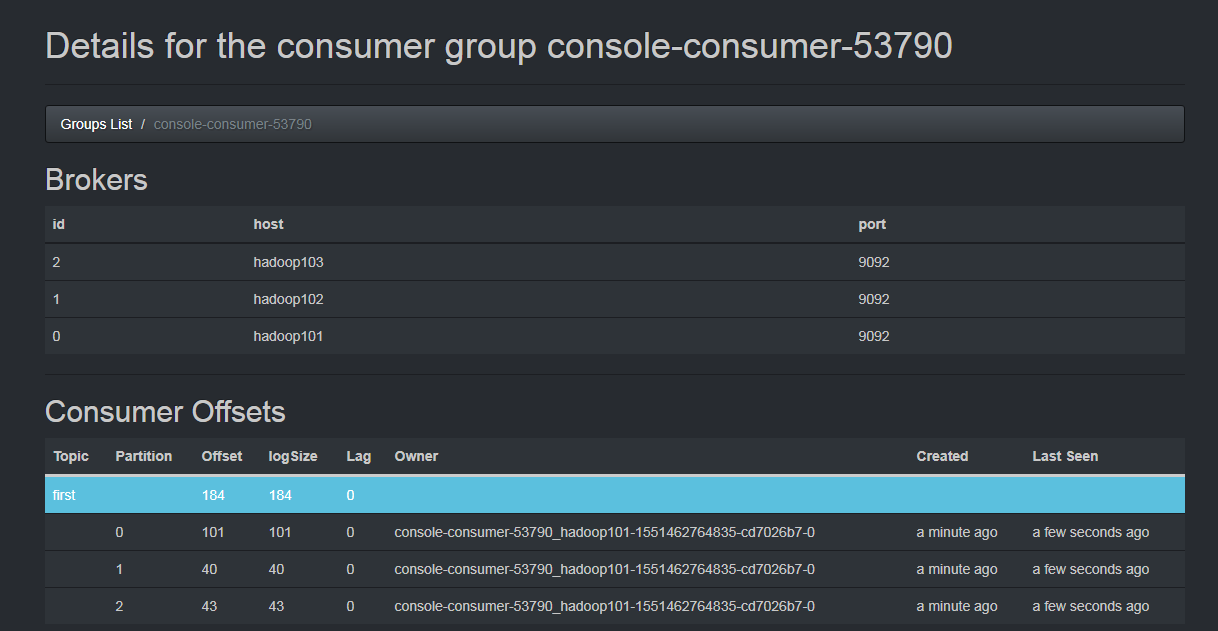
[kris@hadoop101 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop101:9092 --topic first
>hello
>world
[kris@hadoop101 kafka]$ bin/kafka-console-consumer.sh --zookeeper hadoop101:2181 --topic first
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
hello
world
java
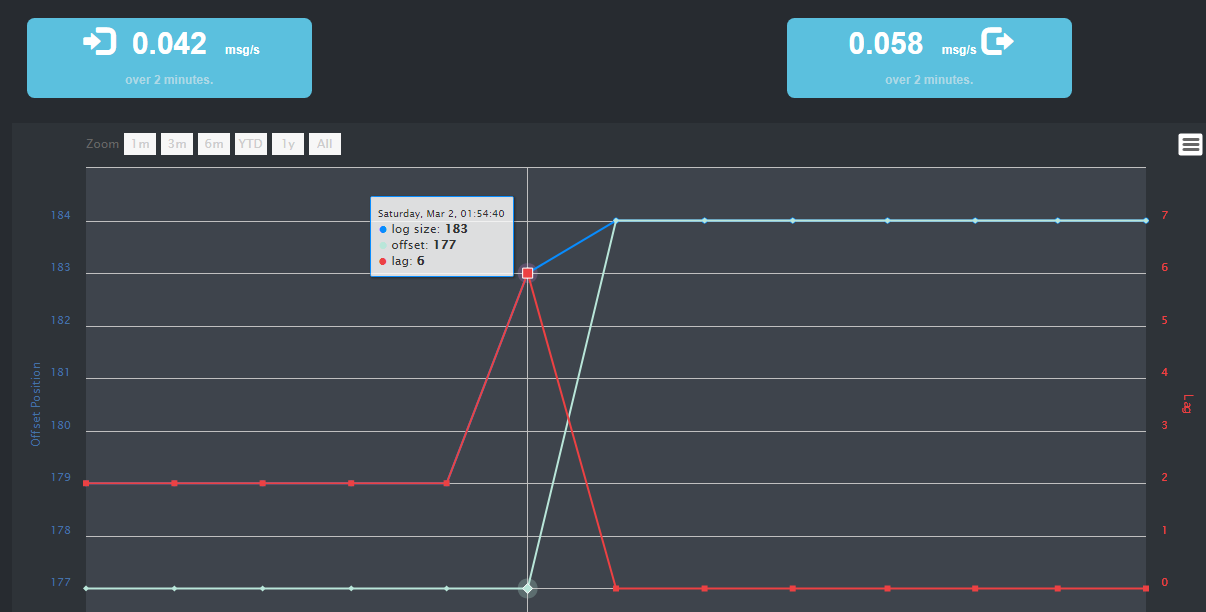
主题生产到了longSize184的offset,目前消费到177,lag还有6个没有消费到;
lag有多少条消息没有被消费;到最后都被消费掉lag=0
关于kafka 生产者性能监控:Monitor Kafka Producer for Performance和kafka exporter能监控哪些指标的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于apache kafka监控系列-KafkaOffsetMonitor、Apache Kafka(五)- Safe Kafka Producer、Kafka 0.11.0 Java API 中文翻译—— KafkaProducer、Kafka Manager| KafkaMonitor的相关信息,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

