在本文中,我们将详细介绍代码教程丨用DolphinDB实时计算分钟资金流的各个方面,同时,我们也将为您带来关于5G+工业互联网丨DolphinDB携手诺基亚贝尔打造高精度实时计算平台、DolphinD
在本文中,我们将详细介绍代码教程丨用 DolphinDB 实时计算分钟资金流的各个方面,同时,我们也将为您带来关于5G+工业互联网丨DolphinDB携手诺基亚贝尔打造高精度实时计算平台、DolphinDB Python API 离线安装教程、DolphinDB SQL 案例教程、DolphinDB VSCode 插件使用教程的有用知识。
本文目录一览:- 代码教程丨用 DolphinDB 实时计算分钟资金流
- 5G+工业互联网丨DolphinDB携手诺基亚贝尔打造高精度实时计算平台
- DolphinDB Python API 离线安装教程
- DolphinDB SQL 案例教程
- DolphinDB VSCode 插件使用教程

代码教程丨用 DolphinDB 实时计算分钟资金流
DolphinDB内置的流数据框架支持流数据的发布,订阅,预处理,实时内存计算,复杂指标的滚动窗口计算、滑动窗口计算、累计窗口计算等,是一个运行高效、使用便捷的流数据处理框架。
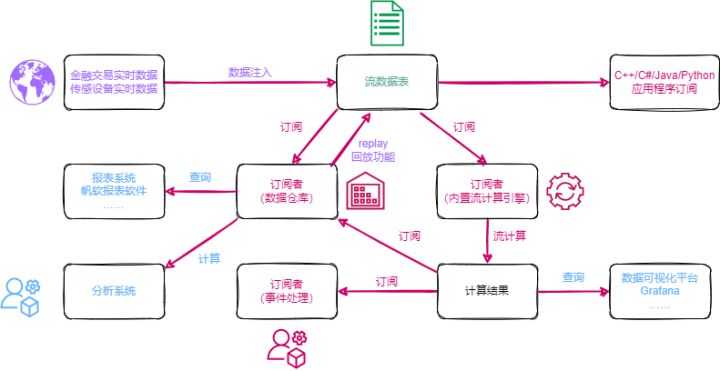
本教程主要提供一种基于DolphinDB流数据处理框架,实时计算分钟资金流的低延时解决方案。
本教程包含内容:
- 应用场景描述
- 开发环境配置
- 代码开发
- 结果展示
- 总结
1. 应用场景描述
1.1 数据源
本教程基于上交所2020年某日的逐笔成交数据进行代码调试,在DolphinDB中存储的表结构为:
| name | typeString | comment |
|---|---|---|
| SecurityID | SYMBOL | 股票代码 |
| Market | SYMBOL | 交易所 |
| TradeTime | TIMESTAMP | 交易时间 |
| TradePrice | DOUBLE | 交易价格 |
| TradeQty | INT | 成交量 |
| TradeAmount | DOUBLE | 成交额 |
| BuyNum | INT | 买单订单号 |
| SellNum | INT | 卖单订单号 |
1.2 计算指标
本教程示例代码计算了1分钟滚动窗口的资金流指标:
| 含义 | |
|---|---|
| BuySmallAmount | 过去1分钟内,买方向小单的成交额,成交股数小于等于50000股 |
| BuyBigAmount | 过去1分钟内,买方向大单的成交额,成交股数大于50000股 |
| SellSmallAmount | 过去1分钟内,卖方向小单的成交额,成交股数小于等于50000股 |
| SellBigAmount | 过去1分钟内,卖方向大单的成交额,成交股数大于50000股 |
关于资金流大小单的划分规则,不同的开发者会有不同的定义方法。以常用的股票行情软件为例:
(1)东方财富
- 超级大单:>50万股或100万元
- 大单:10-50万股或20-100万元
- 中单:2-10万股或4-20万元
- 小单:<2万股或4万元
(2)新浪财经
- 特大单:>100万元
- 大单:20-100万元
- 小单:5-20万元
- 散单:<5万元
包括大智慧、同花顺等,不同软件之间的大小单区分规则都会有差异。
但是判断条件都是基于成交股数或成交金额。
注意:本教程中,资金流大小单的判断条件基于成交股数,只划分了大单和小单两种,判断的边界值是随机定义的,开发者必须根据自己的实际场景进行调整。
1.3 实时计算方案
本教程通过自定义聚合函数的方法,实时计算资金流,在DolphinDB中的处理流程如下图所示:
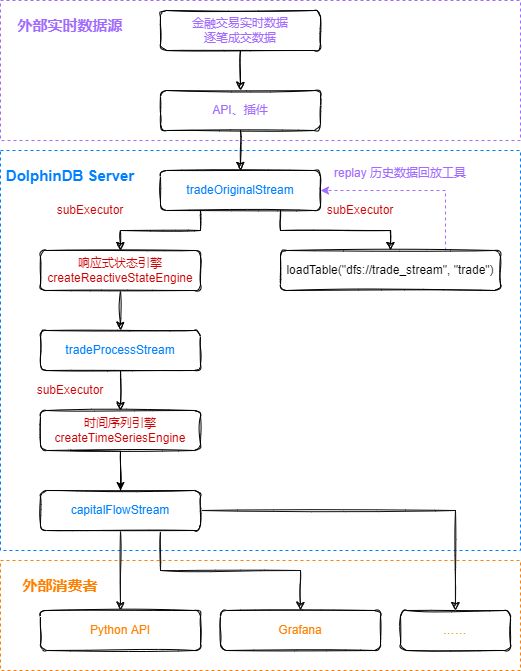
处理流程图说明:
(1)tradeOriginalStream、tradeProcessStream、capitalFlowStream都是共享的异步持久化流数据表。
- tradeOriginalStream:用于接收和发布股票逐笔成交实时流数据。
- tradeProcessStream:用于接收和发布响应式状态引擎处理后的中间结果数据。
- capitalFlowStream:用于接收和发布时间序列引擎处理后的1分钟滚动窗口的资金流指标。
- 将内存表共享的目的是让当前节点所有其它会话对该表可见,实时流数据通过API写入DolphinDB流数据表时与DolphinDB Server的会话相对于定义这些表的会话可能不是同一个,所以需要共享。
- 对流数据表进行持久化的目的主要有两个:一是控制该表的最大内存占用,通过设置enableTableShareAndPersistence函数中的cacheSize大小,控制该表在内存中保留的最大记录条数,进而控制该表的最大内存占用;二是在节点异常关闭的极端情况下,从持久化数据文件中恢复已经写入流数据表但是未消费的数据,保证流数据“至少消费一次”的需求。
- 流数据表持久化采用异步的方式进行,可以有效提高流表写入的吞吐量。只有流数据表才可以被订阅消费,所以需要将以上的tradeOriginalStream、tradeProcessStream、capitalFlowStream表定义成流数据表。
(2)subExecutor表示流数据处理线程。
- 通过设置配置文件的subExecutors参数指定节点的最大可用流数据处理线程数。
- 通过设置subscribeTable函数中的hash参数,指定消费该topic的流数据处理线程。例如subExecutors设置为n,则hash可以从0至n-1进行指定,对应流数据处理线程1至n。
(3)响应式状态引擎和时间序列引擎是DolphinDB的内置的高性能流计算引擎。
- 针对常用的统计计算函数都已实现增量计算。
- 在上述场景中,响应式状态引擎对原始数据进行了加工处理,使其满足时间序列引擎处理的输入要求。
- 在上述场景中,时间序列引擎用于计算生成1分钟滚动窗口的资金流指标。
(4)loadTable("dfs://trade_stream", "trade") 用于存储原始数据,做数据的持久化。
(5)loadTable("dfs://trade_stream", "trade") 中存储的历史数据,可以通过DolphinDB内置的replay回放工具进行控速回放。
- 历史数据回放工具可以基于历史数据开发流计算代码的开发场景,验证流计算代码的计算正确性、计算效率等。
- 历史数据回放工具也可以用于将历史数据回放到流计算引擎,进行历史数据的批量计算。
2. 开发环境配置
2.1 DolphinDB server服务器环境
- CPU类型:Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz
- 逻辑CPU总数:8
- 内存:64GB
- OS:64位 CentOS Linux 7 (Core)
2.2 DolphinDB server部署
- server版本:1.30.18 或 2.00.6
- server部署模式:单节点
- 配置文件:dolphindb.cfg
localSite=localhost:8848:local8848
mode=single
maxMemSize=64
maxConnections=512
workerNum=8
localExecutors=7
maxConnectionPerSite=15
newValuePartitionPolicy=add
webWorkerNum=2
dataSync=1
persistenceDir=/opt/DolphinDB/server/local8848/persistenceDir
maxPubConnections=64
subExecutors=16
subPort=8849
subThrottle=1
persistenceWorkerNum=1
lanCluster=0配置参数persistenceDir需要开发人员根据实际环境配置。
单节点部署教程:单节点部署
2.3 DolphinDB client开发环境
- CPU类型:Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz 3.60 GHz
- 逻辑CPU总数:8
- 内存:32GB
- OS:Windows 10 专业版
- DolphinDB GUI版本:1.30.15
DolphinDB GUI安装教程:GUI教程
3. 代码开发
本教程代码开发工具采用DolphinDB GUI,所有代码均可在DolphinDB GUI客户端开发工具执行。
3.1 创建存储历史数据的库表
//login account
login("admin", "123456")
//create database and table
dbName = "dfs://trade"
tbName = "trade"
if(existsDatabase(dbName)){
dropDatabase(dbName)
}
db1 = database(, VALUE, 2020.01.01..2022.01.01)
db2 = database(, HASH, [SYMBOL, 5])
db = database(dbName, COMPO, [db1, db2])
schemaTable = table(
array(SYMBOL, 0) as SecurityID,
array(SYMBOL, 0) as Market,
array(TIMESTAMP, 0) as TradeTime,
array(DOUBLE, 0) as TradePrice,
array(INT, 0) as TradeQty,
array(DOUBLE, 0) as TradeAmount,
array(INT, 0) as BuyNum,
array(INT, 0) as SellNum
)
db.createPartitionedTable(table=schemaTable, tableName=tbName, partitionColumns=`TradeTime`SecurityID, compressMethods={TradeTime:"delta"})- 分区原则:建议落在1个最小分区的数据在内存的大小约150MB~500MB,上交所2020年1月2日的股票逐笔成交数据为16325584条,加载到内存的大小约750MB,所以采用组合分区的方法,第一层按天分区,第二层对股票代码按HASH分5个分区,每个分区的全部数据加载到内存后约占用250MB内存空间。
- 创建数据库时,选择DolphinDB的OLAP存储引擎进行数据的存储。
- 创建数据表时,按照分区方法,指定
TradeTime和SecurityID为分区字段,在对大数据集查询时,必须指定TradeTime和SecurityID的过滤条件,起到分区剪枝的作用。 - DolphinDB默认数据存储的压缩算法为lz4,对于时间、日期类型的数据,建议指定采用delta压缩算法存储,提高存储的压缩比。
3.2 导入上交所2020年某日的逐笔成交历史数据
- 历史数据对象为csv文本数据,磁盘空间占用1.2GB。
- 本教程中csv文本数据存储路径:
/hdd/hdd9/data/streaming_capital_flow/20200102_SH_trade.csv
//load data
csvDataPath = "/hdd/hdd9/data/streaming_capital_flow/20200102_SH_trade.csv"
dbName = "dfs://trade"
tbName = "trade"
trade = loadTable("dfs://trade", "trade")
schemaTable = table(trade.schema().colDefs.name as `name, trade.schema().colDefs.typeString as `type)
loadTextEx(dbHandle=database(dbName), tableName=tbName, partitionColumns=`TradeTime`SecurityID, filename=csvDataPath, schema=schemaTable)数据导入完成后,可以执行以下查询语句确认数据是否导入成功:
select count(*) from loadTable("dfs://trade", "trade") group by date(TradeTime) as TradeDate执行完后,返回如下信息,说明数据成功导入:
| TradeDate | count |
|---|---|
| 2020.01.02 | 16051658 |
3.3 创建存储实时数据的库表
//login account
login("admin", "123456")
//create database and table
dbName = "dfs://trade_stream"
tbName = "trade"
if(existsDatabase(dbName)){
dropDatabase(dbName)
}
db1 = database(, VALUE, 2020.01.01..2022.01.01)
db2 = database(, HASH, [SYMBOL, 5])
db = database(dbName, COMPO, [db1, db2])
schemaTable = table(
array(SYMBOL, 0) as SecurityID,
array(SYMBOL, 0) as Market,
array(TIMESTAMP, 0) as TradeTime,
array(DOUBLE, 0) as TradePrice,
array(INT, 0) as TradeQty,
array(DOUBLE, 0) as TradeAmount,
array(INT, 0) as BuyNum,
array(INT, 0) as SellNum
)
db.createPartitionedTable(table=schemaTable, tableName=tbName, partitionColumns=`TradeTime`SecurityID, compressMethods={TradeTime:"delta"})3.4 清理环境并创建相关流数据表
// clean up environment
def cleanEnvironment(parallel){
for(i in 1..parallel){
try{ unsubscribeTable(tableName=`tradeOriginalStream, actionName="tradeProcess"+string(i)) } catch(ex){ print(ex) }
try{ unsubscribeTable(tableName=`tradeProcessStream, actionName="tradeTSAggr"+string(i)) } catch(ex){ print(ex) }
try{ dropStreamEngine("tradeProcess"+string(i)) } catch(ex){ print(ex) }
try{ dropStreamEngine("tradeTSAggr"+string(i)) } catch(ex){ print(ex) }
}
try{ unsubscribeTable(tableName=`tradeOriginalStream, actionName="tradeToDatabase") } catch(ex){ print(ex) }
try{ dropStreamTable(`tradeOriginalStream) } catch(ex){ print(ex) }
try{ dropStreamTable(`tradeProcessStream) } catch(ex){ print(ex) }
try{ dropStreamTable(`capitalFlowStream) } catch(ex){ print(ex) }
undef all
}
//calculation parallel, developers need to modify according to the development environment
parallel = 3
cleanEnvironment(parallel)
go
//create stream table: tradeOriginalStream
colName = `SecurityID`Market`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNum`SellNum
colType = `SYMBOL`SYMBOL`TIMESTAMP`DOUBLE`INT`DOUBLE`INT`INT
tradeOriginalStreamTemp = streamTable(1000000:0, colName, colType)
try{ enableTableShareAndPersistence(table=tradeOriginalStreamTemp, tableName="tradeOriginalStream", asynWrite=true, compress=true, cacheSize=1000000, retentionMinutes=1440, flushMode=0, preCache=10000) } catch(ex){ print(ex) }
undef("tradeOriginalStreamTemp")
go
setStreamTableFilterColumn(tradeOriginalStream, `SecurityID)
//create stream table: tradeProcessStream
colName = `SecurityID`TradeTime`Num`TradeQty`TradeAmount`BSFlag
colType = `SYMBOL`TIMESTAMP`INT`INT`DOUBLE`SYMBOL
tradeProcessStreamTemp = streamTable(1000000:0, colName, colType)
try{ enableTableShareAndPersistence(table=tradeProcessStreamTemp, tableName="tradeProcessStream", asynWrite=true, compress=true, cacheSize=1000000, retentionMinutes=1440, flushMode=0, preCache=10000) } catch(ex){ print(ex) }
undef("tradeProcessStreamTemp")
go
setStreamTableFilterColumn(tradeProcessStream, `SecurityID)
//create stream table: capitalFlow
colName = `TradeTime`SecurityID`BuySmallAmount`BuyBigAmount`SellSmallAmount`SellBigAmount
colType = `TIMESTAMP`SYMBOL`DOUBLE`DOUBLE`DOUBLE`DOUBLE
capitalFlowStreamTemp = streamTable(1000000:0, colName, colType)
try{ enableTableShareAndPersistence(table=capitalFlowStreamTemp, tableName="capitalFlowStream", asynWrite=true, compress=true, cacheSize=1000000, retentionMinutes=1440, flushMode=0, preCache=10000) } catch(ex){ print(ex) }
undef("capitalFlowStreamTemp")
go
setStreamTableFilterColumn(capitalFlowStream, `SecurityID)parallel参数是指流计算的并行度,与3.5中的parallel参数含义相同。go语句的作用是对代码分段进行解析和执行。setStreamTableFilterColumn函数作用是指定流数据表的过滤列,与subscribeTable函数的filter参数配合使用。
3.5 注册流计算引擎和订阅流数据表
//real time calculation of minute index
defg calCapitalFlow(Num, BSFlag, TradeQty, TradeAmount){
// You can define the smallBigBoundary by yourself
smallBigBoundary = 50000
tempTable1 = table(Num as `Num, BSFlag as `BSFlag, TradeQty as `TradeQty, TradeAmount as `TradeAmount)
tempTable2 = select sum(TradeQty) as TradeQty, sum(TradeAmount) as TradeAmount from tempTable1 group by Num, BSFlag
BuySmallAmount = exec sum(TradeAmount) from tempTable2 where TradeQty<=smallBigBoundary && BSFlag==`B
BuyBigAmount = exec sum(TradeAmount) from tempTable2 where TradeQty>smallBigBoundary && BSFlag==`B
SellSmallAmount = exec sum(TradeAmount) from tempTable2 where TradeQty<=smallBigBoundary && BSFlag==`S
SellBigAmount = exec sum(TradeAmount) from tempTable2 where TradeQty>smallBigBoundary && BSFlag==`S
return nullFill([BuySmallAmount, BuyBigAmount, SellSmallAmount, SellBigAmount], 0)
}
//real time calculation of capitalFlow
//calculation parallel, developers need to modify according to the development environment
parallel = 3
for(i in 1..parallel){
//create ReactiveStateEngine: tradeProcess
createReactiveStateEngine(name="tradeProcess"+string(i), metrics=[<TradeTime>, <iif(BuyNum>SellNum, BuyNum, SellNum)>, <TradeQty>, <TradeAmount>, <iif(BuyNum>SellNum, "B", "S")>], dummyTable=tradeOriginalStream, outputTable=tradeProcessStream, keyColumn="SecurityID")
subscribeTable(tableName="tradeOriginalStream", actionName="tradeProcess"+string(i), offset=-1, handler=getStreamEngine("tradeProcess"+string(i)), msgAsTable=true, hash=i-1, filter = (parallel, i-1), reconnect=true)
//create DailyTimeSeriesEngine: tradeTSAggr
createDailyTimeSeriesEngine(name="tradeTSAggr"+string(i), windowSize=60000, step=60000, metrics=[<calCapitalFlow(Num, BSFlag, TradeQty, TradeAmount) as `BuySmallAmount`BuyBigAmount`SellSmallAmount`SellBigAmount>], dummyTable=tradeProcessStream, outputTable=capitalFlowStream, timeColumn="TradeTime", useSystemTime=false, keyColumn=`SecurityID, useWindowStartTime=true, forceTriggerTime=60000)
subscribeTable(tableName="tradeProcessStream", actionName="tradeTSAggr"+string(i), offset=-1, handler=getStreamEngine("tradeTSAggr"+string(i)), msgAsTable=true, batchSize=2000, throttle=1, hash=parallel+i-1, filter = (parallel, i-1), reconnect=true)
}
//real time data to database
subscribeTable(tableName="tradeOriginalStream", actionName="tradeToDatabase", offset=-1, handler=loadTable("dfs://trade_stream", "trade"), msgAsTable=true, batchSize=20000, throttle=1, hash=6, reconnect=true)parallel参数是指流计算的并行度,与3.4中的parallel参数含义相同。- 本教程设置
parallel=3,表示资金流计算的并行度为3,能够支撑的上游逐笔交易数据的最大流量为10万笔每秒。2022年1月某日,沪深两市全市场股票,在09:30:00开盘时候的逐笔交易数据流量峰值可以达到4.2万笔每秒,所以生产环境部署的时候,为了避免因流量高峰时流处理堆积造成延时增加的现象,可以将parallel设置为3,提高系统实时计算的最大负载。
3.6 Python API实时订阅计算结果
# -*- coding: utf-8 -*-
"""
DolphinDB python api version: 1.30.17.2
python version: 3.7.8
DolphinDB server version:1.30.18 or 2.00.5
last modification time: 2022.05.12
last modification developer: DolpinDB
"""
import dolphindb as ddb
import numpy as np
from threading import Event
def resultProcess(lst):
print(lst)
s = ddb.session()
s.enableStreaming(8800)
s.subscribe(host="192.192.168.8", port=8848, handler=resultProcess, tableName="capitalFlowStream", actionName="SH600000", offset=-1, resub=False, filter=np.array([''600000'']))
Event().wait()- 执行Python代码前,必须先在DolphinDB server端定义流数据表
capitalFlowStream,且通过函数setStreamTableFilterColumn对该表设置过滤列,配合Python API streaming功能函数subscribe的filte参数一起使用。 s.enableStreaming(8800)此处8800是指客户端Python程序占用的监听端口,设置任意Python程序所在服务器的空闲端口即可。- Python API streaming功能函数
subscribe的host和port参数为DolphinDB server的IP地址和端口;handler参数为回调函数,示例代码自定义了resultProcess回调函数,动作为打印实时接收到的数据;tableName参数为DolphinDB server端的流数据表,示例代码订阅了capitalFlowStream;offset参数设置为-1,表示订阅流数据表最新记录;resub参数为是否需要自动重连;filter表示过滤订阅条件,示例代码订阅了流数据表capitalFlowStream中SecurityID代码为600000的计算结果。
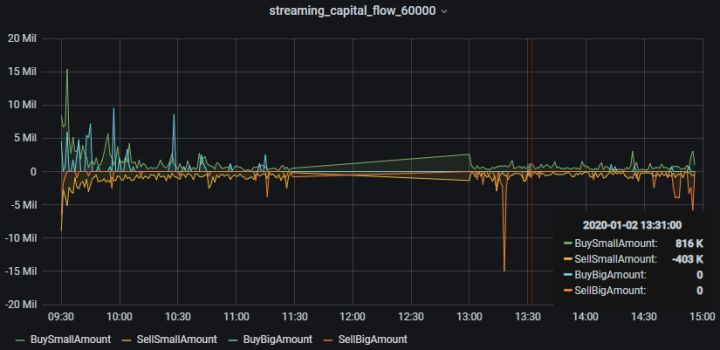
3.7 Grafana实时监控资金流向
Grafana配置DolphinDB数据源及监控DolphinDB数据表中数据的教程:Grafana连接DolphinDB数据源
本教程监控每分钟的主买小单资金、主卖小单资金、主买大单资金和主卖大单资金流入情况。
Grafana中的Query代码:
- 主买小单资金
select gmtime(TradeTime) as time_sec, BuySmallAmount from capitalFlowStream where SecurityID=`600000- 主卖小单资金(卖方向标记为负数显示)
select gmtime(TradeTime) as time_sec, -SellSmallAmount as SellSmallAmount from capitalFlowStream where SecurityID=`600000- 主买大单资金
select gmtime(TradeTime) as time_sec, BuyBigAmount from capitalFlowStream where SecurityID=`600000- 主卖大单资金(卖方向标记为负数显示)
select gmtime(TradeTime) as time_sec, -SellBigAmount as SellBigAmount from capitalFlowStream where SecurityID=`600000
因为Grafana默认显示UTC时间,和DolphinDB server内的数据时间存在8个小时时差,所以Grafana中的Query需要用到
gmtime函数进行时区的转换。
3.8 历史数据回放
t = select * from loadTable("dfs://trade", "trade") where time(TradeTime) between 09:30:00.000 : 14:57:00.000 order by TradeTime, SecurityID
submitJob("replay_trade", "trade", replay{t, tradeOriginalStream, `TradeTime, `TradeTime, 100000, true, 1})
getRecentJobs()执行完后,返回如下信息:

如果endTime和errorMsg为空,说明任务正在正常运行中。
3.9 流计算状态监控函数
- 流数据表订阅状态查询
getStreamingStat().pubTables流数据表被订阅成功后,就可以通过上述监控函数查到具体的订阅信息。执行完后,返回如下信息:
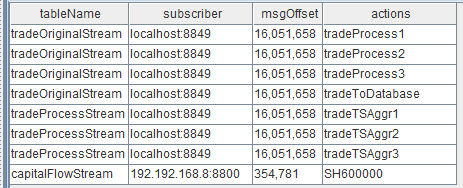
表中第二列的数据:
订阅者(subscriber)为localhost:8849,表示节点内部的订阅,8849为配置文件dolphindb.cfg中的subPort参数值;
订阅者(subscriber)为192.192.168.8:8800,表示Python API发起的订阅,8800是Python代码中指定的监听端口。
- 流数据表发布队列查询
getStreamingStat().pubConns当生产者产生数据,实时写入流数据表时,可以通过上述监控函数实时监测发布队列的拥堵情况。执行完后,返回如下信息:

实时监测发布队列的拥堵情况时,需要关注的指标是queueDepth,即发布队列深度。如果队列深度呈现不断增加的趋势,说明上游生产者实时产生的数据流量太大,已经超过数据发布的最大负载,导致发布队列拥堵,实时计算延时增加。
queueDepthLimit为配置文件dolphindb.cfg中的maxPubQueueDepthPerSite参数值,表示发布节点的消息队列的最大深度(记录条数)。
- 节点内部订阅者消费状态查询
getStreamingStat().subWorkers当流数据表把实时接收到的生产者数据发布给节点内部的订阅者后,可以通过上述监控函数实时监测消费队列的拥堵情况。执行完后,返回如下信息:

实时监测消费队列的拥堵情况时,需要关注的指标是每个订阅的queueDepth,即消费队列深度。如果某个订阅的消费队列深度呈现不断增加的趋势,说明该订阅的消费处理线程超过最大负载,导致消费队列拥堵,实时计算延时增加。
queueDepthLimit为配置文件dolphindb.cfg中的maxSubQueueDepthPerSite参数值,表示订阅节点的消息队列的最大深度(记录条数)。
4. 结果展示
4.1 节点内的计算结果表
计算结果表capitalFlowStream,可以通过DolphinDB所有API查询接口实时查询,通过DolphinDB GUI实时查看该表的结果,返回:
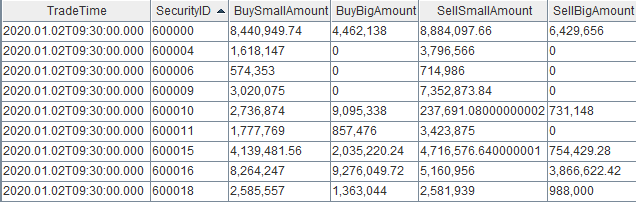
4.2 Python API实时订阅的计算结果
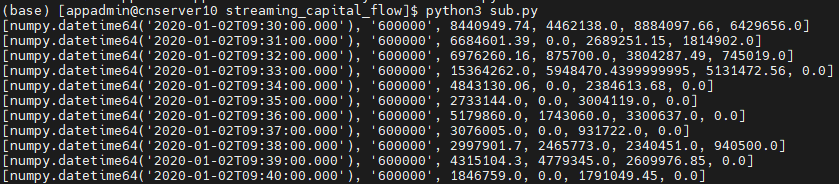
4.3 Grafana实时监控结果
5. 总结
本教程基于DolphinDB流数据处理框架,提供了一种实时计算分钟资金流的低延时解决方案。本教程以事件时间驱动窗口计算,DolphinDB也提供机器时间驱动窗口计算,可以在实际开发过程中灵活选择。本教程旨在提高开发人员在使用 DolphinDB 内置的流数据框架开发流计算业务场景时的开发效率、降低开发难度,更好地挖掘 DolphinDB 在复杂实时流计算场景中的价值。
附件
业务代码
01.创建存储历史数据的库表并导入数据
02.创建存储实时数据的库表
03.清理环境并创建相关流数据表
04.注册流计算引擎和订阅流数据表
05.PythonSub
06.历史数据回放
07.流计算状态监控函数
示例数据
20200102_SH_trade.csv

5G+工业互联网丨DolphinDB携手诺基亚贝尔打造高精度实时计算平台
近日,由智臾科技(DolphinDB)承担、诺基亚贝尔参与,双方共同申报的「基于5G Pre-TSN 网络的高精度时间同步实时计算平台」项目,成功入围浙江省“尖兵”、“领雁”研发攻关计划项目,时序数据库技术将尝试用于解决"5G+工业互联网"中低成本终端缺少高精度时间支持的难题。
项目简介
在工业互联网和工业制造领域,5G 凭借着大带宽、高可靠、低时延、广连接等特性,促成了云计算、大数据、人工智能、物联网、区块链与工业互联网等新一代信息技术的无缝融合,打通了数据从采集、存储、传送、处理、分析到决策的全过程,数据已经成为新一代生产要素,其中针对典型的异常检测问题,基于丰富的传感器采集的数据,引入了大数据分析和机器学习,带来了对数据时间相关性和海量实时数据存储和计算、分析处理的问题。
本项目计划引入 4G/5G 系统(用户设备+无线接入网+核心网),以及 ORAN 无线智能控制平台(RIC)和 ETSI MEC API 框架,搭建一个边缘计算平台,以找到能用更低成本、更轻量的方法来满足使用 5G 系统的大数据分析和机器学习算法中对于数据时间相关性的要求。ORAN 架构定义了近实时的无线智能控制平台和可编程的对无线接入网的增强,它提供了一个标准框架来解决这个问题。
同时将开发一个集数据库和数据计算功能于一体的实时计算平台,以满足对海量数据进行低时延异常检测、实时计算和机器学习的需求。其主要功能模块包含:高性能高压缩的数据存储引擎,支持海量数据的高速读写;多范式编程语言,支持丰富的计算函数与统计分析和机器学习功能;实时数据流计算,内置流数据时间序列聚合引擎,横截面聚合引擎和异常检测引擎可实现高性能流计算,支持亚毫秒级的信息延迟。
DolphinDB将和诺基亚贝尔携手合作,充分发挥DolphinDB高性能分布式时序数据库在海量数据存储、内置编程脚本语言和高速实时计算上的领先优势,依托诺基亚贝尔在5G 上行数据上的先进赋时技术,共同研发低成本、高精度的多终端时间戳同步系统,将时间戳精度从目前的几十到几百毫秒降低到低于 5毫秒,从而打造"弱终端、强基站"的增强 5G 系统。
行业痛点
目前5G+工业互联网在推动制造业向数字化、网络化、智能化转变过程中正发挥越来越重要的作用,但在推广过程中也遇到一些痛点问题:
- 因为精准授时需要北斗/GPS等授时设备或同步时钟源,室内环境还需光纤网络,投资巨大,所以很多行业都没有用高精度授时的传感设备,时间精度低。
- 虽然目前5G 网络号称低时延,但实际网络时延抖动能高达几十毫秒;
- 实时计算分析软件无法实现毫秒级响应。
这些问题导致不同数据源的数据时间戳不准且难以对齐,制约了高端制造业数据要素的挖掘效力。
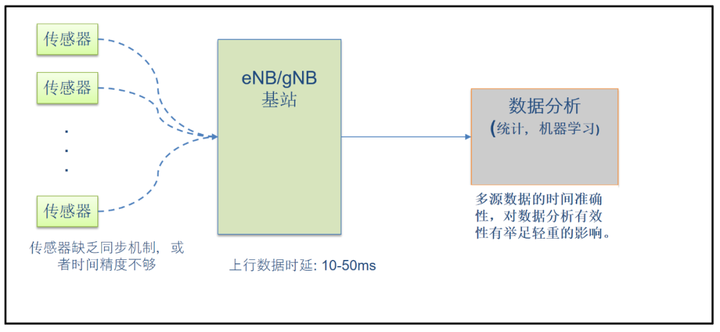
图1 多源头的数据存在时间同步问题
研发重点
本项目拟基于开放无线接入网ORAN 架构,实现弱终端、强基站,用低成本方式提高传感器的时间精度,确保时间精度误差小于5ms,主要开发内容包括如下三个方面:
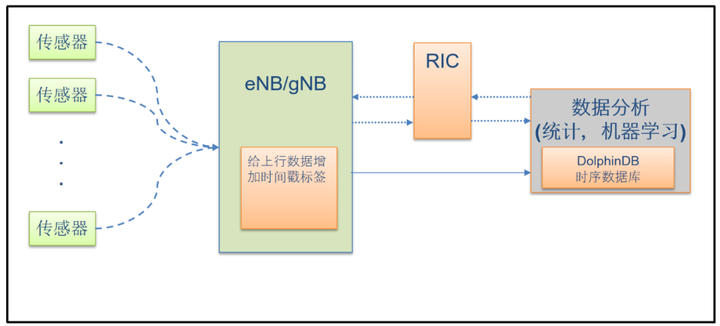
图2 系统架构图
- 用5G基站收到数据的时间,加上智能补偿来取代发送方的绝对时间,实现弱终端、强基站。
- 基于无线接入网智能控制器(RIC),对传统5G基站进行增强,对带有特定识别号(如IP或者切片ID等)的上行数据增加高精度的时间戳,同时报告上行传输中可能发生数据丢失时的异常事件。
- 采用集数据存储和计算于一体的DolphinDB实时计算平台进行数据分析。针对时序数据的流数据处理,历史数据处理,机器学习建模,均可以在分布式数据库内完成。优化基础算法、内存管理与系统架构,实现毫秒级SQL和计算响应速度。
应用场景
本项目高精度时间戳的获得,将从根本上解决多源头数据存在的时间同步精度低的难题,为工业互联网和工业制造领域的大数据分析和机器学习提供高精度的可用数据,从而显著提升数据分析和预测的精度。
项目成果将首先应用于电缆、半导体等高速生产线的设备状态实时异常检测领域,比如某公司的射频电缆生产场景,其生产工序包含一条连续的流水线,和几个离散的生产步骤,各自使用独立的设备。这种依赖于独立的分散过程检测有一个缺陷,门限设置过低,容易产生误报;门限设置过高,则成品率低。因此需要对相关的数据进行关联分析,并更精准地识别是否存在生产质量问题,以及生产工序是否存在系统性误差等深度问题。本项目成果应用于这套异常检测系统,将显著提高产品的成品率。
关于我们
DolphinDB是一款专为海量时序数据设计的数据库产品,将编程语言、数据库和分布式计算从底层进行一体化设计,开创性地解决了快速开发、高速运行和简单部署三者难以兼顾的难题,为海量结构化数据的快速存储、检索、 分析及计算量身订做一站式解决方案。
DolphinDB目前被广泛应用于金融市场全域(低频、中频和高频)的数据存储、数据清洗、因子分析、策略回测、实时计算等场景中。在物联网领域,尤其是化工、电力、能源、水务等行业,DolphinDB通过联合各行业头部集成商,将DolphinDB集成到行业解决方案中,实现海量数据的存储和实时计算,为用户提供性能优异的整体解决方案。

DolphinDB Python API 离线安装教程
出于安全考虑,通常生产环境与互联网隔离,因此无法使用 pip install 在线安装 DolphinDB Python API(以下简称 Python API)。本文介绍如何离线安装 Python API 环境,包括 conda 环境和 wheel 安装两种方式。用户可根据生产环境的使用需求、应用场景自行选择。
1 环境准备
首先准备构建环境,包括在线环境与离线环境,其中在线环境用于在线收集和构建资源,离线环境用于离线安装与验证。
构建环境需要与目标环境尽可能的一致,包括操作系统版本、CPU 架构、Python 版本等。其中在线环境用于下载并构建各种资源,离线环境用于构建与测试 Python API 的安装包。
1.1 Linux 环境准备
推荐使用类似 virtual box 的虚拟化工具来制作环境。假设我们需要在 KyLin v10,x86-64, Python 3.8 的目标环境中安装 Python API,那么需要准备以下环境:
- 在线环境
操作系统:KyLin v10
CPU:Intel(R) Core(TM) i7-10700 CPU @ 2.90GHz
主机平台:VirtualBox 6.1
网络:NetWork Bridge
- 离线环境
操作系统:KyLin v10
CPU:Intel(R) Core(TM) i7-10700 CPU @ 2.90GHz
主机平台:VirtualBox 6.1
网络:HostOnly
其中 HostOnly(仅主机模式)的网络模式可以保证该机器与互联网无法连接。
1.2 Windows 环境准备
Windows 环境可以准备两台机器(可以是 PC),一台用于在线获取资源,并禁用另一台机器的网络进行离线安装测试。有关 Windows 下安装和配置 Conda 环境,详见 Windows 安装。
2 Linux conda 安装
2.1 安装 miniconda
推荐使用 miniconda,通常生产环境比较复杂,需要虚拟环境以保证隔离性。
Miniconda — conda documentation
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
sh Miniconda3-latest-Linux-x86_64.sh安装并激活 base 虚拟环境。
source ~/.bashrc使用 conda env list 验证安装已完成:

2.2 配置 miniconda
分别配置在线、离线环境的 conda:
- conda 环境配置
conda config // 在 ~/目录下会出现文件 .condarc- 编辑
~/.condarc文件
show_channel_urls: true envs_dirs: - ~/envs pkgs_dirs: - ~/pkgs2.3 在线环境下载包
- 运行以下命令下载 package
conda create -n test38 numpy=1.22.3 pandas python=3.8.13 --download-only要求 numpy 为1.18到1.22.3之间的版本, 推荐使用1.22.3版本。
2. 压缩并上传 package
压缩 .condarc pkgs_dirs 路径下的依赖包,并上传至离线环境的 pkgs 目录。
tar -zcvf pkgs.tar.gz pkgs/
md5sum pkgs.tar.gz > pkgs.tar.gz.md52.4 离线安装 conda 环境
- 上传至离线环境后,需检查下完整性:
(base) root@peter-VirtualBox:~# md5sum -c pkgs.tar.gz.md5
pkgs.tar.gz: 成功2. 校验完整性通过后,再解压:
tar -zxvf pkgs.tar.gz3. 创建虚拟环境:
conda create -n offline38 numpy pandas python=3.8.13 --offline
conda activate offline382.5 安装 DolphinDB Python API
1. 下载 whl 包
根据 CPU 架构、操作系统,从官方网站 pypi.org 下载对应的 Python API 安装包。
对应 x86_64, Python3.8 的包:
下载链接
2. pip 离线安装
pip install dolphindb-1.30.19.2-cp38-cp38-manylinux2010_x86_64.whl3. 验证安装是否成功
(offline38) root@peter-VirtualBox:~# python
Python 3.8.13 (default, Mar 28 2022, 11:38:47)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import dolphindb as ddb
>>> s = ddb.session()
>>> s
<dolphindb.session.session object at 0x7fa5d6534280>能正常生成 session 就说明已安装成功安装 Python API。
3 Linux wheel 安装
3.1 在线环境收集 wheel 包
使用 pip wheel 命令收集相关 whl 包:
pip install wheel && pip wheel dolphindb执行完成后,默认会在当前目录保存相关 whl 包。
(py38) [root@node1 ~]# ls *.whl|sort
dolphindb-1.30.19.2-cp38-cp38-manylinux2010_x86_64.whl
future-0.18.2-py3-none-any.whl
numpy-1.22.3-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
pandas-1.5.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
python_dateutil-2.8.2-py2.py3-none-any.whl
pytz-2022.2.1-py2.py3-none-any.whl
six-1.16.0-py2.py3-none-any.whl3.2 离线环境安装 wheel 包
pip install *.whl(py38) root@peter-VirtualBox:~/wpkgs# pip install *.whl
Processing ./dolphindb-1.30.19.2-cp38-cp38-manylinux2010_x86_64.whl
Processing ./future-0.18.2-py3-none-any.whl
Processing ./numpy-1.22.3-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
Processing ./pandas-1.5.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
Processing ./python_dateutil-2.8.2-py2.py3-none-any.whl
Processing ./pytz-2022.2.1-py2.py3-none-any.whl
Processing ./six-1.16.0-py2.py3-none-any.whl
Installing collected packages: pytz, six, numpy, future, python-dateutil, pandas, dolphindb
Successfully installed dolphindb-1.30.19.2 future-0.18.2 numpy-1.22.3 pandas-1.5.0 python-dateutil-2.8.2 pytz-2022.2.1 six-1.16.03.3 安装后验证
分别验证一下 whl 包和 Python API。
- pip list
(py38) root@peter-VirtualBox:~/wpkgs# pip list
Package Version
--------------- ---------
certifi 2022.9.14
dolphindb 1.30.19.2
future 0.18.2
numpy 1.22.3
pandas 1.5.0
pip 22.1.2
python-dateutil 2.8.2
pytz 2022.2.1
setuptools 63.4.1
six 1.16.0
wheel 0.37.1- Python API
(offline38) root@peter-VirtualBox:~# python
Python 3.8.13 (default, Mar 28 2022, 11:38:47)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import dolphindb as ddb
>>> s = ddb.session()
>>> s
<dolphindb.session.session object at 0x7fa5d6534280>能正常生成 session 就说明安装成功。
4 Windows conda 安装
分别在离线环境、在线环境安装并配置好 miniconda 环境。并通过在线环境构建
- dolphindb 依赖包
- dolphindb wheel 包
并上传至离线环境,来完成安装。
注:miniconda 的安装和配置分别在在线环境和离线环境完成,且目录名称须一致。
4.1 安装 miniconda
选择对应 Python 版本的 minicoda,下载 Miniconda3 Windows 64-bit 并安装。安装完成后,将 conda 加入 Windows 命令搜索路径:
此电脑 → 属性 → 查找设置 → 输入: 编辑系统环境变量 → 环境变量 → 系统环境变量
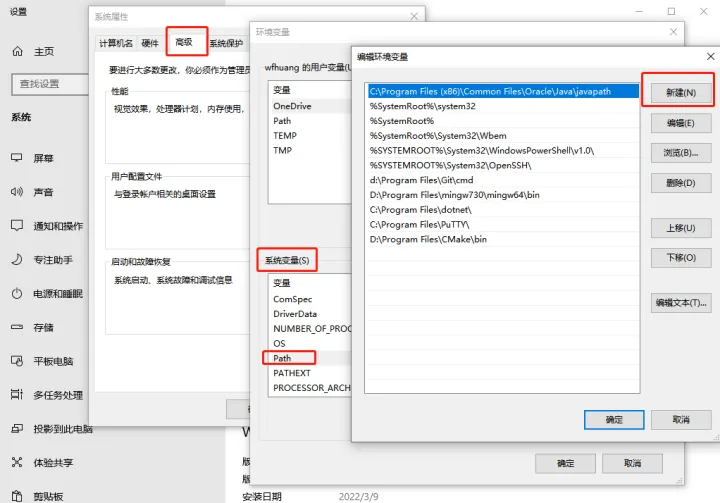
在新建中输入 condabin 目录的完整路径,如:
D:\ProgramData\Miniconda3\condabin点击确定,新开 cmd 窗口验证
C:\Users\wfhuang>conda -V
conda 4.12.04.2 配置 miniconda
设置包路径,如 D:\pkgs
D:\pythonApi>conda config --add pkgs_dirs D:\pkgs4.3 在线环境下载包
参考4.2,在在线环境中配置好包路径,并下载 DolphinDB 相关依赖包
conda create -n test38 numpy=1.22.3 future pandas python=3.8.13 --download-only在设置的 pkgs_dirs 中,会有存放相关依赖包。压缩后,包大小约为450MB
4.4 离线安装 conda 环境
- 将pkgs压缩包上传至离线环境,比较包的所占字节数,验证包是否完整。
- 校验完整性通过后,再解压至 pkgs 目录、创建虚拟环境:
conda create -n offline38 numpy pandas future python=3.8.13 --offline
conda activate offline38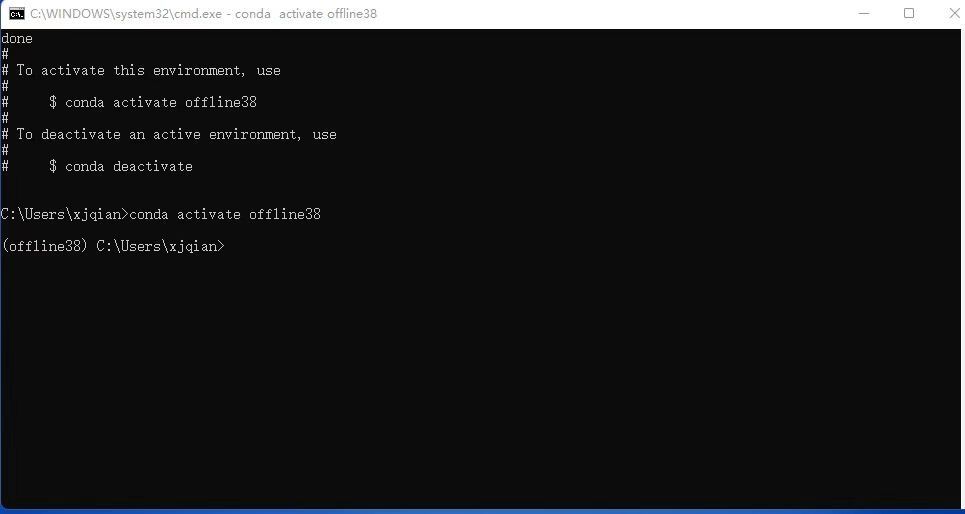
4.5 安装 Python API
- 下载 whl 包
根据 CPU 架构、操作系统,从官方网站 DolphinDB 下载对应的 Python API 安装包。
对应 Windows, x86_64, Python3.8 的包:
https://files.pythonhosted.org/packages/62/ff/382aff0a2add9ce5c779c14d0d7fbfcec62ab0748b5778731a7fe524c2af/dolphindb-1.30.19.2-cp38-cp38-win_amd64.whl
- pip 离线安装
pip install dolphindb-1.30.19.2-cp38-cp38-win_amd64.whl
- 验证安装是否成功
import dolphindb as ddb
s = ddb.session()
s.connect("192.168.1.157", 8848, "admin", "123456")
s.run("print(\"Welcome to DolphinDB!\")")
s.close()
D:\pythonApi>python hello_ddb.py
Welcome to DolphinDB!输出欢迎信息说明安装已经成功。
5 Windows wheel 安装
配置一个与目标环境相同的构建环境。例如目标环境是 x86-64, Windows server 2016, Python 3.8.10,那么可以准备一个 x86-64, Windows 10, Python 3.8.10 的 PC 环境。
5.1 在线环境收集 wheel 包
收集 Python API 的 wheel 包,并生成清单文件 requirements.txt。
1. pip wheel
使用 wheel 在当前环境构建相关 whl 包,并解决相关依赖。
pip wheel dolphindb -i https://pypi.tuna.tsinghua.edu.cn/simple使用 -i 可以指定镜像源加速构建,例如中国地区可以选择清华源。执行完成后,默认会在当前目录保存相关 whl 包。
2. pip install
安装 Python API,用于生成依赖清单文件 requirements.txt。
pip install dolphindb -i https://pypi.tuna.tsinghua.edu.cn/simple3. pip freeze
使用 freeze 解析 Python API 的依赖,并输出至文件 requirements.txt。
pip freeze dolphindb > requirements.txt上述步骤完成后,目录类似如下(不同版本会有差异)。

5.2 离线环境安装 wheel 包
将相关 whl 包、requirements.txt 上传至 Python 离线环境,并通过 pip install 安装,
使用 -r 选项从指定的清单文件 requirements.txt 中批量安装 wheel 包。
pip install -r requirements.txt
D:\pythonApi>pip install -r requirements.txt
Processing d:\pythonapi\dolphindb-1.30.19.2-cp38-cp38-win_amd64.whl
Processing d:\pythonapi\numpy-1.22.3-cp38-cp38-win_amd64.whl
Processing d:\pythonapi\pandas-1.5.1-cp38-cp38-win_amd64.whl
Processing d:\pythonapi\python_dateutil-2.8.2-py2.py3-none-any.whl
Processing d:\pythonapi\pytz-2022.6-py2.py3-none-any.whl
Processing d:\pythonapi\six-1.16.0-py2.py3-none-any.whl
Collecting future==0.18.2
Using cached future-0.18.2-py3-none-any.whl
Installing collected packages: six, pytz, python-dateutil, numpy, pandas, future, dolphindb
Successfully installed dolphindb-1.30.19.2 future-0.18.2 numpy-1.22.3 pandas-1.5.1 python-dateutil-2.8.2 pytz-2022.6 six-1.16.05.3 安装后验证
分别验证下 whl 包和 Python API 。
- pip list
C:\pythonApi>pip list
Package Version
--------------- ---------
dolphindb 1.30.19.2
future 0.18.2
numpy 1.22.3
pandas 1.5.1
pip 21.1.1
python-dateutil 2.8.2
pytz 2022.6
setuptools 56.0.0
six 1.16.0- 验证安装是否成功
import dolphindb as ddb
s = ddb.session()
s.connect("192.168.1.157", 8848, "admin", "123456")
s.run("print(\"Welcome to DolphinDB!\")")
s.close()
D:\pythonApi>python hello_ddb.py
Welcome to DolphinDB!输出欢迎信息说明安装已经成功。
6 总结
总体而言,wheel 包安装比较简单快捷,而 conda 安装相对复杂,但是可以构建一个隔离环境。
| 安装方式 | 优点 | 不足 |
|---|---|---|
| conda | 提供虚拟环境 | 整个安装包大概在500M左右,上传至生产环境比较耗时,且需要校验完整性 |
| wheel | 简单快捷,安装包小 | 无法提供虚拟环境,可能与现有的 Python 环境相冲突 |
7 附录
7.1 pip 常用命令
pip list // 列出当前安装的包
pip freeze packageA // 列出 packageA 的依赖信息
pip wheel packageA // 构建 packageA 的依赖 wheel 包
pip search packageA // 在官方仓库 PyPI 搜索 packageA7.2 conda 常用命令
- 离线创建虚拟环境
conda create -n py38 python=3.8.13 --offline- 激活/关闭虚拟环境
conda env list //查看所有虚拟环境
conda activate py38 //激活 py38
conda deactivate //退出当前虚拟环境- 清理并删除 conda 环境:
conda deactivate
conda remove -n offline38 --all7.3 常见问题处理
Q: conda 离线安装缺失包
PackagesNotFoundError: The following packages are not available from current channels:
- pandas
- python=3.8.13
- numpyA: 检查下 pkgs_dirs 是否设置正确,以及在该目录下是否有提示信息中的包。不能有任何中间目录,例如设置 conda 的包目录为 pkgs,那么 pkgs/pkgs/numpy 是无法被 conda 找到的。
Q: wheel 包未安装
error: invalid command ''bdist_wheel''A: 使用 pip 安装 wheel
pip install wheelQ: future 包缺失
Failed to build future
ERROR: Failed to build one or more wheels
WARNING: Ignoring invalid distribution -ip (d:\program files\python3.7\lib\site-packages)A: 可以手动收集下 future 包,并上传至离线环境。
pip wheel futureQ: 构建 future whl 包失败
Failed to build future
ERROR: Failed to build one or more wheels
WARNING: Ignoring invalid distribution -ip (d:\program files\python3.7\lib\site-packages)A: 因 pip 下载、安装未成功而导致的环境异常,进入 pip --version 输出信息中的 site-packages/pip 目录,删除~开头的一些临时文件。
(base) [root@node1 ~]# pip --version
pip 21.2.4 from /root/miniconda3/lib/python3.9/site-packages/pip (python 3.9)Q: Python API 安装失败
ERROR: Could not find a version that satisfies the requirement dolphindb (from versions: none)A: 安装环境与 whl 包不匹配导致。可以按如下步骤处理:
- 通过 PyPI 确认是否存在支持当前操作系统(例如 Linux ARM 架构、Mac M1等)的 DolphinDB API 安装包。若存在,则将该 whl 包下载至本地。
- 通过如下命令查看适合当前系统环境支持的 whl 包后缀。
pip debug --verbose- 根据 Compatible tags 的显示信息,将 DolphinDB 的 whl 包名修改为适合系统架构的名称。以 Mac(x86_64) 系统为例:安装包名为“dolphindb-1.30.19.2-cp37-cp37m-macosx_10_16_x86_64.whl”。但查询到 pip 支持的当前系统版本为10.13,则使用“10_13”替换 whl 包名中的“10_16”。
- 尝试安装更名后的 whl 包。
若执行完上述操作后,仍无法安装或导入,可在 DolphinDB 社区 中进行反馈。

DolphinDB SQL 案例教程
本教程重点介绍了一些常见场景下的SQL编写案例,通过优化前后性能对比或正确编写方法介绍,说明DolphinDB SQL脚本的使用技巧,案例共分四类:条件过滤相关案例、分布式表相关案例、分组计算相关案例及元编程相关案例,共计22个应用实例,案例中用到的测试数据为基于真实数据结构模拟的2000只股票快照数据。
1 测试环境说明
处理器:Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz
核数:64
内存:512 GB
操作系统:CentOS Linux release 7.9
License:免费版License,CPU 2核,内存 8GB
DolphinDB Server 版本:DolphinDB_Linux64_V2.00.4,单节点模式部署
DolphinDB GUI 版本:DolphinDB_GUI_V1.30.15
以下章节案例中所用到的2020年06月测试数据为上交所 Level-1 快照数据,基于真实数据结构模拟2000只股票快照数据,基于 OLAP 与 TSDB 存储引擎的建库建表、数据模拟、数据插入脚本如下:
model = table(1:0, `SecurityID`DateTime`PreClosePx`OpenPx`HighPx`LowPx`LastPx`Volume`Amount`BidPrice1`BidPrice2`BidPrice3`BidPrice4`BidPrice5`BidOrderQty1`BidOrderQty2`BidOrderQty3`BidOrderQty4`BidOrderQty5`OfferPrice1`OfferPrice2`OfferPrice3`OfferPrice4`OfferPrice5`OfferQty1`OfferQty2`OfferQty3`OfferQty4`OfferQty5, [SYMBOL, DATETIME, DOUBLE, DOUBLE, DOUBLE, DOUBLE, DOUBLE, LONG, DOUBLE, DOUBLE, DOUBLE, DOUBLE, DOUBLE, DOUBLE, LONG, LONG, LONG, LONG, LONG, DOUBLE, DOUBLE, DOUBLE, DOUBLE, DOUBLE, LONG, LONG, LONG, LONG, LONG])
// OLAP 存储引擎建库建表
dbDate = database("", VALUE, 2020.06.01..2020.06.07)
dbSecurityID = database("", HASH, [SYMBOL, 10])
db = database("dfs://Level1", COMPO, [dbDate, dbSecurityID])
createPartitionedTable(db, model, `Snapshot, `DateTime`SecurityID)
// TSDB 存储引擎建库建表
dbDate = database("", VALUE, 2020.06.01..2020.06.07)
dbSymbol = database("", HASH, [SYMBOL, 10])
db = database("dfs://Level1_TSDB", COMPO, [dbDate, dbSymbol], engine="TSDB")
createPartitionedTable(db, model, `Snapshot, `DateTime`SecurityID, sortColumns=`SecurityID`DateTime)
def mockHalfDayData(Date, StartTime) {
t_SecurityID = table(format(600001..602000, "000000") + ".SH" as SecurityID)
t_DateTime = table(concatDateTime(Date, StartTime + 1..2400 * 3) as DateTime)
t = cj(t_SecurityID, t_DateTime)
size = t.size()
return table(t.SecurityID as SecurityID, t.DateTime as DateTime, rand(100.0, size) as PreClosePx, rand(100.0, size) as OpenPx, rand(100.0, size) as HighPx, rand(100.0, size) as LowPx, rand(100.0, size) as LastPx, rand(10000, size) as Volume, rand(100000.0, size) as Amount, rand(100.0, size) as BidPrice1, rand(100.0, size) as BidPrice2, rand(100.0, size) as BidPrice3, rand(100.0, size) as BidPrice4, rand(100.0, size) as BidPrice5, rand(100000, size) as BidOrderQty1, rand(100000, size) as BidOrderQty2, rand(100000, size) as BidOrderQty3, rand(100000, size) as BidOrderQty4, rand(100000, size) as BidOrderQty5, rand(100.0, size) as OfferPrice1, rand(100.0, size) as OfferPrice2, rand(100.0, size) as OfferPrice3, rand(100.0, size) as OfferPrice4, rand(100.0, size) as OfferPrice5, rand(100000, size) as OfferQty1, rand(100000, size) as OfferQty2, rand(100000, size) as OfferQty3, rand(100000, size) as OfferQty4, rand(100000, size) as OfferQty5)
}
def mockData(DateVector, StartTimeVector) {
for(Date in DateVector) {
for(StartTime in StartTimeVector) {
data = mockHalfDayData(Date, StartTime)
// OLAP 存储引擎分布式表插入模拟数据
loadTable("dfs://Level1", "Snapshot").append!(data)
// TSDB 存储引擎分布式表插入模拟数据
loadTable("dfs://Level1_TSDB", "Snapshot").append!(data)
}
}
}
mockData(2020.06.01..2020.06.02, 09:30:00 13:00:00)
2 条件过滤相关案例
where 条件子句包含一个或多个条件表达式,根据表达式指定的过滤条件,可以过滤出满足需求的记录。
条件表达式中可以使用 DolphinDB 内置函数,如聚合、序列、向量函数,也可以使用用户自定义函数。需要注意的是,DolphinDB 不支持在分布式查询的 where 子句中使用聚合函数,如sum、count。因为执行聚合函数之前,分布式查询需要通过 where 子句来筛选相关分区的数据,达到分区剪枝的效果,减少查询耗时。如果聚合函数出现在where子句中,则分布式查询不能缩窄相关分区范围。
2.1 where 条件子句使用 in 关键字
场景:数据表 t1 含有股票的某些信息,数据表 t2 含有股票的行业信息,需要根据股票的行业信息进行过滤。
首先,载入测试数据库中的表 “Snapshot” 赋给变量 t1,并模拟构建行业信息数据表 t2,示例如下:
t1 = loadTable("dfs://Level1", "Snapshot")
SecurityIDs = exec distinct SecurityID from t1 where date(DateTime) = 2020.06.01
t2 = table(SecurityIDs as SecurityID,
take(`Mul`IoT`Eco`Csm`Edu`Food, SecurityIDs.size()) as Industry)
优化前:
将数据表 t1 与数据表 t2 根据 SecurityID 字段进行 left join,然后指定 where 条件进行过滤,示例如下:
timer res1 = select SecurityID, DateTime
from lj(t1, t2, `SecurityID)
where date(DateTime) = 2020.06.01, Industry=`Edu
查询耗时 336 ms。
需要注意的是,以上脚本中的 timer 函数通常用于计算一行或一段脚本的执行时间,该时间指的是脚本在 DolphinDB Server 端的运行耗时,而不包括脚本运行结果集返回到客户端的耗时。若结果集数据量过大,序列化/反序列化以及网络传输的耗时可能会远远超过脚本在服务器上的运行耗时。
优化后:
从数据表 t2 获取行业为 “Edu” 的股票代码向量,并使用 in 关键字指定条件范围,示例如下:
SecurityIDs = exec SecurityID from t2 where Industry="Edu"
timer res2 = select SecurityID, DateTime
from t1
where date(DateTime) = 2020.06.01, SecurityID in SecurityIDs
查询耗时 72 ms。
each(eqObj, res1.values(), res2.values()) // true
each 函数对表的每列分别通过 eqObj 比较,返回均为 true,说明优化前后返回的结果相同。但与优化前写法相比,优化后写法查询性能提升约4倍。这是因为,在 SQL 语句中,表连接的耗时远高于 where 子句中的过滤条件的耗时,因此在能够使用字典或 in 关键字的情况下应避免使用 join。
2.2 分组数据过滤
场景:截取单日全市场股票交易快照数据,筛选出每只股票交易量最大的前 25% 的记录。
首先,载入测试数据库表并将该表对象赋值给变量 snapshot ,之后可以直接引用变量 snapshot ,示例如下:
snapshot = loadTable("dfs://Level1", "Snapshot")
使用 context by 对于股票分组,并根据 Volume 字段计算 75% 分位点的线性插值作为最小值,示例如下:
timer res1 = select * from snapshot
where date(DateTime) = 2020.06.01
context by SecurityID having Volume >= percentile(Volume, 75, "linear")
context by 是 DolphinDB SQL 引入的一个关键词,用于分组计算。与 group by 用于聚合不同,context by 只是对数据分组而不做聚合操作,因此不改变数据的记录数。
having 子句总是跟在 group by 或者 context by 后,用来将结果进行过滤,只返回满足指定条件的聚合函数值的组结果。having 与 group by 搭配使用时,表示是否输出某个组的结果。having 与 context by 搭配使用时,既可以表示是否输出这个组的结果,也可以表示输出组中的哪些行。
场景:承接以上场景,选出每只股票交易量最大的 25% 的记录后,计算 LastPx 的标准差。
优化前:
使用 context by 对股票分组,并根据 Volume 字段计算 75% 位置处的线性插值作为过滤条件的最小值,再根据 group by 对股票分组,并计算标准差,最后使用 order by 对于股票排序,示例如下:
timer select std(LastPx) as std from (
select SecurityID, LastPx from snapshot
where date(DateTime) = 2020.06.01
context by SecurityID
having Volume >= percentile(Volume, 75, "linear"))
group by SecurityID
order by SecurityID
耗时 242 ms。
优化后:
使用 group by 对股票分组,aggrTopN 高阶函数选择交易量最大的 25% 的记录,并计算标准差。示例如下:
timer select aggrTopN(std, LastPx, Volume, 0.25, false) as std from snapshot
where date(DateTime) = 2020.06.01
group by SecurityID
order by SecurityID
耗时 124 ms。
优化前先把数据分组并进行过滤,合并数据后再分组计算聚合值。优化后,在数据分组后,直接进行过滤和聚合,减少了中间步骤,从而提升了性能。
2.3 where 条件子句使用逗号或 and
where 子句中多条件如果使用 “,” 进行连接时,在查询时会按照顺序对 “,” 前的条件层层进行过滤;若使用 and 进行连接时,会对所有条件在原表内分别进行筛选后再将结果取交集。
下面将通过几个示例,比较使用 and 和逗号再不同场景下进行条件过滤的异同。
首先,产生模拟数据,示例如下:
N = 10000000
t = table(take(2019.01.01..2019.01.03, N) as date,
take(`C`MS`MS`MS`IBM`IBM`IBM`C`C$SYMBOL, N) as sym,
take(49.6 29.46 29.52 30.02 174.97 175.23 50.76 50.32 51.29, N) as price,
take(2200 1900 2100 3200 6800 5400 1300 2500 8800, N) as qty)
根据过滤条件是否使用序列相关函数,如 deltas, ratios, ffill, move, prev, cumsum 等,可以分为以下两种情况。
2.3.1 过滤条件与序列无关
示例代码如下:
timer(10) t1 = select * from t where qty > 2000, date = 2019.01.02, sym = `C
timer(10) t2 = select * from t where qty > 2000 and date = 2019.01.02 and sym = `C
each(eqObj, t1.values(), t2.values()) // true
以上两个查询耗时分别为902 ms、930 ms。此时,使用逗号与 and 的查询性能相差不大。
测试不同条件先后顺序对于查询性能与查询结果的影响,示例代码如下:
timer(10) t3 = select * from t where date = 2019.01.02, sym = `C, qty > 2000
timer(10) t4 = select * from t where date = 2019.01.02 and sym = `C and qty > 2000
each(eqObj, t1.values(), t3.values()) // true
each(eqObj, t2.values(), t4.values()) // true
以上两个查询耗时分别为669 ms、651 ms。此时,使用逗号与 and 的查询性能相差不大。
说明过滤条件与序列无关时,条件先后顺序对于查询结果无影响。但性能方面 t3(t4) 较 t1(t2) 提升约30%,这是因为 date 字段比 qty 字段筛选性更强。
2.3.2 过滤条件与序列有关
示例代码如下:
timer(10) t1 = select * from t where ratios(qty) > 1, date = 2019.01.02, sym = `C
timer(10) t2 = select * from t where ratios(qty) > 1 and date = 2019.01.02 and sym = `C
each(eqObj, t1.values(), t2.values()) // true
以上两个查询耗时分别为1503 ms、1465 ms。
此时,使用逗号与 and 的查询性能相差无几。序列条件作为第一个条件,使用逗号连接时,首先按照原表中数据的顺序进行计算,后面条件与序列无关,所以查询结果与 and 连接时保持一致。
测试不同条件先后顺序对于查询性能与查询结果的影响,示例代码如下:
timer(10) t3 = select * from t where date = 2019.01.02, sym = `C, ratios(qty) > 1
timer(10) t4 = select * from t where date = 2019.01.02 and sym = `C and ratios(qty) > 1
each(eqObj, t2.values(), t4.values()) // true
each(eqObj, t1.values(), t3.values()) // false
以上两个查询耗时分别为507 ms、1433 ms,第一个each函数返回均为true,即 t2 与 t4 查询结果相同;第二个each 函数返回均为 false,即 t1 与 t3 查询结果不同。
说明过滤条件与序列相关时,对于使用 and 连接的查询语句,条件先后顺序对于查询结果无影响,性能方面亦无差别;对于使用逗号的查询语句,序列条件在后,性能虽有提升,但查询结果不同。
综合上述测试结果分析可知:
- 过滤条件与序列无关时,使用逗号或 and 均可,这是因为系统内部对于 and 做了优化,即将 and 转换为逗号,逗号会按照条件先后顺序层层过滤,因此条件先后顺序不同,执行查询时会有所差别,建议尽可能将过滤能力较强的条件放在前面,以减少后面过滤条件需要查询的数据量;
- 过滤条件与序列相关时,必须使用 and,会对所有过滤条件在原表内分别筛选,再将过滤结果取交集,因此条件先后顺序不影响查询结果与性能。
3 分布式表相关案例
分布式查询和普通查询的语法并无差异,理解分布式查询的工作原理有助于编写高效的 SQL 查询语句。系统首先根据 where 条件子句确定查询涉及的分区,然后分解查询语句为多个子查询,并把子查询发送到相关分区所在的位置(map),最后在发起节点汇总所有分区的查询结果(merge),并进行进一步的查询(reduce)。
3.1 分区剪枝
场景:查询每只股票在某个时间范围内的记录数目。
首先,载入测试数据库下的表 “Snapshot” 并将该表对象赋值给变量 snapshot,示例如下:
snapshot = loadTable("dfs://Level1", "Snapshot")
优化前:
where条件子句根据日期过滤时,使用temporalFormat函数对于日期进行格式转换,如下:
timer t1 = select count(*) from snapshot
where temporalFormat(DateTime, "yyyy.MM.dd") >= "2020.06.01" and temporalFormat(DateTime, "yyyy.MM.dd") <= "2020.06.02"
group by SecurityID
查询耗时 4145 ms。
优化后:
使用 date 函数将 DateTime 字段转换为 DATE 类型,如下:
timer t2 = select count(*) from snapshot
where date(DateTime) between 2020.06.01 : 2020.06.02 group by SecurityID
查询耗时 92 ms。
each(eqObj, t1.values(), t2.values()) // true
与优化前写法相比,查询性能提升数十倍。DolphinDB 在解决海量数据的存取时,并不提供行级的索引,而是将分区作为数据库的物理索引。系统在执行分布式查询时,首先根据 where 条件确定需要的分区。大多数分布式查询只涉及分布式表的部分分区,系统无需全表扫描,从而节省大量时间。但若不能根据 where 条件确定分区,进行全表扫描,就会大大降低查询性能。
可以看到以上优化前的脚本,分区字段套用了 temporalFormat 函数先对所有日期进行转换,因此系统无法做分区剪枝。
下面例举了部分其它导致系统 无法做分区剪枝 的案例:
例1:对分区字段进行运算。
select count(*) from snapshot where date(DateTime) + 1 > 2020.06.01
例2:使用链式比较。
select count(*) from snapshot where 2020.06.01 < date(DateTime) < 2020.06.03
例3:过滤条件未使用分区字段。
select count(*) from snapshot where Volume < 500
例4:与分区字段比较时使用其它列。AnnouncementDate字段非snapshot表中字段,此处仅为举例说明。
select count(*) from snapshot where date(DateTime) < AnnouncementDate - 3
3.2 GROUP BY并行查询
场景:对在某个时间范围内所有股票,标记涨跌,并计算第一档行情买卖双方报价之差、总交易量等指标。
首先,载入测试数据库中的表,示例如下:
snapshot = loadTable("dfs://Level1", "Snapshot")
优化前:
首先,筛选 2020年06月01日09:30:00 以后的数据,收盘价高于开盘价的记录,标志位设置为1;否则,标志位设置为0,将结果赋给一个内存表。然后,使用 group by 子句根据 SecurityID, DateTime, Flag三个字段分组,并统计分组内 OfferPrice1 的记录数以及 Volume 的和,示例如下:
timer {
tmp_t = select *, iif(LastPx > OpenPx, 1, 0) as Flag
from snapshot
where date(DateTime) = 2020.06.01, second(DateTime) >= 09:30:00
t1 = select iif(max(OfferPrice1) - min(BidPrice1) == 0, 0, 1) as Price1Diff, count(OfferPrice1) as OfferPrice1Count, sum(Volume) as Volumes
from tmp_t
group by SecurityID, date(DateTime) as Date, Flag
}
查询耗时 6249 ms。
优化后:
不再引入中间内存表,直接从分布式表进行查询计算。示例如下:
timer t2 = select iif(max(OfferPrice1) - min(BidPrice1) == 0, 0, 1) as Price1Diff, count(OfferPrice1) as OfferPrice1Count, sum(Volume) as Volumes
from snapshot
where date(DateTime) = 2020.06.01, second(DateTime) >= 09:30:00
group by SecurityID, date(DateTime) as Date, iif(LastPx > OpenPx, 1, 0) as Flag
查询耗时 1112 ms。
each(eqObj, t1.values(), (select * from t2 order by SecurityID, Date, Flag).values()) // true
与优化前写法相比,优化后写法查询性能提升约 6 倍。
性能的提升来自于两个方面:
(1)优化前的写法先把分区数据合并到一个内存表,然后再用 group by 分组计算,比优化后的写法多了合并与拆分的两个步骤。
(2)优化后的写法直接对分布式表进行分组计算,充分利用 CPU 多核并行计算。而优化前的写法合并成一个内存表后,只利用单核进行分组计算。
作为一个通用规则,对于分布式表的查询和计算,尽可能不要生成中间结果,直接在原始的分布式表上做计算,性能最优。
3.3 分组查询使用 map 关键字
场景:查询每只股票每分钟的记录数目。
首先,载入测试数据库表:
snapshot = loadTable("dfs://Level1", "Snapshot")
优化前:
timer result = select count(*) from snapshot group by SecurityID, bar(DateTime, 60)
查询耗时 996 ms。
优化后:
使用map关键字。
timer result = select count(*) from snapshot group by SecurityID, bar(DateTime, 60) map
查询耗时 864 ms。与优化前写法相比,查询性能提升约10%~20%。
优化前分组查询或计算时分为两个步骤:
- 每个分区内部计算;
- 所有分区的结果进行进一步计算,以确保最终结果的正确。
如果分区的粒度大于分组的粒度,那么第一步骤完全可以保证结果的正确。此场景中,一级分区为粒度为“天”,大于分组的粒度”分钟”,可以使用 map 关键字,避免第二步骤的计算开销,从而提升查询性能。
4 分组计算相关案例
4.1 查询最新的 N 条记录
场景:获取每只股票最新的10条记录。
仅对2020年06月01日的数据进行分组求 TOP 10。context by 子句对数据进行分组,返回结果中每一组的行数和组内元素数量相同,再结合 csort 和 top 关键字,可以获取每组数据的最新记录。以行数为960万行的数据为例:
OLAP 存储引擎:
timer t1 = select * from loadTable("dfs://Level1", "Snapshot") where date(DateTime) = 2020.06.01 context by SecurityID csort DateTime limit -10
查询耗时 4289 ms。
TSDB 存储引擎:
timer t2 = select * from loadTable("dfs://Level1_TSDB", "Snapshot") where date(DateTime) = 2020.06.01 context by SecurityID csort DateTime limit -10
查询耗时 1122 ms。
each(eqObj, t1.values(), t2.values()) //true
TSDB 是 DolphinDB 2.0 版本推出的存储引擎,引入了排序列,相当于对分区内部建立了一个索引。因此对于时间相关、单点查询场景,性能较OLAP存储引擎会有进一步提升。
此例中,TSDB 存储引擎的查询性能较 OLAP 存储引擎提升约 4 倍。
context by 是 DolphinDB SQL 独有的创新,是对标准 SQL 语句的拓展。在关系型数据库管理系统中,一张表由行的集合组成,行之间没有顺序。可以使用如 min, max, avg, stdev 等聚合函数来对行进行分组,但是不能对分组内的行使用序列相关的聚合函数,比如first, last等,或者使用顺序敏感的滑动窗口函数和累积计算函数,如cumsum, cummax, ratios, deltas等。
DolphinDB 使用列式存储引擎,因此能更好地支持对时间序列的数据进行处理,而其特有的 context by 子句使组内处理时间序列数据更加方便。
4.2 计算滑动 VWAP
场景:一个内存表包含3000只股票,每只股票10000条记录,使用循环与 context by 两种方法分别计算mwavg (移动加权平均,Moving Weighted Average),比较二者性能差异。
首先,产生模拟数据,示例如下:
syms = format(1..3000, "SH000000")
N = 10000
t = cj(table(syms as symbol), table(rand(100.0, N) as price, rand(10000, N) as volume))
优化前:
使用循环,每一次取出某只股票相应的10000条记录的价格、交易量字段,计算 mwavg,共执行3000次,然后合并每一次的计算结果。
arr = array(ANY, syms.size())
timer {
for(i in 0 : syms.size()) {
price_vec = exec price from t where symbol = syms[i]
volume_vec = exec volume from t where symbol = syms[i]
arr[i] = mwavg(price_vec, volume_vec, 4)
}
res1 = reduce(join, arr)
}
查询耗时 25 min。
优化后:
使用 context by,根据股票分组,每个分组内部分别计算 mwavg。
timer res2 = select mwavg(price, volume, 4) from t
context by symbol
查询耗时 3176 ms。
each(eqObj, res1, res2[`mwavg_price]) // true
两种方法的性能相差约 400 多倍。
原因是,context by 仅对全表数据扫描一次,并对所有股票分组,再对每组分别进行计算;而 for 循环每一次循环都要扫描全表以获取某只股票相应的10000记录,所以耗时较长。
4.3 计算累积 VWAP
场景:每分钟计算每只股票自开盘到现在的所有交易的 vwap (交易量加权平均价格,Volume Weighted Average Price)。
首先,载入测试数据库表:
snapshot = loadTable("dfs://Level1", "Snapshot")
使用 group by 对股票分组,再对时间做分钟聚合并使用 cgroup by 分组,计算 vwap;然后使用 order by 子句对分组计算结果排序,最后对每只股票分别计算累计值。
timer result = select wavg(LastPx, Volume) as vwap
from snapshot
group by SecurityID
cgroup by minute(DateTime) as Minute
order by SecurityID, Minute
查询耗时 1499 ms。
cgroup by (cumulative group) 为 DolphinDB SQL 独有的功能,是对标准 SQL 语句的拓展,可以进行累计分组计算,第一次计算使用第一组记录,第二次计算使用前两组记录,第三次计算使用前三组记录,以此类推。
使用cgroup by时,必须同时使用 order by 对分组计算结果进行排序。cgroup by 的 SQL 语句仅支持以下聚合函数:sum, sum2, sum3, sum4, prod, max, min, first, last, count, size, avg, std, var, skew, kurtosis, wsum, wavg, corr, covar, contextCount, contextSum, contextSum2。
4.4 计算 N 股 VWAP
场景:计算每只股票最近 1000 shares 相关的所有 trades 的 vwap。
筛选1000 shares 时可能出现以下情形,如 shares 为100、300、600的3个 trades 之和恰好为1000,或者shares 为900、300两个 trades 之和超过1000。首先需要找到参与计算的 trades,使得 shares 之和恰好超过1000,且保证减掉时间点最新的一个 trade 后,shares 之和小于1000,然后计算一下它们的 vwap。
首先,产生模拟数据,示例如下:
n = 500000
t = table(rand(string(1..4000), n) as sym, rand(10.0, n) as price, rand(500, n) as vol)
优化前:
使用group by对于股票进行分组,针对每只股票分别调用自定义聚合函数 lastVolPx1,针对所有 trades 采用循环计算,并判断 shares 是否恰好超过 bound,最后计算 vwag。如下:
defg lastVolPx1(price, vol, bound) {
size = price.size()
cumSum = 0
for(i in 0:size) {
cumSum = cumSum + vol[size - 1 - i]
if(cumSum >= bound) {
price_tmp = price.subarray(size - 1 - i :)
vol_tmp = vol.subarray(size - 1 - i :)
return wavg(price_tmp, vol_tmp)
}
if(i == size - 1 && cumSum < bound) {
return wavg(price, vol)
}
}
}
timer lastVolPx_t1 = select lastVolPx1(price, vol, 1000) as lastVolPx from t group by sym
查询耗时 187 ms。
优化后:
使用 group by 对股票进行分组,针对每支股票分别调用自定义聚合函数 lastVolPx2,计算累积交易量向量,以及恰好满足 shares 大于 bound 的起始位置,最后计算 vwag。如下:
defg lastVolPx2(price, vol, bound) {
cumVol = vol.cumsum()
if(cumVol.tail() <= bound)
return wavg(price, vol)
else {
start = (cumVol <= cumVol.tail() - bound).sum()
return wavg(price.subarray(start:), vol.subarray(start:))
}
}
timer lastVolPx_t2 = select lastVolPx2(price, vol, 1000) as lastVolPx from t group by sym
查询耗时 73 ms。
each(eqObj, lastVolPx_t1.values(), lastVolPx_t2.values()) // true
与优化前写法相比,lastVolPx2 使用了向量化编程方法,性能提升一倍多。因此,编写 DolphinDB SQL 时,应当尽可能地使用向量化函数,避免使用循环。
4.5 分段统计股票价格变化率
场景:已知股票市场快照数据,根据其中某个字段,分段统计并计算每只股票价格变化率。
仅对2020年06月01日的数据举例说明。首先,使用 group by 对股票以及 OfferPrice1 字段连续相同的数据分组,然后计算每只股票第一档价格的变化率,示例如下:
timer t = select last(OfferPrice1) \ first(OfferPrice1) - 1
from loadTable("dfs://Level1", "Snapshot")
where date(DateTime) = 2020.06.01
group by SecurityID, segment(OfferPrice1, false)
查询耗时 511 ms。
segment 函数用于向量分组,将连续相同的元素分为一组,返回与输入向量等长的向量。下一个案例中也使用了segment 函数分组,以展示该函数在连续区间分组计算时的易用性。
4.6 计算不同连续区间的最值
场景:期望根据某个字段的值,获取大于或等于目标值的连续区间窗口,并在每个窗口内取该字段最大值的第一条记录。
首先,产生模拟数据,示例如下:
t = table(2021.09.29 + 0..15 as date,
0 0 0.3 0.3 0 0.5 0.3 0.5 0 0 0.3 0 0.4 0.6 0.6 0 as value)
targetVal = 0.3
优化前:
自定义一个函数 generateGrp,如果当前值大于或等于目标值,记录下当前记录对应的分组 ID;如果下一条记录的值小于目标值,分组 ID 加 1,以保证不同的连续数据划分到不同的分组。
def generateGrp(targetVal, val) {
arr = array(INT, val.size())
n = 1
for(i in 0 : val.size()) {
if(val[i] >= targetVal) {
arr[i] = n
if(val[i + 1] < targetVal) n = n + 1
}
}
return arr
}
使用 context by 根据分组 ID 分组,并结合 having 语句过滤最大值,limit 语句限制返回第一条记录。
timer(1000) {
tmp = select date, value, generateGrp(targetVal, value) as grp from t
res1 = select date, value from tmp where grp != 0
context by grp
having value = max(value) limit 1
}
查询耗时 142 ms。
优化后:
使用 segment 函数结合 context by 语句对大于或等于目标值的连续数据分组,并使用 having 语句过滤。
timer(1000) res2 = select * from t
context by segment(value >= targetVal)
having value >= targetVal and value = max(value) limit 1
查询耗时 123 ms。
each(eqObj, res1.values(), res2.values()) // true
与优化前写法相比,优化后写法查询性能提升约 10%。
segment 函数一般用于序列相关的分组,与循环相比,性能略有提升,可以化繁为简,使代码更为优雅。
4.7 不同聚合方式计算指标
场景:期望根据不同的标签对于某个字段采用不同的聚合方式。
例如,标签为 code1 时,每10分钟取 “max”;标签为 code2 时,每10分钟取 “min”;标签为 code3 时,每10分钟取 “avg”。最后获得一个行转列宽表。
首先,产生模拟数据,示例如下:
N = 1000000
t = table("code" + string(take(1..3, N)) as tag,
sort(take([2021.06.28T00:00:00, 2021.06.28T00:10:00, 2021.06.28T00:20:00], N)) as time,
take([1.0, 2.0, 9.1, 2.0, 3.0, 9.1, 9.1, 2.0, 3.0], N) as value)
构建一个字典,标签为键,函数名称为值。使用 group by 对时间、标签分组,并调用自定义聚合函数,实现对不同标签的 value 进行不同的运算。
codes = dict(`code1`code2`code3, [max, min, avg])
defg func(tag, value, codes) : codes[tag.first()](value)
timer {
t_tmp = select func(tag, value, codes) as value from t
group by tag, interval(time, 10m, "null") as time
t_result = select value from t_tmp pivot by time, tag
}
查询耗时 76 ms。
上例中使用的 interval 函数只能在 group by 子句中使用,不能单独使用,缺失值的填充方式可以为:prev, post, linear, null, 具体数值和 none。
4.8 计算股票收益波动率
场景:已知某只股票过去十年的日收益率,期望按月计算该股票的波动率。
首先,产生模拟数据,示例如下:
N = 3653
t = table(2011.11.01..2021.10.31 as date,
take(`AAPL, N) as code,
rand([0.0573, -0.0231, 0.0765, 0.0174, -0.0025, 0.0267, 0.0304, -0.0143, -0.0256, 0.0412, 0.0810, -0.0159, 0.0058, -0.0107, -0.0090, 0.0209, -0.0053, 0.0317, -0.0117, 0.0123], N) as rate)
使用 interval 函数对于日期按月分组,并计算标准差。其中,fill 类型为 prev,表示使用前一个值填充缺失值。
timer res = select std(rate) from t group by code, interval(month(date), 1, "prev")
查询耗时 1.8 ms。
4.9 计算股票组合的价值
场景:进行指数套利交易回测时,计算给定股票组合的价值。
当数据量极大时,一般数据分析系统进行回测时,对系统内存及速度的要求极高。以下案例,展现了使用 DolphinDB SQL 语言可极为简洁地进行此类计算。
为了简化起见,假定某个指数仅由两只股票组成:AAPL 与 FB。模拟数据如下:
syms = take(`AAPL, 6) join take(`FB, 5)
time = 2019.02.27T09:45:01.000000000 + [146, 278, 412, 445, 496, 789, 212, 556, 598, 712, 989]
prices = 173.27 173.26 173.24 173.25 173.26 173.27 161.51 161.50 161.49 161.50 161.51
quotes = table(take(syms, 100000) as Symbol,
take(time, 100000) as Time,
take(prices, 100000) as Price)
weights = dict(`AAPL`FB, 0.6 0.4)
ETF = select Symbol, Time, Price*weights[Symbol] as weightedPrice from quotes
优化前:
首先,需要将原始数据表的3列(时间,股票代码,价格)转换为同等长度但是宽度为指数成分股数量加1的数据表,然后向前补充空值(forward fill NULLs),进而计算每行的指数成分股对指数价格的贡献之和。示例如下:
timer {
colAAPL = array(DOUBLE, ETF.Time.size())
colFB = array(DOUBLE, ETF.Time.size())
for(i in 0:ETF.Time.size()) {
if(ETF.Symbol[i] == `AAPL) {
colAAPL[i] = ETF.weightedPrice[i]
colFB[i] = NULL
}
if(ETF.Symbol[i] == `FB) {
colAAPL[i] = NULL
colFB[i] = ETF.weightedPrice[i]
}
}
ETF_TMP1 = table(ETF.Time, ETF.Symbol, colAAPL, colFB)
ETF_TMP2 = select last(colAAPL) as colAAPL, last(colFB) as colFB from ETF_TMP1 group by time, Symbol
ETF_TMP3 = ETF_TMP2.ffill()
t1 = select Time, rowSum(colAAPL, colFB) as rowSum from ETF_TMP3
}
以上代码块耗时 713 ms。
优化后:
使用 pivot by 子句根据时间、股票代码对于数据表重新排序,将时间作为行,股票代码作为列,然后使用ffill 函数填充 NULL 元素,使用 avg 函数计算均值,最后 rowSum 函数计算每个时间点的股票价值之和,仅需以下一行代码,即可实现上述所有步骤。示例如下:
timer t2 = select rowSum(ffill(last(weightedPrice))) from ETF pivot by Time, Symbol
查询耗时 23 ms。
each(eqObj, t1.values(), t2.values()) //true
与优化前写法相比,优化后写法查询性能提升约 30 倍。
此例中,仅以两只股票举例说明,当股票数量更多时,使用循环遍历的方式更为繁琐,而且性能极低。
pivot by 是 DolphinDB SQL 独有的功能,是对标准SQL语句的拓展,可以将表中两列或多列的内容按照两个维度重新排列,亦可配合数据转换函数使用。不仅编程简洁,而且无需产生中间过程数据表,有效避免了内存不足的问题,极大地提升了计算速度。
以下是与此场景类似的另外一个案例,属于物联网典型场景。
场景:假设一个物联网场景中存在三个测点进行实时数据采集,期望针对每个测点分别计算一分钟均值,再对同一分钟的三个测点均值求和。
首先,产生模拟数据,示例如下:
N = 10000
t = table(take(`id1`id2`id3, N) as id,
rand(2021.01.01T00:00:00.000 + 100000 * (1..10000), N) as time,
rand(10.0, N) as value)
使用 bar 函数对时间做一分钟聚合,并使用 pivot by 子句根据分钟、测点对数据表重新排序,将分钟作为行,测点作为列,然后使用 ffill 函数填充 NULL 元素,使用 avg 函数计算均值,然后再使用 rowSum 函数计算每个时间点的测点值之和。最后使用 group by 子句结合 interval 函数对于缺失值进行填充。
timePeriod = 2021.01.01T00:00:00.000 : 2021.01.01T01:00:00.000
timer result = select sum(rowSum) as v from (
select rowSum(ffill(avg(value))) from t
where id in `id1`id2`id3, time
between timePeriod
pivot by bar(time, 60000) as minute, id)
group by interval(minute, 1m, "prev") as minute
查询耗时 12 ms。
4.10 根据成交量切分时间窗口
场景:已知股票市场分钟线数据,期望根据成交量对股票在时间上进行切分,最终得到时间窗口不等的若干条数据,包含累计成交量,以及每个窗口的起止时间。
具体切分规则为:假如期望对某只股票成交量约150万股便进行一次时间切分。切分时,如果当前组加上下一条数据的成交量与150万更接近,则下一条数据加入当前组;否则,从下一条数据开始一个新的组。
首先,产生模拟数据,示例如下:
N = 28
t = table(take(`600000.SH, N) as wind_code,
take(2015.02.11, N) as date,
take(13:03:00..13:30:00, N) as time,
take([288656, 234804, 182714, 371986, 265882, 174778, 153657, 201388, 175937, 138388, 169086, 203013, 261230, 398971, 692212, 494300, 581400, 348160, 250354, 220064, 218116, 458865, 673619, 477386, 454563, 622870, 458177, 880992], N) as volume)
根据切分规则,自定义一个累计函数 caclCumVol,如果当前组需要包含下一条数据的成交量,返回新的累计成交量;否则,返回下一条数据的成交量,即开始一个新的组。
def caclCumVol(target, cumVol, nextVol) {
newVal = cumVol + nextVol
if(newVal < target) return newVal
else if(newVal - target > target - cumVol) return nextVol
else return newVal
}
使用高阶函数 accumulate,迭代地应用 caclCumVol 函数到前一个累计成交量和下一个成交量上。如果累计成交量等于当前一条数据的成交量,则表示开始一个新的组,此时记录下当前这条数据的时间,作为一个窗口的起始时间,否则为空,通过 ffill 填充,使得同一组数据拥有相同的起始时间,最后根据起始时间分组并做聚合计算。
timer result = select first(wind_code) as wind_code, first(date) as date, sum(volume) as sum_volume, last(time) as endTime
from t
group by iif(accumulate(caclCumVol{1500000}, volume) == volume, time, NULL).ffill() as startTime
查询耗时 0.9 ms。
4.11 股票因子归整
场景:已知沪深两市某个10分钟因子,分别存储为一张分布式表,另有一张股票清单维度表存储股票代码相关信息。期望从沪市、深市分别取出部分股票代码相应因子,根据股票、日期对于因子做分组归整,并做行列转换。
首先,自定义一个函数createDBAndTable,用于创建分布式库表,如下:
def createDBAndTable(dbName, tableName) {
if(existsTable(dbName, tableName)) return loadTable(dbName, tableName)
dbDate = database(, VALUE, 2021.07.01..2021.07.31)
dbSecurityID = database(, HASH, [SYMBOL, 1])
db = database(dbName, COMPO, [dbDate, dbSecurityID])
model = table(1:0, `SecurityID`Date`Time`FactorID`FactorValue, [SYMBOL, DATE, TIME, SYMBOL, DOUBLE])
return createPartitionedTable(db, model, tableName, `Date`SecurityID)
}
执行以下代码,创建两个分布式表、一个维度表,并写入模拟数据,如下:
dates = 2020.01.01..2021.10.31
time = join(09:30:00 + 1..12 * 60 * 10, 13:00:00 + 1..12 * 60 * 10)
syms = format(1..2000, "000000") + ".SH"
tmp = cj(cj(table(dates), table(time)), table(syms))
t = table(tmp.syms as SecurityID, tmp.dates as Date, tmp.time as Time, take(["Factor01"], tmp.size()) as FactorID, rand(100.0, tmp.size()) as FactorValue)
createDBAndTable("dfs://Factor10MinSH", "Factor10MinSH").append!(t)
syms = format(2001..4000, "000000") + ".SZ"
tmp = cj(cj(table(dates), table(time)), table(syms))
t = table(tmp.syms as SecurityID, tmp.dates as Date, tmp.time as Time, take(["Factor01"], tmp.size()) as FactorID, rand(100.0, tmp.size()) as FactorValue)
createDBAndTable("dfs://Factor10MinSZ", "Factor10MinSZ").append!(t)
db = database("dfs://infodb", VALUE, 1 2 3)
model = table(1:0, `SecurityID`Info, [SYMBOL, STRING])
if(!existsTable("dfs://infodb", "MdSecurity")) createTable(db, model, "MdSecurity")
loadTable("dfs://infodb", "MdSecurity").append!(
table(join(format(1..2000, "000000") + ".SH", format(2001..4000, "000000") + ".SZ") as SecurityID,
take(string(NULL), 4000) as Info))
优化前:
首先,分别从沪市、深市取出因子 Factor01 在某个时间范围的数据,合并后,再从股票代码维度表中取出需要归整的股票,通过表连接方式对合并结果进行过滤,最后使用 pivot by 子句根据时间、股票代码两个维度重新排列。
timer {
nt1 = select concatDateTime(Date, Time) as TradeTime, SecurityID, FactorValue from loadTable("dfs://Factor10MinSH", "Factor10MinSH") where Date between 2019.01.01 : 2021.10.31, FactorID = "Factor01"
nt2 = select concatDateTime(Date, Time) as TradeTime, SecurityID, FactorValue from loadTable("dfs://Factor10MinSZ", "Factor10MinSZ") where Date between 2019.01.01 : 2021.10.31, FactorID = "Factor01"
unt = unionAll(nt1, nt2)
sec = select SecurityID from loadTable("dfs://infodb", "MdSecurity") where substr(SecurityID, 0, 3) in ["001", "003", "005", "007"]
res = select * from lj(sec, unt, `SecurityID)
res = select FactorValue from res pivot by TradeTime, SecurityID
}
查询耗时 6922 ms。
优化后:
首先,从股票代码维度表中取出需要归整的股票列表,然后从沪深两市取出因子 Factor01。使用 in 关键字进行过滤,再使用 pivot by 根据时间、股票代码两个维度进行重新排列,最后合并结果。
timer {
sec = exec SecurityID from loadTable("dfs://infodb", "MdSecurity") where substr(SecurityID, 0, 3) in ["001", "003", "005", "007"]
nt1 = select concatDateTime(Date, Time) as TradeTime, SecurityID, FactorValue from loadTable("dfs://Factor10MinSH", "Factor10MinSH") where Date between 2019.01.01 : 2021.10.31, SecurityID in sec, FactorID = "Factor01"
re1 = panel(nt1.TradeTime, nt1.SecurityID, nt1.FactorValue)
nt2 = select concatDateTime(Date, Time) as TradeTime, SecurityID, FactorValue from loadTable("dfs://Factor10MinSZ", "Factor10MinSZ") where Date between 2019.01.01 : 2021.10.31, SecurityID in sec, FactorID = "Factor01"
re2 = panel(nt2.TradeTime, nt2.SecurityID, nt2.FactorValue)
res = re1 + re2
}
查询耗时 5129 ms。
与优化前相比,优化后查询性能提升约 20%。
综合对比上述写法,概括出几个SQL编写技巧:
(1)尽量避免不必要的表连接;
(2)尽可能早地使用分区过滤;
(3)推迟数据的合并。
4.12 根据交易额统计单子类型
场景:对不同日期、不同股票、买单卖单,分别统计某个时间范围内的特大单、大单、中单、小单的累计交易量、交易额。
具体规则为:交易额小于4万是小单,大于等于4万且小于20万是中单,大于等于20万且小于100万是大单,大于100万是特大单。
首先,产生模拟数据,示例如下:
N = 1000000
t = table(take(2021.11.01..2021.11.15, N) as date,
take([09:30:00, 09:35:00, 09:40:00, 09:45:00, 09:47:00, 09:49:00, 09:50:00, 09:55:00, 09:56:00, 10:00:00], N) as time,
take(`AAPL`FB`MSFT$SYMBOL, N) as symbol,
take([10000, 30000, 50000, 80000, 100000], N) as volume,
rand(100.0, N) as price,
take(`BUY`SELL$SYMBOL, N) as side)
优化前:
使用 group by 根据日期、股票、买卖方向分组,使用四个查询语句分别计算小单、中单、大单、特大单的累计交易量、交易额,再将结果合并。
timer {
// 小单
resS = select sum(volume) as volume_sum, sum(volume * price) as amount_sum, 0 as type
from t
where time <= 10:00:00, volume * price < 40000
group by date, symbol, side
// 中单
resM = select sum(volume) as volume_sum, sum(volume * price) as amount_sum, 1 as type
from t
where time <= 10:00:00, 40000 <= volume * price < 200000
group by date, symbol, side
// 大单
resB = select sum(volume) as volume_sum, sum(volume * price) as amount_sum, 2 as type
from t
where time <= 10:00:00, 200000 <= volume * price < 1000000
group by date, symbol, side
// 特大单
resX = select sum(volume) as volume_sum, sum(volume * price) as amount_sum, 3 as type
from t
where time <= 10:00:00, volume * price >= 1000000
group by date, symbol, side
res1 = table(N:0, `date`symbol`side`volume_sum`amount_sum`type, [DATE, SYMBOL, SYMBOL, LONG, DOUBLE, INT])
res1.append!(resS).append!(resM).append!(resB).append!(resX)
}
查询耗时 135 ms。
第一种优化写法:
自定义一个函数 getType,使用 iff 函数嵌套方式得到当前成交单子类型,然后使用 group by 对日期、股票、买卖方向、单子类型分组,并计算累计交易量、交易额。
def getType(amount) {
return iif(amount < 40000, 0, iif(amount >= 40000 && amount < 200000, 1, iif(amount >= 200000 && amount < 1000000, 2, 3)))
}
timer res2 = select sum(volume) as volume_sum, sum(volume*price) as amount_sum
from t
where time <= 10:00:00
group by date, symbol, side, getType(volume * price) as type
查询耗时 114 ms。
与优化前写法相比,优化后写法查询性能提升约 20%。虽然性能略有提升,但大大简化了代码编写。
需要注意的是,此处有个优化技巧,group by 后面字段类型为 INT、LONG、SHORT、SYMBOL 时,系统内部进行了优化,查询性能会有一定提升,所以本例中 getType 函数返回类型为 INT。
第二种优化写法:
range = [0.0, 40000.0, 200000.0, 1000000.0, 100000000.0]
timer res3 = select sum(volume) as volume_sum, sum(volume*price) as amount_sum
from t
where time <= 10:00:00
group by date, symbol, side, asof(range, volume*price) as type
查询耗时 95 ms。
与第一种优化写法区别在于,使用 asof 函数而非自定义函数,判断交易额落在哪个区间,然后以此分组并计算累计交易量、交易额。
each(eqObj, (select date, symbol, side, type, volume_sum, amount_sum
from res1 order by date, symbol, side, type).values(), res2.values()) // true
each(eqObj, res2.values(), res3.values()) // true
以下是 asof 函数在另外一个场景下的应用。
场景:针对某个日期、某只股票,统计某一数值列落在不同的区间范围的记录数目。
首先,产生模拟数据,示例如下:
N = 100000
t = table(take(2021.11.01, N) as date,
take(`AAPL, N) as code,
rand([-5, 5, 10, 15, 20, 25, 100], N) as value)
range = [-9999, 0, 10, 30, 9999]
优化前:
自定义一个函数 generateGrp,遍历不同的区间范围,判断数值列是否包含在当前的区间范围内,区间范围遵循左闭右开原则,并返回一个布尔型向量。如果为 true,表示数值包含在当前的区间范围内,则以下划线连接区间范围的左右边界作为分组 ID;如果为 false,表示数值不包含在当前的区间范围内,则将其置为空字符串。
然后使用高阶函数 reduce 将遍历结果合并,最后使用 group by 根据日期、股票、不同的区间范围分组,并聚合计算记录数目。
def generateGrp(range, val) {
res = array(ANY, range.size()-1)
for(i in 0 : (range.size()-1)) {
cond = val >= range[i] && val < range[i+1]
res[i] = iif(cond, strReplace(range[i] + "_" + range[i+1], "-", ""), string(NULL))
}
return reduce(add, res)
}
timer res1 = select count(*) from t group by date, code, generateGrp(range, value) as grp
查询耗时 38 ms。
优化后:
使用 asof 函数结合 group by 语句对于日期、股票、不同的区间范围分组,并聚合计算记录数目。
timer res2 = select count(*) from t
group by date, code, asof(range, value) as grp
查询耗时 14 ms。
与优化前写法相比,优化后写法查询性能提升约 2 倍多。
asof 函数一般用于分段统计,与循环相比,不仅性能大大提升,而且代码更为简洁。下一个案例也是使用了asof 函数用于统计。
5 元编程相关案例
5.1 动态生成 SQL 语句案例 1
场景:已知股票市场分钟线数据,使用元编程方式,根据股票、日期分组,每隔 10 分钟做一次聚合计算。
首先,产生模拟数据,示例如下:
N = 10000000
t = table(take(format(1..4000, "000000") + ".SH", N) as SecurityID,
take(2021.10.01..2021.10.31, N) as DataDate,
take(join(09:30:00 + 1..120 * 60, 13:00:00 + 1..120 * 60), N) as TradeTime,
rand(100.0, N) as cal_variable)
min_num = 10
优化前:
查询语句拼接为一个字符串,使用 parseExpr 函数将字符串解析为元代码,再使用 eval 函数执行生成的元代码。
res = parseExpr("select " + avg + "(cal_variable) as FactorValue from t group by bar(TradeTime, " + min_num + "m) as minute_TradeTime, SecurityID, DataDate").eval()
查询耗时 219 ms。
优化后:
DolphinDB 内置了 sql 函数用于动态生成 SQL 语句,然后使用 eval 函数执行生成的 SQL 语句。其中,sqlCol 函数将列名转化为表达式,makeCall 函数指定参数调用 bar 函数并生成脚本,sqlColAlias 函数使用元代码和别名定义一个列。
groupingCols = [sqlColAlias(makeCall(bar, sqlCol("TradeTime"), duration(min_num.string() + "m")), "minute_TradTime"), sqlCol("SecurityID"), sqlCol("DataDate")]
res = sql(select = sqlCol("cal_variable", funcByName("avg"), "FactorValue"),
from = t, groupBy = groupingCols, groupFlag = GROUPBY).eval()
查询耗时 200 ms。
类似地,sqlUpdate 函数用于动态生成 SQL update 语句的元代码,sqlDelete 函数用于动态生成 SQL delete语句的元代码。
5.2 动态生成 SQL 语句案例 2
场景:每天需要执行一组查询,合并查询结果。
首先,产生模拟数据,示例如下:
N = 100000
t = table(take(50982208 51180116 41774759, N) as vn,
rand(25 1180 50, N) as bc,
take(814 333 666, N) as cc,
take(11 12 3, N) as stt,
take(2 116 14, N) as vt,
take(2020.02.05..2020.02.05, N) as dsl,
take(52354079..52354979, N) as mt)
例如,每天需要执行一组查询,如下:
t1 = select * from t where vn=50982208, bc=25, cc=814, stt=11, vt=2, dsl=2020.02.05, mt < 52355979 order by mt desc limit 1
t2 = select * from t where vn=50982208, bc=25, cc=814, stt=12, vt=2, dsl=2020.02.05, mt < 52355979 order by mt desc limit 1
t3 = select * from t where vn=51180116, bc=25, cc=814, stt=12, vt=2, dsl=2020.02.05, mt < 52354979 order by mt desc limit 1
t4 = select * from t where vn=41774759, bc=1180, cc=333, stt=3, vt=116, dsl=2020.02.05, mt < 52355979 order by mt desc limit 1
reduce(unionAll, [t1, t2, t3, t4])
以下案例通过元编程动态生成 SQL 语句实现。过滤条件包含的列和排序的列相同,可编写如下自定义函数 bundleQuery 实现相关操作:
def bundleQuery(tbl, dt, dtColName, mt, mtColName, filterColValues, filterColNames){
cnt = filterColValues[0].size()
filterColCnt = filterColValues.size()
orderByCol = sqlCol(mtColName)
selCol = sqlCol("*")
filters = array(ANY, filterColCnt + 2)
filters[filterColCnt] = expr(sqlCol(dtColName), ==, dt)
filters[filterColCnt+1] = expr(sqlCol(mtColName), <, mt)
queries = array(ANY, cnt)
for(i in 0:cnt) {
for(j in 0:filterColCnt){
filters[j] = expr(sqlCol(filterColNames[j]), ==, filterColValues[j][i])
}
queries.append!(sql(select=selCol, from=tbl, where=filters, orderBy=orderByCol, ascOrder=false, limit=1))
}
return loop(eval, queries).unionAll(false)
}
bundleQuery 中各个参数的含义如下:
- tbl 是数据表。
- dt 是过滤条件中日期的值。
- dtColName 是过滤条件中日期列的名称。
- mt 是过滤条件中 mt 的值。
- mtColName 是过滤条件中 mt 列的名称,以及排序列的名称。
- filterColValues 是其他过滤条件中的值,用元组表示,其中的每个向量表示一个过滤条件,每个向量中的元素表示该过滤条件的值。
- filterColNames 是其他过滤条件中的列名,用向量表示。
上面一组 SQL 语句,相当于执行以下代码:
dt = 2020.02.05
dtColName = "dsl"
mt = 52355979
mtColName = "mt"
colNames = `vn`bc`cc`stt`vt
colValues = [50982208 50982208 51180116 41774759, 25 25 25 1180, 814 814 814 333, 11 12 12 3, 2 2 2 116]
bundleQuery(t, dt, dtColName, mt, mtColName, colValues, colNames)
登录 admin 管理员用户后,执行以下脚本将 bundleQuery 函数定义为函数视图,以确保在集群的任何节点重启系统之后,都可直接调用该函数。
addFunctionView(bundleQuery)
如果每次都手动编写全部 SQL 语句,工作量大,并且扩展性差,通过元编程动态生成 SQL 语句可以解决这个问题。

DolphinDB VSCode 插件使用教程
VSCode 是微软开发的一款轻量、高性能又有极强扩展性的代码编辑器。它提供了强大的插件框架,开发者可以通过编写插件拓展 VSCode 编辑器的功能,甚至支持新的编程语言。
为提升用户体验,我们开发了针对 DolphinDB 数据库的 VSCode 插件,在 VSCode 中增加了对自研的 DolphinDB 脚本语言的支持,让用户可以编写并执行脚本来操作数据库,或查看数据库中的数据。
本教程主要包含以下内容:
- 下载安装
- 编辑服务器链接配置
- 新建脚本文件
- 执行代码
- 在线浏览数据集和生成的对象
- 函数的自动补齐和实时文档浏览
- VSCode视窗
点击下方图片跳转链接,快速查看新功能介绍视频

下载安装
点击 VSCode 左侧导航栏的 Extensions 图标,或者通过 Ctrl+Shift+X 快捷键打开插件安装窗口。在搜索框中输入 dolphindb,即可搜索到 dolphindb 插件,点击 Install 进行安装。具体方法可查看插件详情。

如果因为网络原因安装失败,需通过下方链接手动下载后缀为 .vsix 的插件,点击 Version History 下载最新的版本到本地,并将其拖到 VSCode 插件面板中。
https://marketplace.visualstudio.com/items?itemName=dolphindb.dolphindb-vscode
注意:安装后需重启 VSCode 使插件生效。
编辑服务器连接配置
打开 VSCode 设置。在搜索框中输入 dolphindb,点击下方的 settings.json ,编辑里面的 dolphindb.connections 配置项。 dolphindb.connections 下的一个 {...} 对象,表示一个连接配置,用户可通过手动修改该对象,来创建或删除会话。其中 name 和 url 是必填属性。
"dolphindb.connections": [
//一个连接配置如下:
{
"name": "local8848", // 连接的别名
"url": "ws://127.0.0.1:8848", // 连接的 ip 和 port,格式为 "ws://ip:port"
"autologin": true, // 是否开启自动登录,需配置用户名密码才生效
"username": "admin",
"password": "123456",
"python": false // 是否启用 python parser
}
]配置连接后,用户可以通过编辑器左侧面板资源管理器下的 DOLPHINDB 窗口查看并切换连接。默认情况下,DOLPHINDB 窗口显示的连接并没有连接到服务器,但选择连接并在该连接下执行脚本后便会自动连接到服务器。切换服务器连接后,原连接不会断开。
注意:若修改了连接配置项,原连接会自动断开。

新建脚本文件
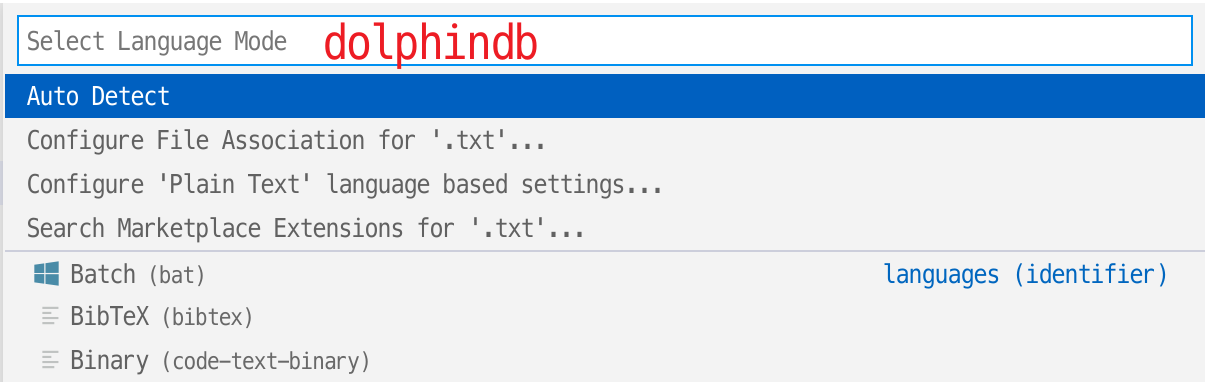
- 如果脚本文件名后缀是 .dos ,插件会自动识别为 DolphinDB 语言。
- 如果脚本文件名后缀非 .dos,比如是 .txt,则需要手动关联 DolphinDB 语言。方法如下:点击 VSCode 编辑器右下角状态栏的语言选择按钮,如下图:

在语言选择弹框中输入 dolphindb 后回车,即可切换当前文件关联的语言为 DolphinDB 语言。
执行代码
VSCode 中默认通过快捷键 Ctrl + E 执行 DolphinDB 代码。如果需要自定义代码执行的快捷键,则需在 VSCode 的 文件 > 首选项 > 键盘快捷方式 (File > Preferences > Keyboard Shortcuts) 中进行修改。在搜索栏中输入 dolphindb,找到 execute 并双击,根据提示修改快捷键。
若使用默认快捷键,则通过 Ctrl + E 快捷键来执行选中的代码,若没有选中代码,则会执行当前光标所在的行。
在线浏览数据集和生成的对象。
VSCode 编辑器左侧面板资源管理器中展示了连接的会话,用户可在此查看会话中的所有变量。这里具体展示了变量的名称,类型,维度以及占用的内存大小。用户也可点击变量栏右侧的图标在浏览器浏览该变量具体信息。
请确保以下两点,以避免服务器出现连接错误 (如:ws://xxx errored):
- DolphinDB Server 版本不低于 1.30.16 或 2.00.4 。
- 如果配置了系统代理,则代理软件以及代理服务器需要支持 WebSocket 连接。否则请在系统中关闭代理,或者将 DolphinDB Server 的 IP 添加到排除列表,然后重启 VSCode。
函数的自动补齐和实时文档浏览。
用户在 VSCode 编辑器输入函数时,将自动补齐函数名,且可展开函数的具体信息。将光标悬浮至对应函数可自动显示该函数对应的文档。
VSCode 视窗
- 变量导航条
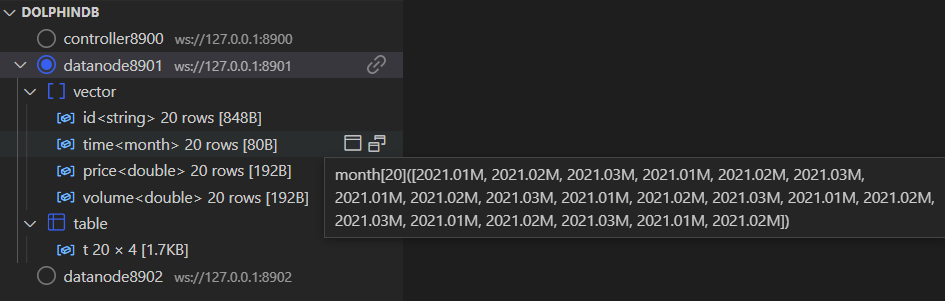
连接栏:点击左侧圆形图标切换到对应的连接,点击右侧的链接图标可断开连接。
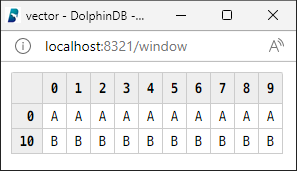
变量栏:鼠标悬浮于对应变量,可查看该变量的值。变量(scalar 和 pair 类型除外)右侧有两个图标。点击第一个图标会将变量在浏览器中进行展示,且每次点击都会刷新变量值。点击第二个图标,会打开浏览器弹窗(请开启浏览器允许弹框功能)如下图,便于用户查看变量及观察变量前后的变化。
- 数据浏览器
点击变量右侧的第一个图标可以打开一个公共的浏览器页面(localhost:8321)。可在该页面查看变量的内容。其他用户也可通过(ip:8321)查看对应 ip 用户代码执行的实时结果。

- 终端
DolphinDB 脚本的执行结果会在终端显示:
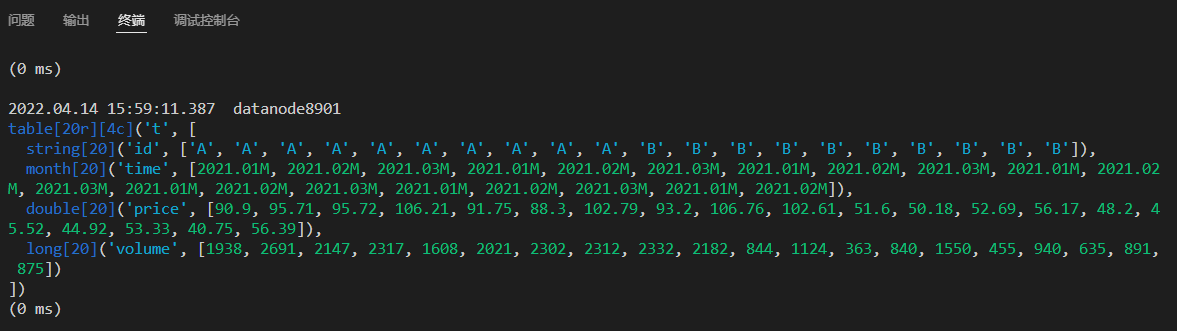
执行结果的第一行显示代码的执行时间,会话对应的服务器别名。
以表为例,打印执行结果见上图:
- 首先显示数据形式,此处为 table。[20r][4c] 表示该表是一个 20 行 4 列的数据表。
- 然后依次打印每列的数据类型,长度,列名以及包含的数据。
- 最后显示代码执行的耗时。
我们今天的关于代码教程丨用 DolphinDB 实时计算分钟资金流的分享已经告一段落,感谢您的关注,如果您想了解更多关于5G+工业互联网丨DolphinDB携手诺基亚贝尔打造高精度实时计算平台、DolphinDB Python API 离线安装教程、DolphinDB SQL 案例教程、DolphinDB VSCode 插件使用教程的相关信息,请在本站查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

